Einige Leser haben vielleicht schon einmal von Centrifugo gehört . Dieser Artikel konzentriert sich auf die Entwicklung der zweiten Version des Servers und der neuen Echtzeitbibliothek für die zugrunde liegende Go-Sprache.
Ich heiße Alexander Emelin. Letzten Sommer bin ich dem Avito-Team beigetreten, wo ich jetzt bei der Entwicklung des Avito Messenger-Backends helfe. Die neue Arbeit, die in direktem Zusammenhang mit der schnellen Zustellung von Nachrichten an Benutzer steht, und die neuen Kollegen haben mich dazu inspiriert, weiter am Open-Source-Projekt Centrifugo zu arbeiten.

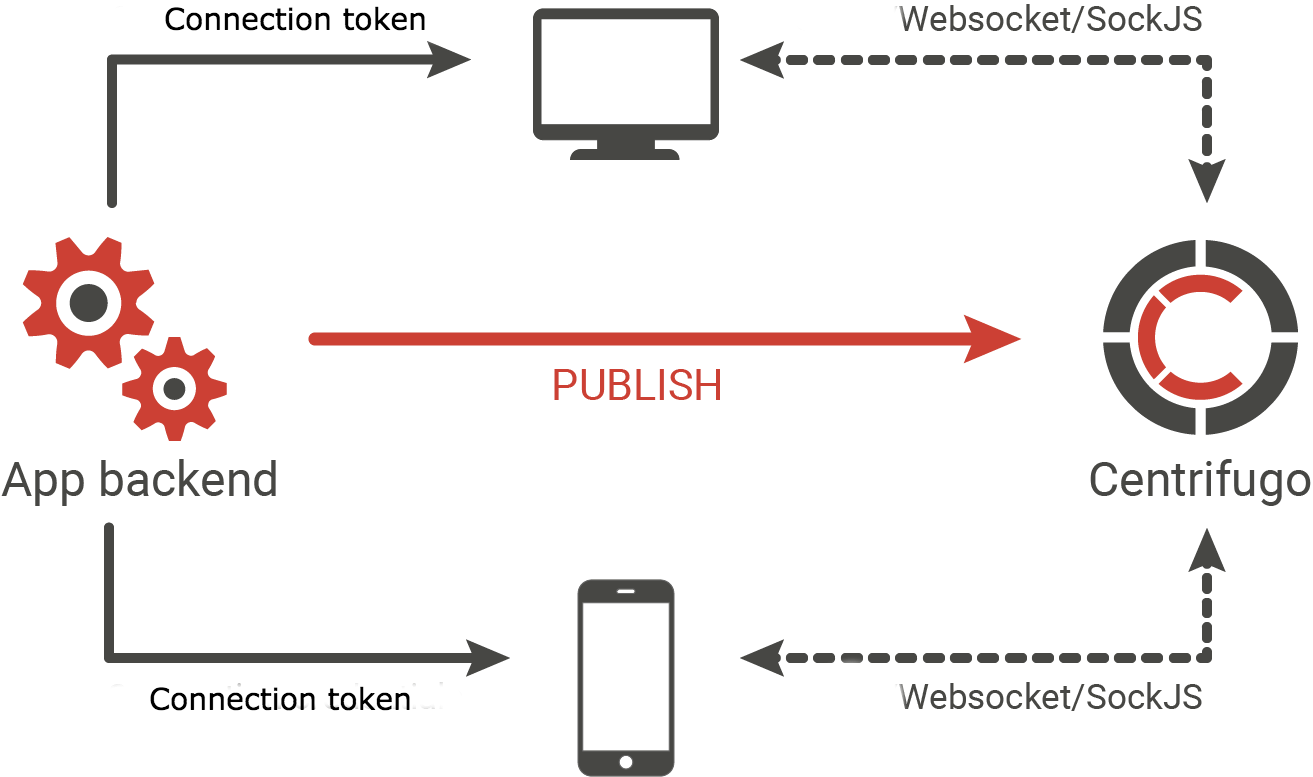
Kurz gesagt - dies ist ein Server, der die Aufgabe übernimmt, konstante Verbindungen von Benutzern Ihrer Anwendung aufrechtzuerhalten. Websocket- oder SockJS- Polyfill wird als Transport verwendet. Wenn keine Websocket-Verbindung hergestellt werden kann, können Eventsource-, XHR-Streaming-, Long-Polling- und andere HTTP-basierte Transporte ausgeführt werden. Clients abonnieren Kanäle, für die das Backend über die Centrifuge-API neue Nachrichten veröffentlicht, sobald sie entstehen. Anschließend werden die Nachrichten an Benutzer übermittelt, die den Kanal abonniert haben. Mit anderen Worten, es ist ein PUB / SUB-Server.
Derzeit wird der Server in einer relativ großen Anzahl von Projekten verwendet. Darunter befinden sich beispielsweise einige Mail.Ru-Projekte (Intranet, Technopark / Technosphere-Schulungsplattformen, Zertifizierungszentrum usw.) mit Centrifugo, einem schönen Dashboard an der Rezeption im Büro von Badoo Moskau, und 350.000 Benutzer sind gleichzeitig mit dem spot.im-Dienst verbunden zur Zentrifuge.
Einige Links zu früheren Artikeln über den Server und seine Anwendung für diejenigen, die zuerst von dem Projekt erfahren:
Ich habe im Dezember letzten Jahres mit der Arbeit an der zweiten Version begonnen und mache bis heute weiter. Mal sehen, was passiert. Ich schreibe diesen Artikel nicht nur, um das Projekt irgendwie bekannt zu machen, sondern auch, um vor der Veröffentlichung von Centrifugo v2 ein etwas konstruktiveres Feedback zu erhalten - jetzt gibt es Raum für Manöver und rückwärts inkompatible Änderungen.
Echtzeitbibliothek für Go
In der Go-Community stellt sich von Zeit zu Zeit die Frage: Gibt es Alternativen zu socket.io on Go? Manchmal bemerkte ich, wie Entwicklern als Reaktion darauf geraten wird, sich auf Centrifugo zu konzentrieren. Centrifugo ist jedoch ein selbst gehosteter Server, keine Bibliothek - der Vergleich ist nicht fair. Ich wurde auch mehrmals gefragt, ob Centrifugo-Code zum Schreiben von Echtzeitanwendungen in Go wiederverwendet werden kann. Und die Antwort war: theoretisch möglich, aber ich konnte die Abwärtskompatibilität der API interner Pakete nicht auf eigenes Risiko garantieren. Es ist klar, dass es für niemanden einen Grund gibt, dies zu riskieren, und Gabeln ist auch eine Option. Außerdem würde ich nicht sagen, dass die API für interne Pakete im Allgemeinen für eine solche Verwendung vorbereitet wurde.
Daher bestand eine der ehrgeizigen Aufgaben, die ich bei der Arbeit an der zweiten Version des Servers lösen wollte, darin, den Serverkern in Go in eine separate Bibliothek zu unterteilen. Ich halte dies für sinnvoll, wenn man bedenkt, wie viele Funktionen die Zentrifuge hat, um an die Produktion angepasst zu werden. Es sind sofort viele Funktionen verfügbar, mit denen skalierbare Echtzeitanwendungen erstellt werden können, sodass Entwickler keine eigenen Lösungen mehr schreiben müssen. Ich habe bereits früher über diese Funktionen geschrieben und werde im Folgenden auch einige davon skizzieren.
Ich werde versuchen, ein weiteres Plus der Existenz einer solchen Bibliothek zu rechtfertigen. Die meisten Centrifugo-Benutzer sind Entwickler, die Backends in Sprachen / Frameworks mit schlechter Parallelitätsunterstützung schreiben (z. B. Django / Flask / Laravel / ...): Arbeiten Sie nach Möglichkeit mit vielen dauerhaften Verbindungen auf nicht offensichtliche oder ineffiziente Weise. Dementsprechend können nicht alle Benutzer bei der Entwicklung eines in Go geschriebenen Servers helfen (kitschig wegen mangelnder Sprachkenntnisse). Daher kann auch eine sehr kleine Community von Go-Entwicklern in der Bibliothek bei der Entwicklung des Centrifugo-Servers helfen.
Das Ergebnis ist eine Zentrifugenbibliothek . Dies ist immer noch WIP, aber absolut alle Funktionen, die in der Beschreibung auf Github angegeben sind, sind implementiert und funktionieren. Da die Bibliothek eine ziemlich umfangreiche API bietet, bevor ich die Abwärtskompatibilität garantiere, würde ich gerne einige erfolgreiche Beispiele für die Verwendung in realen Projekten auf Go hören. Es gibt noch keine. Sowie erfolglos :). Es gibt keine.
Ich verstehe, dass ich durch die Benennung der Bibliothek auf die gleiche Weise wie der Server für immer mit Verwirrung umgehen werde. Ich denke jedoch, dass dies die richtige Wahl ist, da Clients (wie z. B. centrifuge-js, centrifuge-go) sowohl mit der Centrifuge-Bibliothek als auch mit dem Centrifugo-Server arbeiten. Außerdem ist der Name in den Köpfen der Benutzer bereits fest verankert, und ich möchte diese Assoziationen nicht verlieren. Und doch werde ich zur besseren Übersicht noch einmal klarstellen:
- Zentrifuge - eine Bibliothek für die Go-Sprache,
- Centrifugo ist eine schlüsselfertige Lösung, ein separater Service, der in Version 2 auf der Centrifuge-Bibliothek basiert.
Aufgrund seines Designs geht Centrifugo (ein eigenständiger Dienst, der nichts über Ihr Backend weiß) davon aus, dass der Nachrichtenfluss über den Echtzeittransport vom Server zum Client erfolgt. Was meinst du Wenn der Benutzer beispielsweise eine Nachricht in den Chat schreibt, muss diese Nachricht zuerst an das Anwendungs-Backend (z. B. AJAX im Browser) gesendet, auf der Backend-Seite validiert, bei Bedarf in der Datenbank gespeichert und dann an die Centrifuge-API gesendet werden. Die Bibliothek hebt diese Einschränkung auf, sodass Sie den bidirektionalen Austausch asynchroner Nachrichten zwischen dem Server und dem Client sowie RPC-Aufrufe organisieren können.
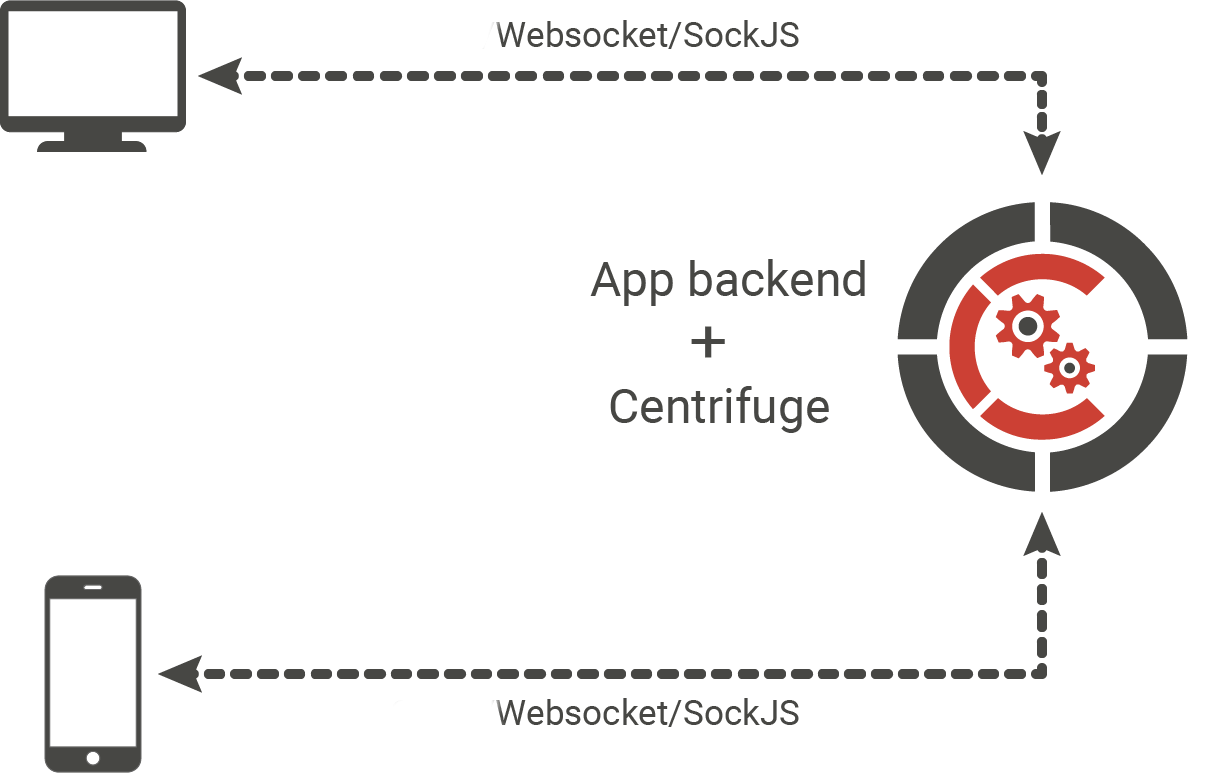
Schauen wir uns ein einfaches Beispiel an: Wir implementieren einen kleinen Server auf Go mithilfe der Centrifuge-Bibliothek. Der Server empfängt Nachrichten von Browser-Clients über Websocket, der Client verfügt über ein Textfeld, in das Sie eine Nachricht eingeben können, drücken Sie die Eingabetaste - und die Nachricht wird an alle Benutzer gesendet, die den Kanal abonniert haben. Das heißt, die einfachste Version des Chats. Es schien mir am bequemsten, dies in Form eines Kerns zu platzieren .
Sie können wie gewohnt laufen:
git clone https:
Gehen Sie dann zu http: // localhost: 8000 und öffnen Sie mehrere Browser-Registerkarten.
Wie Sie sehen können, tritt der Einstiegspunkt in die Geschäftslogik der Anwendung auf, wenn die Rückruffunktionen On().Connect() hängen bleiben:
node.On().Connect(func(ctx context.Context, client *centrifuge.Client, e centrifuge.ConnectEvent) centrifuge.ConnectReply { client.On().Disconnect(func(e centrifuge.DisconnectEvent) centrifuge.DisconnectReply { log.Printf("client disconnected") return centrifuge.DisconnectReply{} }) log.Printf("client connected via %s", client.Transport().Name()) return centrifuge.ConnectReply{} })
Der auf Rückrufen basierende Ansatz schien mir für die Interaktion mit der Bibliothek am bequemsten zu sein. Außerdem wird bei der Implementierung des Socket-io-Servers auf Go ein ähnlicher, nur schwach typisierter Ansatz verwendet. Wenn Sie plötzlich darüber nachdenken, wie die API idiomatischer gemacht werden könnte, würde ich mich freuen zu hören.
Dies ist ein sehr einfaches Beispiel, das nicht alle Funktionen der Bibliothek demonstriert. Jemand kann bemerken, dass es für solche Zwecke einfacher ist, eine Bibliothek für die Arbeit mit Websocket zu verwenden. Zum Beispiel Gorilla Websocket. Das ist eigentlich so. Selbst in diesem Fall müssen Sie jedoch einen anständigen Teil des Servercodes aus dem Beispiel im Gorilla Websocket-Repository kopieren. Was ist, wenn:
- Sie müssen die Anwendung auf mehrere Computer skalieren.
- oder Sie benötigen nicht einen gemeinsamen Kanal, sondern mehrere - und Benutzer können diese dynamisch abonnieren und abbestellen, während Sie in Ihrer Anwendung navigieren.
- oder Sie müssen arbeiten, wenn die Websocket-Verbindung nicht hergestellt werden konnte (es gibt keine Unterstützung im Client-Browser, es gibt eine Browser-Erweiterung, eine Art Proxy auf dem Weg zwischen dem Client und dem Server unterbricht die Verbindung).
- oder Sie müssen Nachrichten wiederherstellen, die der Client während kurzer Unterbrechungen der Internetverbindung verpasst hat, ohne die Hauptdatenbank zu laden.
- oder Sie benötigen die Kontrolle über die Benutzerautorisierung im Kanal,
- oder Sie müssen die permanente Verbindung von Benutzern trennen, die in der Anwendung deaktiviert sind.
- oder Sie benötigen Informationen darüber, wer sich gerade auf dem Kanal befindet oder welche Ereignisse jemand vom Kanal abonniert / abgemeldet hat.
- oder benötigen Sie Metriken und Überwachung?
Die Centrifuge-Bibliothek kann Ihnen dabei helfen - tatsächlich hat sie alle grundlegenden Funktionen geerbt, die zuvor in Centrifugo verfügbar waren. Weitere Beispiele für die oben genannten Punkte finden Sie auf Github .
Das starke Erbe von Centrifugo kann ein Minus sein, da die Bibliothek alle Servermechaniken übernommen hat, die recht originell sind und möglicherweise für jemanden nicht offensichtlich oder mit unnötigen Funktionen überladen erscheinen. Ich habe versucht, den Code so zu organisieren, dass nicht verwendete Funktionen die Gesamtleistung nicht beeinträchtigen.
Es gibt einige Optimierungen in der Bibliothek, die eine effizientere Nutzung der Ressourcen ermöglichen. Dies kombiniert mehrere Nachrichten in einem Websocket-Frame, um beim Schreiben von Systemaufrufen zu speichern, oder verwendet beispielsweise Gogoprotobuf, um Protobuf-Nachrichten und andere zu serialisieren. Apropos Protobuf.
Binäres Protobuf-Protokoll
Ich wollte wirklich, dass Centrifugo mit Binärdaten arbeitet ( und nicht nur mit mir ), daher wollte ich in der neuen Version zusätzlich zu dem auf JSON basierenden ein Binärprotokoll hinzufügen. Nun wird das gesamte Protokoll als Protobuf-Schema beschrieben . Dies ermöglichte es uns, es strukturierter zu gestalten und einige nicht offensichtliche Entscheidungen im Protokoll der ersten Version zu überdenken.
Ich denke, Sie müssen nicht lange sagen, was die Vorteile von Protobuf gegenüber JSON sind - Kompaktheit, Serialisierungsgeschwindigkeit, strenges Schema. Es gibt einen Nachteil in Form von Unleserlichkeit, aber jetzt haben Benutzer die Möglichkeit zu entscheiden, was für sie in einer bestimmten Situation wichtiger ist.
Im Allgemeinen sollte der vom Centrifugo-Protokoll bei Verwendung von Protobuf anstelle von JSON erzeugte Datenverkehr um das ~ 2-fache abnehmen (ohne Anwendungsdaten). Der CPU-Verbrauch in meinen synthetischen Lasttests verringerte sich im Vergleich zu JSON um das ~ 2-fache. Diese Zahlen sprechen eigentlich wenig darüber, was in der Praxis alles vom Lastprofil einer bestimmten Anwendung abhängt.
Aus Gründen des Interesses habe ich einen Computer mit Debian 9.4 und 32 Intel® Xeon® Platinum 8168 CPU bei 2,70 GHz vCPU-Benchmark gestartet, mit dem wir die Bandbreite der Client-Server-Interaktion bei Verwendung des JSON-Protokolls und des Protobuf-Protokolls vergleichen konnten. Es gab 1000 Abonnenten für 1 Kanal. In diesem Kanal wurden Nachrichten in 4 Streams veröffentlicht und an alle Abonnenten übermittelt. Die Größe jeder Nachricht betrug 128 Bytes.
Ergebnisse für JSON:
$ go run main.go -s ws:
Ergebnisse für den Fall Protobuf:
$ go run main.go -s ws:
Möglicherweise stellen Sie fest, dass der Durchsatz einer solchen Installation bei Protobuf mehr als doppelt so hoch ist. Das Client-Skript finden Sie hier - dies ist das Nats-Benchmark-Skript, das an die Realität von Centrifuge angepasst ist .
Es ist auch erwähnenswert, dass die Leistung der JSON-Serialisierung auf dem Server mit demselben Ansatz wie bei gogoprotobuf - Pufferpool und Codegenerierung - "hochgepumpt" werden kann. Derzeit wird JSON durch ein Paket aus der auf Reflect basierenden Go-Standardbibliothek serialisiert. In Centrifugo wird beispielsweise die erste Version von JSON mithilfe einer Bibliothek , die einen Pufferpool bereitstellt, manuell serialisiert. Ähnliches kann in Zukunft im Rahmen der zweiten Version getan werden.
Hervorzuheben ist, dass Protobuf auch bei der Kommunikation mit dem Server über einen Browser verwendet werden kann. Der Javascript-Client verwendet hierfür die Bibliothek protobuf.js. Da die protobufjs-Bibliothek sehr umfangreich ist und die Anzahl der Benutzer im Binärformat mithilfe des Webpacks und seines Tree-Shaking-Algorithmus gering ist, generieren wir zwei Versionen des Clients - eine nur mit JSON-Protokollunterstützung und die andere mit JSON- und Protobuf-Unterstützung. In anderen Umgebungen, in denen die Größe der Ressourcen keine so wichtige Rolle spielt, können sich Kunden keine Sorgen um diese Trennung machen.
JSON Web Token (JWT)
Eines der Probleme bei der Verwendung eines eigenständigen Servers wie Centrifugo besteht darin, dass er nichts über Ihre Benutzer und deren Authentifizierungsmethode sowie über die Art des Sitzungsmechanismus weiß, den Ihr Backend verwendet. Und Sie müssen die Verbindung irgendwie authentifizieren.
Zu diesem Zweck wurde in der ersten Version von Centrifuge beim Verbinden die SHA-256-HMAC-Signatur verwendet, die auf einem geheimen Schlüssel basiert, der nur dem Backend und der Centrifuge bekannt ist. Dadurch wurde sichergestellt, dass die vom Kunden übermittelte Benutzer-ID wirklich ihm gehört.
Vielleicht war die korrekte Übertragung von Verbindungsparametern und die Erzeugung eines Tokens eine der Hauptschwierigkeiten bei der Integration von Centrifugo in das Projekt.
Als die Zentrifuge erschien, war der JWT-Standard noch nicht so beliebt. Jetzt, einige Jahre später, stehen Bibliotheken für die JWT-Generation für die beliebtesten Sprachen zur Verfügung . Die Hauptidee von JWT ist genau das, was die Zentrifuge benötigt: Bestätigung der Authentizität der übertragenen Daten. In der zweiten Version von HMAC wurde die Verwendung von JWT durch eine manuell generierte Signatur ersetzt. Dies ermöglichte es, die Notwendigkeit der Unterstützung von Hilfsfunktionen für die korrekte Generierung von Token in Bibliotheken für verschiedene Sprachen zu beseitigen.
In Python kann beispielsweise ein Token für die Verbindung mit Centrifugo wie folgt generiert werden:
import jwt import time token = jwt.encode({"user": "42", "exp": int(time.time()) + 10*60}, "secret").decode() print(token)
Es ist wichtig zu beachten, dass Sie den Benutzer bei Verwendung der Centrifuge-Bibliothek mithilfe der nativen Go-Methode authentifizieren können - innerhalb der Middleware. Beispiele befinden sich im Repository.
GRPC
Während der Entwicklung habe ich versucht, bidirektionales GRPC-Streaming als Transportmittel für die Kommunikation zwischen Client und Server zu verwenden (zusätzlich zu Websocket- und HTTP-basierten SockJS-Fallbacks). Was kann ich sagen Er hat gearbeitet. Ich habe jedoch kein einziges Szenario gefunden, in dem bidirektionales GRPC-Streaming besser wäre als Websocket. Ich habe mich hauptsächlich mit Servermetriken befasst: Datenverkehr, der über die Netzwerkschnittstelle generiert wird, CPU-Verbrauch durch den Server mit einer großen Anzahl eingehender Verbindungen, Speicherverbrauch pro Verbindung.
GRPC hat in jeder Hinsicht gegen Websocket verloren:
- GRPC generiert in ähnlichen Szenarien 20% mehr Verkehr.
- GRPC verbraucht 2-3 mal mehr CPU (abhängig von der Konfiguration der Verbindungen - alle haben unterschiedliche Kanäle oder alle einen Kanal abonniert).
- GRPC verbraucht viermal so viel RAM pro Verbindung. Bei 10.000 Verbindungen verbrauchte der Websocket-Server beispielsweise 500 MB Speicher und GRPC-2 GB.
Die Ergebnisse waren ziemlich ... erwartet. Im Allgemeinen sah ich in GRPC als Client-Transport nicht viel Sinn - und löschte den Code mit gutem Gewissen bis vielleicht zu besseren Zeiten.
GRPC ist jedoch gut darin, wofür es hauptsächlich erstellt wurde - Code zu generieren, mit dem Sie RPC-Aufrufe zwischen Diensten mithilfe eines vorgegebenen Schemas tätigen können. Daher bietet die Zentrifuge neben der HTTP-API jetzt auch GRPC-basierte API-Unterstützung, um beispielsweise neue Nachrichten auf dem Kanal und andere verfügbare Server-API-Methoden zu veröffentlichen.
Schwierigkeiten mit Kunden
Durch die in der zweiten Version vorgenommenen Änderungen wurde die obligatorische Unterstützung von Bibliotheken für die Server-API entfernt - die Integration auf der Serverseite wurde einfacher, das Client-Protokoll im Projekt wurde jedoch geändert und verfügt über eine ausreichende Anzahl von Funktionen. Dies macht die Implementierung von Kunden ziemlich schwierig. Für die zweite Version haben wir jetzt einen Client für Javascript , der in Browsern funktioniert und mit NodeJS und React-Native funktionieren sollte. Es gibt einen Client auf Go, der auf seiner Basis und auf der Basis der Gomobile-Projektordner für iOS und Android erstellt wurde .
Für vollkommenes Glück gibt es nicht genügend native Bibliotheken für iOS und Android. Für die erste Version von Centrifugo wurden sie von Leuten aus der Open-Source-Community gekauft. Ich möchte glauben, dass so etwas jetzt passieren wird.
Ich habe kürzlich mein Glück versucht, indem ich einen Antrag auf ein MOSS-Stipendium von Mozilla gesendet habe, um in die Kundenentwicklung zu investieren, wurde aber abgelehnt. Der Grund ist die unzureichend aktive Community auf Github. Leider stimmt das, aber wie Sie sehen, unternehme ich einige Schritte, um die Situation zu verbessern.

Fazit
Ich habe nicht alle Funktionen angekündigt, die in Centrifugo v2 verfügbar sein werden . Weitere Informationen finden Sie in der Ausgabe zu Github . Die Serverfreigabe hat noch nicht stattgefunden, wird aber bald erfolgen. Es gibt noch unvollendete Momente, einschließlich der Notwendigkeit, die Dokumentation zu vervollständigen. Der Prototyp der Dokumentation kann hier eingesehen werden . Wenn Sie ein Centrifugo-Benutzer sind, ist jetzt der richtige Zeitpunkt, um die zweite Version des Servers zu beeinflussen. Eine Zeit, in der es nicht so beängstigend ist, etwas zu zerbrechen, um es später besser zu machen. Für Interessierte: Die Entwicklung konzentriert sich auf den c2-Zweig .
Es fällt mir schwer zu beurteilen, wie stark die Nachfrage nach der Centrifuge-Bibliothek, die Centrifugo v2 zugrunde liegt, gefragt sein wird. Im Moment freue ich mich, dass ich es auf den aktuellen Stand bringen konnte. Der wichtigste Indikator für mich ist jetzt die Antwort auf die Frage "Würde ich diese Bibliothek selbst in meinem persönlichen Projekt verwenden?" Meine Antwort lautet ja. Bei der Arbeit? Ja Daher glaube ich, dass andere Entwickler es zu schätzen wissen.
PS Ich möchte mich bei den Leuten bedanken, die bei der Arbeit und beim Rat geholfen haben - Dmitry Korolkov, Artemy Ryabinkov, Oleg Kuzmin. Ohne dich wäre es eng.