
2014 trat ich als 6. Data Science-Spezialist in diesem Unternehmen dem kleinen Team der Schibsted Media Group bei. Seitdem habe ich in einer Organisation mit mehr als 40 Mitarbeitern an vielen Unternehmungen auf dem Gebiet der Datenwissenschaft gearbeitet. In diesem Beitrag werde ich über einige Dinge sprechen, die ich in den letzten vier Jahren gelernt habe, zuerst als Spezialist und dann als Manager von Data Science.
Dieser Beitrag folgt dem Beispiel von Robert Chang und seinem ausgezeichneten Artikel „ Doing Data Science in Twitter “, den ich sehr wertvoll fand, als ich ihn 2015 zum ersten Mal las. Der Zweck meines eigenen Beitrags ist es, gleichermaßen nützliche Gedanken mit Data Science-Spezialisten und -Managern auf der ganzen Welt zu teilen.
Ich habe den Beitrag in zwei Teile geteilt:
- Teil I: Datenwissenschaft im wirklichen Leben
- Teil II: Leitung des Data Science-Teams
In Teil I habe ich mich auf die Arbeit konzentriert, die Data Science-Experten tatsächlich leisten, während in Teil II erläutert wird, wie das Data Science-Team so effizient wie möglich verwaltet werden kann. Ich würde sagen, dass beide Teile sowohl für Spezialisten als auch für Manager wichtig sind.
Ich werde nicht viel Zeit damit verbringen zu beschreiben, wer und wer der Data Science-Spezialist ist und wer nicht - im Internet gibt es genügend Artikel zu diesem Thema.
Kurz zu Schibsted: Medien und Marktplätze in mehr als 20 Ländern weltweit. Ich arbeite hauptsächlich an unserem Geschäft mit Marktplätzen, auf denen täglich Millionen von Menschen Waren kaufen und verkaufen. Wenn Sie sich einige Beispiele aus der Praxis der datenwissenschaftlichen Arbeit bei Schibsted ansehen möchten, finden Sie hier eine kleine Auswahl:
Lassen Sie uns in diesem Sinne eintauchen!
Teil I: Datenwissenschaft im wirklichen Leben
Es ist wirklich großartig, als Data Science-Spezialist in einem neuen Unternehmen mit großen Ambitionen zu beginnen, aber es kann auch beängstigend wirken. Was erwarten die Leute um mich herum? Welche Fähigkeiten werden meine Kollegen haben? Wie arbeite ich, um dem Unternehmen zu dienen? In einer Position, in der es so viel Hype gibt, ist es manchmal schwierig, sich nicht wie ein Betrüger zu fühlen.
Die Angst, ein Simpleton zu sein, veranlasst einen Data Science-Experten häufig, sich hauptsächlich auf die Komplexität zu konzentrieren. Dies führt uns zu der ersten Schlussfolgerung.
1.1. Schwierigkeit erhöht den Wert, einfach anfangen
Sie haben einen Data Science-Spezialisten eingestellt, also muss dieses Problem sicherlich sehr komplex sein, oder?

Diese Annahme führt Sie als Data Science-Spezialist häufig in die Irre. Erstens werden die Probleme, auf die Sie im Geschäftsleben stoßen, sehr oft mit relativ einfachen Methoden gelöst. Zweitens ist es wichtig, sich daran zu erinnern, dass Komplexität den Wert erhöht. Ein komplexes Modell erfordert wahrscheinlich mehr Arbeit bei seiner Implementierung, ein höheres Fehlerrisiko und größere Schwierigkeiten bei der Erklärung gegenüber Kunden. Daher sollten Sie immer zuerst nach dem einfachsten Ansatz suchen.
Aber wie kann man verstehen, ob der einfachste Ansatz ausreicht?
1.2. Haben Sie immer ein Basismodell
Schätzungen der Qualität Ihres Modells sind allein ohne Vergleich mit dem Basismodell höchstwahrscheinlich nicht sinnvoll. Ein Vergleich mit der Genauigkeit bei zufälliger Auswahl reicht in den meisten Fällen einfach nicht aus.

Irgendwann haben wir ein Modell erstellt, um die Wahrscheinlichkeit vorherzusagen, dass ein Benutzer zu unserer Site zurückkehrt - das Rückgabemodell. In unserem Modell wurden ungefähr 15 Attribute basierend auf dem Benutzerverhalten verwendet, und wir erreichten eine Genauigkeit von ungefähr ~ 0,8 ROC-AUC. Im Vergleich zur Genauigkeit der Zufallsvorhersage (0,5) waren wir mit diesem Ergebnis sehr zufrieden. Als wir jedoch alles aus dem Modell geworfen haben, mit Ausnahme der beiden wichtigsten Anzeichen: kürzlich (Anzahl der Tage seit dem letzten Besuch) und Häufigkeit (Anzahl der Besuchstage in der Vergangenheit), stellten wir fest, dass eine einfache logistische Regression dieser beiden Variablen eine ROC-AUC von 78% ergab ! Mit anderen Worten, wir könnten mehr als 97% der Leistung erzielen, indem wir mehr als 85% der Attribute wegwerfen.
Ich habe so oft gesehen, wie Data Science-Experten die Ergebnisse von Offline-Experimenten an komplexen Modellen ohne ein einfaches Basismodell zum Vergleich zeigen. Wenn Sie dies sehen, sollten Sie sich immer fragen: Können wir mit einem viel einfacheren Modell das gleiche Ergebnis erzielen?
1.3. Verwenden Sie die Daten, die Sie haben
Ich habe einmal mit einem Dateningenieur und einem anderen Data Science-Spezialisten zu Mittag gegessen. Die Augen des letzteren leuchteten auf, als er über all die erstaunlichen Dinge sprach, die er tun konnte, „wenn er nur Daten zu X, Y oder Z hätte“. Irgendwann während des Gesprächs lachte der Ingenieur: "Sie, Data Science-Experten, sprechen immer darüber, was Sie mit Daten tun können, die Sie nicht haben. Wie wäre es mit etwas mit den Daten, die Sie haben? "

Es klang unhöflich, aber der Ingenieur drückte eine wichtige Wahrheit aus. Sie werden nie den perfekten Datensatz haben und es wird immer Daten geben, die Sie verwenden könnten. In den meisten Fällen können Sie etwas mit dem tun, was Sie haben.
1.4 Übernehmen Sie die Verantwortung für Daten
Wie oben erwähnt, sind Datenqualität und Vollständigkeit fast immer ein Problem. Aber anstatt zu sitzen und darauf zu warten, dass Ihnen jemand Daten auf einem Silbertablett präsentiert, müssen Sie sprechen und die Verantwortung für die Daten übernehmen, die Sie benötigen.

Ich spreche nicht von formaler Eigenverantwortung im Sinne eines Datenverwaltungsmodells. Ich spreche davon, meine Rolle zu erweitern und nach Möglichkeit zu helfen, die Daten zu erhalten, die Sie benötigen.
Dies kann bedeuten, dass Sie an der Erstellung von Datenerfassungsschemata und -formaten teilnehmen. Dies kann bedeuten, dass Sie sich den Javascript-Code ansehen, der in der Webanwendungsoberfläche ausgeführt wird, um sicherzustellen, dass Ereignisse ausgelöst werden, wenn dies erforderlich ist. Oder es könnte bedeuten, Datenpipelines zu erstellen, ohne darauf zu warten, dass die Dateningenieure alles für Sie tun.
1.5. Vergiss die Daten
Dies widerspricht natürlich allem, was ich oben gesagt habe, aber es ist sehr wichtig, sich nicht zu sehr auf die Daten zu konzentrieren, die Sie haben.

Wenn ein neues Problem auftritt, sollten Sie zunächst versuchen, die vorhandenen Daten zu vergessen. Warum so? Ja, da Ihre vorhandenen Daten den Entscheidungsspielraum einschränken können und Sie dadurch davon abgehalten werden, den besten Ansatz zu finden. Sie befinden sich in einem lokalen Optimum, in dem Sie versuchen, die Lösung für jedes Problem in dem Datensatz zu finden, das Ihnen zur Verfügung steht (Verwendung über das Lernen hinaus). Infolgedessen werden Sie niemals neue Datensätze haben.
1.6. Entwickeln Sie ein detailliertes Verständnis der Kausalität
Wir alle wissen, dass Korrelation keinen Kausalzusammenhang impliziert. Das Problem ist, dass viele Data Science-Experten damit aufhören und Angst haben, die Ursache mit der Wirkung in Beziehung zu setzen.

Warum ist das ein Problem? Weil die Produktmanager, das Marketingteam, Ihr CEO oder die Personen, mit denen Sie dort zusammenarbeiten, sich überhaupt keine Sorgen um die Korrelation machen. Sie kümmern sich um einen Kausalzusammenhang.
Der Produktmanager möchte sicher sein, dass er bei der Veröffentlichung dieser neuen Funktion eine 10% ige Steigerung der Produktbeteiligung auslöst. Das Marketing-Team möchte wissen, dass eine Erhöhung der Anzahl der Briefe von 2 pro Woche auf 4 die Benutzer nicht dazu zwingt, sich vom Newsletter abzumelden. Und der CEO möchte wissen, dass Investitionen in eine bessere Ausrichtung zu einer Steigerung der Werbeeinnahmen führen.
Gibt es eine Kompromisslösung? Es stellt sich heraus, dass es zwei davon gibt.
Die bekanntesten Online-Experimente. Tatsächlich führen Sie randomisierte Studien durch, darunter die beliebtesten A / B-Tests. Die Idee ist einfach: Da wir versehentlich ausgewählt haben, wer in der Zielgruppe und wer in der Kontrollgruppe sein wird, kann die von uns verwendete „Behandlung“ als Grund angesehen werden, wenn wir einen statistisch signifikanten Unterschied zwischen den Gruppen feststellen. In der Praxis ist dies eine vernünftige Annahme, ohne auf philosophisches Denken einzugehen.
Ein weniger bekannter Ansatz zur Suche nach Kausalzusammenhängen ist die Kausalmodellierung. Die Idee dabei ist, dass Sie Annahmen über die Kausalstruktur der Welt treffen und dann Beobachtungsdaten (nicht experimentell) verwenden, um zu überprüfen, ob diese Annahmen mit den Daten übereinstimmen, oder um die Stärke verschiedener Ursache-Wirkungs-Beziehungen zu bewerten. Adam Kelleher hat eine großartige Artikelserie mit dem Titel „ Causal Data Science “ geschrieben, die ich zum Lesen empfehle. Darüber hinaus ist die Kausalitätsbibel das Buch Kausalität von Judea Pearl.
Nach meiner Erfahrung verfügen die meisten Data Science-Experten über umfangreiche Erfahrung in der Erstellung von Modellen für maschinelles Lernen und deren Offline-Bewertung. Weit weniger Menschen haben Erfahrung mit Online-Bewertungen und Experimenten. Die Erklärung ist einfach: Sie können den Datensatz von Kaggle herunterladen, das Modell trainieren und es in wenigen Minuten offline auswerten. Um dieses Modell online bewerten zu können, benötigen Sie hingegen Zugriff auf die reale Welt. Selbst wenn Sie in einem Internetunternehmen mit Millionen von Benutzern arbeiten, müssen Sie häufig viele Hindernisse überwinden, um Ihr Modell des maschinellen Lernens den Benutzern zugänglich zu machen.
Während nur wenige Data Science-Experten über umfangreiche Online-Bewertungserfahrung verfügen, haben nur sehr wenige Erfahrung mit der kausalen Modellierung. Ich denke, es gibt viele gute Gründe. Einer der Gründe ist, dass die meisten Bücher über Kausalität ziemlich theoretisch sind, darunter gibt es nur wenige praktische Richtlinien, wie man mit der kausalen Modellierung in der realen Welt beginnt. Ich gehe davon aus, dass wir in den nächsten Jahren mehr praktische Richtlinien für die kausale Modellierung sehen werden.
Durch die Entwicklung eines detaillierten Verständnisses der Kausalität können Sie Ihren Kunden praktische Empfehlungen geben und gleichzeitig Ihre Integrität als Spezialist für Data Science unterstützen.
Teil II: Leitung des Data Science-Teams
Schibsted hat wie viele andere Unternehmen zwei Karrierewege: als selbständiger Arbeitnehmer und als Führungskraft. Im Kontext von Data Science richtet sich die erste an diejenigen, die ihr Wissen auf dem Gebiet der Data Science wirklich erweitern und durch praktische Arbeit und technische Führung einen Beitrag zum Unternehmen leisten möchten. Der Führungspfad ist für diejenigen gedacht, die sich mehr für Personalentwicklung und Teammanagement interessieren.
Ich war mir überhaupt nicht sicher, welcher Weg für mich richtig war, aber am Ende beschloss ich, den Weg des Führers auszuprobieren. Es verging nicht viel Zeit, als mir klar wurde, dass dies wirklich der richtige Weg für mich war, aber natürlich hatte ich viele Probleme (und ich mache es immer noch!).
Die erste Herausforderung besteht darin, dass es weltweit nur sehr wenige andere Data Science-Manager gibt. Wenn Sie der Meinung sind, dass erfahrene Spezialisten für Data Science selten sind, sind erfahrene Manager für Data Science um ein Vielfaches weniger. Sie sind also mehr oder weniger Ihren eigenen Geräten überlassen.
Aber stimmt es, dass sich die Verwaltung eines Data Science-Teams so stark von der Verwaltung anderer Teamtypen unterscheidet? Ja und nein.
Wenn Sie noch nie zuvor ein Team geleitet haben, finden Sie wahrscheinlich das klassische Lesematerial für das Management wie Andrew Groves High Output Management . Darüber hinaus ist der proaktive Rückgriff auf Führungskräfte (aus anderen Disziplinen) zur Beratung von entscheidender Bedeutung.
Data Science-Teams weisen jedoch einige wesentliche Unterschiede auf. Daher konzentrieren wir uns jetzt auf Schlussfolgerungen, insbesondere in Bezug auf Data Science-Teams.
2.1. Das Data Science-Team ist nicht wirklich ein Team
Wenn die meisten Leute an Teams denken, denken sie an so etwas:

Was zeichnet eine Fußballmannschaft wie den FC Barcelona aus? Mindestens drei Dinge:
- Gemeinsames Ziel
- Unterschiedliche Rollen im Team mit jeweils unterschiedlichen Verantwortlichkeiten
- Unabhängigkeit bei der Erreichung Ihres Ziels
Wenn Sie ein Team leiten, das ausschließlich aus Data Science-Spezialisten besteht, ist höchstwahrscheinlich keine dieser Eigenschaften erfüllt. Stattdessen hat Ihr Team:
- Mehrere, sich ändernde Ziele
- Spezialisten, und sie sind in der gleichen Sache gut: Data Science
- Andere Teams, mit denen Sie zusammenarbeiten können, um letztendlich Benutzer und Einnahmen zu beeinflussen
Eine geeignetere Analogie als eine Fußballmannschaft für ein Team von Data Science-Spezialisten ist:
Die Nachfrage nach Dienstleistungen von Mulder und Scully ändert sich im Laufe der Zeit. Sie werden angezogen, wenn ihre Erfahrung erforderlich ist. Und sie werden die Angelegenheit niemals lösen, ohne mit Leuten außerhalb des FBI zu sprechen.
Warum ist diese Unterscheidung wichtig?
Denn wenn Sie ein Team von Data Science-Experten haben und diese als „klassisches“ Team mit einem gemeinsamen Ziel, verschiedenen Rollen und vollständiger Autonomie verwalten, erhalten Sie schnell ein frustriertes Team.
Ich habe gesehen, dass Data Science-Teams wie jedes andere Produkt- oder Entwicklungsteam geführt werden, und die unvermeidliche Folge davon ist, dass Data Science-Spezialisten anfangen, alles andere als Data Science zu tun. Stattdessen entwickeln, zerlegen oder verwalten sie das Produkt.
Data Science-Experten sind also anders. Aber wie garantieren Sie dann, dass Ihre Data Science nicht in einem Elfenbeinturm lebt?
2.2. Betten Sie Data Science-Experten in andere Teams ein
Die Magie entsteht, wenn Sie Data Science-Experten neben Produktmanagern, Programmierern, Schnittstellenforschern, Vermarktern und vielem mehr einsetzen.
Die Zielfunktion, die Sie maximieren möchten, ist einfach die folgende: fruchtbare Interaktion zwischen Data Science-Spezialisten in Ihrem Team und Mitarbeitern in anderen Teams.
Ich denke gerne mit dem Broad-Channel-Konzept darüber nach. Lassen Sie uns dies anhand eines Produktmanagers veranschaulichen, der mit einem Data Science-Spezialisten zusammenarbeitet.
Am schlimmsten ist es, wenn es keinen Kanal zwischen ihnen gibt:

Dies bedeutet, dass keine Kommunikation zwischen DS und PM besteht. Mit anderen Worten, DS sind keine Produktprobleme bekannt, mit denen PM konfrontiert ist, sodass es unmöglich ist, diese Probleme zu analysieren oder zu lösen.
Ein bisschen besser, wenn wir einen engen Kanal zwischen ihnen haben:
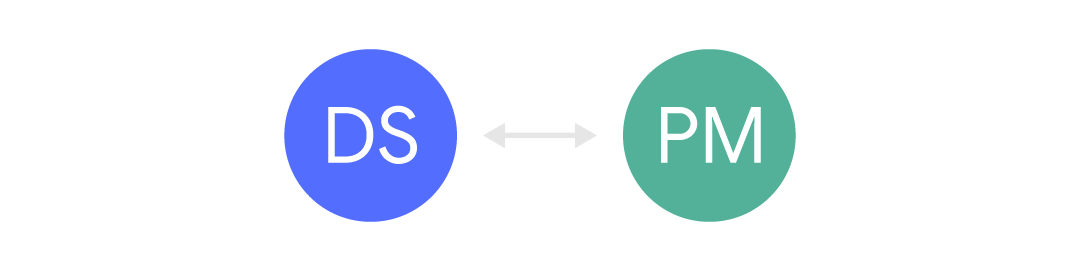
In diesem Fall kommen die Informationen, sind aber normalerweise begrenzt und oft asynchron. Informationen kommen über andere Personen (z. B. einen anderen Manager) oder über Anfrageformulare usw. Diese Art der Kommunikation ist häufig, wenn erwartet wird, dass Data Science-Spezialisten viele verschiedene Kunden bedienen. Dies kann jedoch frustrierend sein, da der Geschäftskontext häufig fehlt und dies zu Missverständnissen und dummem Aufhebens führen kann.
Die effektivste Bedingung ist, wenn wir einen breiten Kanal haben:

Im weitesten Sinne ist ein breiter Kanal, wenn ein Data Science-Spezialist neben einem Produktmanager sitzt. Dadurch können sie natürlich viel effektiver kommunizieren. Es ist nicht immer bequem oder sogar möglich, Menschen physisch in der Nähe zu halten (wir bei Schibsted sind auf 22 verschiedene Länder verteilt!). Es gibt jedoch virtuelle Versionen dieses Prinzips: von Slack über Remote Pair Programming bis hin zu Hangouts.
Natürlich ist es nicht jedem Produktmanager im Unternehmen möglich, mit jedem Data Science-Spezialisten in Ihrem Team einen breiten Kanal zu organisieren. Dies ist nicht skalierbar. Ihre Aufgabe als Manager von Data Science besteht darin, zu bestimmen, wann welche breiten Kanäle organisiert werden sollen. Und dann aus dem Weg!
Einer der Fälle in Schibsted, in denen wir aktiv an der Schaffung eines breiten Kanals gearbeitet haben, war die Entwicklung unseres Autopreis-Tools, mit dem Sie den Preis beim Verkauf Ihres Autos festlegen können ( probieren Sie es auf unserem finnischen Markt in Norwegen aus ). Anfangs hatten wir einen ziemlich dünnen Kanal wie diesen: "Versuchen Sie, das genaueste Preismodell zu erstellen, das Sie können." Wir fanden dies ziemlich ineffizient, da es viele Produktfragen gab, die wir nicht beantworten konnten, ohne in einem frühen Stadium mit Benutzern zu experimentieren.
Nach einiger Zeit endete alles damit, dass wir einen unserer Data Science-Spezialisten in das Produktteam integriert haben und die Ergebnisse viel besser wurden. In diesem Beitrag können Sie einige unserer frühen Arbeiten zu einem Tool für die Fahrzeugbewertung lesen.
Ein Beispiel dafür, wann wir von Anfang an einen breiten Kanal hatten, ist ein Prognosemodell für neue digitale Abonnements . Das Modell trug zur Steigerung der Umsatzumsätze um 540% bei und wurde 2017 mit dem INMA Best Use of Data Analysis Award ausgezeichnet.
2.3. Übernehmen Sie die Verantwortung für die Analytikproduktivität
Andrew Grove gibt im High Output Management-Buch an, dass Sie als Manager die Ergebnisse Ihres Teams besitzen. Dies bedeutet, dass der Data Science-Manager in die Schaffung der bestmöglichen Umgebung investieren muss, damit seine Data Science-Spezialisten produktiv sind.

Dies steht in vielerlei Hinsicht im Widerspruch zu dem oben beschriebenen Einbettungsmodell. Wenn Sie die ganze Zeit alles einbetten, besteht eine hohe Wahrscheinlichkeit, dass Sie Data Warehouses und eine nicht optimale Infrastruktur erhalten, die mehrmals dupliziert werden.
Einige Entwicklungsmanager behaupten, wenn Sie führend werden, sollten Sie die Codierung vollständig einstellen. , Data Science 10% : , . . Data Science.
« 15 , , , , ad-hoc ?! , ».
« ― ?»
.
, . , , , Data Science.
, Lean Management, Data Science. XKCD :
, Data Science . !
2.4. -> ->
«» , Data Science, . Data Science . , , , .

:
- . 98% , , (… , ).
- , , - , .
, Data Science, , , , .
, , .
, , , , . , .
, ― . , . . Slack . ( !) , .
. . , !
, ? , , . , , , Data Science.
. , , , , . .
2.5. ,
Data Science. , . , , - , ?
Ferrari, .

, .

Ferrari , .

Data Science ― , , . , , , , (ROI).
Data Science. - , .
, , . , , , , ― , . , , .
, Data Science . , . , , , .
2.6. OKR
, Data Science. Objectives and Key Results (OKR). , OKR ― , . , . OKR , .
OKR , , , , .
, OKR , . , : , .
, , OKR.
-: OKR. OKR , , , . « », . , . , .
LSTM ? , NLP-, , LSTM . ? . ? , .
OKR, .
, OKR . , .
-: OKR . , . , :
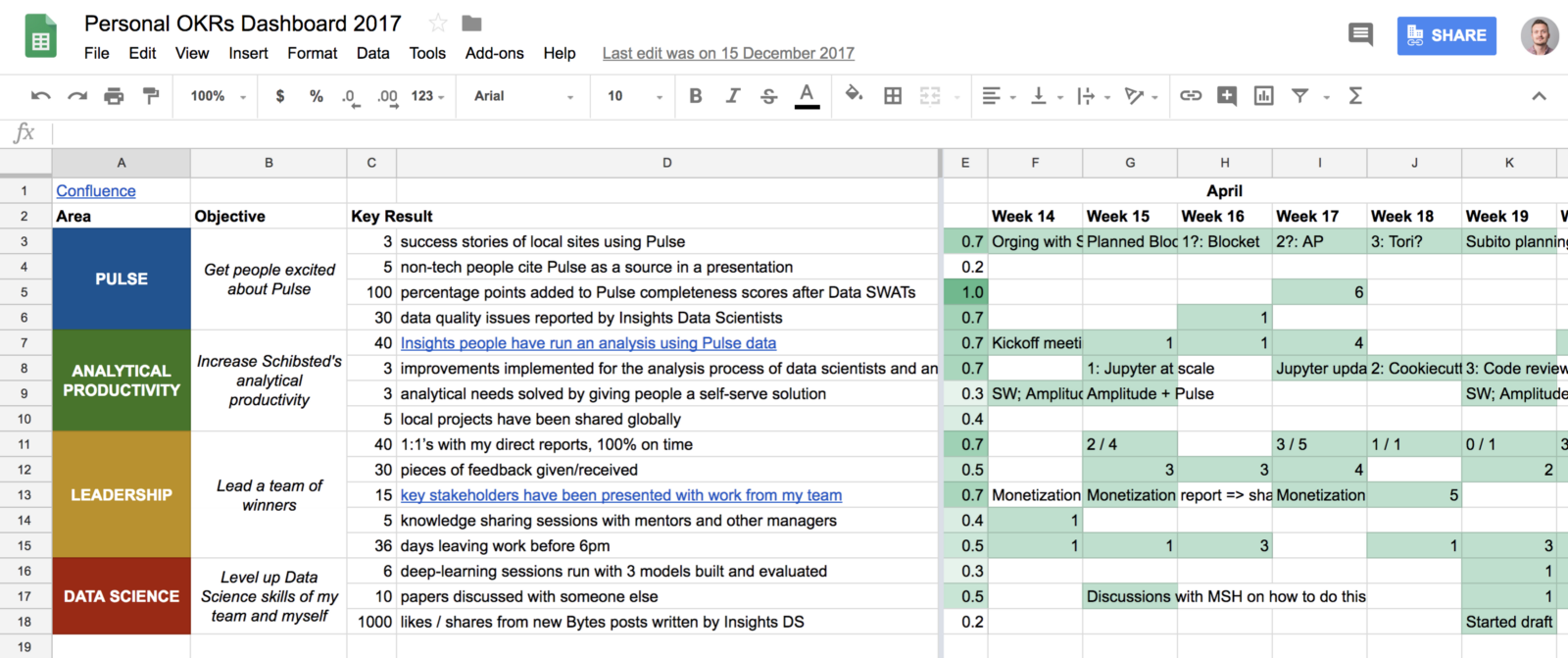
, , 10 , . , , ― . . OKR .
, , OKRs ― .
2.7.
Und am Ende der wichtigste Punkt.
Als Google zwei Jahre lang seine Teams untersuchte, um herauszufinden, warum einige Teams gut und andere weniger funktionieren, fiel eines auf. Das ist psychologische Sicherheit .
Kurz gesagt, psychologische Sicherheit kann als der Glaube zusammengefasst werden, dass Sie nicht bestraft werden, wenn Sie einen Fehler machen.
Denken Sie jetzt im Zusammenhang mit der Einführung zu Teil I darüber nach. Das Betrugssyndrom ist in Data Science sehr groß. Wovor hast du Angst, wenn du dich wie ein Betrüger fühlst? Fehler machen.
Im Laufe der Jahre habe ich festgestellt, dass Menschen aus verschiedenen Bereichen zu Data Science kommen. In unserem Schibsted-Team haben wir das Glück, fantastische Leute mit einem sehr breiten Erfahrungsspektrum zu haben. Personen mit Erfahrung in den Bereichen Finanzen, Forschung, Bildung, Beratung, Softwareentwicklung usw.
Es wäre dumm anzunehmen, dass all diese Leute dasselbe wissen. Im Gegenteil, der Wert einer so vielfältigen Erfahrung liegt in der Tatsache, dass jeder etwas Neues ins Team bringt.
Die Idee eines „Einhorns“ Data Science ist ein Gift für die psychologische Sicherheit.
Gibt es eine schnelle Lösung, um die psychologische Sicherheit zu erhöhen? Ich glaube nicht. Ich bin jedoch der Meinung, dass es als Manager ganz oben auf Ihrer Prioritätenliste stehen sollte - insbesondere, wenn Sie ein neues Team bilden oder wenn neue Mitglieder zu Ihnen stoßen. Obwohl es keine schnelle Lösung gibt, gibt es klare Maßnahmen, die Sie ergreifen können, um die psychologische Sicherheit zu erhöhen. Hier sind einige, die für uns gut funktioniert haben:
- Erstellen Sie eine Feedback- Kultur. Machen Sie deutlich, dass Ihre Teammitglieder nach Präsentationen, Sprints usw. „Pluspunkte und Verbesserungsmöglichkeiten“ miteinander kommunizieren müssen. Übrigens müssen Sie als Manager dies auch tun! Und den Menschen beibringen, wie man konstruktives Feedback richtig gibt - das ist nicht jedermanns Sache.
- Erhöhen Sie die Zeit von Angesicht zu Angesicht . Paarprogrammierung, Problemlösung an der Tafel ... Dies ist besonders wichtig für entfernte Teams. Dieses Ticket ist mit ziemlicher Sicherheit das Geld wert.
- Erstellen Sie Paare oder Teams anstelle von Einzelarbeiten. Sie werden vielleicht weniger Dinge im Team tun, aber Sie werden es besser machen. Und diejenigen, die zusammenarbeiten, werden Vertrauen ineinander aufbauen.
- Ermutigen Sie zu offenen und ehrlichen Besprechungsdiskussionen . Arbeiten Sie aktiv daran, die Sendezeit aller Teilnehmer auszugleichen - einige Personen müssen möglicherweise gebeten werden, zu sprechen.
- Denken Sie an kulturelle Unterschiede . Sie können aus einer egalitären, expliziten und direkten Kultur stammen . Es besteht eine hohe Wahrscheinlichkeit, dass Sie Signale eines Teammitglieds verpassen, die aus einer hierarchischen, impliziten und indirekten Kultur stammen.
- Führen Sie Gruppenexperimente zur kontinuierlichen Verbesserung durch. Die Einbeziehung des gesamten Teams in das Problem „Wie man man ein Team erfolgreich führt“ gibt jedem ein Gefühl der Verantwortung für das Wohlergehen des Teams.
- Messen Sie das Glück und die psychologische Sicherheit. Finden Sie eine einfache Möglichkeit, regelmäßig Fragen zu Glück und psychischer Sicherheit zu stellen. Wenn Sie für diese Zwecke kein trendiges HR-System haben, beginnen Sie einfach mit Typeform und wiederholen Sie den Vorgang, bis Sie und das Team es nützlich finden. Teilen Sie dem Team (anonyme) durchschnittliche Bewertungen oder Ergebnisse mit und beziehen Sie diese in die Verbesserung der Situation ein.
...
Herzlichen Glückwunsch, Sie haben das Ende erreicht! Ich hoffe, dieser Beitrag war für Sie als Spezialist oder Manager von Data Science ein wenig nützlich.
Wir haben ziemlich viel durchgemacht, hier ist eine kurze Liste:
Teil I: Datenwissenschaft im wirklichen Leben
1.1. Komplexität erhöht den Wert, beginnen Sie mit einfach
1.2. Haben Sie immer ein Basismodell
1.3. Verwenden Sie die Daten, die Sie haben
1.4. Übernehmen Sie die Verantwortung für die Daten
1.5. Vergiss die Daten
1.6. Entwickeln Sie ein detailliertes Verständnis der Kausalität
Teil II: Leitung des Data Science-Teams
2.1. Das Data Science-Team ist nicht wirklich ein Team
2.2. Betten Sie Data Science-Experten in andere Teams ein
2.3. Übernehmen Sie die Verantwortung für die Analytikproduktivität
2.4. Daten -> Macht -> Politik
2.5. Nutzen Sie Ihre Ressourcen und streben Sie eine hohe Kapitalrendite an
2.6. OKR für Fokus und Ausrichtung
2.7. Zuallererst psychologische Sicherheit
...
Danke fürs Lesen! Wenn dies hilfreich war, können Sie diesen Beitrag mit anderen teilen. Ich hoffe, eines Tages Ihre eigenen Gedanken über die Arbeit als Spezialist oder Data Science Manager zu sehen