Nur wenige Menschen haben einen Glaster in Russland, und jede Erfahrung ist interessant. Wir haben es groß und industriell und nach der Diskussion im
letzten Beitrag nachgefragt. Ich habe über den Anfang der Erfahrung mit der Migration von Backups vom Enterprise-Speicher auf Glusterfs gesprochen.
Das ist nicht hardcore genug. Wir hörten nicht auf und beschlossen, etwas Ernsthafteres zu sammeln. Daher werden wir hier über Dinge wie Löschcodierung, Sharding, Neuausgleich und dessen Drosselung, Stresstests usw. sprechen.

- Mehr Volum / Subwolum-Theorie
- heißes Ersatzteil
- heilen / heilen / wieder ins Gleichgewicht bringen
- Schlussfolgerungen nach dem Neustart von 3 Knoten (niemals tun)
- Wie wirkt sich das Aufzeichnen mit unterschiedlichen Geschwindigkeiten von verschiedenen VMs und das Ein- und Ausschalten des Shards auf die Subvolumenlast aus?
- Neuausgleich nach dem Verlassen der Scheibe
- schnelles Gleichgewicht
Was wolltest du?
Die Aufgabe ist einfach: ein billiges, aber zuverlässiges Geschäft zu sammeln. Günstig wie möglich, zuverlässig - damit es nicht unheimlich wird, eigene Dateien zum Verkauf darauf zu speichern. Tschüss. Dann nach langen Tests und Backups auf einem anderen Speichersystem - auch auf Client-Systemen.
Anwendung (sequentielle E / A) :
- Backups
- Testinfrastrukturen
- Testen Sie den Speicher für schwere Mediendateien.
Wir sind hier
- Battle File und ernsthafte Testinfrastruktur
- Speicherung wichtiger Daten.
Wie beim letzten Mal ist die Hauptanforderung die Netzwerkgeschwindigkeit zwischen Glaster-Instanzen. 10G ist zunächst in Ordnung.
Theorie: Was ist dispergiertes Volumen?
Das verteilte Volume basiert auf der Erasure Coding (EC) -Technologie, die einen ziemlich wirksamen Schutz gegen Festplatten- oder Serverausfälle bietet. Es ist wie RAID 5 oder 6, aber nicht wirklich. Es speichert das codierte Fragment der Datei für jeden Baustein so, dass nur eine Teilmenge der in den verbleibenden Briks gespeicherten Fragmente erforderlich ist, um die Datei wiederherzustellen. Die Anzahl der Bausteine, die ohne Verlust des Zugriffs auf Daten möglicherweise nicht verfügbar sind, wird vom Administrator während der Erstellung des Volumes konfiguriert.
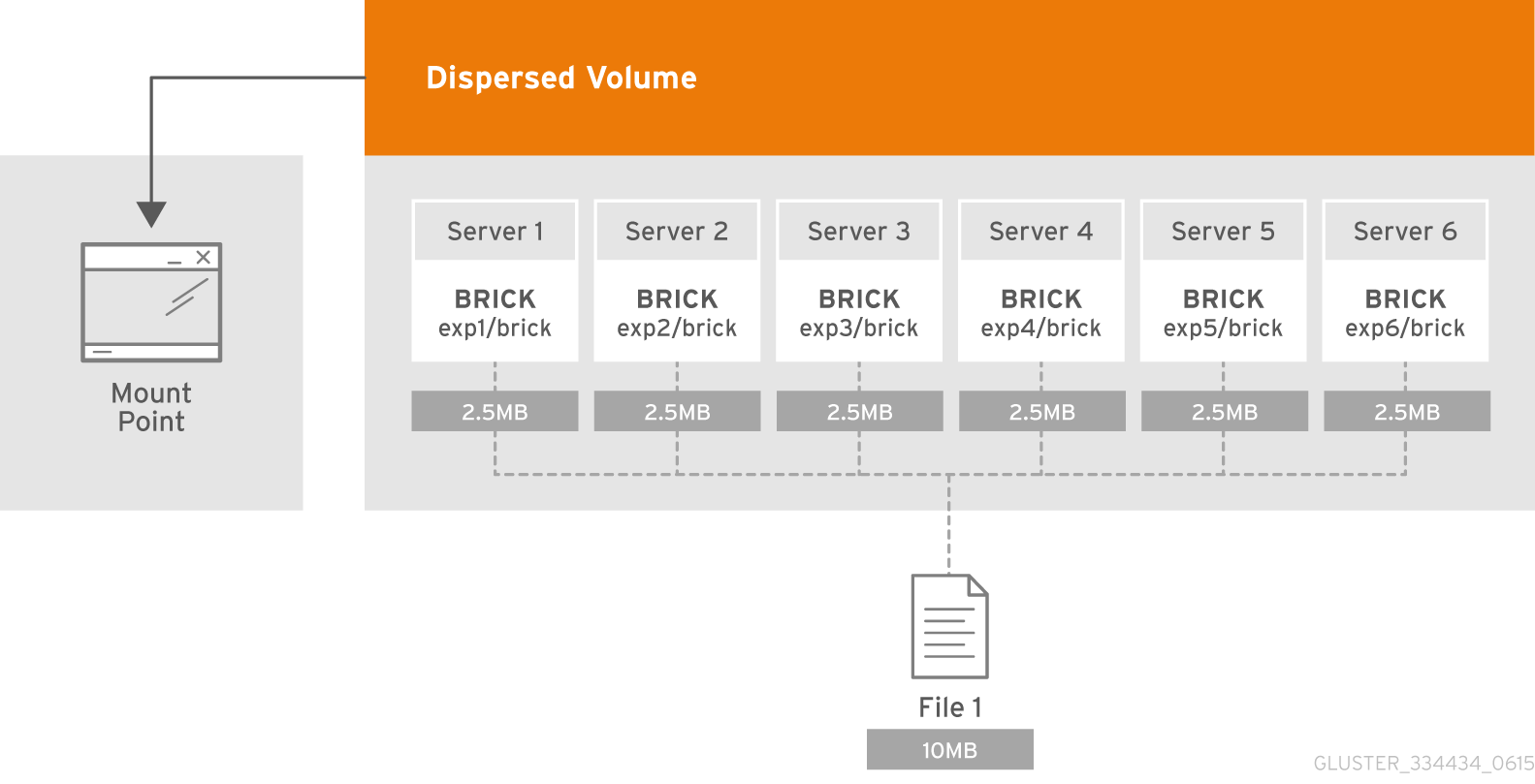
Was ist ein Subvolumen?
Die Essenz des Subvolumens in der GlusterFS-Terminologie manifestiert sich zusammen mit verteilten Volumes. Bei der verteilten Löschung funktioniert die Codierung nur im Rahmen des Subwoofers. Und im Fall von beispielsweise verteilten replizierten Daten werden Daten im Rahmen des Subwoofers repliziert.
Jeder von ihnen ist auf verschiedenen Servern verteilt, wodurch sie frei verlieren oder zur Synchronisierung ausgeben können. In der Abbildung sind die Server (physisch) grün markiert, die Subwölfe sind gepunktet. Jeder von ihnen wird dem Anwendungsserver als Datenträger (Volume) angezeigt:

Es wurde entschieden, dass die verteilte 4 + 2-Konfiguration auf 6 Knoten ziemlich zuverlässig aussieht. Wir können 2 Server oder 2 Festplatten in jedem Subwoofer verlieren, während wir weiterhin Zugriff auf Daten haben.
Wir verfügten über 6 alte DELL PowerEdge R510 mit 12 Festplattensteckplätzen und 3,5 x SATA-Laufwerken mit 48 x 2 TB. Wenn es einen Server mit 12 Festplattensteckplätzen gibt und bis zu 12 TB Laufwerke auf dem Markt sind, können wir im Prinzip Speicher mit bis zu 576 TB nutzbarem Speicherplatz sammeln. Vergessen Sie jedoch nicht, dass die maximale Festplattengröße von Jahr zu Jahr weiter zunimmt, die Leistung jedoch stillsteht und ein Neuaufbau einer 10-12-TB-Festplatte eine Woche dauern kann.
 Volumenerstellung:
Volumenerstellung:Eine ausführliche Beschreibung zur Herstellung von Ziegeln finden Sie in meinem
vorherigen Beitraggluster volume create freezer disperse-data 4 redundancy 2 transport tcp \ $(for i in {0..7} ; do echo {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)
Wir erstellen, aber wir haben es nicht eilig zu starten und zu mounten, da wir noch einige wichtige Parameter anwenden müssen.
Was wir haben: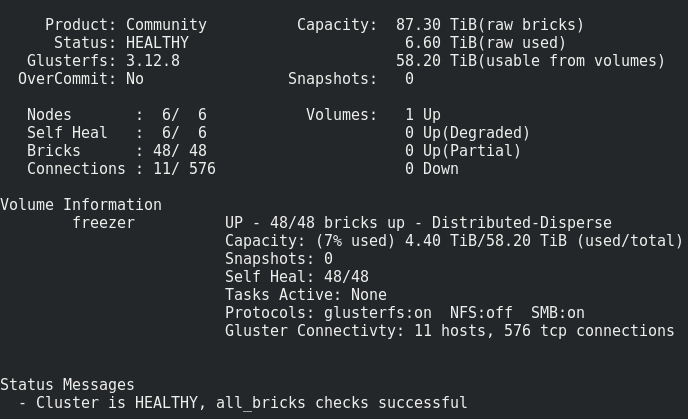
Alles sieht ganz normal aus, aber es gibt eine Einschränkung.
Es besteht darin, ein solches Volumen auf den Steinen aufzunehmen:Dateien werden einzeln in den Subwölfen abgelegt und nicht gleichmäßig über sie verteilt. Daher werden wir früher oder später auf ihre Größe und nicht auf die Größe des gesamten Volumes stoßen. Die maximale Dateigröße, die wir in dieses Repository einfügen können, ist die verwendbare Größe des Subwoofers abzüglich des bereits belegten Speicherplatzes. In meinem Fall ist es <8 Tb.
Was tun? Wie soll ich sein?Dieses Problem wird durch Sharding oder Streifenvolumen gelöst, aber wie die Praxis gezeigt hat, funktioniert der Streifen sehr schlecht.
Deshalb werden wir versuchen zu scherben.
Was ist Splitter, im Detail hier .
Was ist Scherben, kurz gesagt :
Jede Datei, die Sie in ein Volume einfügen, wird in Teile (Shards) unterteilt, die in Subwölfen relativ gleichmäßig angeordnet sind. Die Größe des Shards wird vom Administrator festgelegt, der Standardwert beträgt 4 MB.
Aktivieren Sie das Sharding, nachdem Sie ein Volume erstellt haben, aber bevor es beginnt :
gluster volume set freezer features.shard on
Wir stellen die Größe der Scherbe ein (was ist optimal? Jungs von oVirt empfehlen 512 MB) :
gluster volume set freezer features.shard-block-size 512MB
Empirisch stellt sich heraus, dass die tatsächliche Größe des Splitters in den Ziegeln unter Verwendung des dispergierten Volumens 4 + 2 gleich der Splitterblockgröße / 4 ist, in unserem Fall 512 M / 4 = 128 M.
Jeder Shard gemäß der Löschcodierungslogik wird gemäß den Bausteinen im Rahmen der Unterwelt mit diesen Teilen zerlegt: 4 * 128M + 2 * 128M
Zeichnen Sie die Fehlerfälle, die Gluster mit dieser Konfiguration überlebt:In dieser Konfiguration können wir den Fall von 2 Knoten oder 2 von Datenträgern innerhalb desselben Subvolumens überleben.
Für Tests haben wir uns entschlossen, den resultierenden Speicher in unsere Cloud zu verschieben und fio von virtuellen Maschinen aus auszuführen.
Wir aktivieren die sequentielle Aufzeichnung von 15 VMs und gehen wie folgt vor.
Neustart des 1. Knotens:17:09
Es sieht unkritisch aus (~ 5 Sekunden Nichtverfügbarkeit durch den Parameter ping.timeout).
17:19
Startete Heilung voll.
Die Anzahl der Heilungseinträge nimmt nur zu, wahrscheinlich aufgrund des hohen Schreibaufwands für den Cluster.
17:32
Es wurde beschlossen, die Aufzeichnung von der VM aus zu deaktivieren.
Die Anzahl der Heilungseinträge begann zu sinken.
17:50
heilen getan.
Starten Sie 2 Knoten neu:Es werden die gleichen Ergebnisse wie beim 1. Knoten beobachtet.Starten Sie 3 Knoten neu:Mountpunkt ausgegeben Transportendpunkt ist nicht verbunden, VMs haben Fehler erhalten.
Nach dem Einschalten der Knoten stellte sich der Glaster ohne Störung von unserer Seite wieder her und der Behandlungsprozess begann.4 von 15 VMs konnten jedoch nicht steigen. Ich habe Fehler auf dem Hypervisor gesehen:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic... 2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})... 2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized Traceback (most recent call last): File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started c2.qemu.volumes.attach(controller.qemu(), device) File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach c2.qemu.query(qemu, drive_meth, drive_args) File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging) File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query message["error"].get("desc", "Unknown error") QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
Harte Auszahlung 3 Knoten mit deaktiviertem Sharding Transport endpoint is not connected (107) /GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)
Wir verlieren auch Daten, eine Wiederherstellung ist nicht möglich.
Zahle 3 Knoten vorsichtig mit Sharding zurück. Wird es zu Datenbeschädigungen kommen?Es gibt, aber viel weniger (Zufall?), Ich habe 3 von 30 Laufwerken verloren.
Schlussfolgerungen:- Die Heilung dieser Dateien hängt endlos, ein Ausgleich hilft nicht. Wir schließen daraus, dass die Dateien, für die beim Ausschalten des 3. Knotens eine aktive Aufzeichnung durchgeführt wurde, für immer verloren gehen.
- Laden Sie niemals mehr als 2 Knoten in einer 4 + 2-Konfiguration in der Produktion neu!
- Wie können Sie keine Daten verlieren, wenn Sie wirklich mehr als 3 Knoten neu starten möchten? P Beenden Sie die Aufnahme am Einhängepunkt und / oder stoppen Sie die Lautstärke.
- Knoten oder Steine sollten so schnell wie möglich ersetzt werden. Zu diesem Zweck ist es sehr wünschenswert, zum Beispiel 1-2 a la Hot-Spare-Steine in jedem Knoten für einen schnellen Austausch zu haben. Und noch ein Ersatzknoten mit Bausteinen für den Fall eines Knotendumps.
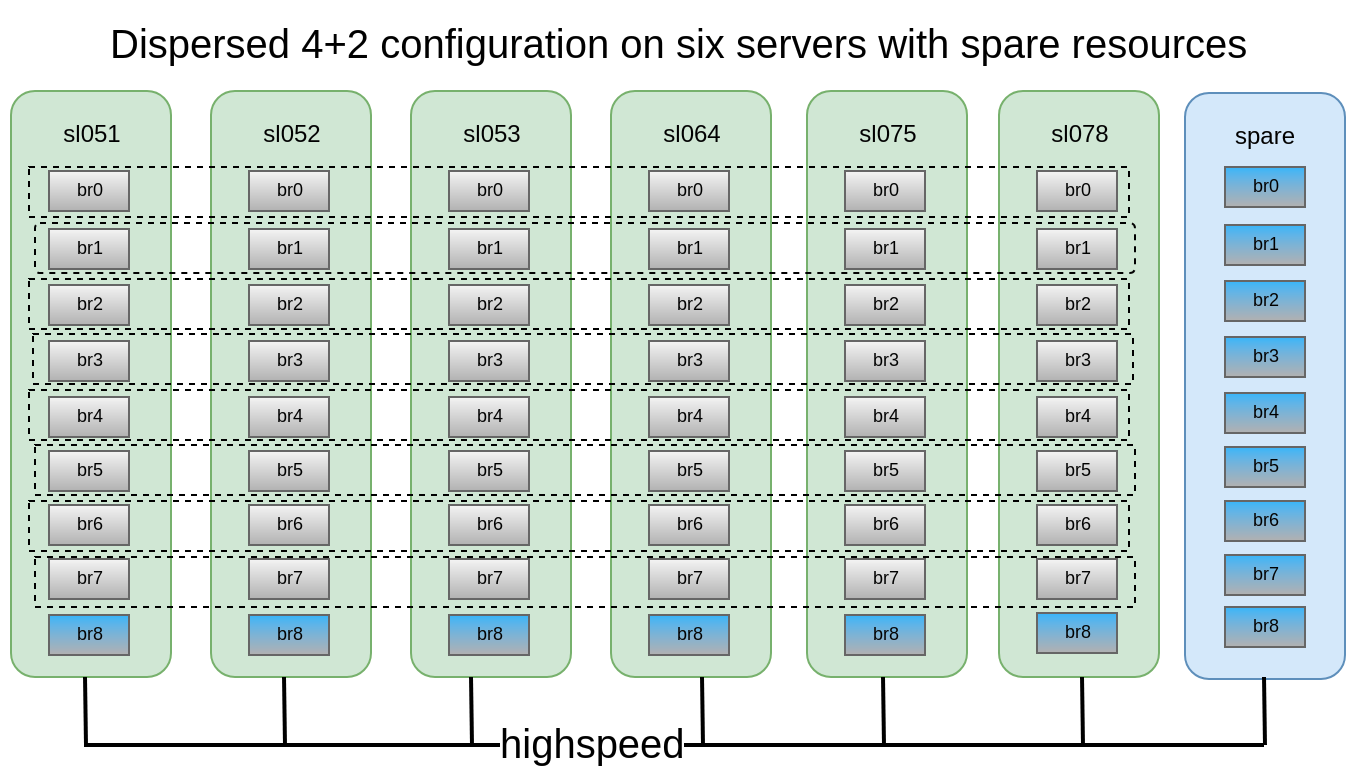
Es ist auch sehr wichtig, Antriebsersatzfälle zu testen
Abfahrten von Briks (Scheiben):
17:20Wir schlagen einen Ziegelstein aus:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick6
17:22 gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit force
Sie können einen solchen Drawdown zum Zeitpunkt des Austauschs des Bausteins sehen (Aufzeichnung aus 1 Quelle):

Der Ersetzungsprozess ist ziemlich lang, mit einer geringen Aufzeichnungsstufe pro Cluster und Standardeinstellungen von 1 TB dauert die Wiederherstellung etwa einen Tag.
Einstellbare Parameter für die Behandlung: gluster volume set cluster.background-self-heal-count 20
Option: zerstreuen. Hintergrundheilungen
Standardwert: 8
Beschreibung: Mit dieser Option können Sie die Anzahl der parallelen Heilungen steuern
Option: disperse.heal-wait-qlength
Standardwert: 128
Beschreibung: Mit dieser Option können Sie die Anzahl der Heilungen steuern, die warten können
Option: disperse.shd-max-threads
Standardwert: 1
Beschreibung: Maximale Anzahl paralleler Heilungen, die SHD pro lokalem Stein ausführen kann. Dies kann die Heilungszeiten erheblich verkürzen, aber auch Ihre Steine zerdrücken, wenn Sie nicht über die dafür erforderliche Speicherhardware verfügen.
Option: disperse.shd-wait-qlength
Standardwert: 1024
Beschreibung: Mit dieser Option können Sie die Anzahl der Heilungen steuern, die in SHD pro Subvolumen warten können
Option: disperse.cpu-Erweiterungen
Standardwert: auto
Beschreibung: Erzwingen Sie, dass die CPU-Erweiterungen verwendet werden, um die Galois-Feldberechnungen zu beschleunigen.
Option: disperse.self-heal-window-size
Standardwert: 1
Beschreibung: Maximale Anzahl von Blöcken (128 KB) pro Datei, für die gleichzeitig ein Selbstheilungsprozess angewendet wird.Stand:
disperse.shd-max-threads: 6 disperse.self-heal-window-size: 4 cluster.self-heal-readdir-size: 2KB cluster.data-self-heal-algorithm: diff cluster.self-heal-window-size: 2 cluster.heal-timeout: 500 cluster.background-self-heal-count: 20 cluster.disperse-self-heal-daemon: enable disperse.background-heals: 18
Mit neuen Parametern wurde 1 TB Daten in 8 Stunden fertiggestellt (dreimal schneller!)
Der unangenehme Moment ist, dass das Ergebnis ein größerer Brik ist als es warwar: Filesystem Size Used Avail Use% Mounted on /dev/sdd 1.9T 645G 1.2T 35% /export/brick2
wurde: Filesystem Size Used Avail Use% Mounted on /dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0
Es ist notwendig zu verstehen. Wahrscheinlich bläst das Ding dünne Scheiben auf. Mit dem anschließenden Austausch des erhöhten Ziegels blieb die Größe gleich.
Neuausrichtung:Nach dem Erweitern oder Verkleinern (ohne Migrieren von Daten) eines Volumes (mit den Befehlen add-paint bzw. remove-paint) müssen Sie die Daten zwischen den Servern neu verteilen. In einem nicht replizierten Volume sollten alle Bausteine aktiv sein, um den Ersetzungsvorgang auszuführen (Startoption). In einem replizierten Volume sollte mindestens einer der Bausteine im Replikat aktiv sein.Ausgleich gestalten:Option: cluster.rebal-throttle
Standardwert: normal
Beschreibung: Legt die maximale Anzahl paralleler Dateimigrationen fest, die auf einem Knoten während des Neuausgleichsvorgangs zulässig sind. Der Standardwert ist normal und erlaubt maximal [($ (Verarbeitungseinheiten) - 4) / 2), 2] Dateien zu b
Wir sind gleichzeitig migriert. Lazy erlaubt jeweils nur die Migration einer Datei und aggressiv erlaubt maximal [($ (Verarbeitungseinheiten) - 4) / 2), 4]Option: cluster.lock-Migration
Standardwert: aus
Beschreibung: Wenn diese Funktion aktiviert ist, werden die mit einer Datei verknüpften Posix-Sperren während des Neuausgleichs migriertOption: cluster.weighted-rebalance
Standardwert: ein
Beschreibung: Wenn diese Option aktiviert ist, werden Dateien mit einer Wahrscheinlichkeit proportional zu ihrer Größe den Bausteinen zugewiesen. Andernfalls haben alle Steine die gleiche Wahrscheinlichkeit (Legacy-Verhalten).Vergleich des Schreibens und anschließenden Lesens derselben fio-Parameter (detailliertere Ergebnisse von Leistungstests - in PM): fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000


 Wenn es interessant ist, vergleichen Sie die Rsync-Geschwindigkeit mit dem Verkehr zu den Glaster-Knoten:
Wenn es interessant ist, vergleichen Sie die Rsync-Geschwindigkeit mit dem Verkehr zu den Glaster-Knoten: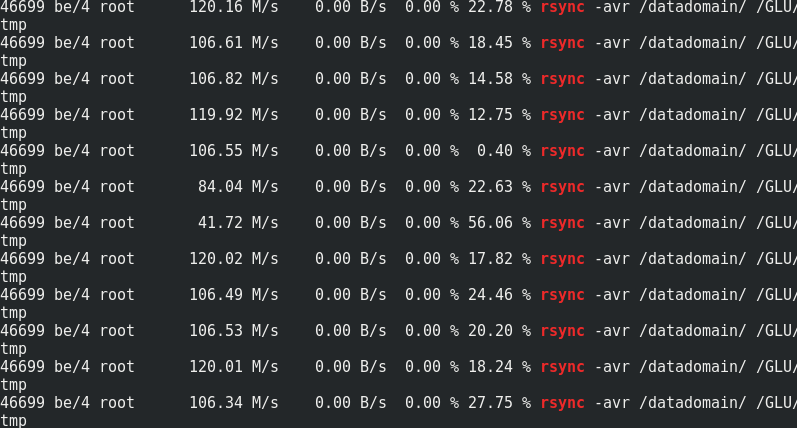
 Es ist ersichtlich, dass ungefähr 170 MB / s / Verkehr bis 110 MB / s / Nutzlast. Es stellt sich heraus, dass dies 33% des zusätzlichen Datenverkehrs sowie 1/3 der Redundanz der Löschcodierung sind.Der Speicherverbrauch auf der Serverseite mit und ohne Last ändert sich nicht:
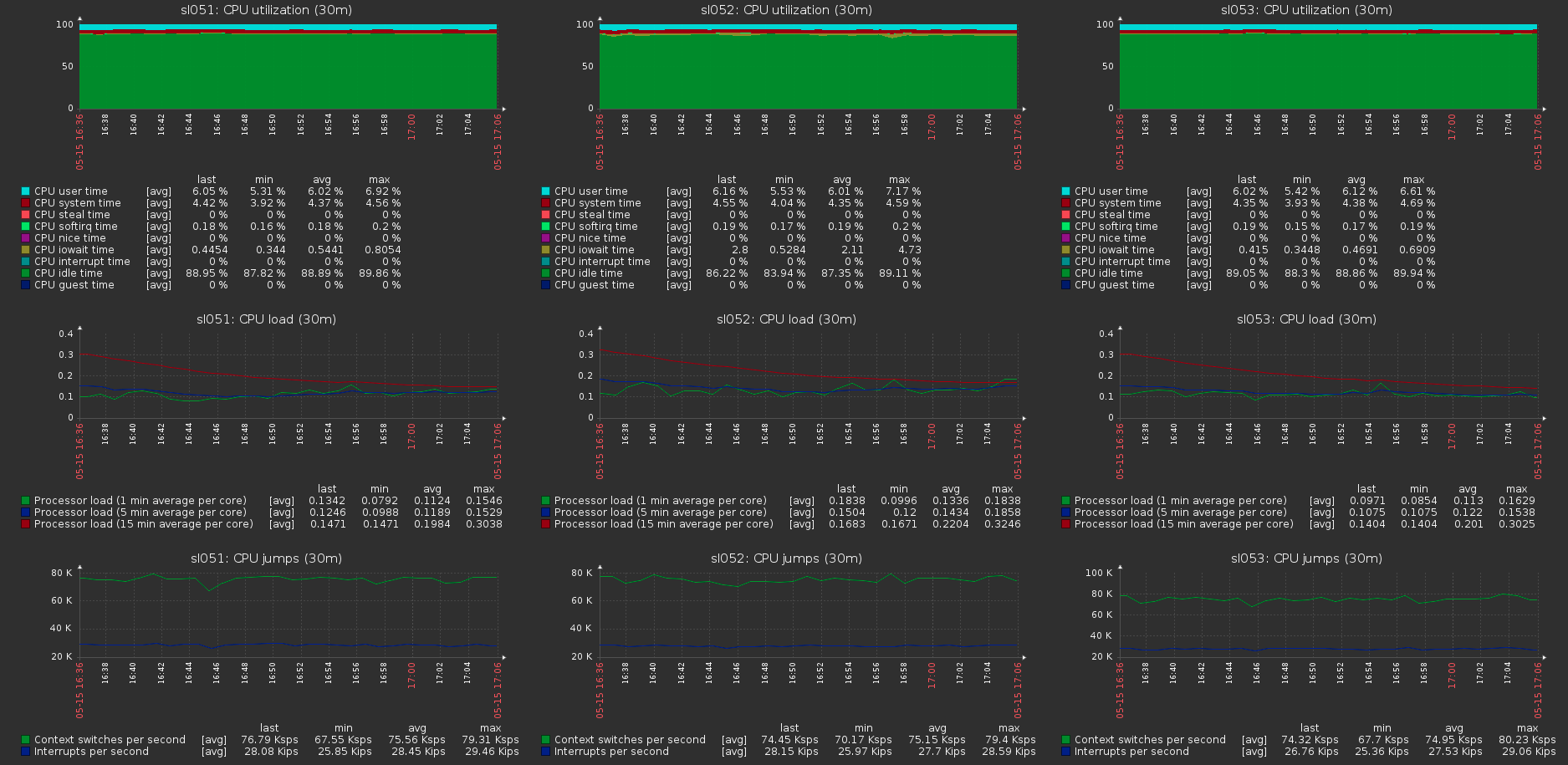
Es ist ersichtlich, dass ungefähr 170 MB / s / Verkehr bis 110 MB / s / Nutzlast. Es stellt sich heraus, dass dies 33% des zusätzlichen Datenverkehrs sowie 1/3 der Redundanz der Löschcodierung sind.Der Speicherverbrauch auf der Serverseite mit und ohne Last ändert sich nicht: Die Last auf den Cluster-Hosts mit der maximalen Last auf dem Volume:
Die Last auf den Cluster-Hosts mit der maximalen Last auf dem Volume: