Welche Anforderungen sollte der Metadatenspeicher für einen Cloud-Dienst erfüllen? Ja, nicht die üblichste, aber für Unternehmen mit Unterstützung für geografisch verteilte Rechenzentren und Active-Active. Offensichtlich sollte das System gut
skalierbar sein, fehlertolerant sein und in der Lage sein, anpassbare Betriebskonsistenzen zu implementieren.Nur Cassandra ist für all diese Anforderungen geeignet, und nichts anderes ist geeignet. Es sollte beachtet werden, dass Cassandra wirklich cool ist, aber die Arbeit damit ähnelt einer Achterbahnfahrt.
In einem Bericht auf der Highload ++ 2017 entschied
Andrei Smirnov (
smira ), dass es nicht interessant sei, über Gutes zu sprechen, aber er sprach ausführlich über jedes Problem, mit dem er konfrontiert war: über Datenverlust und Korruption, über Zombies und Leistungsverlust. Diese Geschichten erinnern wirklich an Achterbahn, aber für alle Probleme gibt es eine Lösung, für die Sie bei cat willkommen sind.
Über den Sprecher: Andrey Smirnov arbeitet für Virtustream, ein Unternehmen, das Cloud-Speicher für Unternehmen implementiert. Die Idee ist, dass Amazon die Cloud unter bestimmten Bedingungen für alle bereitstellt und Virtustream die spezifischen Dinge erledigt, die ein großes Unternehmen benötigt.
Ein paar Worte zu Virtustream
Wir arbeiten in einem völlig entfernten kleinen Team und arbeiten an einer der Virtustream-Cloud-Lösungen. Dies ist eine Wolke der Datenspeicherung.

Ganz einfach gesagt, dies ist eine S3-kompatible API, in der Sie Objekte speichern können. Für diejenigen, die nicht wissen, was S3 ist, ist es nur eine HTTP-API, mit der Sie Objekte irgendwo in die Cloud hochladen, zurückholen, löschen, eine Liste von Objekten abrufen usw. Weiter - komplexere Funktionen basierend auf diesen einfachen Operationen.
Wir haben einige Besonderheiten, die Amazon nicht hat. Eine davon sind die sogenannten Georegionen. In der üblichen Situation müssen Sie eine Region auswählen, wenn Sie ein Repository erstellen und angeben, dass Sie Objekte in der Cloud speichern. Eine Region ist im Wesentlichen ein Rechenzentrum, und Ihre Objekte werden dieses Rechenzentrum niemals verlassen. Wenn ihm etwas passiert, sind Ihre Objekte nicht mehr verfügbar.
Wir bieten Georegionen an, in denen sich Daten gleichzeitig in mehreren Rechenzentren (DC) befinden, mindestens in zwei, wie im Bild. Der Kunde kann jedes Rechenzentrum kontaktieren, für ihn ist es transparent. Die Daten zwischen ihnen werden repliziert, dh wir arbeiten im Aktiv-Aktiv-Modus und ständig. Dies bietet dem Client zusätzliche Funktionen, darunter:
- höhere Zuverlässigkeit beim Speichern, Lesen und Schreiben bei Gleichstromausfall oder Verbindungsverlust;
- Datenverfügbarkeit auch dann, wenn einer der DCs ausfällt;
- Umleiten von Vorgängen zum „nächsten“ DC.
Dies ist eine interessante Gelegenheit - selbst wenn diese DCs geografisch weit voneinander entfernt sind, können einige von ihnen zu unterschiedlichen Zeitpunkten näher am Kunden sein. Der Zugriff auf die Daten zum nächsten DC ist einfach schneller.
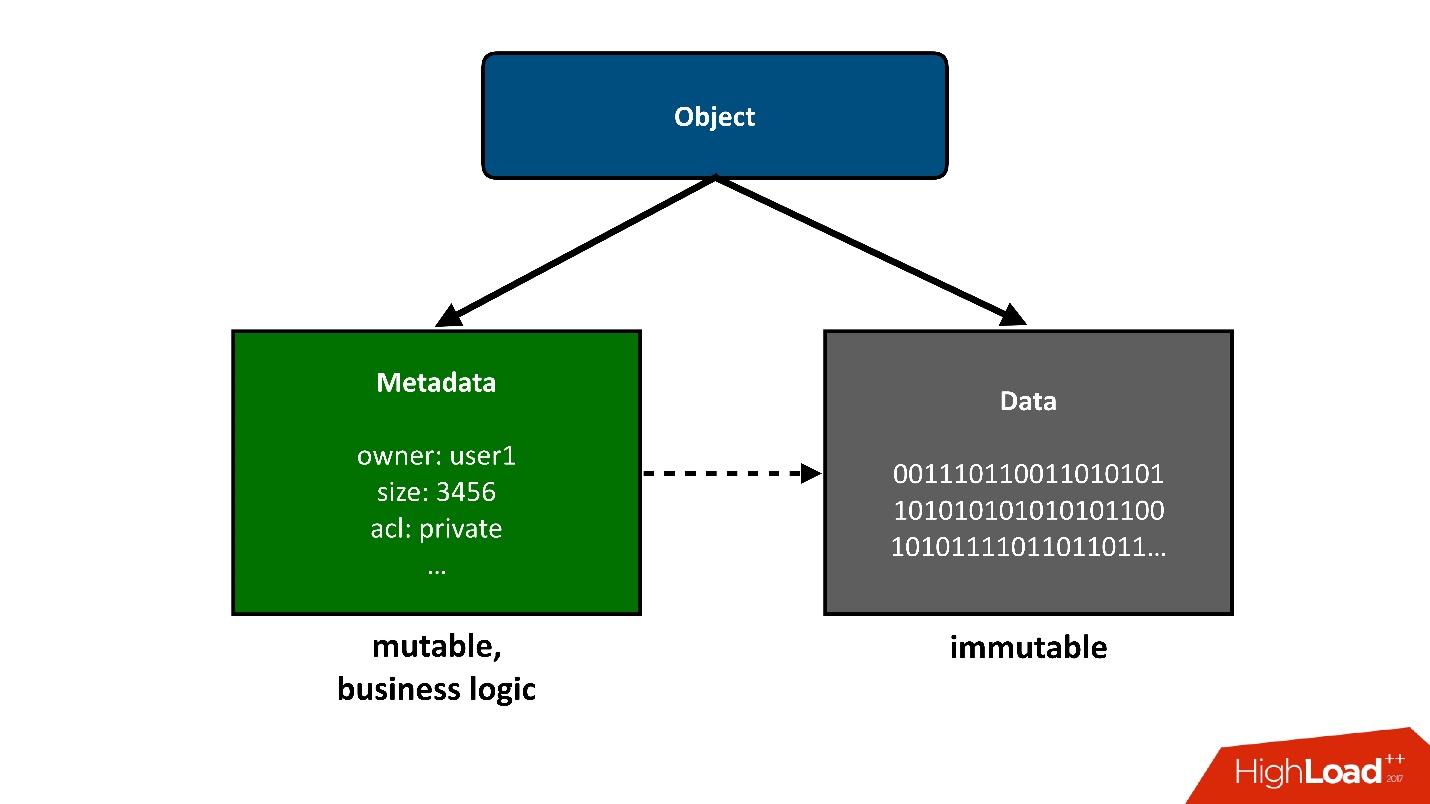
Um die Konstruktion, über die wir sprechen werden, in Teile zu unterteilen, werde ich die in der Wolke gespeicherten Objekte als zwei große Teile präsentieren:
1. Das erste einfache Teil eines Objekts sind
Daten . Sie sind unverändert, wurden einmal heruntergeladen und das ist alles. Das einzige, was ihnen später passieren kann, ist, dass wir sie entfernen können, wenn sie nicht mehr benötigt werden.
Unser vorheriges Projekt bezog sich auf die Speicherung von Exabyte an Daten, sodass wir keine Probleme mit der Datenspeicherung hatten. Dies war für uns bereits eine gelöste Aufgabe.
2.
Metadaten . Alle Geschäftslogiken, alle die interessantesten, bezogen auf den Wettbewerb: Zugriff, Aufzeichnungen, Umschreibungen - im Metadatenbereich.
Die Metadaten über das Objekt nehmen die größte Komplexität des Projekts in sich auf, die Metadaten speichern einen Zeiger auf den Block gespeicherter Daten des Objekts.
Aus Sicht des Benutzers ist dies ein einzelnes Objekt, aber wir können es in zwei Teile teilen. Heute werde ich
nur über Metadaten sprechen.
Zahlen
- Daten : 4 Pbytes.
- Metadatencluster : 3.
- Objekte : 40 Milliarden.
- Metadatengröße : 160 TB (einschließlich Replikation).
- Änderungsrate (Metadaten): 3000 Objekte / s.
Wenn Sie sich diese Indikatoren genau ansehen, fällt Ihnen als Erstes die sehr geringe durchschnittliche Größe des gespeicherten Objekts auf. Wir haben viele Metadaten pro Volumeneinheit der Stammdaten. Für uns war es nicht weniger überraschend als vielleicht für Sie jetzt.
Wir planten, dass wir mindestens eine Datenreihenfolge haben würden, wenn nicht 2, mehr als Metadaten. Das heißt, jedes Objekt ist erheblich größer und die Anzahl der Metadaten ist geringer. Weil das Speichern von Daten billiger ist, weniger Vorgänge mit ihnen und Metadaten sowohl im Sinne der Hardware als auch im Sinne der Wartung und Durchführung verschiedener Vorgänge viel teurer sind.
Darüber hinaus ändern sich diese Daten mit einer ziemlich hohen Geschwindigkeit. Ich habe hier den Spitzenwert angegeben, der Nicht-Spitzenwert ist nicht viel geringer, aber dennoch kann zu bestimmten Zeitpunkten eine ziemlich große Last erhalten werden.
Diese Zahlen stammen bereits aus einem funktionierenden System, aber lassen Sie uns ein wenig auf die Zeit des Entwurfs des Cloud-Speichers zurückgehen.
Auswählen eines Repositorys für Metadaten
Als wir uns der Herausforderung stellten, Georegionen, Active-Active, zu haben und Metadaten irgendwo speichern zu müssen, dachten wir, dass dies möglich sein könnte?
Offensichtlich sollte das Repository (Datenbank) die folgenden Eigenschaften haben:
- Aktiv-Aktiv-Support ;
- Skalierbarkeit.
Wir möchten wirklich, dass unser Produkt sehr beliebt ist, und wir wissen nicht, wie es gleichzeitig wachsen wird. Daher sollte das System skaliert werden.
- Das Gleichgewicht zwischen Fehlertoleranz und Speicherzuverlässigkeit.
Metadaten müssen sicher gespeichert werden, denn wenn wir sie verlieren und eine Verknüpfung zu den darin enthaltenen Daten besteht, verlieren wir das gesamte Objekt.
- Anpassbare Konsistenz der Operationen.
Aufgrund der Tatsache, dass wir in mehreren DCs arbeiten und die Möglichkeit zulassen, dass die DCs möglicherweise nicht verfügbar sind, sind die DCs außerdem weit voneinander entfernt. Während der meisten API-Vorgänge können wir nicht verlangen, dass dieser Vorgang gleichzeitig ausgeführt wird zwei DCs. Es wird einfach zu langsam und unmöglich sein, wenn der zweite DC nicht verfügbar ist. Daher sollte ein Teil der Operationen lokal in einem DC arbeiten.
Offensichtlich sollte jedoch irgendwann eine Art Konvergenz auftreten, und nach der Lösung aller Konflikte sollten die Daten in beiden Rechenzentren sichtbar sein. Daher muss die Konsistenz der Operationen angepasst werden.
Aus meiner Sicht ist Cassandra für diese Anforderungen geeignet.
Cassandra
Ich würde mich sehr freuen, wenn wir Cassandra nicht verwenden müssten, denn für uns war es eine Art neue Erfahrung. Sonst ist nichts geeignet. Dies scheint mir die traurigste Situation auf dem Markt für solche Speichersysteme zu sein - keine
Alternative .

Was ist Cassandra?
Dies ist eine verteilte Schlüsselwertdatenbank. Aus der Sicht der Architektur und der darin eingebetteten Ideen scheint mir alles cool zu sein. Wenn ich das tun würde, würde ich das Gleiche tun. Als wir anfingen, dachten wir darüber nach, unser eigenes Metadatenspeichersystem zu schreiben. Aber je weiter, desto mehr wurde uns klar, dass wir etwas sehr Ähnliches wie Cassandra tun müssen, und die Anstrengungen, die wir dafür aufwenden werden, sind es nicht wert. Für die gesamte Entwicklung
hatten wir nur anderthalb Monate . Es wäre seltsam, sie damit zu verbringen, Ihre Datenbank zu schreiben.
Wenn Cassandra wie eine Torte geschichtet wäre, würde ich drei Schichten auswählen:
1.
Lokaler KV-Speicher auf jedem Knoten.Dies ist ein Cluster von Knoten, von denen jeder Schlüsselwertdaten lokal speichern kann.
2.
Sharding von Daten auf Knoten (konsistentes Hashing).Cassandra kann Daten auf die Knoten des Clusters verteilen, einschließlich der Replikation, und zwar so, dass der Cluster größer oder kleiner werden kann und die Daten neu verteilt werden.
3. Ein
Koordinator zum Umleiten von Anforderungen an andere Knoten.Wenn wir über unsere Anwendung auf Daten für einige Abfragen zugreifen, kann Cassandra unsere Abfrage auf Knoten verteilen, sodass wir die gewünschten Daten und die erforderliche Konsistenzstufe erhalten - wir möchten sie nur als Quorum lesen. oder Quorum mit zwei DCs usw. wollen.
Für uns zwei Jahre bei Cassandra - es ist eine Achterbahn oder Achterbahn - was auch immer Sie wollen. Alles begann tief im Inneren, wir hatten keine Erfahrung mit Cassandra. Wir hatten Angst. Wir fingen an und alles war in Ordnung. Aber dann beginnen ständige Stürze und Starts: Das Problem, alles ist schlecht, wir wissen nicht, was wir tun sollen, wir bekommen Fehler, dann lösen wir das Problem usw.
Diese Achterbahnen enden im Prinzip nicht bis heute.
Gut
Das erste und letzte Kapitel, in dem ich sage, dass Cassandra cool ist. Es ist wirklich cool, ein großartiges System, aber wenn ich weiterhin sage, wie gut es ist, werden Sie wahrscheinlich nicht interessiert sein. Deshalb werden wir dem Schlechten mehr Aufmerksamkeit schenken, aber später.
Cassandra ist wirklich gut.
- Dies ist eines der Systeme, mit denen wir eine Reaktionszeit in Millisekunden haben können , dh offensichtlich weniger als 10 ms. Das ist gut für uns, denn die Reaktionszeit im Allgemeinen ist uns wichtig. Die Operation mit Metadaten ist für uns nur ein Teil einer Operation, die sich auf die Speicherung eines Objekts bezieht, unabhängig davon, ob es empfangen oder aufgezeichnet wird.
- Aus Sicht der Aufzeichnung wird eine hohe Skalierbarkeit erreicht. Sie können in Cassandra mit einer verrückten Geschwindigkeit schreiben, und in einigen Situationen ist dies beispielsweise erforderlich, wenn wir große Datenmengen zwischen Datensätzen verschieben.
- Cassandra ist wirklich fehlertolerant . Der Ausfall eines Knotens führt nicht sofort zu Problemen, obwohl sie früher oder später beginnen werden. Cassandra erklärt, dass es keinen einzigen Fehlerpunkt gibt, aber tatsächlich gibt es überall Fehlerpunkte. Tatsächlich weiß derjenige, der mit der Datenbank gearbeitet hat, dass selbst ein Knotenabsturz normalerweise erst am Morgen auftritt. Normalerweise muss diese Situation schneller behoben werden.
- Einfachheit. Im Vergleich zu anderen relationalen Cassandra-Standarddatenbanken ist es jedoch einfacher zu verstehen, was vor sich geht. Sehr oft geht etwas schief und wir müssen verstehen, was passiert. Cassandra hat mehr Chancen, es herauszufinden und wahrscheinlich zur kleinsten Schraube zu gelangen, als mit einer anderen Datenbank.
Fünf schlechte Geschichten
Ich wiederhole, Cassandra ist gut, es funktioniert für uns, aber ich werde fünf Geschichten über das Schlechte erzählen. Ich denke, dafür hast du es gelesen. Ich werde die Geschichten in chronologischer Reihenfolge geben, obwohl sie nicht sehr miteinander verbunden sind.

Diese Geschichte war die traurigste für uns. Da wir Benutzerdaten speichern, ist es das Schlimmste, sie zu verlieren und
sie für immer zu verlieren, wie es in dieser Situation geschehen ist. Wir haben Möglichkeiten bereitgestellt, Daten wiederherzustellen, wenn wir sie in Cassandra verlieren, aber wir haben sie verloren, so dass wir sie wirklich nicht wiederherstellen konnten.
Um zu erklären, wie dies geschieht, muss ich ein wenig darüber sprechen, wie alles in uns angeordnet ist.
Aus S3-Sicht gibt es einige grundlegende Dinge:
- Bucket - Es kann sich ein riesiger Katalog vorstellen, in den der Benutzer ein Objekt hochlädt (im Folgenden als Bucket bezeichnet).
- Jedem Objekt sind ein Name (Schlüssel) und Metadaten zugeordnet: Größe, Inhaltstyp und ein Zeiger auf die Daten des Objekts. Gleichzeitig ist die Größe des Eimers durch nichts begrenzt. Das heißt, es können 10 Schlüssel sein, vielleicht 100 Milliarden Schlüssel - es gibt keinen Unterschied.
- Jeder wettbewerbsfähige Vorgang ist möglich, dh es können mehrere wettbewerbsfähige Füllungen im selben Schlüssel vorhanden sein, es kann zu einer Löschung des Wettbewerbs usw. kommen.
In unserer Situation können Aktiv-Aktiv-Operationen stattfinden, auch wettbewerbsfähig in verschiedenen DCs, nicht nur in einem. Daher brauchen wir eine Art Erhaltungsschema, mit dem wir eine solche Logik implementieren können. Am Ende haben wir eine einfache Richtlinie gewählt: Die zuletzt aufgezeichnete Version gewinnt. Manchmal finden mehrere Wettbewerbsvorgänge statt, aber es ist nicht erforderlich, dass unsere Kunden dies absichtlich tun. Es kann nur eine Anfrage sein, die gestartet wurde, aber der Client hat nicht auf eine Antwort gewartet, etwas anderes ist passiert, hat es erneut versucht usw.
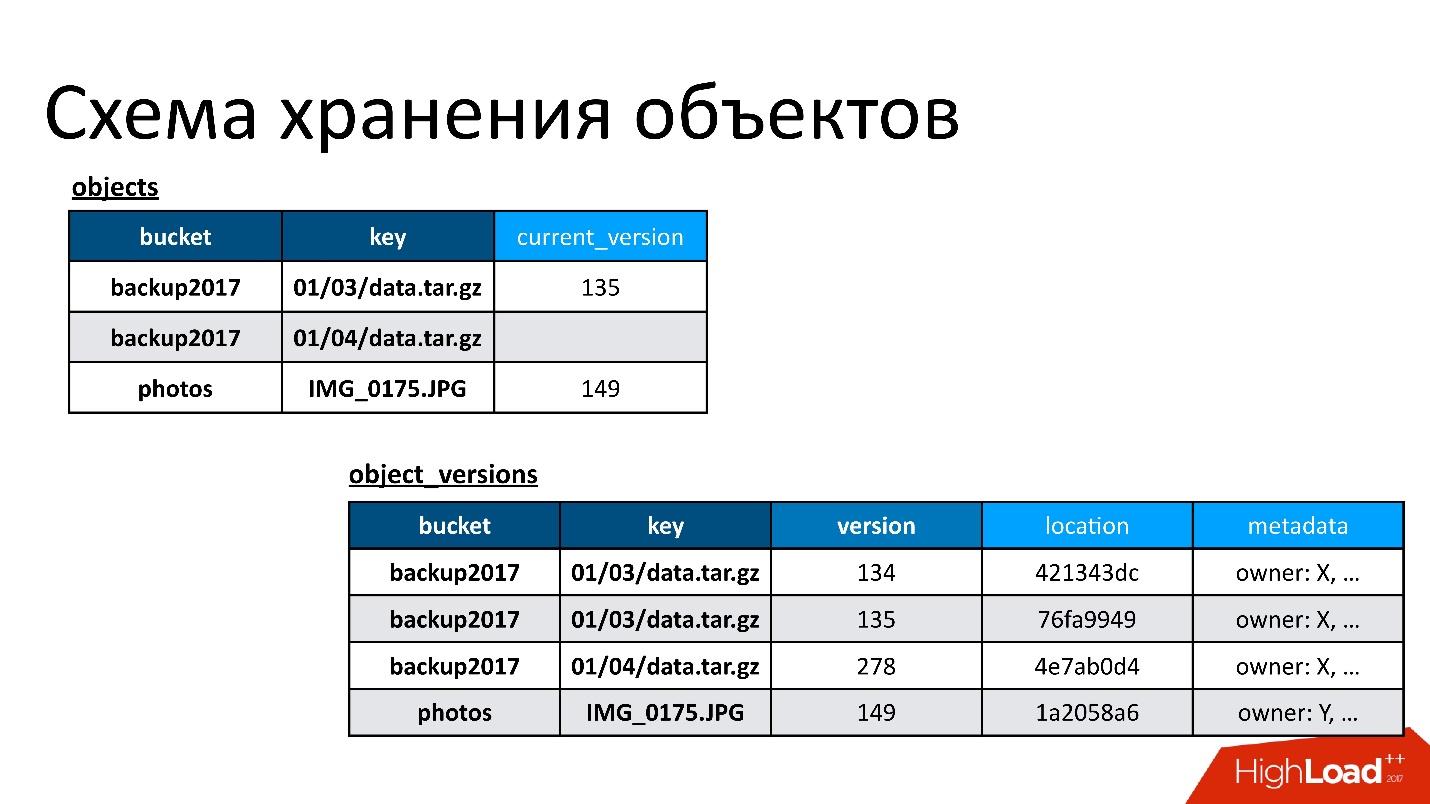
Daher haben wir zwei Basistabellen:
- Objekttabelle . Darin ist ein Paar - der Name des Buckets und der Name des Schlüssels - seiner aktuellen Version zugeordnet. Wenn das Objekt gelöscht wird, ist in dieser Version nichts enthalten. Wenn das Objekt vorhanden ist, gibt es seine aktuelle Version. Tatsächlich ändern wir in dieser Tabelle nur das Feld der aktuellen Version.
- Versionstabelle der Objekte . Wir fügen nur neue Versionen in diese Tabelle ein. Jedes Mal, wenn ein neues Objekt heruntergeladen wird, fügen wir eine neue Version in die Versionstabelle ein, geben ihr eine eindeutige Nummer, speichern alle Informationen dazu und aktualisieren am Ende den Link dazu in der Objekttabelle.
Die Abbildung zeigt ein Beispiel für die Beziehung zwischen Objekttabellen und Versionen von Objekten.

Hier ist ein Objekt mit zwei Versionen - eine aktuelle und eine alte, es gibt ein Objekt, das bereits gelöscht wurde, und seine Version ist noch vorhanden. Wir müssen von Zeit zu Zeit unnötige Versionen bereinigen, dh etwas löschen, auf das sich sonst niemand bezieht. Darüber hinaus müssen wir es nicht sofort löschen, wir können es im verzögerten Modus tun. Dies ist unsere interne Reinigung, wir löschen nur das, was nicht mehr benötigt wird.
Es gab ein Problem.
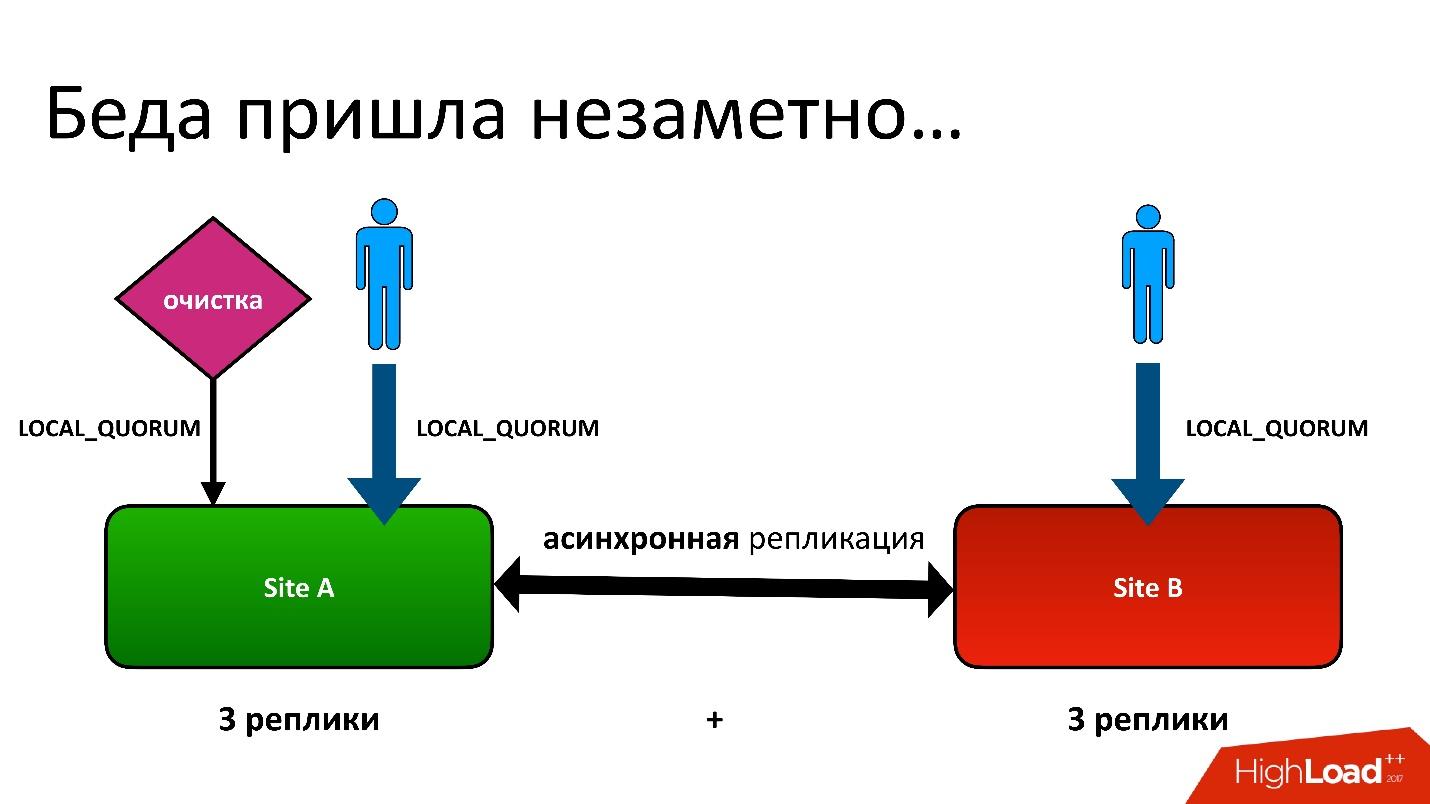
Das Problem war folgendes: Wir haben Aktiv-Aktiv, zwei DCs. In jedem DC werden Metadaten in drei Kopien gespeichert, dh wir haben 3 + 3 - nur 6 Replikate. Wenn Kunden uns kontaktieren, führen wir Operationen mit Konsistenz durch (aus Sicht von Cassandra heißt es LOCAL_QUORUM). Das heißt, es wird garantiert, dass der Datensatz (oder das Lesen) in 2 Replikaten im lokalen DC aufgetreten ist. Dies ist eine Garantie - andernfalls schlägt der Vorgang fehl.
Cassandra wird immer versuchen, in allen 6 Zeilen zu schreiben - 99% der Zeit wird alles in Ordnung sein. Tatsächlich sind alle 6 Repliken gleich, aber uns garantiert 2.
Wir hatten eine schwierige Situation, obwohl es nicht einmal eine Georegion war. Selbst für normale Regionen in einem Domänencontroller haben wir die zweite Kopie der Metadaten in einem anderen Domänencontroller gespeichert. Dies ist eine lange Geschichte, ich werde nicht alle Details geben. Aber am Ende hatten wir einen Bereinigungsprozess, bei dem unnötige Versionen entfernt wurden.
Und dann trat das gleiche Problem auf. Der Reinigungsprozess funktionierte auch mit der Konsistenz des lokalen Quorums in einem Rechenzentrum, da es keinen Sinn macht, es in zwei Rechenzentren auszuführen - sie werden sich gegenseitig bekämpfen.
Alles war in Ordnung, bis sich herausstellte, dass unsere Benutzer manchmal noch in ein anderes Rechenzentrum schreiben, was wir nicht vermuteten. Alles wurde nur für den Fall des Feylovers eingerichtet, aber es stellte sich heraus, dass sie es bereits benutzten.
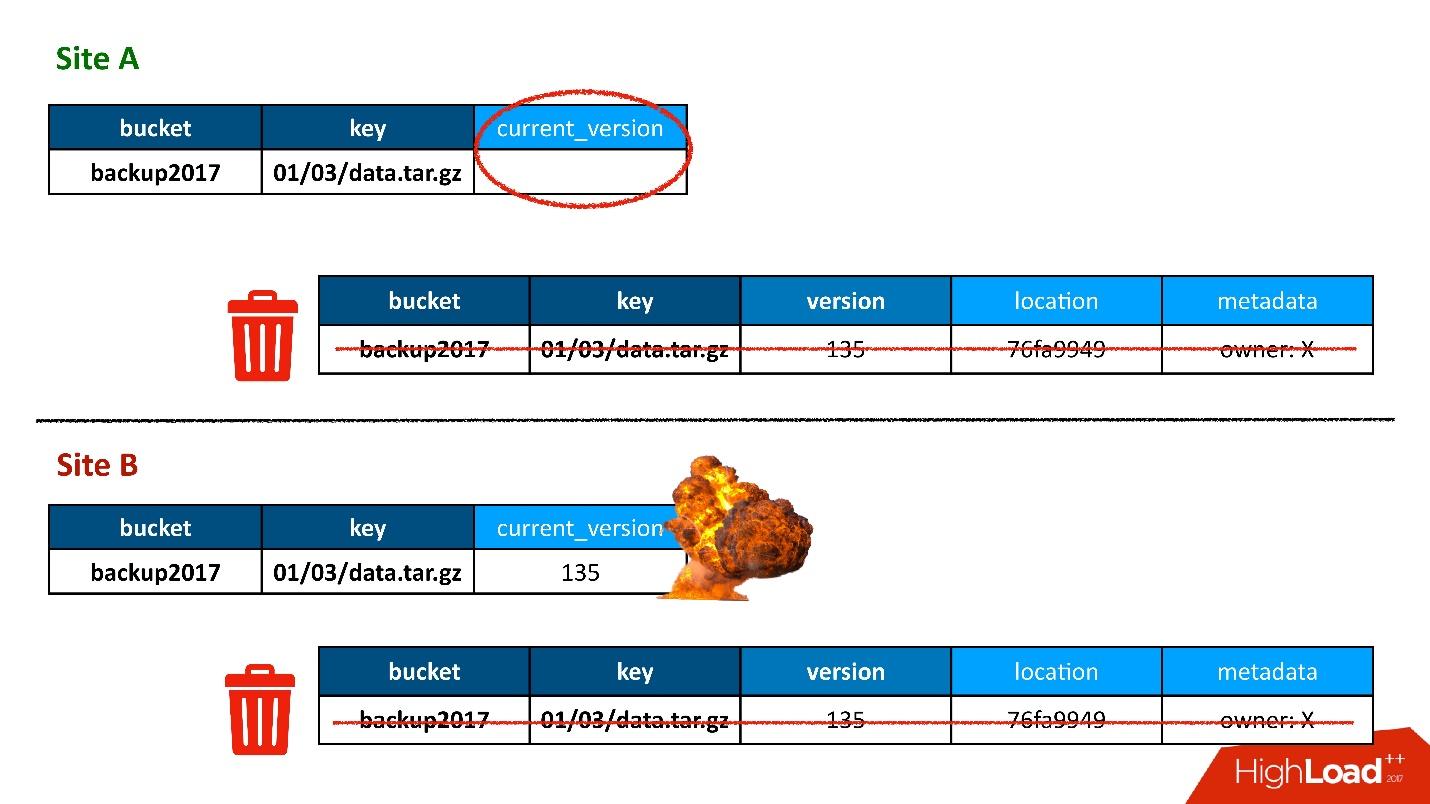
Meistens war alles in Ordnung, bis eines Tages eine Situation eintrat, in der ein Datensatz in der Versionstabelle in beiden Domänencontrollern repliziert wurde, der Datensatz in der Objekttabelle sich jedoch als nur in einem Domänencontroller befand, jedoch nicht in den zweiten überging. Dementsprechend stellte das Reinigungsverfahren, das im ersten (oberen) DC gestartet wurde, fest, dass es eine Version gab, auf die sich niemand bezog, und löschte sie. Und ich habe nicht nur die Version gelöscht, sondern natürlich auch die Daten - alles ist komplett, weil es nur ein unnötiges Objekt ist. Und diese Entfernung ist unwiderruflich.
Natürlich gibt es einen weiteren „Boom“, da wir immer noch einen Datensatz in der Objekttabelle haben, der sich auf eine Version bezieht, die nicht mehr existiert.
Das erste Mal haben wir Daten verloren, und wir haben sie wirklich unwiderruflich verloren - gut, ein bisschen.
Lösung
Was zu tun ist? In unserer Situation ist alles einfach.
Da wir Daten in zwei Rechenzentren gespeichert haben, ist der Reinigungsprozess ein Prozess der Konvergenz und Synchronisation. Wir müssen Daten von beiden DCs lesen. Dieser Vorgang funktioniert nur, wenn beide DCs verfügbar sind. Da ich sagte, dass dies ein verzögerter Prozess ist, der während der Verarbeitung der API nicht auftritt, ist dies nicht beängstigend.
Konsistenz ALL ist ein Merkmal von Cassandra 2. In Cassandra 3 ist alles etwas besser - es gibt eine Konsistenzstufe, die in jedem DC als Quorum bezeichnet wird. Aber auf jeden Fall gibt es das Problem, dass es
langsam ist , weil wir uns zuerst an den Remote-DC wenden müssen. Zweitens bedeutet dies im Fall der Konsistenz aller 6 Knoten, dass es mit der Geschwindigkeit des schlechtesten dieser 6 Knoten arbeitet.
Gleichzeitig findet jedoch der sogenannte
Read-Repair- Prozess statt, wenn nicht alle Replikate synchron sind. Das heißt, wenn die Aufzeichnung irgendwo fehlgeschlagen ist, werden sie durch diesen Vorgang gleichzeitig repariert. So funktioniert Cassandra.
In diesem Fall erhielten wir vom Kunden eine Beschwerde, dass das Objekt nicht verfügbar war. Wir haben es herausgefunden, verstanden warum und als erstes wollten wir herausfinden, wie viele solcher Objekte wir noch haben. Wir haben ein Skript ausgeführt, das versucht hat, ein ähnliches Konstrukt zu finden, wenn in einer Tabelle ein Eintrag vorhanden war, in einer anderen jedoch kein Eintrag.
Plötzlich stellten wir fest, dass wir
10% dieser Aufzeichnungen haben . Wahrscheinlich hätte nichts Schlimmeres passieren können, wenn wir nicht geahnt hätten, dass dies nicht der Fall ist. Das Problem war anders.

Zombies haben sich in unsere Datenbank eingeschlichen. Dies ist der halboffizielle Name für dieses Problem. Um zu verstehen, was es ist, müssen Sie darüber sprechen, wie das Entfernen in Cassandra funktioniert.
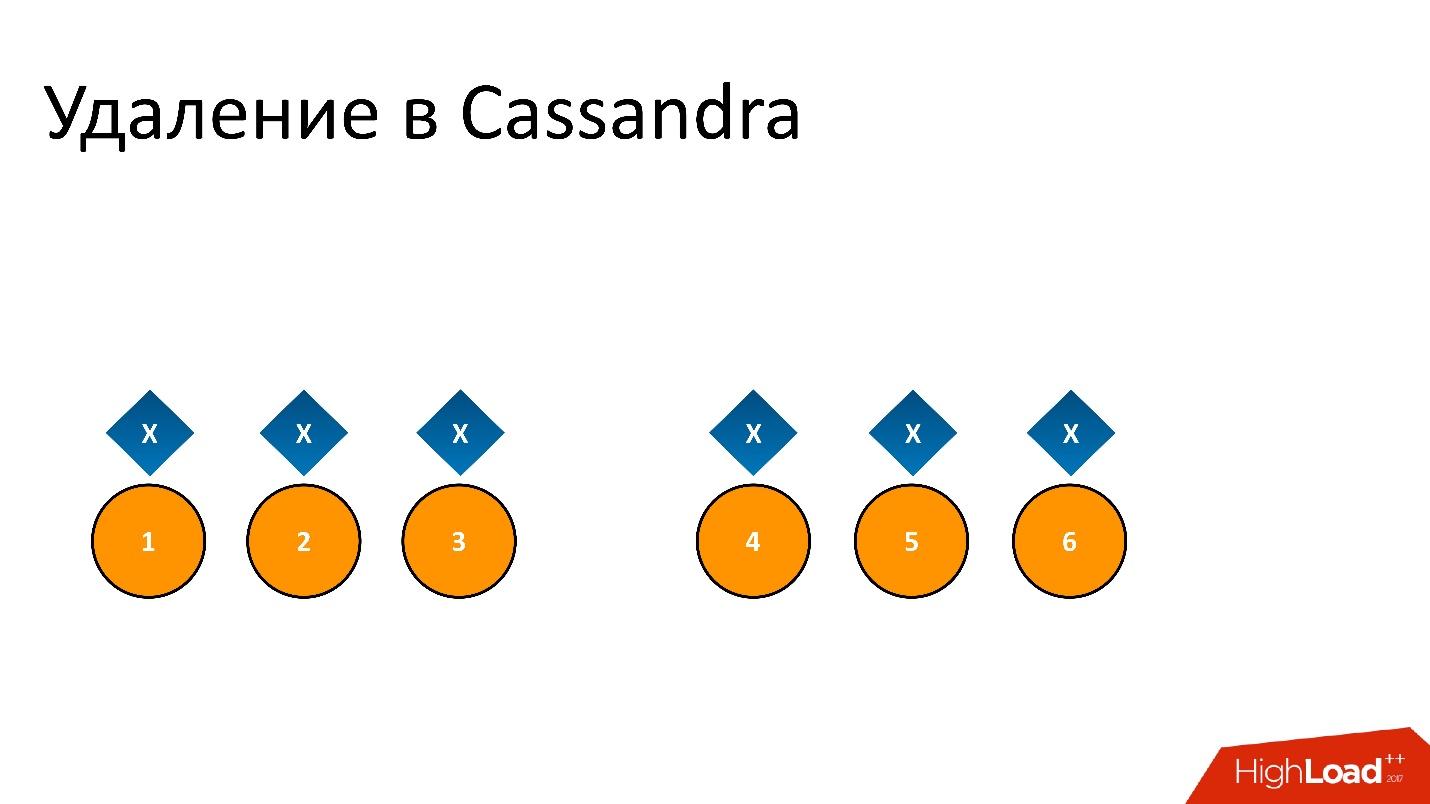
Zum Beispiel haben wir einige Daten
x , die aufgezeichnet und perfekt auf alle 6 Replikate repliziert werden. Wenn wir es löschen möchten, wird das Entfernen wie bei jeder Operation in Cassandra möglicherweise nicht auf allen Knoten durchgeführt.
Zum Beispiel wollten wir die Konsistenz von 2 von 3 in einem DC gewährleisten. Lassen Sie den Löschvorgang auf fünf Knoten ausgeführt werden, bleiben Sie jedoch in einem Datensatz, z. B. weil der Knoten zu diesem Zeitpunkt nicht verfügbar war.
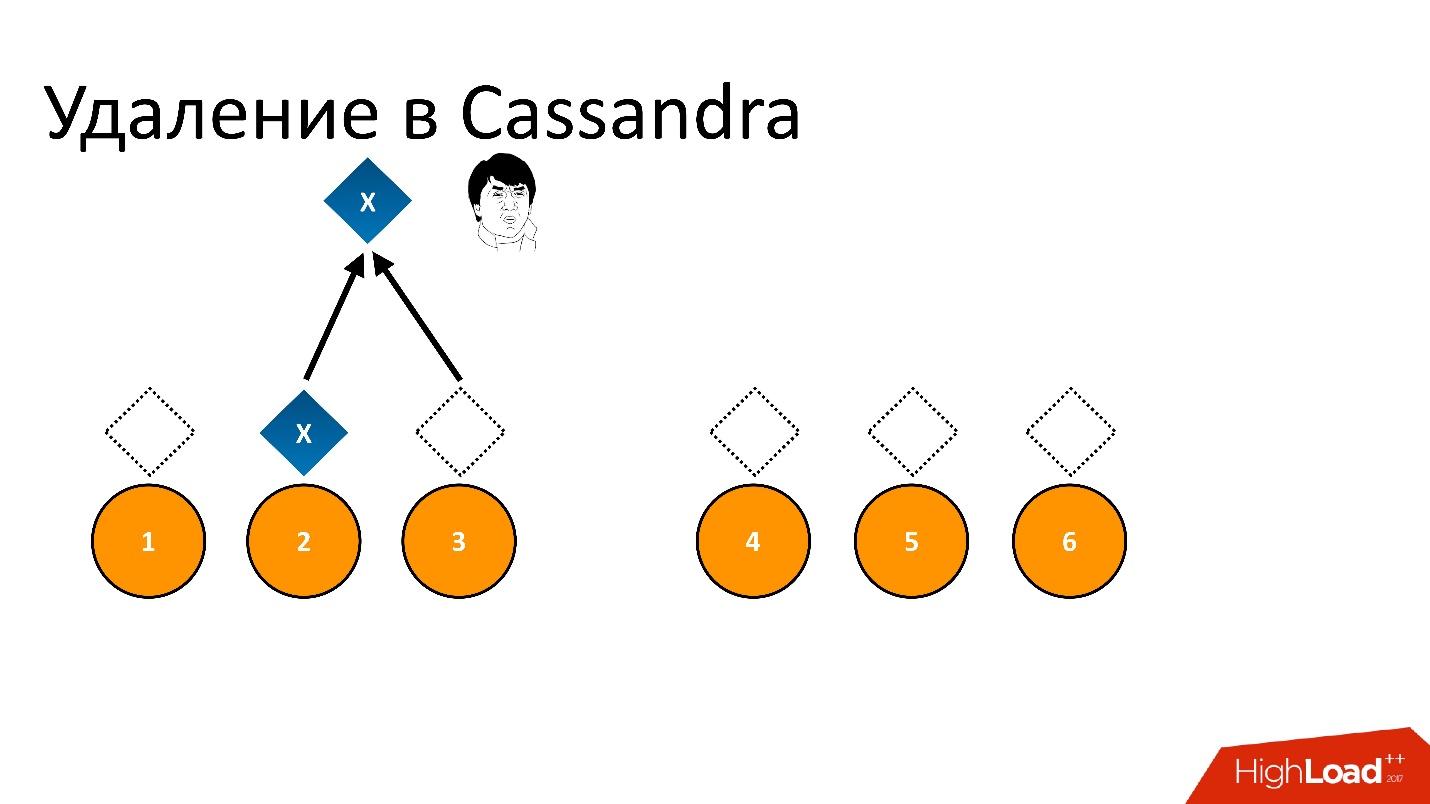
Wenn wir dies löschen und dann versuchen, "Ich möchte 2 von 3" mit derselben Konsistenz zu lesen, interpretiert Cassandra den Wert und seine Abwesenheit als das Vorhandensein von Daten. Das heißt, wenn sie zurückliest, wird sie sagen: "Oh, es gibt Daten!", Obwohl wir sie gelöscht haben. Daher können Sie auf diese Weise nicht löschen.

Cassandra entfernt anders.
Das Löschen ist eigentlich ein Datensatz . Wenn wir Daten löschen, schreibt Cassandra einen kleinen Marker namens
Tombstone (Tombstone). Es markiert, dass die Daten gelöscht werden. Wenn wir also das Löschtoken und die Daten gleichzeitig lesen, bevorzugt Cassandra in dieser Situation immer das Löschtoken und sagt, dass tatsächlich keine Daten vorhanden sind. Das brauchen Sie.
Tombstone — , , , , - , . Tombstone .
Tombstone gc_grace_period . , , .
?
Repair
Cassandra , Repair (). — , . , , , , / , , - - , .. . Repair , .

, - , - . Repair , , . - , — . , .

Repair, , , , — , . 6 . — , , .

, — , - . , . , - , , , .
Lösung
, :
, repair. , , .
repair — , repair. , , 10-20 , , 3 . Tombstone , . , , -.

Cassandra, . .
S3 . , — 10 , 100 . API, — . , , , , , . , , , — , . .
API?

, — , , — , , . . — . , , . , , Cassandra. , — , , , .
, , , , . , . , , . , - , .
Cassandra , . , , , , , .
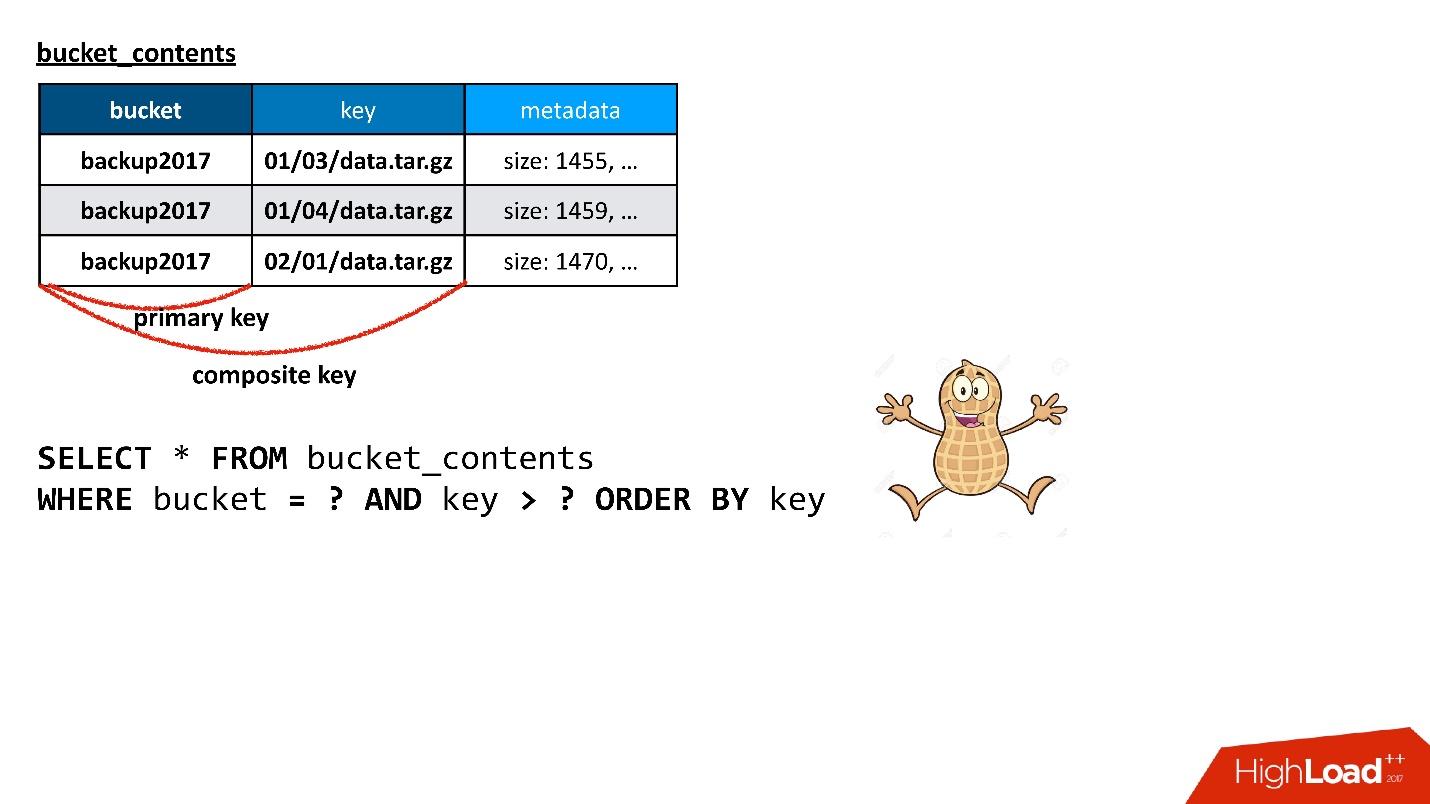
, Cassandra
composite key . , — , - , — . , . ? , , !
, , , , — , .
. Cassandra ,
Cassandra . , , Cassandra, : , , SQL .. !

. Cassandra ? , , API. , , , , ( ) .
, .
, . , , , . , — — . , , , .
Cassandra , . : « 100 », , , , , , 100, .
, ( ), — , , . , , , , , - . 100 , - , , . , SQL .
Cassandra , , Java, . ,
Large Partition , . — , , , , — . , , garbage collection .. .
, ,
, , .
, , - .

, , . . , Large Partition.
:
- ( , - );
- , , . , .
, , , key_hash 0. ,
, . , . , , .
, .

— , , , - - .
— , N ? , Large Partition, — . , . : . , , , , - . , . , , .

— , , - . - , , . , , . , , ..
— , ? , . ? - md5- — , - 30 — , - . . , , .

, , , , . — , . , . , - - - , - - — . , . .
, , , .
Wir haben jetzt einen Zustand des Eimers, der irgendwie in Partitionen unterteilt ist. Dann verstehen wir, dass einige Partitionen zu groß oder zu klein sind. Wir müssen eine neue Partition finden, die einerseits optimal ist, dh die Größe jeder Partition liegt unter einigen unserer Grenzen und ist mehr oder weniger einheitlich. In diesem Fall sollte der Übergang vom aktuellen in einen neuen Zustand eine Mindestanzahl von Aktionen erfordern. Es ist klar, dass für jeden Übergang Schlüssel zwischen Partitionen verschoben werden müssen. Je weniger wir sie verschieben, desto besser.
Wir haben es geschafft. Wahrscheinlich ist der Teil, der sich mit der Auswahl der Verteilung befasst, der schwierigste Teil des gesamten Dienstes, wenn wir über die Arbeit mit Metadaten im Allgemeinen sprechen. Wir haben es umgeschrieben, überarbeitet und tun es immer noch, weil immer einige Clients oder bestimmte Muster zum Erstellen von Schlüsseln gefunden werden, die eine Schwachstelle dieses Schemas treffen.
Zum Beispiel haben wir angenommen, dass der Eimer mehr oder weniger gleichmäßig wachsen würde. Das heißt, wir haben eine Art Distribution aufgenommen und gehofft, dass alle Partitionen entsprechend dieser Distribution wachsen würden. Aber wir haben einen Kunden gefunden, der am Ende immer schreibt, in dem Sinne, dass seine Schlüssel immer in sortierter Reihenfolge sind. Die ganze Zeit schlägt er in der allerletzten Partition, die so schnell wächst, dass es in einer Minute 100.000 Tasten sein können. Und 100.000 ist ungefähr der Wert, der in eine Partition passt.
Wir hätten einfach keine Zeit, eine solche Hinzufügung von Schlüsseln mit unserem Algorithmus zu verarbeiten, und wir mussten eine spezielle vorläufige Verteilung für diesen Client einführen. Da wir wissen, wie seine Schlüssel aussehen, beginnen wir, wenn wir sehen, dass er es ist, am Ende im Voraus leere Partitionen zu erstellen, damit er dort ruhig schreiben kann, und wir würden uns vorerst bis zur nächsten Iteration etwas ausruhen, wenn wir es erneut müssen alles neu verteilen.
All dies geschieht online in dem Sinne, dass wir den Betrieb nicht stoppen. Es kann Lese- und Schreibvorgänge geben. Sie können jederzeit eine Liste von Schlüsseln anfordern. Es wird immer konsistent sein, auch wenn wir gerade dabei sind, die Partitionierung vorzunehmen.
Es ist ziemlich interessant und es stellt sich mit Cassandra heraus. Hier können Sie mit Tricks spielen, die damit zusammenhängen, dass Cassandra Konflikte lösen kann. Wenn wir zwei verschiedene Werte in dieselbe Zeile geschrieben haben, gewinnt der Wert mit einem größeren Zeitstempel.
Normalerweise ist der Zeitstempel der aktuelle Zeitstempel, er kann jedoch manuell übergeben werden. Zum Beispiel möchten wir einen Wert in eine Zeichenfolge schreiben, der auf jeden Fall gerieben werden sollte, wenn der Client selbst etwas schreibt. Das heißt, wir kopieren einige Daten, aber wir möchten, dass der Client, wenn er plötzlich gleichzeitig mit uns schreibt, diese überschreiben kann. Dann können wir unsere Daten einfach mit einem Zeitstempel aus der Vergangenheit kopieren. Dann wird jede aktuelle Aufnahme absichtlich ausgefranst, unabhängig von der Reihenfolge, in der die Aufnahme gemacht wurde.
Mit solchen Tricks können Sie dies online tun.
Lösung
- Lassen Sie niemals das Erscheinen einer großen Trennwand zu .
- Brechen Sie die Daten je nach Aufgabe nach Primärschlüssel auf.
Wenn im Datenschema etwas Ähnliches wie eine große Partition geplant ist, sollten Sie sofort versuchen, etwas dagegen zu unternehmen - finden Sie heraus, wie Sie es brechen und wie Sie davon wegkommen. Früher oder später tritt dies auf, weil jeder invertierte Index früher oder später in fast jeder Aufgabe entsteht. Ich habe Ihnen bereits von einer solchen Geschichte erzählt - wir haben einen Bucket-Schlüssel im Objekt, und wir müssen eine Liste der Schlüssel aus dem Bucket abrufen - tatsächlich ist dies ein Index.
Darüber hinaus kann die Partition nicht nur aus den Daten, sondern auch aus Tombstones (Löschmarkierungen) groß sein. Aus Sicht der Cassandra-Interna (wir sehen sie nie von außen) sind Löschmarkierungen auch Daten, und eine Partition kann groß sein, wenn viele Dinge darin gelöscht werden, da das Löschen ein Datensatz ist. Das sollten Sie auch nicht vergessen.

Eine andere Geschichte, die tatsächlich konstant ist, ist, dass von Anfang bis Ende etwas schief geht. Sie sehen beispielsweise, dass sich die Antwortzeit von Cassandra erhöht hat und langsam reagiert. Wie kann man das Problem verstehen und verstehen? Es gibt nie ein externes Signal, dass das Problem vorliegt.

Zum Beispiel gebe ich ein Diagramm - dies ist die durchschnittliche Antwortzeit des gesamten Clusters. Es zeigt, dass wir ein Problem haben - die maximale Antwortzeit beträgt 12 Sekunden - dies ist das interne Timeout von Cassandra. Dies bedeutet, dass sie sich eine Auszeit nehmen wird. Wenn das Zeitlimit über 12 s liegt, bedeutet dies höchstwahrscheinlich, dass der Garbage Collector funktioniert und Cassandra nicht einmal Zeit hat, zum richtigen Zeitpunkt zu reagieren. Sie antwortet sich per Timeout, aber die Antwortzeit auf die meisten Anfragen sollte, wie gesagt, im Durchschnitt innerhalb von 10 ms liegen.
In der Grafik hat der Durchschnitt bereits Hunderte von Millisekunden überschritten - etwas ist schiefgegangen. Aber wenn man dieses Bild betrachtet, ist es unmöglich zu verstehen, was der Grund ist.

Wenn Sie jedoch die gleichen Statistiken für Cassandra-Knoten erweitern, können Sie sehen, dass im Prinzip alle Knoten mehr oder weniger nichts sind, aber die Antwortzeit für einen Knoten unterscheidet sich um Größenordnungen. Höchstwahrscheinlich gibt es ein Problem mit ihm.
Statistiken über Knoten verändern das Bild vollständig. Diese Statistiken stammen von der Anwendungsseite. Aber hier ist es tatsächlich sehr oft schwierig zu verstehen, wo das Problem liegt. Wenn eine Anwendung auf Cassandra zugreift, greift sie auf einen Knoten zu und verwendet ihn als Koordinator. Das heißt, die Anwendung gibt eine Anforderung aus und der Koordinator leitet sie mit den Daten an die Replikate weiter. Diese antworten bereits und der Koordinator bildet die endgültige Antwort zurück.
Aber warum reagiert der Koordinator langsam? Vielleicht liegt das Problem bei ihm als solchem, das heißt, er verlangsamt sich und antwortet langsam? Oder verlangsamt er sich vielleicht, weil die Repliken langsam auf ihn reagieren? Wenn die Replikate langsam reagieren, sieht es aus Sicht der Anwendung wie eine langsame Antwort des Koordinators aus, obwohl dies nichts damit zu tun hat.
Hier ist eine glückliche Situation - es ist klar, dass nur ein Knoten langsam reagiert und das Problem höchstwahrscheinlich darin liegt.
Komplexität der Interpretation
- Antwortzeit des Koordinators (Knoten vs. Replikat selbst).
- Eine bestimmte Tabelle oder der gesamte Knoten?
- GC Pause? Unzureichender Thread-Pool?
- Zu viele nicht verdichtete SSTables?
Es ist immer schwer zu verstehen, was falsch ist. Es
braucht nur
eine Menge Statistiken und Überwachung , sowohl von der Anwendungsseite als auch von Cassandra selbst, denn wenn es wirklich schlecht ist, ist von Cassandra nichts sichtbar. Sie können die Ebene einzelner Abfragen, die Ebene jeder bestimmten Tabelle und jeden bestimmten Knoten anzeigen.
Es kann zum Beispiel eine Situation geben, in der eine Tabelle der in Cassandra SSTables (separate Dateien) genannten Dateien zu viel enthält. Zum Lesen muss Cassandra grob gesagt alle SSTables sortieren. Wenn es zu viele von ihnen gibt, dauert der Vorgang dieser Sortierung einfach zu lange, und das Lesen beginnt zu sinken.
Die Lösung ist die Komprimierung, die die Anzahl dieser SSTables verringert. Es sollte jedoch beachtet werden, dass sie sich nur auf einem Knoten für eine bestimmte Tabelle befinden kann. Da Cassandra leider in Java geschrieben ist und auf der JVM ausgeführt wird, ist der Garbage Collector möglicherweise in eine solche Pause geraten, dass er einfach keine Zeit hat, zu antworten. Wenn der Garbage Collector angehalten wird, verlangsamen sich nicht nur Ihre Anforderungen, sondern auch die
Interaktion innerhalb des Cassandra-Clusters zwischen Knoten . Die Knoten voneinander werden als untergegangen, dh gefallen, tot betrachtet.
Eine noch unterhaltsamere Situation beginnt, denn wenn ein Knoten berücksichtigt, dass ein anderer Knoten ausgefallen ist, sendet er erstens keine Anforderungen an ihn und zweitens versucht er, die Daten zu speichern, die er zum Replizieren auf einen anderen Knoten benötigen würde sich vor Ort, so dass er beginnt, sich langsam zu töten, etc.
Es gibt Situationen, in denen dieses Problem einfach mit den richtigen Einstellungen gelöst werden kann. Zum Beispiel kann es genügend Ressourcen geben, alles ist in Ordnung und wunderbar, aber nur ein Thread-Pool, dessen Anzahl eine feste Größe hat, muss erhöht werden.
Schließlich müssen wir vielleicht die Wettbewerbsfähigkeit auf der Fahrerseite einschränken. Manchmal kommt es vor, dass zu viele wettbewerbsfähige Anfragen gesendet werden, und wie bei jeder Datenbank kann Cassandra diese nicht bearbeiten und geht zum Clinch, wenn die Antwortzeit exponentiell zunimmt und wir versuchen, immer mehr Arbeit zu leisten.
Verständnis des Kontextes
Es gibt immer einen Kontext für das Problem - was passiert im Cluster, ob die Reparatur jetzt funktioniert, auf welchem Knoten, in welchen Schlüsselbereichen, in welcher Tabelle.
Zum Beispiel hatten wir ziemlich lächerliche Probleme mit Eisen. Wir haben gesehen, dass ein Teil der Knoten langsam ist. Später wurde festgestellt, dass der Grund dafür war, dass sich ihre Prozessoren im BIOS im Energiesparmodus befanden. Aus irgendeinem Grund geschah dies während der Erstinstallation von Eisen, und im Vergleich zu anderen Knoten wurden ungefähr 50% der Prozessorressourcen verwendet.
Das Verständnis eines solchen Problems kann in der Tat schwierig sein. Das Symptom ist folgendes: Es scheint, dass der Knoten die Komprimierung durchführt, aber langsam. Manchmal ist es mit Eisen verbunden, manchmal nicht, aber dies ist nur ein weiterer Cassandra-Fehler.
Daher ist die Überwachung obligatorisch und erfordert viel. Je komplexer die Funktion in Cassandra ist, je weiter sie vom einfachen Schreiben und Lesen entfernt ist, desto mehr Probleme gibt es und desto schneller kann eine Datenbank mit einer ausreichenden Anzahl von Abfragen beendet werden. Schauen Sie sich daher nach Möglichkeit einige „leckere“ Chips nicht an und versuchen Sie, sie zu verwenden. Vermeiden Sie sie so weit wie möglich. Nicht immer möglich - natürlich ist es früher oder später notwendig.

Die neueste Geschichte handelt davon, wie Cassandra die Daten durcheinander gebracht hat. In dieser Situation passierte es in Cassandra. Das war interessant
Wir haben gesehen, dass ungefähr einmal pro Woche in unserer Datenbank mehrere Dutzend beschädigter Leitungen erscheinen - sie sind buchstäblich mit Müll verstopft. Darüber hinaus validiert Cassandra die Daten, die zu ihrer Eingabe gehen. Wenn es sich beispielsweise um eine Zeichenfolge handelt, sollte sie sich in utf8 befinden. Aber in diesen Zeilen war Müll, nicht utf8, und Cassandra gab nicht einmal etwas damit zu tun. Wenn ich versuche zu löschen (oder etwas anderes zu tun), kann ich keinen Wert löschen, der nicht utf8 ist, da ich ihn insbesondere nicht in WHERE eingeben kann, da der Schlüssel utf8 sein muss.
Verdorbene Linien erscheinen irgendwann wie ein Blitz und sind dann für einige Tage oder Wochen wieder verschwunden.
Wir suchten nach einem Problem. Wir dachten, dass es möglicherweise ein Problem in einem bestimmten Knoten gibt, mit dem wir herumspielen, etwas mit Daten tun und SSTables kopieren. Vielleicht können Sie trotzdem Repliken dieser Daten sehen? Vielleicht haben diese Replikate einen gemeinsamen Knoten, den kleinsten gemeinsamen Faktor? Vielleicht stürzt ein Knoten ab? Nein, nichts dergleichen.
Vielleicht etwas mit einer Festplatte? Sind die Daten auf der Festplatte beschädigt? Nein schon wieder.
Vielleicht eine Erinnerung? Nein! Über einen Cluster verteilt.
Vielleicht ist dies eine Art Replikationsproblem? Ein Knoten hat alles verdorben und einen schlechten Wert weiter repliziert? - Nein.
Schließlich ist dies vielleicht ein Anwendungsproblem?
Darüber hinaus tauchten die beschädigten Linien irgendwann in zwei Cassandra-Clustern auf. Einer arbeitete an Version 2.1, der zweite an der dritten. Es scheint, dass Cassandra anders ist, aber das Problem ist das gleiche. Vielleicht sendet unser Service schlechte Daten? Aber es war schwer zu glauben. Cassandra validiert Eingabedaten und konnte keinen Müll schreiben. Aber plötzlich?
Nichts passt.
Eine Nadel wurde gefunden!
Wir haben lange und hart gekämpft, bis wir ein kleines Problem entdeckten: Warum haben wir eine Art Crash-Dump von der JVM auf den Knoten, denen wir nicht viel Aufmerksamkeit geschenkt haben? Und irgendwie sieht es im Stack Trace Garbage Collector verdächtig aus ... Und aus irgendeinem Grund sind auch einige Stack Trace mit Müll verstopft.
Am Ende wurde uns klar - oh,
aus irgendeinem Grund verwenden wir die JVM der alten Version von 2015 . Dies war die einzige gemeinsame Sache, die Cassandra-Cluster auf verschiedenen Versionen von Cassandra vereinte.
Ich weiß immer noch nicht, wo das Problem lag, da in den offiziellen Versionshinweisen der JVM nichts darüber geschrieben wurde. Aber nach dem Update verschwand alles, das Problem trat nicht mehr auf. Darüber hinaus trat es nicht vom ersten Tag an im Cluster auf, sondern irgendwann, obwohl es lange Zeit mit derselben JVM funktionierte.
Datenwiederherstellung
Welche Lektion haben wir daraus gelernt:
● Backup ist nutzlos.
Wie wir herausfanden, waren die Daten in der Sekunde, in der sie aufgezeichnet wurden, beschädigt. Zu dem Zeitpunkt, als die Daten in den Koordinator eingegeben wurden, waren sie bereits beschädigt.
● Eine teilweise Wiederherstellung unbeschädigter Säulen ist möglich.
Einige Spalten wurden nicht beschädigt, wir konnten diese Daten lesen und teilweise wiederherstellen.
● Am Ende mussten wir eine Wiederherstellung aus verschiedenen Quellen durchführen.
Wir hatten Backup-Metadaten im Objekt, aber in den Daten selbst. Um die Verbindung mit dem Objekt wiederherzustellen, haben wir Protokolle usw. verwendet.
● Protokolle sind von unschätzbarem Wert!
Wir konnten alle beschädigten Daten wiederherstellen, aber am Ende ist es sehr schwierig, der Datenbank zu vertrauen, wenn sie Ihre Daten verliert, auch ohne dass Sie etwas unternehmen müssen.
Lösung
- Aktualisieren Sie die JVM nach umfangreichen Tests.
- JVM-Absturzüberwachung.
- Haben Sie eine Cassandra-unabhängige Kopie der Daten.
Als Tipp: Versuchen Sie, eine Art Cassandra-unabhängige Kopie der Daten zu haben, aus der Sie bei Bedarf wiederherstellen können. Dies kann die Lösung der letzten Ebene sein. Lassen Sie es viel Zeit und Ressourcen in Anspruch nehmen, aber es sollte eine Option geben, mit der Sie Daten zurückgeben können.
Bugs
●
Schlechte Qualität der Release-TestsWenn Sie anfangen, mit Cassandra zu arbeiten, besteht das ständige Gefühl (insbesondere wenn Sie relativ gesehen von „guten“ Datenbanken, z. B. PostgreSQL, wechseln), dass Sie definitiv einen neuen hinzufügen, wenn Sie einen Fehler in der vorherigen Version behoben haben. Und der Fehler ist kein Unsinn, es sind normalerweise beschädigte Daten oder anderes falsches Verhalten.
●
Anhaltende Probleme mit komplexen FunktionenJe komplexer die Funktion ist, desto mehr Probleme, Fehler usw. sind damit verbunden.
●
Verwenden Sie in 2.1 keine inkrementelle ReparaturDie berühmte Reparatur, über die ich gesprochen habe und die die Datenkonsistenz im Standardmodus behebt, wenn alle Knoten abgefragt werden, funktioniert gut. Aber nicht im sogenannten inkrementellen Modus (wenn die Reparatur Daten überspringt, die sich seit der vorherigen Reparatur nicht geändert haben, was ziemlich logisch ist). Es wurde vor langer Zeit offiziell angekündigt, da es eine Funktion gibt, aber jeder sagt: „Nein, in Version 2.1, benutze sie niemals! Er wird definitiv etwas vermissen. In 3 beheben wir es. "
●
Verwenden Sie in 3.x jedoch keine inkrementelle ReparaturAls die dritte Version herauskam, sagten sie einige Tage später: „Nein, Sie können sie in der dritten nicht verwenden. Es gibt eine Liste mit 15 Fehlern. Verwenden Sie daher in keinem Fall eine inkrementelle Reparatur. Im 4. werden wir es besser machen! “
Ich glaube ihnen nicht. Dies ist ein großes Problem, insbesondere bei zunehmender Clustergröße. Daher müssen Sie ihren Bugtracker ständig überwachen und sehen, was passiert. Leider ist es unmöglich, ohne sie zu leben.
● Sie
müssen JIRA im Auge behalten
Wenn Sie alle Datenbanken im Vorhersagbarkeitsspektrum verteilen, befindet sich Cassandra für mich links im roten Bereich. Das bedeutet nicht, dass es schlecht ist, man muss nur darauf vorbereitet sein, dass Cassandra im wahrsten Sinne des Wortes unvorhersehbar ist: sowohl in der Art und Weise, wie es funktioniert, als auch in der Tatsache, dass etwas passieren kann.

Ich möchte, dass Sie andere Rechen finden und darauf treten, denn aus meiner Sicht ist Cassandra, egal was passiert, gut und sicherlich nicht langweilig. Denken Sie nur an die Unebenheiten auf der Straße!
Offenes Treffen von HighLoad ++ - Aktivisten
Am 31. Juli um 19:00 Uhr findet in Moskau ein Treffen der Redner, des Programmkomitees und der Aktivisten der HighLoad ++ 2018-Konferenz der Entwickler von Hochlastsystemen statt. Wir werden ein kleines Brainstorming über das diesjährige Programm organisieren, um nichts Neues und Wichtiges zu verpassen. Das Meeting ist offen, aber Sie müssen sich registrieren .
Ruf nach Papieren
Aktive Annahme von Bewerbungen für Berichte bei Highload ++ 2018. Das Programmkomitee wartet bis Ende des Sommers auf Ihr Abstract.