Hallo allerseits! Mein Name ist Misha Kamenshchikov, ich beschäftige mich mit Data Science und der Entwicklung von Microservices im Avito-Empfehlungsteam. In diesem Artikel werde ich über unsere Empfehlungen für ähnliche Anzeigen sprechen und darüber, wie wir sie mit mehrarmigen Banditen verbessern. Ich habe auf der Highload ++ Siberia- Konferenz und auf der Veranstaltung "Data & Science: Marketing" einen Vortrag zu diesem Thema gehalten.

Artikelübersicht
Empfehlungen zu Avito
Zunächst ein kurzer Überblick über alle Arten von Empfehlungen zu Avito.
Personalisierte Empfehlungen für Benutzerelemente
User-Item-Empfehlungen basieren auf den Aktionen des Benutzers und sollen ihm helfen, das gewünschte Produkt schnell zu finden oder etwas potenziell Interessantes zu zeigen. Sie können auf der Hauptseite der Website und der Anwendungen oder in Mailinglisten angezeigt werden. Um solche Empfehlungen zu erstellen, verwenden wir zwei Arten von Modellen: offline und online.
Die Offline-Modelle basieren auf Matrixfaktorisierungsalgorithmen, die in wenigen Tagen auf alle Daten trainiert werden, und die Empfehlungen werden in einem schnellen Repository zur Verteilung an Benutzer gespeichert. Online-Modelle berücksichtigen Empfehlungen im laufenden Betrieb anhand des Inhalts von Anzeigen aus dem Nutzerverlauf. Der Vorteil von Offline-Modellen besteht darin, dass sie genauere und qualitativ hochwertigere Empfehlungen liefern, jedoch nicht die neuesten Benutzeraktionen berücksichtigen, die während des Modelltrainings auftreten können, als das Trainingsmuster festgelegt wurde. Online-Modelle reagieren sofort auf Benutzeraktionen, und Empfehlungen können sich mit jeder Aktion ändern.
Kaltstartempfehlungen
Alle Empfehlungssysteme haben ein sogenanntes Kaltstartproblem. Dies bedeutet, dass die oben beschriebenen Modelle einem neuen Benutzer ohne eine Historie von Aktionen keine Empfehlungen geben können. In solchen Fällen ist es besser, den Nutzer mit den Inhalten auf der Website vertraut zu machen und dabei nicht nur zufällige Anzeigen auszuwählen, sondern beispielsweise Anzeigen aus Kategorien, die in der Region des Nutzers beliebt sind.
Suchempfehlungen
Für Benutzer, die häufig die Suche verwenden, empfehlen wir Verknüpfungen für die Suche. Sie senden den Benutzer an eine bestimmte Kategorie und legen Filter fest. Solche Empfehlungen finden Sie oben auf der Hauptseite der Anwendung.
Artikel-Artikel-Empfehlungen
Artikel-Artikel-Empfehlungen werden auf der Website in Form ähnlicher Ankündigungen auf der Produktkarte angezeigt. Sie können auf allen Plattformen unter der Anzeigenbeschreibung angezeigt werden. Das Empfehlungsmodell ist derzeit ausschließlich inhaltlich und verwendet keine Informationen zu Nutzeraktionen. Daher können wir sofort ähnliche unter aktiven Anzeigen auf der Website für eine neue Anzeige abrufen. Später in diesem Artikel werde ich über diese spezielle Art von Empfehlung sprechen.
Ausführlichere Informationen zu allen Arten von Empfehlungen zu Avito haben wir bereits in unserem Blog geschrieben. Lesen Sie, wenn Sie interessiert sind.
Ähnliche Anzeigen
So sieht ein Block mit ähnlichen Anzeigen aus:

Diese Art von Empfehlung erschien zuerst auf der Website, und die Logik wurde in der Sphinx- Suchmaschine implementiert. Tatsächlich ist dieses Modell eine lineare Kombination verschiedener Faktoren: Wortübereinstimmung, Entfernung, Preisdifferenz und andere Parameter.
Basierend auf den Parametern der Zielanzeige wird in Sphinx eine Anfrage generiert und integrierte Ranglisten werden für die Rangfolge verwendet.
Beispiel anfordern:
SELECT id, weight as ranker_weight, ranker_weight * 10 + (metro_id=42) * 5 + (location_id=2525) * 10 + (110000 / (abs(price - 1100000) + 110000)) * 5 as rel FROM items WHERE MATCH('@title |scott|scale|700|premium') AND microcat_id=100 ORDER BY rel DESC, sort_time DESC LIMIT 0,32 OPTION max_matches=32, ranker=expr('sum(word_count)')
Wenn Sie versuchen, diesen Ansatz formeller zu beschreiben, können Sie sich die Ranglisten in Form einiger Gewichte vorstellen und Anzeigenparameter (Quelle ist die Originalanzeige) und (gezielte Anzeige). Für jeden der Parameter führen wir die Ähnlichkeitsfunktion ein . Sie können binär (z. B. das Zusammentreffen der Stadt der Anzeige), diskret (der Abstand zwischen den Anzeigen) und kontinuierlich (z. B. die relative Preisdifferenz) sein. Dann wird für zwei Ankündigungen das Endergebnis durch die Formel ausgedrückt
Mit der Suchmaschine können Sie den Wert dieser Formel für eine ausreichend große Anzahl von Anzeigen schnell lesen und die Lieferung in Echtzeit bewerten.
Dieser Ansatz zeigte sich in seiner ursprünglichen Form recht gut, hatte jedoch erhebliche Nachteile.
Probleme angehen
Zunächst wurden die Gewichte zunächst fachmännisch ausgewählt und standen außer Zweifel. Manchmal gab es Änderungen in den Gewichten, aber sie wurden auf der Grundlage eines Punktfeedbacks und nicht auf der Grundlage einer Analyse des Benutzerverhaltens im Allgemeinen vorgenommen.
Zweitens wurden die Gewichte auf der Baustelle fest codiert, und Änderungen an ihnen waren sehr unpraktisch.
Schritt in Richtung Automatisierung
Der erste Schritt zur Verbesserung des Empfehlungsmodells war das Entfernen der gesamten Logik in einem separaten Microservice in Python. Dieser Service gehörte bereits vollständig zu unserem Empfehlungsteam, und wir konnten ziemlich oft Experimente durchführen.
Jedes Experiment kann durch die sogenannte "Konfiguration" charakterisiert werden - eine Reihe von Gewichten für Ranglisten. Wir möchten Konfigurationen generieren und die beste basierend auf Benutzeraktionen auswählen. Wie können diese Konfigurationen generiert werden?
Die erste Option, die von Anfang an bestand, ist die fachmännische Generierung von Konfigurationen. Das heißt, wir gehen davon aus, dass Menschen bei der Suche nach einem Auto beispielsweise bei der Suche nach einem Auto an Optionen interessiert sind, deren Preis dem von ihnen angezeigten nahe kommt, und nicht nur an ähnlichen Modellen, die erheblich mehr kosten können.
Die zweite Option sind zufällige Konfigurationen. Wir legen für jeden Parameter eine Art Verteilung fest und nehmen dann einfach eine Stichprobe aus dieser Verteilung. Diese Methode ist schneller, da Sie nicht für alle Kategorien über die einzelnen Parameter nachdenken müssen.
Eine kompliziertere Option ist die Verwendung genetischer Algorithmen. Wir wissen, welche der Konfigurationen uns in Bezug auf Benutzeraktionen den besten Effekt bietet, sodass wir sie bei jeder Iteration verlassen und neue hinzufügen können: zufällig oder fachkundig.
Eine noch komplexere Option, die eine zufriedene lange Geschichte von Experimenten erfordert, ist die Verwendung von maschinellem Lernen. Wir können eine Reihe von Parametern als Merkmalsvektor und eine Zielmetrik als Zielvariable darstellen. Dann werden wir einen solchen Satz von Parametern finden, der nach Einschätzung des Modells unsere Zielmetrik maximiert.
In unserem Fall haben wir uns für die ersten beiden Ansätze sowie für genetische Algorithmen in der einfachsten Form entschieden: Wir verlassen das Beste, entfernen das Schlimmste.
Jetzt kommen wir zum interessantesten Teil des Artikels: Wir können Konfigurationen generieren, aber wie können Experimente durchgeführt werden, damit sie schnell und effizient sind?
Experimentieren
Das Experiment kann im Format des A / B / ... -Tests durchgeführt werden. Dazu müssen wir N Konfigurationen generieren, auf statistisch signifikante Ergebnisse warten und schließlich die beste Konfiguration auswählen. Dies kann ziemlich lange dauern, und während des Tests kann eine feste Gruppe von Benutzern Empfehlungen von schlechter Qualität erhalten - mit einer zufälligen Generierung von Konfigurationen ist dies durchaus möglich. Wenn wir dem Experiment eine neue Konfiguration hinzufügen möchten, müssen wir den Test erneut starten. Wir wollen aber schnell Experimente durchführen, um die Bedingungen des Experiments ändern zu können. Und damit Benutzer nicht unter absichtlich schlechten Konfigurationen leiden. Vielarmige Banditen werden uns dabei helfen.
Mehrarmige Banditen
Der Name der Methode stammt von den "einarmigen Banditen" - Spielautomaten in einem Casino mit einem Hebel, für den Sie ziehen und gewinnen können. Stellen Sie sich vor, Sie befinden sich in einem Raum mit einem Dutzend dieser Maschinen und haben N freie Versuche, auf einer dieser Maschinen zu spielen. Natürlich möchten Sie mehr Geld gewinnen, aber Sie wissen nicht im Voraus, welche Maschine den größten Gewinn erzielt. Das Problem bei vielarmigen Banditen liegt genau darin, die rentabelste Maschine mit minimalen Verlusten zu finden (auf nachteiligen Maschinen zu spielen).
Wenn wir dies in Bezug auf unsere Empfehlungsaufgabe formulieren, stellt sich heraus, dass die Maschinen Konfigurationen sind, jeder Versuch eine Auswahl einer Konfiguration zum Generieren von Empfehlungen ist und die Verstärkung eine Zielmetrik ist, die vom Feedback des Benutzers abhängt.
Der Vorteil von Banditen gegenüber A / B / ... -Tests
Ihr Hauptvorteil ist, dass sie es uns ermöglichen, das Verkehrsaufkommen abhängig vom Erfolg einer bestimmten Konfiguration zu ändern. Dies löst nur das Problem, dass die Leute während des gesamten Experiments schlechte Empfehlungen erhalten. Wenn sie nicht auf die Empfehlungen klicken, wird der Bandit dies schnell verstehen und diese Konfiguration nicht auswählen. Außerdem können wir dem Experiment jederzeit eine neue Konfiguration hinzufügen oder einfach eine der aktuellen löschen. Alles zusammen gibt uns die Flexibilität, Experimente durchzuführen und löst die Probleme des Ansatzes mit A / B / ... -Tests.

Gangster-Strategien
Es gibt viele Strategien zur Lösung des mehrarmigen Banditenproblems. Als nächstes werde ich einige Klassen von einfach zu implementierenden Strategien beschreiben, die wir versucht haben, in unserer Aufgabe anzuwenden. Aber zuerst müssen Sie verstehen, wie Sie die Wirksamkeit von Strategien vergleichen können. Wenn wir im Voraus wissen, welcher Stift die maximale Verstärkung bietet, besteht die optimale Strategie immer darin, diesen Stift zu ziehen. Wir legen die Anzahl der Schritte fest und berechnen die optimale Belohnung . Für die Strategie werden wir auch die Belohnung zählen. und das Konzept vorstellen ::
Weitere Strategien können nur mit diesem Wert verglichen werden. Ich stelle fest, dass Strategien eine Art Veränderung haben
kann unterschiedlich sein, und eine Strategie kann für eine kleine Anzahl von Schritten besser sein, und eine andere für eine große.
Gierige Strategien
Wie der Name schon sagt, basieren gierige Strategien auf einem einfachen Prinzip: Wählen Sie immer den Stift, der im Durchschnitt die größte Belohnung bietet. Die Strategien dieser Klasse unterscheiden sich darin, wie wir die Umgebung erkunden, um genau diesen Stift zu bestimmen. Es gibt zum Beispiel Strategie. Sie hat einen Parameter - Dies bestimmt die Wahrscheinlichkeit, mit der wir nicht den besten, sondern den zufälligen Stift auswählen und so unsere Umgebung erkunden. Sie können auch die Wahrscheinlichkeit von Recherchen im Laufe der Zeit verringern. Diese Strategie heißt . Gierige Strategien sind sehr einfach umzusetzen und verständlich, aber nicht immer effektiv.
UCB1
Diese Strategie ist völlig deterministisch - der Stift wird anhand der derzeit verfügbaren Informationen eindeutig bestimmt. Hier ist die Formel:
Teil der Formel mit
bedeutet die Mitte des j-ten Stiftes und ist für die Ausbeutung verantwortlich, genau wie bei gierigen Strategien. Der zweite Teil der Formel ist für die Exploration verantwortlich.
Ist die Gesamtzahl der Aktionen
- die Anzahl der Aktionen des j-ten Stifts. Es gibt eine nachgewiesene Schätzung für diese Strategie auf
. Sie können hier darüber lesen.
Thompson Sampling
Bei dieser Strategie weisen wir jedem Stift eine zufällige Verteilung zu und probieren bei jedem Schritt eine Zahl aus dieser Verteilung aus, wobei wir einen Stift entsprechend dem Maximum auswählen. Basierend auf dem Feedback aktualisieren wir die Verteilungsparameter so, dass die besten Stifte einer Verteilung mit einem großen Durchschnitt entsprechen und ihre Streuung mit der Anzahl der Aktionen abnimmt. Sie können mehr über diese Strategie in einem ausgezeichneten Artikel lesen.
Strategievergleich
Simulieren wir die oben beschriebenen Strategien in einer künstlichen Umgebung mit drei Griffen, von denen jeder einer Bernoulli-Verteilung mit einem Parameter entspricht entsprechend. Unsere Strategien:
- mit ;;
- UCB1;
- Thompson Beta Sampling
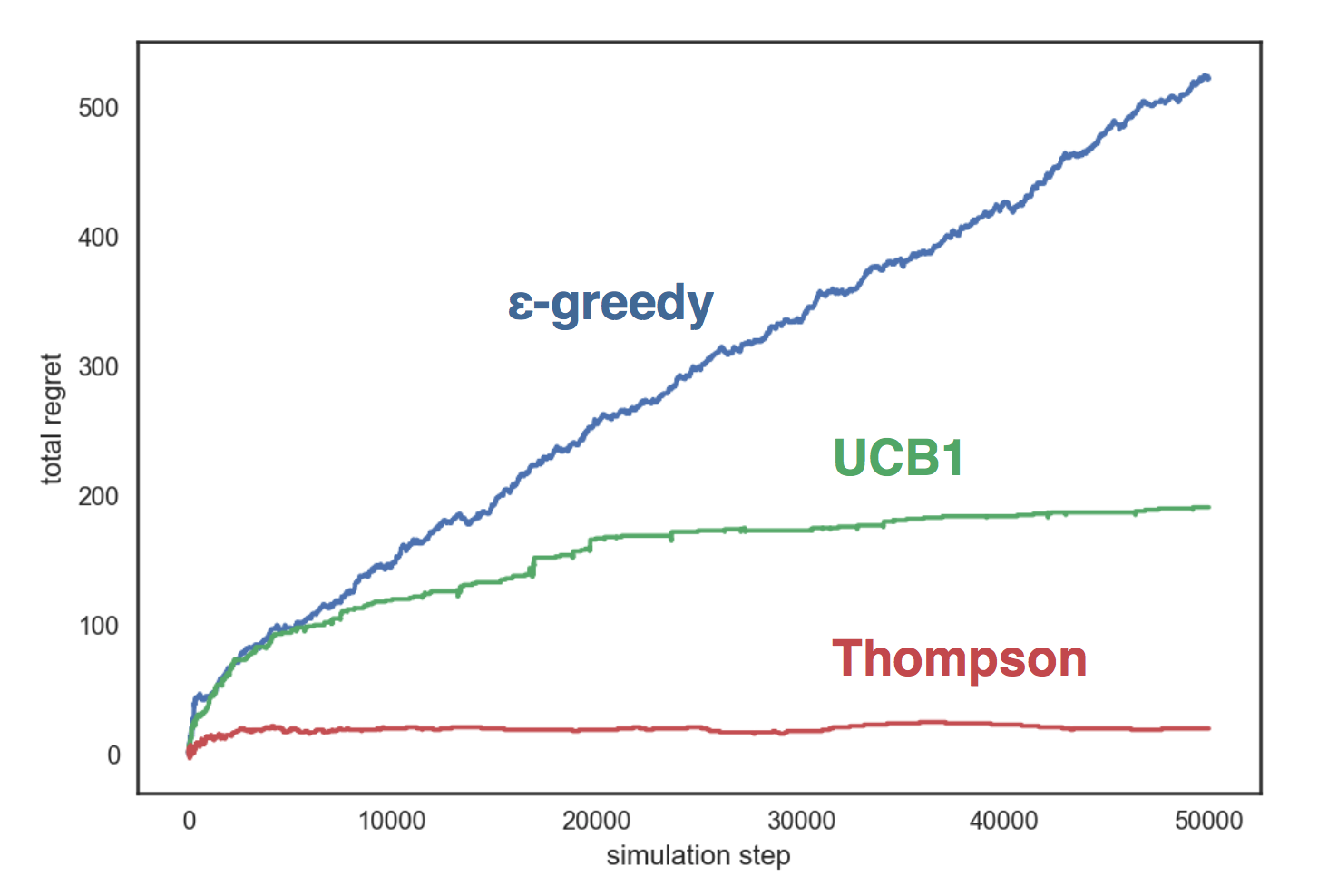
Die Grafik zeigt, dass die gierige Strategie wächst linear und in den beiden anderen Strategien - logarithmisch - und Thompsons Stichprobe zeigt sich viel besser als die anderen und sie wächst fast nicht mit der Anzahl der Schritte.
Der Vergleichscode ist auf GitHub verfügbar.
Ich habe dich mit mehrarmigen Banditen bekannt gemacht und jetzt kann ich dir sagen, wie wir sie benutzt haben.
Mehrarmige Banditen in Avito
Wir haben also mehrere Konfigurationen (Parametersätze) und möchten mit Hilfe von mehrarmigen Banditen die beste aus ihnen auswählen. Damit Banditen lernen können, benötigen wir ein wichtiges Detail - Benutzerfeedback. Gleichzeitig sollte die Auswahl der Maßnahmen, für die wir geschult werden, unseren Zielen entsprechen. Ich möchte, dass Benutzer mehr Transaktionen mit besseren Empfehlungen durchführen.
Wählen Sie Zielaktionen
Der erste Ansatz zur Auswahl gezielter Maßnahmen war recht einfach und naiv. Als Zielmetrik haben wir die Anzahl der Ansichten ausgewählt, und die Banditen haben gelernt, wie diese Metrik gut optimiert werden kann. Aber es gab ein Problem: Mehr Ansichten sind nicht immer gut. In der Kategorie "Auto" konnten wir beispielsweise die Anzahl der Aufrufe um 15% erhöhen, gleichzeitig ging die Anzahl der Kontaktanfragen jedoch um etwa den gleichen Betrag zurück. Bei näherer Betrachtung stellte sich heraus, dass die Banditen einen Stift wählten, bei dem der Filter nach Region ausgeschaltet war. Daher wurden im Block Anzeigen aus ganz Russland geschaltet, wobei die Auswahl an ähnlichen Anzeigen natürlich größer ist. Dies führte zu einer Zunahme der Anzahl der Aufrufe: Äußerlich schienen die Empfehlungen von besserer Qualität zu sein, aber als sie die Produktkarte betraten, stellten die Leute fest, dass das Auto sehr weit von ihnen entfernt war und stellten keine Kontaktanfrage.
Der zweite Ansatz besteht darin, zu lernen, wie von der Anzeige eines Blocks zu einer Kontaktanforderung konvertiert wird. Dieser Ansatz schien besser zu sein als der vorherige, schon allein deshalb, weil diese Metrik fast direkt für die Qualität der Empfehlungen verantwortlich ist. Aber ein anderes Problem trat auf - die tägliche Saisonalität. Abhängig von der Tageszeit können sich die Konvertierungswerte um das vierfache (!) Mal unterscheiden (dies ist häufig mehr als der Effekt einer besseren Konfiguration), und der Stift, der im ersten Intervall mit einer hohen Konvertierung ausgewählt werden konnte, wurde weiterhin häufiger als andere ausgewählt.
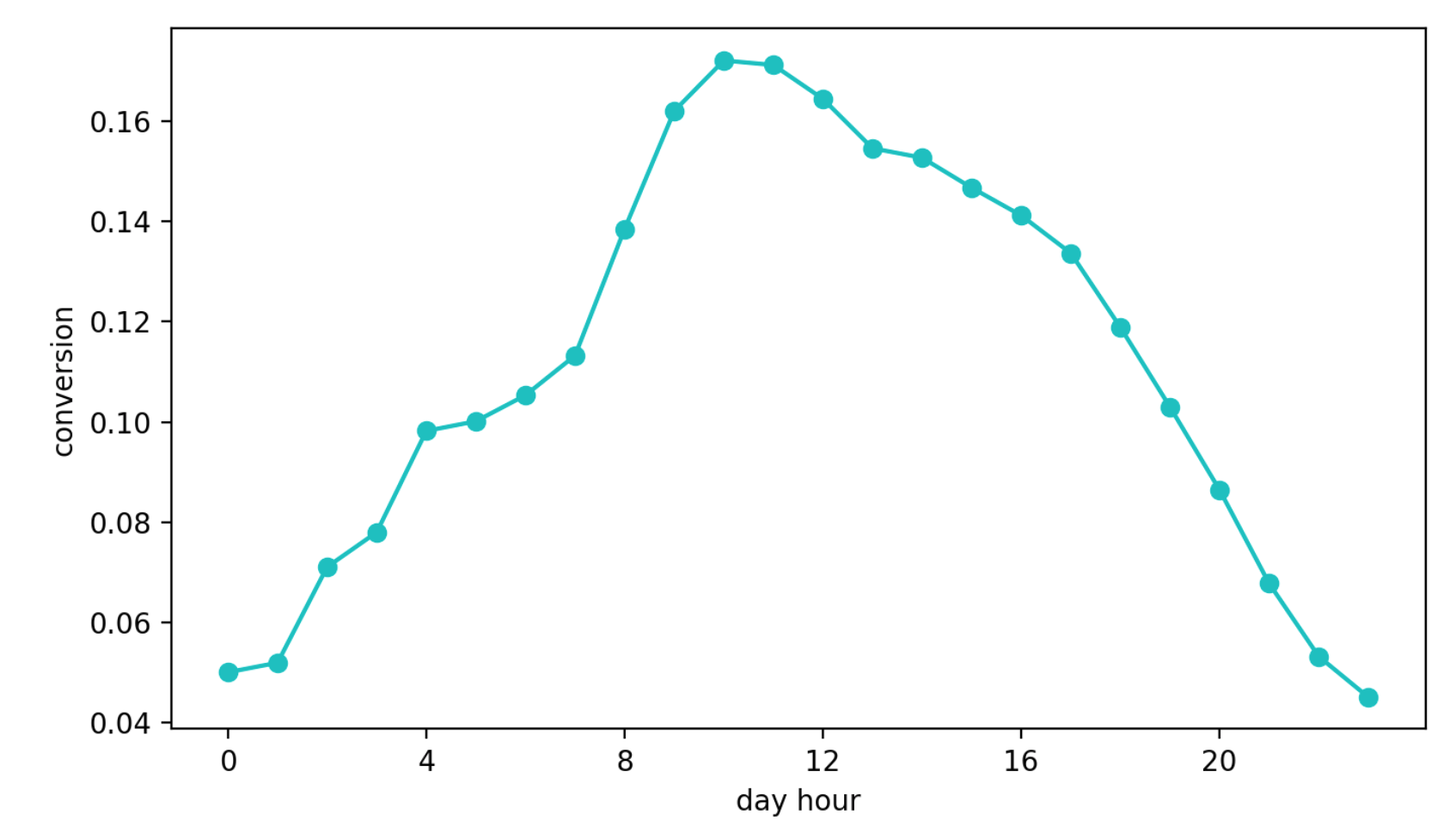
Tägliche Conversion-Dynamik (Werte der Y-Achse geändert)
Schließlich der dritte Ansatz. Wir benutzen es jetzt. Wir wählen die Referenzgruppe aus, die immer Empfehlungen zum gleichen Algorithmus erhält und nicht dem Einfluss von Banditen unterliegt. Als nächstes betrachten wir die absolute Anzahl der Kontakte in unserer Zielgruppe und Referenz. Ihre Beziehung unterliegt keiner Saisonalität, da wir die Referenzgruppe zufällig auswählen und dieser Ansatz bequemerweise auf der Thompson-Stichprobe beruht.
Unsere Strategie
Wir unterscheiden die Referenz- und Zielgruppen wie oben beschrieben. Initialisieren Sie dann N Handles (jedes entspricht einer Konfiguration) mit der Beta-Verteilung
Bei jedem Schritt:
- Für jeden Stift nehmen wir eine Zahl aus der entsprechenden Verteilung und wählen den Stift entsprechend dem Maximum aus.
- Zählen Sie die Anzahl der Aktionen in Gruppen und für eine bestimmte Zeitspanne (in unserem Fall 10 Sekunden) und aktualisieren Sie die Verteilungsparameter für den ausgewählten Stift: , .
Mit dieser Strategie optimieren wir die benötigte Metrik, die Anzahl der Kontaktanfragen in der Zielgruppe und vermeiden die oben beschriebenen Probleme. Darüber hinaus zeigte dieser Ansatz im globalen A / B-Test die besten Ergebnisse.
Ergebnisse
Der globale A / B-Test war wie folgt organisiert: Alle Anzeigen werden zufällig in zwei Gruppen unterteilt. Zu den Ankündigungen eines von ihnen zeigen wir Empfehlungen mit Hilfe von Banditen und zum anderen - mit dem alten Expertenalgorithmus. Anschließend messen wir die Anzahl der Conversion-Kontaktanfragen in jeder der Gruppen (Anfragen, die nach dem Wechsel zu Anzeigen aus dem ähnlichen Block gestellt wurden). Im Durchschnitt erhält eine Gruppe mit Banditen in allen Kategorien etwa 10% mehr gezielte Aktionen als die Kontrolle, in einigen Kategorien kann dieser Unterschied jedoch 30% erreichen.
Mit der erstellten Plattform können Sie die Logik schnell ändern, Banditen Konfigurationen hinzufügen und Hypothesen validieren.
Wenn Sie Fragen zu unserem Empfehlungsdienst oder zu mehrarmigen Banditen haben, stellen Sie diese in den Kommentaren. Ich werde gerne antworten.