
Wir in der Analytics-Abteilung des Online-Kinos Okko lieben es, die Berechnung der Filmgebühren von Alexander Nevsky so weit wie möglich zu automatisieren und in der Freizeit neue Dinge zu lernen und coole Dinge zu implementieren, die sich aus irgendeinem Grund normalerweise in Bots für Telegram umsetzen. Zum Beispiel haben wir vor dem Start der FIFA Fussball-Weltmeisterschaft 2018 einen Bot für den Arbeitschat ausgerollt, der Wetten auf die Verteilung der endgültigen Plätze sammelte, und nach dem Finale haben wir die Ergebnisse anhand einer vorab erfundenen Metrik berechnet und die Gewinner ermittelt. Kroatien hat nicht vier unter die ersten vier gesetzt.
In der letzten Freizeit, in der wir die russischen TOP-10-Komödien zusammengestellt haben, haben wir uns der Erstellung eines Bots gewidmet , der eine Berühmtheit findet, nach der der Benutzer am meisten aussieht. Im Arbeitschat schätzten alle die Idee so sehr, dass wir beschlossen, den Bot öffentlich zugänglich zu machen. In diesem Artikel erinnern wir uns kurz an die Theorie, sprechen über die Erstellung unseres Bots und wie man es selbst macht.
Ein bisschen Theorie (meistens in Bildern)
In einem meiner vorherigen Artikel habe ich ausführlich darüber gesprochen, wie Gesichtserkennungssysteme angeordnet sind. Ein interessierter Leser kann dem Link folgen, und ich werde im Folgenden nur die Hauptpunkte skizzieren.
Sie haben also ein Foto, auf dem vielleicht sogar ein Gesicht gezeigt wird, und Sie möchten verstehen, wer es ist. Dazu müssen Sie 4 einfache Schritte ausführen:
- Wählen Sie das Rechteck aus, das an das Gesicht grenzt.
- Markieren Sie wichtige Punkte des Gesichts.
- Richten Sie Ihr Gesicht aus und beschneiden Sie es.
- Konvertieren Sie ein Gesichtsbild in eine maschinell interpretierte Darstellung.
- Vergleichen Sie diese Ansicht mit anderen, die Sie zur Verfügung haben.
Gesichtsauswahl
Obwohl Faltungs-Neuronale Netze in letzter Zeit gelernt haben, Gesichter in Bildern nicht schlechter als klassische Methoden zu finden, sind sie dem klassischen HOG in Bezug auf Geschwindigkeit und Benutzerfreundlichkeit immer noch unterlegen.
HOG - Histogramme orientierter Gradienten. Dieser Typ ordnet jedes Pixel des Quellbildes seinem Gradienten zu - einem Vektor, in dessen Richtung sich die Helligkeit der Pixel am meisten ändert. Der Vorteil dieses Ansatzes besteht darin, dass die absoluten Werte der Helligkeit der Pixel nicht berücksichtigt werden, sondern nur deren Verhältnis ausreicht. Daher wird ein normales, abgedunkeltes, schlecht beleuchtetes und verrauschtes Gesicht in ungefähr demselben Verlaufshistogramm angezeigt.
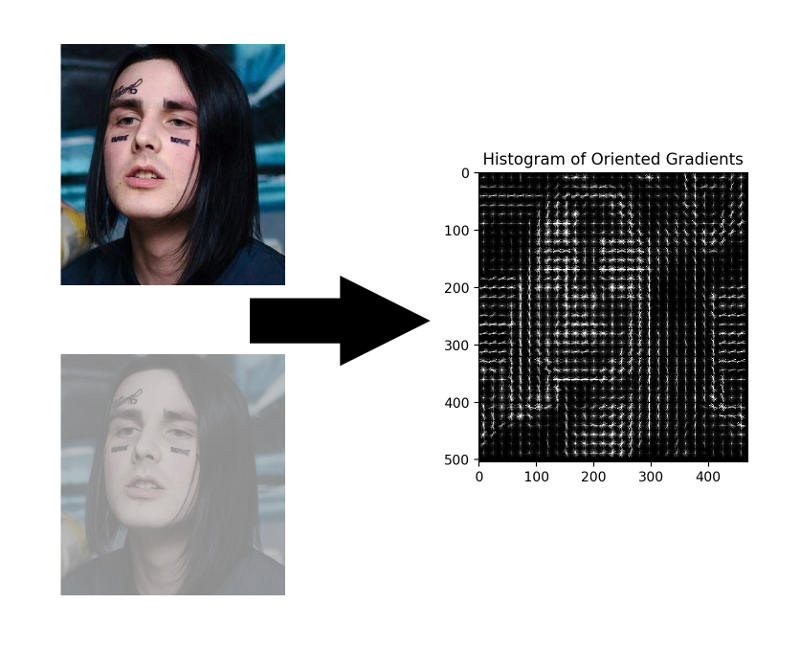
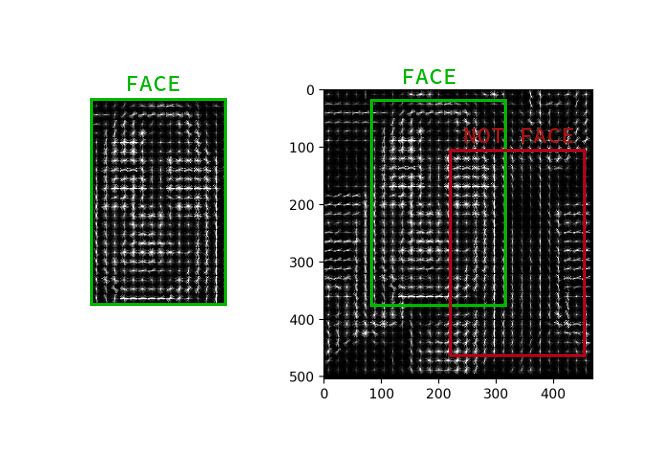
Es ist nicht notwendig, den Gradienten für jedes Pixel zu berechnen, es reicht aus, den durchschnittlichen Gradienten für jedes kleine Quadrat n mal n zu berechnen. Mithilfe des empfangenen Vektorfelds können Sie dann durch einen Detektor mit einem Fenster gehen und für jedes Fenster bestimmen, wie wahrscheinlich das Gesicht darin ist. Der Detektor kann SVM, eine zufällige Gesamtstruktur oder etwas anderes sein.
Markieren Sie wichtige Punkte

Schlüsselpunkte sind Punkte, die helfen, eine Person im Raum zu identifizieren. Schwache und unsichere Wissenschaftler benötigen in der Regel 68 Schlüsselpunkte und in besonders vernachlässigten Fällen sogar noch mehr. Normale und selbstbewusste Jungen, die 300.000 pro Sekunde verdienten, hatten immer genug von fünf: die inneren und äußeren Augen- und Nasenwinkel.
Solche Punkte können beispielsweise durch eine Kaskade von Regressoren extrahiert werden.
Gesichtsausrichtung
Geklebte Anwendungen in der Kindheit? Hier ist alles genau gleich: Sie erstellen eine affine Transformation, die drei beliebige Punkte in ihre Standardpositionen übersetzt. Die Nase kann so gelassen werden, wie sie ist, aber damit die Augen ihre Zentren zählen können - das sind die drei Punkte, die bereit sind.

Konvertieren Sie Gesichtsbilder in Vektoren

Drei Jahre sind seit der Veröffentlichung des Artikels über FaceNet vergangen . In dieser Zeit erschienen viele interessante Trainingsschemata und Verlustfunktionen, aber sie ist es, die unter den verfügbaren OpenSource-Lösungen dominiert. Anscheinend ist das Ganze eine Kombination aus leichtem Verständnis, Implementierung und anständigen Ergebnissen. Vielen Dank zumindest für die Tatsache, dass die Architektur in den letzten drei Jahren auf ResNet geändert wurde.
FaceNet lernt aus dreifachen Beispielen: (Anker, positiv, negativ). Anker- und Positivbeispiele gehören einer Person, während Negativ als Gesicht einer anderen Person gewählt wird, was aus irgendeinem Grund dem Netzwerk zu nahe an der ersten liegt. Die Verlustfunktion ist so konzipiert, dass dieses Missverständnis korrigiert, die notwendigen Beispiele zusammengeführt und das Unnötige daraus entfernt werden.

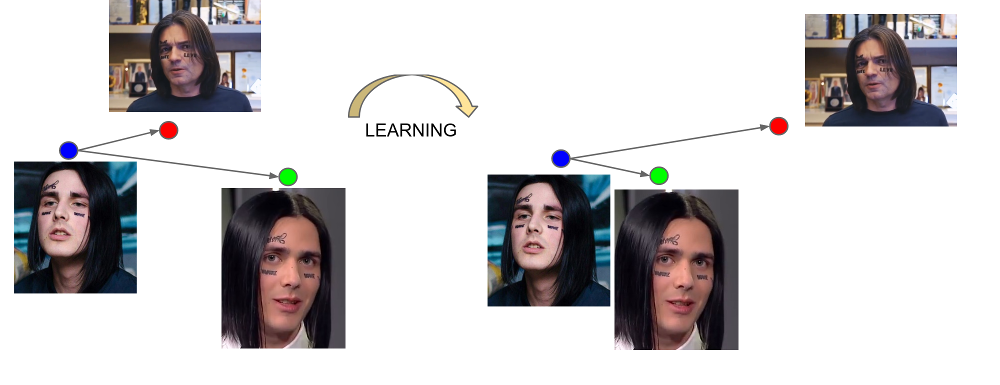
Die Ausgabe der letzten Schicht des Netzwerks wird als Einbettung bezeichnet - eine repräsentative Darstellung einer Person in einem bestimmten Raum kleiner Dimension (normalerweise 128-dimensional).
Gesichtsvergleich
Das Schöne an gut ausgebildeten Einbettungen ist, dass die Gesichter einer Person in einem kleinen Raumviertel angezeigt werden, das von den Einbettungen der Gesichter anderer Personen entfernt ist. Für diesen Raum können Sie also ein Ähnlichkeitsmaß eingeben, den Kehrwert der Entfernung: Euklidisch oder Kosinus, je nachdem, über welche Entfernung das Netzwerk trainiert wurde.
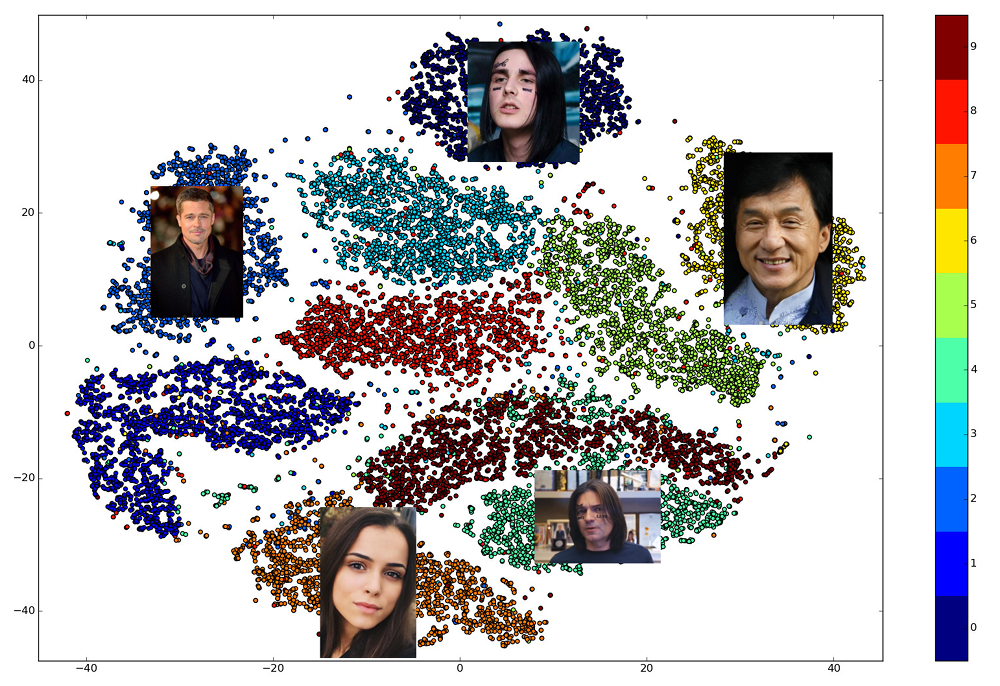
Daher müssen wir im Voraus Einbettungen für alle Personen erstellen, unter denen die Suche durchgeführt wird, und dann für jede Anforderung den nächsten Vektor unter ihnen finden. Oder lösen Sie auf andere Weise das Problem, k nächste Nachbarn zu finden, wobei k gleich eins sein kann oder nicht, wenn wir eine fortgeschrittenere Geschäftslogik verwenden möchten. Die Person, die den Ergebnisvektor besitzt, ist der anfordernden Person am ähnlichsten.

Welche Bibliothek soll ich benutzen?
Die Auswahl an offenen Bibliotheken, die verschiedene Teile der Pipeline implementieren, ist großartig. dlib und OpenCV können Gesichter und wichtige Punkte finden, und vorab trainierte Versionen von Netzwerken können für jedes große neuronale Netzwerk-Framework gefunden werden. Es gibt ein OpenFace- Projekt, in dem Sie die Architektur für Ihre Anforderungen an Geschwindigkeit und Qualität auswählen können. Mit nur einer Bibliothek können Sie jedoch alle 5 Punkte der Gesichtserkennung in Aufrufen von drei Funktionen auf hoher Ebene dlib : dlib . Gleichzeitig ist es in modernem C ++ geschrieben, verwendet BLAS, hat einen Wrapper für Python, benötigt keine GPU und arbeitet recht schnell auf einer CPU. Unsere Wahl fiel auf sie.
Mach deinen eigenen Bot
Dieser Abschnitt wurde bereits in buchstäblich jeder Anleitung zum Erstellen von Bots beschrieben, aber sobald wir dasselbe schreiben, müssen wir es wiederholen. Wir schreiben @BotFather und bitten ihn um ein Token für unseren neuen Bot.
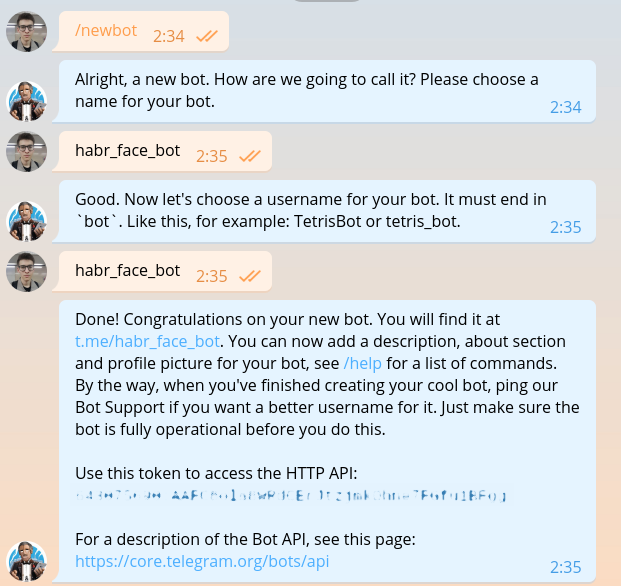
Das Token sieht 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg so aus: 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg . Bei jeder Anforderung an die Telegramm-Bot-API ist eine Autorisierung erforderlich.
Ich hoffe, dass derzeit niemand Zweifel an der Auswahl einer Programmiersprache hat. Natürlich muss man in Haskell schreiben. Beginnen wir mit dem Hauptmodul.
import System.Process main :: IO () main = do (_, _, _, handle) <- createProcess (shell "python bot.py") _ <- waitForProcess handle putStrLn "Done!"
Wie Sie dem Code entnehmen können, werden wir in Zukunft ein spezielles DSL verwenden , um Telegramm-Bots zu schreiben. Der Code in diesem DSL wird in separaten Dateien geschrieben. Installieren Sie die Domain-Sprache und alles Notwendige.
python -m venv .env source .env/bin/activate pip install python-telegram-bot
python-telegram-bot ist derzeit das bequemste Framework zum Erstellen von Bots. Es ist leicht zu erlernen, flexibel, skalierbar und unterstützt Multithreading. Leider gibt es im Moment kein einziges normales asynchrones Framework und es müssen alte Threads anstelle der göttlichen Coroutinen verwendet werden.

Das Starten eines Bots mit python-telegram-bot ist einfach. Fügen Sie den folgenden Code zu bot.py
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
Führen Sie den Bot aus. Zu Debugging-Zwecken kann dies mit dem python bot.py ohne dass Haskell-Code ausgeführt wird.
Solch ein einfacher Bot ist in der Lage, ein Minimum an Konversation aufrechtzuerhalten, und kann daher leicht so arrangiert werden, dass er als Front-End-Entwickler arbeitet.
Das Frontend der Entwickler ist jedoch bereits zu umfangreich. Daher werden wir es so schnell wie möglich beenden und die Hauptfunktionalität implementieren. Der Einfachheit halber antwortet unser Bot nur auf Nachrichten mit Fotos und ignoriert alle anderen. Ändern Sie den Code wie folgt.
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
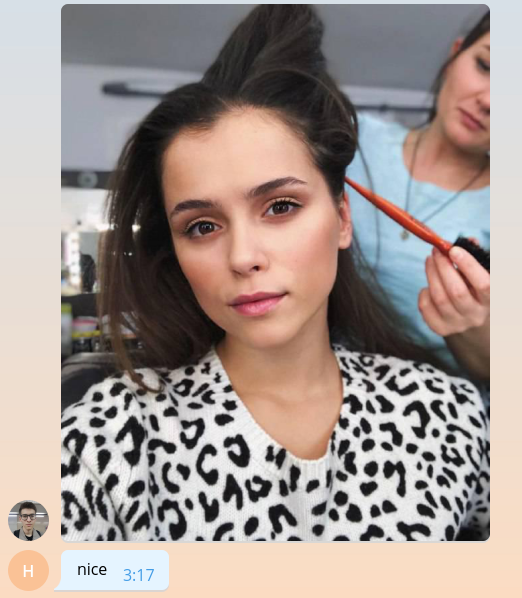
Wenn das Bild in den Telegrammserver eingeht, wird es automatisch auf mehrere vorgegebene Größen angepasst. Der Bot kann seinerseits ein Bild beliebiger Größe von den in der message.photo Liste enthaltenen message.photo die in aufsteigender Reihenfolge sortiert sind. Die einfachste Option: Nehmen Sie das größte Bild auf. In einer Lebensmittelumgebung müssen Sie natürlich über die Netzwerklast und die Ladezeit nachdenken und ein Bild mit der minimal geeigneten Größe auswählen. Fügen Sie den Bild-Download-Code oben in der Funktion handle_photo .
import io
message = update.message photo = message.photo[~0] with io.BytesIO() as fd: file_id = bot.get_file(photo.file_id) file_id.download(out=fd) fd.seek(0)
Das Bild wurde heruntergeladen und befindet sich im Speicher. Um es zu interpretieren und in Form einer Matrix mit numpy , verwenden wir die Bibliotheken Pillow und numpy .
from PIL import Image import numpy as np
Der folgende Code muss dem with Block hinzugefügt werden.
image = Image.open(fd) image.load() image = np.asarray(image)
Die Zeit ist gekommen, dlib. Erstellen Sie außerhalb der Funktion einen Gesichtsdetektor.
import dlib
face_detector = dlib.get_frontal_face_detector()
Und innerhalb der Funktion verwenden wir es.
face_detects = face_detector(image, 1)
Der zweite Parameter der Funktion bezeichnet die Vergrößerung, die angewendet werden muss, bevor versucht wird, Gesichter zu erkennen. Je größer es ist, desto kleiner und komplexer kann der Detektor erkennen, aber desto länger arbeitet er. face_detects - Eine Liste von Gesichtern, sortiert in absteigender Reihenfolge des Vertrauens des Detektors, dass sich das Gesicht davor befindet. In einer realen Anwendung möchten Sie höchstwahrscheinlich eine Logik für die Auswahl der Hauptperson anwenden, und in der Fallstudie beschränken wir uns auf die Auswahl der ersten Person.
if not face_detects: bot.send_message(chat_id=update.message.chat_id, text='no faces') face = face_detects[0]
Wir fahren mit der nächsten Stufe fort - der Suche nach Schlüsselpunkten. Laden Sie das trainierte Modell herunter und bewegen Sie seine Last außerhalb der Funktion.
shape_predictor = dlib.shape_predictor('path/to/shape_predictor_5_face_landmarks.dat')
Finden Sie die wichtigsten Punkte.
landmarks = shape_predictor(image, face)
Das einzige, was noch übrig ist, ist klein: Um das Gesicht zu begradigen, fahren Sie es durch ResNet und erhalten Sie eine 128-dimensionale Einbettung. Glücklicherweise können Sie mit dlib all dies mit einem Anruf erledigen. Sie müssen nur das vorgefertigte Modell herunterladen.
face_recognition_model = dlib.face_recognition_model_v1('path/to/dlib_face_recognition_resnet_model_v1.dat')
embedding = face_recognition_model.compute_face_descriptor(image, landmarks) embedding = np.asarray(embedding)
Schau dir nur an, in was für einer wundervollen Zeit wir leben. Die gesamte Komplexität von Faltungs-Neuronalen Netzen, die Unterstützungsvektormethode und affine Transformationen, die auf die Gesichtserkennung angewendet werden, sind in drei Bibliotheksaufrufen zusammengefasst.
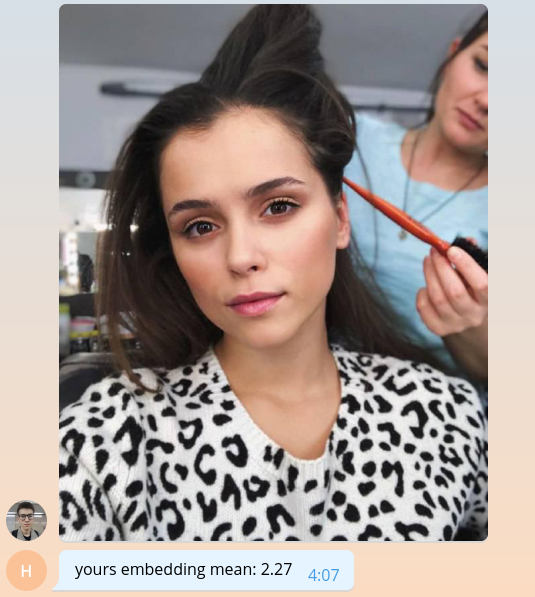
Da wir noch nicht wissen, wie man etwas Sinnvolles macht, geben wir dem Benutzer den Durchschnittswert seiner Einbettung multipliziert mit tausend zurück.
bot.send_message( chat_id=update.message.chat_id, text=f'yours embedding mean: {embedding.mean() * 1e3:.2f}' )
Damit unser Bot bestimmen kann, wie die Prominenten der Benutzer sind, müssen wir jetzt mindestens ein Foto von jedem Prominenten finden, eine Einbettung darauf erstellen und es irgendwo speichern. Wir werden unserem Trainingsbot nur 10 Prominente hinzufügen, deren Fotos von Hand finden und in das photos . So sollte es aussehen:
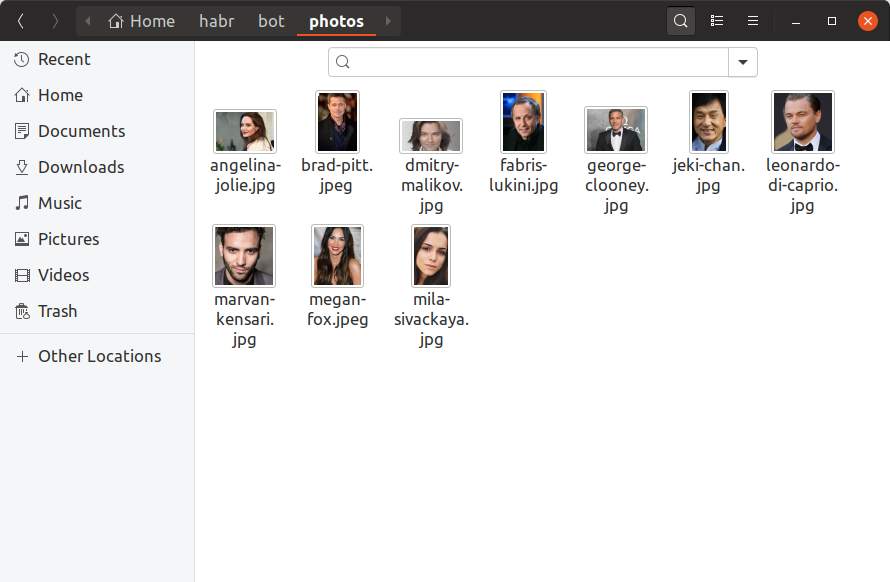
Wenn Sie eine Million Prominente in der Datenbank haben möchten, sieht alles genau gleich aus, nur gibt es mehr Dateien und es ist unwahrscheinlich, dass Sie sie mit Ihren Händen suchen können. Erstellen build_embeddings.py Dienstprogramm build_embeddings.py mit den bereits bekannten dlib Aufrufen und speichern die Einbettungen von Prominenten zusammen mit ihren Namen im Binärformat.
import os import dlib import numpy as np import pickle from PIL import Image face_detector = dlib.get_frontal_face_detector() shape_predictor = dlib.shape_predictor('assets/shape_predictor_5_face_landmarks.dat') face_recognition_model = dlib.face_recognition_model_v1('assets/dlib_face_recognition_resnet_model_v1.dat') fs = os.listdir('photos') es = [] for f in fs: print(f) image = np.asarray(Image.open(os.path.join('photos', f))) face_detects = face_detector(image, 1) face = face_detects[0] landmarks = shape_predictor(image, face) embedding = face_recognition_model.compute_face_descriptor(image, landmarks, num_jitters=10) embedding = np.asarray(embedding) name, _ = os.path.splitext(f) es.append((name, embedding)) with open('assets/embeddings.pickle', 'wb') as f: pickle.dump(es, f)
Fügen Sie unserem Bot-Code das Einbetten hinzu.
import pickle
with open('assets/embeddings.pickle', 'rb') as f: star_embeddings = pickle.load(f)
Und durch umfassende Suche werden wir herausfinden, wie unser Benutzer alle gleich ist.
ds = [] for name, emb in star_embeddings: distance = np.linalg.norm(embedding - emb) ds.append((name, distance)) best_match, best_distance = min(ds, key=itemgetter(1)) bot.send_message( chat_id=update.message.chat_id, text=f'your look exactly like *{best_match}*', parse_mode='Markdown' )
Bitte beachten Sie, dass wir den euklidischen Abstand als Abstand verwenden, weil Das Netzwerk in dlib wurde genau mit dessen Hilfe trainiert.

Das ist alles, Glückwunsch! Wir haben einen einfachen Bot erstellt, der bestimmen kann, wie berühmt der Benutzer ist. Es bleibt noch mehr Fotos zu finden, Branding, Skalierbarkeit, eine Prise Protokollierung hinzuzufügen und alles kann in der Produktion freigegeben werden. All diese Themen sind zu umfangreich, um mit umfangreichen Codelisten ausführlich besprochen zu werden. Daher werde ich im nächsten Abschnitt nur die wichtigsten Punkte im Frage-Antwort-Format skizzieren.
Der vollständige Trainings-Bot-Code ist auf GitHub verfügbar.
Wir reden über unseren Bot
Wie viele Prominente haben Sie in Ihrer Datenbank? Wo hast du sie gefunden?
Die logischste Entscheidung bei der Erstellung des Bots schien darin zu bestehen, Promi-Daten aus unserer internen Inhaltsbasis zu übernehmen. Sie speichert im Format der Grafik Filme und alle Entitäten, die mit Filmen verbunden sind, einschließlich Schauspieler und Regisseure. Für jede Person kennen wir ihren Namen, ihr Login und ihr Passwort aus iCloud, verwandten Filmen und Alias, mit denen Links zur Site generiert werden können. Nach dem Bereinigen und Extrahieren nur der erforderlichen Informationen bleibt die json Datei wie folgt:
[ { "name": " ", "alias": "tilda-swinton", "role": "actor", "n_movies": 14 }, { "name": " ", "alias": "michael-shannon", "role": "actor", "n_movies": 22 }, ... ]
Es gab 22.000 solcher Einträge im Katalog. Übrigens kein Katalog, sondern ein Katalog.
Wo finde ich Fotos für all diese Leute?

Weißt du, hier und da . Es gibt zum Beispiel eine wunderbare Bibliothek , mit der Sie Bilder-Abfrageergebnisse von Google hochladen können. 22.000 Menschen - nicht so viele, mit 56 Streams konnten wir in weniger als einer Stunde Fotos für sie herunterladen.
Unter den heruntergeladenen Fotos müssen Sie defekte, verrauschte Fotos im falschen Format verwerfen. Lassen Sie dann nur diejenigen, bei denen es Gesichter gibt und bei denen diese Gesichter bestimmte Bedingungen erfüllen: den Mindestabstand zwischen den Augen, die Neigung des Kopfes. All dies lässt uns 12.000 Fotos.
Von den 12.000 Prominenten haben Benutzer derzeit nur 2 gefunden. Das heißt, es gibt ungefähr 8.000 Prominente, die immer noch nicht wie alle anderen sind. Lass es nicht einfach so! Öffne Telegramme und finde sie alle.
Wie kann der Prozentsatz der Ähnlichkeit für die euklidische Distanz bestimmt werden?
Gute Frage! In der Tat ist der euklidische Abstand im Gegensatz zum Kosinus oben nicht begrenzt. Daher stellt sich die vernünftige Frage, wie Sie dem Benutzer etwas Bedeutenderes zeigen können als "Herzlichen Glückwunsch, der Abstand zwischen Ihrer Einbettung und der Einbettung von Angelina Jolie beträgt 0,27635462738". Eines unserer Teammitglieder schlug die folgende einfache und geniale Lösung vor. Wenn Sie die Verteilung der Abstände zwischen den Einbettungen erstellen, ist dies normal. Für ihn können Sie also den Durchschnitt und die Standardabweichung berechnen und dann für jeden Benutzer anhand dieser Parameter berücksichtigen, wie viele Prozent der Menschen ihren Prominenten weniger ähnlich sind als er . Dies entspricht der Integration einer Wahrscheinlichkeitsdichtefunktion von d bis plus unendlich, wobei d die Entfernung zwischen Benutzer- und Promi-Rallyes ist.
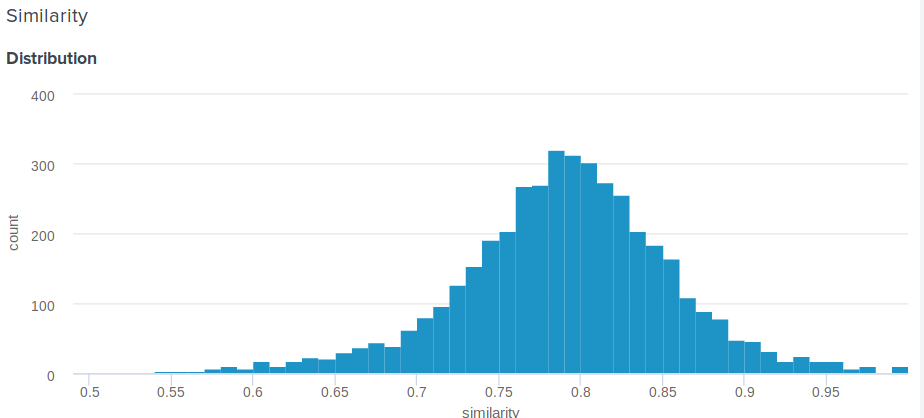
Hier ist die genaue Funktion, die wir verwenden:
def _transform_dist_to_sim(self, dist): p = 0.5 * (1 + erf((dist - self._dist_mean) / (self._dist_std * 1.4142135623730951))) return max(min(1 - p, 1.0), self._min_similarity)
Ist es wirklich notwendig, die Liste aller Gewerkschaften zu durchlaufen, um eine Übereinstimmung zu finden?
Natürlich nicht, das ist nicht optimal und nimmt viel Zeit in Anspruch. Der einfachste Weg, Berechnungen zu optimieren, ist die Verwendung von Matrixoperationen. Anstatt Vektoren voneinander zu subtrahieren, können Sie eine Matrix daraus erstellen, einen Vektor von der Matrix subtrahieren und dann die L2-Norm in Zeilen berechnen.
scores = np.linalg.norm(emb - embeddings, axis=1) best_idx = scores.argmax()
Dies führt bereits zu einer enormen Steigerung der Produktivität, aber es stellt sich heraus, dass Sie noch schneller arbeiten können. Die Suche kann erheblich beschleunigt werden, indem die Genauigkeit der nmslib- Bibliothek ein wenig an Genauigkeit verliert . Es verwendet die HNSW- Methode, um die Suche nach k nächsten Nachbarn zu approximieren. Für alle verfügbaren Vektoren sollte ein sogenannter Index erstellt werden, in dem dann eine Suche durchgeführt wird. Sie können den Index für die euklidische Entfernung wie folgt erstellen und speichern:
import nmslib index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) for idx, emb in enumerate(embeddings): index.addDataPoint(idx, emb) index_time_params = { 'indexThreadQty': 4, 'skip_optimized_index': 0, 'post': 2, 'delaunay_type': 1, 'M': 100, 'efConstruction': 2000 } index.createIndex(index_time_params, print_progress=True) index.saveIndex('./assets/embeddings.bin')
Die Parameter M und efConstruction werden in der Dokumentation ausführlich beschrieben und experimentell anhand der erforderlichen Genauigkeit, Indexkonstruktionszeit und efConstruction ausgewählt. Bevor Sie den Index verwenden können, müssen Sie Folgendes herunterladen:
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) index.loadIndex('./assets/embeddings.bin') query_time_params = {'efSearch': 400} index.setQueryTimeParams(query_time_params)
Der Parameter efSearch wirkt sich auf die Genauigkeit und Geschwindigkeit von Abfragen aus und efConstruction möglicherweise nicht mit der efConstruction . Jetzt können Sie Anfragen stellen.
ids, dists = index.knnQuery(embedding, k=1) best_dx = ids[0] best_dist = dists[0]
In unserem Fall ist nmslib 20-mal schneller als die vektorisierte lineare Version, und eine Anforderung wird durchschnittlich 0.005 Sekunden verarbeitet.
Wie mache ich meinen Bot produktionsbereit?
1. Asynchronität
Zunächst müssen Sie die Funktion handle_photo asynchron machen. Wie ich bereits sagte, bietet python-telegram-bot Multithreading an und implementiert einen praktischen Dekorator.
from telegram.ext.dispatcher import run_async @run_async def handle_photo(bot, update): ...
Jetzt startet das Framework selbst Ihren Handler in einem separaten Thread in seinem Pool. Die Poolgröße wird beim Erstellen des Updater . "Aber in Python gibt es kein Multithreading!" der ungeduldigste von euch hat bereits ausgerufen. Und das ist nicht ganz richtig. Aufgrund der GIL kann regulärer Python-Code nicht parallel ausgeführt werden, aber die GIL wird freigegeben, um auf alle E / A-Vorgänge zu warten, und sie kann auch von Bibliotheken freigegeben werden, die C-Erweiterungen verwenden.
Analysieren Sie nun unsere Funktion handle_photo : Sie besteht lediglich aus dem Warten auf E / A-Vorgänge (Hochladen eines Fotos, Senden einer Antwort, Lesen eines Fotos von der Festplatte usw.) und Aufrufen von Funktionen aus den Bibliotheken numpy , nmslib und Pillow .
Ich habe dlib nicht dlib Grund erwähnt. Die Bibliothek, die den nativen Code aufruft, ist nicht erforderlich, um die GIL dlib und dlib dieses Recht. Sie braucht dieses Schloss nicht, sie lässt sie einfach nicht los. Der Autor sagt, dass er die entsprechende Pull-Anfrage gerne annehmen wird, aber ich bin zu faul.
2. Mehrfachverarbeitung
Der einfachste Weg, mit dlib besteht darin, das Modell in einer separaten Entität zu kapseln und in einem separaten Prozess auszuführen. Und besser im Prozesspool.
def _worker_initialize(config): global model model = Model(config) model.load_state() def _worker_do(image): return model.process_image(image) pool = multiprocessing.Pool(8, initializer=_worker_initialize, initargs=(config,))
result = pool.apply(_worker_do, (image,))
3. Eisen
Wenn Ihr Bot ständig Fotos von einer Festplatte lesen muss, stellen Sie sicher, dass es sich bei der Festplatte um eine SSD handelt. Oder mounten Sie sie sogar in RAM. Ping an Telegrammserver und Kanalqualität ist ebenfalls wichtig.
4. Hochwasserschutz
Durch Telegramme können Bots nicht mehr als 30 Nachrichten pro Sekunde senden. Wenn Ihr Bot beliebt ist und viele Leute ihn gleichzeitig verwenden, ist es sehr einfach, ein Verbot für einige Sekunden zu erwischen, was sich für viele Benutzer als Enttäuschung gegenüber den Erwartungen herausstellen wird. Um dieses Problem zu lösen, bietet uns der python-telegram-bot eine Warteschlange, die nicht mehr als das angegebene Nachrichtenlimit pro Sekunde senden kann, wobei gleiche Intervalle zwischen den Sendungen eingehalten werden.
from telegram.ext.messagequeue import MessageQueue
Um es zu verwenden, müssen Sie Ihren eigenen Bot definieren und ihn beim Erstellen des Updater ersetzen.
from telegram.utils.promise import Promise class MQBot(Bot): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self._message_queue = MessageQueue( all_burst_limit=30, all_time_limit_ms=1000 ) def __del__(self): try: self._message_queue.stop() finally: super().__del__() def send_message(self, *args, **kwargs): is_group = kwargs.get('chat_id', 0) >= 0 return self._message_queue(Promise(super().send_message, args, kwargs), is_group)
bot = MQBot(token=TOKEN) updater = Updater(bot=bot)
5. Web-Hooks
In einer Produktumgebung sollten Web Hooks immer anstelle von Long Polling verwendet werden, um Updates von Telegrammservern zu erhalten. Worum es geht und wie man es benutzt, lesen Sie hier .
6. Wissenswertes
json . , ultrajson .
IO-: , , . , .
6.
, . , , , . , .
, , BI-tool Splunk .
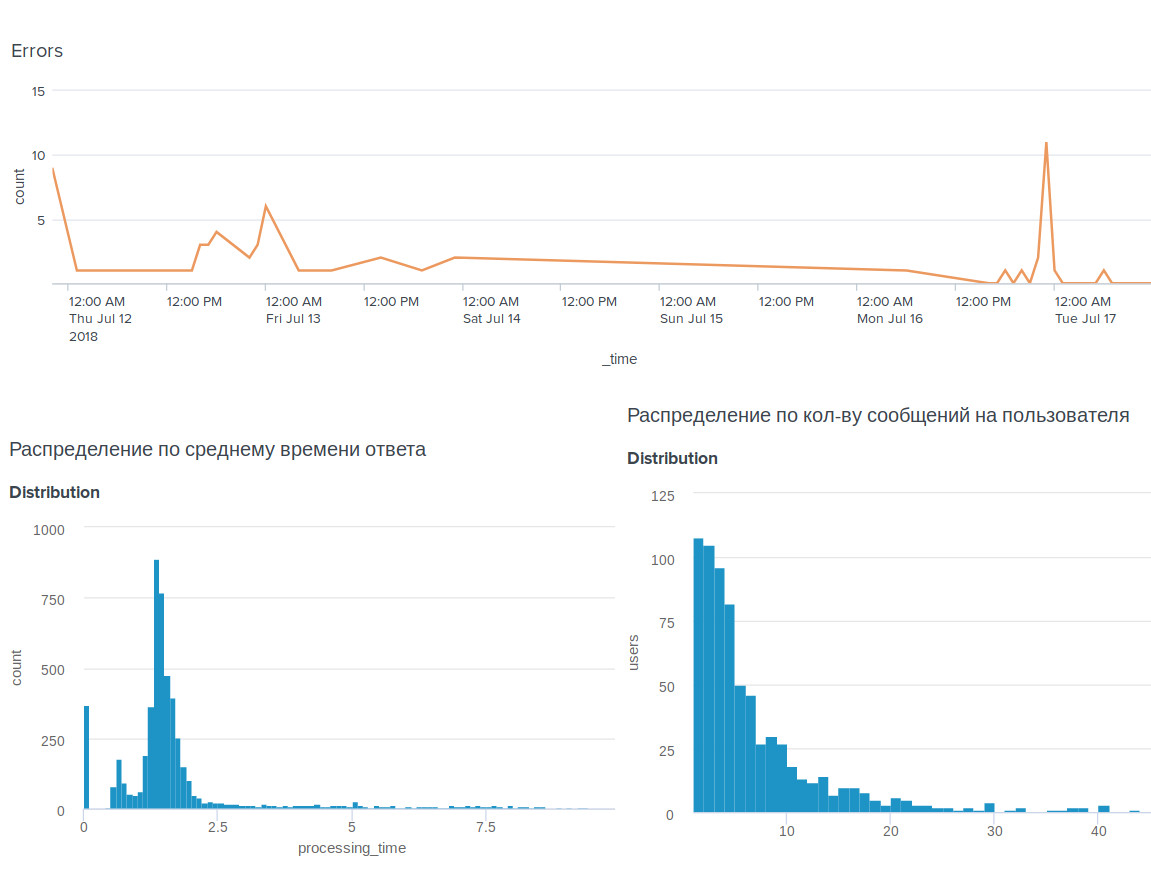
, . , .
, . , : @OkkoFaceBot .