Als Dropbox gerade gestartet wurde, kommentierte ein Benutzer von Hacker News, dass es mit mehreren Bash-Skripten unter Verwendung von FTP und Git implementiert werden könnte. Dies kann in keiner Weise gesagt werden. Dies ist ein großer Cloud-Dateispeicher mit Milliarden neuer Dateien pro Tag, die nicht nur irgendwie in der Datenbank gespeichert werden, sondern auch so, dass jede Datenbank innerhalb der letzten sechs Tage zu einem beliebigen Zeitpunkt wiederhergestellt werden kann.
Unter dem Schnitt das Transkript des Berichts von
Glory Bakhmutov (
m0sth8 ) auf Highload ++ 2017 darüber, wie sich die Datenbanken in Dropbox entwickelt haben und wie sie jetzt angeordnet sind.
Über den Redner: Ehre sei Bakhmutov - Site Reliability Engineer im Dropbox-Team, liebt Go sehr und erscheint manchmal im Podcast von golangshow.com.
Inhalt
Dropbox-Architektur im Klartext
Dropbox erschien im Jahr 2008. Dies ist im Wesentlichen ein Cloud-Dateispeicher. Als Dropbox gerade gestartet wurde, sagte ein Benutzer von Hacker News, dass es mit mehreren Bash-Skripten unter Verwendung von FTP und Git implementiert werden könnte. Trotzdem entwickelt sich Dropbox weiter und ist jetzt ein ziemlich großer Dienst mit mehr als 1,5 Milliarden Benutzern, 200.000 Unternehmen und einer großen Anzahl (mehrere Milliarden!) Täglich neuer Dateien.
Wie sieht Dropbox aus?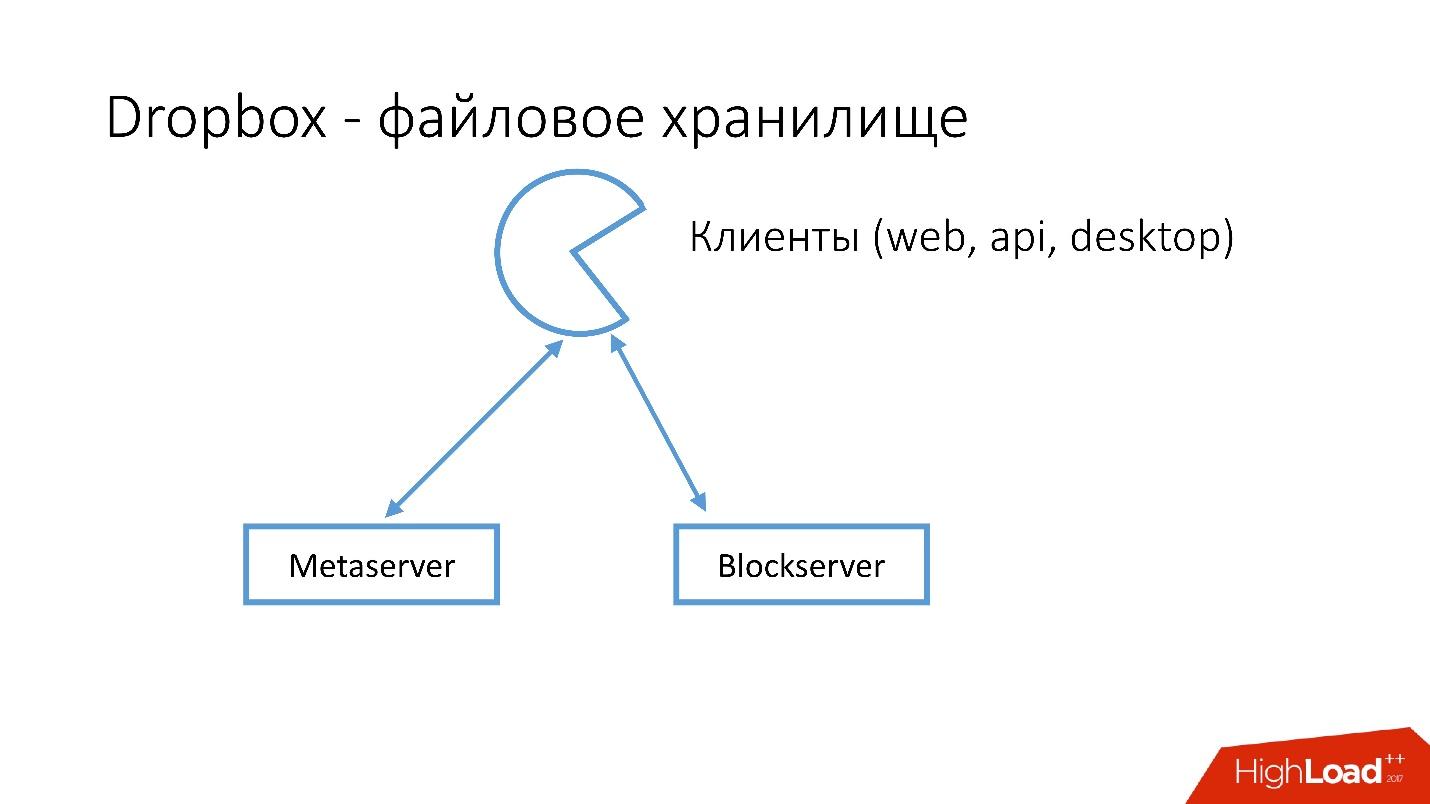
Wir haben mehrere Clients (Webschnittstelle, API für Anwendungen, die Dropbox verwenden, Desktopanwendungen). Alle diese Clients verwenden die API und kommunizieren mit zwei großen Diensten, die logisch unterteilt werden können in:
- Metaserver
- Blockserver
Metaserver speichert Metainformationen über die Datei: Größe, Kommentare dazu, Links zu dieser Datei in Dropbox usw. Blockserver speichert nur Informationen zu Dateien: Ordner, Pfade usw.
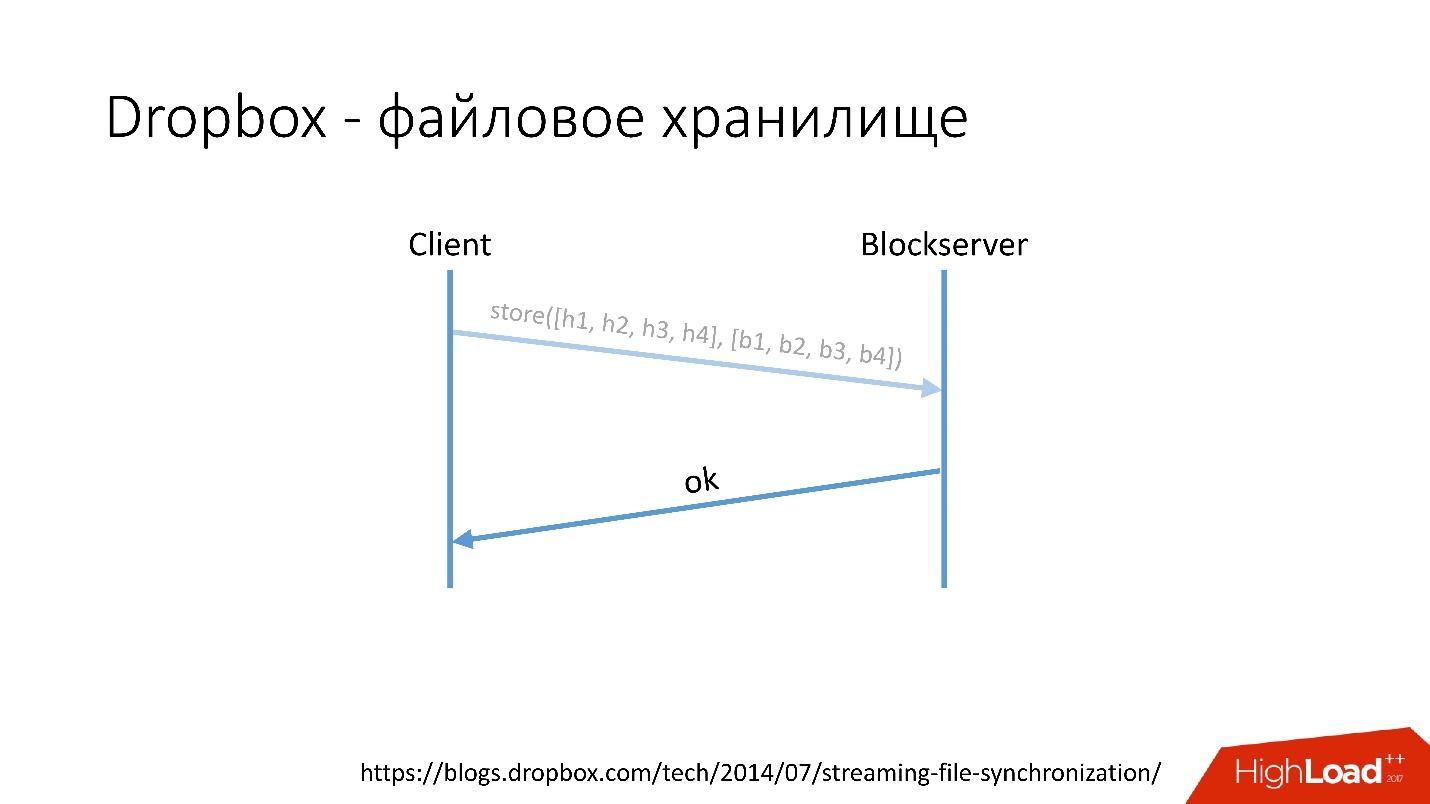
Wie funktioniert esZum Beispiel haben Sie eine video.avi-Datei mit einer Art Video.
 Link von der Folie
Link von der Folie- Der Client teilt diese Datei in mehrere Blöcke auf (in diesem Fall jeweils 4 MB), berechnet die Prüfsumme und sendet eine Anfrage an Metaserver: "Ich habe eine * .avi-Datei, ich möchte sie hochladen, die Hash-Beträge sind so und so."
- Metaserver gibt die Antwort zurück: "Ich habe diese Blöcke nicht, lasst uns herunterladen!" Oder er kann antworten, dass er alle oder einige der Blöcke hat und nur die verbleibenden geladen werden müssen.
 Link von der Folie
Link von der Folie- Danach geht der Client zu Blockserver, sendet die Hash-Menge und den Datenblock selbst, der auf dem Blockserver gespeichert ist.
- Blockserver bestätigt den Vorgang.
 Link von der Folie
Link von der FolieDies ist natürlich ein sehr vereinfachtes Schema, das Protokoll ist viel komplizierter: Es gibt eine Synchronisation zwischen Clients innerhalb desselben Netzwerks, es gibt Kerneltreiber, die Fähigkeit, Kollisionen aufzulösen usw. Dies ist ein ziemlich komplexes Protokoll, aber es funktioniert schematisch so.

Wenn ein Client etwas auf Metaserver speichert, gehen alle Informationen an MySQL. Blockserver speichert auch Informationen über Dateien, wie sie strukturiert sind, aus welchen Blöcken sie bestehen, in MySQL. Blockserver speichert die Blöcke auch selbst im Blockspeicher, der wiederum Informationen darüber speichert, wo welcher Block liegt, auf welchem Server und wie er verarbeitet wird, auch in MYSQL.
Um Exabyte an Benutzerdateien zu speichern, speichern wir gleichzeitig zusätzliche Informationen in einer Datenbank mit mehreren Dutzend Petabyte, die auf 6.000 Server verteilt sind.
Datenbankentwicklungsverlauf
Wie haben sich die Datenbanken in Dropbox entwickelt?

Im Jahr 2008 begann alles mit einem Metaserver und einer globalen Datenbank. Alle Informationen, die Dropbox irgendwo speichern musste, speicherte er in der einzigen globalen MySQL. Dies dauerte nicht lange, da die Anzahl der Benutzer zunahm und einzelne Datenbanken und Tablets in den Datenbanken schneller anstiegen als andere.

Daher wurden 2011 mehrere Tabellen an separate Server gesendet:
- Benutzer mit Informationen zu Benutzern, z. B. Anmeldungen und oAuth-Token;
- Host mit Dateiinformationen von Blockserver;
- Verschiedenes , das nicht an der Verarbeitung von Anforderungen aus der Produktion beteiligt war, sondern für Dienstprogrammfunktionen wie Stapeljobs verwendet wurde.
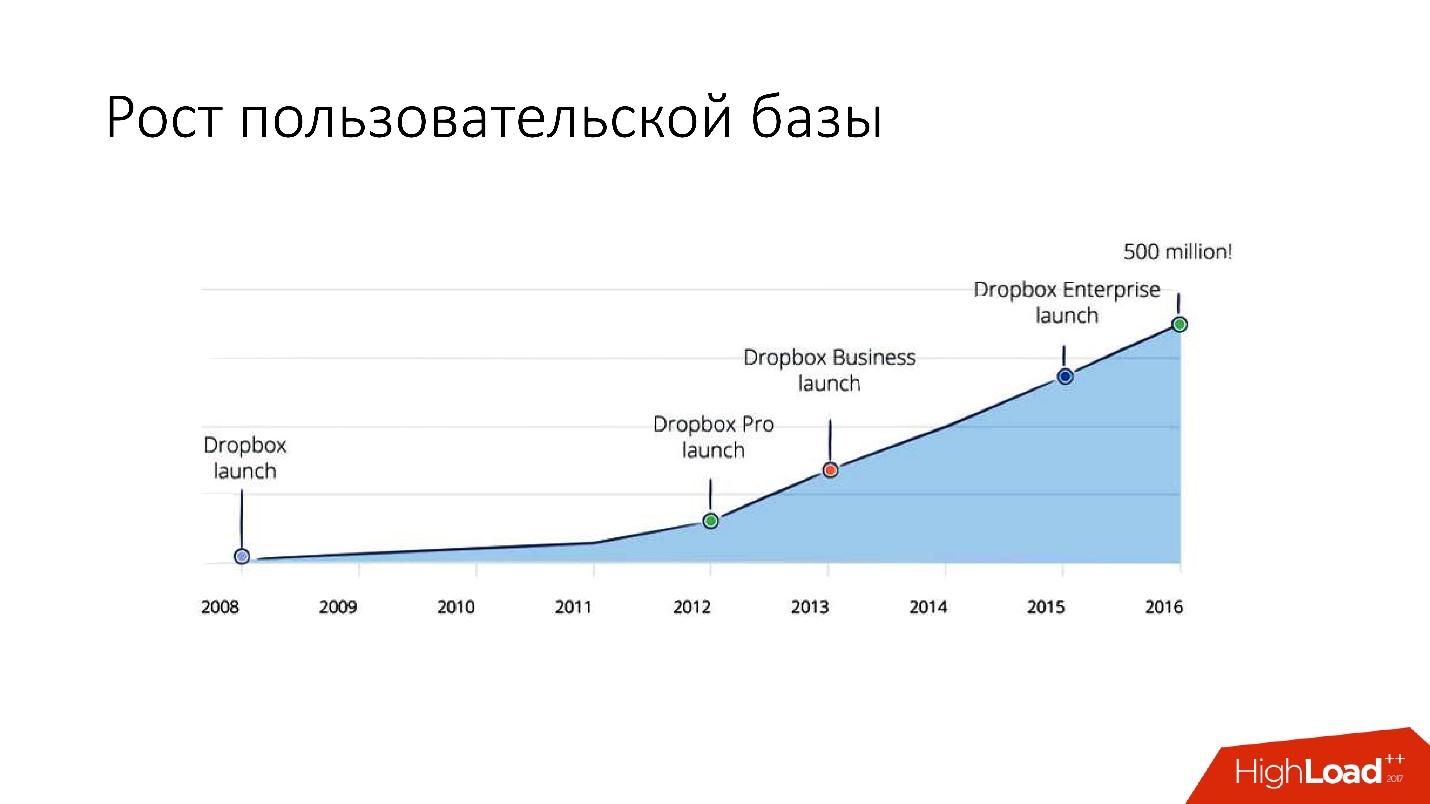
Aber nach 2012 begann Dropbox sehr stark zu wachsen, seitdem sind
wir um
etwa 100 Millionen Benutzer pro Jahr gewachsen.
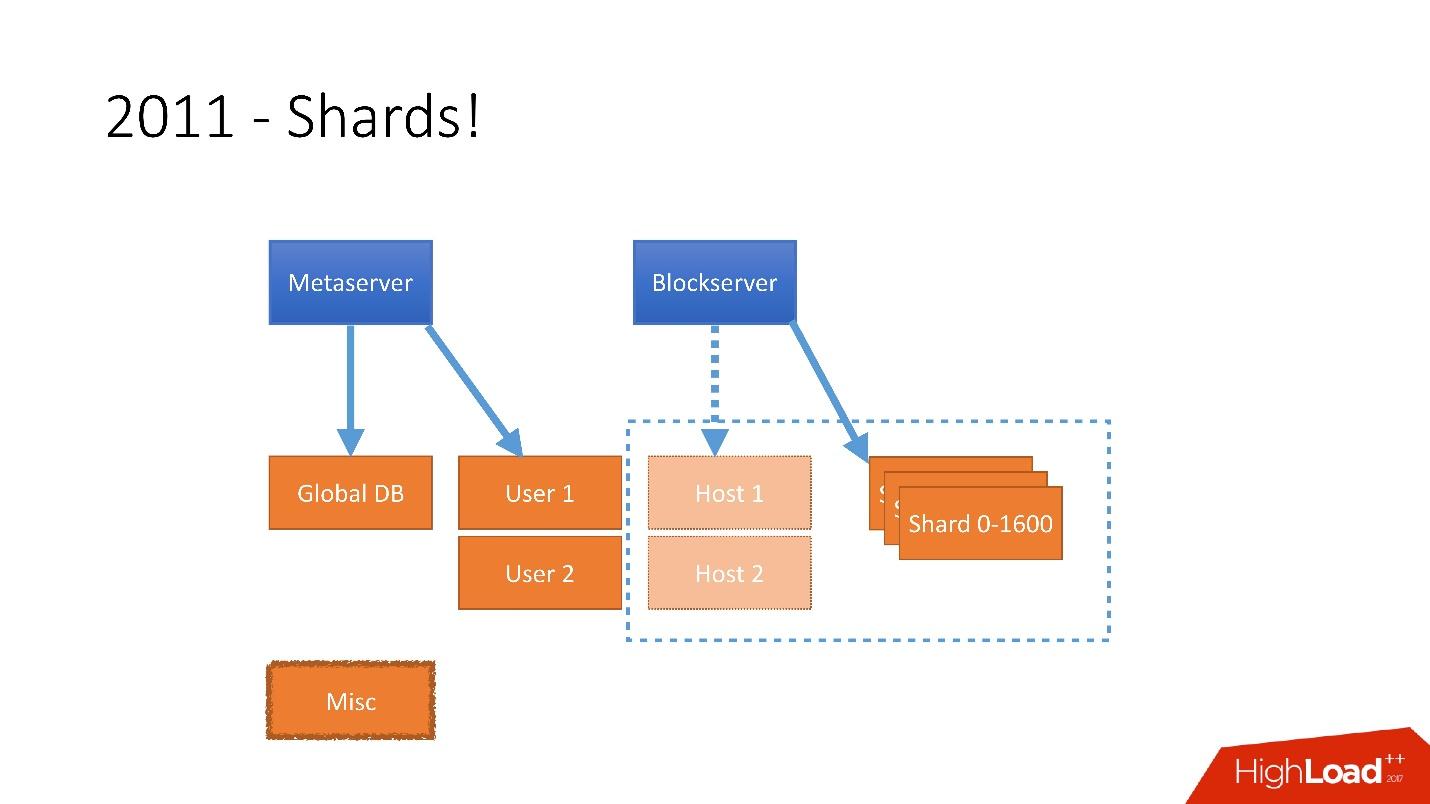
Es war notwendig, ein so großes Wachstum zu berücksichtigen, und deshalb hatten wir Ende 2011 Scherben - eine Basis bestehend aus 1.600 Scherben. Anfangs nur 8 Server mit jeweils 200 Shards. Jetzt sind es 400 Master-Server mit jeweils 4 Shards.
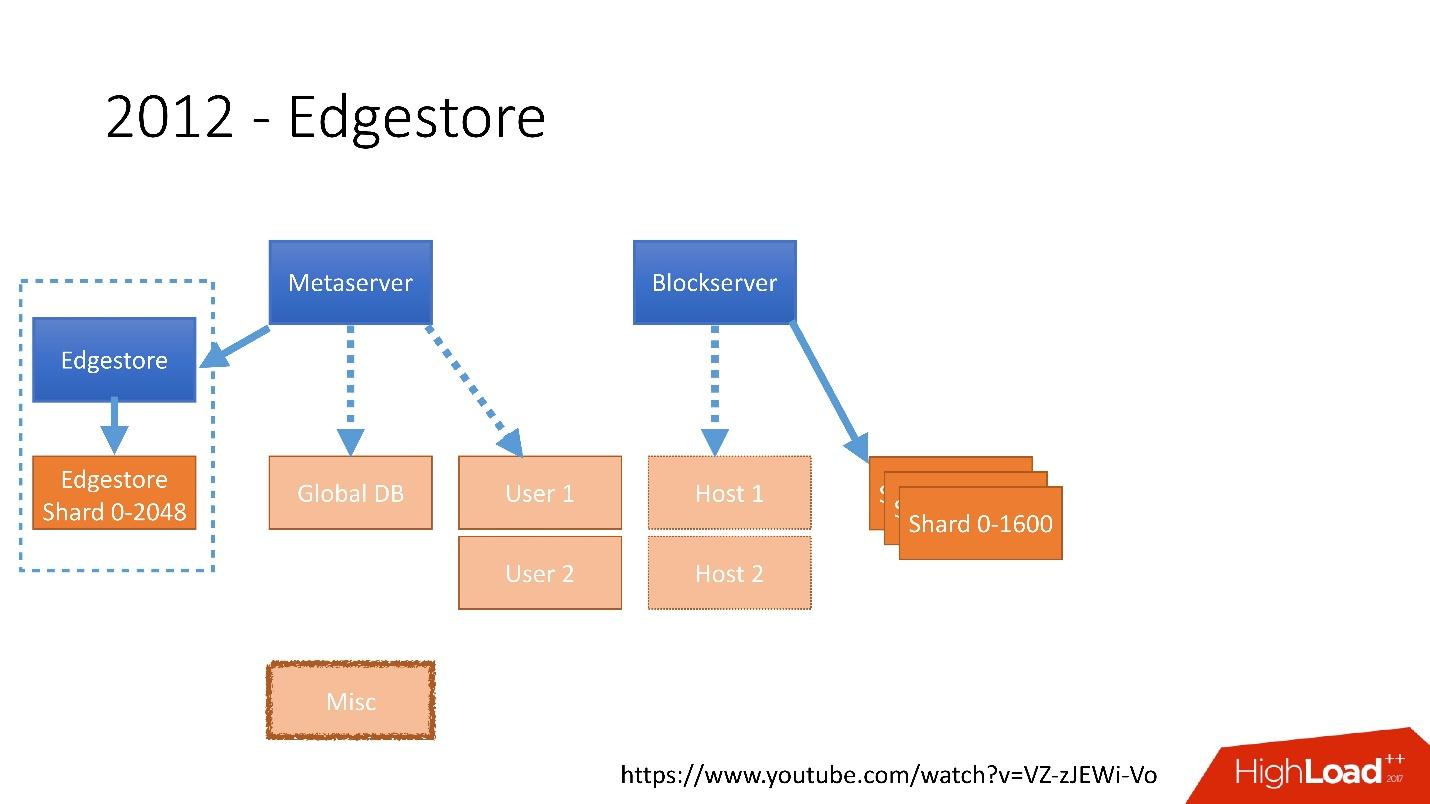 Link von der Folie
Link von der FolieIm Jahr 2012 haben wir festgestellt, dass das Erstellen und Aktualisieren von Tabellen in der Datenbank für jede hinzugefügte Geschäftslogik sehr schwierig, trostlos und problematisch ist. Aus diesem
Grund haben wir 2012 unseren eigenen
Grafikspeicher erfunden, den wir
Edgestore genannt haben.
Seitdem werden alle von der Anwendung generierten Geschäftslogiken und Metainformationen in Edgestore gespeichert.
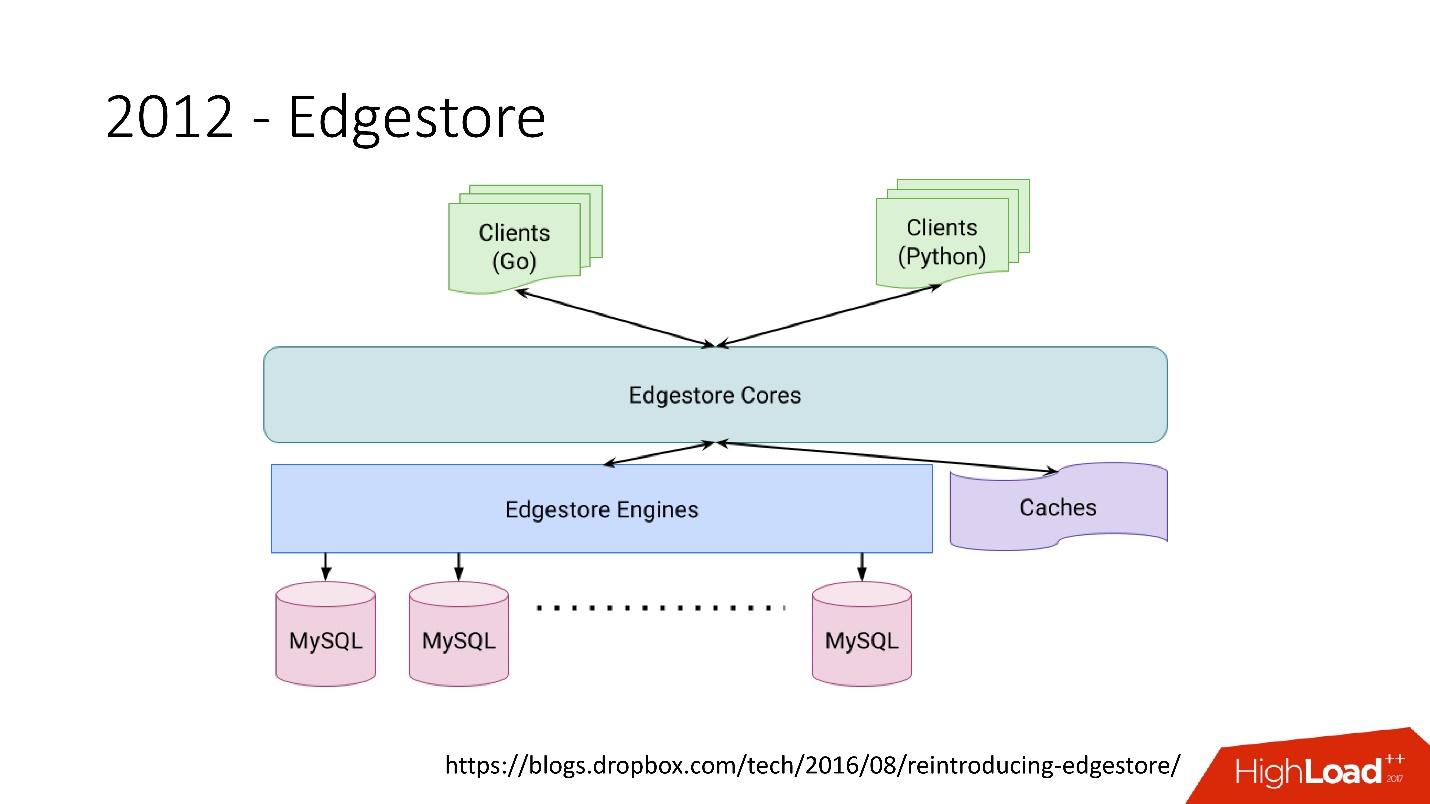
Edgestore abstrahiert MySQL im Wesentlichen von Clients. Clients haben bestimmte Entitäten, die durch Links von der gRPC-API zu Edgestore Core verbunden sind, wodurch diese Daten in MySQL konvertiert und irgendwie dort gespeichert werden (im Grunde gibt es all dies aus dem Cache).
 Link von der Folie2015 verließen wir Amazon S3
Link von der Folie2015 verließen wir Amazon S3 und entwickelten unseren eigenen Cloud-Speicher namens Magic Pocket. Es enthält Informationen darüber, wo sich eine Blockdatei befindet, auf welchem Server, über die Bewegungen dieser Blöcke zwischen Servern, die in MySQL gespeichert sind.
 Link von der Folie
Link von der FolieMySQL wird jedoch auf sehr knifflige Weise verwendet - im Wesentlichen als große verteilte Hash-Tabelle. Dies ist eine ganz andere Belastung, hauptsächlich beim Lesen von zufälligen Datensätzen. 90% der Auslastung ist I / O.
Datenbankarchitektur
Zunächst haben wir sofort einige Prinzipien identifiziert, nach denen wir die Architektur unserer Datenbank erstellen:
- Zuverlässigkeit und Haltbarkeit . Dies ist das wichtigste Prinzip und was Kunden von uns erwarten - Daten sollten nicht verloren gehen.
- Die Optimalität der Lösung ist ein ebenso wichtiges Prinzip. Beispielsweise sollten Sicherungen schnell durchgeführt und auch schnell wiederhergestellt werden.
- Einfachheit der Lösung - sowohl architektonisch als auch in Bezug auf Service und Weiterentwicklungsunterstützung.
- Betriebskosten . Wenn etwas die Lösung optimiert, aber sehr teuer ist, passt dies nicht zu uns. Zum Beispiel ist ein Slave, der einen Tag hinter dem Master liegt, für Backups sehr praktisch, aber dann müssen Sie 1.000 weitere zu 6.000 Servern hinzufügen - die Betriebskosten eines solchen Slaves sind sehr hoch.
Alle Prinzipien müssen
überprüfbar und messbar sein , dh sie müssen Metriken haben. Wenn wir über die Betriebskosten sprechen, müssen wir berechnen, wie viele Server wir beispielsweise in Datenbanken haben, wie viele Server in Backups gehen und wie viel es letztendlich für Dropbox kostet. Wenn wir eine neue Lösung auswählen, zählen wir alle Metriken und konzentrieren uns auf sie. Bei der Auswahl einer Lösung orientieren wir uns voll und ganz an diesen Grundsätzen.
Basistopologie
Die Datenbank ist wie folgt aufgebaut:
- Im Hauptdatenzentrum haben wir einen Master, in dem alle Datensätze vorkommen.
- Der Master-Server verfügt über zwei Slave-Server, auf denen eine semisynchrone Replikation erfolgt. Server sterben oft ab (ungefähr 10 pro Woche), daher benötigen wir zwei Slave-Server.
- Slave-Server befinden sich in separaten Clustern. Cluster sind vollständig getrennte Räume im Rechenzentrum, die nicht miteinander verbunden sind. Wenn ein Raum ausbrennt, bleibt der zweite vollständig funktionsfähig.
- Auch in einem anderen Rechenzentrum haben wir den sogenannten Pseudo-Master (Intermediate Master), der eigentlich nur ein Slave ist, der einen anderen Slave hat.
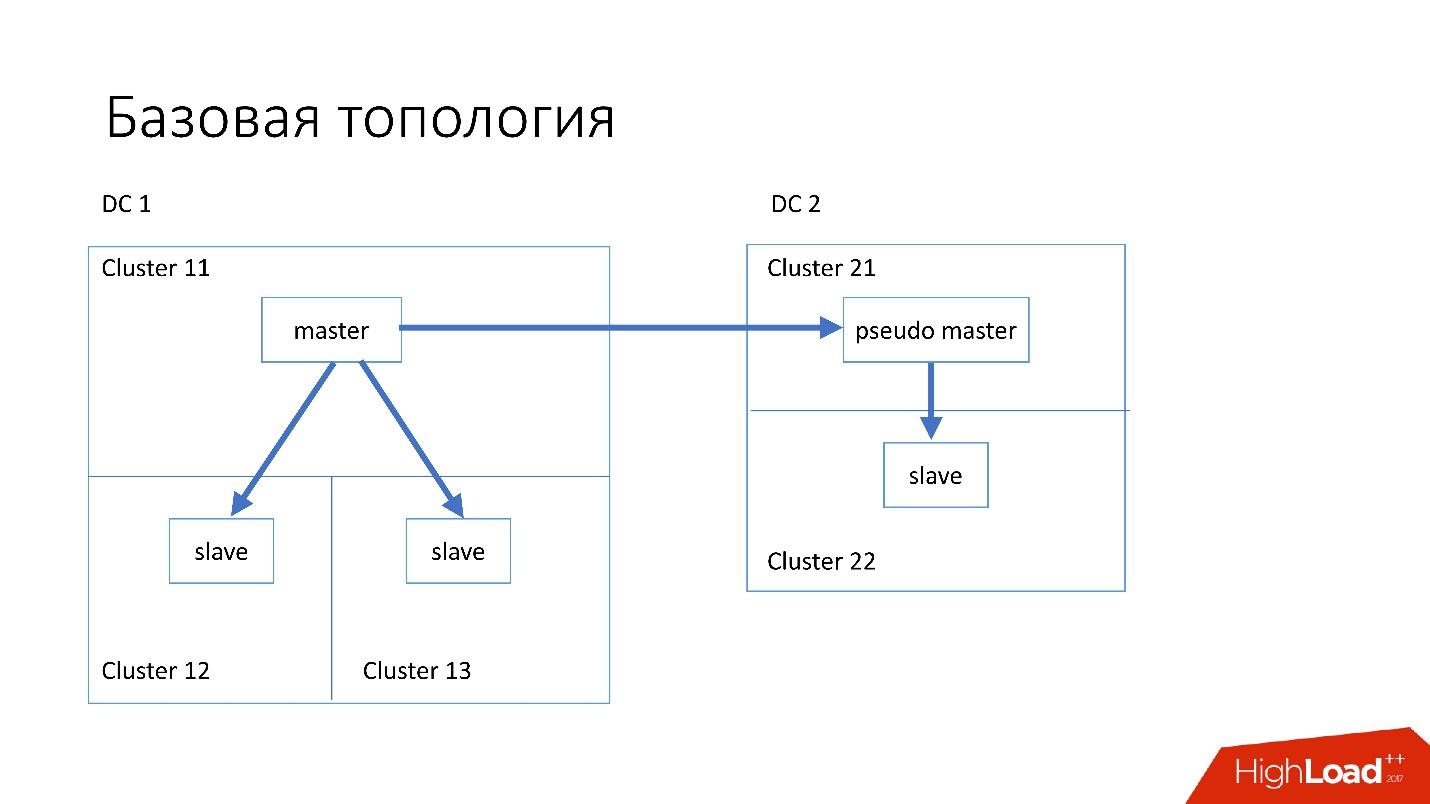
Eine solche Topologie wurde gewählt, weil, wenn das erste Rechenzentrum plötzlich in uns stirbt, wir im zweiten Rechenzentrum eine
fast vollständige Topologie haben . Wir ändern einfach alle Adressen in Discovery, und Kunden können arbeiten.
Spezialisierte Topologien
Wir haben auch spezialisierte Topologien.
Die
Magic Pocket- Topologie besteht aus einem Master-Server und zwei Slave-Servern. Dies geschieht, weil Magic Pocket selbst Daten zwischen Zonen dupliziert. Wenn ein Cluster verloren geht, können alle Daten aus anderen Zonen durch Löschcode wiederhergestellt werden.

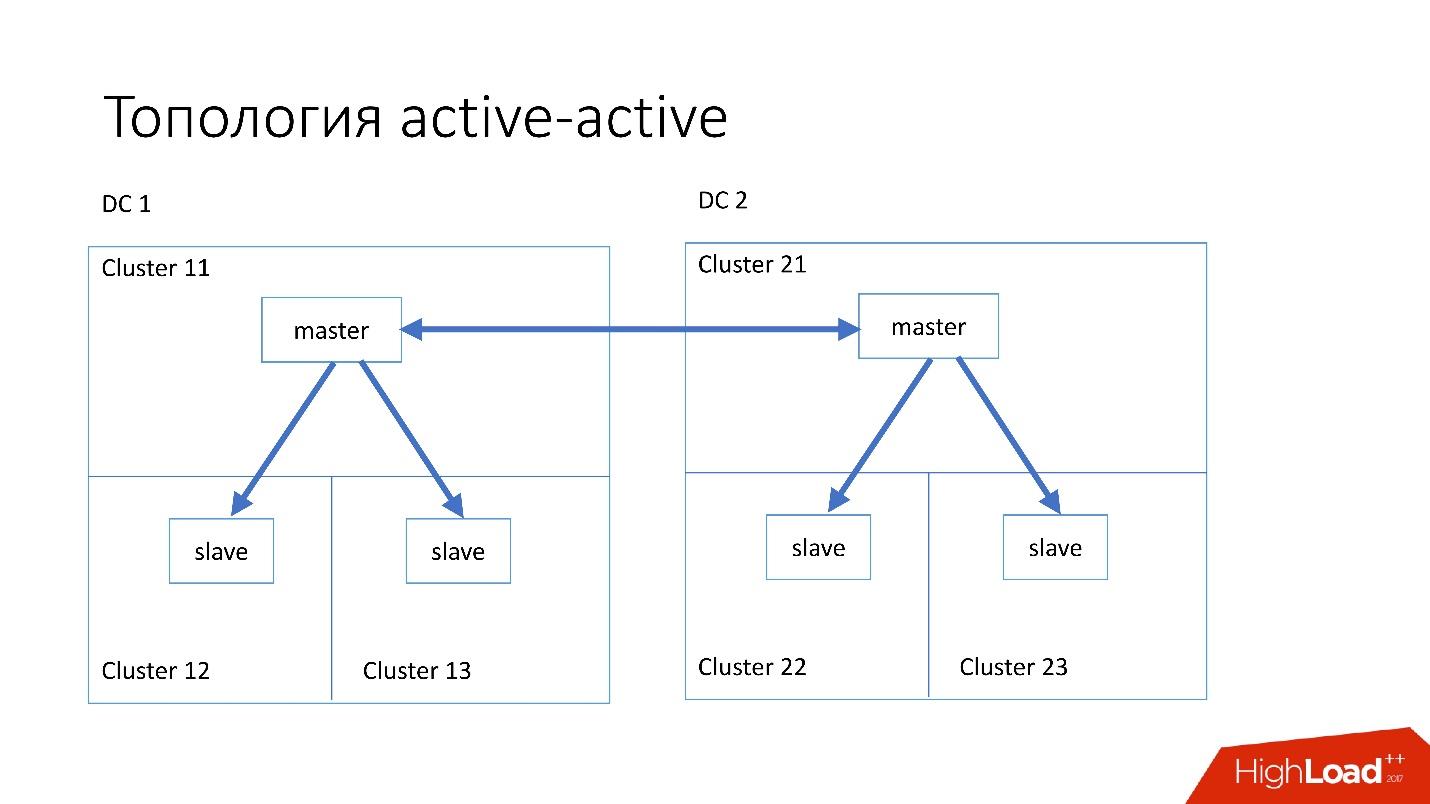
Die
Aktiv-Aktiv- Topologie ist die von Edgestore verwendete benutzerdefinierte Topologie. Es hat einen Master und zwei Slaves in jedem der beiden Rechenzentren und sie sind Slaves für einander. Dies ist ein sehr
gefährliches Schema , aber Edgestore auf seiner Ebene weiß genau, welche Daten auf welchem Master über welchen Bereich geschrieben werden können. Daher wird diese Topologie nicht unterbrochen.
Instanz
Wir haben vor 4-5 Jahren ziemlich einfache Server mit einer Konfiguration von installiert:
- 2x Xeon 10 Kerne;
- 5 TB (8 SSD Raid 0 *);
- 384 GB Speicher.
* Raid 0 - weil es einfacher und viel schneller ist, einen gesamten Server zu ersetzen als Laufwerke.
Einzelne Instanz
Auf diesem Server haben wir eine große MySQL-Instanz, auf der sich mehrere Shards befinden. Diese MySQL-Instanz ordnet sich sofort fast den gesamten Speicher zu. Auf dem Server werden auch andere Prozesse ausgeführt: Proxy, Statistiksammlung, Protokolle usw.
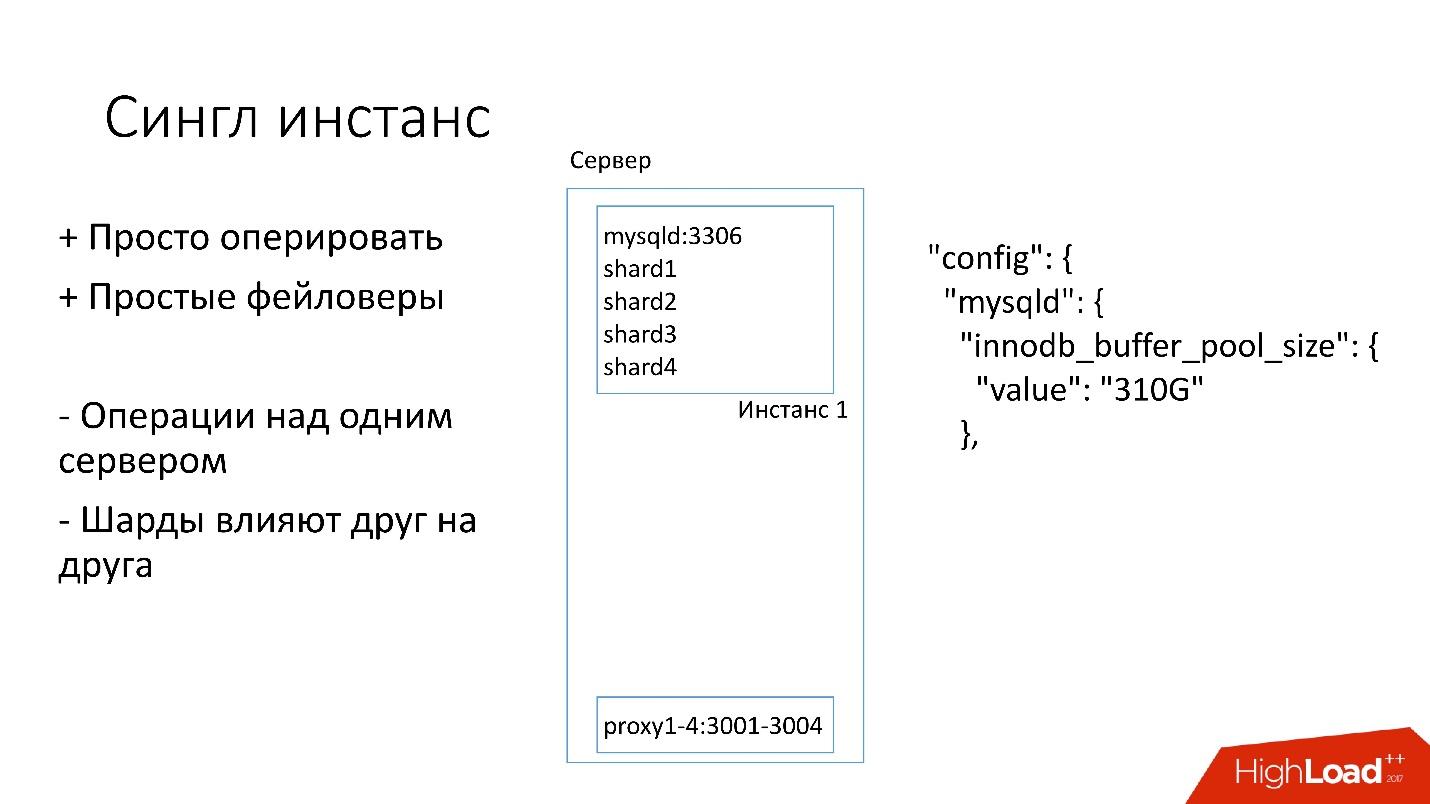
Diese Lösung ist insofern gut:
+ Es ist
einfach zu verwalten . Wenn Sie die MySQL-Instanz ersetzen müssen, ersetzen Sie einfach den Server.
+
Mach einfach Faylovers .
Andererseits:
- Es ist problematisch, dass Operationen auf der gesamten Instanz von MySQL und sofort auf allen Shards ausgeführt werden. Wenn Sie beispielsweise eine Sicherungskopie erstellen müssen, sichern wir alle Shards gleichzeitig. Wenn Sie einen Faylover machen müssen, machen wir einen Faylover aus allen vier Scherben gleichzeitig. Dementsprechend leidet die Zugänglichkeit viermal mehr.
- Probleme beim Replizieren eines Shards betreffen andere Shards. Die MySQL-Replikation ist nicht parallel und alle Shards arbeiten in einem einzelnen Thread. Wenn einem Splitter etwas passiert, werden auch die anderen Opfer.
Jetzt wechseln wir zu einer anderen Topologie.
Multi Instanz

In der neuen Version werden mehrere MySQL-Instanzen gleichzeitig auf dem Server mit jeweils einem Shard gestartet. Was ist besser
+ Wir können
Operationen nur an einem bestimmten Splitter ausführen . Das heißt, wenn Sie einen Faylover benötigen, wechseln Sie nur einen Shard. Wenn Sie ein Backup benötigen, sichern wir nur einen Shard. Dies bedeutet, dass die Vorgänge erheblich beschleunigt werden - viermal für einen Server mit vier Shards.
+
Scherben beeinflussen sich kaum gegenseitig .
+
Verbesserung der Replikation. Wir können verschiedene Kategorien und Klassen von Datenbanken mischen. Edgestore nimmt viel Platz ein, zum Beispiel alle 4 TB, und Magic Pocket nimmt nur 1 TB ein, ist aber zu 90% ausgelastet. Das heißt, wir können verschiedene Kategorien kombinieren, die E / A- und Maschinenressourcen auf unterschiedliche Weise verwenden, und 4 Replikationsströme starten.
Natürlich hat diese Lösung ihre Nachteile:
- Das größte Minus ist, dass es
viel schwieriger ist, all dies zu verwalten . Wir brauchen einen cleveren Planer, der versteht, wo er diese Instanz aufnehmen kann, wo es eine optimale Last gibt.
-
Härter als die Failover .
Deshalb kommen wir erst jetzt zu dieser Entscheidung.
Entdeckung
Clients müssen irgendwie wissen, wie sie sich mit der gewünschten Datenbank verbinden können, also haben wir Discovery, das:
- Benachrichtigen Sie den Client sehr schnell über Topologieänderungen. Wenn wir Master und Slave wechseln, sollten Kunden fast sofort davon erfahren.
- Die Topologie sollte nicht von der MySQL-Replikationstopologie abhängen, da wir bei einigen Operationen die MySQL-Topologie ändern. Wenn wir beispielsweise im vorbereitenden Schritt auf dem Zielmaster, in dem wir einen Teil der Shards übertragen, aufteilen, werden einige der Slave-Server auf diesen Zielmaster neu konfiguriert. Kunden müssen dies nicht wissen.
- Es ist wichtig, dass die Operationen atomar sind und der Zustand überprüft wird. Es ist unmöglich, dass zwei verschiedene Server derselben Datenbank gleichzeitig Master werden.
Wie sich Discovery entwickelt hat
Anfangs war alles einfach: die Datenbankadresse im Quellcode in der Konfiguration. Wenn wir die Adresse aktualisieren mussten, wurde alles nur sehr schnell bereitgestellt.

Leider funktioniert dies nicht, wenn viele Server vorhanden sind.
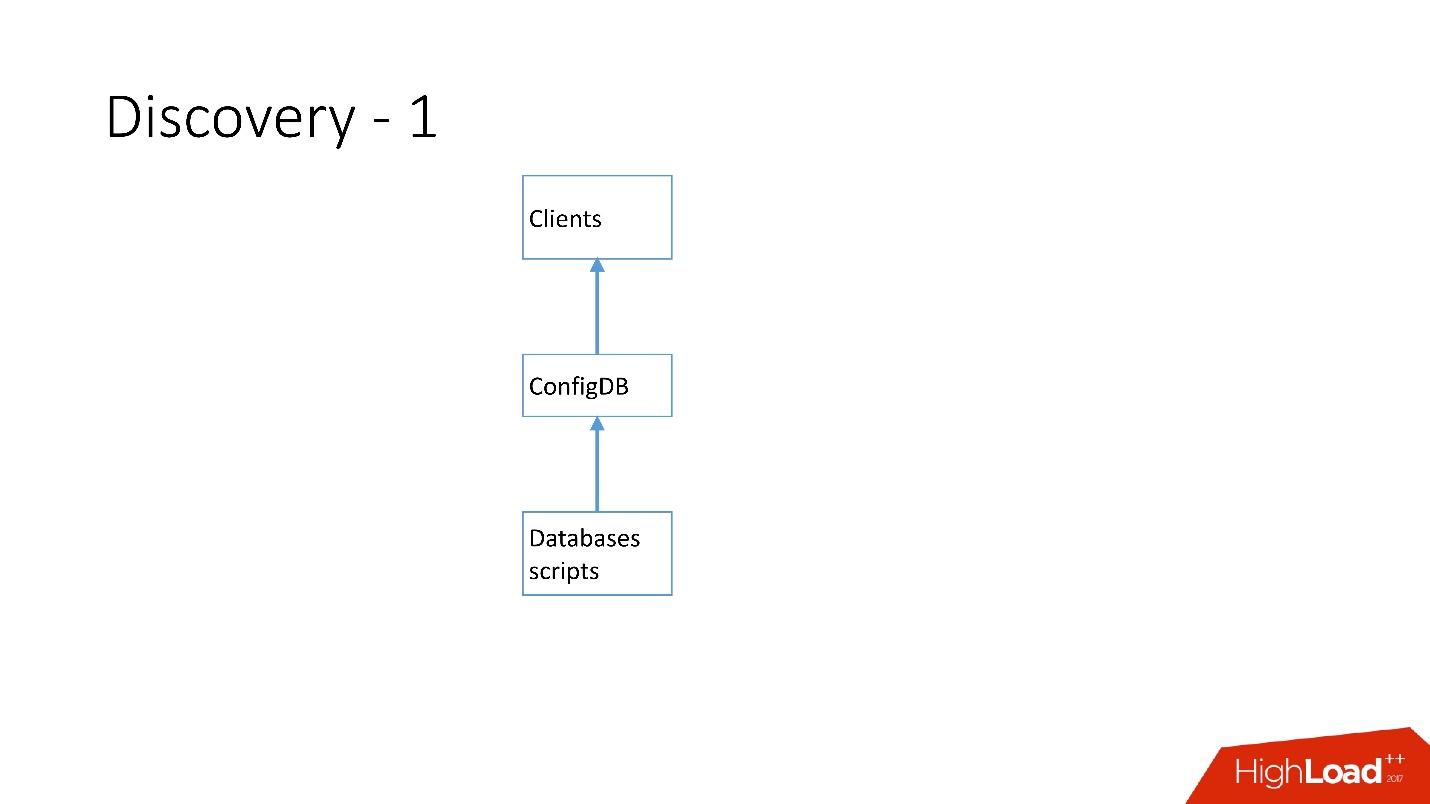
Oben ist die allererste Entdeckung, die wir haben. Es gab Datenbankskripte, die das Typenschild in ConfigDB änderten - es war ein separates MySQL-Typenschild, und Clients haben diese Datenbank bereits abgehört und regelmäßig Daten von dort abgerufen.

Die Tabelle ist sehr einfach, es gibt eine Datenbankkategorie, einen Shard-Schlüssel, einen Datenbankklassen-Master / Slave, einen Proxy und eine Datenbankadresse. Tatsächlich forderte der Client eine Kategorie, eine DB-Klasse, einen Shard-Schlüssel an, und die MySQL-Adresse wurde zurückgegeben, zu der er bereits eine Verbindung herstellen konnte.
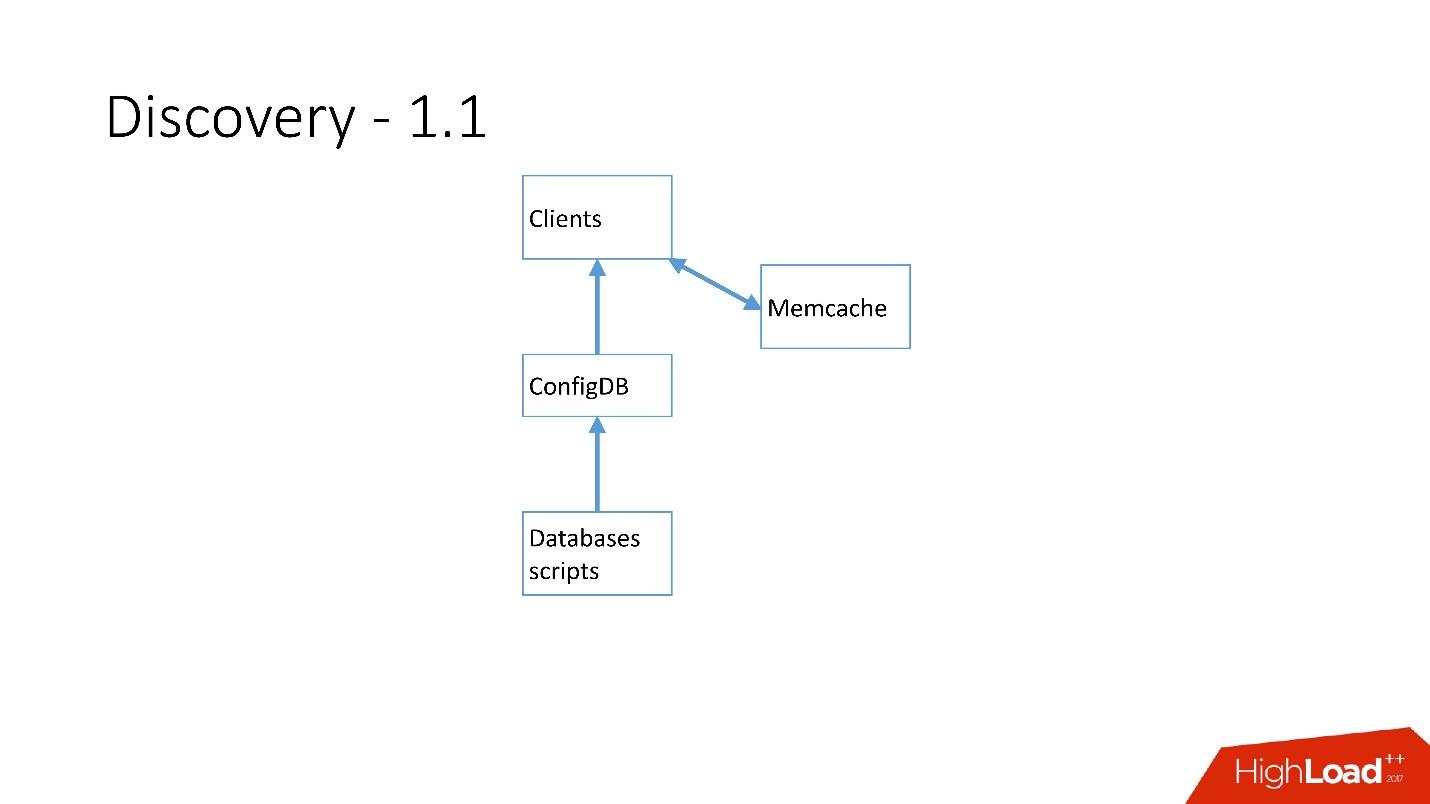
Sobald es viele Server gab, wurde Memcache hinzugefügt und die Clients begannen bereits mit ihm zu kommunizieren.
Aber dann haben wir es überarbeitet. MySQL-Skripte begannen über gRPC zu kommunizieren, über einen Thin Client mit einem Dienst namens RegisterService. Als einige Änderungen auftraten, hatte RegisterService eine Warteschlange, und er verstand, wie diese Änderungen angewendet werden. RegisterService hat Daten in AFS gespeichert. AFS ist unser internes System, das auf ZooKeeper basiert.

Die zweite Lösung, die hier nicht gezeigt wird, verwendete ZooKeeper direkt, und dies verursachte Probleme, da jeder Shard ein Knoten in ZooKeeper war. Zum Beispiel stellen 100.000 Clients eine Verbindung zu ZooKeeper her. Wenn sie plötzlich aufgrund eines Fehlers gestorben sind, werden sofort 100.000 Anfragen an ZooKeeper gesendet, die einfach gelöscht werden und nicht mehr steigen können.
Daher wurde
das AFS-System entwickelt
, das von der gesamten Dropbox verwendet wird . Tatsächlich wird die Arbeit mit ZooKeeper für alle Kunden abstrahiert. Der AFS-Dämon wird lokal auf jedem Server ausgeführt und bietet eine sehr einfache Datei-API des Formulars: Erstellen Sie eine Datei, löschen Sie eine Datei, fordern Sie eine Datei an, erhalten Sie eine Benachrichtigung über eine Dateiänderung und vergleichen und tauschen Sie Vorgänge aus. Das heißt, Sie können versuchen, die Datei durch eine Version zu ersetzen. Wenn sich diese Version während der Änderung geändert hat, wird der Vorgang abgebrochen.
Im Wesentlichen eine solche Abstraktion über ZooKeeper, in der es einen lokalen Backoff- und Jitter-Algorithmus gibt. ZooKeeper stürzt unter Last nicht mehr ab. Mit AFS erstellen wir Backups in S3 und GIT. Anschließend benachrichtigt der lokale AFS die Clients selbst, dass sich die Daten geändert haben.

In AFS werden Daten als Dateien gespeichert, dh es handelt sich um eine Dateisystem-API. Das Obige ist beispielsweise die Datei shard.slave_proxy - die größte Datei benötigt ungefähr 28 KB. Wenn wir die Kategorie der Klasse shard und slave_proxy ändern, erhalten alle Clients, die diese Datei abonnieren, eine Benachrichtigung. Sie lesen diese Datei erneut, die alle erforderlichen Informationen enthält. Mithilfe des Shard-Schlüssels erhalten sie eine Kategorie und konfigurieren den Verbindungspool zur Datenbank neu.
Operationen
Wir verwenden sehr einfache Vorgänge: Heraufstufen, Klonen, Sichern / Wiederherstellen.
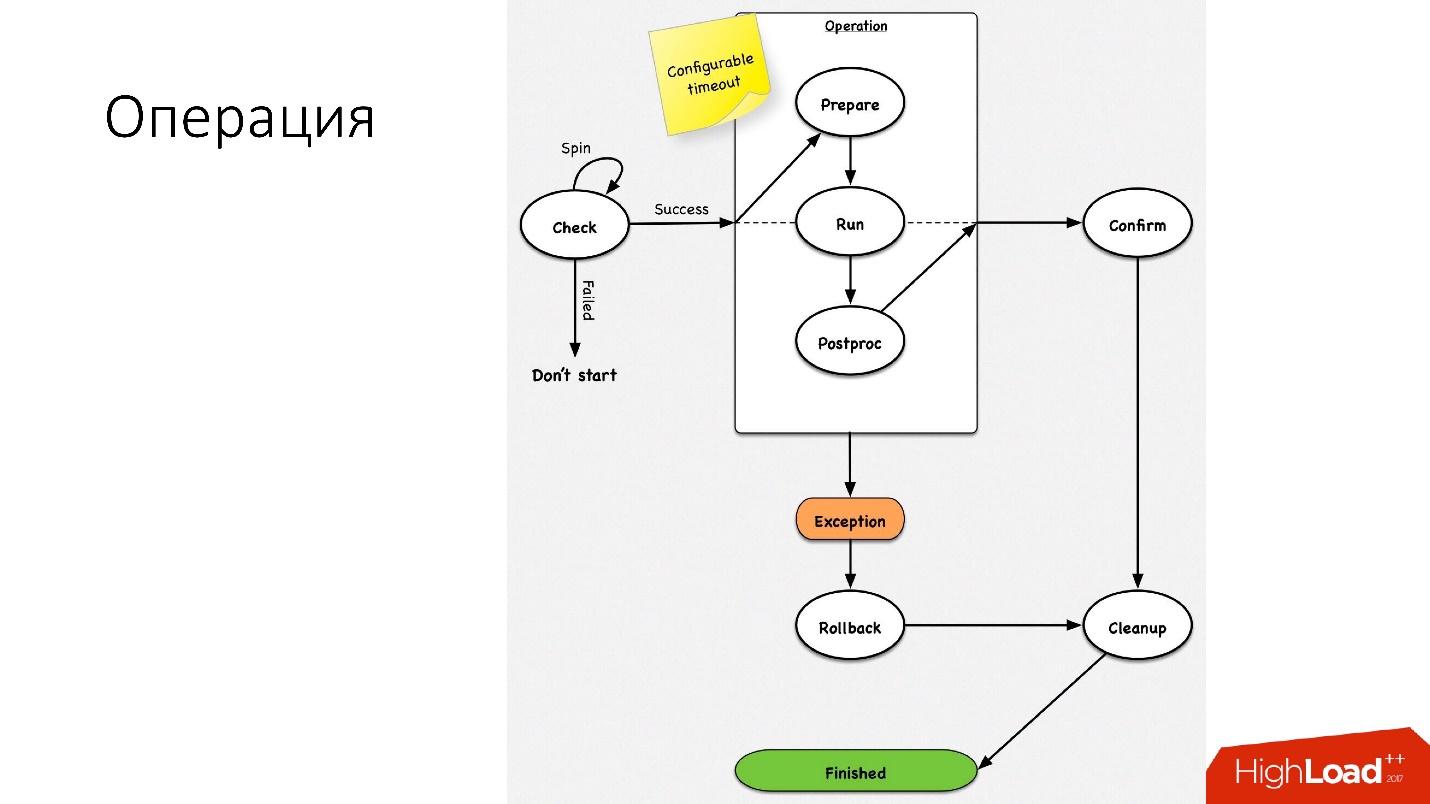 Eine Operation ist eine einfache Zustandsmaschine
Eine Operation ist eine einfache Zustandsmaschine . Wenn wir in die Operation gehen, führen wir einige Überprüfungen durch, zum Beispiel eine Schleuderprüfung, die mehrmals anhand des Zeitlimits überprüft, ob wir diese Operation ausführen können. Danach führen wir einige vorbereitende Maßnahmen durch, die keine Auswirkungen auf externe Systeme haben. Als nächstes die Operation selbst.
Alle Schritte innerhalb einer Operation haben einen
Rollback-Schritt (Rückgängig). Wenn bei der Operation ein Problem auftritt, versucht die Operation, das System an seiner ursprünglichen Position wiederherzustellen. Wenn alles in Ordnung ist, erfolgt die Bereinigung und der Vorgang ist abgeschlossen.
Wir haben eine so einfache Zustandsmaschine für jede Operation.
Beförderung (Masterwechsel)
Dies ist eine sehr häufige Operation in der Datenbank. Es gab Fragen, wie man Änderungen an einem funktionierenden Hot-Master-Server vornimmt - es wird einen Einsatz bekommen. Es ist nur so, dass alle diese Vorgänge auf Slave-Servern ausgeführt werden und dann Slave-Änderungen mit Master-Plätzen vorgenommen werden. Daher ist die
Werbemaßnahme sehr häufig .

Wir müssen den Kernel aktualisieren - wir tauschen, wir müssen die Version von MySQL aktualisieren - wir aktualisieren auf Slave, wechseln zu Master, aktualisieren dort.

Wir haben eine sehr schnelle Beförderung erreicht. Zum Beispiel
haben wir für vier Scherben jetzt eine Beförderung für ungefähr 10-15 s. Die obige Grafik zeigt, dass die Verfügbarkeit von Werbeaktionen um 0,0003% gelitten hat.
Aber normale Werbung ist nicht so interessant, weil dies gewöhnliche Operationen sind, die jeden Tag durchgeführt werden. Failover sind interessant.
Failover (Ersatz für einen defekten Master)
Ein Failover bedeutet, dass die Datenbank tot ist.
- Wenn der Server wirklich gestorben ist, ist dies nur ein idealer Fall.
- In der Tat kommt es vor, dass die Server teilweise am Leben sind.
- Manchmal stirbt der Server sehr langsam. Die RAID-Controller, das Festplattensystem fallen aus, einige Anforderungen geben Antworten zurück, aber einige Flows sind blockiert und geben keine Antworten zurück.
- Es kommt vor, dass der Master einfach überlastet ist und nicht auf unseren Gesundheitscheck reagiert. Aber wenn wir befördert werden, wird auch der neue Meister überlastet und es wird nur noch schlimmer.
Der Austausch verstorbener Master-Server erfolgt ca.
2-3 mal am Tag . Dies ist ein vollautomatischer Prozess, bei dem kein menschliches Eingreifen erforderlich ist. Der kritische Abschnitt dauert ungefähr 30 Sekunden und es gibt eine Reihe zusätzlicher Überprüfungen, um festzustellen, ob der Server tatsächlich lebt oder möglicherweise bereits gestorben ist.
Unten sehen Sie ein Beispieldiagramm, wie der Faylover funktioniert.

Im ausgewählten Abschnitt
starten wir
den Master-Server neu . Dies ist notwendig, da wir MySQL 5.6 haben und die semisynchrone Replikation nicht verlustfrei ist. Daher sind Phantom-Lesevorgänge möglich, und wir brauchen diesen Master, auch wenn er nicht gestorben ist, so schnell wie möglich zu töten, damit Clients die Verbindung dazu trennen. Daher führen wir einen Hard-Reset über Ipmi durch - dies ist die erste wichtige Operation, die wir ausführen müssen. In der MySQL 5.7-Version ist dies nicht so kritisch.
Clustersynchronisation. Warum brauchen wir eine Clustersynchronisation?
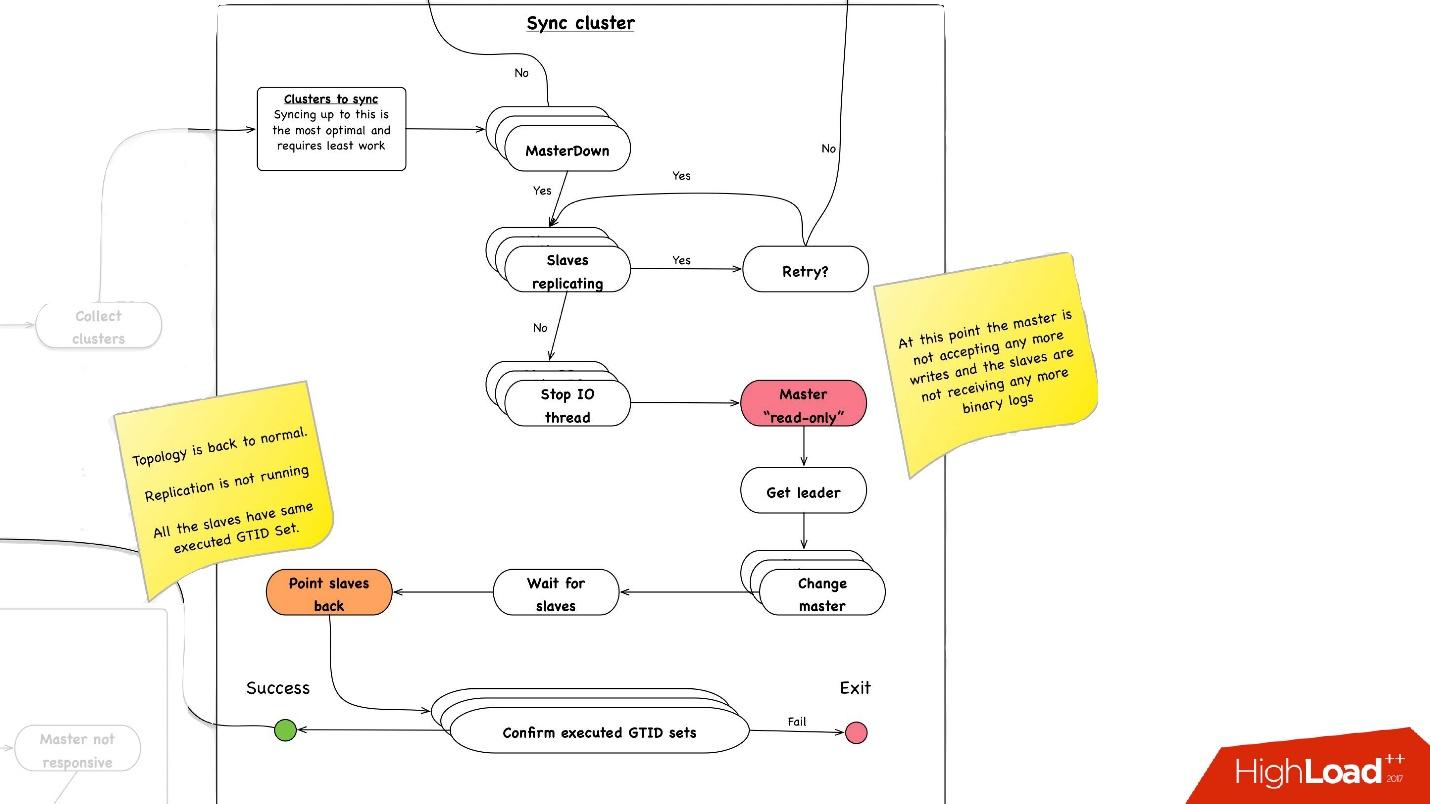
Wenn wir uns mit unserer Topologie an das vorherige Bild erinnern, hat ein Master-Server drei Slave-Server: zwei in einem Rechenzentrum, einer im anderen. Bei der Beförderung muss sich der Master im selben Hauptdatenzentrum befinden. Aber manchmal, wenn Slaves mit Semisync geladen werden, kommt es vor, dass ein Semisync-Slave ein Slave in einem anderen Rechenzentrum wird, weil er nicht geladen wird. Daher müssen wir zuerst den gesamten Cluster synchronisieren und dann bereits eine Promotion auf dem Slave in dem von uns benötigten Rechenzentrum durchführen. Dies geschieht ganz einfach:
- Wir stoppen alle E / A-Threads auf allen Slave-Servern.
- Danach wissen wir bereits mit Sicherheit, dass der Master "schreibgeschützt" ist, da die Semisync-Verbindung getrennt wurde und niemand anderes dort etwas schreiben kann.
- Als nächstes wählen wir den Slave mit dem größten abgerufenen / ausgeführten GTID-Satz aus, dh mit der größten Transaktion, die er entweder heruntergeladen oder bereits angewendet hat.
- Wir konfigurieren alle Slave-Server für diesen ausgewählten Slave neu, starten den E / A-Thread und sie werden synchronisiert.
- Wir warten, bis sie synchronisiert sind. Danach wird der gesamte Cluster synchronisiert. Am Ende überprüfen wir, ob der GTID-Satz überall, wo wir ihn ausgeführt haben, auf dieselbe Position gesetzt ist.
Die zweite wichtige Operation ist die Clustersynchronisation . Die weitere Werbung beginnt wie folgt: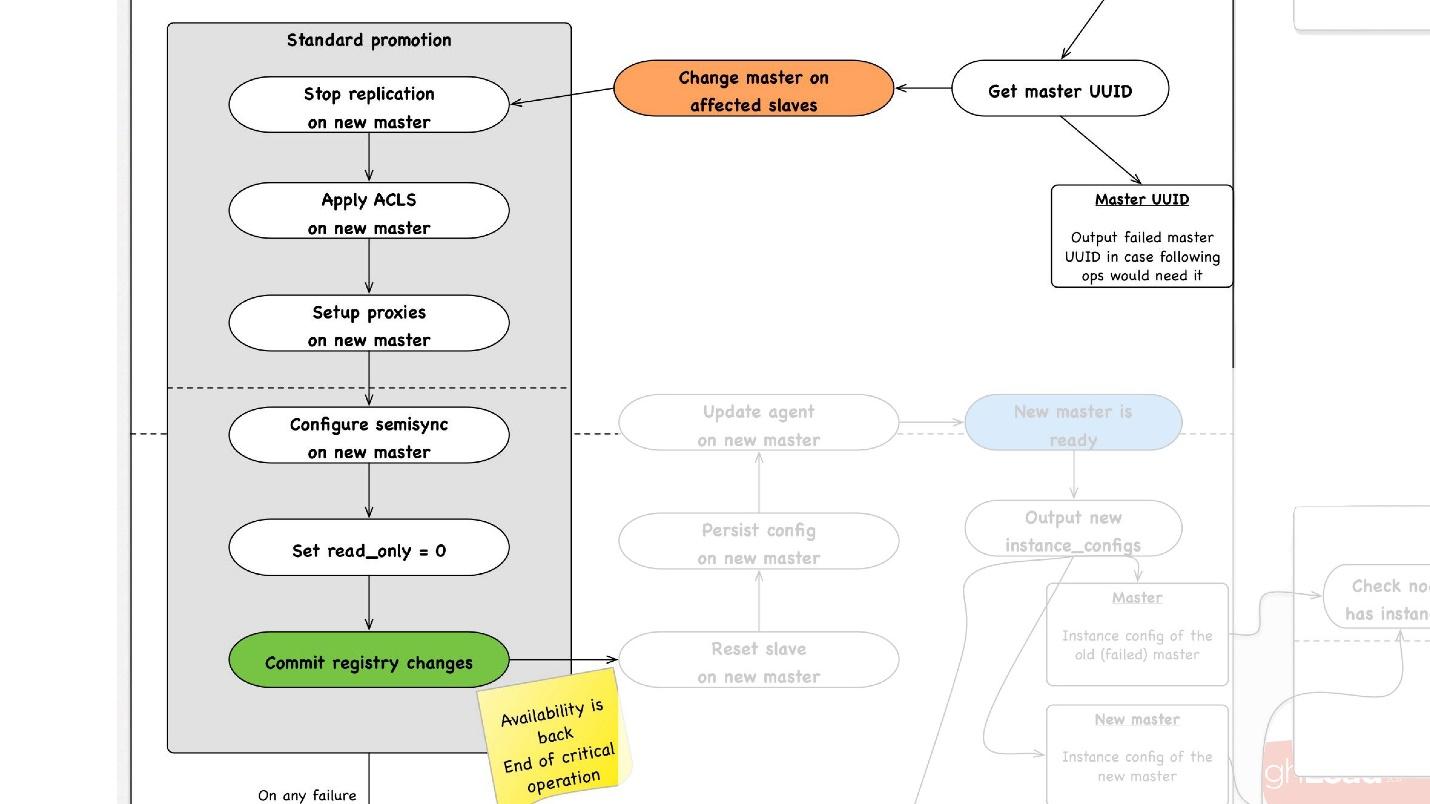
- Wir wählen jeden Slave im Rechenzentrum aus, den wir benötigen, sagen ihm, dass er Master ist, und starten den Standard-Promotion-Vorgang.
- Wir konfigurieren alle Slave-Server für diesen Master neu, stoppen dort die Replikation, wenden ACLs an, fahren Benutzer ein, stoppen einige Proxys und starten möglicherweise etwas neu.
- Am Ende machen wir read_only = 0, das heißt, wir sagen, dass wir jetzt in den Master schreiben und die Topologie aktualisieren können. Von nun an gehen Kunden zu diesem Master und alles funktioniert für sie.
- - . - , , , , , proxy .
- .
, rollback , . rollback reboot. , , , — change master — master .
— . , , , , .
● slave
, slave-, . .
●
, , . .
●
, , . . 3 .
, , , :
- . 1 40 .
- .
, . 1 40 , , , .
, . . 4 .
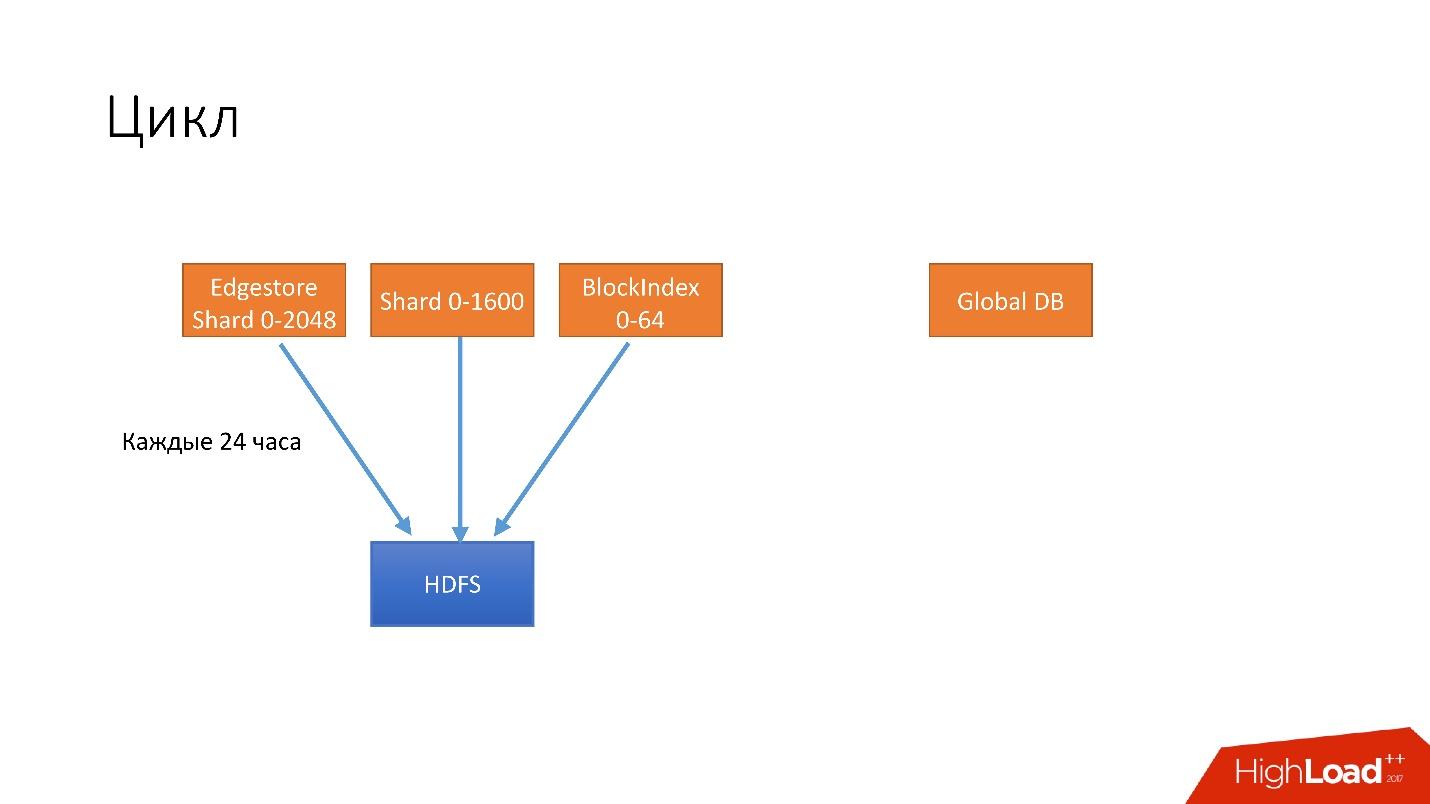
- 24 . HDFS, .
- 6 unsharded databases, Global DB. , , , .
- 3 S3.
- 3 S3 .

. , 3 , HDFS 3 , 6 S3. .
, .

, , . , , recovery - . , , - . 100 , .
, , , , , , , . .

hot-, Percona xtrabackup. —stream=xbstream, , . script-splitter, , .
MySQL 2x. 3 , , , 1 500 . , , HDFS S3.
.

, , HDFS S3, , splitter xtrabackup, . crash-recovery.
hot , crash-recovery . , . binlog, master.
binlogs?binlog'. master , 4 , 100 , HDFS.
: Binlog Backuper, . , , binlog HDFS.
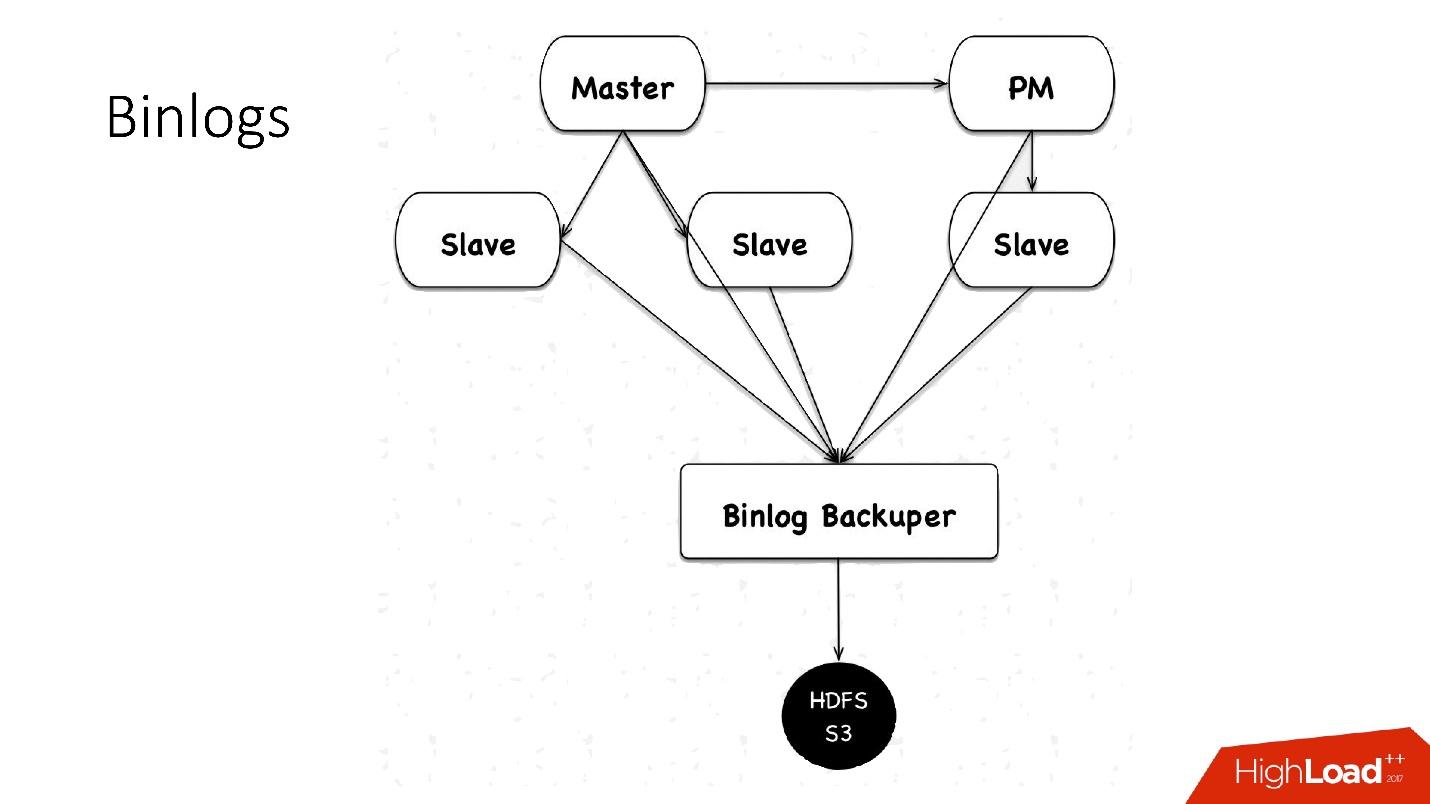
, 4 , 5 , , , . HDFS S3 .
.
:
- — 10 , 45 — .
- , scheduler multi instance slave master .
- — , . , , , , , , . pt-table-checksum , .
, :
- 1 10 , . crash-recovery, .
- .

slave -, . , . Alles ist sehr einfach.
++
. Hardware , (HDD) 10 , + crash recovery xtrabackup, . , , . , , , , HDD , HDFS .
, — :
- ;
- .
, HDFS, , , .
Automatisierung
, 6 000 . , , — :
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
, , , , — , -. , .
Availability () — , . — recovery , .

MySQL , heartbeat. Heartbeat — timestamp.
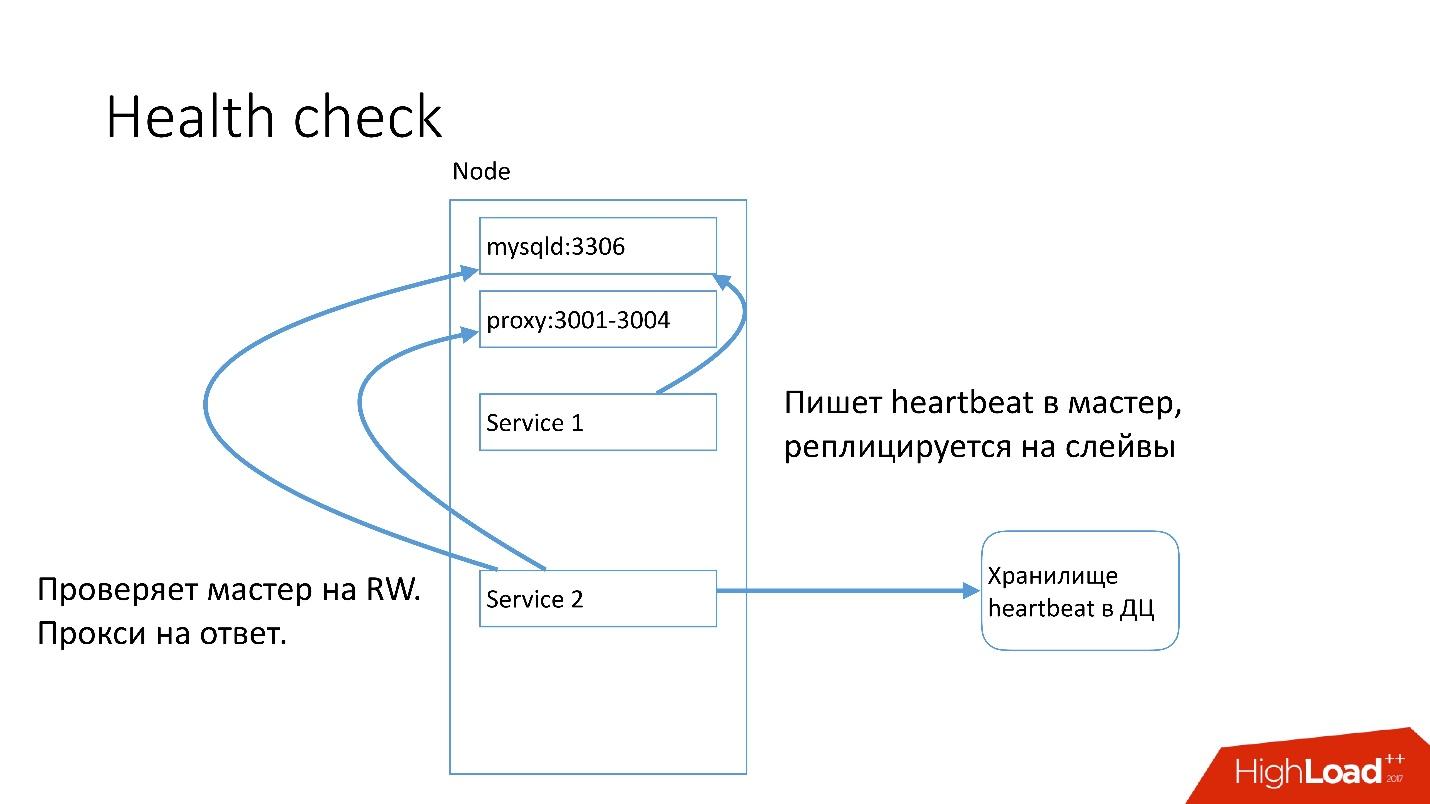
, , , master read-write. heartbeat.
auto-replace , .
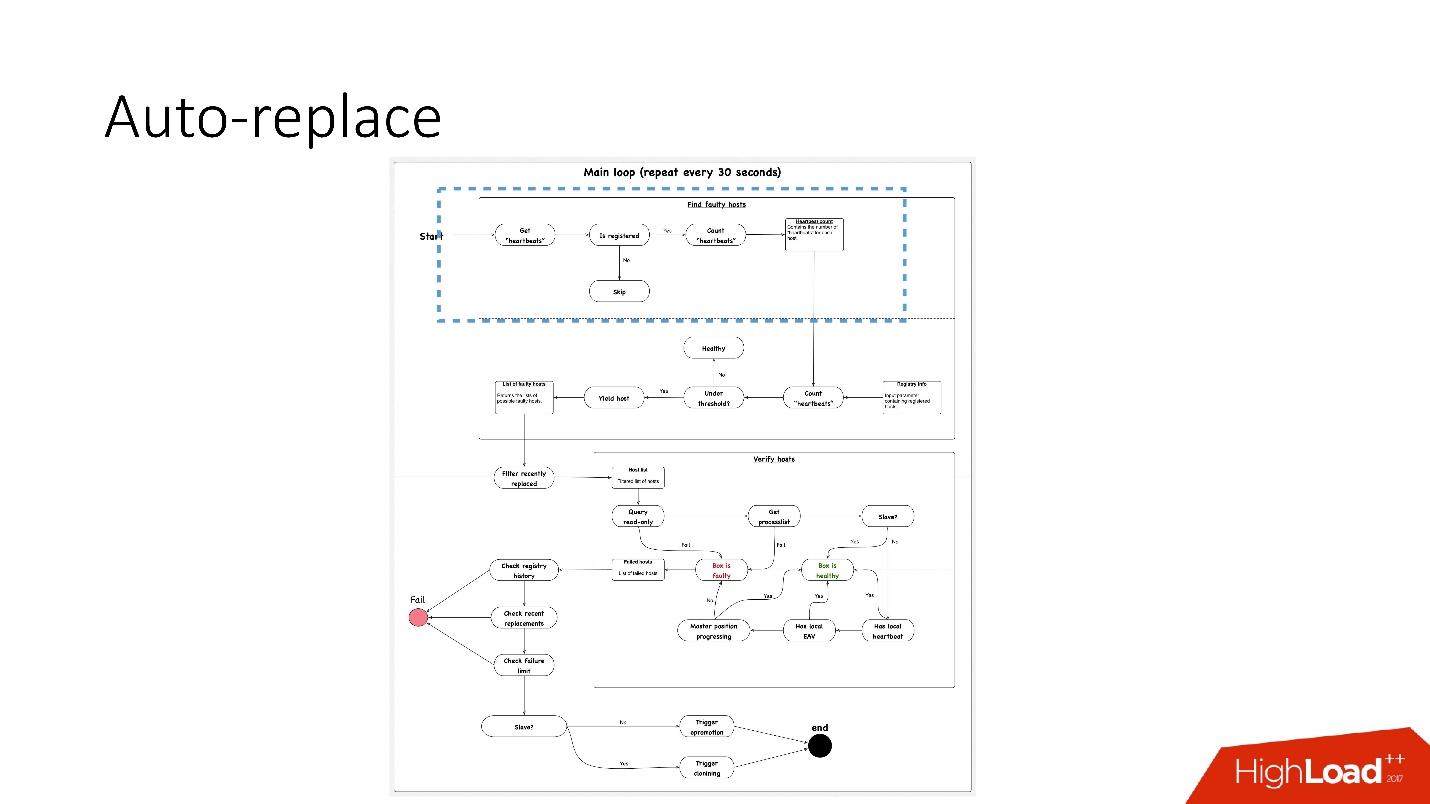 , 91 .?
, 91 .?- , heartbeat . , . heartbeat', , heartbeat' 30 .
- Überprüfen Sie als Nächstes, ob ihre Anzahl den Schwellenwert erfüllt. Wenn nicht, stimmt etwas mit dem Server nicht - da er keinen Herzschlag gesendet hat.
- Danach führen wir für alle Fälle eine umgekehrte Überprüfung durch - plötzlich sind diese beiden Dienste ausgefallen, etwas befindet sich im Netzwerk oder die globale Datenbank kann den Heartbeat aus irgendeinem Grund nicht schreiben. Bei der umgekehrten Überprüfung stellen wir eine Verbindung zu einer defekten Datenbank her und überprüfen deren Status.
- Wenn alles andere fehlschlägt, prüfen wir, ob die Master-Position voranschreitet oder nicht, ob Datensätze darauf vorhanden sind. Wenn nichts passiert, funktioniert dieser Server definitiv nicht.
- Der letzte Schritt ist das automatische Ersetzen.
Das automatische Ersetzen ist sehr konservativ. Er möchte nie viele automatische Operationen ausführen.
- Zuerst prüfen wir, ob in letzter Zeit Topologieoperationen stattgefunden haben. Möglicherweise wurde dieser Server gerade hinzugefügt und etwas darauf läuft noch nicht.
- Wir überprüfen, ob zu irgendeinem Zeitpunkt Ersatz im selben Cluster vorhanden war.
- Überprüfen Sie, welche Fehlergrenze wir haben. Wenn wir viele Probleme gleichzeitig haben - 10, 20 -, werden wir nicht alle automatisch lösen, da wir versehentlich den Betrieb aller Datenbanken stören können.
Daher
lösen wir jeweils
nur ein Problem .
Dementsprechend beginnen wir für den Slave-Server mit dem Klonen und entfernen ihn einfach aus der Topologie. Wenn es sich um einen Master handelt, starten wir den Feylover, die sogenannte Notfall-Promotion.
DBManager
DBManager ist ein Dienst zur Verwaltung unserer Datenbanken. Es hat:
- Smart Task Scheduler, der genau weiß, wann der Job zu starten ist;
- Protokolle und alle Informationen: Wer, wann und was gestartet - das ist die Quelle der Wahrheit;
- Synchronisationspunkt.
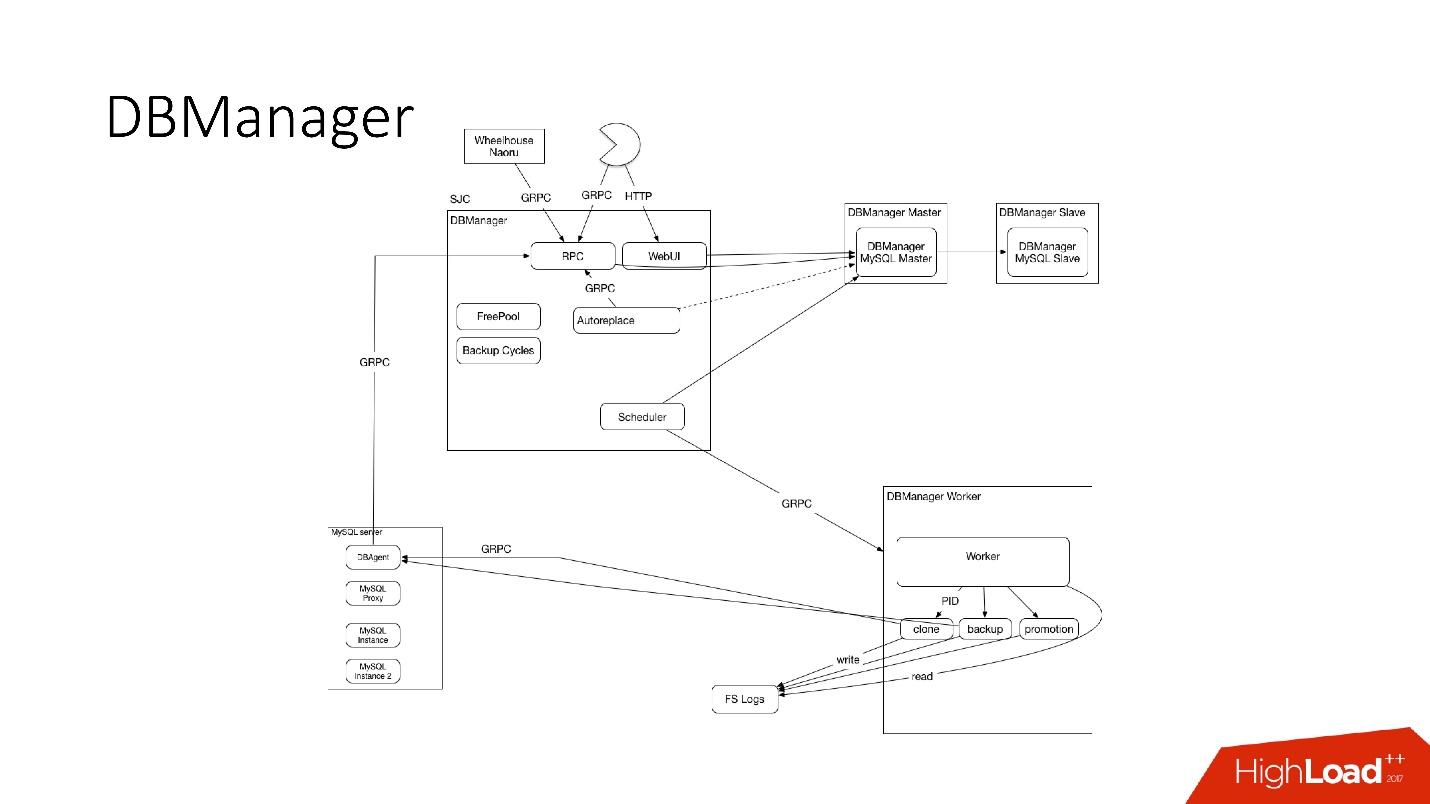
DBManager ist architektonisch recht einfach.
- Es gibt Clients, entweder DBAs, die etwas über die Weboberfläche tun, oder Skripte / Dienste, die DBAs geschrieben haben, die über gRPC zugreifen.
- Es gibt externe Systeme wie Wheelhouse und Naoru, die über gRPC an DBManager gehen.
- Es gibt einen Planer, der versteht, welche Operation wann und wo er beginnen kann.
- Es gibt einen sehr dummen Arbeiter, der, wenn eine Operation zu ihm kommt, sie startet und per PID prüft. Worker kann neu starten, Prozesse werden nicht unterbrochen. Alle Mitarbeiter befinden sich so nah wie möglich an den Servern, auf denen die Vorgänge stattfinden, sodass wir beispielsweise beim Aktualisieren von ACLS nicht viele Roundtrips durchführen müssen.
- Auf jedem SQL-Host haben wir einen DBAgent - dies ist ein RPC-Server. Wenn Sie eine Operation auf dem Server ausführen müssen, senden wir eine RPC-Anfrage.
Wir haben eine Weboberfläche für DBManager, über die Sie die aktuell ausgeführten Aufgaben, Protokolle für diese Aufgaben, wer sie wann gestartet hat, welche Vorgänge für den Server einer bestimmten Datenbank usw. ausgeführt wurden, anzeigen können.
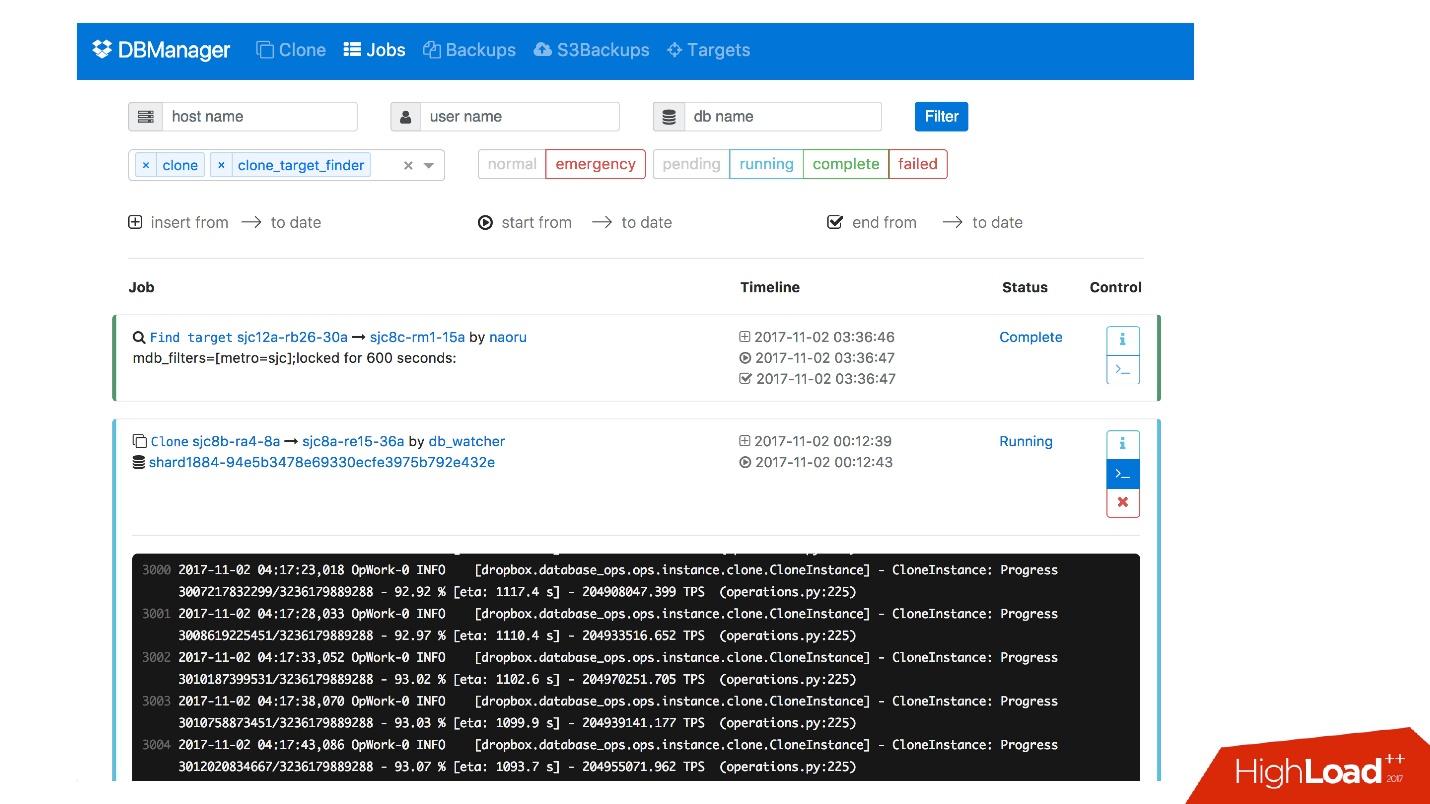
Es gibt eine ziemlich einfache CLI-Oberfläche, über die Sie Aufgaben ausführen und in praktischen Ansichten anzeigen können.
Abhilfemaßnahmen
Wir haben auch ein System, um auf Probleme zu reagieren. Wenn beispielsweise etwas kaputt geht, das Laufwerk abstürzt oder ein Dienst nicht funktioniert, funktioniert
Naoru. Dies ist das System, das in Dropbox funktioniert, von jedem verwendet wird und speziell für solche kleinen Aufgaben entwickelt wurde. Ich habe in meinem
Bericht 2016 über Naoru gesprochen.
Wheelhouse basiert auf einer
Zustandsmaschine und ist für lange Prozesse ausgelegt. Zum Beispiel müssen wir den Kernel auf allen MySQL auf unserem gesamten Cluster von 6.000 Computern aktualisieren. Wheelhouse macht dies klar - Updates auf dem Slave-Server, startet die Promotion, Slave wird Master, Updates auf dem Master-Server. Dieser Vorgang kann ein oder sogar zwei Monate dauern.
Überwachung

Es ist sehr wichtig.
Wenn Sie das System nicht überwachen, funktioniert es höchstwahrscheinlich nicht.
Wir überwachen alles in MySQL - alle Informationen, die wir von MySQL erhalten können, werden irgendwo gespeichert, wir können rechtzeitig darauf zugreifen. Wir speichern Informationen zu InnoDb, Statistiken zu Anfragen, zu Transaktionen, zur Länge von Transaktionen, Perzentile zu Transaktionslängen, zur Replikation, im Netzwerk - alles in allem - eine große Anzahl von Metriken.
Alarm
Wir haben 992 Warnungen konfiguriert. Tatsächlich befasst sich niemand mit Metriken. Es scheint mir, dass es keine Leute gibt, die zur Arbeit kommen und anfangen, sich das Metrikdiagramm anzusehen. Es gibt interessantere Aufgaben.

Daher gibt es Warnungen, die funktionieren, wenn bestimmte Schwellenwerte erreicht werden.
Wir haben 992 Warnungen, egal was passiert, wir werden es herausfinden .
Vorfälle

Wir haben PagerDuty - einen Dienst, über den Benachrichtigungen an verantwortliche Personen gesendet werden, die Maßnahmen ergreifen.

In diesem Fall ist ein Fehler bei der Notfallwerbung aufgetreten, und unmittelbar danach wurde eine Warnung aufgezeichnet, dass der Master gefallen ist. Danach überprüfte der Dienstoffizier, was eine Notfallförderung verhinderte, und führte die erforderlichen manuellen Operationen durch.
Wir werden sicherlich jeden aufgetretenen Vorfall analysieren, für jeden Vorfall haben wir eine Aufgabe im Task-Tracker. Selbst wenn dieser Vorfall ein Problem in unseren Warnungen darstellt, erstellen wir auch eine Aufgabe. Wenn das Problem in der Warnungslogik und den Schwellenwerten liegt, müssen diese geändert werden. Warnungen sollten nicht nur das Leben der Menschen verderben. Ein Alarm ist immer schmerzhaft, besonders um 4 Uhr morgens.
Testen
Wie bei der Überwachung bin ich sicher, dass jeder testet. Zusätzlich zu den Komponententests, mit denen wir unseren Code abdecken, haben wir Integrationstests, in denen wir testen:
- alle Topologien, die wir haben;
- alle Operationen auf diesen Topologien.
Wenn wir Beförderungsvorgänge haben, testen wir Beförderungsvorgänge im Integrationstest. Wenn wir klonen, klonen wir für alle Topologien, die wir haben.
Topologiebeispiel
Wir haben Topologien für alle Gelegenheiten: 2 Rechenzentren mit mehreren Instanzen, mit Shards, keine Shards, mit Clustern, ein Rechenzentrum - im Allgemeinen fast jede Topologie - auch solche, die wir nicht verwenden, nur um zu sehen.

In dieser Datei haben wir nur die Einstellungen, welche Server und mit was wir erhöhen müssen. Zum Beispiel müssen wir den Master erhöhen, und wir sagen, dass wir dies mit solchen und solchen Instanzdaten tun müssen, mit solchen und solchen Datenbanken an solchen und solchen Ports. Fast alles passt zusammen mit Bazel, das auf der Grundlage dieser Dateien eine Topologie erstellt, den MySQL-Server startet und dann den Test startet.

Der Test sieht sehr einfach aus: Wir geben an, welche Topologie verwendet wird. In diesem Test testen wir auto_replace.
- Wir erstellen den auto_replace-Dienst und starten ihn.
- Wir töten den Meister in unserer Topologie, warten eine Weile und sehen, dass der Zielsklave Meister geworden ist. Wenn nicht, ist der Test fehlgeschlagen.
Stufen
Bühnenumgebungen sind dieselben Datenbanken wie in der Produktion, es gibt jedoch keinen Benutzerverkehr, aber synthetischen Verkehr, der der Produktion über Percona Playback, Sysbench und ähnliche Systeme ähnelt.
In Percona Playback zeichnen wir Datenverkehr auf, verlieren ihn dann in der Bühnenumgebung mit unterschiedlicher Intensität und können 2-3 mal schneller verlieren. Das heißt, es ist künstlich, aber sehr nahe an der tatsächlichen Last.
Dies ist notwendig, da wir in Integrationstests unsere Produktion nicht testen können. Wir können die Warnung oder die Tatsache, dass Metriken funktionieren, nicht testen. In der Testphase testen wir Warnungen, Metriken und Vorgänge, beenden die Server regelmäßig und stellen sicher, dass sie normal erfasst werden.
Außerdem testen wir die gesamte Automatisierung zusammen, da bei Integrationstests höchstwahrscheinlich ein Teil des Systems getestet wird und beim Staging alle automatisierten Systeme gleichzeitig funktionieren. Manchmal denken Sie, dass sich das System so und nicht anders verhält, aber es kann sich ganz anders verhalten.
DRT (Disaster Recovery Testing)
Wir führen auch Tests in der Produktion durch - direkt auf realen Grundlagen. Dies wird als Disaster Recovery-Test bezeichnet. Warum brauchen wir das?
● Wir möchten unsere Garantien testen.
Dies wird von vielen großen Unternehmen durchgeführt. Zum Beispiel hat Google einen Dienst, der so stabil funktioniert - 100% der Zeit -, dass alle Dienste, die ihn verwendet haben, entschieden haben, dass dieser Dienst wirklich 100% stabil ist und niemals abstürzt. Daher musste Google diesen Dienst absichtlich einstellen, damit die Nutzer diese Möglichkeit berücksichtigen.
Wir sind also - wir haben die Garantie, dass MySQL funktioniert - und manchmal funktioniert es nicht! Und wir haben die Garantie, dass es für einen bestimmten Zeitraum möglicherweise nicht funktioniert. Kunden sollten dies berücksichtigen. Von Zeit zu Zeit töten wir den Produktionsmaster, oder wenn wir einen Faylover machen wollen, töten wir alle Slaves, um zu sehen, wie sich die semisynchrone Replikation verhält.
● Kunden sind auf diese Fehler vorbereitet (Austausch und Tod des Masters)
Warum ist das gut? Wir hatten einen Fall, in dem während der Promotion 4 von 1600 Shards die Verfügbarkeit auf 20% sank. Es scheint, dass etwas nicht stimmt, für 4 Scherben ab 1600 sollte es einige andere Zahlen geben. Failover für dieses System waren selten, etwa einmal im Monat, und alle entschieden: "Nun, es ist ein Failover, es passiert."
Irgendwann, als wir auf ein neues System umgestiegen sind, hat eine Person beschlossen, diese beiden Heartbeat-Aufzeichnungsdienste zu optimieren und zu einem zu kombinieren. Dieser Dienst hat etwas anderes getan und ist am Ende gestorben und der Herzschlag hat aufgehört aufzuzeichnen. So kam es, dass wir für diesen Kunden 8 Faylovers pro Tag hatten. Alles lag - 20% Verfügbarkeit.
Es stellte sich heraus, dass bei diesem Client die Lebensdauer 6 Stunden beträgt. Dementsprechend hatten wir, sobald der Meister starb, alle Verbindungen für weitere 6 Stunden gehalten. Der Pool konnte nicht weiter funktionieren - seine Verbindungen bleiben erhalten, er ist begrenzt und funktioniert nicht. Es wurde repariert.
Wir machen den Feylover wieder - nicht mehr 20%, aber immer noch viel. Irgendwas stimmt immer noch nicht. Es stellte sich heraus, dass ein Fehler in der Implementierung des Pools. Auf Anfrage wandte sich der Pool vielen Scherben zu und verband dies alles. Wenn einige Scherben fieberhaft waren, trat im Go-Code eine Rennbedingung auf, und der gesamte Pool war verstopft. Alle diese Scherben konnten nicht mehr funktionieren.
Disaster Recovery-Tests sind sehr nützlich, da Clients auf diese Fehler vorbereitet sein müssen und ihren Code überprüfen müssen.
● Plus Disaster Recovery-Tests sind gut, da sie während der Geschäftszeiten stattfinden und alles vorhanden ist, weniger Stress, die Leute wissen, was jetzt passieren wird. Das passiert nachts nicht und es ist großartig.
Fazit
1. Alles muss automatisiert werden, niemals in die Hände bekommen.
Jedes Mal, wenn jemand mit unseren Händen in das System steigt, stirbt und bricht alles in unserem System - jedes Mal! - auch bei einfachen Operationen. Zum Beispiel starb ein Sklave, eine Person musste einen zweiten hinzufügen, entschied sich jedoch, den toten Sklaven mit seinen Händen aus der Topologie zu entfernen. Anstelle des Verstorbenen kopierte er jedoch das Kommando live - der Meister blieb überhaupt ohne Sklaven. Solche Operationen sollten nicht manuell durchgeführt werden.
2. Die Tests sollten kontinuierlich und automatisiert (und in der Produktion) sein.
Ihr System ändert sich, Ihre Infrastruktur ändert sich. Wenn Sie einmal nachgesehen haben und es zu funktionieren schien, bedeutet dies nicht, dass es morgen funktionieren wird. Daher müssen Sie jeden Tag, auch in der Produktion, ständig automatisierte Tests durchführen.
3. Stellen Sie sicher, dass Sie Clients (Bibliotheken) besitzen.
Benutzer wissen möglicherweise nicht, wie Datenbanken funktionieren. Sie verstehen möglicherweise nicht, warum Zeitüberschreitungen erforderlich sind, um am Leben zu bleiben. Daher ist es besser, diese Kunden zu besitzen - Sie werden ruhiger sein.
4. Es ist notwendig, Ihre Grundsätze für den Aufbau des Systems und Ihre Garantien festzulegen und diese stets einzuhalten.
Somit können Sie 6.000 Datenbankserver unterstützen.
Bei Fragen nach dem Bericht und insbesondere bei den Antworten darauf gibt es auch viele nützliche Informationen.Fragen und Antworten
- Was passiert, wenn die Last der Shards unausgewogen ist - einige Metainformationen zu einer Datei haben sich als beliebter herausgestellt? Ist es möglich, diese Scherbe zu verbreiten, oder unterscheidet sich die Belastung der Scherben nirgendwo um Größenordnungen?
Sie unterscheidet sich nicht um Größenordnungen. Es ist fast normal verteilt. Wir haben Drosselung, das heißt, wir können den Shard nicht überlasten. Wir drosseln auf Client-Ebene. Im Allgemeinen kommt es vor, dass ein Stern ein Foto hochlädt und die Scherbe praktisch explodiert. Dann verbieten wir diesen Link
- Sie sagten, Sie haben 992 Warnungen. Könnten Sie näher erläutern, was es ist - ist es sofort einsatzbereit oder wurde es erstellt? Wenn erstellt, ist es Handarbeit oder so etwas wie maschinelles Lernen?
Dies wird alles manuell erstellt. Wir haben unser eigenes internes System namens Vortex, in dem Metriken gespeichert und Warnungen darin unterstützt werden. Es gibt eine Yaml-Datei, die besagt, dass beispielsweise eine Bedingung vorliegt, dass Sicherungen jeden Tag ausgeführt werden müssen. Wenn diese Bedingung erfüllt ist, funktioniert die Warnung nicht. Wenn nicht ausgeführt, wird eine Warnung ausgegeben.
Dies ist unsere interne Entwicklung, da nur wenige Personen so viele Metriken speichern können, wie wir benötigen.
- Wie stark müssen die Nerven sein, um DRT zu machen? Du bist gefallen, CODERED, steigt nicht auf, mit jeder Minute Panik mehr.
Im Allgemeinen ist das Arbeiten in Datenbanken wirklich ein Schmerz. Wenn die Datenbank abstürzt, funktioniert der Dienst nicht, die gesamte Dropbox funktioniert nicht. Das ist ein echter Schmerz. DRT ist insofern nützlich, als es eine Geschäftsuhr ist. Das heißt, ich bin bereit, ich sitze an meinem Schreibtisch, ich habe Kaffee getrunken, ich bin frisch, ich bin bereit, alles zu tun.
Schlimmer noch, wenn es um 4 Uhr morgens passiert und es nicht DRT ist. Zum Beispiel der letzte große Fehler, den wir kürzlich hatten. Beim Injizieren eines neuen Systems haben wir vergessen, den OOM-Score für MySQL festzulegen. Es gab einen anderen Dienst, der binlog las. Irgendwann ist unser Bediener manuell - wieder manuell! - führt den Befehl aus, um einige Informationen in der Percona-Prüfsummentabelle zu löschen. Nur ein einfaches Löschen, eine einfache Operation, aber diese Operation erzeugte ein riesiges Binlog. Der Dienst las dieses Binlog in den Speicher, OOM Killer kam und überlegte, wen er töten sollte. Und wir haben vergessen, den OOM-Score festzulegen, und das tötet MySQL!
Wir haben 40 Meister, die um 4 Uhr morgens sterben. Wenn 40 Meister sterben, ist das wirklich sehr beängstigend und gefährlich. DRT ist nicht beängstigend und nicht gefährlich. Wir lagen ungefähr eine Stunde.
DRT ist übrigens eine gute Möglichkeit, solche Momente zu proben, damit wir genau wissen, welche Abfolge von Aktionen erforderlich ist, wenn etwas massenhaft kaputt geht.
- Ich möchte mehr über das Wechseln von Master-Master erfahren. Erstens, warum wird beispielsweise ein Cluster nicht verwendet? Ein Datenbankcluster, dh kein Master-Slave mit Switching, sondern eine Master-Master-Anwendung, sodass es nicht beängstigend ist, wenn einer fällt.
Meinen Sie so etwas wie Gruppenreplikation, Galera-Cluster usw.? Es scheint mir, dass die Gruppenanwendung noch nicht lebensbereit ist. Leider haben wir Galera noch nicht ausprobiert. Dies ist großartig, wenn sich ein Faylover in Ihrem Protokoll befindet, aber leider so viele andere Probleme hat und es nicht so einfach ist, zu dieser Lösung zu wechseln.
- Es scheint, dass es in MySQL 8 so etwas wie einen InnoDb-Cluster gibt. Nicht versucht?
Wir haben noch 5,6 wert. Ich weiß nicht, wann wir zu 8 wechseln werden. Vielleicht versuchen wir es.
- Wenn Sie in diesem Fall einen großen Master haben, stellt sich beim Wechsel von einem zum anderen heraus, dass sich die Warteschlange auf den Slave-Servern mit hoher Last ansammelt. Wenn der Master gelöscht ist, muss die Warteschlange erreicht werden, damit der Slave in den Master-Modus wechselt - oder wird dies irgendwie anders gemacht?
Die Belastung des Masters wird durch Semisync geregelt. Semisync beschränkt die Masteraufzeichnung auf die Leistung des Slave-Servers. Natürlich kann es sein, dass die Transaktion kam, Semisync funktionierte, aber die Slaves haben diese Transaktion für eine sehr lange Zeit verloren. Sie müssen dann warten, bis der Slave diese Transaktion bis zum Ende verliert.
- Aber dann werden neue Daten gemastert, und es wird notwendig sein ...
Wenn wir den Promotionsprozess starten, deaktivieren wir I / O. Danach kann der Master nichts mehr schreiben, da Semisync repliziert wird. Phantomlesung kann leider kommen, aber dies ist bereits ein weiteres Problem.
- Dies sind alles schöne Zustandsautomaten - worauf sind die Skripte geschrieben und wie schwierig ist es, einen neuen Schritt hinzuzufügen? Was muss mit der Person getan werden, die dieses System schreibt?
Alle Skripte sind in Python geschrieben, alle Dienste sind in Go geschrieben. Dies ist unsere Politik. Das Ändern der Logik ist einfach - nur im Python-Code, der das Zustandsdiagramm generiert.
- Und Sie können mehr über das Testen lesen. Wie werden Tests geschrieben, wie werden Knoten in einer virtuellen Maschine bereitgestellt - sind dies Container?
Ja Wir werden mit Hilfe von Bazel testen. Es gibt einige Konfigurationsdateien (json) und Bazel greift auf ein Skript zurück, das mithilfe dieser Konfigurationsdatei die Topologie für unseren Test erstellt. Dort werden verschiedene Topologien beschrieben.
In Docker-Containern funktioniert alles für uns: entweder in CI oder in Devbox. Wir haben ein Devbox-System. Wir entwickeln alle auf einem Remote-Server, und dies kann beispielsweise funktionieren. Dort läuft es auch in Bazel, in einem Docker-Container oder in der Bazel Sandbox. Bazel ist sehr kompliziert, macht aber Spaß.
- Wenn Sie 4 Instanzen auf einem Server erstellt haben, haben Sie an Speichereffizienz verloren?
Jede Instanz ist kleiner geworden. Je weniger Speicher MySQL verwendet, desto einfacher ist es für ihn zu leben. Jedes System ist mit wenig Speicher einfacher zu bedienen. An diesem Ort haben wir nichts verloren. Wir haben die einfachsten C-Gruppen, die diese Instanzen aus dem Speicher beschränken.
- Wenn Sie 6.000 Server haben, auf denen Datenbanken gespeichert sind, können Sie angeben, wie viele Milliarden Petabyte in Ihren Dateien gespeichert sind?
Dies sind Dutzende von Exabytes, wir haben ein Jahr lang Daten von Amazon gegossen.
- Es stellte sich heraus, dass Sie zuerst 8 Server mit 200 Shards und dann 400 Server mit jeweils 4 Shards hatten. Sie haben 1600 Shards - ist das eine Art fest codierter Wert? Schaffst du es nie wieder? Wird es weh tun, wenn Sie zum Beispiel 3.200 Scherben benötigen?
Ja, es war ursprünglich 1600. Dies wurde vor etwas weniger als 10 Jahren getan, und wir leben immer noch. Aber wir haben immer noch 4 Scherben - 4 Mal können wir den Raum noch vergrößern.
- Wie sterben Server hauptsächlich aus welchen Gründen? Was passiert öfter, seltener und es ist besonders interessant, ob spontane Block-Carapters auftreten?
Das Wichtigste ist, dass die Festplatten herausfliegen. Wir haben RAID 0 - die Festplatte ist abgestürzt, der Master ist gestorben. Dies ist das Hauptproblem, aber es ist für uns einfacher, diesen Server zu ersetzen. Google ist einfacher, das Rechenzentrum zu ersetzen, wir haben noch einen Server. Wir hatten fast nie eine Korruptionsprüfsumme. Um ehrlich zu sein, ich erinnere mich nicht, wann es das letzte Mal war. Wir aktualisieren den Assistenten nur oft. Unsere Lebenszeit für einen Meister ist auf 60 Tage begrenzt. Es kann nicht länger leben, danach ersetzen wir es durch einen neuen Server, da sich aus irgendeinem Grund ständig etwas in MySQL ansammelt und nach 60 Tagen Probleme auftreten. Vielleicht nicht in MySQL, vielleicht in Linux.
Wir wissen nicht, was dieses Problem ist, und wir wollen uns nicht damit befassen.
Wir haben die Zeit nur auf 60 Tage begrenzt und den gesamten Stapel aktualisiert. Sie müssen sich nicht an einen Meister halten.— , 6 . , JPEG , JPEG, , ? , , - ? — , ?
, . — Dropbox .
— ? ? , , - , , ? , 10 . , 7 , 6 , . ?
Dropbox - , . . , , , - .
, . , , , . - , 6 , , , , .
, facebook youtube- — Highload++ 2018 . , 1 .