In einem früheren Artikel,
Überblick über neuronale Netze zur Bildklassifizierung , haben wir uns mit den Grundkonzepten von Faltungs-Neuronalen Netzen sowie den zugrunde liegenden Ideen vertraut gemacht. In diesem Artikel werden einige tiefe neuronale Netzwerkarchitekturen mit großer Verarbeitungsleistung betrachtet - wie AlexNet, ZFNet, VGG, GoogLeNet und ResNet - und die Hauptvorteile jeder dieser Architekturen zusammengefasst. Die Struktur des Artikels basiert auf einem Blogeintrag
Grundlegende Konzepte von Faltungs-Neuronalen Netzen, Teil 3 .
Derzeit ist die
ImageNet Challenge der Hauptanreiz für die Entwicklung von Maschinenerkennungssystemen und die Bildklassifizierung. Die Kampagne ist ein Wettbewerb für die Arbeit mit Daten, bei dem den Teilnehmern ein großer Datensatz (mehr als eine Million Bilder) zur Verfügung gestellt wird. Die Aufgabe des Wettbewerbs besteht darin, einen Algorithmus zu entwickeln, mit dem Sie die erforderlichen Bilder in Objekte in 1000 Kategorien - wie Hunde, Katzen, Autos und andere - mit einer minimalen Anzahl von Fehlern einteilen können.
Gemäß den offiziellen Regeln des Wettbewerbs müssen die Algorithmen eine Liste von nicht mehr als fünf Kategorien von Objekten in absteigender Reihenfolge des Vertrauens für jede Kategorie von Bildern bereitstellen. Die Bildmarkierungsqualität wird anhand des Etiketts bewertet, das am besten mit der Grundwahrheitseigenschaft des Bildes übereinstimmt. Die Idee ist, dem Algorithmus zu ermöglichen, mehrere Objekte im Bild zu identifizieren und keine Strafpunkte zu sammeln, falls eines der erkannten Objekte tatsächlich im Bild vorhanden war, aber nicht in der Grundwahrheitseigenschaft enthalten war.
Im ersten Jahr des Wettbewerbs erhielten die Teilnehmer vorab ausgewählte Bildattribute für das Training des Modells. Dies können beispielsweise Zeichen des
SIFT- Algorithmus sein, der unter Verwendung einer Vektorquantisierung verarbeitet wird und zur Verwendung in der Wortbeutelmethode oder zur Darstellung als räumliche Pyramide geeignet ist. 2012 gab es jedoch einen echten Durchbruch in diesem Bereich: Eine Gruppe von Wissenschaftlern der University of Toronto hat gezeigt, dass ein tiefes neuronales Netzwerk im Vergleich zu herkömmlichen Modellen für maschinelles Lernen, die auf der Grundlage von Vektoren aus zuvor ausgewählten Bildeigenschaften erstellt wurden, signifikant höhere Ergebnisse erzielen kann. In den folgenden Abschnitten werden die erste 2012 vorgeschlagene innovative Architektur sowie die Architekturen betrachtet, die bis 2015 folgen.
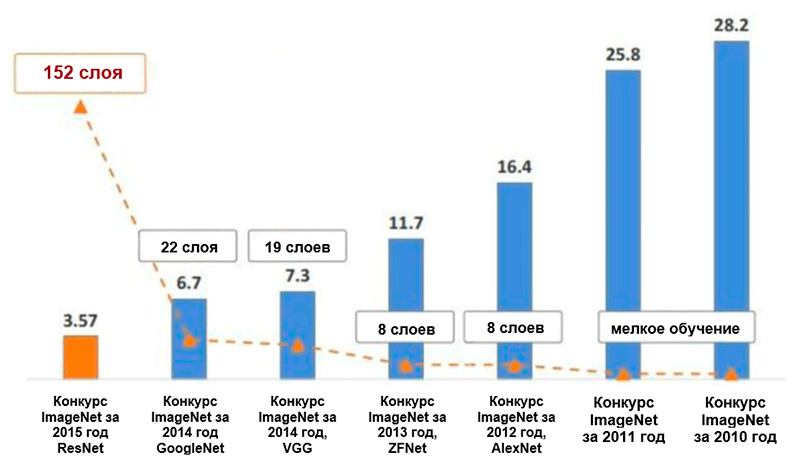 Diagramm der Änderungen der Anzahl der Fehler (in Prozent) bei der Klassifizierung von ImageNet * -Bildern für die fünf führenden Kategorien. Bild aus der Präsentation von Kaiming He, Deep Residual Learning for Image Recognition
Diagramm der Änderungen der Anzahl der Fehler (in Prozent) bei der Klassifizierung von ImageNet * -Bildern für die fünf führenden Kategorien. Bild aus der Präsentation von Kaiming He, Deep Residual Learning for Image RecognitionAlexnet
Die AlexNet- Architektur wurde 2012 von einer Gruppe von Wissenschaftlern (A. Krizhevsky, I. Sutskever und J. Hinton) von der University of Toronto vorgeschlagen. Dies war eine innovative Arbeit, in der die Autoren (zu dieser Zeit) erstmals tiefe Faltungsnetzwerke mit einer Gesamttiefe von acht Schichten (fünf Faltungsschichten und drei vollständig verbundene Schichten) verwendeten.
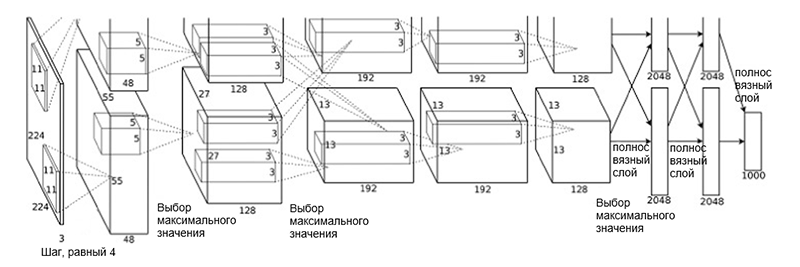 Architektur AlexNet
Architektur AlexNetDie Netzwerkarchitektur besteht aus folgenden Schichten:
- [Faltungsschicht + Maximalwertauswahl + Normalisierung] x 2
- [Faltungsschicht] x 3
- [Auswahl des Maximalwerts]
- [Volle Schicht] x 3
Ein solches Schema mag etwas seltsam aussehen, da der Lernprozess aufgrund seiner hohen Rechenkomplexität zwischen den beiden GPUs aufgeteilt wurde. Diese Arbeitsteilung zwischen GPUs erfordert eine manuelle Trennung des Modells in vertikale Blöcke, die miteinander interagieren.
Die Architektur von AlexNet hat die Anzahl der Fehler in den fünf führenden Kategorien auf 16,4 Prozent reduziert - fast die Hälfte im Vergleich zu früheren fortgeschrittenen Entwicklungen! Ebenfalls im Rahmen dieser Architektur wurde eine solche Aktivierungsfunktion als lineare Gleichrichtereinheit (
ReLU ) eingeführt, die derzeit der Industriestandard ist. Das Folgende ist eine kurze Zusammenfassung anderer Hauptmerkmale der AlexNet-Architektur und ihres Lernprozesses:
- Intensive Datenerweiterung
- Ausschlussmethode
- Optimierung mit SGD-Moment (siehe Optimierungsleitfaden „Übersicht über Algorithmen zur Optimierung des Gradientenabfalls“)
- Manuelle Einstellung der Lerngeschwindigkeit (Reduzierung dieses Koeffizienten um 10 bei Stabilisierung der Genauigkeit)
- Das endgültige Modell ist eine Sammlung von sieben Faltungs-Neuronalen Netzen
- Die Schulung wurde auf zwei NVIDIA * GeForce GTX * 580-Grafikprozessoren mit jeweils insgesamt 3 GB Videospeicher durchgeführt.
Zfnet
Die von den Forschern M. Zeiler und R. Fergus von der New York University vorgeschlagene
ZFNet- Netzwerkarchitektur ist nahezu identisch mit der AlexNet-Architektur. Die einzigen signifikanten Unterschiede zwischen ihnen sind wie folgt:
- Filtergröße und Schritt in der ersten Faltungsschicht (in AlexNet beträgt die Filtergröße 11 × 11 und der Schritt 4; in ZFNet - 7 × 7 bzw. 2)
- Die Anzahl der Filter in sauberen Faltungsschichten (3, 4, 5).
 ZFNet-Architektur
ZFNet-ArchitekturDank der ZFNet-Architektur sank die Anzahl der Fehler in den fünf führenden Kategorien auf 11,4 Prozent. Möglicherweise spielt dabei die genaue Abstimmung der Hyperparameter (Größe und Anzahl der Filter, Paketgröße, Lerngeschwindigkeit usw.) die Hauptrolle. Es ist jedoch auch wahrscheinlich, dass die Ideen der ZFNet-Architektur einen sehr wichtigen Beitrag zur Entwicklung von Faltungs-Neuronalen Netzen geleistet haben. Ziller und Fergus schlugen ein System zur Visualisierung von Kernen, Gewichten und einer verborgenen Ansicht von Bildern mit dem Namen DeconvNet vor. Dank ihr wurde ein besseres Verständnis und eine Weiterentwicklung der Faltungs-Neuronalen Netze möglich.
VGG Net
2014 schlugen K. Simonyan und E. Zisserman von der Universität Oxford eine Architektur namens
VGG vor . Die Hauptidee dieser Struktur ist es
, die Filter so einfach wie möglich zu
halten . Daher werden alle Faltungsoperationen unter Verwendung eines Filters der Größe 3 und eines Schritts der Größe 1 ausgeführt, und alle Unterabtastungsoperationen werden unter Verwendung eines Filters der Größe 2 und eines Schritts der Größe 2 durchgeführt. Dies ist jedoch nicht alles. Zusammen mit der Einfachheit der Faltungsmodule ist das Netzwerk erheblich gewachsen - jetzt hat es 19 Schichten! Die wichtigste Idee, die zuerst in dieser Arbeit vorgeschlagen wurde, besteht darin
, Faltungsschichten ohne Unterabtastungsschichten aufzuerlegen . Die zugrunde liegende Idee ist, dass eine solche Überlagerung immer noch ein ausreichend großes Empfangsfeld liefert (zum Beispiel haben drei überlagerte Faltungsschichten mit einer Größe von 3 × 3 in Schritten von 1 ein Empfangsfeld ähnlich einer Faltungsschicht mit einer Größe von 7 × 7). Die Anzahl der Parameter ist jedoch erheblich geringer als in Netzwerken mit großen Filtern (dient als Regularisierer). Zusätzlich wird es möglich, zusätzliche nichtlineare Transformationen einzuführen.
Im Wesentlichen haben die Autoren gezeigt, dass Sie selbst mit sehr einfachen Bausteinen im ImageNet-Wettbewerb qualitativ hochwertige Ergebnisse erzielen können. Die Anzahl der Fehler für die fünf führenden Kategorien wurde auf 7,3 Prozent reduziert.
 VGG-Architektur. Bitte beachten Sie, dass die Anzahl der Filter umgekehrt proportional zur räumlichen Größe des Bildes ist.
VGG-Architektur. Bitte beachten Sie, dass die Anzahl der Filter umgekehrt proportional zur räumlichen Größe des Bildes ist.GoogleNet
Bisher bestand die gesamte Architekturentwicklung darin, Filter zu vereinfachen und die Tiefe des Netzwerks zu erhöhen. 2014 schlug C. Szegedy zusammen mit anderen Teilnehmern einen völlig anderen Ansatz vor und schuf die damals komplexeste Architektur namens GoogLeNet.
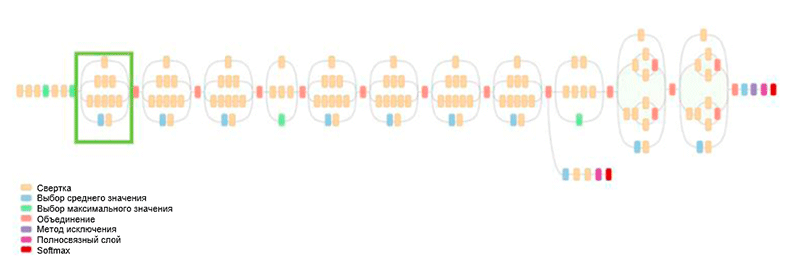 GoogLeNet-Architektur. Es verwendet das Inception-Modul, das in der Abbildung grün hervorgehoben ist. Der Netzwerkaufbau basiert auf diesen Modulen
GoogLeNet-Architektur. Es verwendet das Inception-Modul, das in der Abbildung grün hervorgehoben ist. Der Netzwerkaufbau basiert auf diesen ModulenEine der wichtigsten Errungenschaften dieser Arbeit ist das sogenannte Inception-Modul, das in der folgenden Abbildung dargestellt ist. Netzwerke anderer Architekturen verarbeiten Eingabedaten nacheinander, Schicht für Schicht, während unter Verwendung des Inception-Moduls
Eingabedaten parallel verarbeitet werden . Auf diese Weise können Sie die Ausgabe beschleunigen und die
Gesamtzahl der Parameter minimieren.
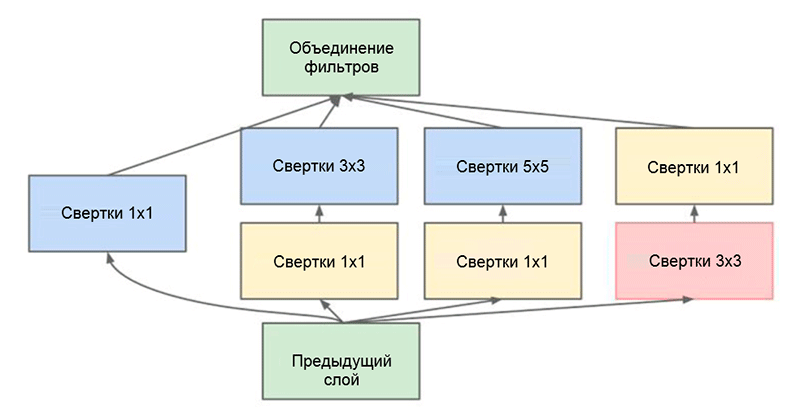 Inception-Modul. Beachten Sie, dass das Modul mehrere parallele Zweige verwendet, die unterschiedliche Eigenschaften basierend auf denselben Eingabedaten berechnen und dann die Ergebnisse kombinieren
Inception-Modul. Beachten Sie, dass das Modul mehrere parallele Zweige verwendet, die unterschiedliche Eigenschaften basierend auf denselben Eingabedaten berechnen und dann die Ergebnisse kombinierenEin weiterer interessanter Trick, der im Inception-Modul verwendet wird, ist die Verwendung von Faltungsschichten der Größe 1 × 1. Dies mag sinnlos erscheinen, bis wir uns daran erinnern, dass der Filter die gesamte Dimension der Tiefe abdeckt. Somit ist eine 1 × 1-Faltung ein einfacher Weg, um die Dimension einer Eigenschaftskarte zu reduzieren. Diese Art von Faltungsschichten wurde erstmals
von M. Lin et al. In
Network eingeführt. Eine umfassende und verständliche Erklärung findet sich auch im Blog-Beitrag
Convolution [1 × 1] - Nützlichkeit entgegen der Intuition von A. Prakash.
Letztendlich reduzierte diese Architektur die Anzahl der Fehler für die fünf führenden Kategorien um ein weiteres halbes Prozent - auf einen Wert von 6,7 Prozent.
Resnet
Im Jahr 2015 kam eine Gruppe von Forschern (Cuming Hee und andere) von Microsoft Research Asia auf eine Idee, die derzeit von den meisten Mitgliedern der Community als eine der wichtigsten Phasen bei der Entwicklung von Deep Learning angesehen wird.
Eines der Hauptprobleme tiefer neuronaler Netze ist das Problem eines verschwindenden Gradienten. Kurz gesagt, dies ist ein technisches Problem, das auftritt, wenn die Fehlerrückausbreitungsmethode für den Gradientenberechnungsalgorithmus verwendet wird. Bei der Arbeit mit der Rückübertragung von Fehlern wird eine Kettenregel verwendet. Wenn der Gradient am Ende des Netzwerks einen kleinen Wert hat, kann er außerdem einen unendlich kleinen Wert annehmen, wenn er den Anfang des Netzwerks erreicht. Dies kann zu völlig anderen Problemen führen, einschließlich der grundsätzlichen Unmöglichkeit, das Netzwerk zu lernen (weitere Informationen finden Sie im Blogeintrag von R. Kapur
Das Problem eines verblassenden Gradienten ).
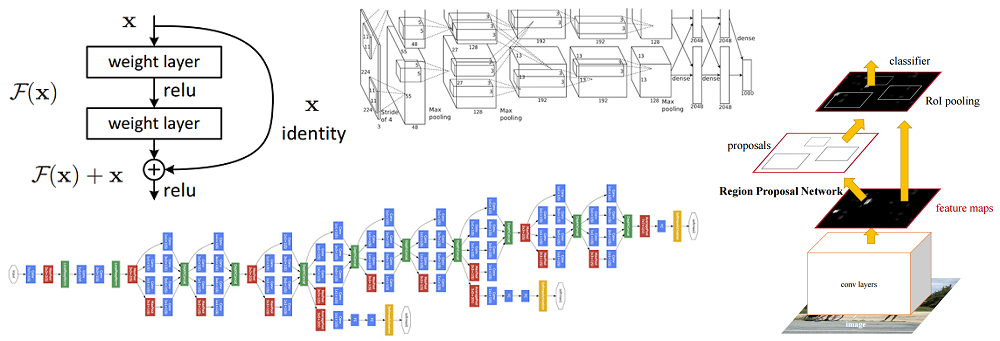
Um dieses Problem zu lösen, schlugen Caiming Hee und seine Gruppe die folgende Idee vor: Dem Netzwerk zu ermöglichen, die Restzuordnung (ein Element, das der Eingabe hinzugefügt werden sollte) anstelle der Anzeige selbst zu untersuchen. Technisch erfolgt dies über die in der Abbildung gezeigte Bypass-Verbindung.
 Schematische Darstellung des Restblocks: Die Eingangsdaten werden über eine verkürzte Verbindung unter Umgehung der Konvertierungsschichten übertragen und zum Ergebnis addiert. Bitte beachten Sie, dass eine „identische“ Verbindung dem Netzwerk keine zusätzlichen Parameter hinzufügt, weshalb ihre Struktur nicht kompliziert ist
Schematische Darstellung des Restblocks: Die Eingangsdaten werden über eine verkürzte Verbindung unter Umgehung der Konvertierungsschichten übertragen und zum Ergebnis addiert. Bitte beachten Sie, dass eine „identische“ Verbindung dem Netzwerk keine zusätzlichen Parameter hinzufügt, weshalb ihre Struktur nicht kompliziert istDiese Idee ist äußerst einfach, aber gleichzeitig äußerst effektiv. Es löst das Problem des verschwindenden Gradienten und ermöglicht es ihm, sich ohne Änderungen von den oberen zu den unteren Schichten durch "identische" Verbindungen zu bewegen. Dank dieser Idee können Sie sehr tiefe, extrem tiefe Netzwerke trainieren.
Das Netzwerk, das 2015 die ImageNet Challenge gewann, enthielt 152 Ebenen (die Autoren konnten das Netzwerk mit 1001 Ebenen trainieren, aber es lieferte ungefähr das gleiche Ergebnis, sodass sie nicht mehr damit arbeiteten). Darüber hinaus konnte mit dieser Idee die Anzahl der Fehler für die fünf führenden Kategorien buchstäblich um die Hälfte reduziert werden - auf einen Wert von 3,6 Prozent. Laut einer Studie über das,
was ich im ImageNet-Wettbewerb von A. Karpathy
im Wettbewerb mit einem Faltungsnetzwerk gelernt habe, beträgt die menschliche Leistung für diese Aufgabe ungefähr 5 Prozent. Dies bedeutet, dass die ResNet-Architektur zumindest bei dieser Bildklassifizierungsaufgabe die menschlichen Ergebnisse übertreffen kann.