Hallo Kollegen! Wir erinnern Sie daran, dass wir vor nicht allzu langer Zeit ein
Buch über Spark veröffentlicht haben und derzeit ein
Buch über Kafka das neueste Korrekturlesen durchläuft.
Wir hoffen, dass diese Bücher erfolgreich genug sind, um das Thema fortzusetzen - zum Beispiel für die Übersetzung und Veröffentlichung von Literatur zu Spark Streaming. Wir wollten Ihnen heute eine Übersetzung zur Integration dieser Technologie in Kafka anbieten.
1. BegründungApache Kafka + Spark Streaming ist eine der besten Kombinationen zum Erstellen von Echtzeitanwendungen. In diesem Artikel werden wir die Details einer solchen Integration ausführlich diskutieren. Außerdem sehen wir uns ein Beispiel mit Spark Streaming-Kafka an. Anschließend diskutieren wir den „Empfängeransatz“ und die Option der direkten Integration von Kafka und Spark Streaming. Beginnen wir also mit der Integration von Kafka und Spark Streaming.
 2. Integration von Kafka und Spark Streaming
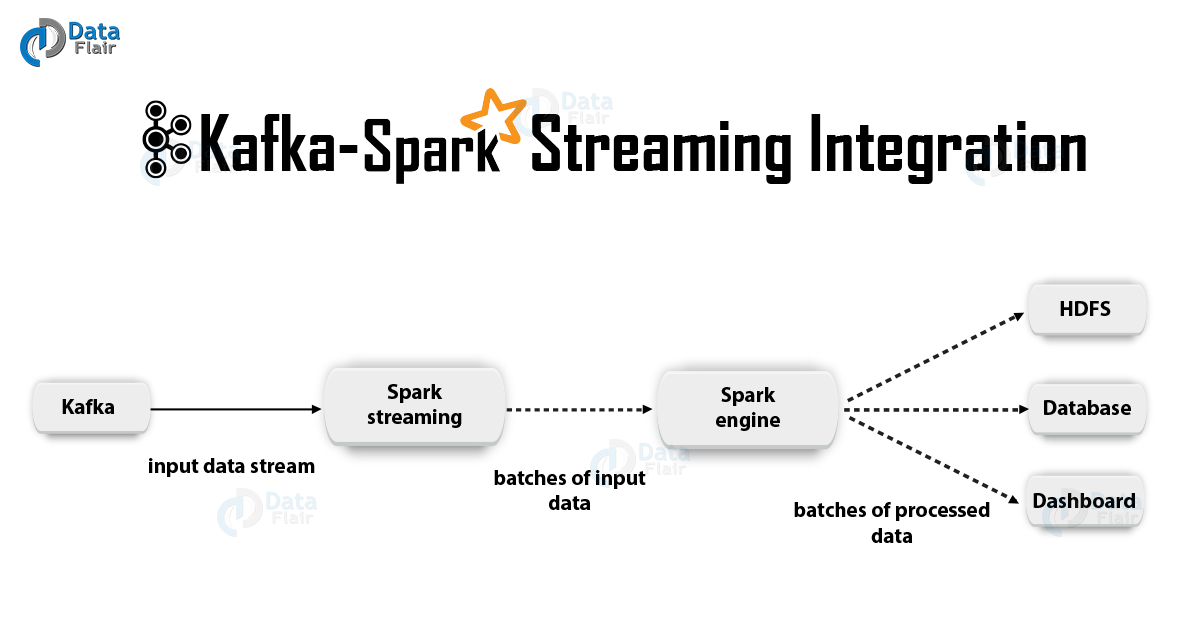
2. Integration von Kafka und Spark StreamingBei der Integration von Apache Kafka und Spark Streaming gibt es zwei mögliche Ansätze zum Konfigurieren von Spark Streaming zum Empfangen von Daten von Kafka - d. H. zwei Ansätze zur Integration von Kafka und Spark Streaming. Erstens können Sie Empfänger und die übergeordnete Kafka-API verwenden. Der zweite (neuere) Ansatz ist die Arbeit ohne Empfänger. Für beide Ansätze gibt es unterschiedliche Programmiermodelle, die sich beispielsweise in Bezug auf Leistung und semantische Garantien unterscheiden.
Lassen Sie uns diese Ansätze genauer betrachten.
a. Empfängerbasierter AnsatzIn diesem Fall wird der Empfang der Daten vom Empfänger bereitgestellt. Mit der von Kafka bereitgestellten High-Level-Verbrauchs-API implementieren wir den Empfänger. Ferner werden die empfangenen Daten in Spark Artists gespeichert. Anschließend werden Jobs in Kafka - Spark Streaming gestartet, in denen Daten verarbeitet werden.
Bei Verwendung dieses Ansatzes bleibt jedoch das Risiko eines Datenverlusts im Fehlerfall (mit der Standardkonfiguration) bestehen. Infolgedessen muss in Kafka - Spark Streaming zusätzlich ein Write-Ahead-Protokoll eingefügt werden, um Datenverluste zu vermeiden. Somit werden alle von Kafka empfangenen Daten synchron im Write-Ahead-Protokoll in einem verteilten Dateisystem gespeichert. Deshalb können auch nach einem Systemausfall alle Daten wiederhergestellt werden.
Als Nächstes sehen wir uns an, wie dieser Ansatz mit Empfängern in einer Anwendung mit Kafka - Spark Streaming verwendet wird.
ich. BindungJetzt verbinden wir unsere Streaming-Anwendung mit dem folgenden Artefakt für Scala / Java-Anwendungen. Wir verwenden die Projektdefinitionen für SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
Bei der Bereitstellung unserer Anwendung müssen wir jedoch die oben genannte Bibliothek und ihre Abhängigkeiten hinzufügen. Dies wird für Python-Anwendungen benötigt.
ii. ProgrammierungErstellen Sie als Nächstes einen
DStream Eingabestream, indem Sie
KafkaUtils in den Stream-Anwendungscode importieren:
import org.apache.spark.streaming.kafka._ val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
Darüber hinaus können Sie mit den Optionen createStream Schlüsselklassen und Werteklassen sowie die entsprechenden Klassen für deren Dekodierung angeben.
iii. BereitstellungWie bei jeder Spark-Anwendung wird der Befehl spark-submit zum Starten verwendet. Die Details unterscheiden sich jedoch geringfügig in Scala / Java-Anwendungen und in Python-Anwendungen.
Darüber hinaus können Sie mit
–packages das
spark-streaming-Kafka-0-8_2.11 und seine Abhängigkeiten direkt zum
spark-submit spark-streaming-Kafka-0-8_2.11 hinzufügen. Dies ist nützlich für Python-Anwendungen, bei denen es unmöglich ist, Projekte mit SBT / Maven zu verwalten.
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
Sie können auch das JAR-Archiv der Maven-Artefakt-
spark-streaming-Kafka-0-8-assembly aus dem Maven-Repository herunterladen. Fügen Sie es dann zu
spark-submit mit -
jars .
b. Direkte Ansprache (keine Empfänger)Nach dem Ansatz unter Verwendung von Empfängern wurde ein neuerer Ansatz entwickelt - der „direkte“. Es bietet zuverlässige End-to-End-Garantien. In diesem Fall fragen wir Kafka regelmäßig nach Offsets von Offsets für jedes Thema / jeden Abschnitt und sorgen nicht für die Datenlieferung durch die Empfänger. Zusätzlich wird die Größe des Lesefragments bestimmt, dies ist für die korrekte Verarbeitung jedes Pakets notwendig. Schließlich wird eine einfache konsumierende API verwendet, um Bereiche mit Daten von Kafka mit den angegebenen Offsets zu lesen, insbesondere wenn Datenverarbeitungsjobs gestartet werden. Der gesamte Vorgang ist wie das Lesen von Dateien aus einem Dateisystem.
Hinweis: Diese Funktion wurde in Spark 1.3 für Scala und die Java-API sowie in Spark 1.4 für die Python-API angezeigt.
Lassen Sie uns nun diskutieren, wie dieser Ansatz in unserer Streaming-Anwendung angewendet wird.
Die Consumer-API wird unter folgendem Link ausführlicher beschrieben:
Apache Kafka Verbraucher | Beispiele für Kafka Consumerich. Bindung
Dieser Ansatz wird zwar nur in Scala / Java-Anwendungen unterstützt. Erstellen Sie mit dem folgenden Artefakt das SBT / Maven-Projekt.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ii. ProgrammierungImportieren Sie als Nächstes KafkaUtils und erstellen Sie einen Eingabe-
DStream im Stream-Anwendungscode:
import org.apache.spark.streaming.kafka._ val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
In den Kafka-Parametern müssen Sie entweder
metadata.broker.list oder
bootstrap.servers angeben. Daher werden standardmäßig Daten ab dem letzten Versatz in jedem Abschnitt von Kafka verwendet. Wenn Sie jedoch möchten, dass der Messwert vom kleinsten Fragment
auto.offset.reset müssen Sie in den Kafka-Parametern die Konfigurationsoption
auto.offset.reset .
KafkaUtils.createDirectStream Sie mit den Optionen
KafkaUtils.createDirectStream , können Sie außerdem von einem beliebigen Versatz aus mit dem Lesen beginnen. Dann werden wir Folgendes tun, um auf die in jedem Paket verbrauchten Kafka-Fragmente zuzugreifen.
Wenn wir die Überwachung von Kafka basierend auf Zookeeper mithilfe spezieller Tools organisieren möchten, können wir Zookeeper mithilfe ihrer Hilfe selbst aktualisieren.
iii. BereitstellungDer Bereitstellungsprozess ähnelt in diesem Fall dem Bereitstellungsprozess in der Variante mit dem Empfänger.
3. Die Vorteile eines direkten AnsatzesDer zweite Ansatz zur Integration von Spark Streaming in Kafka übertrifft den ersten aus folgenden Gründen:
a. Vereinfachte ParallelitätIn diesem Fall müssen Sie nicht viele Kafka-Eingabestreams erstellen und kombinieren. Mit Kafka-Spark-Streaming werden jedoch so viele RDD-Segmente erstellt, wie Kafka-Segmente für den Verbrauch vorhanden sind. Alle diese Kafka-Daten werden parallel gelesen. Daher können wir sagen, dass wir eine Eins-zu-Eins-Entsprechung zwischen den Segmenten Kafka und RDD haben werden, und ein solches Modell ist verständlicher und einfacher zu konfigurieren.
b. WirksamkeitUm Datenverluste während des ersten Ansatzes vollständig zu vermeiden, mussten die Informationen in einem Protokoll führender Datensätze gespeichert und dann repliziert werden. Tatsächlich ist dies ineffizient, da die Daten zweimal repliziert werden: das erste Mal von Kafka selbst und das zweite Mal vom Write-Ahead-Protokoll. Beim zweiten Ansatz wird dieses Problem beseitigt, da kein Empfänger vorhanden ist und daher kein führendes Schreibjournal benötigt wird. Wenn wir einen ausreichend langen Datenspeicher in Kafka haben, können Sie Nachrichten direkt von Kafka wiederherstellen.
s Genau einmalige SemantikGrundsätzlich haben wir beim ersten Ansatz die übergeordnete Kafka-API verwendet, um verbrauchte Lesefragmente in Zookeeper zu speichern. Dies ist jedoch die Gewohnheit, Daten von Kafka zu konsumieren. Während Datenverluste zuverlässig beseitigt werden können, besteht eine geringe Wahrscheinlichkeit, dass bei einigen Fehlern einzelne Datensätze zweimal verwendet werden können. Der springende Punkt ist die Inkonsistenz zwischen dem zuverlässigen Datenübertragungsmechanismus in Kafka - Spark Streaming und dem Fragmentlesen in Zookeeper. Daher verwenden wir im zweiten Ansatz die einfache Kafka-API, für die kein Zugriff auf Zookeeper erforderlich ist. Hier werden die gelesenen Fragmente in Kafka - Spark Streaming verfolgt, dazu werden Kontrollpunkte verwendet. In diesem Fall wird die Inkonsistenz zwischen Spark Streaming und Zookeeper / Kafka beseitigt.
Daher empfängt Spark Streaming auch bei Fehlern jeden Datensatz streng einmal. Hier müssen wir sicherstellen, dass unsere Ausgabeoperation, in der die Daten in einem externen Speicher gespeichert werden, entweder idempotent oder eine atomare Transaktion ist, in der sowohl die Ergebnisse als auch die Offsets gespeichert werden. So wird genau einmalige Semantik bei der Ableitung unserer Ergebnisse erreicht.
Es gibt jedoch einen Nachteil: Offsets in Zookeeper werden nicht aktualisiert. Mit den auf Zookeeper basierenden Überwachungstools von Kafka können Sie daher den Fortschritt nicht verfolgen.
Wenn die Verarbeitung auf diese Weise angeordnet ist, können wir jedoch weiterhin auf Offsets verweisen. Wir wenden uns an jedes Paket und aktualisieren Zookeeper selbst.
Das ist alles, worüber wir über die Integration von Apache Kafka und Spark Streaming sprechen wollten. Wir hoffen es hat euch gefallen.