Die Größe von Transistoren in modernen Mikroschaltungen nimmt unaufhaltsam ab - trotz der Tatsache, dass sie seit mehreren Jahren über den Tod von Moores Gesetz sprechen und die physikalische Grenze der Miniaturisierung bereits nahe ist (genauer gesagt, sie wurde an einigen Stellen bereits erfolgreich umgangen). Dieser Rückgang ist jedoch nicht umsonst, und der Appetit der Benutzer wächst schneller als die Fähigkeiten der Chipentwickler. Daher werden neben der Miniaturisierung von Transistoren andere, oft nicht weniger fortschrittliche Technologien verwendet, um moderne mikroelektronische Produkte herzustellen.

In meinem letzten Satz habe ich bewusst den Ausdruck "Mikroelektronikprodukt" anstelle des Wortes "Mikroschaltung" verwendet, da sich dieser Artikel auf die Tatsache konzentriert, dass im CPU- oder GPU-Gehäuse möglicherweise nicht nur ein Kristall, sondern ein ganzes System aus mehreren Chips vorhanden ist und aufgerufen: ein System in einem Paket oder ein System in einem Paket.
Der Begriff „System in einem Fall“ ist viel weniger bekannt als der verwandte Begriff „System auf einem Chip“, den Entwickler gerne mit irgendetwas übertrumpfen. Darüber hinaus ist jetzt fast jeder Chip (mit Ausnahme der einfachsten) irgendwie ein System auf einem Chip, und die Zeiten der Mikroprozessorsätze und sogar einzelner Chips der Süd- und Nordbrücken gehören der Vergangenheit an. Die Vorteile von Systemen auf einem Chip liegen auf der Hand: weniger Gehäuse auf der Platine, weniger Fläche (was billiger bedeutet), weniger Streuinduktivitäten und Kapazitäten (was bedeutet, dass das Produkt besser und schneller arbeitet), einfacher für den Benutzer (es ist bequemer zu implementieren und weniger Platz für Fehler). billiger in der Produktion (anstelle mehrerer spezialisierter Mikroschaltungen kann eine weitere universelle hergestellt werden).
Systeme auf einem Chip haben aber auch ihre Tücken.
Erstens, wenn Sie versuchen, alles auf einmal auf einen Kristall zu schieben, laufen Sie Gefahr, einen Chip von einer solchen Größe (und mit so vielen Beinen) zu bekommen, dass er auf keinen Fall passt. Darüber hinaus besteht (wie ein professioneller Technologe in den Kommentaren vorschlägt) die Gefahr, dass ein sehr großer Chip nicht in die Größe des Feldes des photolithografischen Scanners gelangt. Sie können diese Einschränkung umgehen, aber es ist technisch sehr schwierig und dementsprechend sehr teuer.
Zweitens ist der Prozentsatz der Ausbeute umso geringer, je größer der Chip ist, insbesondere wenn Sie für die Produktion mehrere Fenster auf einer Fotomaske zusammennähen müssen. Und das wirkt sich natürlich auch auf die Kosten aus.
Drittens, wenn Ihr System aus heterogenen Komponenten besteht, kann es für die Qualität des Systems zu schwierig, zu teuer oder zu schlecht sein, sie alle auf einem Chip zu kombinieren. Zum Beispiel benötigt DRAM spezielle Kondensatoren, deren Hinzufügen zu einem „normalen“ Herstellungsprozess für das Werk unangemessen teuer sein kann (was aus diesem Grund zu Preiserhöhungen für Kunden führen wird). Hochfrequenz- oder Leistungskomponenten auf Silizium können erheblich schlechtere Parameter aufweisen als auf A3B5-Materialien (Galliumarsenid und seine Analoga), und die Verbindung der digitalen und analogen Teile auf demselben Kristall verursacht ein Rauschproblem.
Die Kombination aller oben genannten Faktoren hat dazu geführt, dass der Trend „Alles auf einen Kristall setzen“ durch einen ausgewogeneren Ansatz sowie die rasche Entwicklung von Technologien zum Verpacken von Kristallen in einem Fall ersetzt wurde.
Leistung und Ertrag
Das erste Beispiel, das mir in den Sinn kommt, sind natürlich AMD-Mikroprozessoren (siehe KDPV). Systeme für Multi-Core-Produkte gelten als einer der wichtigsten Gründe für den jüngsten Aufstieg des Unternehmens, der vor dem Hintergrund von Intel-Problemen bei der Einführung eines neuen technischen Prozesses aufgrund der geringen Ausbeute an riesigen Chips stattfindet.

Die Abbildung zeigt einen 28-Kern Intel Xeon Chip. Die Größe dieser Prozessoren erreicht verrückte 456 Quadratmillimeter, während die AMD-Chipgrenze für einen Achtkernchip etwa 200 Quadratmillimeter beträgt und Produkte mit mehr Kernen aus mehreren identischen Kristallen auf einer zweischichtigen Leiterplatte im Prozessorgehäuse zusammengesetzt werden.

In dieser Abbildung sehen Sie das Design der Platine im Gehäuse der EPYC- und Threadripper-Prozessoren (auch bekannt als KDPV). Vier Achtkernkristalle befinden sich auf einer zweischichtigen Platte. Im Fall von Threadripper mit der Hälfte der deaktivierten Kerne. Warum werden Kristalle so irrational verwendet?
Erstens kann die Herstellung eines Kristalltyps billiger sein als mehrere verschiedene.
Zweitens gilt das Gleiche für den Rest des Kabelbaums. Eine unnötige Deaktivierung kann billiger und technologischer sein als die Entwicklung und Herstellung mehrerer verschiedener Modelle.
Drittens ist der Prozentsatz der Ausbeute, der für einen 200-Millimeter-Chip geeignet ist, höchstwahrscheinlich auch nicht ideal, und eine solche Konstruktion des Endprodukts ermöglicht die Verwendung von Kristallen, in denen nicht alle Kerne arbeiten. Intel macht genau das Gleiche, aber ihre Ausgabeprobleme sind aufgrund größerer Kristalle viel stärker.

Und hier ist ein noch interessanteres Beispiel, auch von AMD. AMD Fiji ist eine GPU mit integriertem Hochgeschwindigkeitsspeicher direkt im Gehäuse. Warum ist das wichtig? Weil viel kürzere Leitungen vom Prozessor zum Speicher hohe Geschwindigkeiten und damit eine höhere Leistung ermöglichen. Im Gegensatz zum vorherigen Beispiel sind die Kristalle im Gehäuse unterschiedlich. Darüber hinaus gibt es nicht fünf, wie es auf den ersten Blick scheinen mag, sondern viel mehr - zweiundzwanzig. Hier ist ein Abschnitt der Struktur:
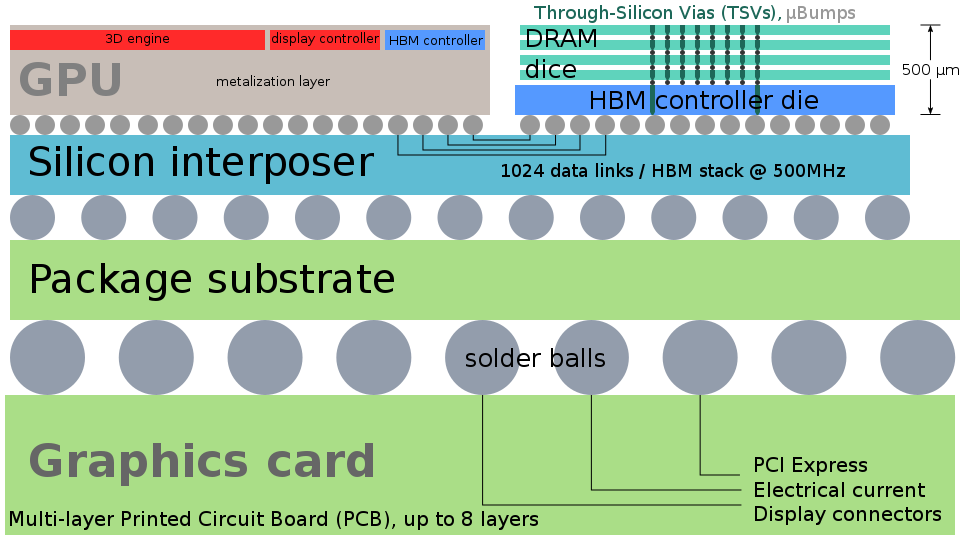
Die oberste Schicht ist der GPU-Chip selbst und das „Regal“ mehrerer (in diesem Fall vier) Speicherchips, die mit TSV (Through-Silicon-Via) verbunden sind - leitenden Säulen, die den Kristall bis zur gesamten Dicke durchlaufen.
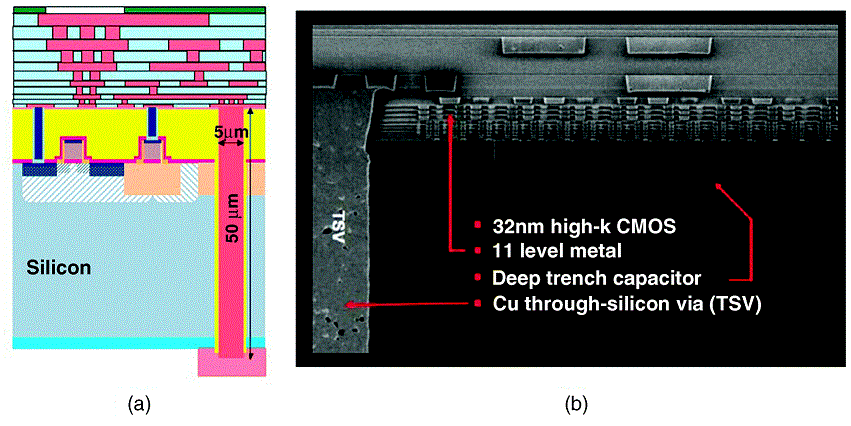
TSVs sehen ungefähr so aus, schematisch und in realem Maßstab.
Die TSV-Technologie, die ursprünglich nur für Speicher-Arrays gedacht war (schließlich gibt es nie zu viel Speicher, oder?), Wird jetzt immer weiter verbreitet, auch dank des nächsten Chips unter der GPU und dem Speicher.
Silicon Interposer ist ein Ersatz für eine mehrschichtige Leiterplatte aus einem Siliziumkristall, die mehrere Metallisierungs- und TSV-Schichten zum Verbinden der Chips oben und des Gehäuses enthält. Die Verwendung von Silizium ermöglicht es, wesentlich kleinere Elementgrößen (Einheiten von Mikrometern) als eine Leiterplatte zu erhalten, gleichzeitig können die Entwurfsstandards jedoch grob genug sein, so dass dieser Verbindungschip eine hohe Ausbeute und einen erschwinglichen Preis aufweist. Die kleineren Abmessungen der Elemente bedeuten einen geringeren Einfluss der parasitären Parameter der Verbindungen, und die bereits erwähnten TSVs sind viel kompakter als die Durchkontaktierungen auf der Leiterplatte und ermöglichen den Transport von Hunderten oder sogar Tausenden von Kontakten durch den Interposer zum Gehäuse. Zusammen mit MEMS sind solche Verbindungschips ein wichtiger neuer Markt für veraltete Fabriken mit Wafern mit einem Durchmesser von 100 bis 150 Millimetern.
Ein weiterer Pionier der 3D-Integration ist Xilinx. Technologisch gesehen ähneln die FPGAs AMD-Produkten (insbesondere solchen mit integriertem Speicher), und auch die Motive sind ähnlich: FPGAs sind eine Marktnische, in der ein frühzeitiger Übergang zu einem neuen Herstellungsverfahren einen ernsthaften Vorteil gegenüber Wettbewerbern bieten kann. Nach verschiedenen Schätzungen kann in einem frühen Stadium der Lebensdauer einer Technologie eine drei- bis vierfache Reduzierung der Kristallgröße die Ausbeute um das Zwei- bis Dreifache von einigen zehn Prozent auf mehr als die Hälfte erhöhen. Darüber hinaus sind FPGAs eine reguläre Struktur, auf der es zweckmäßig ist, technologische Defekte zu verfolgen. Daher sind FPGA-Hersteller typische „Erstkunden“ für neue Herstellungsverfahren, und Xilinx kann aufgrund der Tatsache, dass ihre Produkte mehrere kleine Kristalle anstelle eines in voller Größe enthalten, neue Modelle mehrere Monate schneller als die Konkurrenz auf den Markt bringen.

Hier ist ein Querschnitt der Innenseiten des Xilinx FPGA. Der obere Chip ist eigentlich ein Teil des FPGA mit sehr kleinen Kontakten (40-45 Mikrometer) zum Interposer, die mehrere Chips miteinander verbinden, und am Boden befindet sich die Basis des Gehäuses, das ein Dutzend Schichten seiner eigenen Metallverbindungen aufweist.

Zum Vergleich - FPGA Altera auf einem riesigen Kristall. Fünfhundertsechzig Quadratmillimeter, Carl! Wenn dieser Beitrag plötzlich von mikroelektronischen Produktionstechnologen gelesen wird, stellen Sie sicher, dass sie keinen Herzinfarkt haben.
Intel / Altera sitzt natürlich nicht still und beobachtet den Erfolg der Wettbewerber. Ihre neueste Entwicklung bei geschlossenen Systemen ist die Embedded Multi-Chip Interconnect Bridge (EMIB). Es ist praktisch, es mit dem Intel Stratix 10 FPGA zu betrachten.
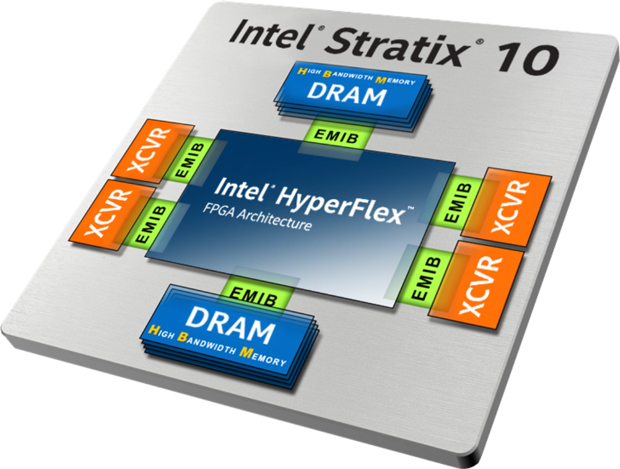
Wie Sie sehen können, verbindet EMIB (einen!) FPGA-Chip, Speicher (und hier mehrstöckige Strukturen) und periphere Kristalle. Was ist das EMIB? Etwas höher schrieb ich über Silizium-Interposer, dass es aufgrund eines härteren technischen Prozesses einen viel niedrigeren Preis hat als ein Chip ähnlicher Größe, der mit dünner Technologie hergestellt wurde. Trotzdem ist der Interposer riesig. Ist es möglich, es kleiner zu machen?
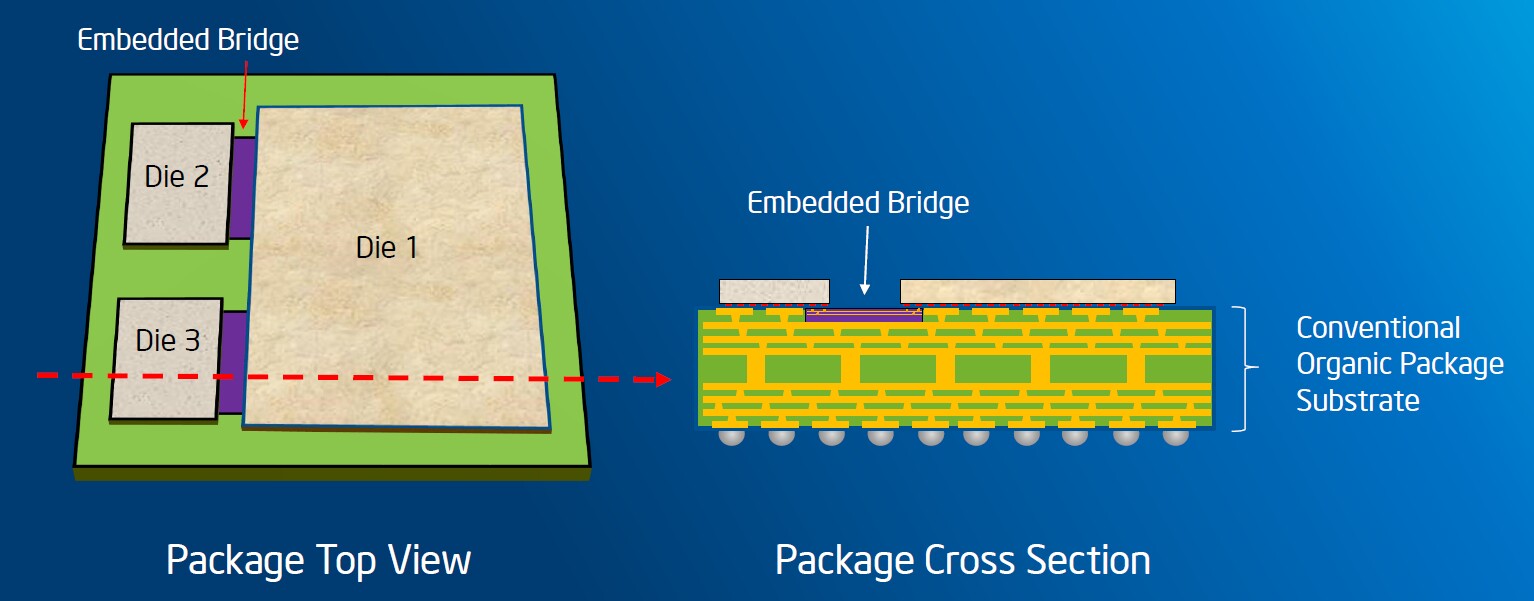
Intels Antwort lautet ja. Die Idee von EMIB ist es, mehrere kleine anstelle eines großen Interposers zu verwenden und diese wiederum direkt in das Körpersubstrat zu integrieren.
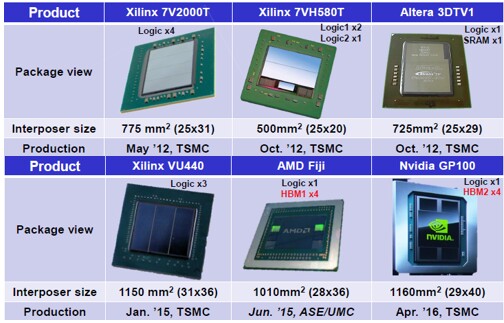
Hier ist eine kleine Auswahl von Produkten, die mit Silizium-Interposern hergestellt wurden. Achten Sie auf ihre kolossalen Dimensionen nach mikroelektronischen Maßstäben und auf die Tatsache, dass die Kampfchips von Xilinx, wie oben erläutert, in mehrere kleine Teile unterteilt sind.
Mehr als nur Leistung.
Die folgende Abbildung zeigt das Innere eines ADC-Gehäuses und eines Schaltplans für analoge Geräte. Es sieht aus wie eine ganz normale Leiterplatte für den ADC, nur kleiner, oder? Das ist richtig, das ist es, nur aufgrund der Verwendung von Open-Frame-Komponenten wurden die mit falschen Elementen verbundenen Fehler reduziert, und die Tatsache, dass die Karte in Analog Devices entwickelt wurde, ermöglicht es ihnen, viel Zeit für den Kunden zu sparen und gleichzeitig sicherzustellen, dass der Benutzer nicht durch die Auswahl der falschen Fehler durcheinander kommt Komponenten oder schlecht verdrahtete Platine.

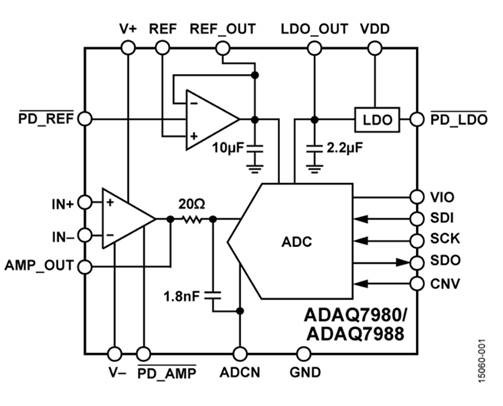
In der obigen Abbildung gibt es jedoch einen kleinen Trick: Sehen Sie Kristalle auf zwei Etagen? Der obere Kristall ist ein Chip mit den aktiven Komponenten des ADC selbst und (anscheinend) einem doppelten Operationsverstärker, und der untere Kristall ist die passiven Komponenten (Kondensatoren und Widerstände). Durch die Ausführung auf einem separaten Kristall können Sie diese viel größer machen (und damit Fehler reduzieren), ohne den Hauptkristall zu erhöhen (und damit die Kosten dafür zu erhöhen).
Das Gleiche kann auf einem Chip durchgeführt werden (was in der Tat nicht ungewöhnlich ist, insbesondere bei in Mikrocontrollern eingebauten ADCs), aber ein solcher Chip ist viel größer (was bedeutet, wie wir herausgefunden haben, besteht das Risiko, den Prozentsatz der Verwendbarkeit zu verringern) Die Technologie für ihn muss alle notwendigen zusätzlichen Optionen unterstützen. Darüber hinaus führt die Kombination verschiedener Blöcke auf demselben Kristall dazu, dass sichergestellt werden muss, dass sie sich nicht gegenseitig beeinflussen (z. B. Rauschen auf dem Kristallsubstrat irgendwie beseitigen).
Zusätzliche Gehäusefunktionen
Wie wir bereits herausgefunden haben, können Sie durch Verpacken unterschiedlicher Elemente (einschließlich passiver SMD-Komponenten) in einem Gehäuse die Abmessungen des Endprodukts erheblich reduzieren und sogar dessen Geschwindigkeit erhöhen. Was aber, wenn wir das Gehäuse selbst als Funktionselement des Geräts verwenden?
Im Jahr 2013 implementierten Intel-Prozessoren (Haswell Microarchitecture) einen integrierten Spannungsregler (FIVR), bei dem der aktive Teil des Reglers auf dem Prozessorchip implementiert und der passive Teil (Kondensatoren und Induktivitäten) in das Gehäuse integriert wurde.
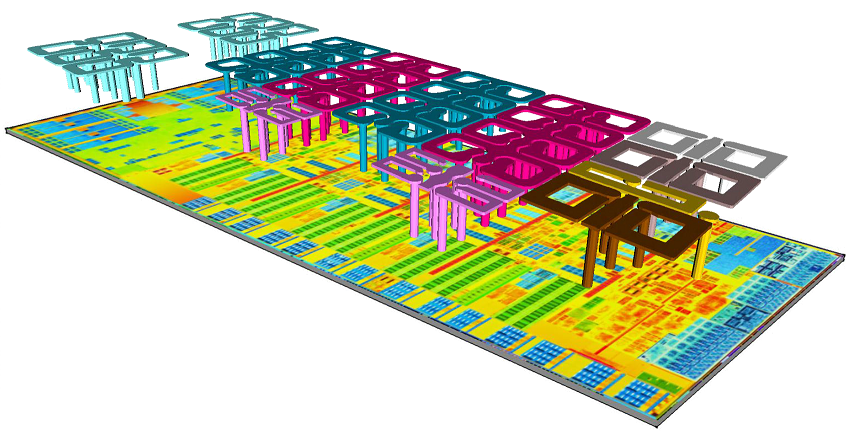
Die integrale Induktivität bereitet allen Chipentwicklern Kopfschmerzen, da die Spulen auf dem Chip nicht nur mit den besten, sondern auch mit den großen Parametern erhalten werden (was bedeutet, dass sie insbesondere bei dünnen Technologien sehr teuer sind). Und hier geht es um Signalspulen ohne Kern, von Stromübertragung ist überhaupt keine Rede. Intel hat dieses Problem erfolgreich umgangen, indem Dutzende paralleler kleiner Spulen mit einer Frequenz von 160 MHz in das Mikroprozessorgehäuse integriert wurden. So konnten sie den Strombedarf des Mikroprozessors deutlich vereinfachen.
Bei dieser Entwicklung ist jedoch etwas schiefgegangen, und in der nächsten Generation von Haswell-Prozessoren gab es keine Intel FIVR-Prozessoren mehr. Seitdem gab es Gerüchte, dass sie zum FIVR zurückkehren werden, aber bisher sind sie Gerüchte geblieben.
Aber auch ohne Intel entwickelt sich die Integrationsrichtung der passiven Komponenten in dem Fall aktiv, beispielsweise in Fällen vom Typ LTCC (Niedertemperaturkeramik). Dort gibt es natürlich Einschränkungen und Fallstricke (zum Beispiel im Zusammenhang mit der Genauigkeit der Bewertungen), aber diese Technologie ist gefragt und entwickelt sich aktiv weiter. Das geschichtete LTCC-Gehäuse sieht ungefähr so aus:
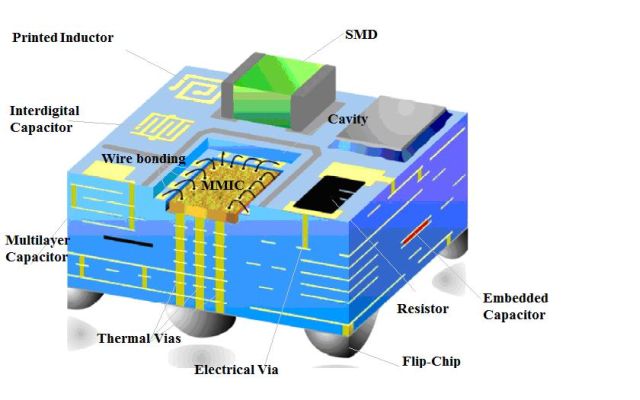
Die Abbildung zeigt alle Arten von passiven Elementen aus mehrschichtiger Keramik und sogar einen Metallkühlkörper (dies ist bei einer leistungsstarken Mikrowellenschaltung der Fall). Tatsächlich ist es eine Mischung des Gehäuses mit einer Keramikplatine. Solche Teile sind bei HF-Modulen sehr beliebt und auch in der Kleinserienproduktion relativ billig.
Was sonst?
In diesem Fall gibt es viele potenzielle Anwendungen für Systeme, und es ist fast unmöglich, alle aufzulisten. Darüber hinaus taucht ständig etwas Neues auf, auch aufgrund der Tatsache, dass diese Technologien viel günstiger sind als 10-7-5-3-Nanometer-Transistoren.
Ein gutes Beispiel für die neuen Anwendungen und Eigenschaften, die die Integration heterogener Chips in einem Gehäuse eröffnet, sind verschiedene optische Systeme, mit denen Sie mit SiP einen Empfänger oder Emitter (normalerweise nicht auf Silizium hergestellt) sowie deren Stromversorgungs- und Steuerschaltungen zusammenbauen können. In der folgenden Abbildung - ein Prototyp einer optischen Verbindung mit 400 Gbit / s (und Versprechen vor Terabit), zusammengestellt am belgischen Forschungsinstitut IMEC.

Darüber hinaus berücksichtigen solche vielversprechenden Anwendungen für Systeme im Fall beispielsweise Interpozers mit eingebauten Kapillaren für die Flüssigkeitskühlung (nicht nur Spielprozessoren, sondern auch Power Keys und Laser), integrierte MEMS-Einheiten im Fall und vieles mehr nicht in den engen Rahmen von Moores Gesetz fallen. Darüber hinaus wird das allgegenwärtige Internet der Dinge als wichtiger Markt für Systeme angesehen, wenn kleine Größen, das Fehlen von Verlusten (hauptsächlich Energie, nicht Zeit) bei Störelementen und die Fähigkeit, passive Komponenten, beispielsweise Teile des Funkwegs, in die Mikroschaltung zu integrieren, wichtig sind.