
Dies ist eine Fortsetzung des ersten Teils des Artikels.
Im ersten Teil des Artikels sprach der Autor auf mail.ru über die Bedingungen des Wettbewerbs für das Spiel Agario, die Struktur der Spielwelt und teilweise über die Struktur des Bots. Zum Teil, weil sie nur die Vorrichtung von Eingangssensoren und Befehlen am Ausgang des neuronalen Netzwerks betrafen (im Folgenden wird in Bildern und Text eine Abkürzung NN verwendet). Versuchen wir also, die Black Box zu öffnen und zu verstehen, wie dort alles angeordnet ist.
Und hier ist das erste Bild:
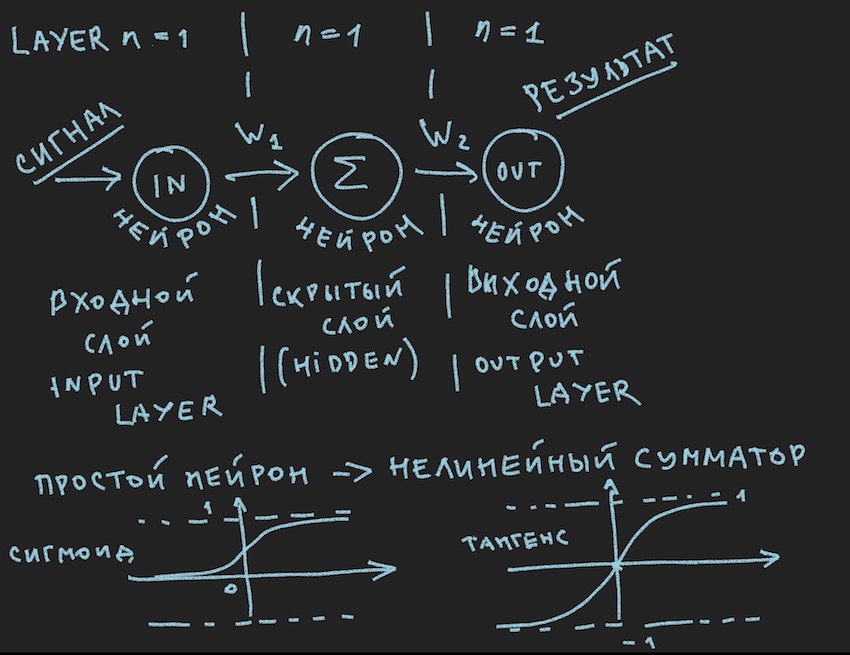
Es zeigt schematisch, was bei meinem Leser ein gelangweiltes Lächeln hervorrufen sollte, sagen sie noch einmal in der ersten Klasse, sie wurden schon oft in verschiedenen Quellen gesehen . Aber wir wollen dieses Bild wirklich praktisch auf die Verwaltung des Bots anwenden, also schauen wir es uns nach dem wichtigen Hinweis genauer an.
Wichtiger Hinweis: Es gibt eine Vielzahl vorgefertigter Lösungen (Frameworks) für die Arbeit mit neuronalen Netzen:

Alle diese Pakete lösen die Hauptaufgaben für den Entwickler neuronaler Netze: den Aufbau und das Training von NN oder die Suche nach "optimalen" Gewichten. Die Hauptmethode dieser Suche ist die Backpropagation . Es wurde in den 70er Jahren des letzten Jahrhunderts erfunden, wie aus dem Artikel unter dem obigen Link hervorgeht. In dieser Zeit hat es als Boden des Schiffes verschiedene Verbesserungen erfahren, aber das Wesentliche ist dasselbe: Gewichtskoeffizienten mit einer Basis von Trainingsbeispielen zu finden, und es ist äußerst wünschenswert, dass jeder Diese Beispiele enthielten eine vorgefertigte Antwort in Form eines Ausgangssignals eines neuronalen Netzwerks. Der Leser kann gegen mich protestieren. dass selbstlernende Netzwerke verschiedener Klassen und Prinzipien bereits erfunden wurden, aber soweit ich weiß, läuft dort nicht alles reibungslos. Natürlich gibt es Pläne, diesen Zoo genauer zu studieren, aber ich denke, ich werde Gleichgesinnte finden, die feststellen, dass ein selbstgemachtes Fahrrad ohne spezielle Zeichnungen für den Schöpfer noch stärker gebogen ist als ein Förderklon eines idealen Fahrrads.
Der Autor verstand, dass der Spieleserver höchstwahrscheinlich nicht über diese Bibliotheken verfügt und die von den Organisatoren als 1 Prozessorkern zugewiesene Rechenleistung für ein umfangreiches Framework eindeutig nicht ausreicht, und entwickelte sein eigenes Fahrrad. Ein wichtiger Kommentar dazu endete.
Kehren wir zu dem Bild zurück, das das wahrscheinlich einfachste der möglichen neuronalen Netze mit einer verborgenen Schicht (auch bekannt als verborgene Schicht oder verborgene Schicht) zeigt. Jetzt hat der Autor selbst das Bild mit Ideen zu diesem einfachen Beispiel stetig betrachtet, um dem Leser die Tiefen künstlicher neuronaler Netze zu offenbaren. Wenn alles zu einem Primitiven vereinfacht ist, ist es einfacher, die Essenz zu verstehen. Die Quintessenz ist, dass das Neuron der verborgenen Schicht nichts zusammenzufassen hat. Und höchstwahrscheinlich ist dies nicht einmal ein neuronales Netzwerk. In Lehrbüchern ist das einfachste NN ein Netzwerk mit zwei Eingängen. Hier sind wir also sozusagen die Entdecker des einfachsten der einfachsten Netzwerke.
Versuchen wir, dieses neuronale Netzwerk (Pseudocode) zu beschreiben:
Wir führen die Netzwerktopologie in Form eines Arrays ein, wobei jedes Element der Schicht und der Anzahl der darin enthaltenen Neuronen entspricht:
int array Topology= { 1, 1, 1}
Wir benötigen auch ein Float-Array von Gewichten des neuronalen Netzwerks W, wenn wir unser Netzwerk als "Feed-Forward-Neuronale Netzwerke (FF oder FFNN)" betrachten, bei dem jedes Neuron der aktuellen Schicht mit jedem Neuron der nächsten Schicht verbunden ist, erhalten wir die Dimension des Arrays W [Anzahl der Schichten , die Anzahl der Neuronen in der Schicht, die Anzahl der Neuronen in der Schicht]. Nicht ganz die optimale Codierung, aber angesichts des heißen Atems der GPU irgendwo sehr nah im Text ist es verständlich.
Ein kurzes CalculateSize Verfahren zum Zählen der Anzahl der neuroncount Neuronenanzahl und der Anzahl ihrer Verbindungen im neuronalen Netzwerk mit dendritecount wird dem Autor neuroncount die Art dieser Verbindungen besser erklären:
void CalculateSize(array int Topology, int neuroncount, int dendritecount) { for (int i : Topology) // i neuroncount += i; for (int layer = 0, layer <Topology.Length - 1, layer++) // for (int i = 0, i < Topology[layer] + 1, i++) // for (int j = 0, j < Topology[layer + 1], j++) // dendritecount++; }
Mein Leser, der dies alles bereits weiß, der Autor ist im ersten Artikel zu dieser Meinung gekommen, wird sicherlich nicht fragen: Warum in der dritten verschachtelten Schleife Topologie [Schicht1 + 1] anstelle von Topologie [Schicht1], die dem Neuron mehr gibt als in der Netzwerktopologie . Ich werde nicht antworten. Es ist auch nützlich für den Leser, Hausaufgaben zu machen.
Wir sind fast einen Schritt vom Aufbau eines funktionierenden neuronalen Netzwerks entfernt. Es bleibt die Funktion der Summierung der Signale am Eingang des Neurons und seiner Aktivierung hinzuzufügen. Es gibt viele Aktivierungsfunktionen, aber diejenigen, die der Natur des Neurons am nächsten kommen, sind Sigmoid und Tangensoid (wahrscheinlich ist es besser, es so zu nennen, obwohl dieser Name in der Literatur nicht verwendet wird, das Maximum tangential ist, aber dies ist der Name des Graphen, obwohl was ein Graph ist, wenn er nicht die Funktion widerspiegelt?)
Hier haben wir also die Neuronenaktivierungsfunktionen (sie sind im Bild im unteren Teil vorhanden).
float Sigmoid(float x) { if (x < -10.0f) return 0.0f; else if (x > 10.0f) return 1.0f; return (float)(1.0f / (1.0f + expf(-x))); }
Sigmoid gibt Werte von 0 bis 1 zurück.
float Tanh(float x) { if (x < -10.0f) return -1.0f; else if (x > 10.0f) return 1.0f; return (float)(tanhf(x)); }
Der Tangentoid gibt Werte von -1 bis 1 zurück.
Die Hauptidee eines Signals, das ein neuronales Netzwerk durchläuft, ist eine Welle: Ein Signal wird Eingangsneuronen zugeführt -> über neuronale Verbindungen gelangt das Signal zur zweiten Schicht -> Neuronen der zweiten Schicht fassen die Signale zusammen, die sie erreicht haben, geändert durch interneuronale Gewichte -> wird durch ein zusätzliches Vorspannungsgewicht hinzugefügt -> Wir verwenden die Aktivierungsfunktion-> und gehen zur nächsten Schicht (lesen Sie den ersten Zyklus aus dem Beispiel nach Schichten), dh wir wiederholen die Kette von Anfang an, nur die Neuronen der nächsten Schicht werden zu Eingangsneuronen. Zur Vereinfachung müssen Sie nicht einmal die Werte der Neuronen des gesamten Netzwerks speichern, sondern nur die NN-Gewichte und die Werte der Neuronen der aktiven Schicht.
Wir senden erneut ein Signal an den Eingang NN, die Welle lief durch die Schichten und auf der Ausgangsschicht entfernen wir den erhaltenen Wert.
Nach dem Geschmack des Lesers ist es hier möglich, das Programm mithilfe von Rekursion oder nur einem Dreifachzyklus wie dem des Autors zu lösen. Um die Berechnungen zu beschleunigen, müssen Sie keine Objekte in Form von Neuronen und deren Verbindungen und anderen OOPs umzäunen. Dies ist wiederum auf das Gefühl enger GPU-Berechnungen zurückzuführen, und bei GPUs bleibt OOP aufgrund ihrer Art der Massenparallelität etwas stehen, dies ist relativ zu c # und C ++.
Darüber hinaus wird der Leser aufgefordert, unabhängig den Weg zum Aufbau eines neuronalen Netzwerks in Code zu gehen, wobei sein Leser dies freiwillig wünscht, dessen Fehlen dem Autor klar und vertraut ist, da es für Beispiele zum Erstellen von NN von Grund auf viele Beispiele im Netzwerk gibt, so dass es schwierig sein wird, in die Irre zu gehen so einfach wie ein neuronales Netzwerk mit direkter Verteilung im obigen Bild.
Aber wo wird der Leser ausrufen, der noch nicht von der vorherigen Passage abgewichen ist und in der Kindheit Recht haben wird? Der Autor hat den Wert des Buches durch Illustrationen dazu bestimmt. Hier bitte:
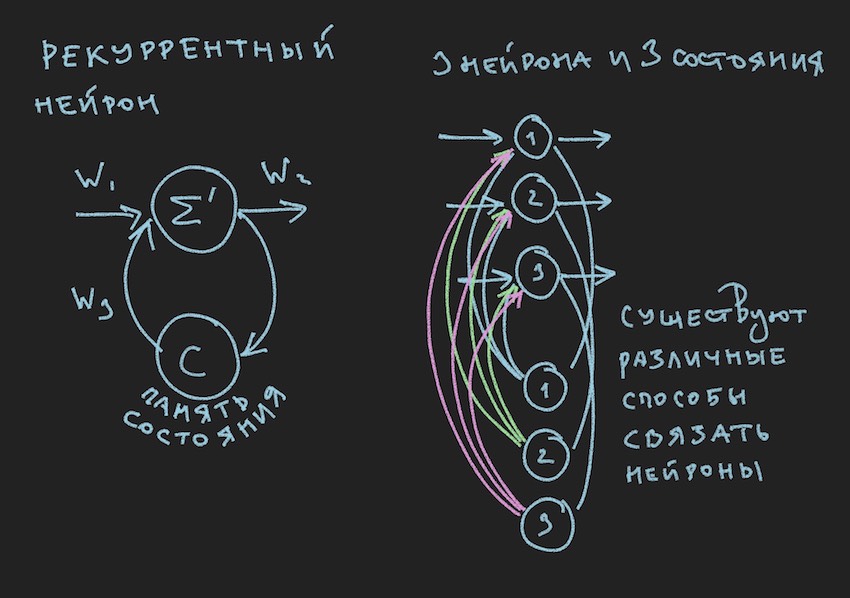
Im Bild sehen wir ein wiederkehrendes Neuron und ein aus solchen Neuronen aufgebautes NN wird als wiederkehrendes oder RNN bezeichnet. Das angegebene neuronale Netzwerk hat ein Kurzzeitgedächtnis und wurde vom Autor für den Bot als das vielversprechendste in Bezug auf die Anpassung an den Spielprozess ausgewählt. Natürlich baute der Autor ein neuronales Netzwerk mit direkter Verteilung auf, aber auf der Suche nach einer „effektiven“ Lösung wechselte er zu RNN.
Ein wiederkehrendes Neuron hat einen zusätzlichen Zustand C, der nach dem ersten Durchgang eines Signals durch ein Neuron gebildet wird, Tick + 0 auf der Zeitachse. In einfachen Worten ist dies eine Kopie des Ausgangssignals eines Neurons. Lesen Sie im zweiten Schritt Tick + 1 (da das Netzwerk mit der Frequenz des Spielbot und des Servers arbeitet), kehrt der Wert C durch zusätzliche Gewichte zum Eingang der neuronalen Schicht zurück und nimmt somit an der Signalbildung teil, jedoch bereits zum Zeitpunkt Tick + 1.
Hinweis: In der Arbeit von Forschungsgruppen zur Verwaltung von NN-Spiel-Bots besteht die Tendenz, zwei Rhythmen für ein neuronales Netzwerk zu verwenden. Ein Rhythmus ist die Frequenz des Spiel-Ticks, der zweite Rhythmus ist beispielsweise doppelt so langsam wie der erste. Verschiedene Teile des NN arbeiten mit unterschiedlichen Frequenzen, was eine unterschiedliche Sicht auf die Spielsituation innerhalb des NN ermöglicht und dadurch dessen Flexibilität erhöht.
Um RNN im Bot-Code zu erstellen, fügen wir ein zusätzliches Array in die Topologie ein, wobei jedes Element der Schicht und der Anzahl der darin enthaltenen neuronalen Zustände entspricht:
int array TopologyNN= { numberofSensors, 16, 8, 4}
int array TopologyRNN= { 0, 16, 0, 0 }
Aus der obigen Topologie ist ersichtlich, dass die zweite Schicht wiederkehrend ist, da sie neuronale Zustände enthält. Wir führen auch zusätzliche Gewichte in Form eines Gleitkommas des WRR-Arrays ein, das dieselbe Dimension wie das W-Array hat.
Die Anzahl der Verbindungen in unserem neuronalen Netzwerk wird sich etwas ändern:
for (int layer = 0, layer < TopologyNN.Length - 1, layer++) for (int i = 0, i < TopologyNN[layer] + 1, i++) for (int j = 0, j < TopologyNN[layer + 1] , j++) dendritecount++; for (int layer = 0, layer < TopologyRNN.Length - 1, layer++) for (int i = 0, i< TopologyRNN[layer] + 1 , i++) for (int j = 0, j< TopologyRNN[layer], j++) dendritecount++;
Der Autor wird am Ende dieses Artikels den allgemeinen Code für ein wiederkehrendes neuronales Netzwerk anhängen. Das Wichtigste ist jedoch das Prinzip: Der Durchgang einer Welle durch Schichten bei einem wiederkehrenden NN ändert nichts grundlegend, nur ein weiterer Begriff wird der Neuronenaktivierungsfunktion hinzugefügt. Dies ist der Begriff des Zustands der Neuronen auf dem vorherigen Tick multipliziert mit dem Gewicht der neuronalen Verbindung.
Wir gehen davon aus, dass Theorie und Praxis neuronaler Netze aktualisiert wurden, aber der Autor ist sich klar darüber im Klaren, dass er den Leser nicht näher an das Verständnis gebracht hat, wie man diese einfache Struktur neuronaler Netze lehrt, um Entscheidungen im Spiel zu treffen. Wir haben keine Bibliotheken mit Beispielen für das Unterrichten von NN. In den Internetgruppen der Bot-Entwickler gab es eine Meinung: Geben Sie uns eine Protokolldatei in Form von Koordinaten von Bots und anderen Spielinformationen, um eine Bibliothek mit Beispielen zu bilden. Leider konnte der Autor nicht herausfinden, wie diese Protokolldatei für das Training von NN verwendet werden soll. Ich werde dies gerne in den Kommentaren zum Artikel diskutieren. Daher war die einzige Methode, die dem Autor zur Verfügung stand, um die Trainingsmethode zu verstehen oder vielmehr "effektive" Neurobalances (Neuroconnections) zu finden, der genetische Algorithmus.
Erstellt ein Bild über die Prinzipien des genetischen Algorithmus:
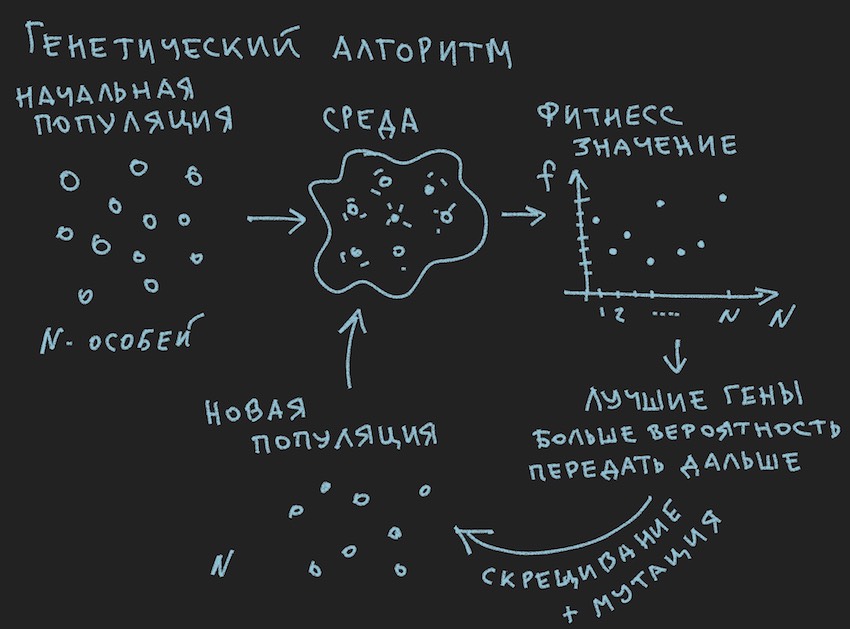
Also der genetische Algorithmus .
Der Autor wird versuchen, sich nicht mit der Theorie dieses Prozesses zu befassen, sondern sich nur an das Minimum zu erinnern, das erforderlich ist, um den Artikel vollständig zu lesen.
Im genetischen Algorithmus ist das Gen die Hauptarbeitsflüssigkeit (DNA ist der Name des Moleküls). Das Genom in unserem Fall ist ein sequentieller Satz von Genen oder eine eindimensionale Anordnung von ...
In der Anfangsphase der Arbeit mit einem neu aufgebauten neuronalen Netzwerk muss es initialisiert werden. Die Initialisierung bezieht sich auf die Zuordnung von Zufallswerten von -1 bis 1 zu neuronalen Gleichgewichten. Der Autor hat erwähnt, dass der Wertebereich von -1 bis 1 zu extrem ist und trainierte Netzwerke Gewichte in einem kleineren Bereich haben, beispielsweise von -0,5 bis 0,5, und dass Sie einen anfänglichen Wertebereich von ausgezeichnet nehmen sollten von -1 bis 1. Wir werden jedoch den klassischen Weg gehen, alle Schwierigkeiten in einem Gate zu sammeln und ein möglichst breites Segment anfänglicher Zufallsvariablen als Grundlage für die Initialisierung des neuronalen Netzwerks zu verwenden.
Nun erfolgt eine Bijektion . Wir gehen davon aus, dass die Länge (Größe) des Bot-Genoms gleich der Gesamtlänge der Arrays des neuronalen Netzwerks TopologyNN.Length + TopologyRNN.Length ist, nicht umsonst, dass der Autor die Zeit des Lesers mit dem Verfahren zum Zählen neuronaler Verbindungen verbracht hat.
Hinweis: Wie der Leser bereits selbst festgestellt hat, übertragen wir nur die Gewichte des neuronalen Netzwerks auf den Genotyp, die Verbindungsstruktur, Aktivierungsfunktionen und Neuronenzustände werden nicht übertragen. Für einen genetischen Algorithmus sind nur neuronale Verbindungen ausreichend, was darauf hindeutet, dass sie die Informationsträger sind. Es gibt Entwicklungen, bei denen der genetische Algorithmus auch die Struktur von Verbindungen im neuronalen Netzwerk ändert und es recht einfach ist, sie zu implementieren. Hier lässt der Autor dem Leser Raum für Kreativität, obwohl er selbst mit Interesse darüber nachdenken wird: Sie müssen die Verwendung von zwei unabhängigen Genomen und zwei Fitnessfunktionen (vereinfacht zwei unabhängige genetische Algorithmen) verstehen, oder Sie können alle dasselbe Gen und denselben Algorithmus verwenden.
Und da wir NN mit Zufallsvariablen initialisiert haben, haben wir damit das Genom initialisiert. Der umgekehrte Prozess ist ebenfalls möglich: Initialisierung des Genotyps durch Zufallsvariablen und anschließendes Kopieren in neuronale Gewichte. Die zweite Option ist üblich. Da der genetische Algorithmus im Programm oft außerhalb der Essenz selbst existiert und nur durch die Genomdaten und den Wert der Fitnessfunktion damit verbunden ist ... Stopp, Stopp, wird der Leser sagen, das Bild zeigt deutlich die Population und kein Wort über das einzelne Genom.
Ok, fügen Sie dem Gedankenofen des Lesers einige Bilder hinzu:
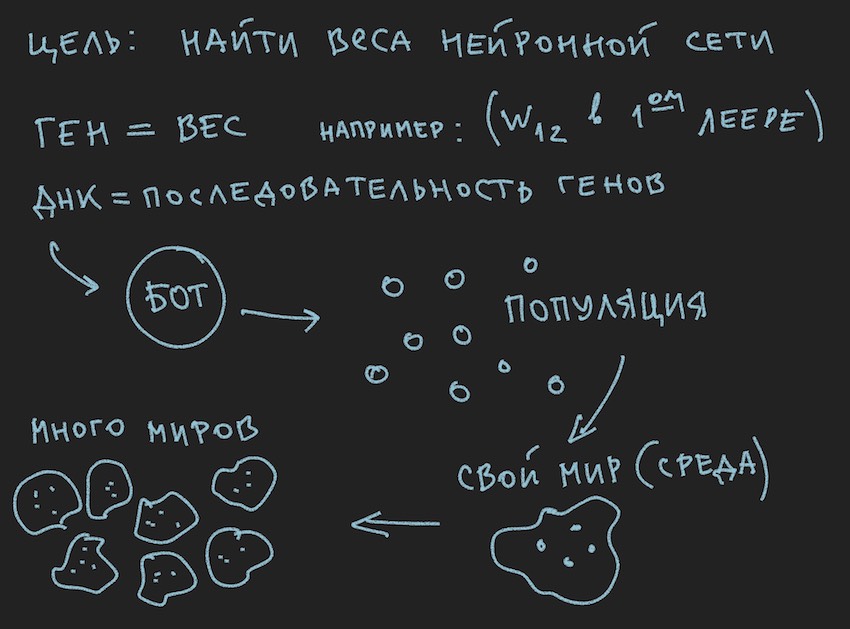
Da der Autor die Bilder vor dem Schreiben des Textes des Artikels gemalt hat, unterstützen sie den Text, folgen jedoch nicht dem Buchstaben zum Buchstaben der aktuellen Geschichte.
Aus den gewonnenen Informationen folgt, dass der Hauptarbeitskörper des genetischen Algorithmus eine Population von Genomen ist . Dies steht etwas im Widerspruch zu dem, was der Autor zuvor gesagt hat, aber wie man in der realen Welt ohne kleine Widersprüche auskommt. Gestern drehte sich die Sonne um die Erde, und heute spricht der Autor über das neuronale Netzwerk im Software-Bot. Kein Wunder, dass er sich an den Ofen der Vernunft erinnerte.
Ich vertraue darauf, dass der Leser selbst das Problem der Widersprüche der Welt löst. Die Bot-Welt ist für den Artikel völlig autark.
Was der Autor in diesem Teil des Artikels jedoch bereits geschafft hat, ist die Bildung einer Population von Bots.
Schauen wir es uns von der Softwareseite aus an:
Es gibt einen Bot (es kann ein Objekt in OOP sein, eine Struktur, obwohl es wahrscheinlich auch ein Objekt oder nur ein Array von Daten ist). Im Inneren enthält der Bot Informationen zu Koordinaten, Geschwindigkeit, Masse und anderen Informationen, die für den Spielprozess nützlich sind. Die Hauptsache für uns ist jedoch, dass er je nach Implementierung einen Link zu seinem Genotyp oder Genotyp selbst enthält. Dann können Sie auf verschiedene Arten vorgehen, sich auf Arrays neuronaler Netzwerkgewichte beschränken oder ein zusätzliches Array von Genotypen einführen, da es für den Leser bequem ist, sich dies in seiner Vorstellung vorzustellen. In den ersten Phasen hat der Autor des Programms Arrays von Neurobalances und Genotypen zugewiesen. Dann weigerte er sich, Informationen zu duplizieren und beschränkte sich auf die Gewichte des neuronalen Netzwerks.
Nach der Logik der Geschichte müssen Sie sagen, dass die Population der Bots eine Reihe der oben genannten Bots ist. Was für eine Spielschleife ... Wieder anhalten, welcher Spielzyklus? Die Entwickler stellten höflich einen Platz für nur einen Bot an Bord eines Spielwelt-Simulationsprogramms auf einem Server oder maximal vier Bots in einem lokalen Simulator zur Verfügung. Und wenn Sie sich an die vom Autor gewählte Topologie des neuronalen Netzwerks erinnern:
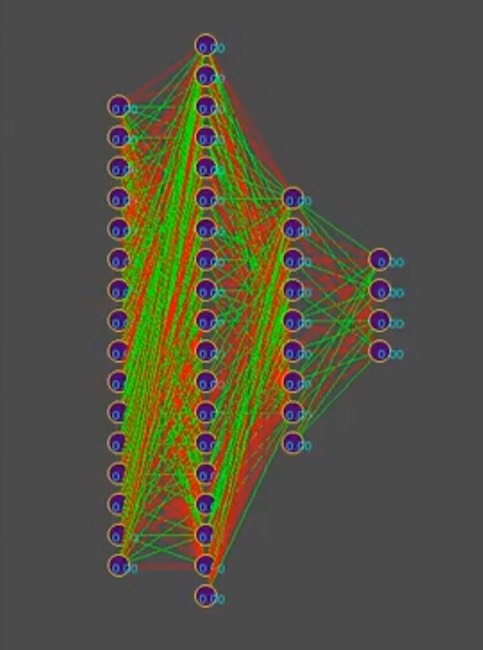
Nehmen wir zur Vereinfachung der Geschichte an, dass der Genotyp ungefähr 1000 neuronale Verbindungen enthält. Im Simulator sehen Genotypen übrigens so aus (Rot ist ein negativer Genwert, Grün ist ein positiver Wert, jede Linie ist ein separates Genom):

Hinweis zum Foto: Im Laufe der Zeit ändert sich das Muster in Richtung der Dominanz einer der Lösungen. Vertikale Streifen sind häufige Genotypgene.
Wir haben also 1000 Gene im Genotyp und maximal vier Bots im Spielwelt-Simulator-Programm der Organisatoren des Wettbewerbs. Wie oft müssen Sie eine Simulation eines Bots-Kampfes ausführen, damit selbst die klügsten mit brutaler Gewalt auf der Suche nach "effektiv" näher kommen?
Genotyp, lesen Sie die "effektive" Kombination neuronaler Verbindungen, vorausgesetzt, dass jede neuronale Verbindung in Schritten von -1 bis 1 variiert, und welcher Schritt? Die Initialisierung war zufällig float, es sind 15 Dezimalstellen. Der Schritt ist uns noch nicht klar. In Bezug auf die Anzahl der Varianten von Kombinationen neuronaler Gewichte geht der Autor davon aus, dass dies eine unendliche Zahl ist, wenn eine bestimmte Schrittgröße gewählt wird, wahrscheinlich eine endliche Zahl. In jedem Fall sind diese Zahlen jedoch mehr als 4 Stellen im Simulator, selbst wenn der sequentielle Start aus der Warteschlange der Bots plus gleichzeitiger paralleler Start der offiziellen Simulatoren bis zu 10 berücksichtigt wird auf einem Computer (für Fans der Vintage-Programmierung: Computer).
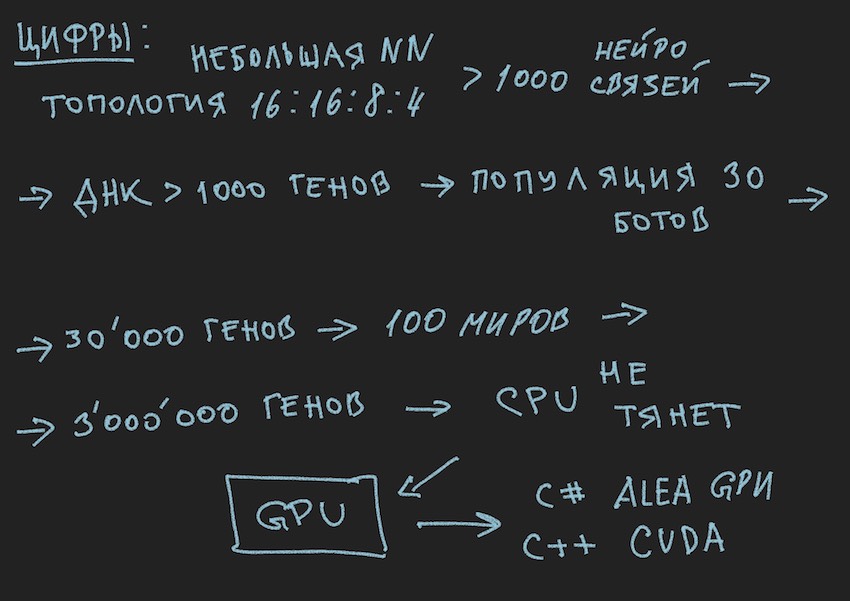
Ich hoffe die Bilder helfen dem Leser.
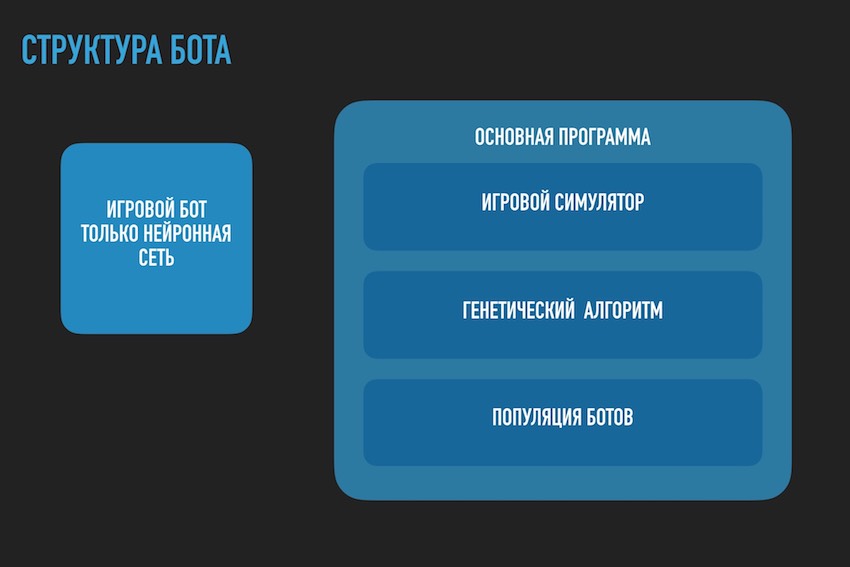
Hier müssen Sie innehalten und über die Architektur der Softwarelösung sprechen. Da die Lösung in Form eines separaten Software-Bots, der auf die Wettbewerbsseite hochgeladen wurde, nicht mehr geeignet war. Es war notwendig, das Bot-Spiel nach den Regeln des Wettbewerbs im Rahmen des Ökosystems der Organisatoren und des Programms zu trennen, um die Konfiguration des neuronalen Netzwerks für ihn zu finden. Das folgende Diagramm stammt aus der Präsentation für die Konferenz, spiegelt jedoch im Allgemeinen das tatsächliche Bild wider.
Er erinnerte sich an einen bärtigen Witz:
Große Organisation.
Um 18.00 Uhr arbeiten alle Mitarbeiter als einer. Plötzlich schaltet einer der Mitarbeiter den Computer aus, zieht sich an und geht.
Jeder folgt ihm mit einem überraschten Blick.
Am nächsten Tag. Um 18.00 Uhr schaltet derselbe Mitarbeiter den Computer aus und geht. Alle arbeiten weiter und beginnen unzufrieden zu flüstern.
Am nächsten Tag. Um 18.00 Uhr schaltet derselbe Mitarbeiter den Computer aus ...
Ein Kollege kommt auf ihn zu:
-Wenn Sie sich nicht schämen, arbeiten wir am Ende des Quartals, so viele Berichte, wir wollen auch pünktlich nach Hause und Sie sind so ein Individuum ...
- Leute, ich mache generell Urlaub!
… Fortsetzung folgt.
Ja, ich habe fast vergessen, den RNN-Berechnungsprozedurcode anzuhängen. Er ist gültig und unabhängig geschrieben, sodass möglicherweise Fehler darin enthalten sind. Zur Verstärkung werde ich es so bringen, wie es ist, es ist in c ++, wie es auf CUDA (eine Bibliothek zum Berechnen auf der GPU) angewendet wird.
Hinweis: Mehrdimensionale Arrays kommen auf GPUs nicht gut miteinander aus. Natürlich gibt es Texturen und Matrixberechnungen, aber sie empfehlen die Verwendung eindimensionaler Arrays.
Ein Beispielarray [i, j] der Dimension M mal j wird zu einem Array der Form [i * M + j].
Quellcode des Berechnungsverfahrens RNN __global__ void cudaRNN(Bot *bot, argumentsRNN *RNN, ConstantStruct *Const, int *Topology, int *TopologyRNN, int numElements, int gameTick) { int tid = blockIdx.x * blockDim.x + threadIdx.x; int threadN = gridDim.x * blockDim.x; int TopologySize = Const->TopologySize; for (int pos = tid; pos < numElements; pos += threadN) { const int ii = pos; const int iiA = pos*Const->ArrayDim; int ArrayDim = Const->ArrayDim; const int iiAT = ii*TopologySize*ArrayDim; if (bot[pos].TTF != 0 && bot[pos].Mass>0) { RNN->outputs[iiA + Topology[0]] = 1.f; //bias int neuroncount7 = Topology[0]; neuroncount7++; for (int layer1 = 0; layer1 < TopologySize - 1; layer1++) { for (int j4 = 0; j4 < Topology[layer1 + 1]; j4++) { for (int i5 = 0; i5 < Topology[layer1] + 1; i5++) { RNN->sums[iiA + j4] = RNN->sums[iiA + j4] + RNN->outputs[iiA + i5] * RNN->NNweights[((ii*TopologySize + layer1)*ArrayDim + i5)*ArrayDim + j4]; } } if (TopologyRNN[layer1] > 0) { for (int j14 = 0; j14 < Topology[layer1]; j14++) { for (int i15 = 0; i15 < Topology[layer1]; i15++) { RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + RNN->neuronContext[iiAT + ArrayDim * layer1 + i15] * RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + i15)*ArrayDim + j14]; } RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + 1.0f* RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + Topology[layer1])*ArrayDim + j14]; //bias=1 } for (int t = 0; t < Topology[layer1 + 1]; t++) { RNN->outputs[iiA + t] = Tanh(RNN->sums[iiA + t] + RNN->sumsContext[iiA + t]); RNN->neuronContext[iiAT + ArrayDim * layer1 + t] = RNN->outputs[iiA + t]; } //SoftMax /* double sum = 0.0; for (int k = 0; k <ArrayDim; ++k) sum += exp(RNN->outputs[iiA + k]); for (int k = 0; k < ArrayDim; ++k) RNN->outputs[iiA + k] = exp(RNN->outputs[iiA + k]) / sum; */ } else { for (int i1 = 0; i1 < Topology[layer1 + 1]; i1++) { RNN->outputs[iiA + i1] = Sigmoid(RNN->sums[iiA + i1]); //sigma } } if (layer1 + 1 != TopologySize - 1) { RNN->outputs[iiA + Topology[layer1 + 1]] = 1.f; } for (int i2 = 0; i2 < ArrayDim; i2++) { RNN->sums[iiA + i2] = 0.f; RNN->sumsContext[iiA + i2] = 0.f; } } } } }