Kennst du Ivan Tulup? Höchstwahrscheinlich ja, Sie wissen nur noch nicht, um welche Art von Person es sich handelt, und Sie müssen sehr genau auf den Zustand seines Herz-Kreislauf-Systems achten.
Darüber und darüber, wie Asynchronismus in JS unter der Haube funktioniert, wie Event Loop in Browsern und Node.js funktioniert, gibt es Unterschiede und möglicherweise wurden ähnliche Dinge von
Mikhail Bashurov (
SaitoNakamura ) in seinem Bericht über RIT erzählt ++. Wir freuen uns, Ihnen das Protokoll dieser informativen Präsentation mitteilen zu können.
 Über den Sprecher:
Über den Sprecher: Mikhail Bashurov ist ein Fullstack-Webentwickler für JS und .NET von Luxoft. Er liebt schöne Benutzeroberfläche, grüne Tests, Transpilation, Kompilierung, Compiler-Technik und verbesserte Entwicklererfahrung.
Anmerkung des Herausgebers: Mikhails Bericht wurde nicht nur von Folien begleitet, sondern auch von einem Demo-Projekt, in dem Sie auf Schaltflächen klicken und die Ausführung von Mischvorgängen unabhängig verfolgen können. Die beste Option wäre, die
Präsentation in einem angrenzenden Tab zu öffnen und regelmäßig darauf zu verweisen. Der Text enthält jedoch auch Links zu bestimmten Seiten. Und jetzt geben wir das Wort an den Sprecher weiter und genießen das Lesen.
Großvater Ivan Tulup
Ich hatte eine Kandidatur für Ivan Tulup.

Aber ich habe mich für einen konformistischeren Weg entschieden, also treffe dich - Großvater Ivan Tulup!

Tatsächlich müssen nur zwei Dinge über ihn bekannt sein:
- Er spielt gerne Karten.
- Er hat wie alle Menschen ein Herz und es schlägt.
Fakten zum Herzinfarkt
Sie haben vielleicht gehört, dass Fälle von Herzerkrankungen und deren Sterblichkeit in letzter Zeit häufiger geworden sind. Die wahrscheinlich häufigste Herzkrankheit ist ein Herzinfarkt, dh ein Herzinfarkt.
Was ist interessant an Herzinfarkt?
- Meistens tritt es am Montagmorgen auf.
- Bei alleinstehenden Personen ist das Risiko eines Herzinfarkts doppelt so hoch. Hier liegt der Punkt vielleicht nur in der Korrelation und nicht in einem kausalen Zusammenhang. Leider (oder zum Glück) ist dies jedoch so.
- Zehn Dirigenten starben während des Dirigierens an einem Herzinfarkt (anscheinend sehr nervöse Arbeit!).
- Ein Herzinfarkt ist eine Nekrose des Herzmuskels, die durch einen Mangel an Durchblutung verursacht wird.
Wir haben eine Koronararterie, die Blut in den Muskel bringt (Myokard). Wenn das Blut schlecht dorthin fließt, stirbt der Muskel allmählich ab. Dies wirkt sich natürlich äußerst negativ auf das Herz und seine Arbeit aus.
Großvater Ivan Tulup hat auch ein Herz und es schlägt. Aber unser Herz pumpt Blut und das Herz von Ivan Tulup pumpt unseren Code und unsere Sorgen.
Tasky: ein großer Kreislauf der Durchblutung
Was sind Aufgaben? Was kann in einem Browser generell faul sein? Warum werden sie überhaupt gebraucht?
Zum Beispiel führen wir Code aus einem Skript aus. Dies ist ein Herzschlag, und jetzt haben wir Blutfluss. Wir haben auf die Schaltfläche geklickt und das Ereignis abonniert - der Ereignishandler für dieses Ereignis hat ausgespuckt - den Rückruf, den wir gesendet haben. Sie setzten Timeout, Callback funktionierte - eine weitere Aufgabe. Und so ist in Teilen ein Herzschlag eine Aufgabe.

Es gibt viele verschiedene Kohlquellen, je nach Spezifikation gibt es viele davon. Unser Herz schlägt weiter und während es schlägt, ist alles in Ordnung mit uns.
Ereignisschleife im Browser: vereinfachte Version
Dies kann in einem sehr einfachen Diagramm dargestellt werden.
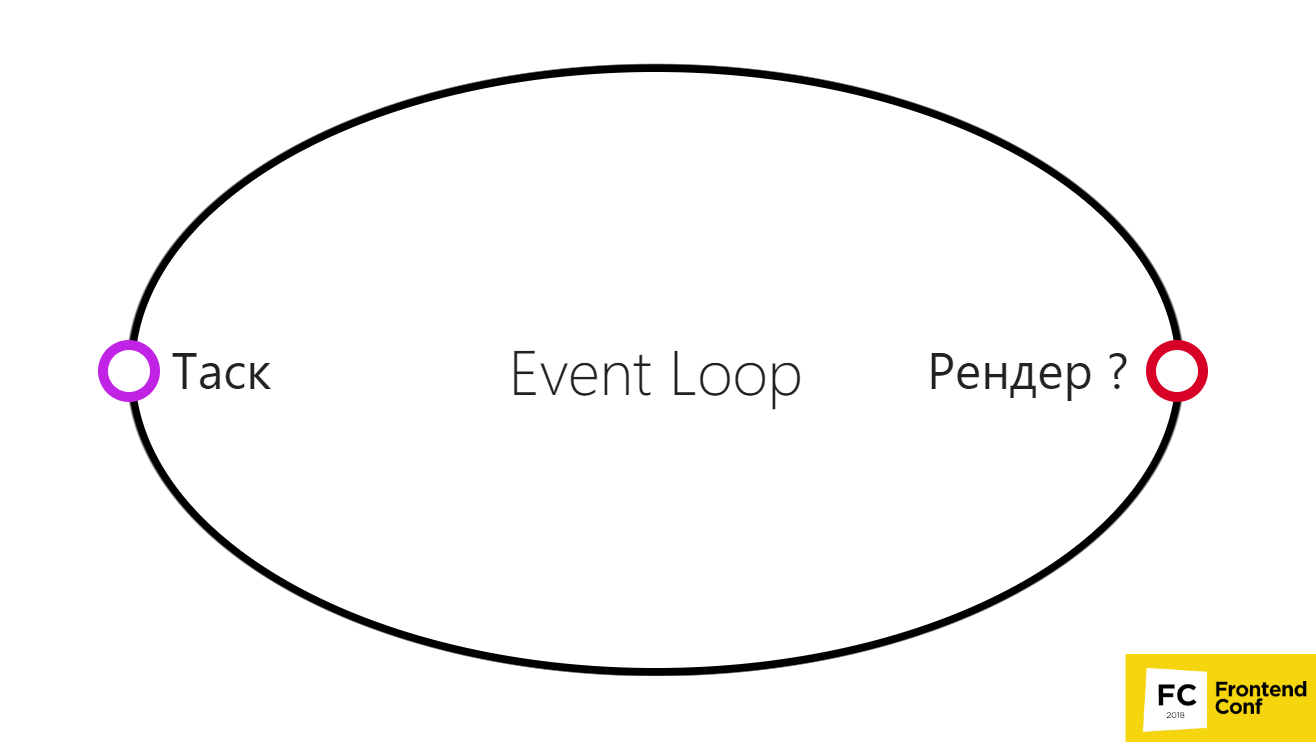
- Es gibt eine Aufgabe, wir haben sie erledigt.
- Dann führen wir das Browser-Rendering aus.
Dies ist jedoch nicht erforderlich, da der Browser in einigen Fällen möglicherweise nicht zwischen zwei Aufgaben rendert.
Dies kann beispielsweise passieren, wenn der Browser mehrere Zeitüberschreitungen oder mehrere Bildlaufereignisse gruppieren kann. Oder irgendwann geht etwas schief und der Browser entscheidet anstelle von 60 fps (normale Bildrate, damit alles kühl und flüssig wird), 30 fps anzuzeigen. Auf diese Weise hat er viel mehr Zeit, um Ihren Code und andere nützliche Arbeiten auszuführen. Er kann mehrere Schocks ausführen.
Daher wird das Rendern nicht wirklich nach jeder Aufgabe ausgeführt.
Aufgabe: Klassifizierung
Es gibt zwei Arten von möglichen Operationen:
- E / A gebunden;
- CPU gebunden.
CPU-gebunden ist unsere nützliche Arbeit, die wir leisten (glauben, anzeigen usw.)
E / A-gebunden sind die Punkte, an denen wir unsere Aufgaben teilen können. Das kann sein:
Wir haben setTimeout 5000 ms erstellt und warten nur auf diese 5000 ms, aber wir können andere nützliche Arbeiten ausführen. Erst wenn diese Zeit vergeht, erhalten wir einen Rückruf und arbeiten daran.
Wir sind online gegangen. Während wir auf eine Antwort vom Netzwerk warten, warten wir nur, aber wir können auch etwas Nützliches tun.
Oder wir gehen zum Beispiel zu Network BD. Wir sprechen auch über Node.js, einschließlich, und wenn wir von Node.js irgendwo ins Netzwerk gehen möchten, bitte - dies ist dieselbe potenzielle E / A-gebundene Aufgabe (Eingabe / Ausgabe).
Lesen Sie die Datei - möglicherweise handelt es sich überhaupt nicht um eine CPU-gebundene Aufgabe. In Node.js wird es aufgrund einer leicht krummen Linux-API im Thread-Pool ausgeführt, um ehrlich zu sein.
Dann ist CPUbound:
- Zum Beispiel, wenn wir eine for of / for (;;) - Schleife ausführen oder das Array irgendwie mit zusätzlichen Methoden durchlaufen: Filter, Map usw.
- JSON.parse oder JSON.stringify, d. H. Nachrichtenserialisierung / -deserialisierung. Dies geschieht alles auf der CPU. Wir können es kaum erwarten, dass alles irgendwo magisch ausgeführt wird.
- Zählen von Hashes, d. H. Krypto-Mining.
Natürlich kann Krypto auch auf der GPU abgebaut werden, aber ich denke - GPU, CPU - Sie verstehen diese Analogie.
Aufgabe: Arrhythmie und Thrombus
Infolgedessen stellt sich heraus, dass unser Herz schlägt: Es erledigt eine Aufgabe, die zweite, die dritte - bis wir etwas falsch machen. Zum Beispiel gehen wir ein Array von 1 Million Elementen durch und zählen die Summe. Es scheint, dass dies nicht so schwierig ist, aber es kann greifbare Zeit dauern. Wenn wir uns ständig Zeit nehmen, ohne die Aufgabe freizugeben, kann unser Rendern nicht ausgeführt werden. Er schwebte in dieser Sehnsucht, und alle Arrhythmien beginnen.
Ich denke, jeder versteht, dass Arrhythmie eine ziemlich unangenehme Herzkrankheit ist. Aber du kannst immer noch mit ihm leben. Was passiert, wenn Sie eine Aufgabe platzieren, bei der einfach die gesamte Ereignisschleife in einer Endlosschleife hängt? Sie legen ein Blutgerinnsel in die Herzkranzgefäße oder eine andere Arterie, und alles wird völlig traurig. Leider wird unser Großvater Ivan Tulup sterben.
Also starb Großvater Ivan ...

Für uns bedeutet dies, dass der gesamte Tab vollständig einfriert - Sie können auf nichts klicken, und dann sagt Chrome: "Aw, Snap!"
Dies ist noch viel schlimmer als Website-Fehler, wenn etwas schief gelaufen ist. Aber wenn überhaupt alles hängen blieb und wahrscheinlich sogar die CPU geladen und der Benutzer im Allgemeinen hängen geblieben ist, wird er höchstwahrscheinlich nie wieder auf Ihre Site gehen.
Die Idee lautet daher: Wir haben eine Aufgabe, und wir müssen nicht lange an dieser Aufgabe festhalten. Wir müssen es schnell freigeben, damit der Browser, wenn überhaupt, rendern kann (wenn er will). Wenn du nicht willst - großartig, tanz!
Philip Roberts Demo: Lupe von Philip Roberts
Betrachten Sie
ein Beispiel :
$.on('button', 'click', function onClick(){ console.log('click'); }); setTimeout(function timeout() { console log("timeout"); }. 5000); console.log(“Hello world");
Das Wesentliche ist: Wir haben eine Schaltfläche, wir abonnieren sie (addEventListener), Timeout wird für 5 Sekunden aufgerufen und sofort in der console.log schreiben wir "Hallo Welt!", In setTimeout schreiben wir Timeout, in onClick schreiben wir Click.
Was passiert, wenn wir es ausführen und oft auf die Schaltfläche klicken - wann wird das Timeout tatsächlich ausgeführt? Schauen wir uns die Demo an:
Der Code beginnt auszuführen, wird auf den Stapel gesetzt, Timeout geht. In der Zwischenzeit haben wir auf den Button geklickt. Am Ende der Warteschlange wurden mehrere Ereignisse hinzugefügt. Während Click ausgeführt wird, wartet Timeout, obwohl 5 Sekunden vergangen sind.
Hier ist onClick schnell, aber wenn Sie eine längere Aufgabe stellen, friert alles ein, wie bereits erläutert. Dies ist ein sehr vereinfachtes Beispiel. Hier ist eine Runde, aber in Browsern ist tatsächlich nicht alles so.
In welcher Reihenfolge werden Ereignisse ausgeführt - was sagt die HTML-Spezifikation aus?
Sie sagt folgendes: Wir haben 2 Konzepte:
- Aufgabenquelle;
- Aufgabenwarteschlange.
Die Aufgabenquelle ist eine Art Aufgabe. Dies kann eine Benutzerinteraktion sein, dh onClick, onChange - etwas, mit dem der Benutzer interagiert. oder Zeitgeber, d. h. setTimeout und setInterval oder PostMessages; oder sogar vollständig wilde Typen wie die Canvas Blob Serialization-Taskquelle - ebenfalls ein separater Typ.
Die Spezifikation besagt, dass für dieselbe Aufgabe Quellaufgaben garantiert in der Reihenfolge ausgeführt werden, in der sie hinzugefügt werden. Für alles andere ist nichts garantiert, da es eine unbegrenzte Anzahl von Aufgabenwarteschlangen geben kann. Der Browser entscheidet, wie viele es sein werden. Mithilfe der Aufgabenwarteschlange und ihrer Erstellung kann der Browser bestimmte Aufgaben priorisieren.
Browserprioritäten und Aufgabenwarteschlangen
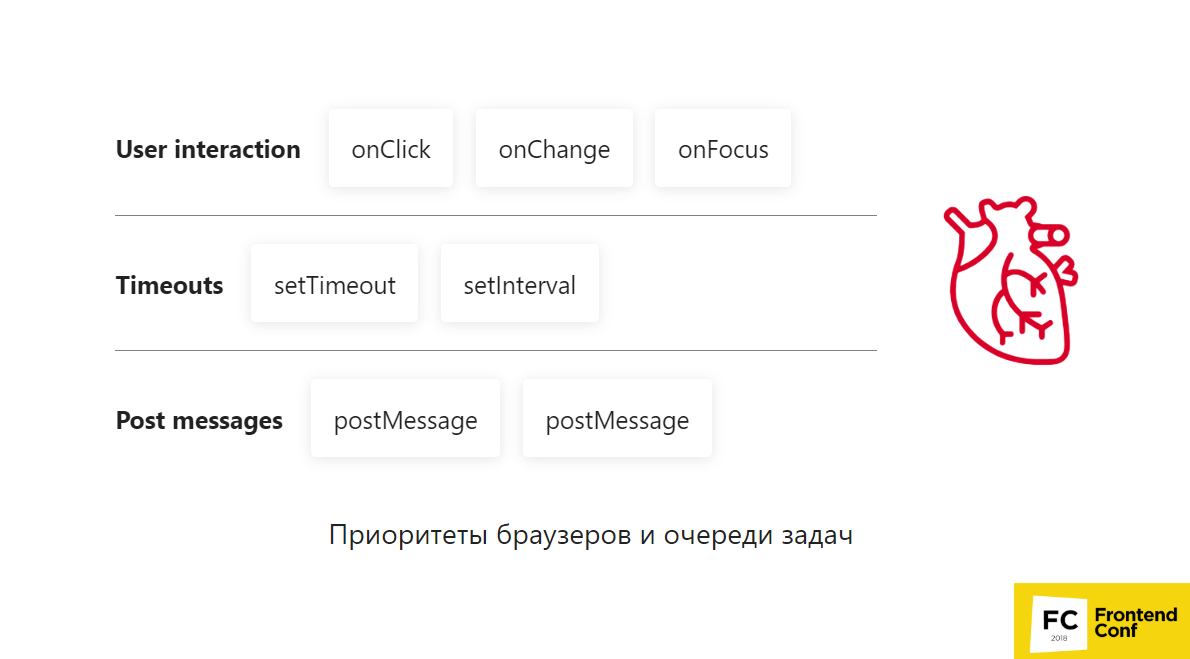
Stellen Sie sich vor, wir haben 3 Zeilen:
- Benutzerinteraktion;
- Zeitüberschreitungen
- Nachrichten posten.
Der Browser beginnt, Aufgaben aus diesen Warteschlangen abzurufen:
- Erstens übernimmt er die Fokus- Benutzerinteraktion - das ist sehr wichtig - ein Herzschlag ist vergangen.
- Dann nimmt er postMessages - na ja , postMessages hat ziemlich hohe Priorität, cool!
- Der nächste, onChange, hat ebenfalls wieder Priorität für die Benutzerinteraktion.
- Als nächstes wird onClick gesendet. Die Benutzerinteraktionswarteschlange ist beendet. Wir haben dem Benutzer alles angezeigt, was benötigt wird.
- Dann nehmen wir setInterval und fügen postMessages hinzu.
- setTimeout führt nur die aktuellste aus . Er war irgendwo am Ende der Leitung.
Dies ist wieder ein sehr vereinfachtes Beispiel, und leider kann
niemand garantieren, wie dies in Browsern funktioniert , da sie dies alles selbst entscheiden. Sie müssen dies selbst testen, wenn Sie herausfinden möchten, was es ist.
Beispielsweise hat postMessages Vorrang vor setTimeout. Möglicherweise haben Sie von so etwas wie setImmediate gehört, das beispielsweise in IE-Browsern nur nativ war. Es gibt jedoch Polydateien, die hauptsächlich nicht auf setTimeout basieren, sondern darauf, einen postMessages-Kanal zu erstellen und ihn zu abonnieren. Dies funktioniert im Allgemeinen schneller, da Browser Prioritäten setzen.
Nun, diese Aufgaben werden ausgeführt. Wann beenden wir unsere Aufgabe und verstehen, dass wir die nächste übernehmen oder rendern können?
Stapel
Der Stapel ist eine einfache Datenstruktur, die nach dem Prinzip "last in - first out" arbeitet, d.h. "Ich habe den letzten gesetzt - du bekommst den ersten
. " Das nächste, wahrscheinlich echte Gegenstück ist ein Kartenspiel. Deshalb spielt unser Großvater Ivan Tulup gerne Karten.
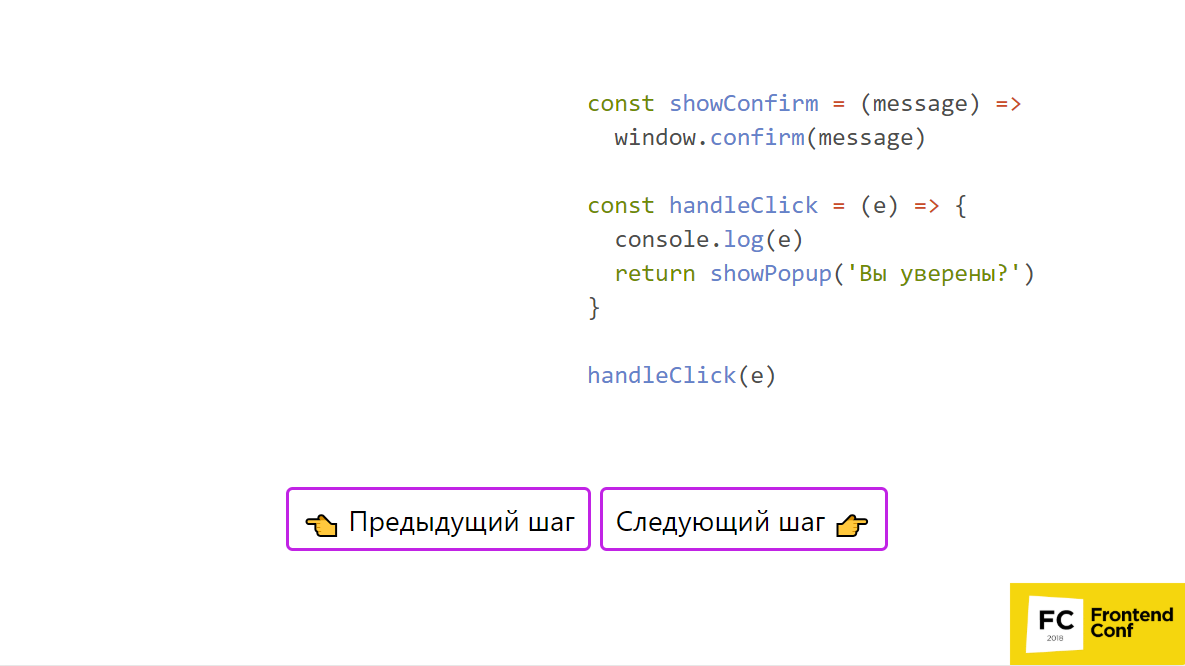
Im obigen Beispiel, in dem Code enthalten ist, kann dasselbe Beispiel in der
Präsentation verwendet werden . An einer Stelle rufen wir handleClick auf, geben console.log ein, rufen showPopup und window auf. bestätigen. Bilden wir einen Stapel.
- Also nehmen wir zuerst handleClick und schieben den Aufruf dieser Funktion auf den Stack - großartig!
- Dann gehen wir in seinen Körper und führen ihn aus.
- Wir legen console.log auf den Stack und führen es sofort aus, da alles vorhanden ist, um es auszuführen.
- Als nächstes setzen wir showConfirm - dies ist ein Funktionsaufruf - großartig.
- Wir setzen Funktionen auf den Stapel - wir setzen seinen Körper, das heißt window.confirm.
Wir haben nichts mehr - wir machen es. Ein Fenster öffnet sich: "Sind Sie sicher?", Klicken Sie auf "Ja" und alles verlässt den Stapel. Jetzt haben wir den showConfirm-Body und den handleClick-Body fertiggestellt. Unser Stapel wird gelöscht und wir können mit der nächsten Aufgabe fortfahren. Frage: OK, ich weiß jetzt, dass Sie alles in kleine Stücke zerbrechen müssen. Wie kann ich das zum Beispiel im elementarsten Fall tun?
Partitionieren eines Arrays in Chunks und asynchrone Verarbeitung
Schauen wir uns das Beispiel mit der meisten Stirn an. Ich warne Sie sofort: Bitte versuchen Sie nicht, dies zu Hause zu wiederholen - es wird nicht kompiliert.

Wir haben ein großes, großes Array und möchten etwas basierend darauf berechnen, um beispielsweise einige Binärdaten zu analysieren. Wir können es einfach in Stücke zerbrechen: Verarbeiten Sie dieses Stück, dies und das. Wir wählen die Größe des Blocks aus, zum Beispiel 10 Tausend Elemente. Wir überlegen, wie viele Blöcke wir haben werden. Wir haben eine parseData-Funktion, die CPU-gebunden ist und wirklich etwas Schweres tun kann. Dann zerlegen wir das Array in Blöcke, machen setTimeout (() => parseData (Slice), 0).
In diesem Fall kann der Browser die Benutzerinteraktion wieder priorisieren und dazwischen rendern. Das heißt, Sie geben zumindest Ihre Ereignisschleife frei und sie funktioniert weiterhin. Dein Herz schlägt weiter und das ist gut so.
Aber das ist wirklich ein sehr "Stirn" Beispiel. Es gibt viele APIs in Browsern, mit denen Sie dies auf speziellere Weise tun können.
Neben setTimeout und setInterval gibt es APIs, die über die Grenzen hinausgehen, z. B. requestAnimationFrame und requestIdleCallback.
Wahrscheinlich sind viele mit
requestAnimationFrame vertraut und verwenden es sogar bereits. Es wird vor dem Rendern ausgeführt. Sein Reiz ist, dass erstens versucht wird, alle 60 fps (oder 30 fps) auszuführen, und zweitens alles unmittelbar vor dem Erstellen des CSS-Objektmodells usw. erfolgt.

Selbst wenn Sie mehrere requestAnimationFrame haben, werden alle Änderungen gruppiert und der Frame wird vollständig ausgegeben. Im Fall von setTimeout können Sie eine solche Garantie sicherlich nicht erhalten. Ein setTimeout ändert eine Sache, die andere eine andere, und dazwischen kann das Rendern verrutschen - Sie haben ein Ruckeln auf dem Bildschirm oder etwas anderes. RequestAnimationFrame ist dafür großartig.
Darüber hinaus gibt es auch
requestIdleCallback. Vielleicht haben Sie gehört, dass es in React v16.0 (Fibre) verwendet wird. RequestIdleCallback funktioniert so, dass es cool zu sein scheint, wenn der Browser versteht, dass zwischen Frames (60 fps) Zeit ist, um etwas Nützliches zu tun, und gleichzeitig bereits alles getan hat - sie haben die Aufgabe erledigt, requestAnimationFrame -, es scheint cool zu sein kann kleine Quanten erzeugen, beispielsweise jeweils 50 ms, so dass Sie etwas tun können (IDLE-Modus).
Es befindet sich nicht im obigen Diagramm, da es sich nicht an einem bestimmten Ort befindet. Der Browser kann entscheiden, es vor dem Frame, nach dem Frame, zwischen dem requestAnimationFrame und dem Render, nach der Task, vor der Task zu platzieren. Niemand kann dies garantieren.
Es ist Ihnen garantiert, dass requestIdleCallback Ihr Ausweg ist, wenn Sie Arbeiten haben, die nicht mit dem Ändern des DOM zusammenhängen (denn dann ist requestAnimationFrame eine Animation usw.), obwohl dies keine übergeordnete Priorität, sondern greifbar ist.
Wenn wir also eine lange CPU-gebundene Operation haben, können wir versuchen, sie in Teile zu zerlegen.
- Wenn dies eine DOM-Änderung ist, verwenden Sie requestAnimationFrame.
- Wenn dies eine nicht priorisierte, kurzlebige und nicht schwierige Aufgabe ist, die die CPU nicht überlastet , fordern Sie IdleCallback an.
- Wenn wir eine große, leistungsstarke Aufgabe haben, die ständig ausgeführt werden muss, gehen wir über die Ereignisschleife hinaus und verwenden WebWorker. Es gibt keinen anderen Weg.
Aufgaben in Browsern:- Zerquetsche alles in kleine Aufgaben.
- Es gibt viele Arten von Aufgaben.
- Aufgaben werden von diesen Typen über Spezifikationswarteschlangen priorisiert.
- Browser entscheiden viel, und der einzige Weg, um zu verstehen, wie es funktioniert, besteht darin, einfach zu überprüfen, ob der eine oder andere Code ausgeführt wird.
- Die Spezifikation wird jedoch nicht immer eingehalten!
Das Problem ist, dass unser Ivan Tulup ein alter Großvater ist, weil die Event-Loop-Implementierungen in Browsern auch sehr alt sind. Sie wurden erstellt, bevor die Spezifikation geschrieben wurde, daher wird die Spezifikation leider respektiert, sofern. Selbst wenn Sie lesen, wie die Spezifikation aussehen sollte, garantiert niemand, dass alle Browser sie unterstützen. Überprüfen Sie daher unbedingt in den Browsern, wie dies tatsächlich funktioniert.
Großvater Ivan Tulup in Browsern ist eine schlecht vorhersehbare Person mit einigen interessanten Funktionen, an die Sie sich erinnern müssen.
Terminator Santa: Maskottchenschleife bei Node.js.
Node.js ist eher so jemand.

Denn einerseits ist es derselbe Großvater mit Bart, aber gleichzeitig ist alles in Phasen verteilt und es ist klar gemalt, wo was getan wird.
Phasen der Ereignisschleife in Node.js:- Timer;
- ausstehender Rückruf;
- untätig, vorbereiten;
- Umfrage;
- überprüfen;
- Rückrufe schließen.
Alles außer dem letzten ist nicht sehr klar, was es bedeutet. Die Phasen haben so seltsame Namen, weil wir unter der Haube, wie wir bereits wissen, Libuv haben, um alle zu regieren:
- Linux - Epoll / POSIX AIO;
- BSD - Warteschlange;
- Windows - IOCP;
- Solaris - Ereignisports.
Tausende von allen!
Darüber hinaus bietet Libuv dieselbe Ereignisschleife. Es hat nicht die Besonderheiten von Node.js, aber es gibt Phasen, und Node.js verwendet sie nur. Aber aus irgendeinem Grund nahm sie die Namen von dort.
Mal sehen, was jede Phase tatsächlich bedeutet.
Die Timer-Phase führt Folgendes aus:
- Rückrufbereite Timer;
- setTimeout und setInterval;
- Aber NICHT setImmediate ist eine andere Phase.
Phase ausstehende Rückrufe
Zuvor wurde in der Dokumentationsphase E / A-Rückrufe genannt. Zuletzt wurde diese Dokumentation korrigiert und widersprach sich nicht mehr. Zuvor wurde an einer Stelle geschrieben, dass E / A-Rückrufe in dieser Phase ausgeführt werden, an einer anderen - in der Abfragephase. Aber jetzt ist dort alles eindeutig und gut geschrieben. Lesen Sie also die Dokumentation - etwas wird viel verständlicher.
In der anstehenden Rückrufphase werden Rückrufe von einigen Systemoperationen (TCP-Fehler) ausgeführt. Das heißt, wenn unter Unix ein Fehler im TCP-Socket vorliegt, möchte er ihn in diesem Fall nicht sofort wegwerfen, sondern im Rückruf, der gerade in dieser Phase ausgeführt wird. Das ist alles was wir über sie wissen müssen. Wir sind praktisch nicht daran interessiert.
Phase Leerlauf, vorbereiten
In dieser Phase können wir überhaupt nichts tun, daher werden wir es im Prinzip vergessen.

Umfragephase
Dies ist die interessanteste Phase in Node.js, da sie die wichtigste nützliche Arbeit leistet:
- Führt E / A-Rückrufe durch (keine ausstehende Rückrufphase!).
- Warten auf Ereignisse von I / O;
- Es ist cool, setImmediate zu machen.
- Keine Timer;
Mit Blick auf die Zukunft wird setImmediate in der nächsten Prüfphase ausgeführt, dh vor Timern garantiert.
Außerdem steuert die Abfragephase den Ablauf der Ereignisschleife. Wenn wir zum Beispiel keine Timer haben, gibt es kein setImmediate, dh niemand hat den Timer gemacht, setImmediate hat nicht aufgerufen, wir blockieren einfach in dieser Phase und warten auf das Ereignis von I / O, wenn etwas zu uns kommt, wenn es Rückrufe gibt wenn wir uns für etwas angemeldet haben.
Wie wird ein nicht blockierendes Modell implementiert? Zum Beispiel können wir bei demselben Epoll ein Ereignis abonnieren - öffnen Sie einen Socket und warten Sie, bis etwas darauf geschrieben wird. Zusätzlich ist das zweite Argument eine Zeitüberschreitung, d.h. Wir werden auf Epoll warten, aber wenn das Timeout endet und das Ereignis von I / O nicht eintritt, wird das Timeout beendet. Wenn ein Ereignis aus dem Netzwerk zu uns kommt (jemand schreibt in den Socket), wird es kommen.
Daher ruft die Abfragephase den frühesten Rückruf vom Heap ab (der Heap ist eine Datenstruktur, die eine gut sortierte Zustellung und Zustellung ermöglicht), nimmt seine Zeitüberschreitung, schreibt in diese Zeitüberschreitung und gibt alles frei. Selbst wenn niemand in den Socket schreibt, funktioniert das Timeout, kehrt zur Abfragephase zurück und die Arbeit wird fortgesetzt.
Es ist wichtig zu beachten, dass in der Abfragephase die Anzahl der Rückrufe gleichzeitig begrenzt ist.
Es ist traurig, dass dies in den verbleibenden Phasen nicht der Fall ist. Wenn Sie eine Zeitüberschreitung von 10 Milliarden hinzufügen, fügen Sie eine Zeitüberschreitung von 10 Milliarden hinzu. Daher ist die nächste Phase die Prüfphase.
Phase prüfen
Hier wird setImmediate ausgeführt. Die Phase ist wunderschön, da setImmediate, das in der Abfragephase aufgerufen wird, garantiert früher als der Timer ausgeführt wird. Weil der Timer erst ganz am Anfang und früher in der Abfragephase auf dem nächsten Tick steht. Daher können wir keine Angst vor der Konkurrenz mit anderen Timern haben und diese Phase für die Dinge verwenden, die wir aus irgendeinem Grund nicht in einem Rückruf ausführen möchten.
Rückrufe zum Schließen der Phase
In dieser Phase werden nicht alle Rückrufe zum Schließen des Sockets und andere Typen ausgeführt:
socket.on('close', …).
Sie führt sie nur aus, wenn dieses Ereignis unerwartet flog, zum Beispiel jemand am anderen Ende schickte: "Alles - schließen Sie die Steckdose - gehen Sie von hier aus, Vasya!" Dann funktioniert diese Phase, da das Ereignis unerwartet ist. Dies betrifft uns jedoch nicht besonders.
Falsche asynchrone Verarbeitung von Chunks in Node.js
Was passiert, wenn wir das gleiche Muster, das wir in Browsern mit setTimeout verwendet haben, auf Node.js setzen - das heißt, wir teilen das Array für jeden Block, den wir setTimeout - 0 machen, in Blöcke auf.
const bigArray = [1..1_000_000] const chunks = getChunks(bigArray) const parseData = (slice) =>
Denken Sie, dass es damit Probleme gibt?
Ich bin schon ein bisschen vorausgelaufen, als ich sagte, wenn Sie 10 Tausend Timeout (oder 10 Milliarden!) Hinzufügen, befinden sich 10 Tausend Timer in der Warteschlange, und er wird sie erhalten und ausführen - es gibt keinen Schutz davor: get - execute, get - zu erfüllen und so weiter ad infinitum.
Nur in der Abfragephase, wenn wir ständig ein Ereignis von E / A erhalten, schreibt immer jemand etwas in den Socket, damit wir mindestens Timer und setImmediate ausführen können, es hat einen Grenzschutz und es ist systemabhängig. Das heißt, es wird auf verschiedenen Betriebssystemen unterschiedlich sein.
Leider haben andere Phasen, einschließlich Timer und setImmediate,
keinen solchen Schutz. Wenn Sie also wie im Beispiel vorgehen, friert alles ein und erreicht die Abfragephase für eine sehr lange Zeit nicht.
Aber glauben Sie, dass sich etwas ändern wird, wenn wir setTimeout (() => parseData (Slice), 0) durch setImmediate (() => parseData (Slice)) ersetzen? - Natürlich gibt es dort auch keinen Schutz für die Kontrollphase.
Um dieses Problem zu lösen, können Sie die
rekursive Verarbeitung aufrufen.
const parseData = (slice) =>
Unter dem Strich haben wir die Funktion parseData verwendet und ihren rekursiven Aufruf geschrieben, aber nicht nur uns selbst, sondern über setImmediate. Wenn Sie dies in der setImmediate-Phase aufrufen, wird das nächste Häkchen und nicht das aktuelle angekreuzt. Dadurch wird die Ereignisschleife freigegeben und im Kreis weitergeführt. Das heißt, wir haben recursiveAsyncParseData, wo wir einen bestimmten Index übergeben, den Block anhand dieses Index abrufen, ihn analysieren - und dann die Warteschlange setImmediate mit dem nächsten Index setzen. Es wird zu unserem nächsten Tick kommen und wir können diese ganze Sache rekursiv verarbeiten.
Das Problem ist zwar, dass dies immer noch eine Art CPU-gebundene Aufgabe ist. Vielleicht wiegt sie sich noch irgendwie und nimmt sich Zeit in Event Loop. Höchstwahrscheinlich möchten Sie, dass Ihre Node.js rein E / A-gebunden sind.
Daher ist es besser, einige andere Dinge zu verwenden, z. B. den
Prozessgabel / Thread-Pool.Jetzt wissen wir über Node.js, dass:
- alles ist in Phasen verteilt - nun, das wissen wir klar;
- Es gibt Schutz vor zu langer Abstimmungsphase, aber nicht vor dem Rest.
- rekursive Verarbeitungsmuster können angewendet werden, um die Ereignisschleife nicht zu blockieren;
- Es ist jedoch besser, Process Fork, Thread Pool und Child Process zu verwenden
Sie sollten auch mit dem Thread-Pool vorsichtig sein, da Node.js dort Dinge startet, insbesondere die DNS-Auflösung, da die DNS-Auflösungsfunktion für Linux aus irgendeinem Grund nicht asynchron ist. Daher muss es in ThreadPool ausgeführt werden. Unter Windows zum Glück nicht. Dort können Sie Dateien aber asynchron lesen. Unter Linux ist das leider unmöglich.
Meiner Meinung nach beträgt das Standardlimit 4 Prozesse in ThreadPool. Wenn Sie dort aktiv etwas tun, konkurriert es daher mit allen anderen - mit fs und anderen. Sie können ThreadPool erhöhen, aber auch sehr sorgfältig. Lesen Sie also etwas zu diesem Thema.
Mikrotask: Lungenkreislauf
Wir haben Aufgaben in Node.js und Aufgaben in Browsern. Möglicherweise haben Sie bereits von Mikrotask gehört. Mal sehen, was es ist und wie sie funktionieren, und mit Browsern beginnen.
Mikrotask in Browsern
Um zu verstehen, wie Mikrotasking funktioniert, wenden wir uns dem Ereignisschleifenalgorithmus gemäß dem whatwg-Standard zu. Gehen wir also zur Spezifikation und sehen Sie, wie alles aussieht.

In die menschliche Sprache übersetzt sieht es ungefähr so aus:
- Nehmen Sie die freie Aufgabe von unserer Linie
- Wir führen es aus
- Wir führen einen Mikrotask-Checkpoint durch - OK, wir wissen immer noch nicht, was es ist, aber wir erinnern uns daran.
- Wir aktualisieren das Rendering (falls erforderlich) und kehren zum ersten Punkt zurück.

Sie werden an der im Diagramm angegebenen Stelle und an mehreren weiteren Stellen durchgeführt, über die wir bald erfahren werden. Das heißt, die Aufgabe ist beendet, Mikrotasking wird ausgeführt.
Quellen von Mikrotuckern
Wichtig - nicht Versprechen selbst, nämlich Versprechen. Der Rückruf, der dann platziert wurde, ist eine Mikrotask. Wenn Sie dann 10 angerufen haben - Sie haben 10 Mikrowagen, dann 10 Tausend - 10 Tausend Kleinstwagen.
- Mutationsbeobachter.
- Object.observe , das veraltet ist und niemand braucht.
Wie viele verwenden den Mutationsbeobachter?
Ich denke, nur wenige verwenden den Mutationsbeobachter. Wahrscheinlich wird Promise.then häufiger verwendet, deshalb werden wir es im Beispiel betrachten.
Merkmale des Mikrotask-Checkpoints:- Wir machen alles - das bedeutet, dass wir alle Mikrotasks ausführen, die wir bis zum Ende in der Warteschlange haben. Wir lassen nichts los - wir nehmen und tun einfach alles, was ist, sie sollten mikro sein, oder?
- Sie können dabei immer noch neue Mikrotask generieren, die am selben Mikrotask-Prüfpunkt ausgeführt werden.
- Was auch wichtig ist - sie werden nicht nur nach der Ausführung der Aufgabe ausgeführt, sondern auch nach dem Reinigen des Stapels.
Dies ist ein interessanter Punkt. Es stellt sich heraus, dass es möglich ist, neue Mikrotasks zu generieren, und wir alle werden sie bis zum Ende erfüllen. Was kann uns das führen?

Wir haben zwei Herzen. Ich habe das erste Herz mit JS-Animation und das zweite mit CSS-Animation animiert. Es gibt noch eine weitere großartige Funktion namens starveMicrotasks. Wir rufen Promise.resolve auf und setzen dann die gleiche Funktion ein.
Sehen Sie in der
Präsentation, was passiert, wenn Sie diese Funktion aufrufen.
Ja, das Herz von JS wird aufhören, weil wir eine Mikrotask hinzufügen und dann eine Mikrotask hinzufügen und dann eine Mikrotask hinzufügen ... Und so endlos.
Das heißt, der rekursive Aufruf von Microtucks wird alles hängen lassen. Aber es scheint, dass ich alles asynchron habe! Es sollte losgelassen werden, ich habe dort setTimeout angerufen. Nein! Leider müssen Sie mit Mikrotask vorsichtig sein. Wenn Sie also einen rekursiven Aufruf verwenden, seien Sie vorsichtig - Sie können alles blockieren.
Wie wir uns erinnern, wird die Mikrotask außerdem am Ende der Stapelbereinigung ausgeführt. Wir erinnern uns, was ein Stapel ist. Es stellte sich heraus, dass der setTimeout-Rückruf ausgeführt wurde, sobald wir unseren Code verlassen hatten - das war's - Mikrotasks gingen genau dort hin. Dies kann zu interessanten Nebenwirkungen führen.
Betrachten Sie
ein Beispiel .

Es gibt einen Knopf und einen grauen Behälter, in dem es liegt. Wir abonnieren den Klick sowohl auf die Schaltfläche als auch auf den Container. , , , .
2 :
- Promise.resolve;
- .then, console.log('RO')
«FUS», – «DAH!» ( ).
, ? , , «FUS RO DAH!» Großartig! , .

, , . – . , - ?

! .

, .
, , , . ,
.
- — buttonHandleClick, .
- Promise.resolve. . , console.log('RO') . .
- console.log('FUS').
- buttonHandleClick . .
- , (divHandleClick) , «DAH!».
- HandleClick .
, . ?
:
- button.click(). .
- button HandleClick.
- Promise.resolve then. , Promise.resolve .
- console.log «FUS».
- buttonHandleClick , .
(click) , , . divHandleClick , , console.log('DAH!') . , .
, , button.click .
. , , . , , .
: () ( ). - , , stopPropagation. , , , , - , .
, - ( junior-) — «», promise, , then , - . ,
, : , , . . , - .
( 4) , . , , , , - . .
, :- Event Loop. Das ist unangenehm.
- , .
, . — , , .
Node.js
Node.js Promise.then process.nextTick. , — . , , , , .
process.nextTick
, process.nextTick, setImmediate? Node.js ?
. createServer, EventEmitter, , listen ( ), .
const createServer = () => { const evEmitter = new EventEmitter() return { listen: port => { evEmitter.emit('listening', port) return evEmitter } } } const server = createServer().listen(8080) server.on('listening', () => console.log('listening'))
, , 8080, listening console.log - .
, , - .
createServer, . listen, , . .
, , . Was kann getan werden? process.nextTick: evEmitter.emit('listening', port) process.nextTick(() => evEmitter.emit('listening', port)).
,
process.nextTick , . EventEmitter, . , , API, . process.nextTick, emit , userland . createServer, , listen, listening. — process.nextTick — ! , , .
process.nextTick . , .
, process.nextTick , Promise.then . process.nextTick , — , Event Loop, Node.js. , , .
process.nextTick , ghbvtybnm setImmediate , C++ .. process.nextTick .
Async/await
API — async/await, - . . , async/await Promise, Event Loop . , .
Nützliche Links
, !Frontend Conf — 4 5 , . , :
Komm, es wird interessant sein!