Bis vor kurzem wurden in Odnoklassniki etwa 50 TB Echtzeitdaten in SQL Server gespeichert. Für ein solches Volume ist es nahezu unmöglich, mit SQL DBMS einen schnellen, zuverlässigen und sogar ausfallsicheren Zugriff auf Rechenzentren bereitzustellen. Normalerweise verwenden sie in solchen Fällen eines der NoSQL-Repositorys, aber nicht alles kann auf NoSQL übertragen werden: Einige Entitäten benötigen Garantien für ACID-Transaktionen.
Dies führte dazu, dass wir NewSQL-Speicher verwendeten, dh ein DBMS, das Fehlertoleranz, Skalierbarkeit und Leistung von NoSQL-Systemen bietet, aber gleichzeitig ACID-Garantien bewahrt, die klassischen Systemen vertraut sind. Es gibt nur wenige funktionierende industrielle Systeme in dieser neuen Klasse, daher haben wir ein solches System selbst implementiert und in den kommerziellen Betrieb versetzt.
Wie es funktioniert und was passiert ist - lesen Sie unter dem Schnitt.
Heute hat Odnoklassniki mehr als 70 Millionen Besucher pro Monat. Wir gehören
zu den fünf größten sozialen Netzwerken der Welt und zu den zwanzig Websites, auf denen Benutzer die meiste Zeit verbringen. Infrastruktur "OK" bewältigt sehr hohe Lasten: mehr als eine Million HTTP-Anforderungen / Sek. An die Fronten. Teile der Serverflotte in einer Menge von mehr als 8000 Teilen befinden sich nahe beieinander - in vier Moskauer Rechenzentren, wodurch eine Netzwerklatenz von weniger als 1 ms zwischen ihnen möglich ist.
Wir verwenden Cassandra seit 2010, beginnend mit Version 0.6. Heute sind mehrere Dutzend Cluster in Betrieb. Der schnellste Cluster verarbeitet mehr als 4 Millionen Vorgänge pro Sekunde und der größte speichert 260 TB.
All dies sind jedoch gewöhnliche NoSQL-Cluster, die zum Speichern
schwach konsistenter Daten verwendet werden. Wir wollten jedoch den konsistenten Hauptspeicher Microsoft SQL Server ersetzen, der seit der Gründung von Odnoklassniki verwendet wird. Der Speicher bestand aus mehr als 300 SQL Server Standard Edition-Computern, die 50 TB Daten enthielten - Geschäftseinheiten. Diese Daten werden im Rahmen von ACID-Transaktionen geändert und erfordern eine
hohe Konsistenz .
Um Daten auf SQL Server-Knoten zu verteilen, haben wir sowohl die vertikale als auch die horizontale
Partitionierung (Sharding) verwendet. In der Vergangenheit haben wir ein einfaches Daten-Sharding-Schema verwendet: Jede Entität war einem Token zugeordnet - eine Funktion der ID der Entität. Entitäten mit demselben Token wurden auf demselben SQL Server platziert. Die Master-Detail-Typ-Beziehung wurde so implementiert, dass die Token der Haupt- und generierten Datensätze immer übereinstimmten und sich auf demselben Server befanden. In einem sozialen Netzwerk werden fast alle Datensätze im Auftrag eines Benutzers generiert. Dies bedeutet, dass alle Benutzerdaten in einem funktionalen Subsystem auf einem Server gespeichert sind. Das heißt, Tabellen eines SQL Servers waren fast immer an einer Geschäftstransaktion beteiligt, wodurch die Datenkonsistenz mithilfe lokaler ACID-Transaktionen sichergestellt werden konnte, ohne dass
langsame und unzuverlässige verteilte ACID-Transaktionen erforderlich waren.
Dank Sharding und der Beschleunigung von SQL:
- Wir verwenden keine Fremdschlüsseleinschränkungen, da sich die Entitäts-ID beim Sharding auf einem anderen Server befinden kann.
- Aufgrund der zusätzlichen Belastung der DBMS-CPU werden keine gespeicherten Prozeduren und Trigger verwendet.
- Wir verwenden keine JOINs wegen all der oben genannten und vieler zufälliger Lesevorgänge von der Festplatte.
- Außerhalb einer Transaktion verwenden wir zur Reduzierung von Deadlocks die Isolationsstufe Read Uncommitted.
- Wir führen nur kurze Transaktionen durch (durchschnittlich kürzer als 100 ms).
- Aufgrund der großen Anzahl von Deadlocks verwenden wir kein mehrzeiliges UPDATE und DELETE - wir aktualisieren nur einen Datensatz.
- Wir führen Abfragen immer nur über Indizes aus. Eine Abfrage mit einem Plan für einen vollständigen Tabellenscan bedeutet für uns eine Überlastung der Datenbank und deren Ausfall.
Diese Schritte ermöglichten es, die maximale Leistung von SQL-Servern zu erreichen. Die Probleme wurden jedoch immer größer. Schauen wir sie uns an.
SQL-Probleme
- Da wir proprietäres Sharding verwendet haben, haben Administratoren manuell neue Shards hinzugefügt. Während dieser ganzen Zeit haben skalierbare Datenreplikate keine Anforderungen erfüllt.
- Wenn die Anzahl der Datensätze in der Tabelle zunimmt, nimmt die Einfüge- und Änderungsgeschwindigkeit ab. Wenn Sie einer vorhandenen Tabelle Indizes hinzufügen, sinkt die Geschwindigkeit um ein Vielfaches. Die Erstellung und Neuerstellung von Indizes geht mit Ausfallzeiten einher.
- Wenn nur wenige Windows for SQL Server in der Produktion sind, ist die Verwaltung Ihrer Infrastruktur schwierig
Das Hauptproblem ist jedoch
Fehlertoleranz
Classic SQL Server weist eine schlechte Fehlertoleranz auf. Angenommen, Sie haben nur einen Datenbankserver, der alle drei Jahre ausfällt. Zu diesem Zeitpunkt funktioniert die Site 20 Minuten lang nicht. Dies ist akzeptabel. Wenn Sie 64 Server haben, funktioniert die Site nicht alle drei Wochen. Und wenn Sie 200 Server haben, funktioniert die Site nicht jede Woche. Das ist ein Problem.
Was kann getan werden, um die Ausfallsicherheit von SQL Server zu verbessern? Wikipedia bietet uns an, einen
leicht zugänglichen Cluster zu erstellen: Wenn eine der Komponenten ausfällt, gibt es eine doppelte.
Dies erfordert eine Flotte teurer Geräte: Mehrfachredundanz, Glasfaser, gemeinsamer Speicher und die Einbeziehung einer Reserve funktionieren nicht zuverlässig: Etwa 10% der Einschlüsse schlagen mit einem Sicherungsknoten durch die Engine hinter dem Hauptknoten fehl.
Der Hauptnachteil eines solchen hoch zugänglichen Clusters ist jedoch die Nullverfügbarkeit bei Ausfall des Rechenzentrums, in dem es sich befindet. Odnoklassniki verfügt über vier Rechenzentren, in denen wir im Falle eines vollständigen Unfalls Arbeit leisten müssen.
Zu diesem
Zweck können Sie die in SQL Server integrierte
Multi-Master- Replikation verwenden. Diese Lösung ist aufgrund der Softwarekosten viel teurer und weist bekannte Probleme bei der Replikation auf - unvorhersehbare Transaktionsverzögerungen während der synchronen Replikation und Verzögerungen bei der Verwendung der Replikation (und infolgedessen verlorene Änderungen) während der asynchronen. Die implizite
manuelle Lösung von Konflikten macht diese Option für uns völlig unanwendbar.
All diese Probleme erforderten eine radikale Lösung, und wir gingen zu einer detaillierten Analyse über. Hier müssen wir uns mit den grundlegenden Funktionen von SQL Server vertraut machen - Transaktionen.
Einfache Transaktion
Betrachten Sie aus Sicht eines angewandten SQL-Programmierers die einfachste Transaktion: Hinzufügen eines Fotos zu einem Album. Alben und Fotos werden auf verschiedenen Platten gespeichert. Das Album hat einen öffentlichen Fototheke. Dann wird eine solche Transaktion in die folgenden Schritte unterteilt:
- Wir sperren das Album per Schlüssel.
- Erstellen Sie einen Eintrag in der Fototabelle.
- Wenn das Foto einen öffentlichen Status hat, wird der öffentliche Fotozähler im Album aufgelöst, der Datensatz aktualisiert und die Transaktion festgeschrieben.
Oder in Form von Pseudocode:
TX.start("Albums", id); Album album = albums.lock(id); Photo photo = photos.create(…); if (photo.status == PUBLIC ) { album.incPublicPhotosCount(); } album.update(); TX.commit();
Wir sehen, dass das häufigste Geschäftstransaktionsszenario darin besteht, Daten aus der Datenbank in den Speicher des Anwendungsservers zu lesen, etwas zu ändern und die neuen Werte wieder in der Datenbank zu speichern. Normalerweise aktualisieren wir bei einer solchen Transaktion mehrere Entitäten, mehrere Tabellen.
Bei der Ausführung einer Transaktion kann es zu einer wettbewerbsbedingten Änderung derselben Daten von einem anderen System kommen. Beispielsweise kann Antispam entscheiden, dass der Benutzer verdächtig ist und daher alle Fotos des Benutzers nicht mehr öffentlich sein sollten. Sie sollten zur Moderation gesendet werden. Dies bedeutet, dass photo.status auf einen anderen Wert geändert und die entsprechenden Zähler abgeschraubt werden. Wenn dieser Vorgang ohne Garantien für die Atomizität der Anwendung und die Isolierung konkurrierender Modifikationen wie bei
ACID erfolgt , ist das Ergebnis offensichtlich nicht das, was benötigt wird - entweder zeigt der Fotozähler den falschen Wert an oder es werden nicht alle Fotos zur Moderation gesendet.
Es gibt viele ähnliche Codes, die verschiedene Geschäftseinheiten im Rahmen einer Transaktion während der gesamten Existenz von Odnoklassniki manipulieren. Aus der Erfahrung mit der Migration auf NoSQL mit
eventueller Konsistenz wissen wir, dass die größten Schwierigkeiten (und Zeitkosten) darin bestehen, Code zu entwickeln, der auf die Aufrechterhaltung der Datenkonsistenz abzielt. Daher haben wir die Hauptanforderung für ein neues Repository betrachtet, um echte logische ACID-Transaktionen für die Anwendungslogik bereitzustellen.
Weitere ebenso wichtige Anforderungen waren:
- Wenn das Rechenzentrum ausfällt, sollten sowohl Lesen als auch Schreiben in den neuen Speicher verfügbar sein.
- Aktuelle Entwicklungsgeschwindigkeit beibehalten. Das heißt, wenn Sie mit einem neuen Repository arbeiten, sollte die Codemenge ungefähr gleich sein, es sollte nicht erforderlich sein, dem Repository etwas hinzuzufügen, Algorithmen zur Lösung von Konflikten zu entwickeln, Sekundärindizes zu verwalten usw.
- Die Geschwindigkeit des neuen Speichers sollte sowohl beim Lesen von Daten als auch bei der Verarbeitung von Transaktionen hoch genug sein, was effektiv die Unanwendbarkeit von akademisch strengen, universellen, aber langsamen Lösungen wie beispielsweise zweiphasigen Commits bedeutete .
- Automatische Skalierung im laufenden Betrieb.
- Mit gewöhnlichen billigen Servern, ohne exotische Eisenstücke kaufen zu müssen.
- Die Möglichkeit, den Speicher von den Entwicklern des Unternehmens zu entwickeln. Mit anderen Worten, ihren eigenen oder Open Source-basierten Lösungen, vorzugsweise in Java, wurde Vorrang eingeräumt.
Entscheidungen, Entscheidungen
Bei der Analyse möglicher Lösungen kamen wir zu zwei möglichen Architekturoptionen:
Der erste besteht darin, einen beliebigen SQL Server zu verwenden und die erforderliche Fehlertoleranz, den Skalierungsmechanismus, den Failovercluster, die Konfliktlösung und verteilte, zuverlässige und schnelle ACID-Transaktionen zu implementieren. Wir haben diese Option als nicht trivial und zeitaufwändig eingestuft.
Die zweite Möglichkeit besteht darin, ein vorgefertigtes NoSQL-Repository mit implementierter Skalierung, einem Failover-Cluster und Konfliktlösung zu verwenden und Transaktionen und SQL selbst zu implementieren. Auf den ersten Blick scheint selbst die Aufgabe der Implementierung von SQL, ganz zu schweigen von ACID-Transaktionen, jahrelang eine Aufgabe zu sein. Aber dann merkten wir , dass eine Reihe von SQL - Funktionen , die wir in der Praxis verwenden, weit weg von ANSI SQL bis
Cassandra CQL weit von ANSI SQL. Bei näherer Betrachtung von CQL stellten wir fest, dass es nah genug an dem war, was wir brauchten.
Cassandra und CQL
Also, was ist interessant an Cassandra, welche Fähigkeiten hat es?
Zunächst können Sie hier Tabellen mit Unterstützung für verschiedene Datentypen erstellen. Sie können SELECT oder UPDATE für den Primärschlüssel ausführen.
CREATE TABLE photos (id bigint KEY, owner bigint,…); SELECT * FROM photos WHERE id=?; UPDATE photos SET … WHERE id=?;
Um konsistente Replikatdaten sicherzustellen, verwendet Cassandra einen
Quorum-Ansatz . Im einfachsten Fall bedeutet dies, dass, wenn drei Replikate derselben Zeile auf verschiedenen Knoten des Clusters platziert werden, der Datensatz als erfolgreich angesehen wird, wenn die meisten Knoten (d. H. Zwei von drei) den Erfolg dieser Schreiboperation bestätigen. Die Daten einer Reihe gelten als konsistent, wenn beim Lesen die meisten Knoten abgefragt und bestätigt wurden. Somit ist bei Vorhandensein von drei Replikaten eine vollständige und sofortige Datenkonsistenz im Falle eines Ausfalls eines Knotens garantiert. Dieser Ansatz ermöglichte es uns, ein noch zuverlässigeres Schema zu implementieren: Senden Sie immer Anforderungen an alle drei Replikate und warten Sie auf eine Antwort der beiden schnellsten. Die späte Antwort des dritten Replikats wird dann verworfen. Ein Knoten, der mit einer Antwort zu spät kommt, kann schwerwiegende Probleme haben - Bremsen, Speicherbereinigung in der JVM, direkte Speicherrückgewinnung im Linux-Kernel, Hardwarefehler, Trennung vom Netzwerk. Dies hat jedoch keine Auswirkungen auf die Vorgänge oder Daten des Kunden.
Der Ansatz, wenn wir uns drei Knoten zuwenden und eine Antwort von zwei erhalten, wird als
Spekulation bezeichnet : Eine Anfrage nach zusätzlichen Bemerkungen wird gesendet, noch bevor sie „abfällt“.
Ein weiterer Vorteil von Cassandra ist Batchlog - ein Mechanismus, der entweder die vollständige Anwendung oder die vollständige Nichtanwendung des von Ihnen vorgenommenen Änderungspakets garantiert. Dies ermöglicht es uns, A in ACID zu lösen - Atomizität sofort.
Die Transaktionen in Cassandra sind den sogenannten "
Lightweight-Transaktionen " am nächsten. Sie sind jedoch weit entfernt von "echten" ACID-Transaktionen: Tatsächlich ist es eine Gelegenheit,
CAS auf Daten von nur einem Datensatz zu erstellen, wobei ein Konsens über das schwere Protokoll Paxos erzielt wird. Daher ist die Geschwindigkeit solcher Transaktionen gering.
Was wir in Cassandra vermisst haben
Also mussten wir echte ACID-Transaktionen in Cassandra implementieren. Damit könnten wir leicht zwei weitere praktische Funktionen des klassischen DBMS implementieren: konsistente schnelle Indizes, mit denen wir Datenabtastungen nicht nur für den Primärschlüssel und den üblichen Generator monotoner Auto-Inkrement-IDs durchführen können.
C * eins
So wurde das neue
C * One DBMS geboren, das aus drei Arten von Serverknoten besteht:
- Speicher - die (fast) Standard-Cassandra-Server, die für die Speicherung von Daten auf lokalen Laufwerken verantwortlich sind. Wenn die Last und die Datenmenge zunehmen, kann ihre Anzahl leicht auf zehn oder Hunderte skaliert werden.
- Transaktionskoordinatoren - Aktiviert die Transaktionsausführung.
- Clients sind Anwendungsserver, die Geschäftsvorgänge implementieren und Transaktionen initiieren. Es kann Tausende solcher Kunden geben.
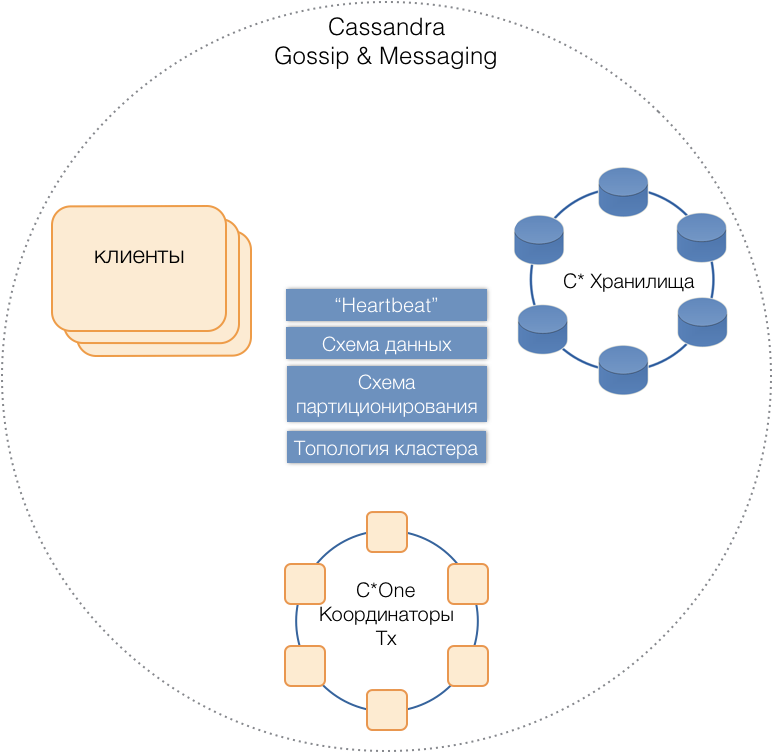
Alle Servertypen befinden sich in einem gemeinsamen Cluster. Verwenden Sie das interne Cassandra-Nachrichtenprotokoll, um miteinander zu kommunizieren, und
klatschen Sie , um Clusterinformationen auszutauschen. Mithilfe von Heartbeat lernen Server gegenseitige Fehler kennen, unterstützen ein einziges Datenschema - Tabellen, deren Struktur und Replikation. Partitionierungsschema, Clustertopologie usw.
Kunden
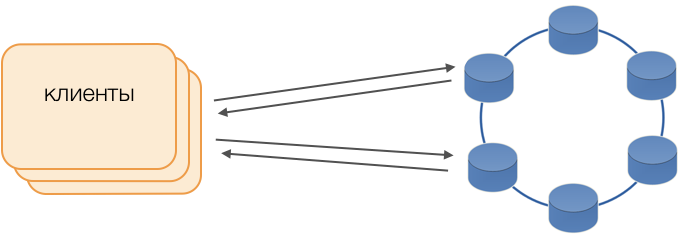
Anstelle von Standardtreibern wird der Fat Client-Modus verwendet. Ein solcher Knoten speichert keine Daten, kann jedoch als Koordinator für die Ausführung von Abfragen fungieren, dh der Client selbst führt die Funktion des Koordinators seiner Anforderungen aus: Er fragt Replikat-Repositorys ab und löst Konflikte. Dies ist nicht nur zuverlässiger und schneller als ein Standardtreiber, der die Kommunikation mit einem Remote-Koordinator erfordert, sondern ermöglicht Ihnen auch die Steuerung der Übertragung von Anforderungen. Außerhalb einer auf dem Client geöffneten Transaktion werden Anforderungen an den Speicher gesendet. Wenn der Client die Transaktion geöffnet hat, werden alle Anforderungen innerhalb der Transaktion an den Transaktionskoordinator gesendet.

C * Ein Transaktionskoordinator
Der Koordinator ist das, was wir für C * One von Grund auf neu implementiert haben. Er ist verantwortlich für die Verwaltung von Transaktionen, Sperren und der Reihenfolge, in der Transaktionen angewendet werden.
Für jede Transaktion, die bearbeitet wird, generiert der Koordinator einen Zeitstempel: Jede nachfolgende Transaktion ist größer als die vorherige Transaktion. Da das Konfliktlösungssystem in Cassandra auf Zeitstempeln basiert (von zwei widersprüchlichen Datensätzen wird der aktuelle mit dem neuesten Zeitstempel als relevant angesehen), wird der Konflikt immer zugunsten der nachfolgenden Transaktion gelöst. Daher haben wir
Lamport-Uhren implementiert - eine kostengünstige Möglichkeit, Konflikte in einem verteilten System zu lösen.
Schlösser
Um die Isolation sicherzustellen, haben wir uns für die einfachste Methode entschieden - pessimistische Sperren für den Primärschlüssel des Datensatzes. Mit anderen Worten, bei einer Transaktion muss der Datensatz zuerst gesperrt, erst dann gelesen, geändert und gespeichert werden. Erst nach einem erfolgreichen Commit kann ein Datensatz entsperrt werden, damit konkurrierende Transaktionen ihn verwenden können.
Das Implementieren dieser Sperre ist in einer nicht zugewiesenen Umgebung einfach. In einem verteilten System gibt es zwei Hauptmethoden: entweder verteilte Sperren für den Cluster implementieren oder Transaktionen verteilen, sodass Transaktionen mit einem einzelnen Datensatz immer von demselben Koordinator ausgeführt werden.
Da in unserem Fall die Daten bereits von lokalen Transaktionsgruppen in SQL verteilt werden, wurde beschlossen, den Koordinatoren lokale Transaktionsgruppen zuzuweisen: Ein Koordinator führt alle Transaktionen mit einem Token von 0 bis 9 aus, der zweite mit einem Token von 10 bis 19 usw. Infolgedessen wird jede der Koordinatorinstanzen zu einem Transaktionsgruppenstamm.
Dann können die Sperren als banale HashMap im Speicher des Koordinators implementiert werden.
Koordinatorfehler
Da ein Koordinator ausschließlich eine Gruppe von Transaktionen bedient, ist es sehr wichtig, die Tatsache des Ausfalls schnell festzustellen, damit ein wiederholter Versuch, die Transaktion auszuführen, abgelaufen ist. Um es schnell und zuverlässig zu machen, haben wir ein vollständig verbundenes Quorum-Hearbeat-Protokoll angewendet:
Jedes Rechenzentrum verfügt über mindestens zwei Koordinatorknoten. In regelmäßigen Abständen sendet jeder Koordinator eine Heartbeat-Nachricht an die anderen Koordinatoren und informiert sie über deren Funktionsweise sowie über die Heartbeat-Nachrichten, von denen die Koordinatoren im Cluster zum letzten Mal stammen.

Nachdem jeder Koordinator ähnliche Informationen von den anderen in der Zusammensetzung seiner Heartbeat-Nachrichten erhalten hat, entscheidet er selbst, welche Clusterknoten funktionieren und welche nicht. Dies richtet sich nach dem Quorum-Prinzip: Wenn der Knoten X von der Mehrheit der Knoten im Cluster Informationen über den normalen Empfang von Nachrichten vom Knoten Y erhalten hat, dann Y funktioniert. Umgekehrt ist Y fehlgeschlagen, sobald die Mehrheit den Verlust von Nachrichten vom Knoten Y meldet. Es ist merkwürdig, dass wenn ein Quorum dem Knoten X mitteilt, dass er keine weiteren Nachrichten von ihm empfängt, sich der Knoten X selbst als fehlgeschlagen betrachtet.
Herzschlagnachrichten werden mit einer hohen Frequenz von etwa 20 Mal pro Sekunde mit einer Dauer von 50 ms gesendet. In Java ist es aufgrund der vergleichbaren Länge der vom Garbage Collector verursachten Pausen schwierig, eine Anwendungsantwort von 50 ms zu gewährleisten. Mit dem G1-Garbage Collector konnten wir eine solche Reaktionszeit erreichen, mit der wir das Ziel für die Dauer der GC-Pausen angeben können. Manchmal, ziemlich selten, geht die Pause des Kollektors jedoch über 50 ms hinaus, was zu einer falschen Fehlererkennung führen kann. Um dies zu verhindern, meldet der Koordinator den Ausfall des Remote-Knotens nicht, wenn die erste Heartbeat-Nachricht von ihm verschwindet, nur wenn mehrere nacheinander verschwinden. Daher konnten wir den Knotenausfall des Koordinators in 200 ms erkennen.
Es reicht jedoch nicht aus, schnell zu verstehen, welcher Knoten nicht mehr funktioniert. Sie müssen etwas dagegen tun.
Reservierung
Das klassische Schema geht davon aus, dass im Falle der Weigerung eines Meisters, eine Neuwahl mit einem der
modischen universellen Algorithmen zu starten. Solche Algorithmen weisen jedoch bekannte Probleme mit der Zeitkonvergenz und der Dauer des Wahlprozesses selbst auf. Mit dem Ersatzschaltbild der Koordinatoren in einem vollständig verbundenen Netzwerk konnten wir solche zusätzlichen Verzögerungen vermeiden:
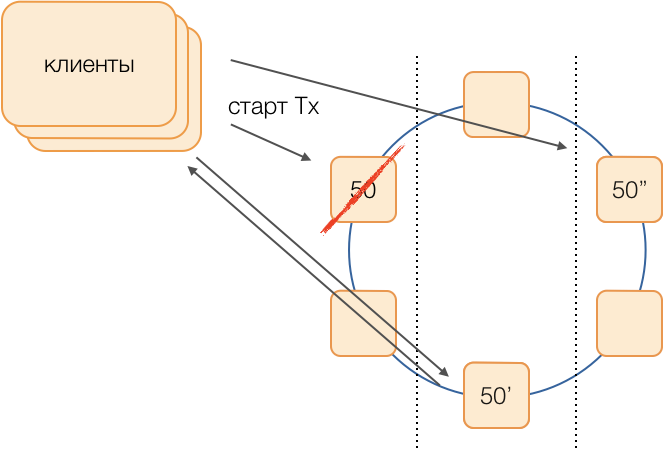
Angenommen, wir möchten eine Transaktion in Gruppe 50 ausführen. Wir werden im Voraus ein Substitutionsschema festlegen, dh welche Knoten Transaktionen der Gruppe 50 ausführen, wenn der Hauptkoordinator ausfällt. Unser Ziel ist es, das System bei einem Ausfall des Rechenzentrums betriebsbereit zu halten. Wir bestimmen, dass die erste Reserve ein Knoten aus einem anderen Rechenzentrum ist und die zweite Reserve ein Knoten aus dem dritten. Dieses Schema wird einmal ausgewählt und ändert sich erst, wenn sich die Clustertopologie ändert, dh bis neue Knoten in das Schema eintreten (was sehr selten vorkommt). Das Verfahren zur Auswahl eines neuen aktiven Masters bei Ausfall des alten ist immer das folgende: Die erste Reserve wird zum aktiven Master, und wenn sie nicht mehr funktioniert, wird die zweite Reserve.
Ein solches Schema ist zuverlässiger als der universelle Algorithmus, da es zur Aktivierung eines neuen Masters ausreicht, die Tatsache des Ausfalls des alten zu bestimmen.
Aber wie werden Kunden verstehen, welcher der Master jetzt arbeitet? Für 50 ms ist es nicht möglich, Informationen an Tausende von Kunden zu senden. Eine Situation ist möglich, wenn ein Client eine Anforderung zum Öffnen einer Transaktion sendet, ohne zu wissen, dass dieser Assistent nicht mehr funktioniert, und die Anforderung nach einer Zeitüberschreitung hängen bleibt. Um dies zu verhindern, senden Kunden spekulativ eine Anfrage zum sofortigen Öffnen einer Transaktion an den Gruppenmaster und seine beiden Reserven, aber nur derjenige, der derzeit der aktive Master ist, wird diese Anfrage beantworten. Der Client führt die gesamte nachfolgende Kommunikation innerhalb der Transaktion nur mit dem aktiven Master durch.
Die Sicherungsmaster erhalten Anforderungen für nicht eigene Transaktionen in der Warteschlange ungeborener Transaktionen, wo sie für einige Zeit gespeichert werden. Wenn der aktive Master stirbt, verarbeitet der neue Master Anforderungen zum Öffnen von Transaktionen aus seiner Warteschlange und antwortet dem Client. Wenn es dem Client bereits gelungen ist, eine Transaktion mit dem alten Master zu öffnen, wird die zweite Antwort ignoriert (und eine solche Transaktion wird offensichtlich nicht abgeschlossen und vom Client wiederholt).
Wie eine Transaktion funktioniert
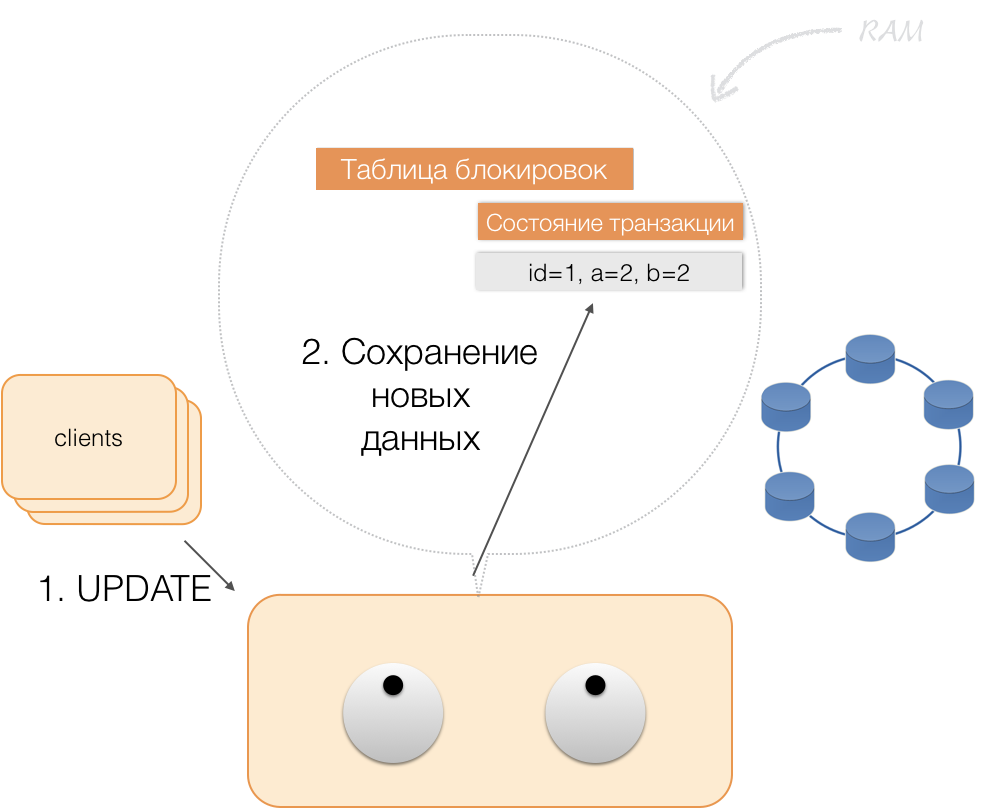
Angenommen, ein Client hat einem Koordinator eine Anforderung zum Öffnen einer Transaktion für eine solche Entität mit einem solchen Primärschlüssel gesendet. Der Koordinator sperrt diese Entität und legt sie in der Sperrtabelle im Speicher ab. Bei Bedarf liest der Koordinator diese Entität aus dem Speicher und speichert die empfangenen Daten in einem Transaktionsstatus im Speicher des Koordinators.
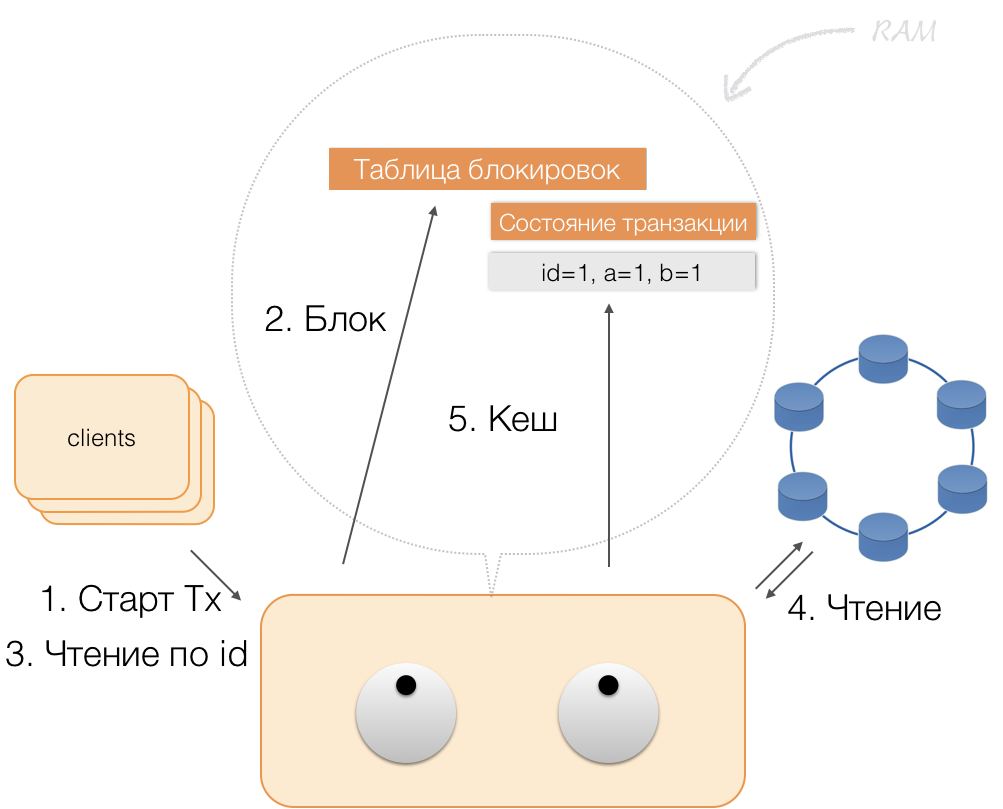
Wenn der Client die Daten in der Transaktion ändern möchte, sendet er dem Koordinator eine Anforderung zum Aktualisieren der Entität und legt die neuen Daten in der Transaktionsstatustabelle im Speicher ab. Damit ist die Aufzeichnung abgeschlossen - die Aufzeichnung wird nicht im Repository durchgeführt.
Wenn ein Client im Rahmen einer aktiven Transaktion seine eigenen geänderten Daten anfordert, verhält sich der Koordinator folgendermaßen:
- Befindet sich die ID bereits in der Transaktion, werden die Daten aus dem Speicher entnommen.
- Wenn sich keine ID im Speicher befindet, werden die fehlenden Daten von den Speicherknoten gelesen und mit den bereits im Speicher befindlichen Daten kombiniert. Das Ergebnis wird an den Client zurückgegeben.
Somit kann der Client seine eigenen Änderungen lesen, während andere Clients diese Änderungen nicht sehen, da sie nur im Speicher des Koordinators gespeichert sind und sich noch nicht in Cassandra-Knoten befinden.
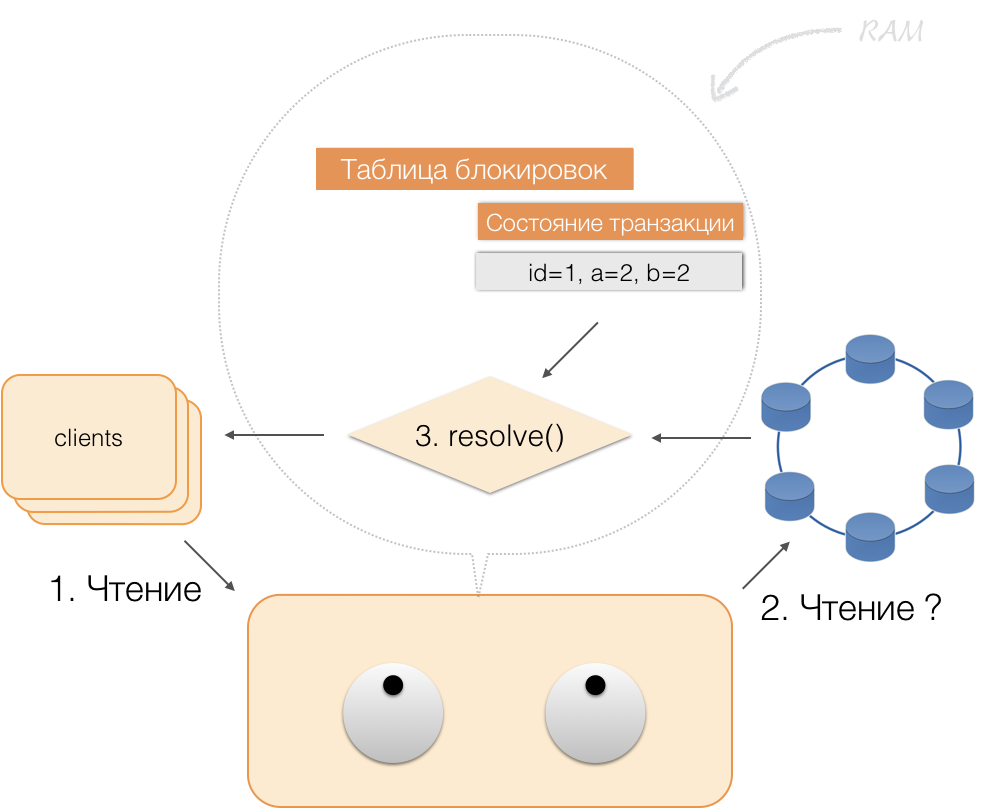
Wenn der Client ein Commit sendet, wird der Status im Speicher des Dienstes vom Koordinator im protokollierten Stapel gespeichert und bereits in Form eines protokollierten Stapels an die Cassandra-Repositorys gesendet. Repositorys tun alles, damit dieses Paket atomar (vollständig) angewendet werden kann, und senden eine Antwort an den Koordinator zurück, der die Sperren aufhebt und dem Client den Erfolg der Transaktion bestätigt.

Um zum Koordinator zurückzukehren, reicht es aus, den vom Status der Transaktion belegten Speicher freizugeben.
Als Ergebnis der oben genannten Verbesserungen haben wir die Prinzipien von ACID implementiert:
- Atomizität . Dies ist eine Garantie dafür, dass keine Transaktion teilweise an das System gebunden wird, alle Unteroperationen abgeschlossen werden oder keine einzige ausgeführt wird. Wir halten uns aufgrund der protokollierten Charge in Cassandra an dieses Prinzip.
- Konsistenz. Jede erfolgreiche Transaktion erfasst per Definition nur akzeptable Ergebnisse. Wenn nach dem Öffnen einer Transaktion und dem Ausführen eines Teils der Vorgänge festgestellt wird, dass das Ergebnis nicht gültig ist, wird ein Rollback durchgeführt.
- Isolierung . Wenn eine Transaktion ausgeführt wird, sollten parallele Transaktionen das Ergebnis nicht beeinflussen. Konkurrierende Transaktionen werden mithilfe pessimistischer Sperren des Koordinators isoliert. Bei Lesevorgängen außerhalb der Transaktion wird das Prinzip der Isolation auf der Ebene Read Committed eingehalten.
- Nachhaltigkeit . Unabhängig von den Problemen auf den unteren Ebenen - Systemabschaltung, Hardwarefehler - müssen Änderungen, die durch eine erfolgreich abgeschlossene Transaktion vorgenommen wurden, nach Wiederaufnahme des Betriebs gespeichert bleiben.
Index lesen
Nehmen Sie einen einfachen Tisch:
CREATE TABLE photos ( id bigint primary key, owner bigint, modified timestamp, …)
Sie hat eine ID (Primärschlüssel), einen Eigentümer und ein Änderungsdatum. Sie müssen eine sehr einfache Anfrage stellen - wählen Sie die Daten des Eigentümers mit dem Änderungsdatum "für den letzten Tag" aus.
SELECT * WHERE owner=? AND modified>?
Damit eine solche Abfrage schnell funktioniert, müssen Sie in klassischem SQL-DBMS einen Index nach Spalten erstellen (Eigentümer, geändert). Wir können das ganz einfach machen, da wir jetzt ACID-Garantien haben!
Indizes in C * One
Es gibt eine Quelltabelle mit Fotos, in der die Datensatz-ID der Primärschlüssel ist.

Für den C * -Index erstellt One eine neue Tabelle, die eine Kopie des Originals ist. Der Schlüssel entspricht dem Indexausdruck und enthält auch den Primärschlüssel des Datensatzes aus der Quelltabelle:
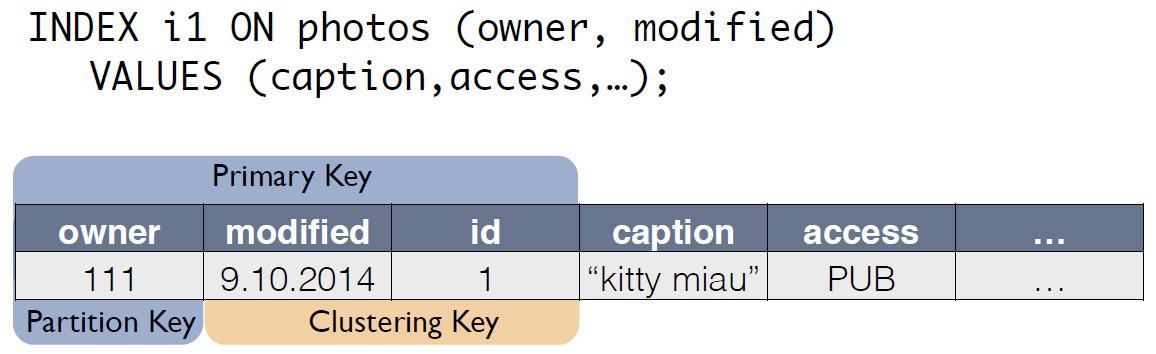
Jetzt kann die Anfrage nach dem "Eigentümer für den letzten Tag" als Auswahl aus einer anderen Tabelle umgeschrieben werden:
SELECT * FROM i1_test WHERE owner=? AND modified>?
Die Konsistenz der Daten aus der Originalfototabelle und dem Index i1 wird vom Koordinator automatisch beibehalten. Allein basierend auf dem Datenschema generiert und speichert der Koordinator die Änderung beim Empfang der Änderung nicht nur in der Haupttabelle, sondern auch in den Kopieränderungen. Mit der Indextabelle werden keine zusätzlichen Aktionen ausgeführt, Protokolle werden nicht gelesen, Sperren werden nicht verwendet. Das heißt, das Hinzufügen von Indizes verbraucht fast keine Ressourcen und hat praktisch keinen Einfluss auf die Geschwindigkeit, mit der Änderungen angewendet werden.
Mit ACID konnten wir Indizes „wie in SQL“ implementieren. Sie sind konsistent, können skaliert werden, schnell arbeiten, zusammengesetzt und in die CQL-Abfragesprache integriert werden.
Um Indizes zu unterstützen, müssen Sie keine Änderungen am Anwendungscode vornehmen. Alles ist einfach wie in SQL. Und am wichtigsten ist, dass Indizes die Ausführungsgeschwindigkeit von Änderungen an der ursprünglichen Transaktionstabelle nicht beeinflussen.Was ist passiert?
Wir haben C * One vor drei Jahren entwickelt und in Betrieb genommen.Was haben wir am Ende bekommen? Lassen Sie uns dies am Beispiel eines Subsystems zum Verarbeiten und Speichern von Fotos bewerten, einer der wichtigsten Arten von Daten in einem sozialen Netzwerk. Es geht nicht um die Körper der Fotos selbst, sondern um alle Arten von Metainformationen. In Odnoklassniki gibt es derzeit etwa 20 Milliarden solcher Datensätze. Das System verarbeitet 80.000 Leseanforderungen pro Sekunde und bis zu 8.000 ACID-Transaktionen pro Sekunde, die mit Datenänderungen verbunden sind.Bei Verwendung von SQL mit Replikationsfaktor = 1 (jedoch in RAID 10) wurden die Foto-Metainformationen auf einem gut zugänglichen Cluster von 32 Computern mit Microsoft SQL Server (plus 11 Sicherungen) gespeichert. Außerdem wurden 10 Server zum Speichern von Sicherungen zugewiesen. Insgesamt 50 teure Autos. Gleichzeitig arbeitete das System ohne Reserve bei Nennlast.Nach der Migration auf das neue System haben wir den Replikationsfaktor = 3 erhalten - eine Kopie in jedem Rechenzentrum. Das System besteht aus 63 Cassandra-Speicherknoten und 6 Koordinatormaschinen mit insgesamt 69 Servern. Diese Maschinen sind jedoch viel billiger. Ihre Gesamtkosten betragen etwa 30% der Systemkosten in SQL. In diesem Fall wird die Last bei 30% gehalten.Mit der Einführung von C * One nahmen auch die Verzögerungen ab: In SQL dauerte der Schreibvorgang etwa 4,5 ms. In C * One - ungefähr 1,6 ms. Die Transaktionsdauer beträgt durchschnittlich weniger als 40 ms, das Festschreiben erfolgt in 2 ms, die Lese- und Schreibdauer beträgt durchschnittlich 2 ms. Das 99. Perzentil - nur 3-3,1 ms, die Anzahl der Zeitüberschreitungen verringerte sich um das 100-fache - alles aufgrund der weit verbreiteten Verwendung von Spekulationen.Bisher wurden die meisten SQL Server-Knoten außer Betrieb genommen, neue Produkte werden nur mit C * One entwickelt. Wir haben C * One für die Arbeit in unserer One-Cloud angepasst , wodurch wir die Bereitstellung neuer Cluster beschleunigen, die Konfiguration vereinfachen und den Betrieb automatisieren konnten. Ohne Quellcode wäre es viel schwieriger und krückenherstellender.Jetzt arbeiten wir daran, unsere anderen Speichereinrichtungen in die Cloud zu übertragen - aber das ist eine ganz andere Geschichte.