Stellen Sie sich vor, Sie haben einen Textabschnitt. Ist es möglich zu verstehen, welche Emotionen dieser Text mit sich bringt: Freude, Traurigkeit, Wut? Du kannst. Wir vereinfachen unsere Aufgabe und klassifizieren die Emotionen ohne Angabe als positiv oder negativ. Es gibt viele Möglichkeiten, dieses Problem zu lösen, und eine davon sind
Faltungs-Neuronale Netze (Faltungs-Neuronale Netze). CNN wurde ursprünglich für die Bildverarbeitung entwickelt, bewältigt jedoch erfolgreich Aufgaben im Bereich der automatischen Textverarbeitung. Ich werde Ihnen eine binäre Analyse der Tonalität russischsprachiger Texte unter Verwendung eines Faltungsnetzwerks vorstellen, für das Vektordarstellungen von Wörtern auf der Grundlage eines trainierten
Word2Vec- Modells gebildet wurden.
Der Artikel ist von Übersichtscharakter, ich habe die praktische Komponente hervorgehoben. Und ich möchte Sie sofort warnen, dass Entscheidungen, die in jeder Phase getroffen werden, möglicherweise nicht optimal sind. Ich empfehle Ihnen, sich vor dem Lesen mit dem
einleitenden Artikel über die Verwendung von CNN bei der Verarbeitung natürlicher Sprache vertraut zu machen und
Material über Methoden zur Vektordarstellung von Wörtern zu lesen.
Architektur
Die betrachtete CNN-Architektur basiert auf den Ansätzen [1] und [2]. Ansatz [1], der ein Ensemble aus Faltungsnetzwerken und wiederkehrenden Netzwerken verwendet, belegte beim größten jährlichen Wettbewerb in der Computerlinguistik SemEval-2017 den ersten Platz [3] in fünf Nominierungen bei der Analyse der Tonalität von
Aufgabe 4 .
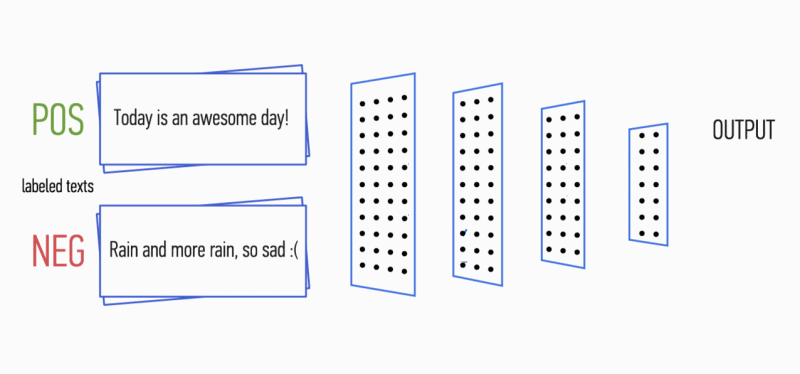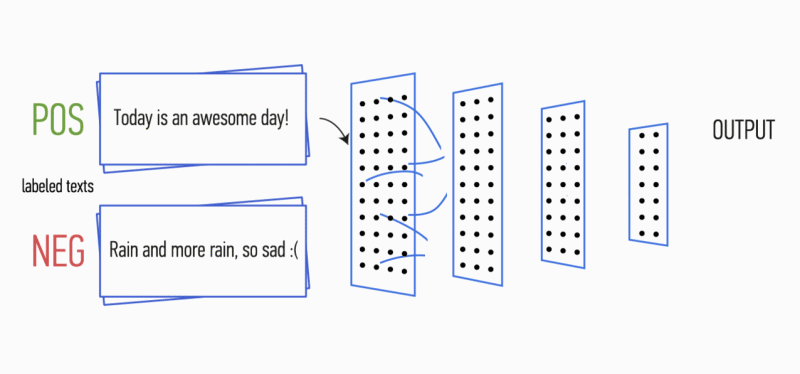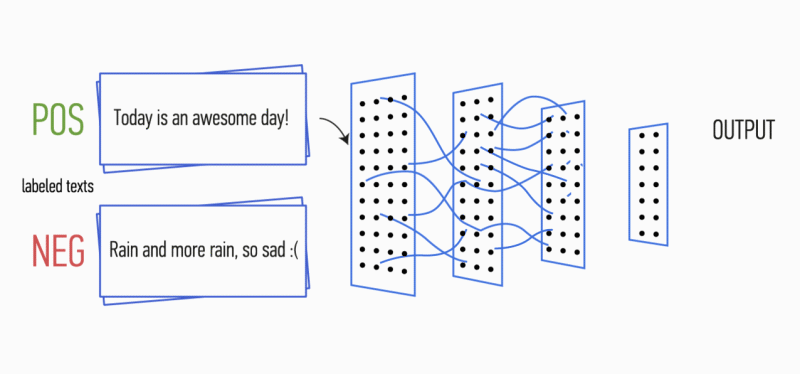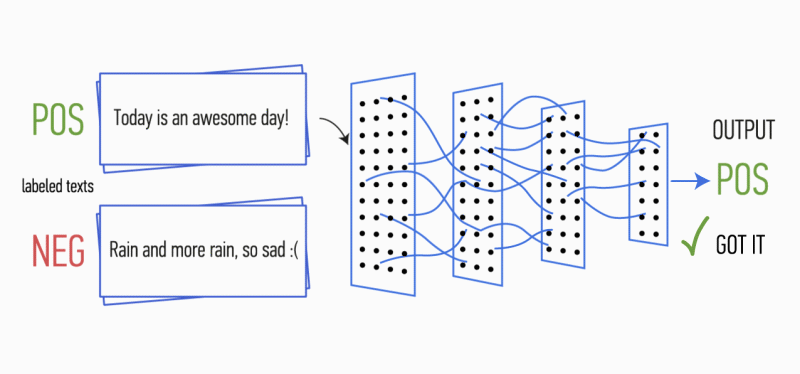
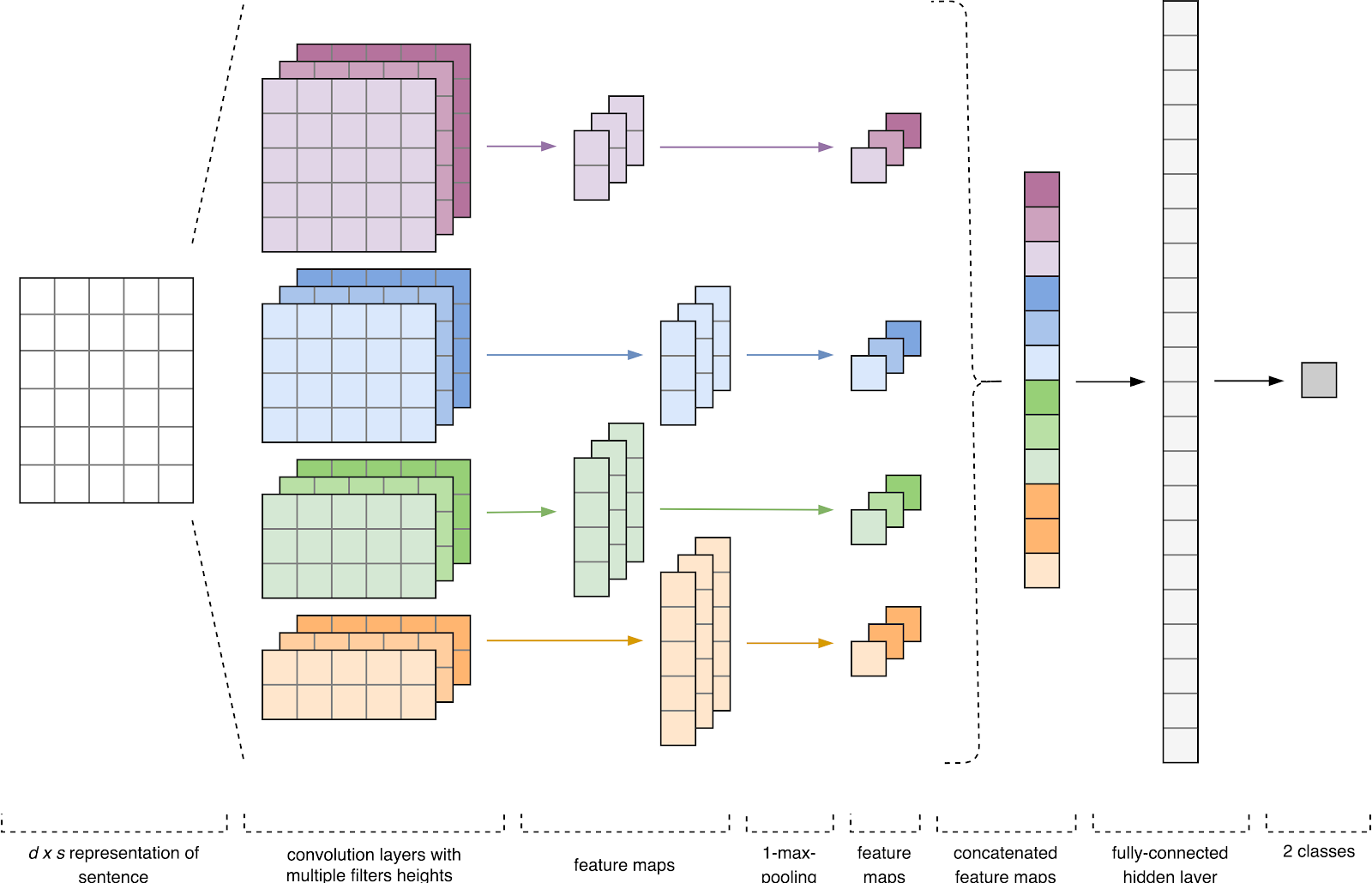 Abbildung 1. CNN-Architektur [2].
Abbildung 1. CNN-Architektur [2].Der CNN-Eingang (Fig. 1) ist eine Matrix mit einer festen Höhe
n , wobei jede Zeile eine Vektorabbildung eines Tokens in einen Merkmalsraum der Dimension
k ist . Verteilende Semantik-Tools wie Word2Vec, Glove, FastText usw. werden häufig verwendet, um einen Feature-Space zu bilden.
In der ersten Stufe wird die Eingangsmatrix von Faltungsschichten verarbeitet. Filter haben in der Regel eine feste Breite, die der Dimension des Attributraums entspricht, und für Filtergrößen ist nur ein Parameter konfiguriert - Höhe
h . Es stellt sich heraus, dass
h die Höhe benachbarter Linien ist, die vom Filter zusammen betrachtet werden. Dementsprechend variiert die Dimension der Ausgangsmerkmalsmatrix für jedes Filter in Abhängigkeit von der Höhe dieses Filters
h und der Höhe der ursprünglichen Matrix
n .
Als nächstes wird die am Ausgang jedes Filters erhaltene Merkmalskarte von einer Unterabtastschicht mit einer spezifischen Verdichtungsfunktion (1-Max-Pooling im Bild) verarbeitet, d.h. Reduziert die Dimension der generierten Feature-Map. Somit werden die wichtigsten Informationen für jede Faltung unabhängig von ihrer Position im Text extrahiert. Mit anderen Worten, für die verwendete Vektoranzeige ermöglicht die Kombination von Faltungsschichten und Unterabtastungsschichten das Extrahieren der signifikantesten
n- Gramm aus dem Text.
Danach werden die am Ausgang jeder Unterabtastschicht berechneten Merkmalskarten zu einem gemeinsamen Merkmalsvektor kombiniert. Es wird dem Eingang einer verborgenen, vollständig verbundenen Schicht zugeführt und dann der Ausgangsschicht des neuronalen Netzwerks zugeführt, wo die endgültigen Klassenbezeichnungen berechnet werden.
Trainingsdaten
Für das Training habe ich das
Korpus von Kurztexten von Julia Rubtsova ausgewählt , die auf der Grundlage russischsprachiger Nachrichten von Twitter [4] erstellt wurden. Es enthält 114 991 positive, 111 923 negative Tweets sowie eine Basis nicht zugeordneter Tweets mit einem Volumen von 17 639 674 Nachrichten.
import pandas as pd import numpy as np
Vor dem Training haben die Texte die Vorbearbeitung bestanden:
- in Kleinbuchstaben umwandeln;
- Ersetzen von "e" durch "e";
- Ersetzen von Links zum "URL" -Token;
- Ersetzen der Erwähnung des Benutzers durch das USER-Token;
- Interpunktionszeichen entfernen.
import re def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
Als nächstes teilte ich den Datensatz in ein Trainings- und Testmuster im Verhältnis 4: 1 auf.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
Vektoranzeige von Wörtern
Die Eingabedaten des Faltungs-Neuronalen Netzwerks sind eine Matrix mit einer festen Höhe
n , wobei jede Zeile eine Vektorabbildung eines Wortes in einen Merkmalsraum der Dimension
k ist . Um die Einbettungsschicht eines neuronalen Netzwerks zu bilden, habe ich das Dienstprogramm Word2Vec [5] für verteilende Semantik verwendet, um die semantische Bedeutung von Wörtern in den Vektorraum abzubilden. Word2Vec findet Beziehungen zwischen Wörtern, indem angenommen wird, dass semantisch verwandte Wörter in ähnlichen Kontexten gefunden werden. Sie können mehr über Word2Vec im
Originalartikel sowie
hier und
hier lesen. Da Tweets durch Interpunktion von Autoren und Emoticons gekennzeichnet sind, wird das Definieren der Grenzen von Sätzen zu einer ziemlich zeitaufwändigen Aufgabe. In dieser Arbeit habe ich angenommen, dass jeder Tweet nur einen Satz enthält.
Die Basis nicht zugeordneter Tweets wird im SQL-Format gespeichert und enthält mehr als 17,5 Millionen Datensätze. Der Einfachheit halber habe ich es mit
diesem Skript in SQLite konvertiert.
import sqlite3
Anschließend habe ich mithilfe der Gensim-Bibliothek das Word2Vec-Modell mit den folgenden Parametern trainiert:
- Größe = 200 - Dimension des Attributraums;
- window = 5 - die Anzahl der Wörter aus dem Kontext, den der Algorithmus analysiert;
- min_count = 3 - Das Wort muss mindestens dreimal vorkommen, damit das Modell es berücksichtigt.
import logging import multiprocessing import gensim from gensim.models import Word2Vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
 Abbildung 2. Visualisierung von Clustern ähnlicher Wörter mit t-SNE.
Abbildung 2. Visualisierung von Clustern ähnlicher Wörter mit t-SNE.Für ein detaillierteres Verständnis der Funktionsweise von Word2Vec in Abb.
Abbildung 2 zeigt die Visualisierung mehrerer Cluster ähnlicher Wörter aus dem trainierten Modell, die mithilfe
des t-SNE-Visualisierungsalgorithmus in einen zweidimensionalen Raum abgebildet wurden.
Vektoranzeige von Texten
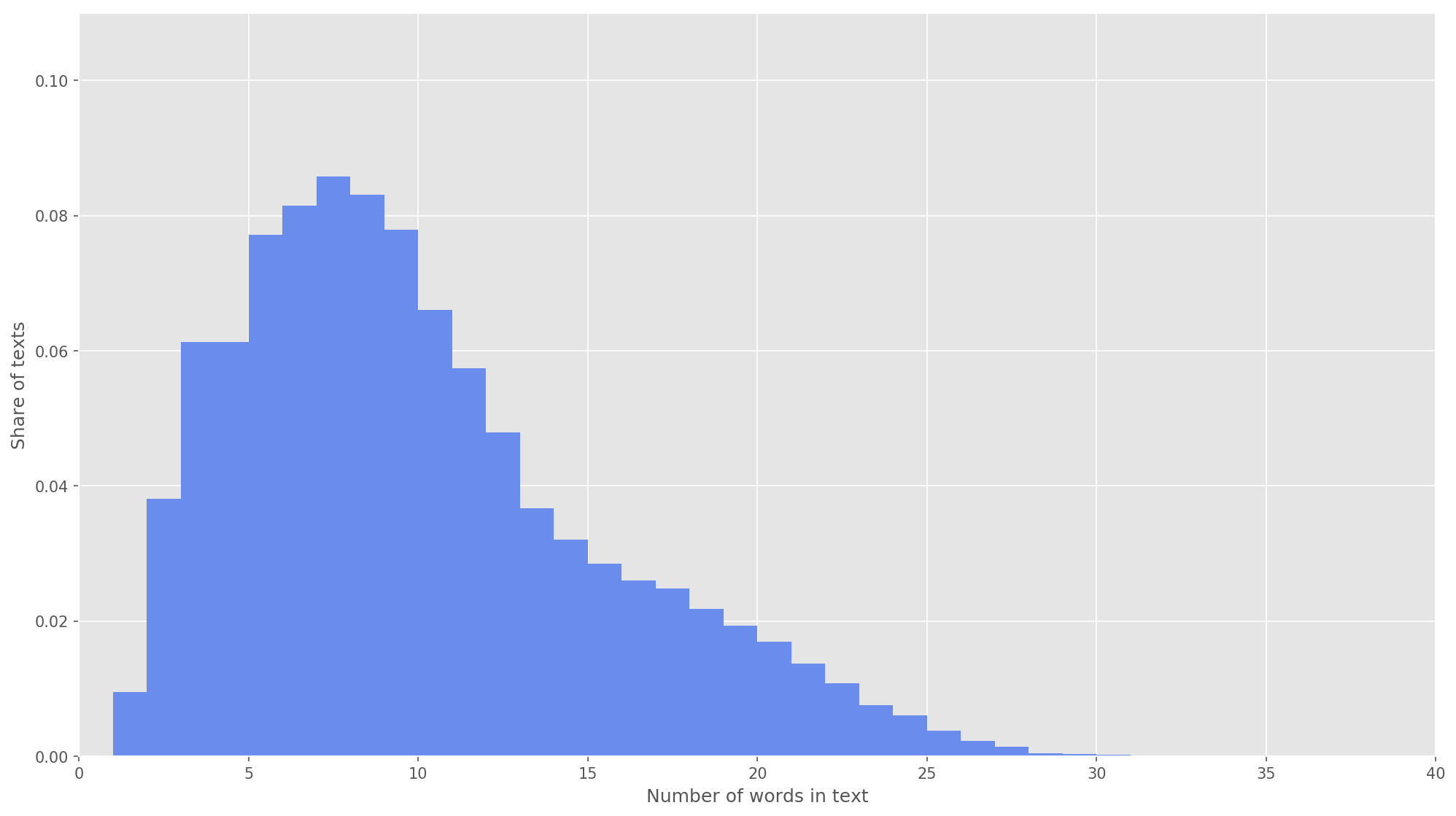 Abb. 3. Die Verteilung der Länge der Texte.
Abb. 3. Die Verteilung der Länge der Texte.Im nächsten Schritt wurde jeder Text einem Array von Token-IDs zugeordnet. Ich habe die Dimension des Textvektors
s = 26 gewählt , da bei diesem Wert 99,71% aller Texte im gebildeten Körper vollständig abgedeckt sind (Abb. 3). Wenn während der Analyse die Anzahl der Wörter im Tweet die Höhe der Matrix überschritt, wurden die verbleibenden Wörter verworfen und bei der Klassifizierung nicht berücksichtigt. Die endgültige Dimension der Vorschlagsmatrix betrug
s × d = 26 × 200 .
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences
Faltungs-Neuronales Netz
Um ein neuronales Netzwerk aufzubauen, habe ich die Keras-Bibliothek verwendet, die als übergeordnetes Add-On für TensorFlow, CNTK und Theano fungiert. Keras verfügt über eine hervorragende Dokumentation sowie ein Blog, das viele Aufgaben des maschinellen Lernens abdeckt, z. B. das
Initialisieren der Einbettungsschicht . In unserem Fall wurde die Einbettungsschicht durch die Gewichte initiiert, die durch Lernen von Word2Vec erhalten wurden. Um Änderungen in der Einbettungsschicht zu minimieren, habe ich sie in der ersten Trainingsphase eingefroren.
from keras.layers import Input from keras.layers.embeddings import Embedding tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32') tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH, weights=[embedding_matrix], trainable=False)(tweet_input)
In der entwickelten Architektur wurden Filter mit den Höhen
h = (2, 3, 4, 5) verwendet, die für die parallele Verarbeitung von Bigrams, Trigrammen, 4 Gramm bzw. 5 Gramm ausgelegt sind. Für jede Filterhöhe wurden jedem neuronalen Netzwerk 10 Faltungsschichten hinzugefügt. Die Aktivierungsfunktion ist ReLU. Die Empfehlungen zur Ermittlung der optimalen Höhe und Anzahl der Filter finden Sie in [2].
Nach der Verarbeitung durch Faltungsschichten wurden die Attributkarten Unterabtastschichten zugeführt, auf die die 1-Max-Pooling-Operation angewendet wurde, wodurch die signifikantesten n-Gramm aus dem Text extrahiert wurden. In der nächsten Phase verschmolzen sie zu einem gemeinsamen Merkmalsvektor (Kombinationsschicht), der in eine verborgene, vollständig verbundene Schicht mit 30 Neuronen eingespeist wurde. In der letzten Stufe wurde die endgültige Merkmalskarte mit einer sigmoidalen Aktivierungsfunktion der Ausgangsschicht des neuronalen Netzwerks zugeführt.
Da neuronale Netze nach der Einbettungsschicht und vor der verborgenen, vollständig verbundenen Schicht zu Umschulungen neigen, habe ich eine Dropout-Regularisierung mit der Wahrscheinlichkeit eines Vertex-Auswurfs p = 0,2 hinzugefügt.
from keras import optimizers from keras.layers import Dense, concatenate, Activation, Dropout from keras.models import Model from keras.layers.convolutional import Conv1D from keras.layers.pooling import GlobalMaxPooling1D branches = []
Ich habe das endgültige Modell mit der Adam-Optimierungsfunktion (Adaptive Moment Estimation) und der binären Kreuzentropie als Funktion von Fehlern konfiguriert. Die Qualität des Klassifikators wurde im Hinblick auf makrogemittelte Genauigkeit, Vollständigkeit und f-Maße bewertet.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1]) model.summary()
In der ersten Trainingsphase wurde die Einbettungsschicht eingefroren, alle anderen Schichten wurden für 10 Epochen trainiert:
- Die Größe der Gruppe von Beispielen, die für das Training verwendet werden, beträgt 32.
- Größe der Validierungsstichprobe: 25%.
from keras.callbacks import ModelCheckpoint checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1) history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
ProtokolleTrain on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
Dann wählte er das Modell mit den höchsten F-Maßen im Validierungsdatensatz aus, d.h. Modell aus der achten Bildungsepoche (F
1 = 0,7791). Das Modell hat die Einbettungsschicht aufgetaut und anschließend fünf weitere Trainingsperioden gestartet.
from keras import optimizers
ProtokolleTrain on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703
Der höchste Indikator
F 1 = 76,80% in der Validierungsstichprobe wurde in der dritten Ära des Trainings erreicht. Die Qualität des trainierten Modells anhand der Testdaten betrug
F 1 = 78,1% .
Tabelle 1. Analyse der Qualität der Stimmung anhand von Testdaten.
Ergebnis
Als Basislösung habe ich
einen naiven Bayes-Klassifikator mit einem multinomialen Verteilungsmodell
trainiert. Die Vergleichsergebnisse sind in der Tabelle dargestellt. 2.
Tabelle 2. Vergleich der Qualität der Analyse der Tonalität.
Wie Sie sehen können, hat die Qualität der CNN-Klassifizierung MNB um mehrere Prozent übertroffen. Metrikwerte können noch weiter erhöht werden, wenn Sie an der Optimierung von Hyperparametern und der Netzwerkarchitektur arbeiten. Sie können beispielsweise die Anzahl der Trainingszeiten ändern, die Wirksamkeit der Verwendung verschiedener Vektordarstellungen von Wörtern und ihrer Kombinationen überprüfen, die Anzahl der Filter und ihre Höhe auswählen, eine effektivere Textvorverarbeitung (Tippfehlerkorrektur, Normalisierung, Stempelung) implementieren und die Anzahl der darin enthaltenen vollständig verbundenen Ebenen und Neuronen anpassen .
Der Quellcode
ist auf Github verfügbar. Geschulte CNN- und Word2Vec-Modelle können hier heruntergeladen
werden .
Quellen
- Cliche M. BB_twtr bei SemEval-2017 Aufgabe 4: Twitter-Stimmungsanalyse mit CNNs und LSTMs // Vorträge des 11. Internationalen Workshops zur semantischen Evaluation (SemEval-2017). - 2017 - S. 573-580.
- Zhang Y., Wallace B. Eine Sensitivitätsanalyse (und ein Leitfaden für Praktiker zu) Faltungs-Neuronalen Netzen zur Satzklassifizierung // arXiv-Vorabdruck arXiv: 1510.03820. - 2015.
- Rosenthal S., Farra N., Nakov P. SemEval-2017 Aufgabe 4: Stimmungsanalyse in Twitter // Vorträge des 11. Internationalen Workshops zur semantischen Evaluation (SemEval-2017). - 2017 - S. 502-518.
- Yu. V. Rubtsova. Erstellen eines Textkörpers zum Einstellen des Tonklassifikators // Software Products and Systems, 2015, Nr. 1 (109), —C.72-78.
- Mikolov T. et al. Verteilte Darstellungen von Wörtern und Phrasen und ihre Zusammensetzung // Fortschritte in neuronalen Informationsverarbeitungssystemen. - 2013 - S. 3111-3119.