Bevor der von uns geschriebene Code ausgeführt wird, ist es ein ziemlich langer Weg.
Andrey Melikhov hat in seinem Bericht zu RIT ++ 2018 jeden Schritt auf diesem Weg am Beispiel der V8-Engine untersucht. Kommen Sie unter die Katze, um herauszufinden, was uns ein tiefes Verständnis der Prinzipien des Compilers gibt und wie Sie JavaScript-Code produktiver machen können.

Wir werden herausfinden, ob WASM eine Silberkugel zur Verbesserung der Codeleistung ist und ob Optimierungen immer gerechtfertigt sind.
Spoiler: „Vorzeitige Optimierung ist die Wurzel aller Krankheiten“, Donald Knuth.
 Über den Sprecher:
Über den Sprecher: Andrei Melikhov arbeitet bei Yandex.Money, schreibt aktiv auf Node.js und weniger im Browser, sodass Server-JavaScript näher bei ihm ist. Andrew unterstützt und entwickelt die devShacht-Community. Schauen Sie sich also
GitHub oder
Medium an .
Motivation und Glossar
Heute werden wir über die JIT-Kompilierung sprechen. Ich denke, das ist interessant für dich, da du das liest. Lassen Sie uns jedoch klären, warum Sie wissen müssen, was JIT ist und wie V8 funktioniert, und warum das Schreiben von React in einem Browser nicht ausreicht.
- Ermöglicht das Schreiben von effizienterem Code , da unsere Sprache spezifisch ist.
- Es zeigt Rätsel, warum der Code in den Bibliotheken anderer Leute so geschrieben ist und nicht anders. Manchmal stoßen wir auf alte Bibliotheken und sehen, dass das, was dort geschrieben steht, irgendwie seltsam ist, aber wenn dies notwendig ist, ist es nicht notwendig - es ist nicht klar. Wenn Sie wissen, wie es funktioniert, verstehen Sie, warum dies getan wurde.
- Das ist einfach interessant . Darüber hinaus können wir verstehen, was Axel Rauschmeier, Benedict Moyrer und Dan Abramov auf Twitter kommunizieren.
Laut Wikipedia ist JavaScript eine hochinterpretierte Programmiersprache mit dynamischer Typisierung. Wir werden uns mit diesen Bedingungen befassen.
Zusammenstellung und InterpretationKompilierung - Wenn das Programm in Binärcode geliefert wird und zunächst für die Umgebung optimiert ist, in der es funktionieren wird.
Interpretation - wenn wir den Code so liefern, wie er ist.
JavaScript wird so geliefert, wie es ist - es ist eine interpretierte Sprache, wie sie auf Wikipedia geschrieben ist.
Dynamische und statische EingabeStatische und dynamische Typisierung wird oft mit schwacher und starker Typisierung verwechselt. Zum Beispiel ist C eine Sprache mit statisch schwacher Typisierung. JavaScript hat eine schwache dynamische Typisierung.
Welches ist besser? Wenn das Programm kompiliert wird, ist es auf die Umgebung ausgerichtet, in der es ausgeführt wird, was bedeutet, dass es besser funktioniert. Durch statische Eingabe wird dieser Code effizienter. In JavaScript ist das Gegenteil der Fall.
Gleichzeitig wird unsere Anwendung immer komplexer: Sowohl auf dem Client als auch auf dem Server erscheinen auf Node.js riesige Cluster, die einwandfrei funktionieren und Java-Anwendungen ersetzen.
Aber wie funktioniert das alles, wenn es zunächst ein Verlierer zu sein scheint?
JIT wird alle versöhnen! Oder zumindest versuchen.
Wir haben eine JIT (Just In Time Compilation), die zur Laufzeit stattfindet. Wir werden über sie sprechen.
Js Motoren
- Ungeliebtes Chakra, das sich im Internet Explorer befindet. Es funktioniert nicht einmal mit JavaScript, sondern mit Jscript - es gibt eine solche Teilmenge.
- Modernes Chakra und ChakraCore, die in Edge funktionieren;
- SpiderMonkey in FireFox;
- JavaScriptCore in WebKit. Es wird auch in React Native verwendet. Wenn Sie eine RN-Anwendung für Android haben, läuft diese auch auf JavaScriptCore - die Engine wird mit der Anwendung geliefert.
- V8 ist mein Favorit. Es ist nicht das Beste, ich arbeite nur mit Node.js, in dem es die Haupt-Engine ist, wie in allen Chrome-basierten Browsern.
- Rhino und Nashorn sind die in Java verwendeten Engines. Mit ihrer Hilfe können Sie dort auch JavaScript ausführen.
- JerryScript - für eingebettete Geräte;
- und andere...
Sie können Ihre eigene Engine schreiben, aber wenn Sie sich einer effektiven Ausführung nähern, kommen Sie zu ungefähr demselben Schema, das ich später zeigen werde.
Heute werden wir über den V8 sprechen, und ja, er ist nach dem 8-Zylinder-Motor benannt.
Wir klettern unter die Haube
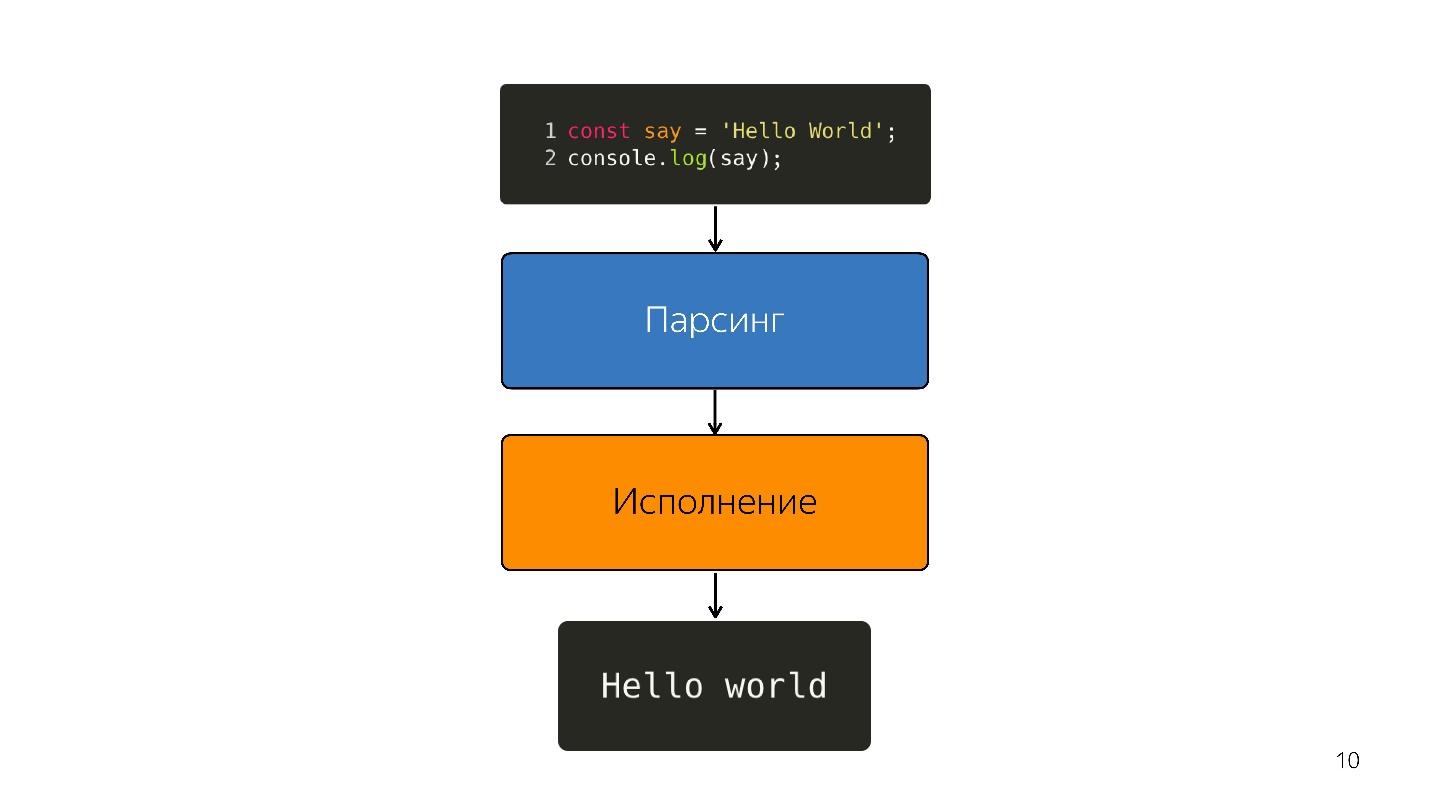
Wie wird Javascript ausgeführt?
- In JavaScript ist Code enthalten, der mitgeliefert wird.
- er analysiert;
- wird ausgeführt;
- das Ergebnis wird erhalten.
Durch das Parsen wird Code in einen
abstrakten Syntaxbaum umgewandelt . AST ist eine Anzeige der syntaktischen Struktur des Codes in Form eines Baums. Dies ist eigentlich praktisch für das Programm, obwohl es schwer zu lesen ist.
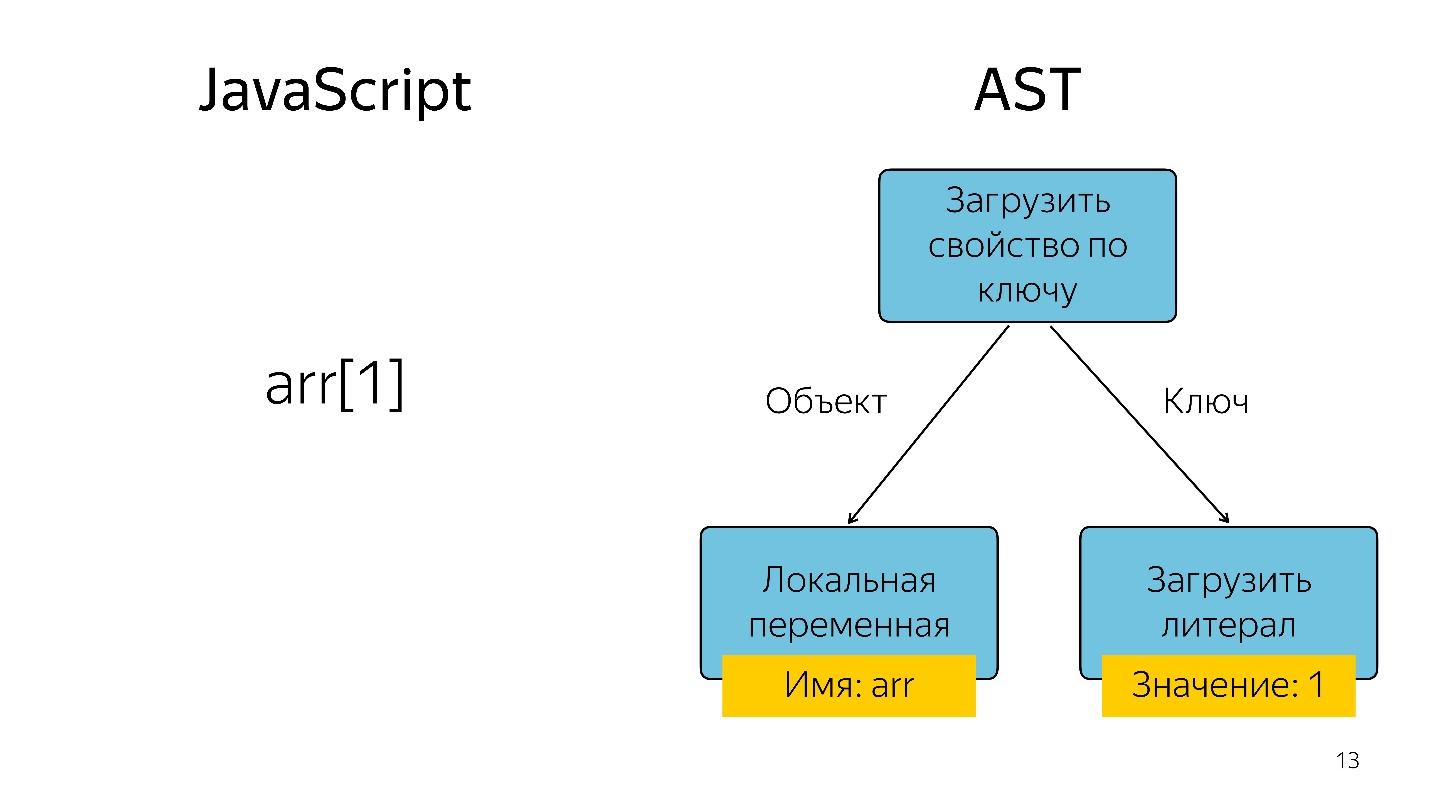
Das Abrufen eines Array-Elements mit Index 1 in Form eines Baums wird als Operator und zwei Operanden dargestellt: Laden Sie die Eigenschaft mit dem Schlüssel und diesen Schlüsseln.
Wo wird AST eingesetzt?
AST ist nicht nur in Motoren. Mit AST schreiben viele Dienstprogramme Erweiterungen, darunter:
- ESLint;
- Babel;
- Schöner
- Jscodeshift.
Mit der coolen Sache Jscodeshift, über die noch nicht jeder Bescheid weiß, können Sie beispielsweise Transformationen schreiben. Wenn Sie die API einer Funktion ändern, können Sie diese Transformationen festlegen und Änderungen im gesamten Projekt vornehmen.

Wir gehen weiter. Der Prozessor versteht den abstrakten Syntaxbaum nicht und benötigt
Maschinencode . Daher findet eine weitere Transformation durch den Interpreter statt, da die Sprache interpretiert wird.
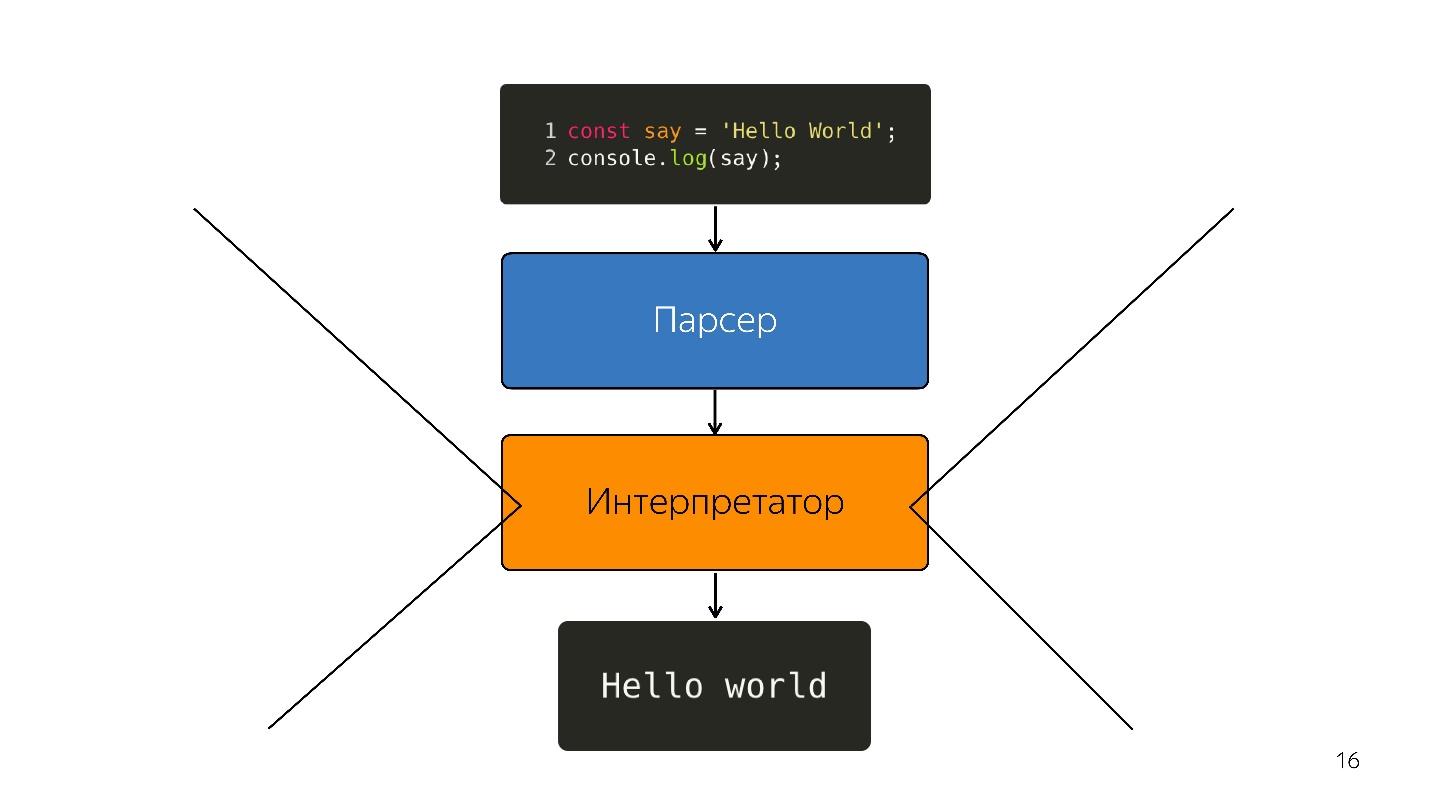
So war es, während Browser ein bisschen JavaScript hatten - markieren Sie die Zeile, öffnen Sie etwas, schließen Sie. Aber jetzt haben wir Anwendungen - SPA, Node.js, und der
Interpreter wird zu einem Engpass .
JIT-Compiler optimieren
Anstelle eines Interpreters wird ein optimierender JIT-Compiler angezeigt, dh ein Just-in-Time-Compiler. Ahead-of-Time-Compiler arbeiten vor der Anwendungsausführung und JIT - während. In Bezug auf das Optimierungsproblem versucht der JIT-Compiler zu erraten, wie der Code ausgeführt wird, welche Typen verwendet werden, und den Code so zu optimieren, dass er besser funktioniert.
Eine solche Optimierung wird als
spekulativ bezeichnet , da sie über das Wissen darüber
spekuliert , was zuvor mit dem Code geschehen ist. Das heißt, wenn etwas mit dem Nummerntyp zehnmal aufgerufen wurde, glaubt der Compiler, dass dies die ganze Zeit passieren wird, und optimiert für diesen Typ.
Wenn Boolean in die Eingabe eingeht, tritt natürlich eine Deoptimierung auf. Stellen Sie sich eine Funktion vor, die Zahlen hinzufügt.
const foo=(a, b) => a + b;
foo (1, 2);
foo (2, 3);Einmal gefaltet, das zweite Mal. Der Compiler erstellt die Vorhersage: "Dies sind Zahlen, ich habe eine coole Lösung zum Hinzufügen von Zahlen!" Und Sie schreiben
foo('WTF', 'JS') und übergeben die Zeilen an die Funktion - wir haben JavaScript, wir können eine Zeile mit einer Zahl hinzufügen.
Zu diesem Zeitpunkt tritt eine Deoptimierung auf.
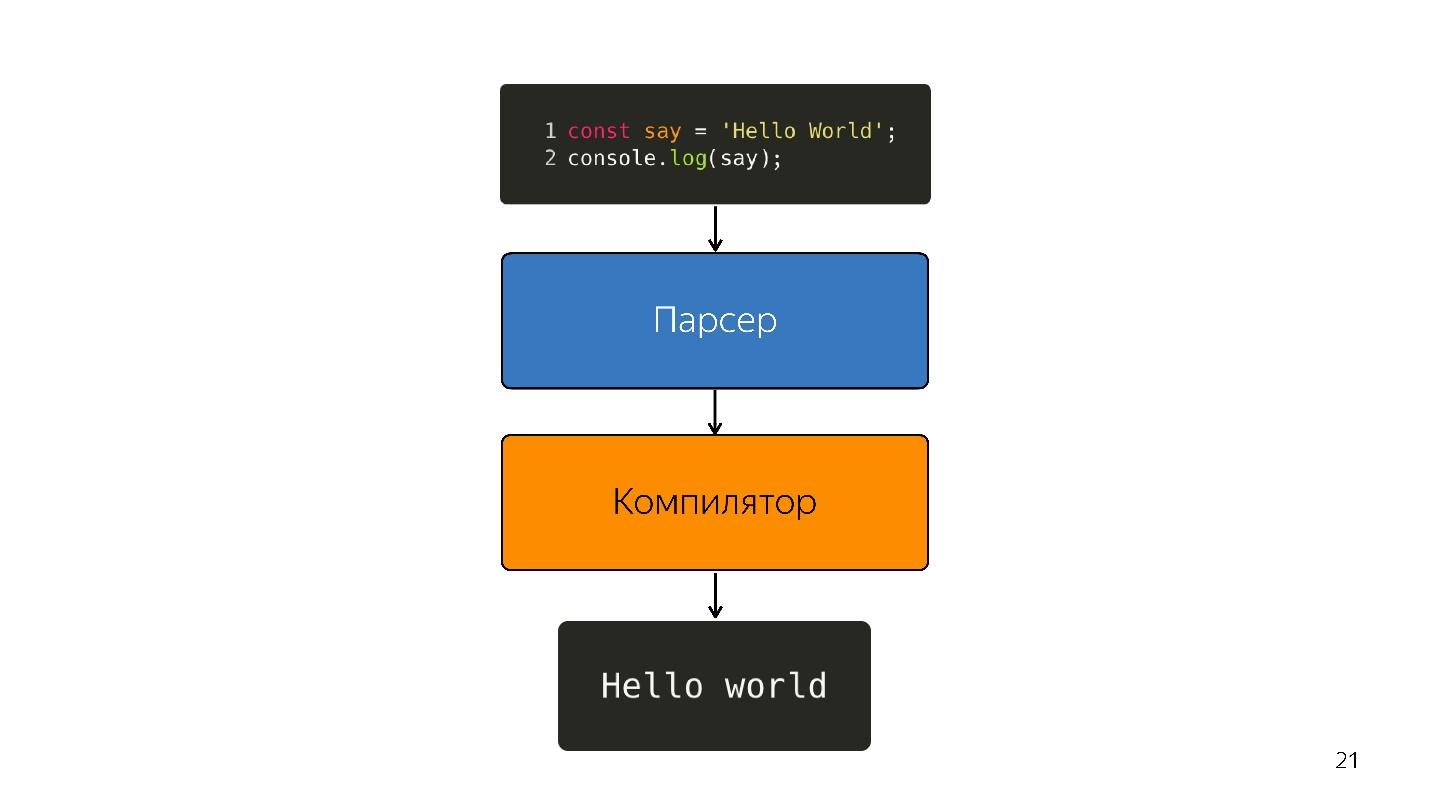
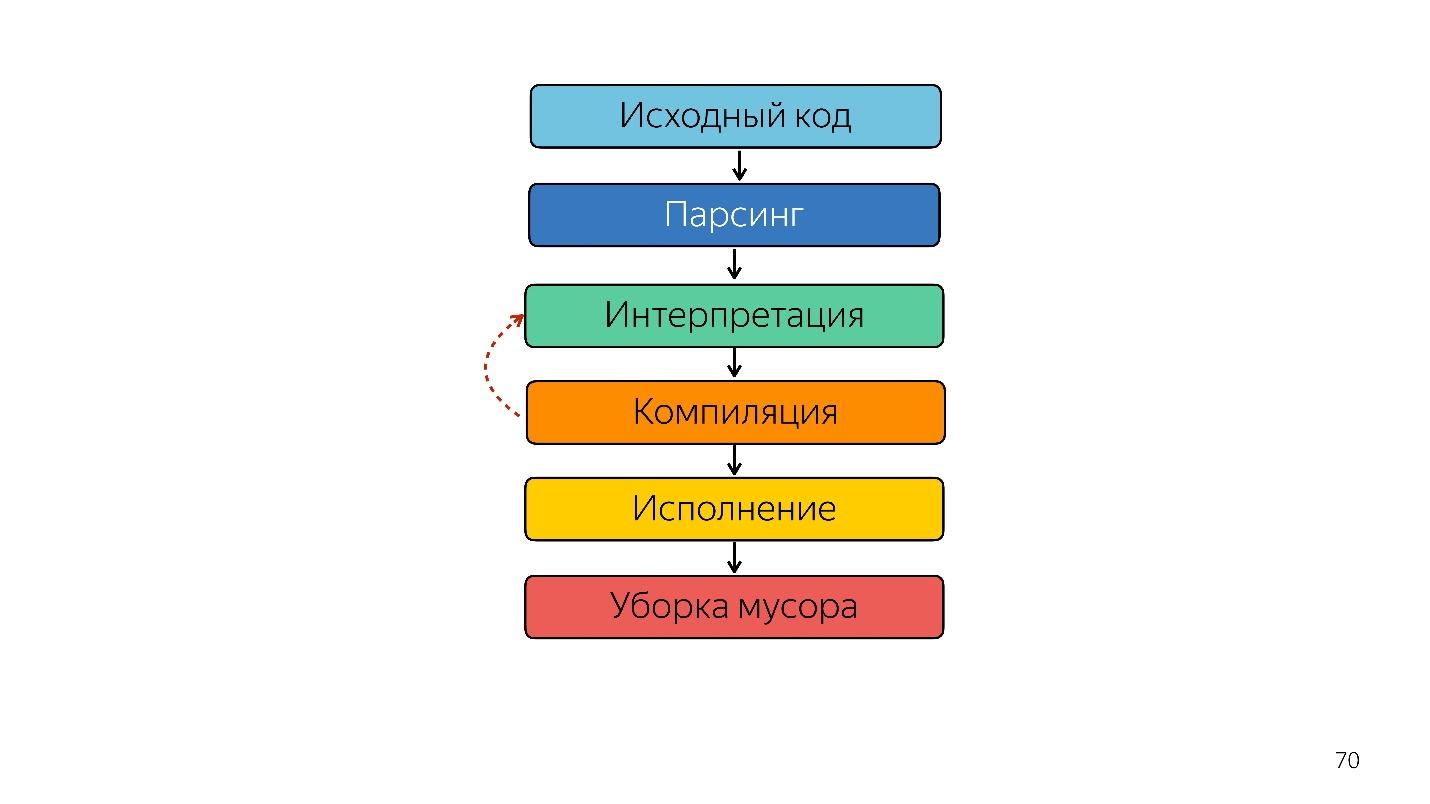
Also wurde der Interpreter durch den Compiler ersetzt. Das obige Diagramm scheint eine sehr einfache Pipeline zu haben. In Wirklichkeit ist alles etwas anders.
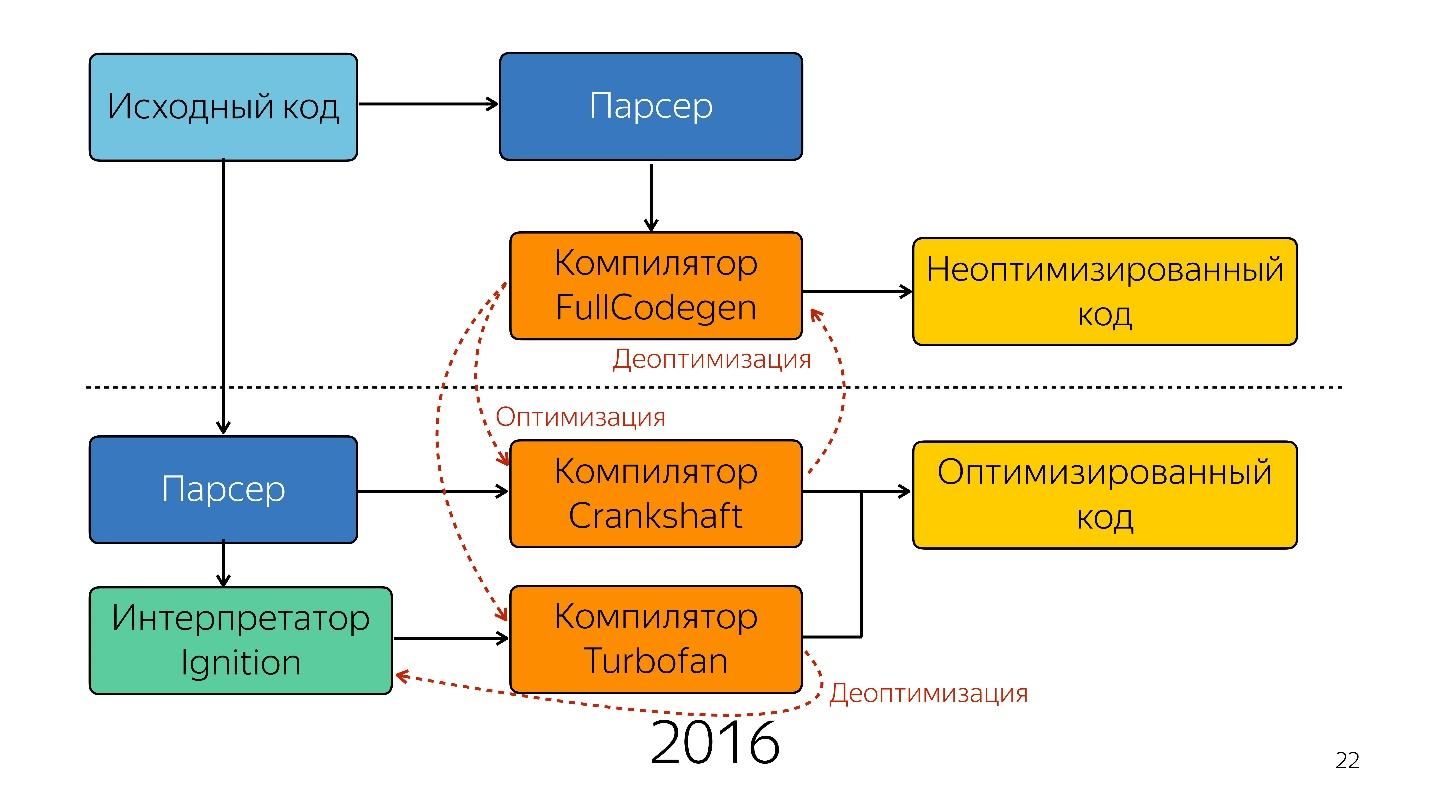
Das war bis letztes Jahr. Letztes Jahr konnte man viele Berichte von Google hören, dass sie eine neue Pipeline mit TurboFan gestartet haben, und jetzt sieht das Schema einfacher aus.
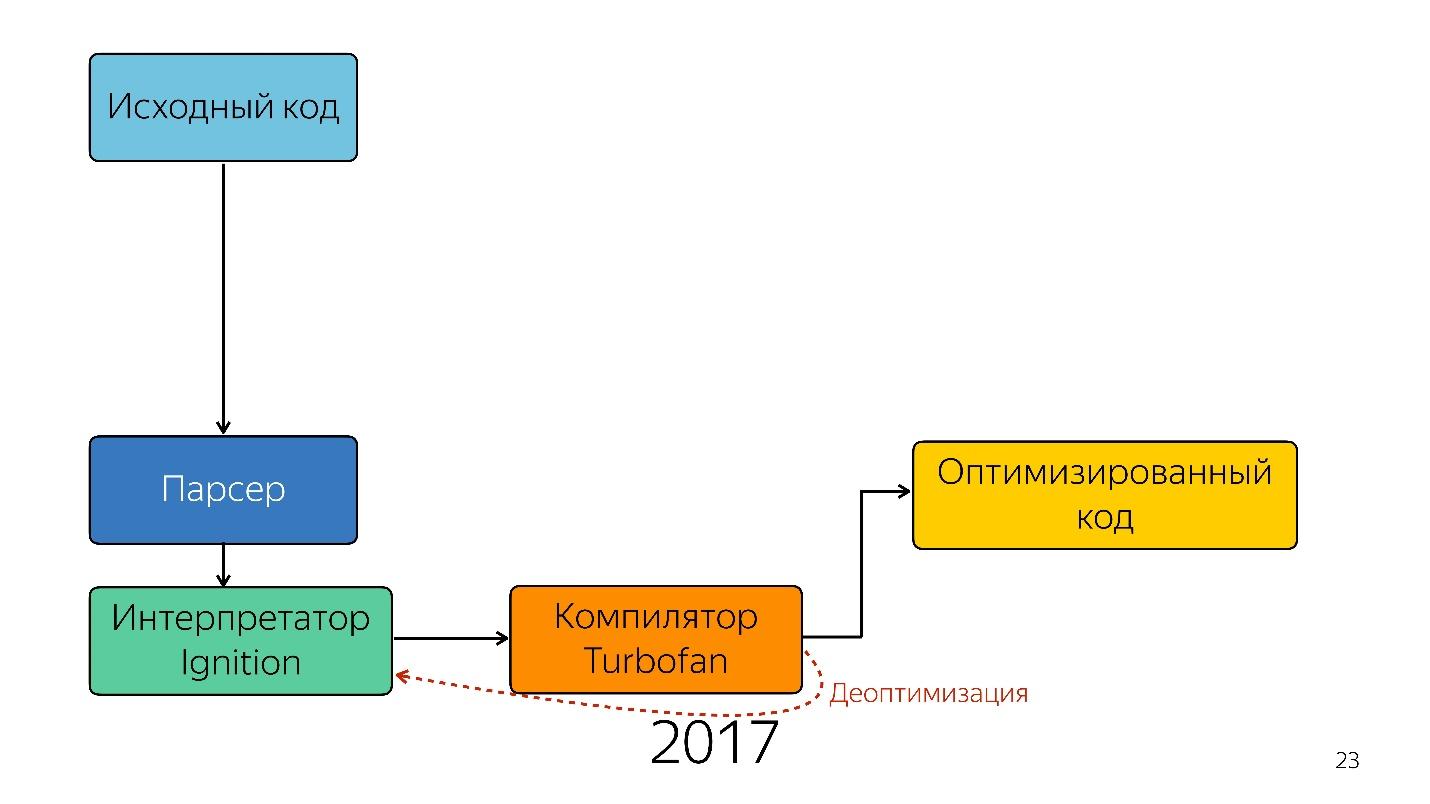
Interessanterweise erschien hier ein Dolmetscher.
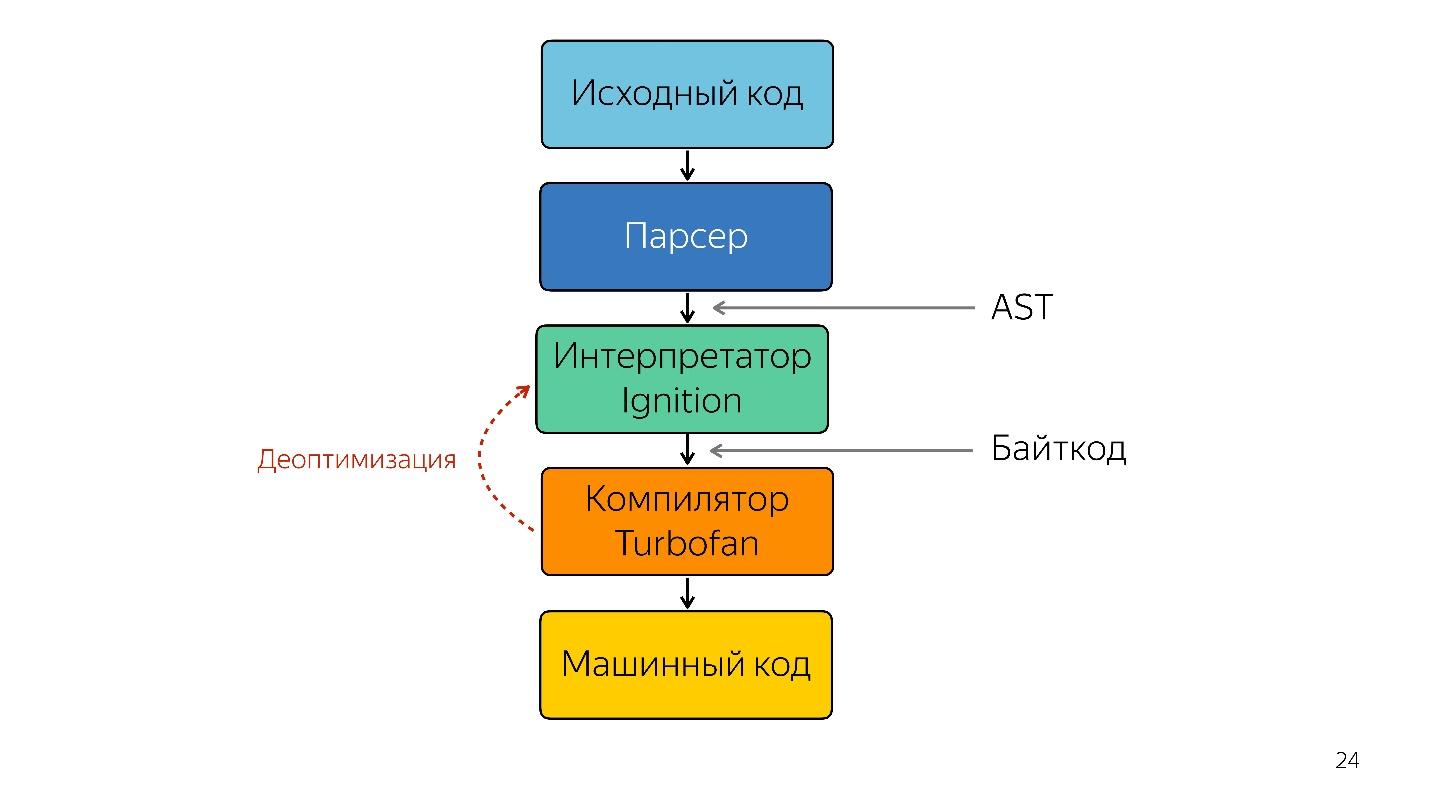
Ein Interpreter wird benötigt, um einen abstrakten Syntaxbaum in einen Bytecode umzuwandeln und den Bytecode an einen Compiler zu übergeben. Im Falle einer Deoptimierung geht er erneut zum Dolmetscher.
Dolmetscherzündung
Bisher gab es kein Ignition-Interpreter-Schema. Google sagte zunächst, dass kein Dolmetscher benötigt wird - JavaScript ist bereits kompakt und interpretierbar genug - wir werden nichts gewinnen.
Das Team, das mit mobilen Anwendungen arbeitete, stieß jedoch auf das folgende Problem.

In den Jahren 2013 bis 2014 nutzten die Menschen häufiger mobile Geräte, um auf das Internet zuzugreifen als auf den Desktop. Grundsätzlich ist dies kein iPhone, sondern von einfacheren Geräten - sie haben wenig Speicher und einen schwachen Prozessor.
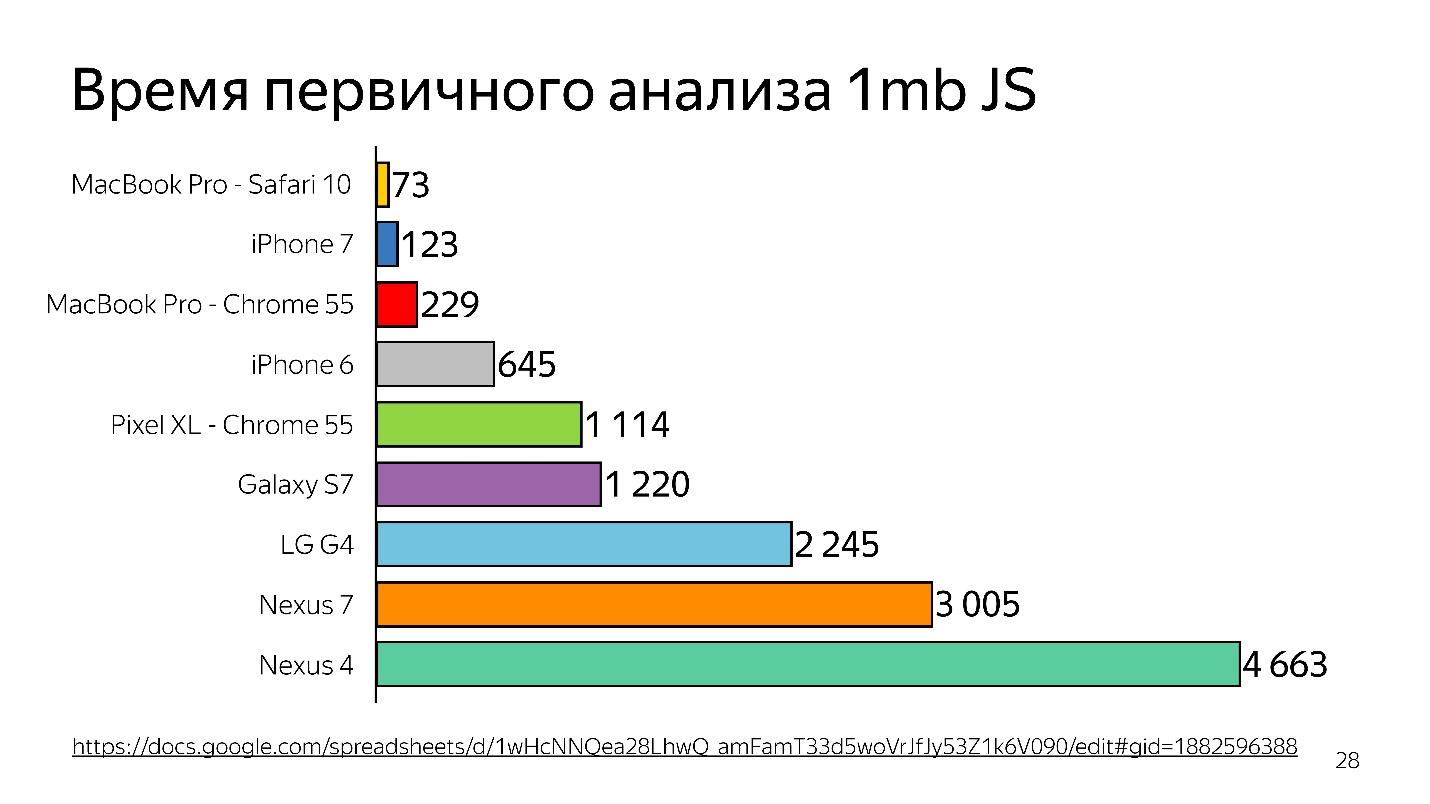
Oben sehen Sie eine grafische Darstellung der anfänglichen Analyse von 1 MB Code vor dem Starten des Interpreters. Es ist zu sehen, dass der Desktop sehr viel gewinnt. Das iPhone ist auch nicht schlecht, aber es hat eine andere Engine, und wir sprechen über V8, das in Chrome funktioniert.
Wussten Sie, dass Chrome auf dem iPhone weiterhin unter JavaScriptCore funktioniert?
Somit wird Zeit verschwendet - und dies ist nur eine Analyse, keine Ausführung - Ihre Datei wurde geladen und versucht zu verstehen, was darin geschrieben ist.
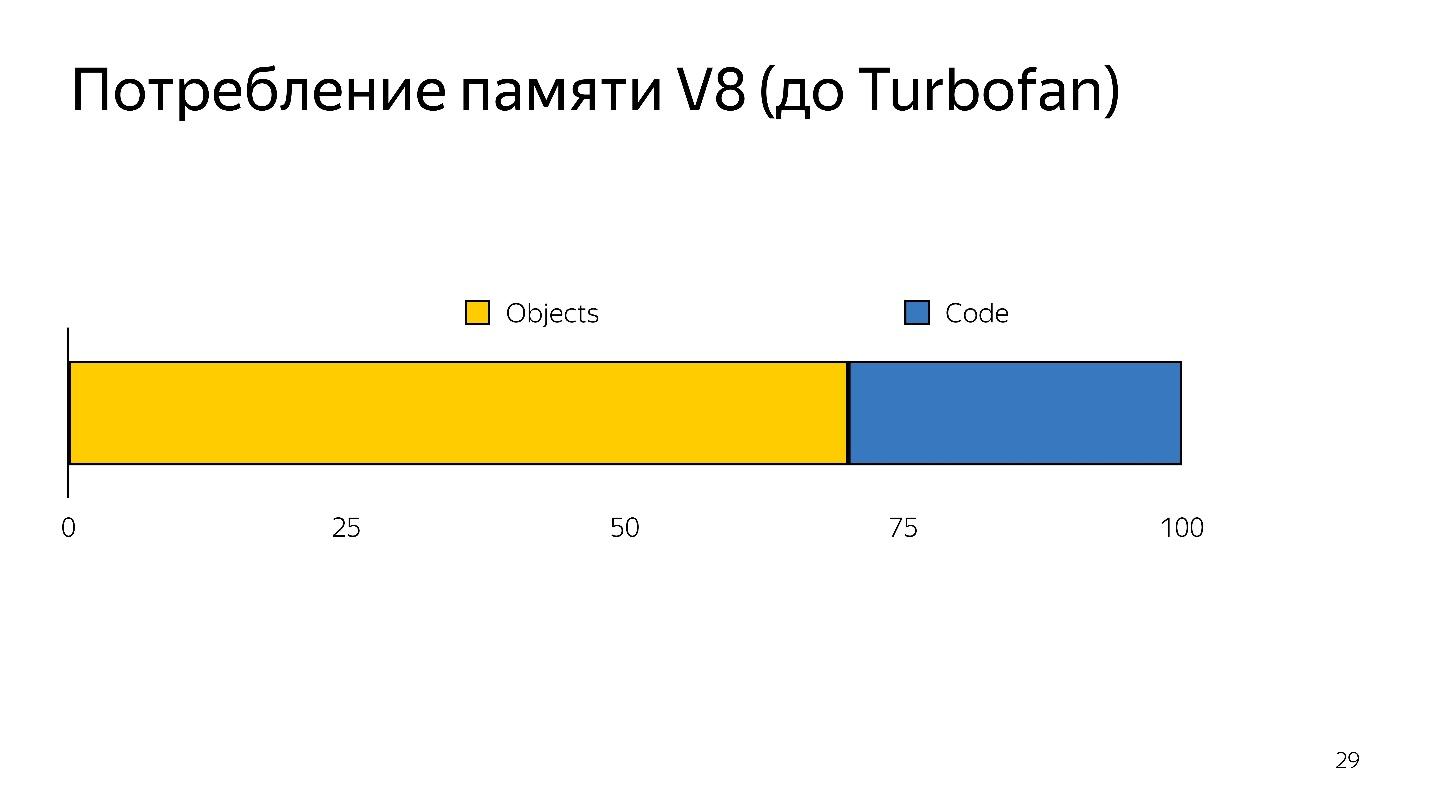
Wenn eine Deoptimierung auftritt, müssen Sie den Quellcode erneut verwenden, d. H. es muss irgendwo aufbewahrt werden. Es hat viel Gedächtnis gekostet.
Somit hatte der Dolmetscher zwei Aufgaben:
- Reduzieren Sie den Parsing-Overhead.
- Speicherverbrauch reduzieren.
Die Aufgaben wurden durch den Wechsel zu einem Bytecode-Interpreter gelöst.
 Bytecode in Chrome ist ein Registriergerät mit einer Batterie
Bytecode in Chrome ist ein Registriergerät mit einer Batterie . SpiderMonkey hat eine gestapelte Maschine, dort befinden sich alle Daten auf dem Stapel, aber es gibt keine Register. Hier sind sie.
Wir werden nicht vollständig analysieren, wie dies funktioniert. Schauen Sie sich nur das Codefragment an.

Hier heißt es: Nehmen Sie den Wert, der in der Batterie liegt, und addieren Sie ihn zu dem Wert, der im Register
a0 liegt,
dh in der Variablen
a . Über Typen ist hier noch nichts bekannt. Wenn es sich um echten Assembler-Code handeln würde, würde er mit dem Verständnis geschrieben, welche Art von Verschiebungen sich im Speicher befinden und was sich darin befindet. Hier ist nur eine Anweisung - nehmen Sie, was im Register
a0 liegt, und addieren Sie es zu dem Wert, der in der Batterie liegt.
Natürlich nimmt der Interpreter nicht nur den abstrakten Syntaxbaum und übersetzt ihn in Bytecode.
Es gibt auch Optimierungen, zum Beispiel die Beseitigung von totem Code.
Wenn ein Codeabschnitt nicht aufgerufen wird, wird er weggeworfen und nicht weiter gespeichert. Wenn Ignition zwei Zahlen hinzufügt, fügt er sie hinzu und lässt sie so, dass keine unnötigen Informationen gespeichert werden. Erst danach wird der Bytecode erhalten.
Optimierung und Deoptimierung
Kalte und heiße Züge
Dies ist das einfachste Thema.
Kalte Funktionen sind solche, die einmal oder gar nicht aufgerufen wurden, heiße Funktionen sind solche, die mehrmals aufgerufen wurden. Es ist unmöglich genau zu sagen, wie oft - zu jedem Zeitpunkt kann dies wiederholt werden. Aber irgendwann wird die Funktion heiß und der Motor versteht, dass sie optimiert werden muss.

Das Arbeitsschema.
- Zündung (Dolmetscher) sammelt Informationen. Er konvertiert nicht nur JavaScript in Bytecode, sondern versteht auch, welche Typen eingegangen sind, welche Funktionen heiß geworden sind, und erzählt dem Compiler davon.
- Es gibt eine Optimierung.
- Der Compiler führt den Code aus. Alles funktioniert gut, aber hier kommt ein Typ an, den er nicht erwartet hat, er hat keinen Code, um mit diesem Typ zu arbeiten.
- Es kommt zu einer Deoptimierung. Der Compiler greift auf den Ignition-Interpreter für diesen Code zu.
Dies ist ein normaler Zyklus, der ständig auftritt, aber nicht unendlich ist. Irgendwann sagt der Motor: "Nein, es ist unmöglich zu optimieren" und beginnt ohne Optimierung auszuführen. Es ist wichtig zu verstehen, dass Monomorphismus beobachtet werden muss.
Monomorphismus ist, wenn immer die gleichen Typen zum Eingang Ihrer Funktion kommen. Das heißt, wenn Sie ständig Zeichenfolgen erhalten, müssen Sie dort keinen Booleschen Wert übergeben.
Aber was tun mit Objekten? Objekte sind alle Objekte. Wir haben Klassen, aber sie sind nicht real - es ist nur Zucker über dem Prototypmodell. Aber innerhalb der Engine gibt es sogenannte versteckte Klassen.
Versteckte Klassen
Es gibt versteckte Klassen in allen Engines, nicht nur in V8. Überall werden sie anders genannt, in Bezug auf V8 ist es Map.
Alle von Ihnen erstellten Objekte haben versteckte Klassen. Wenn Sie
Wenn Sie sich den Speicherprofiler ansehen, werden Sie feststellen, dass es Elemente gibt, in denen die Liste der Elemente gespeichert ist, Eigenschaften, in denen die Eigenschaft gespeichert ist, und Map (normalerweise der erste Parameter), in der ein Link dazu in der ausgeblendeten Klasse angegeben ist.
Map beschreibt die Struktur von Objekten, da in JavaScript die Eingabe grundsätzlich nur strukturell und nicht nominal möglich ist. Wir können beschreiben, wie unser Objekt aussieht und wofür es funktioniert.
Beim Löschen / Hinzufügen von Eigenschaften von Objekten mit ausgeblendeten Klassen ändert sich das Objekt und es wird ein neues zugewiesen. Schauen wir uns den Code an.
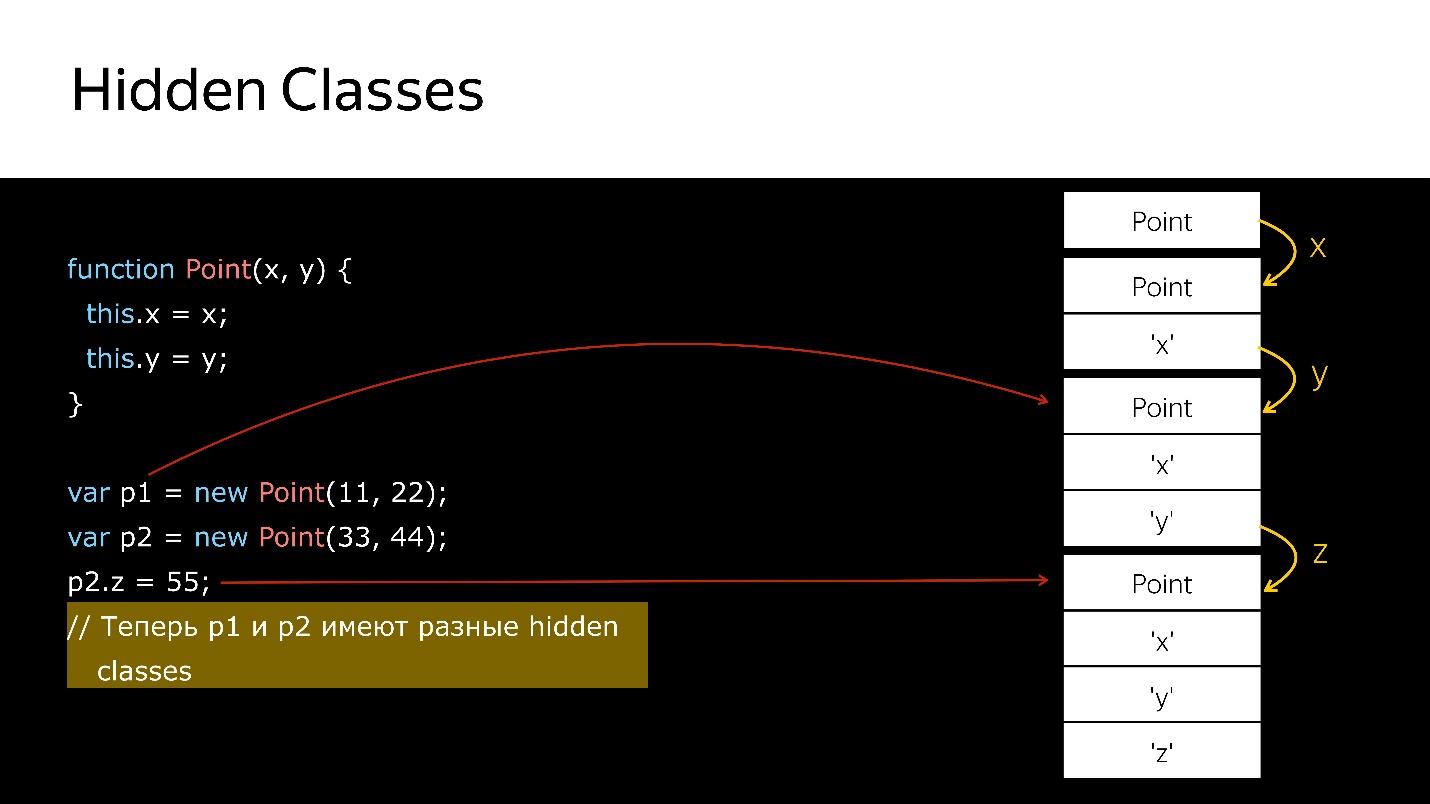
Wir haben einen Konstruktor, der ein neues Objekt vom Typ Point erstellt.
- Erstellen Sie ein Objekt.
- Binden Sie eine versteckte Klasse daran, die besagt, dass es sich um ein Objekt vom Typ Point handelt.
- Wir haben das x-Feld hinzugefügt - eine neue versteckte Klasse, die besagt, dass es sich um ein Objekt vom Typ Point handelt, bei dem der x-Wert an erster Stelle steht.
- Y hinzugefügt - die neuen versteckten Klassen, in denen x und dann y.
- Erstellt ein anderes Objekt - das gleiche passiert. Das heißt, er bindet auch das, was bereits geschaffen wurde. In diesem Moment sind diese beiden Objekte vom gleichen Typ (über versteckte Klassen).
- Wenn dem zweiten Objekt ein neues Feld hinzugefügt wird, wird im Objekt eine neue ausgeblendete Klasse angezeigt. Für die Motoren p1 und p2 sind dies Objekte unterschiedlicher Klassen, da sie unterschiedliche Strukturen haben
- Wenn Sie das erste Objekt irgendwohin übertragen, tritt beim Übertragen des zweiten Objekts eine Deoptimierung auf. Die erste bezieht sich auf eine versteckte Klasse, die zweite auf eine andere.
Wie kann ich nach versteckten Klassen suchen?In Node.js können Sie die Node-Allow-Natives-Syntax ausführen. Dann haben Sie die Möglichkeit, Befehle in einer speziellen Syntax zu schreiben, die natürlich nicht in der Produktion verwendet werden kann. Es sieht so aus:
%HaveSameMap({'a':1}, {'b':1})
Niemand garantiert, dass diese Befehle morgen funktionieren, sie sind nicht in der ECMAScript-Spezifikation enthalten, das ist alles zum Debuggen.
Was ist Ihrer Meinung nach das Ergebnis des Aufrufs der% HaveSameMap-Funktion für zwei Objekte? Die richtige Antwort ist falsch, weil einer ein Feld hat und der andere
b . Dies sind verschiedene Objekte. Dieses Wissen kann für die Inline-Caches-Technik verwendet werden.
Inline-Caches
Wir rufen eine sehr einfache Funktion auf, die ein Feld von einem Objekt zurückgibt. Die Rücksendung des Geräts scheint sehr einfach zu sein. Wenn Sie sich jedoch die ECMAScript-Spezifikation ansehen, werden Sie feststellen, dass es eine große Liste der Schritte gibt, die Sie ausführen müssen, um das Feld vom Objekt abzurufen. Denn wenn sich das Feld nicht im Objekt befindet, befindet es sich möglicherweise in seinem Prototyp. Vielleicht ist es Setter, Getter und so weiter. All dies muss überprüft werden.

In diesem Fall hat das Objekt einen Link zur Karte, der besagt: Um das Feld
x zu erhalten , müssen Sie einen Versatz um eins machen, und wir erhalten
x . Sie müssen nirgendwo klettern, in keinem Prototyp ist alles in der Nähe. Inline-Caches verwenden dies.
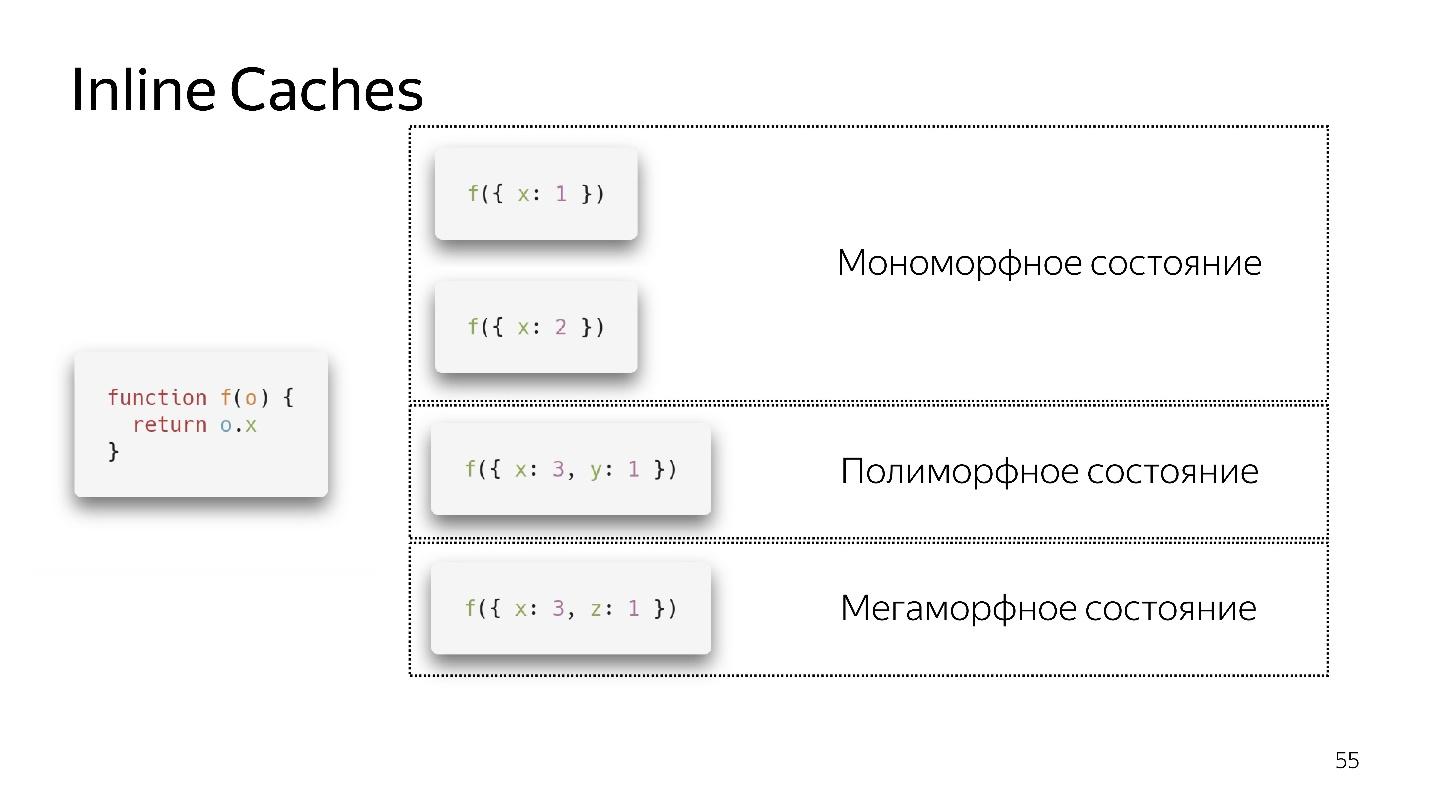
- Wenn wir die Funktion zum ersten Mal aufrufen, ist alles in Ordnung, der Interpreter hat die Optimierung durchgeführt
- Beim zweiten Aufruf wird ein monomorpher Zustand gespeichert.
- Ich rufe die Funktion ein drittes Mal auf und übergebe ein etwas anderes Objekt {x: 3, y: 1}. Deoptimierung tritt auf, wenn erscheint, gehen wir in einen polymorphen Zustand über. Jetzt weiß der Code, der diese Funktion ausführt, dass zwei verschiedene Arten von Objekten hineinfliegen können.
- Wenn wir mehrere Objekte mehrmals passieren, bleibt es in einem polymorphen Zustand und fügt neue ifs hinzu. Aber irgendwann ergibt sich und geht in einen megamorphen Zustand über, d.h. wann: "Zu viele verschiedene Typen kommen am Eingang an - ich weiß nicht, wie ich es optimieren soll!"
Es scheint, dass jetzt 4 polymorphe Zustände erlaubt sind, aber morgen können es 8 sein. Dies wird von den Entwicklern der Engine entschieden. Wir bleiben besser in einem monomorphen, im Extremfall polymorphen Zustand. Der Übergang zwischen monomorphen und polymorphen Zuständen ist teuer, da Sie zum Interpreter gehen, den Code erneut abrufen und erneut optimieren müssen.
Arrays
In JavaScript gibt es neben den spezifischen typisierten Arrays einen Typ
Array. Es gibt 6 davon im V8-Motor:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS - nur ein gepacktes Array kleiner Ganzzahlen. Es gibt Optimierungen für ihn.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS - ein gepacktes Array von Doppelelementen, es gibt auch Optimierungen dafür, aber langsamere.
3. [1, 2, 3, 4, 'X'] // PACKED_ELEMENTS - ein gepacktes Array, in dem sich Objekte, Zeichenfolgen und alles andere befinden. Auch für ihn gibt es Optimierungen.
Die folgenden drei Typen sind Arrays des gleichen Typs wie die ersten drei, jedoch mit Löchern:
4. [1, / * Loch * /, 2, / * Loch * /, 3, 4] // HOLEY_SMI_ELEMENTS
5. [1.2, / * Loch * /, 2, / * Loch * /, 3,4] // HOLEY_DOUBLE_ELEMENTS
6. [1, / * hole * /, 'X'] // HOLEY_ELEMENTS
Wenn in Ihren Arrays Löcher auftreten, werden Optimierungen weniger effizient. Sie beginnen schlecht zu arbeiten, weil es unmöglich ist, dieses Array hintereinander zu durchlaufen und Iterationen zu sortieren. Jeder nachfolgende Typ ist weniger optimiert
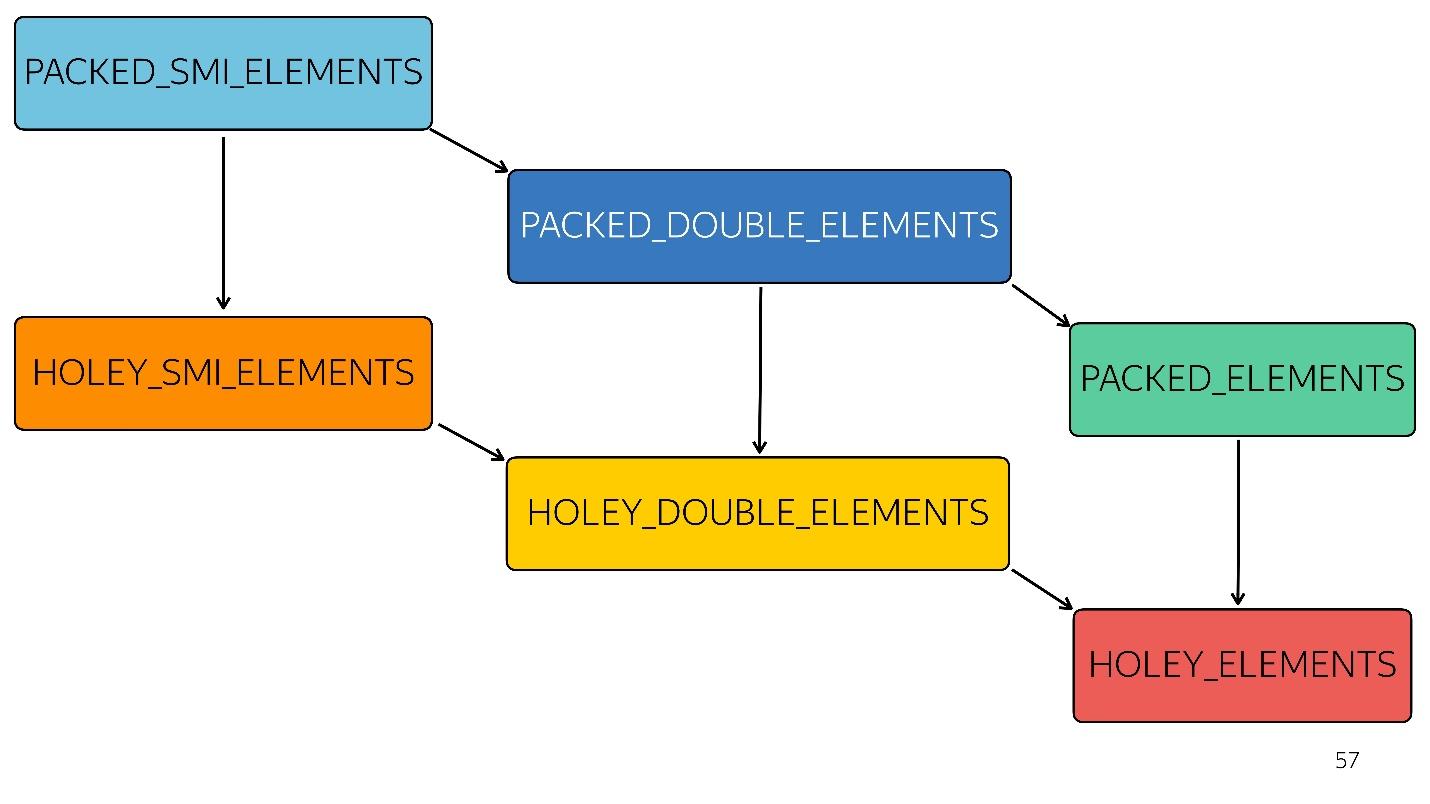
Im Diagramm wird alles oben Genannte schneller optimiert. Das heißt, alle Ihre nativen Methoden - Map, Reduce, Sort - Inside sind gut optimiert. Mit jedem Typ wird die Optimierung jedoch schlechter.
Zum Beispiel kam ein einfaches Array [
1 ,
2 ,
3 ] zum Eingang (typgepackte kleine Ganzzahl). Wir haben dieses Array leicht geändert, indem wir ihm ein Double hinzugefügt haben - es ist in den Status PACKED_DOUBLE_ELEMENTS übergegangen. Fügen Sie ein Objekt hinzu - wechseln Sie zum nächsten Status, dem grünen Rechteck PACKED_ELEMENTS. Fügen Sie Löcher hinzu - wechseln Sie in den Status HOLEY_ELEMENTS. Wir möchten den vorherigen Zustand wiederherstellen, damit er wieder „gut“ wird - wir löschen alles, was wir geschrieben haben, und bleiben im selben Zustand ... mit Löchern! Das heißt, HOLEY_ELEMENTS unten rechts im Diagramm. Zurück funktioniert das nicht. Ihre Arrays können nur schlechter werden, aber nicht umgekehrt.
Array-ähnliches Objekt
Wir stoßen häufig auf Array-ähnliche Objekte - dies sind Objekte, die wie Arrays aussehen, weil sie ein Längenzeichen haben. Tatsächlich sind sie wie eine Piratenkatze, das heißt, sie scheinen ähnlich zu sein, aber in Bezug auf die Effizienz des Rumkonsums ist eine Katze schlechter als ein Pirat. Ebenso ist ein Array-ähnliches Objekt wie ein Array, jedoch nicht effizient.

Unsere beiden bevorzugten Array-ähnlichen Objekte sind Argumente und document.querySelectorAII. Es gibt so schöne funktionale Dinge.
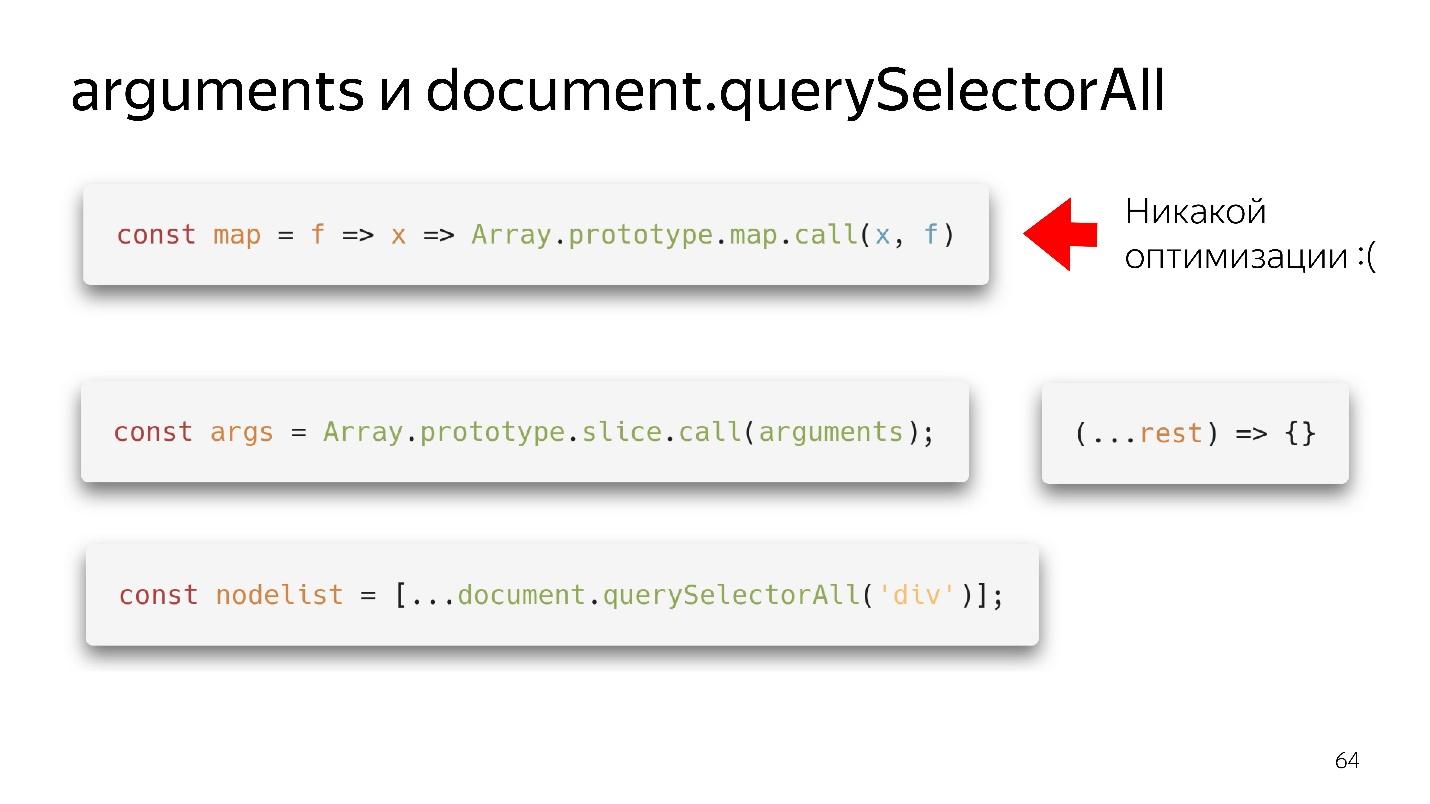
Wir haben eine Karte - wir haben sie aus dem Prototyp herausgerissen und können sie anscheinend verwenden. Wenn jedoch kein Array zu seiner Eingabe gelangt ist, erfolgt keine Optimierung. Unsere Engine ist nicht in der Lage, Objekte zu optimieren.
Was muss getan werden?
- Die Old-School-Option - durch Slice.call () wird ein echtes Array.
- Die moderne Option ist noch besser: schreiben (... ruhen), ein sauberes Array erhalten - keine Argumente - alles ist in Ordnung!
Mit querySelectorAll das Gleiche - aufgrund der Verbreitung können wir es in ein vollwertiges Array verwandeln und mit allen Optimierungen arbeiten.
Große Arrays
Rätsel: neues Array (1000) vs Array = []
Welche Option ist besser: Erstellen Sie sofort ein großes Array und füllen Sie es mit 1000 Objekten in einer Schleife oder erstellen Sie ein leeres und füllen Sie es schrittweise?
Richtige Antwort: hängt von ab.
Was ist der Unterschied?
- Wenn wir auf die erste Weise ein Array erstellen und 1000 Elemente füllen, erstellen wir 1000 Löcher. Dieses Array wird nicht optimiert. Aber er wird schnell schreiben.
- Wenn Sie ein Array gemäß der zweiten Variante erstellen, wird ein wenig Speicher zugewiesen, wir schreiben beispielsweise 60 Elemente, ein wenig mehr Speicher wird zugewiesen usw.
Das heißt, im ersten Fall schreiben wir schnell - wir arbeiten langsam; im zweiten schreiben wir langsam - wir arbeiten schnell.
Müllsammler
Der Müllsammler frisst auch ein wenig Zeit und Ressourcen. Ohne tief zu tauchen, werde ich die häufigste Basis geben.

Unser generatives Modell hat einen
Raum aus jungen und alten Objekten . Das erstellte Objekt fällt in den Raum junger Objekte. Nach einiger Zeit beginnt die Reinigung. Wenn das Objekt nicht über Links von der Wurzel aus erreicht werden kann, kann es im Müll gesammelt werden. Wenn das Objekt noch verwendet wird, wird es in den Bereich alter Objekte verschoben, der weniger häufig gereinigt wird. Irgendwann werden jedoch die alten Objekte gelöscht.

So funktioniert ein automatischer Garbage Collector - er bereinigt Objekte auf der Grundlage, dass keine Links zu ihnen vorhanden sind. Dies sind zwei verschiedene Algorithmen.
- Das Spülen ist schnell, aber nicht effektiv.
- Mark-Sweep ist langsam aber effizient.
Wenn Sie mit der Profilerstellung des Speicherverbrauchs in Node.js beginnen, erhalten Sie so etwas.

Zuerst wächst es abrupt - das ist die Arbeit des Scavenge-Algorithmus. Dann tritt ein scharfer Abfall auf - dieser Mark-Sweep-Algorithmus hat Müll im Raum alter Objekte gesammelt. In diesem Moment beginnt sich alles etwas zu verlangsamen.
Sie können es nicht kontrollieren , weil Sie nicht wissen, wann es passieren wird. Sie können nur die Größen anpassen.
Daher verfügt die Pipeline über eine Speicherbereinigungsphase, die Zeit in Anspruch nimmt.
Noch schneller?
Schauen wir in die Zukunft. Was tun als nächstes, wie schneller sein?
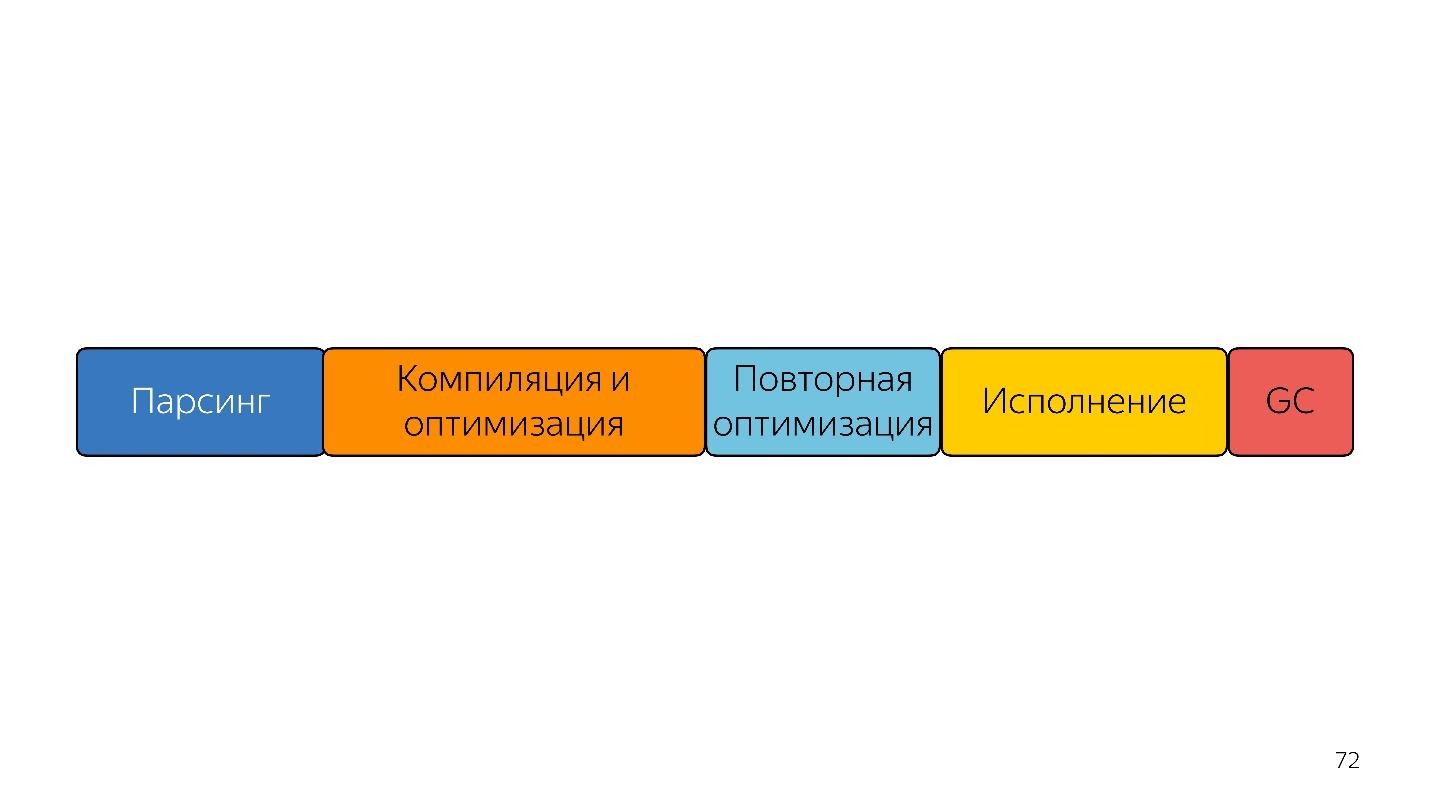
In dieser Zeile hängen die Blockgrößen in etwa in der dafür benötigten Zeit zusammen.
Das erste, was Menschen in den Sinn kommt, die von Bytecode gehört haben - senden Sie sofort einen Bytecode an die Eingabe und dekodieren Sie ihn, anstatt ihn zu analysieren -, ist schneller!

Das Problem ist, dass der Bytecode jetzt anders ist. Wie gesagt: in Safari eins, in FireFox ein anderes, in Chrome drittens. Trotzdem haben Entwickler von Mozilla, Bloomberg und Facebook einen solchen
Vorschlag unterbreitet , aber dies ist die Zukunft.
Es gibt ein weiteres Problem - Kompilieren, Optimieren und erneutes Optimieren, wenn der Compiler dies nicht erraten hat. Stellen Sie sich vor, es gibt eine statisch typisierte Sprache an der Eingabe, die effektiven Code erzeugt, was bedeutet, dass keine Neuoptimierung mehr erforderlich ist, da das, was wir haben, bereits effizient ist. Eine solche Eingabe kann nur einmal kompiliert und optimiert werden. Der resultierende Code ist effizienter und wird schneller ausgeführt.
Was kann man noch tun? Stellen Sie sich vor, diese Sprache verfügt über eine manuelle Speicherverwaltung. Dann brauchen Sie keinen Müllsammler. Die Linie ist kürzer und schneller geworden.

Ratet mal, wie es aussieht?
WebAssembly ungefähr
So funktioniert es: manuelle Speicherverwaltung, statisch typisiert
Sprachen und schnelle Ausführung.

Ist WebAssembly eine Silberkugel?

Nein, weil es für JavaScript steht. WASM kann noch nichts tun. Er hat keinen Zugriff auf die DOM-API. Es befindet sich in der JavaScript-Engine - in derselben Engine! Es erledigt alles über JavaScript, sodass
WASM Ihren Code nicht beschleunigt . Es kann einzelne Berechnungen beschleunigen, aber Ihr Austausch zwischen JavaScript und WASM wird ein Engpass sein.
Daher, während unsere Sprache JavaScript ist und nur es, und einige Hilfe von der Black Box.
Insgesamt
Es können drei Arten der Optimierung unterschieden werden.
●
Algorithmische OptimierungenEs gibt einen Artikel von Vyacheslav Egorov, der einst V8 entwickelt hat und jetzt Dart entwickelt, "
Vielleicht brauchen Sie Rust nicht, um Ihr JS zu beschleunigen ". Erzählen Sie kurz ihre Geschichte.
Es gab eine JavaScript-Bibliothek, die nicht sehr schnell funktionierte. Einige Leute haben es in Rust umgeschrieben, kompiliert und WebAssembly erhalten, und die Anwendung begann schneller zu arbeiten. Vyacheslav Egorov als erfahrener JS-Entwickler beschloss, diese zu beantworten. Er wandte algorithmische Optimierungen an und die JavaScript-Lösung wurde viel schneller als die Rust-Lösung. Im Gegenzug haben diese Leute dies gesehen, die gleichen Optimierungen vorgenommen und erneut gewonnen, aber nicht sehr viel - es hängt von der Engine ab: In Mozilla haben sie gewonnen, in Chrome nicht.
Heute haben wir nicht über algorithmische Optimierungen gesprochen, und Front-End-Renderings sprechen normalerweise nicht darüber. Dies ist sehr schlecht, da die
Algorithmen auch ermöglichen, dass der Code schneller ausgeführt wird . Sie entfernen einfach die Zyklen, die Sie nicht benötigen.
●
Sprachspezifische OptimierungenDarüber haben wir heute gesprochen: Unsere Sprache wird dynamisch typisiert interpretiert. Wenn Sie wissen, wie Arrays, Objekte und Monomorphismus funktionieren,
können Sie effizienten Code schreiben . Dies muss bekannt und korrekt geschrieben sein.
●
Motorspezifische OptimierungenDies sind die gefährlichsten Optimierungen. Wenn Ihr sehr kluger, aber nicht sehr kontaktfreudiger Entwickler, der viele solcher Optimierungen angewendet und niemandem davon erzählt hat, die Dokumentation nicht geschrieben hat, wird beim Öffnen des Codes nicht JavaScript angezeigt, sondern beispielsweise Crankshaft Script. Das heißt, JavaScript wurde mit einem tiefen Verständnis der Funktionsweise des Kurbelwellenmotors vor zwei Jahren geschrieben. Es funktioniert alles, wird aber jetzt nicht mehr benötigt.
Daher müssen solche Optimierungen unbedingt dokumentiert und mit Tests abgedeckt werden, die ihre derzeitige Wirksamkeit belegen. Sie müssen überwacht werden. Sie müssen nur dann zu ihnen gehen, wenn Sie irgendwo wirklich langsamer geworden sind - ohne das Wissen über so tiefe Geräte können Sie einfach nicht auskommen. Daher scheint der berühmte Satz von Donald Knuth logisch.

Sie müssen nicht versuchen, harte Optimierungen zu implementieren, nur weil Sie positive Bewertungen darüber gelesen haben.
Man sollte Angst vor solchen Optimierungen haben, unbedingt Metriken dokumentieren und belassen. Sammeln Sie im Allgemeinen immer Metriken.
Metriken sind wichtig!Nützliche Links:Frontend Conf Moscow 4 5 . 15 , , :
- (KeepSolid) , Offline First Persistent Storage
- (TradingView) WebGL WebAssembly , , API .
- , Google Docs.