Dies ist die zweite Vorlesung mit J. Subbotnik über Datenbanken - die
erste, die wir vor einigen Wochen veröffentlicht haben.
Der Leiter der Allzweck-DBMS-Gruppe Dmitry Sarafannikov sprach über die Entwicklung des Data Warehouse in Yandex: Wie wir uns für eine S3-kompatible Schnittstelle entschieden haben, warum wir uns für PostgreSQL entschieden haben, auf welche Art von Rechen wir getreten sind und wie wir damit umgehen sollen.
- Hallo allerseits! Mein Name ist Dima, in Yandex mache ich Datenbanken.
Ich werde Ihnen sagen, wie wir S3 gemacht haben, wie wir genau zu S3 gekommen sind und welche Art von Speicher vorher war. Die erste davon ist Elliptics. Sie wird in Open Source veröffentlicht und ist auf GitHub verfügbar. Viele mögen darauf gestoßen sein.

Dies ist im Wesentlichen eine verteilte Hash-Tabelle mit einem 512-Bit-Schlüssel, das Ergebnis von SHA-512. Es bildet einen Schlüsselring, der zufällig zwischen Maschinen aufgeteilt wird. Wenn Sie dort Maschinen hinzufügen möchten, werden die Schlüssel neu verteilt, und es erfolgt ein Neuausgleich. Dieses Repository hat seine eigenen Probleme, insbesondere im Zusammenhang mit der Neuausrichtung. Wenn Sie eine ausreichend große Anzahl von Schlüsseln haben, müssen Sie bei ständig wachsenden Volumina ständig Autos dort abladen, und bei einer sehr großen Anzahl von Schlüsseln kann es sein, dass die Neuausrichtung einfach nicht konvergiert. Das war ein ausreichend großes Problem.
Gleichzeitig eignet sich dieser Speicher hervorragend für mehr oder weniger statische Daten, wenn Sie eine große Menge einmaliger Daten hochladen und diese dann schreibgeschützt laden. Für solche Entscheidungen passt es perfekt.
Wir gehen weiter. Die Probleme beim Neuausgleich waren ziemlich ernst, so dass der nächste Speicher erschien.

Was ist seine Essenz? Dies ist kein Schlüsselwertspeicher, sondern ein Wertspeicher. Wenn Sie dort ein Objekt oder eine Datei hochladen, erhalten Sie einen Schlüssel, mit dem Sie diese Datei abrufen können. Was gibt es? Theoretisch hundertprozentiger Schreibzugriff, wenn Sie freien Speicherplatz im Speicher haben. Wenn Sie eine Schreibmaschine haben, schreiben Sie einfach an andere, die nicht liegen und auf denen freier Speicherplatz vorhanden ist. Sie erhalten andere Schlüssel und nehmen Ihre Daten ruhig auf.
Dieser Speicher ist sehr einfach zu skalieren, Sie können ihn mit Eisen werfen, es wird funktionieren. Es ist sehr einfach und zuverlässig. Der einzige Nachteil: Der Client verwaltet den Schlüssel nicht, und alle Clients müssen die Schlüssel irgendwo speichern und die Zuordnung ihrer Schlüssel speichern. Dies ist für alle unpraktisch. Tatsächlich ist dies eine sehr ähnliche Aufgabe für alle Kunden, und jeder löst sie auf seine eigene Weise in seinen Metabasen usw. Dies ist unpraktisch. Gleichzeitig möchte ich jedoch nicht die Zuverlässigkeit und Einfachheit dieses Speichers verlieren, sondern arbeitet mit Netzwerkgeschwindigkeit.
Dann haben wir uns S3 angesehen. Dies ist ein Schlüsselwertspeicher, der Client verwaltet den Schlüssel, der gesamte Speicher ist in sogenannte Buckets unterteilt. In jedem Bucket ist der Schlüsselraum von minus unendlich bis plus unendlich. Der Schlüssel ist eine Art Textzeichenfolge. Und wir haben uns für diese Option entschieden. Warum S3?
Alles ist ganz einfach. Zu diesem Zeitpunkt wurden bereits viele vorgefertigte Clients für verschiedene Programmiersprachen geschrieben, und viele vorgefertigte Tools zum Speichern von Daten in S3, z. B. Datenbanksicherungen, wurden bereits geschrieben. Andrew
sprach über eines der Beispiele. Es gibt bereits eine einigermaßen durchdachte API, die seit Jahren im Einsatz ist, und Sie müssen dort nichts erfinden. Die API verfügt über viele praktische Funktionen wie Listings, mehrteilige Uploads usw. Deshalb haben wir uns entschlossen, dran zu bleiben.
Wie mache ich S3 aus unserem Speicher? Was fällt dir ein? Da Clients selbst die Zuordnung von Schlüsseln speichern, nehmen wir einfach die Datenbank neben sie und speichern die Zuordnung dieser Schlüssel darin. Beim Lesen finden wir nur die Schlüssel und den Speicher in unserer Datenbank und geben dem Kunden, was er will. Wenn Sie dies schematisch skizzieren, wie erfolgt die Füllung?

Es gibt eine bestimmte Entität, hier heißt sie Proxy, das sogenannte Backend. Er akzeptiert die Datei, lädt sie in den Speicher hoch, holt den Schlüssel von dort und speichert ihn in der Datenbank. Alles ist ganz einfach.
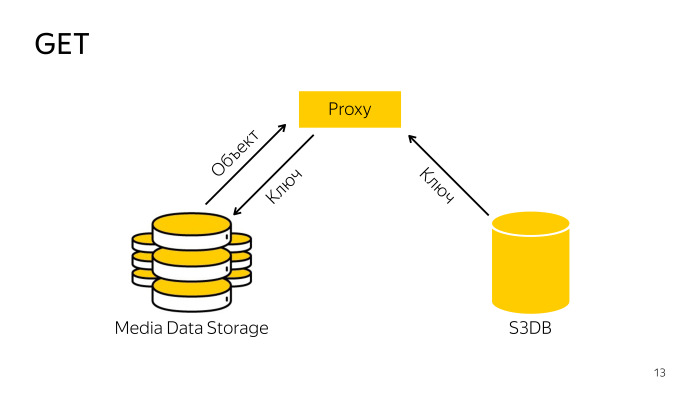
Wie ist die Quittung? Der Proxy findet den erforderlichen Schlüssel in der Datenbank, geht mit dem Schlüssel zum Speicher, lädt das Objekt von dort herunter und gibt es an den Client weiter. Alles ist auch einfach.
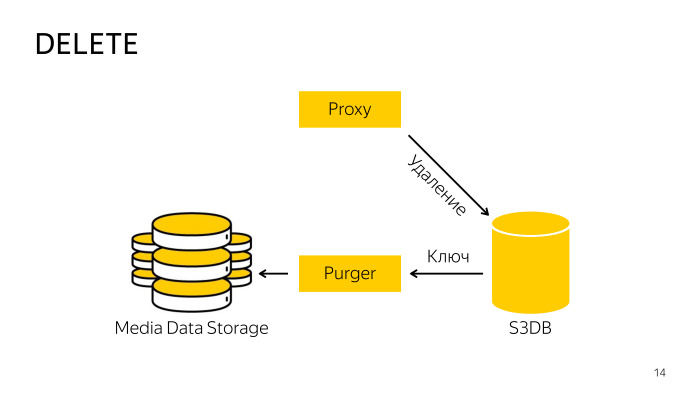
Wie ist die Entfernung? Beim Löschen direkt aus dem Speicher funktioniert der Proxy nicht, da es schwierig ist, die Datenbank und den Speicher zu koordinieren. Er geht einfach zur Datenbank und teilt ihr mit, dass dieses Objekt gelöscht wird. Dort wird das Objekt in die Löschwarteschlange verschoben und im Hintergrund ein speziell ausgebildeter Fachmann Der Roboter nimmt diese Schlüssel, löscht sie aus dem Speicher und aus der Datenbank. Alles hier ist auch ganz einfach.
Wir haben PostgreSQL als Datenbank für diese Metabasis ausgewählt.
Sie wissen bereits, dass wir ihn sehr lieben. Mit der Übertragung von Yandex.Mail haben wir ausreichend Erfahrung mit PostgreSQL gesammelt, und als verschiedene Mail-Dienste umgezogen sind, haben wir mehrere sogenannte Sharding-Muster entwickelt. Einer von ihnen fiel mit geringfügigen Modifikationen gut auf den S3, aber dort lief es gut.
Was sind die Sharding-Optionen? Dies ist ein großes Repository. Auf einer Yandex-weiten Skala müssen Sie sofort denken, dass es viele Objekte geben wird. Sie müssen sofort darüber nachdenken, wie Sie alles sharden können. Sie können im Namen des Objekts durch Hash sharden. Dies ist der zuverlässigste Weg, aber dies funktioniert hier nicht, da S3 beispielsweise Listen enthält, in denen die Liste der Schlüssel in sortierter Reihenfolge angezeigt werden soll. Wenn Sie zwischenspeichern, werden alle Sortierungen entfernt, die Sie entfernen müssen alle Objekte, damit die Ausgabe der API-Spezifikation entspricht.
Bei der nächsten Option können Sie im Namen oder in der ID des Buckets nach Hash sharden. Ein Bucket kann in einem Datenbank-Shard leben.
Eine weitere Option ist das Sharding über Schlüsselbereiche hinweg. Innerhalb des Eimers gibt es Platz von minus unendlich bis plus unendlich, wir können ihn in eine beliebige Anzahl von Bereichen unterteilen, wir nennen diesen Bereich einen Block, er kann nur in einer Scherbe leben.

Wir haben uns für die dritte Option entschieden, die durch Brocken zersplittert wird, da sich theoretisch unendlich viele Objekte in einem Eimer befinden können und diese dumm nicht in ein Stück Eisen passen. Es wird große Probleme geben, also werden wir nach Belieben in Scherben schneiden und anordnen. Das ist alles.

Was ist passiert? Die gesamte Datenbank besteht aus drei Komponenten. S3 Proxy - eine Gruppe von Hosts, es gibt auch eine Datenbank. PL / Proxy befinden sich unter dem Balancer, Anfragen von diesem Backend fliegen dorthin. Weiter S3Meta, eine solche Gruppe von Bässen, die Informationen über Eimer und Brocken speichert. Und S3DB, Shards, in denen Objekte gespeichert sind, eine Löschwarteschlange. Wenn es schematisch dargestellt ist, sieht es so aus.
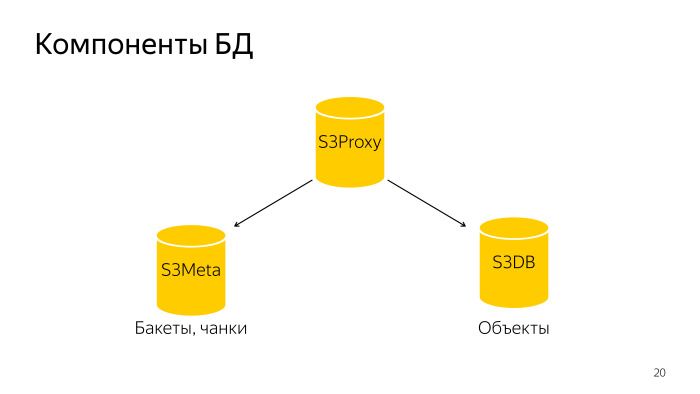
Eine Anfrage geht an S3Proxy, geht an S3Meta und S3DB und gibt Informationen nach oben aus.

Lassen Sie uns genauer betrachten. S3Proxy, Funktionen darin werden in der prozeduralen Sprache PLProxy erstellt. Diese Sprache ermöglicht es Ihnen, remote gespeicherte Prozeduren oder Anforderungen auszuführen. So sieht der Code der ObjectInfo-Funktion im Wesentlichen wie eine Get-Anforderung aus.
Der LProxy-Cluster verfügt über den Cluster-Operator, in diesem Fall db_ro. Was bedeutet das?

Bei einer typischen Datenbank-Shard-Konfiguration gibt es einen Master und zwei Replikate. Der Master betritt den db_rw-Cluster, alle drei Hosts geben db-ro ein. Hier können Sie eine schreibgeschützte Anforderung senden, und eine Schreibanforderung wird an db_rw gesendet. Der db_rw-Cluster enthält alle Master aller Shards.
Bei der nächsten RUN ON-Anweisung wird entweder der Wert all verwendet, was bedeutet, dass auf allen Shards entweder ein Array oder eine Art Shard ausgeführt wird. In diesem Fall erhält es das Ergebnis der Funktion get_object_shard als Eingabe. Dies ist die Nummer des Shards, auf dem das angegebene Objekt liegt.
Und Ziel - welche Funktion soll auf dem Remote-Shard aufgerufen werden? Er wird diese Funktion aufrufen und die Argumente ersetzen, die in diese Funktion eingeflogen sind.

Die Funktion get_object_shard ist ebenfalls in PLProxy geschrieben, bereits ein Meta_ro-Cluster. Die Anforderung wird an den S3Meta-Shard gesendet, der diese Funktion get_bucket_meta_shard zurückgibt.
S3Meta kann auch gesplittert werden, wir haben es auch gelegt, obwohl dies irrelevant ist, aber es gibt eine Möglichkeit. Und es wird die Funktion get_object_shard auf S3Meta aufrufen.

get_bucket_meta_shard ist nur ein Text-Hash im Namen eines Buckets. Wir haben S3Meta nur durch einen Hash im Namen eines Buckets gemischt.

Betrachten Sie S3Meta, was darin passiert. Die wichtigste Information, die es gibt, ist eine Tabelle mit Blöcken. Ich habe einige unnötige Informationen ein wenig herausgeschnitten. Das Wichtigste, was noch übrig ist, ist Bucket_id, der Startschlüssel, der Endschlüssel und der Shard, in dem dieser Block liegt.

Wie würde eine Abfrage in einer solchen Tabelle aussehen, die uns den Block zurückgibt, in dem beispielsweise das Testobjekt liegt? So. Minus unendlich in Textform, wir haben es als Nullwert dargestellt, es gibt so subtile Punkte, dass Sie start_key und end_key auf Null prüfen müssen.

Die Anfrage sieht nicht sehr gut aus und der Plan sieht noch schlechter aus. Als eine der Optionen für einen Plan für eine solche Anforderung bietet BitmapOr. Und 6.000 Knochen, die einen solchen Plan wert sind.

Wie kann es anders sein? In PostgreSQL gibt es so etwas Wunderbares wie den Hauptindex, der den Bereichstyp indizieren kann. Der Bereich ist im Wesentlichen das, was wir brauchen. Wir haben diesen Typ erstellt, die Funktion s3.to_keyrange gibt uns tatsächlich den Bereich zurück. Wir können mit dem Operator "enthält" nach dem Block suchen, in dem sich unser Schlüssel befindet. Und dafür wird hier eine Ausschlussbeschränkung erstellt, die sicherstellt, dass diese Blöcke nicht geschnitten werden. Wir müssen vorzugsweise auf Datenbankebene einige Einschränkungen zulassen, um sicherzustellen, dass sich die Chunks nicht überschneiden können, sodass nur eine Zeile als Antwort auf die Anforderung zurückgegeben wird. Sonst wird es nicht das sein, was wir wollten. So sieht der Plan für eine solche Anfrage aus, der übliche index_scan. Diese Bedingung passt vollständig in die Indexbedingung, und ein solcher Plan hat nur 700 Knochen, zehnmal weniger.

Was ist die Ausschlussbeschränkung?

Erstellen wir eine Testtabelle mit zwei Spalten und fügen zwei Einschränkungen hinzu, eine eindeutige, die jeder kennt, und eine Ausschlussbedingung, deren Parameter gleich sind, solche Operatoren. Stellen wir es mit zwei Operatoren gleich ein, eine solche Platte wurde gebaut.

Dann versuchen wir zwei identische Zeilen einzufügen, wir bekommen den Fehler der Verletzung der Eindeutigkeit des Schlüssels bei der ersten Einschränkung. Wenn wir es fallen lassen, haben wir bereits die Ausschlussbeschränkung verletzt. Dies ist ein häufiger Fall einer eindeutigen Einschränkung.

Tatsächlich ist eine eindeutige Einschränkung dieselbe Ausschlussbedingung, wobei die Operatoren gleich sind. Im Fall einer Ausschlussbedingung können Sie jedoch einige allgemeinere Fälle erstellen.

Wir haben solche Indizes. Wenn Sie genau hinschauen, werden Sie feststellen, dass es sich bei beiden um den Hauptindex handelt, und im Allgemeinen sind sie gleich. Sie fragen sich wahrscheinlich, warum Sie dieses Geschäft überhaupt duplizieren. Ich werde es dir sagen.

Indizes sind so etwas, insbesondere der Hauptindex, dass die Tabelle ihr eigenes Leben führt, Aktualisierungen auftreten, geteilt werden usw. Der Index wird dort schlecht, er ist nicht mehr optimal. Und es gibt eine solche Praxis, insbesondere die Erweiterung pg repack. Indizes werden von Zeit zu Zeit regelmäßig neu erstellt.
Wie erstelle ich einen Index unter einer eindeutigen Einschränkung neu? Erstellen Sie derzeit einen Index erstellen, erstellen Sie denselben Index ruhig daneben, ohne ihn zu sperren, und dann ist der Ausdruck alter table aus der Einschränkung user_index so und so. Und alles, alles ist klar und gut hier, es funktioniert.
Im Falle einer Ausschlussbeschränkung können Sie sie nur durch Neuindex-Sperren neu erstellen. Genauer gesagt, Ihr Index wird ausschließlich blockiert, und tatsächlich bleiben alle Abfragen übrig. Dies ist nicht akzeptabel. Der Hauptindex kann lange genug erstellt werden. Daher behalten wir neben dem zweiten Index, dessen Volumen kleiner ist, weniger Platz ein, der Segelflugzeug verwendet ihn und wir können diesen Index wettbewerbsfähig neu erstellen, ohne ihn zu blockieren.
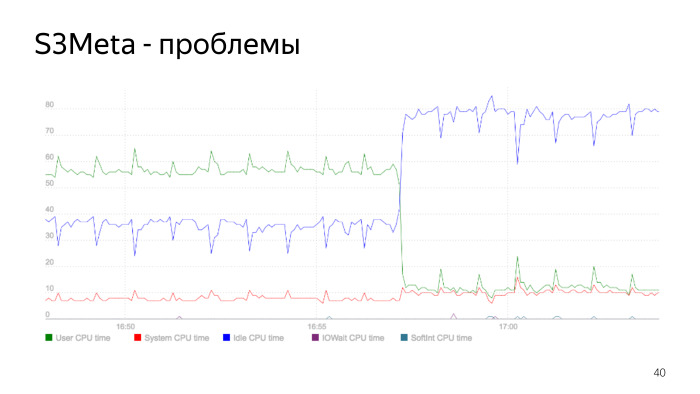
Hier ist ein Diagramm des Prozessorverbrauchs. Die grüne Linie gibt den Prozessorverbrauch in user_space an und springt von 50% auf 60%. Zu diesem Zeitpunkt sinkt der Verbrauch stark. Dies ist der Moment, in dem der Index neu aufgebaut wird. Wir haben den Index neu erstellt, den alten gelöscht, unser Prozessorverbrauch ist stark gesunken. Dies ist ein wesentliches Indexproblem, und dies ist ein gutes Beispiel dafür, wie dies sein kann.
Als wir das alles gemacht haben, haben wir mit Version 9.5 S3DB begonnen. Gemäß dem Plan planten wir, 10 Milliarden Objekte in jedem Shard zu stapeln. Wie Sie wissen, beginnen mehr als 1 Milliarde und noch frühere Probleme, wenn eine Tabelle viele Zeilen enthält. Alles wird viel schlimmer. Es gibt eine Praxis des Abschieds. Zu dieser Zeit gab es zwei Optionen, entweder Standard durch Vererbung, aber dies funktioniert nicht sehr gut, da es eine lineare Partitionsauswahlgeschwindigkeit gibt. Und nach der Anzahl der Objekte zu urteilen, brauchen wir viele Partitionen. Die Jungs von Postgres Pro haben dann aktiv die Erweiterung pg_pathman gesägt.

Wir haben uns für pg_pathman entschieden, wir hatten keine andere Wahl. Sogar Version 1.4. Und wie Sie sehen können, verwenden wir 256 Partitionen. Wir haben die gesamte Objekttabelle in 256 Partitionen aufgeteilt.
Was macht pg_pathman? Mit diesem Ausdruck können Sie 256 Partitionen erstellen, die durch Hash aus der Gebotsspalte partitioniert sind.

Wie funktioniert pg_pathman?
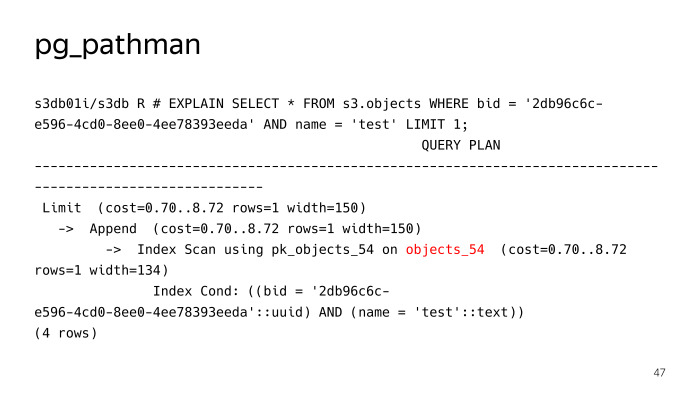
Es registriert seine Haken im Segelflugzeug und ersetzt auf Anfrage im Wesentlichen den Plan. Wir sehen, dass er nicht 256 Partitionen nach einer regulären Suchabfrage für ein Objekt mit dem Namenstest durchsucht hat, sondern sofort festgestellt hat, dass es notwendig ist, in die Tabelle properties_54 zu klettern, aber hier lief nicht alles reibungslos, pg_pathman hat seine eigenen Probleme. Erstens gab es am Anfang einige Fehler, während er sägte, aber dank der Jungs von Postgres Pro haben sie sie schnell behoben und behoben.
Das erste Problem ist die Schwierigkeit, es zu aktualisieren. Das zweite Problem sind vorbereitete Aussagen.
Lassen Sie uns genauer betrachten. Insbesondere das Update. Woraus besteht pg_pathman?

Es besteht im Wesentlichen aus C-Code, der in eine Bibliothek gepackt wird. Und es besteht aus einem SQL-Teil, allen Arten von Funktionen zum Erstellen von Partitionen und so weiter. Außerdem Schnittstellen zu den Funktionen in der Bibliothek. Diese beiden Teile können nicht gleichzeitig aktualisiert werden.
Hier ergeben sich Schwierigkeiten, so etwas wie dieser Algorithmus zum Aktualisieren der Version von pg_pathman. Wir rollen zuerst ein neues Paket mit einer neuen Version, aber PostgreSQL hat alte Versionen im Speicher geladen, es verwendet es. Dies ist in jedem Fall sofort, die Basis muss neu gestartet werden.
Als nächstes rufen wir die Funktion set_enable_parent auf. Sie aktiviert die Funktion in der übergeordneten Tabelle, die standardmäßig deaktiviert ist. Schalten Sie anschließend pathman aus, starten Sie die Datenbank neu, z. B. ALTER EXTENSION UPDATE. Zu diesem Zeitpunkt fällt alles in die übergeordnete Tabelle.
Aktivieren Sie als Nächstes pathman und führen Sie die Funktion in der Erweiterung aus, die Objekte aus der übergeordneten Tabelle überträgt, die sie in dieser kurzen Zeit angegriffen haben, und sie zurück in die Tabellen überträgt, in denen sie liegen sollten. Deaktivieren Sie dann die Verwendung der übergeordneten Tabelle und suchen Sie darin.

Das nächste Problem sind vorbereitete Aussagen.

Wenn wir dieselbe normale Anforderung blockieren, suchen Sie nach Gebot und Schlüssel und versuchen Sie, sie auszuführen. Führen Sie fünf Mal durch - alles ist gut. Wir führen den sechsten durch - wir sehen einen solchen Plan. Und in dieser Hinsicht sehen wir alle 256 Partitionen. Wenn Sie sich diese Bedingungen genau ansehen, sehen wir Dollar 1, Dollar 2, dies ist der sogenannte generische Plan, der allgemeine Plan. Die ersten fünf Abfragen wurden einzeln erstellt, individuelle Pläne wurden für diese Parameter verwendet, pg_pathman konnte sofort bestimmen, da der Parameter im Voraus bekannt ist, und es konnte sofort die Tabelle bestimmen, wohin sie gehen soll. In diesem Fall kann er dies nicht tun. Dementsprechend sollte der Plan alle 256 Partitionen enthalten, und wenn der Executor dies tut, nimmt er eine gemeinsame Sperre für alle 256 Partitionen, und die Leistung einer solchen Lösung ist nicht sofort. Es verliert einfach alle seine Vorteile und jede Anfrage wird wahnsinnig lange ausgeführt.

Wie sind wir aus dieser Situation herausgekommen? Ich musste alles in die gespeicherten Prozeduren in execute in dynamischem SQL einbinden, damit vorbereitete Anweisungen nicht verwendet wurden und der Plan jedes Mal erstellt wurde. So funktioniert es.
Der Nachteil ist, dass Sie den gesamten Code in Strukturen packen müssen, die diese Tabellen berühren. Dies ist hier schwerer zu lesen.

Wie ist die Verteilung von Objekten? In jedem S3DB-Shard werden Blockzähler gespeichert, es gibt auch Informationen darüber, welche Blöcke sich in diesem Shard befinden, und Zähler werden für sie gespeichert. Für jede Mutationsoperation an einem Objekt - Hinzufügen, Löschen, Ändern, Umschreiben - werden diese Zähler für die Blockänderung verwendet. Um nicht dieselbe Zeile zu aktualisieren, wenn sich in diesem Block aktives Gießen befindet, verwenden wir eine ziemlich Standardtechnik, wenn wir einen Delta-Zähler in eine separate Tabelle einfügen. Einmal pro Minute durchläuft ein spezieller Roboter all dies und aggregiert die Zähler am Block .

Außerdem werden diese Zähler mit einiger Verzögerung an S3Meta geliefert. Es gibt bereits ein vollständiges Bild davon, wie viele Zähler sich in welchem Block befinden. Dann können Sie die Verteilung nach Shards betrachten, wie viele Objekte sich in welchem Shard befinden. Auf dieser Grundlage wird eine Entscheidung getroffen, wo der neue Chunk fällt. Wenn Sie einen Bucket erstellen, wird standardmäßig ein einzelner Block von minus unendlich bis plus unendlich erstellt. Abhängig von der aktuellen Verteilung der Objekte, die S3Meta kennt, fällt er in eine Art Shard.
Wenn Sie Daten in diesen Bucket gießen, werden alle diese Daten in diesen Block gegossen. Wenn eine bestimmte Größe erreicht ist, kommt ein spezieller Roboter und teilt diesen Block.

Wir machen diese Stücke klein. Wir tun dies, damit dieser kleine Teil in einen anderen Splitter gezogen werden kann. Wie kommt es zu einem Chunk Split? Hier ist ein normaler Roboter, der diesen Block in S3DB mit einem zweiphasigen Commit aufteilt und die Informationen in S3Meta aktualisiert.
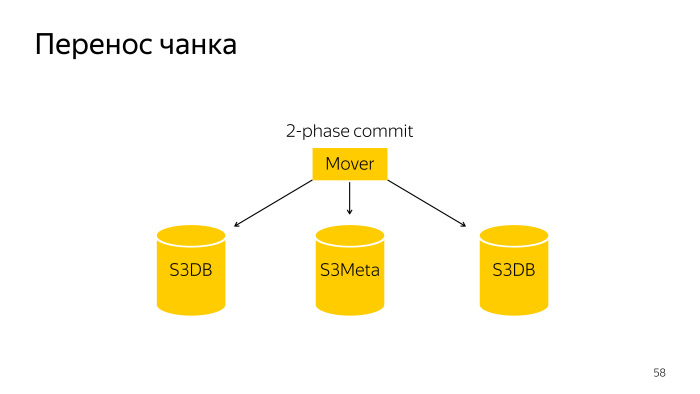
Die Chunk-Übertragung ist eine etwas kompliziertere Operation, da es sich um eine zweiphasige Festschreibung über drei Basen, S3Meta, und zwei Shards, S3DB, handelt, die von einer in eine andere gezogen werden.

S3 hat eine Funktion wie Listings, dies ist die schwierigste Sache, und es gab auch Probleme damit. In der Tat, Auflistungen, sagen Sie S3 - zeigen Sie mir die Objekte, die ich habe. Der rot hervorgehobene Parameter ist jetzt Null. Mit diesem Parameter, Delimeter, Trennzeichen können Sie die Auflistungen angeben, mit welchem Trennzeichen Sie möchten.
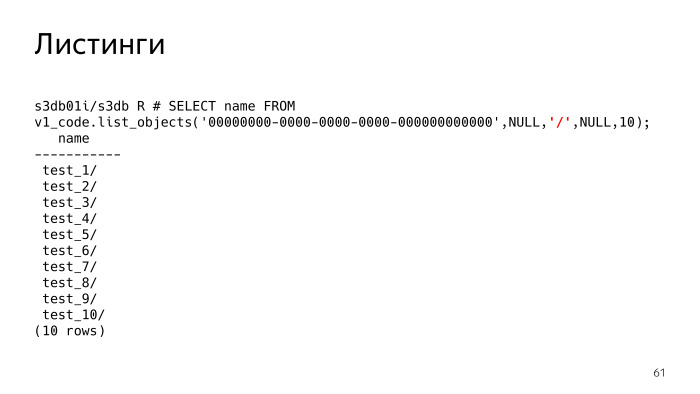
Was bedeutet das? Wenn der Begrenzer nicht festgelegt ist, erhalten wir lediglich eine Liste der Dateien. Wenn wir den Begrenzer festlegen, sollte S3 uns im Wesentlichen die Ordner anzeigen. Ich muss verstehen, dass es solche Ordner gibt, und tatsächlich werden alle Ordner und Dateien im aktuellen Ordner angezeigt. Dem aktuellen Ordner wird ein Präfix vorangestellt, dieser Parameter ist Null. Wir sehen, dass es 10 Ordner gibt.
Alle Schlüssel werden nicht wie im Dateisystem in einer hierarchischen Baumstruktur gespeichert. Jedes Objekt wird als Zeichenfolge gespeichert und hat ein einfaches gemeinsames Präfix. S3 muss selbst verstehen, dass dies ein Arsch ist.

Eine solche Logik ist für deklaratives SQL nicht gut genug, und es ist einfach genug, sie mit imperativem Code zu beschreiben. , PL/pgSQL. , repeatable read. , . , - - , .
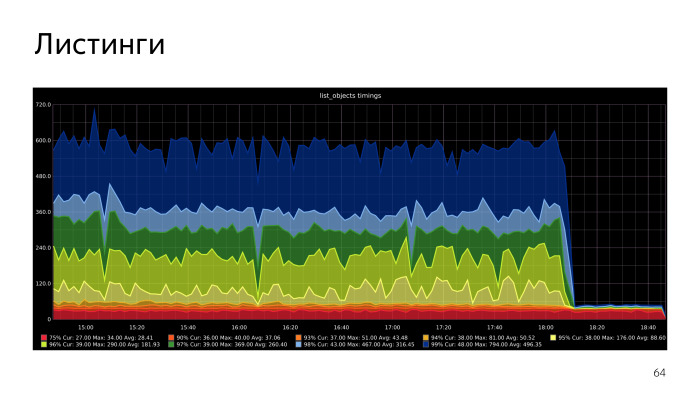
Recursive CTE, , - , execute PL/pgSQL. , . , , , list objects. , .
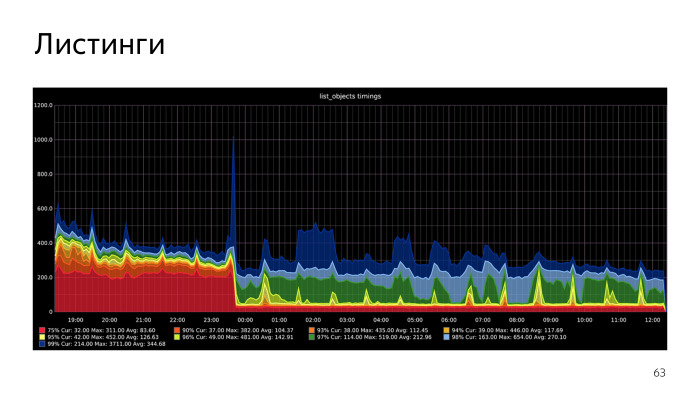
, .
. , .
Docker,
Behave Behave
. , , , .
. , , CPU S3Meta. Gist index CPU, , . CPU S3Meta . , . PLProxy , S3Meta S3DB. , . S3Meta . , .
, , . — , range btree. , btree . , , btree. , . PL/pgSQL-. , .