Kann ich Front-End-Entwicklern auf einfache Weise Informationen über die Cloudless Serverless-Architektur in AWS (Amazon Web Services) geben? Warum nicht. Lassen Sie uns die AWS React / Redux-Anwendung rendern und dann über die Vor- und Nachteile von AWS Lambdas sprechen.
Das Material basiert auf der Abschrift des Berichts von Marina Mironovich von unserer Frühjahrskonferenz HolyJS 2018 in St. Petersburg.Offiziell ist Marina ein führender Entwickler von EPAM. Jetzt arbeitet sie in einer Lösungsarchitektengruppe für einen Kunden und nimmt deshalb an einer Vielzahl von Projekten teil. Daher wird es für uns einfacher sein, den Kreis ihrer aktuellen Interessen zu skizzieren, als alle Technologien aufzulisten, mit denen sie arbeitet.
 Zunächst interessiere ich mich für alle Cloud-Technologien, insbesondere für AWS, weil ich in der Produktion viel damit arbeite. Aber ich versuche mit allem anderen Schritt zu halten.
Zunächst interessiere ich mich für alle Cloud-Technologien, insbesondere für AWS, weil ich in der Produktion viel damit arbeite. Aber ich versuche mit allem anderen Schritt zu halten.
Frontend ist meine erste Liebe und scheint für immer. Insbesondere arbeite ich derzeit mit React und React Native, daher weiß ich etwas mehr darüber. Ich versuche auch, alles andere im Auge zu behalten. Ich interessiere mich für alles, was mit Projektdokumentation zu tun hat, zum Beispiel für UML-Diagramme. Da ich Mitglied der Solution Architect Group bin, muss ich viel tun.
Teil 1. Hintergrund
Die Idee, über Serverless zu sprechen, kam mir vor ungefähr einem Jahr. Ich wollte einfach und natürlich über Serverless für Front-End-Entwickler sprechen. Damit Sie kein zusätzliches Wissen benötigen, um es zu verwenden, können Sie dies jetzt mit mehr Technologien tun.
Bis zu einem gewissen Grad wurde die Idee verwirklicht - ich
habe auf FrontTalks 2017
über Serverless gesprochen. Es stellte sich jedoch heraus, dass 45 Minuten für eine einfache und verständliche Geschichte nicht ausreichen. Daher wurde der Bericht in zwei Teile geteilt, und jetzt vor Ihnen ist die zweite "Serie". Wer das erste nicht gesehen hat - keine Sorge, es wird nicht schaden zu verstehen, was unten geschrieben steht. Wie in anständigen Fernsehsendungen werde ich mit einer Zusammenfassung des vorherigen Teils beginnen. Dann gehe ich zum Saft selbst über - wir rendern die React / Redux-Anwendung. Und schließlich werde ich über die Vor- und Nachteile von Cloud-Funktionen im Prinzip (insbesondere AWS Lambdas) sprechen und darüber, was mit ihnen sonst noch getan werden kann. Ich hoffe, dass dieser Teil für alle nützlich sein wird, die bereits mit dem AWS Lambda vertraut sind. Am wichtigsten ist, dass die Welt nicht mit Amazon endet. Sprechen wir also darüber, was es sonst noch im Bereich der Cloud-Funktionen gibt.
Was ich verwenden werde
Zum Rendern der Anwendung werde ich viele Amazon-Dienste verwenden:
- S3 ist ein Dateisystem in den Clouds. Dort speichern wir statische Assets.
- IAM (Zugriffsrechte für Benutzer und Dienste) - implizit, wird jedoch im Hintergrund verwendet, damit die Dienste miteinander kommunizieren.
- API-Gateway (URL für den Zugriff auf die Site) - Sie sehen die URL, unter der wir unser Lambda aufrufen können.
- CloudFormation (für die Bereitstellung) - wird implizit im Hintergrund verwendet.
- AWS Lambda - dafür sind wir hergekommen.
Was ist serverlos und was ist AWS Lambda?
Eigentlich ist Serverless ein großer Betrug, denn natürlich gibt es Server: Irgendwo fängt alles an. Aber was ist dort los?
Wir schreiben eine Funktion, die auf den Servern ausgeführt wird. Natürlich fängt es nicht nur so an, sondern in einer Art Behälter. Tatsächlich wird diese Funktion im Container auf dem Server als Lambda bezeichnet.
Im Falle von Lambda können wir die Server vergessen. Ich würde sogar folgendes sagen: Wenn Sie die Lambda-Funktion schreiben, ist es schädlich, über sie nachzudenken. Wir arbeiten mit Lambda nicht so wie mit einem Server.
So setzen Sie Lambda ein
Es stellt sich eine logische Frage: Wenn wir keinen Server haben, wie stellen wir ihn bereit? Es gibt SSH auf dem Server, wir haben den Code hochgeladen, ihn gestartet - alles ist in Ordnung. Was tun mit Lambda?
Option 1. Wir können es nicht bereitstellen.AWS in der Konsole hat eine nette und sanfte IDE für uns erstellt, in der wir genau dort eine Funktion schreiben können.

Es ist schön, aber nicht sehr erweiterbar.
Option 2. Wir können eine Zip-Datei erstellen und von der Befehlszeile herunterladenWie erstellen wir eine Zip-Datei?
zip -r build/lambda.zip index.js [node_modules/] [package.json]
Wenn Sie node_modules verwenden, wird dies alles in einem Archiv komprimiert.
Je nachdem, ob Sie eine neue Funktion erstellen oder ob Sie bereits über eine solche Funktion verfügen, können Sie dies auch tun
aws lambda create-function...
entweder
aws lambda update-function-code...
Was ist das Problem? Zunächst möchte die AWS-CLI wissen, ob eine Funktion erstellt wird oder ob Sie bereits eine haben. Dies sind zwei verschiedene Teams. Wenn Sie nicht nur den Code, sondern auch einige Attribute dieser Funktion aktualisieren möchten, treten Probleme auf. Die Anzahl dieser Befehle nimmt zu, und Sie müssen sich in ein Verzeichnis setzen und überlegen, welchen Befehl Sie verwenden möchten.
Wir können es besser und einfacher machen. Dafür haben wir Rahmenbedingungen.
AWS Lambda Frameworks
Es gibt viele solcher Rahmenbedingungen. Dies ist in erster Linie AWS CloudFormation, die in Verbindung mit der AWS CLI funktioniert. CloudFormation ist eine Json-Datei, die Ihre Dienste beschreibt. Sie beschreiben sie in einer Json-Datei, sagen dann über die AWS-CLI "Ausführen" und es wird automatisch alles für Sie im AWS-Service erstellt.
Für eine so einfache Aufgabe wie das Rendern ist es jedoch immer noch schwierig. Hier ist die Eintrittsschwelle zu groß - Sie müssen lesen, welche Struktur CloudFormation usw. hat.
Versuchen wir es zu vereinfachen. Und hier erscheinen verschiedene Frameworks: APEX, Zappa (nur für Python), Claudia.js. Ich habe nur wenige zufällig aufgelistet.
Das Problem und die Stärke dieser Frameworks besteht darin, dass sie hoch spezialisiert sind. Sie sind also sehr gut darin, einfache Aufgaben zu erledigen. Zum Beispiel ist Claudia.js sehr gut zum Erstellen einer REST-API geeignet. Sie wird das AWS-Aufruf-API-Gateway erstellen, sie wird ein Lambda für Sie erstellen, alles wird wunderschön gesperrt sein. Wenn Sie jedoch etwas mehr bereitstellen müssen, treten Probleme auf - Sie müssen etwas hinzufügen, helfen, schauen usw.
Zappa wurde nur für Python geschrieben. Und ich möchte etwas ehrgeizigeres. Und hier kommt Terraform und meine Serverless Liebe.
Serverless liegt irgendwo in der Mitte zwischen der sehr großen CloudFormation, die fast alles kann, und diesen hochspezialisierten Frameworks. Fast alles kann darin bereitgestellt werden, aber alles zu tun ist immer noch recht einfach. Es hat auch eine sehr leichte Syntax.
Terraform ist bis zu einem gewissen Grad ein Analogon zu CloudFormation. Terraform ist Open Source, darin können Sie alles bereitstellen - gut oder fast alles. Und wenn AWS die Services erstellt, können Sie dort etwas Neues hinzufügen. Aber es ist groß und kompliziert.
Um ehrlich zu sein, verwenden wir in der Produktion Terraform, weil mit Terraform alles, was wir haben, einfacher wird - Serverless wird dies alles nicht beschreiben. Aber Terraform ist sehr komplex. Und wenn ich etwas für die Arbeit schreibe, schreibe ich es zuerst auf Serverless, teste es auf Leistung und erst nachdem meine Konfiguration getestet und ausgearbeitet wurde, schreibe ich es auf Terraform neu (das macht noch ein paar Tage „Spaß“).
Serverlos
Warum liebe ich Serverless?
- Serverless verfügt über ein System, mit dem Sie Plugins erstellen können. Meiner Meinung nach ist dies eine Rettung von allem. Serverlos - Open Source. Das Hinzufügen von Open Source ist jedoch nicht immer einfach. Sie müssen verstehen, was im vorhandenen Code passiert, Richtlinien beachten, zumindest den Codestil einhalten, eine PR einreichen, diese PR vergessen und sie drei Jahre lang verstauben. Entsprechend den Ergebnissen gabelst du, und dies wird irgendwo für dich separat sein. Das alles ist nicht sehr gesund. Aber wenn es Plugins gibt, wird alles vereinfacht. Sie müssen etwas hinzufügen - Sie sind auf dem Knie und erstellen Ihr eigenes kleines Plugin. Dazu müssen Sie nicht mehr verstehen, was in Serverless geschieht (wenn dies keine benutzerdefinierte Frage ist). Sie verwenden einfach die verfügbare API, speichern das Plugin irgendwo oder stellen es für alle bereit. Und alles funktioniert für Sie. Darüber hinaus gibt es bereits einen großen Zoo von Plugins und Leuten, die diese Plugins schreiben. Das heißt, vielleicht wurde bereits etwas für Sie entschieden.
- Serverless hilft dabei, Lambda lokal auszuführen. Das ausreichend große Minus des Lambda ist, dass AWS nicht darüber nachgedacht hat, wie wir es debuggen und testen werden. Mit Serverless können Sie jedoch alles lokal ausführen und sehen, was passiert (er tut dies sogar in Verbindung mit der Gateway-API).
Demonstration
Jetzt werde ich zeigen, wie das alles wirklich funktioniert. In den nächsten anderthalb bis zwei Minuten können wir einen Dienst erstellen, der unsere HTML-Seite rendert.
Zuerst führe ich in einem neuen Ordner die SLS Create-Vorlage aus:
mkdir sls-holyjs
cd sls-holyjs
sls create --template aws-nodejs-ecma-script

npm install

Serverlose Entwickler haben sich um uns gekümmert - es ist möglich geworden, Services aus Vorlagen zu erstellen. In diesem Fall verwende ich die Vorlage
nodejs-ecma-script , mit der einige Dateien für mich erstellt werden, z. B. die Webpack-Konfiguration, package.json, einige Funktionen und serverless.yml:
ls

Ich brauche nicht alle Funktionen. Ich werde die erste, zweite Umbenennung in Holyjs entfernen:

Ich werde serveless.yml ein wenig optimieren, wo ich eine Beschreibung aller erforderlichen Dienste habe:
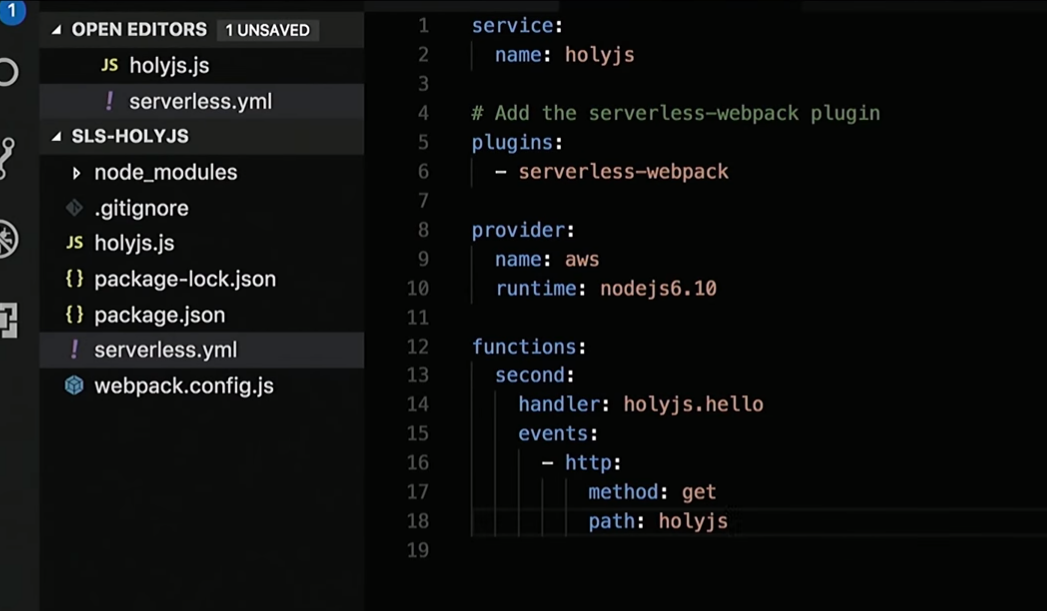
Nun, dann werde ich die Antwort korrigieren, die die Funktion zurückgibt:

Ich mache den HTML-Code "Hello HolyJS" und füge ein Handle zum Rendern hinzu.
Weiter:
sls deploy
Und voila! Es gibt eine URL, über die ich im öffentlichen Zugriff sehen kann, was gerendert wird:

Vertrauen, aber überprüfen. Ich gehe zur AWS-Konsole und überprüfe, ob ich eine HolyJS-Funktion erstellt habe:
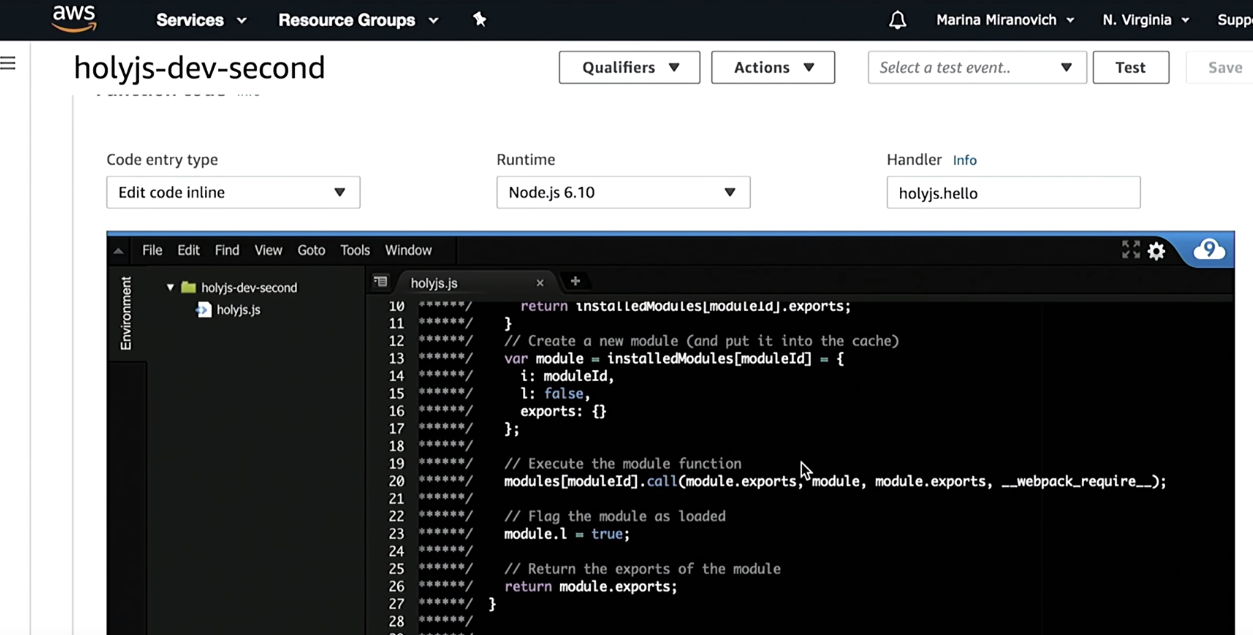
Wie Sie sehen können, erstellt Serverless es vor der Bereitstellung mithilfe von Webpack. Außerdem wird der Rest der dort beschriebenen Infrastruktur erstellt - API-Gateway usw.
Wenn ich dies entfernen möchte:
sls remove
Alle in serverless.yml beschriebenen Infrastrukturen werden gelöscht.

Wenn jemand hinter dem hier beschriebenen Prozess steht, lade ich Sie ein, einfach meinen
vorherigen Bericht zu überprüfen.
Führen Sie Lambda lokal aus
Ich erwähnte, dass Lambda lokal betrieben werden kann. Hier gibt es zwei Startoptionen.
Option 1. Wir führen einfach alles im Terminal ausWir bekommen, was unsere Funktion zurückgibt.
sls invoke local -f [fn_name]
Vergessen Sie nicht, wir machen eine isomorphe Anwendung, es wird HTML und CSS sein, daher ist es im Terminal irgendwie nicht sehr interessant, lange HTML-Zeilen zu betrachten. Dort können Sie überprüfen, ob die Funktion funktioniert. Aber ich möchte dies ausführen und im Browser rendern. Dementsprechend brauche ich ein paar API-Gateways mit Lambda.
Zu diesem Zweck gibt es ein separates Plugin ohne Server und Offline, das Ihr Lambda an einem Port startet (dies ist geschrieben). Anschließend wird im Terminal eine URL angezeigt, über die Sie darauf zugreifen können.
sls offline --port 8000 start
Das Beste daran ist, dass es heißes Nachladen gibt. Das heißt, Sie schreiben den Funktionscode, aktualisieren Ihren Browser und Sie werden aktualisiert, was die Funktion zurückgibt. Sie müssen nicht alles neu starten.
Dies war eine Zusammenfassung des ersten Teils des Berichts. Nun gehen wir zum Hauptteil über.
Teil 2. Rendern mit AWS
Das unten beschriebene Projekt ist
bereits auf GitHub. Wenn Sie interessiert sind, können Sie den Code dort herunterladen.
Beginnen wir damit, wie alles funktioniert.

Angenommen, es gibt einen Benutzer - mich.
- Ich öffne die Seite.
- Unter einer bestimmten URL greifen wir auf die Gateway-API zu. Ich möchte darauf hinweisen, dass die Gateway-API bereits ein AWS-Service ist, wir befinden uns bereits in den Clouds.
- Die Gateway-API ruft Lambda auf.
- Das Lambda rendert die Site und all dies kehrt zum Browser zurück.
- Der Browser beginnt zu rendern und stellt fest, dass einige statische Dateien fehlen. Dann wendet er sich dem S3-Bucket zu (unserem Dateisystem, in dem wir alle statischen Daten speichern; im S3-Bucket können Sie alles einfügen - Schriftarten, Bilder, CSS, JS).
- Daten aus dem S3-Bucket werden an den Browser zurückgegeben.
- Der Browser rendert die Seite.
- Jeder ist glücklich.
Lassen Sie uns einen kleinen Codeüberblick über das machen, was ich geschrieben habe.
Wenn Sie zu GitHub gehen, sehen Sie die folgende Dateistruktur:
lambda-react
README.md
config
package.json
public
scripts
serverless.yml
src
yarn.lock
All dies wird automatisch im React / Redux-Toolkit generiert. In der Tat werden wir hier nur an ein paar Dateien interessiert sein und sie müssen leicht korrigiert werden:
- config
- package.json
- serverless.yml - weil wir bereitstellen werden,
- src - nirgendwo ohne.
Beginnen wir mit der Konfiguration
Um alles auf dem Server zusammenzubringen, müssen wir eine weitere webpack.config hinzufügen:

Diese webpack.config wird bereits für Sie generiert, wenn Sie eine Vorlage verwenden. Und dort wird die Variable
slsw.lib.entries automatisch ersetzt, die auf Ihre Lambda-Handler
slsw.lib.entries . Wenn Sie möchten, können Sie es selbst ändern, indem Sie etwas anderes angeben.

Wir müssen alles für den Knoten rendern (
target: 'node' ). Grundsätzlich bleiben alle anderen Lader die gleichen wie bei einer regulären React-Anwendung.
Weiter zu package.json
Wir werden nur ein paar Skripte hinzufügen - Start und Build wurden bereits mit React / Redux generiert - nichts ändert sich. Fügen Sie ein Skript zum Starten des Lambda und ein Skript zum Bereitstellen des Lambda hinzu.

serverless.yml
Eine sehr kleine Datei - nur 17 Zeilen, alle unten:

Was interessiert uns daran? Zuallererst Handler. Dort wird der vollständige Pfad zur Datei
src/lambda/handler (
src/lambda/handler ) und die Handlerfunktion wird durch den Punkt angegeben.
Wenn Sie wirklich möchten, können Sie mehrere Handler in einer Datei registrieren. Auch hier ist der Weg zum Webpack, der all dies sammeln soll. Grundsätzlich alles: Der Rest wird bereits automatisch generiert.
Das interessanteste ist src
Hier ist eine riesige React / Redux-Anwendung (in meinem Fall ist sie nicht riesig - auf die Seite). Im zusätzlichen Lambda-Ordner finden Sie alles, was wir zum Rendern des Lambda benötigen:
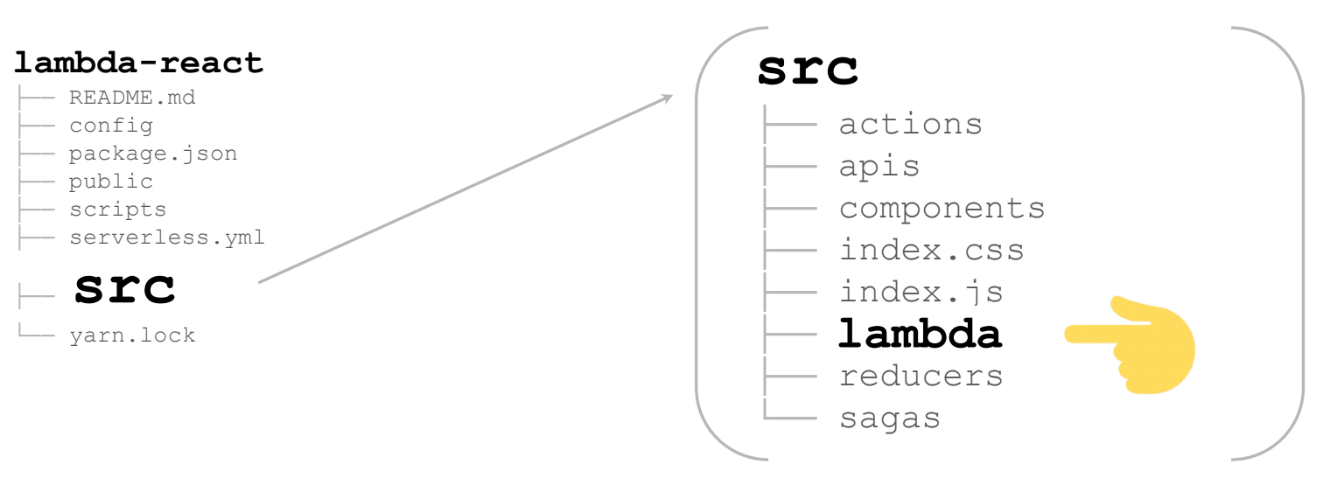
Dies sind 2 Dateien:
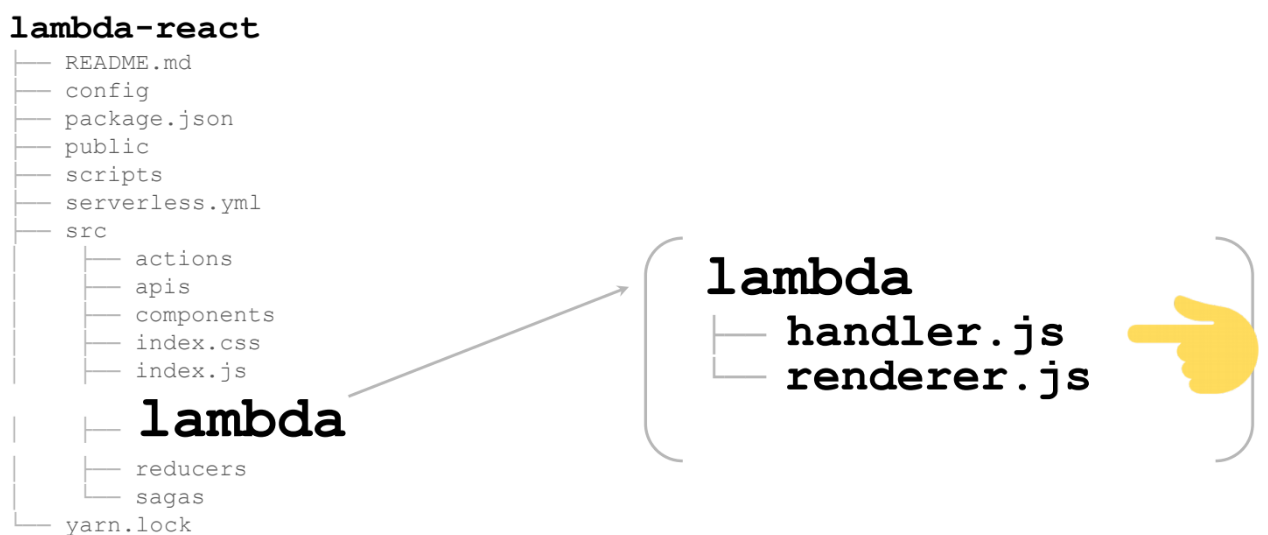
Beginnen wir mit dem Handler. Das wichtigste ist Zeile 13. Dies ist der Renderer, der genau das Lambda ist, das in den Wolken genannt wird:

Wie Sie sehen können, gibt die Funktion
render () ein Versprechen zurück, von dem alle Ausnahmen abgefangen werden müssen. Dies ist die Besonderheit des Lambda, andernfalls endet das Lambda nicht sofort, sondern funktioniert bis zum Timeout. Sie müssen zusätzliches Geld für einen Code bezahlen, der bereits gefallen ist. Um dies zu verhindern, müssen Sie das Lambda so früh wie möglich beenden - zunächst alle Ausnahmen abfangen und behandeln. Wir werden später darauf zurückkommen.
Wenn wir keine Fehler oder Ausnahmen haben, rufen wir die Funktion
createResponse , die buchstäblich fünf Zeilen umfasst. Wir fügen einfach alle Header hinzu, damit sie im Browser korrekt gerendert werden:

Das Interessanteste hier ist die
render , mit der unsere Seite gerendert wird:

Diese Funktion kommt von renderer.js zu uns. Mal sehen, was da ist.
Dort wird eine isomorphe Anwendung gerendert. Darüber hinaus wird es auf jedem Server gerendert - es spielt keine Rolle, ob es sich um Lambda handelt oder nicht.
Ich werde Ihnen nicht im Detail sagen, was eine isomorphe Anwendung ist, wie man sie rendert, da dies ein völlig anderes Thema ist und es Leute gibt, die es besser gesagt haben als ich. Hier sind einige Tutorials, die ich durch Googeln in nur wenigen Minuten gefunden habe:

Wenn Sie andere Berichte kennen, können Sie raten, ich werde auf meinem Twitter Links zu ihnen geben.
Um niemanden zu verlieren, gehe ich einfach nach oben und erzähle, was dort passiert.
Zunächst müssen wir dies mit HTML / React / Redux rendern.
Dies erfolgt über die Standardmethode React -
renderToString :

Als nächstes müssen wir Stile rendern, damit unser Inhalt nicht blinkt. Dies ist keine sehr triviale Aufgabe. Es gibt mehrere npm-Pakete, die das Problem lösen. Zum Beispiel habe ich
node-style-loader , der alles in
styleTag , und dann können Sie es in HTML einfügen.

Wenn es bessere Pakete gibt, liegt es in Ihrem Ermessen.
Als nächstes müssen wir den Redux-Status übergeben. Da Sie auf dem Server rendern, möchten Sie wahrscheinlich einige Daten abrufen, und Sie möchten nicht, dass Redux sie erneut fragt und erneut rendert. Dies ist eine ziemlich normale Aufgabe. Auf der Redux-Hauptwebsite finden Sie Beispiele dazu: Wir erstellen ein Objekt und übergeben es dann über eine globale Variable:

Jetzt etwas näher am Lambda.
Es ist notwendig, eine Fehlerbehandlung durchzuführen. Wir wollen alles fangen und etwas mit ihnen machen, zumindest die Entwicklung von Lambda stoppen. Zum Beispiel habe ich dies durch
promise getan:

Als nächstes müssen wir unsere URLs durch statische Dateien ersetzen. Und dafür müssen wir herausfinden, wo das Lambda läuft - lokal oder irgendwo in den Wolken. Wie finde ich es heraus?
Wir werden dies durch Umgebungsvariablen tun:
…
const bundleUrl = process.env.NODE_ENV === 'AWS' ?
AWS_URL : LOCAL_URL;
Eine interessante Frage: Wie kommen Umgebungsvariablen in einem Lambda zusammen? Eigentlich einfach genug. In yml können Sie beliebige Variablen an die
environment . Wenn es gesperrt ist, sind sie verfügbar:

Nun, ein Bonus - nachdem wir ein Lambda bereitgestellt haben, möchten wir alle statischen Assets bereitstellen. Zu diesem Zweck haben wir bereits ein Plugin geschrieben, in dem Sie den S3-Warenkorb festlegen können, in dem Sie etwas bereitstellen möchten:

Insgesamt haben wir in etwa fünf Minuten eine isomorphe Anwendung durchgeführt, um zu zeigen, dass dies alles einfach ist.
Lassen Sie uns nun ein wenig über die Theorie sprechen - die Vor- und Nachteile von Lambda.
Beginnen wir mit dem Bösen.
Nachteile Lambda-Funktionen
Die Minuspunkte können die Zeit eines Kaltstarts enthalten (oder auch nicht). Für das Lambda auf Node.js, das wir gerade schreiben, bedeutet die Kaltstartzeit beispielsweise nicht viel.
Die folgende Grafik zeigt die Kaltstartzeit. Dies kann eine große Sache sein, insbesondere für Java und C # (achten Sie auf die orangefarbenen Punkte). Sie möchten nicht, dass die Ausführung des Codes nur fünf bis sechs Sekunden dauert.
Für Node.js beträgt die Startzeit fast Null - 30 - 50 ms. Für einige kann dies natürlich auch ein Problem sein. Die Funktionen können jedoch aufgewärmt werden (obwohl dies nicht das Thema dieses Berichts ist). Wenn jemand daran interessiert ist, wie diese Tests durchgeführt wurden, willkommen bei acloud.guru, wird er Ihnen alles erzählen (
im Artikel ).

Was sind die Nachteile?
Größenbeschränkungen des Funktionscodes
Der Code muss kleiner als 50 MB sein. Ist es möglich, eine so große Funktion zu schreiben? Bitte vergessen Sie nicht node_modules. Wenn Sie etwas verbinden, insbesondere wenn dort Binärdateien vorhanden sind, können Sie selbst bei Zip-Dateien problemlos über 50 MB übertragen. Ich habe solche Fälle gehabt. Dies ist jedoch ein zusätzlicher Grund, um zu sehen, was Sie mit node_modules verbinden.
Laufzeitbeschränkungen
Standardmäßig wird die Funktion für eine Sekunde ausgeführt. Wenn es nicht nach einer Sekunde endet, haben Sie eine Zeitüberschreitung. Diese Zeit kann jedoch in den Einstellungen erhöht werden. Beim Erstellen einer Funktion können Sie den Wert auf fünf Minuten einstellen. Fünf Minuten sind eine harte Frist. Dies ist kein Problem für die Website. Wenn Sie jedoch etwas Interessanteres an Lambdas tun möchten, z. B. Bilder verarbeiten, Text in Ton oder Ton in Text konvertieren usw., können solche Berechnungen leicht mehr als fünf Minuten dauern. Und das wird ein Problem sein. Was tun? Lambda optimieren oder nicht verwenden.
Eine weitere interessante Sache, die sich im Zusammenhang mit der Frist für die Ausführung von Lambda ergibt. Erinnern Sie sich an das Layout unserer Website. Alles funktionierte perfekt, bis das Produkt kam und auf der Website Echtzeit-Feeds wünschte - um Nachrichten in Echtzeit anzuzeigen. Wir wissen, dass dies mit WebSockets implementiert wird. WebSockets funktionieren jedoch fünf Minuten lang nicht. Sie müssen länger aufbewahrt werden. Und hier wird das Fünf-Minuten-Limit zum Problem.

Eine kleine Bemerkung. Für AWS ist dies kein Problem mehr. Sie fanden heraus, wie sie das umgehen konnten. Aber im Allgemeinen ist Lambda keine Lösung für Sie, sobald Web-Sockets erscheinen. Sie müssen wieder zu den guten alten Servern wechseln.
Die Anzahl der parallelen Funktionen pro Minute
Oben ist ein Limit von 500 bis 3.000, abhängig von der Region, in der Sie sich befinden. Meiner Meinung nach werden in Europa fast 500. 3000 in den USA unterstützt.
Wenn Sie eine ausgelastete Site haben und mehr als dreitausend Anfragen pro Minute erwarten (was leicht vorstellbar ist), wird dies zu einem Problem. Aber bevor wir über dieses Minus sprechen, lassen Sie uns ein wenig darüber sprechen, wie Lambda skaliert.
Eine Anfrage kommt zu uns und wir bekommen ein Lambda. Während dieses Lambda ausgeführt wird, kommen zwei weitere Anfragen zu uns - wir starten zwei weitere Lambdas. Die Leute kommen auf unsere Seite, Anfragen erscheinen und Lambdas werden immer mehr gestartet.

Dabei zahlen Sie für die Zeit, in der das Lambda läuft. Angenommen, Sie zahlen einen Cent für eine Sekunde Lambda-Ausführung. Wenn Sie 10 Lambdas pro Sekunde haben, zahlen Sie 10 Cent für diese Sekunde. Wenn Sie eine Million Lambdas pro Sekunde haben, sind das ungefähr 10 Tausend Dollar. Unangenehme Figur.
Aus diesem Grund hat AWS entschieden, dass Ihre Brieftasche nicht in einer Sekunde geleert werden soll, wenn Sie Ihre Tests falsch durchgeführt haben und DDOS selbst gestartet haben, was zu Lambdas geführt hat, oder wenn jemand anderes gekommen ist, um DDOS auszuführen. Daher wurde ein Limit von dreitausend festgelegt, damit Sie die Möglichkeit haben, auf die Situation zu reagieren.
Wenn Sie regelmäßig 3000 Anforderungen laden, können Sie in AWS schreiben, wodurch das Limit erhöht wird.
Staatenlos
Dies ist wieder das letzte umstrittene Minus.
Was ist staatenlos? Hier kommt ein Witz über Goldfische auf - sie halten einfach nicht den Kontext:

Das Lambda, das zum zweiten Mal angerufen wird, weiß nichts über den ersten Anruf.
Lassen Sie mich Ihnen ein Beispiel zeigen. Nehmen wir an, ich habe ein System - eine große Black Box. Und dieses System kann unter anderem SMS senden.
Der Benutzer kommt und sagt: SMS-Vorlage Nummer 1 senden. Und das System sendet sie an ein reales Gerät.
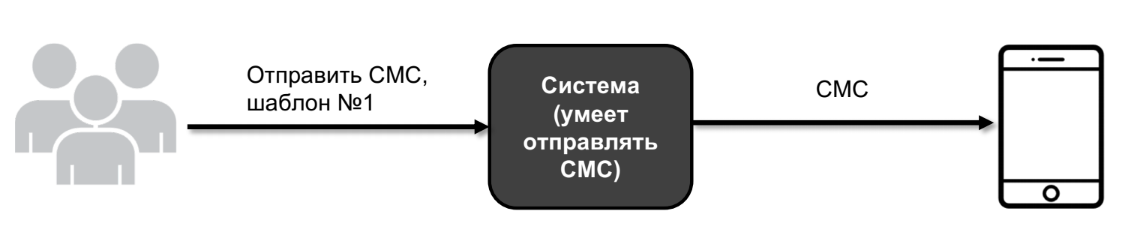
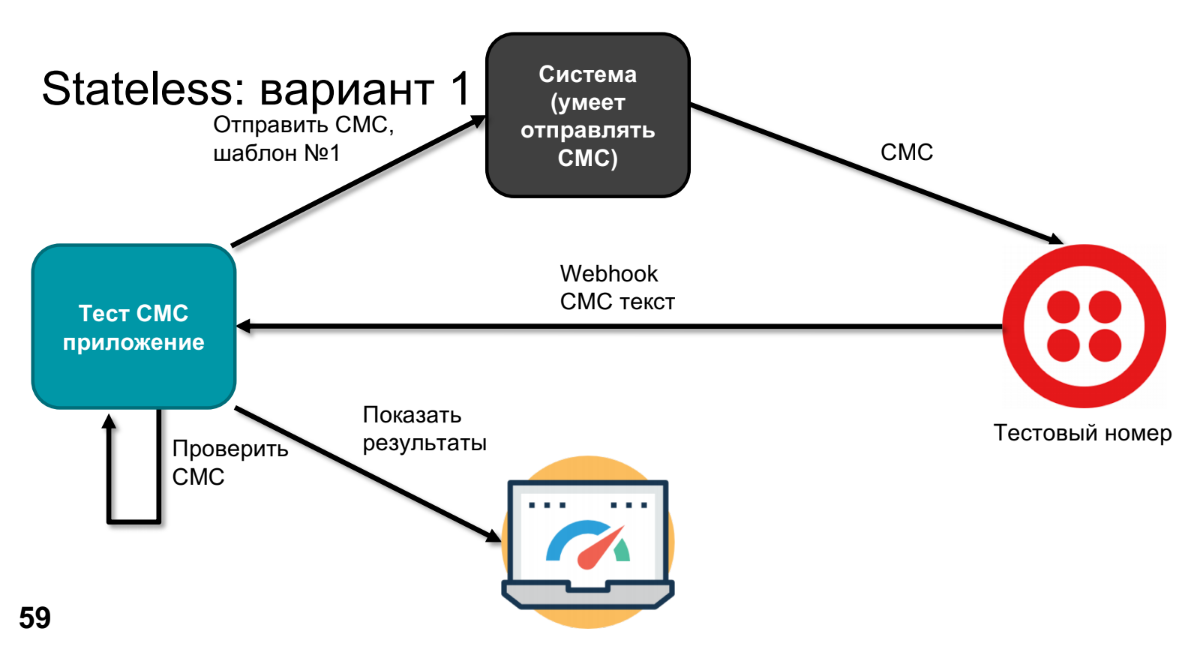
Irgendwann drückt das Produkt den Wunsch aus, herauszufinden, was dort hingehen wird, und zu überprüfen, ob in diesem System nirgendwo etwas kaputt gegangen ist. Dazu ersetzen wir das reale Gerät durch eine Testnummer - beispielsweise kann Twilio dies tun. Er wird Webhook anrufen, den SMS-Text senden, wir werden diesen SMS-Text in der Anwendung verarbeiten (wir müssen überprüfen, ob unsere Vorlage die richtige SMS geworden ist).
Um dies zu überprüfen, müssen wir wissen, was gesendet wurde - wir werden dies über eine Testanwendung tun. Es bleibt zu vergleichen und die Ergebnisse anzuzeigen.
Versuchen wir, dasselbe mit Lambda zu tun.
Lambda wird SMS senden, SMS wird zu Twilio kommen.
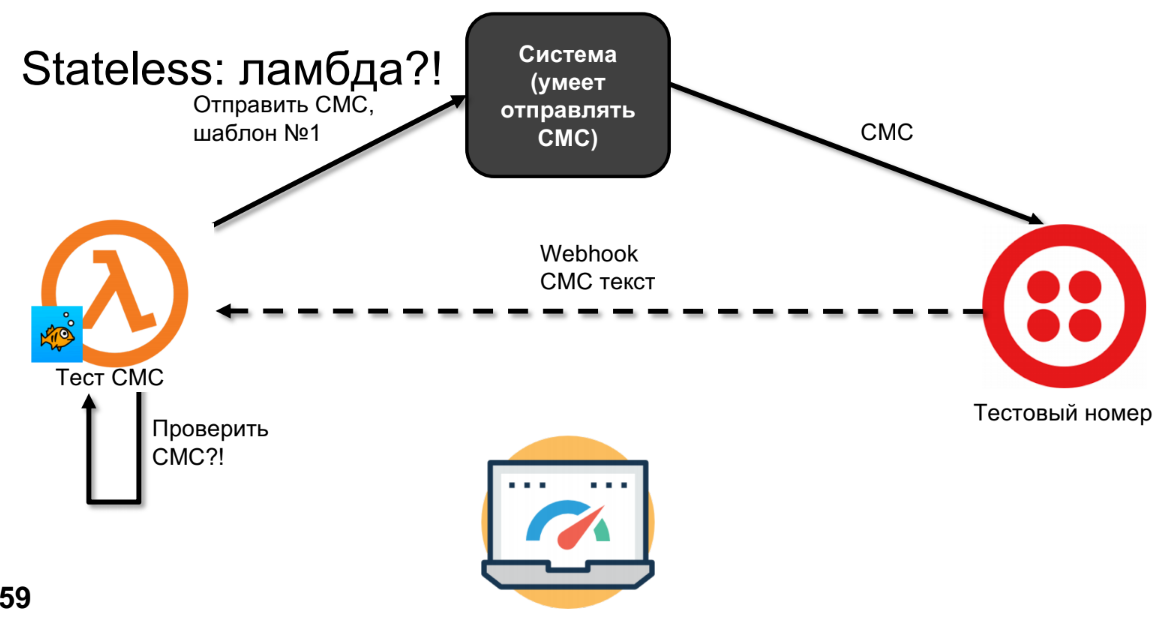
Ich habe die gestrichelte Linie nicht zufällig gezogen, da SMS in Minuten, Stunden oder Tagen zurückgehen können - dies hängt von Ihrem Netzbetreiber ab, dh, dies ist kein synchroner Anruf. Zu diesem Zeitpunkt wird das Lambda alles vergessen und wir können keine SMS mehr abrufen.
Ich würde sagen, dass dies kein Minus ist, sondern ein Feature. Das Schema kann wiederholt werden. Es gibt verschiedene Möglichkeiten, dies zu tun, ich werde meine eigenen anbieten. Wenn wir zustandslos sind und etwas speichern möchten, müssen wir definitiv Speicher verwenden, zum Beispiel eine Datenbank, S3, aber alles, was unseren Kontext speichert.
Im Schema mit dem SMS-Speicher wird es an die Testnummer gesendet. Und wenn Webhook es aufruft - ich schlage vor, zum Beispiel das zweite Lambda aufzurufen, da dies eine etwas andere Funktion ist. Und das zweite Lambda kann bereits das SMS-ku, das aus der Datenbank stammt, abholen, überprüfen und die Ergebnisse anzeigen.

Bingo!
, , . , node.js express-. , . , , , — . ?
, , . — . , -, . , , . , , AWS , . AWS , , . . -, node , Java 12-15 . , , . - node cache — .. — , . , , . .
-
, .
- , . , javascript, . , javascript-, .
- , , . , , . , .
- AWS- — (DynamoDB, Alexa, API Gateway, . .).
?
— , , REST API. , , .
, , … .
- HTTP Services — . REST API, API endpoint — . . , enterprise node.js middleware. java, , js , . .
- IoT — , Alexa - -, , .
- Chat Bots — , IoT.
- Image/Video conversions.
- Machine learning.
- Batch Jobs — - , Batch Job .
Amazon, Google, Azure, IBM, Twillio — cloud functions. , . open source ( , open source — ). open source . . — Docker Swarm, Kubernetes — .
, , -, . AWS , open source .
. . : :
- Iron functions
- Fnproject
- Openfaas
- Apache OpenWhisk
- Kubeless
- Fission
- Funktion
Fnproject , Fnproject Kubernetes-.
. API Gateway (, ), URL, . , , , Kubernetes, .
. HolyJS 2018 Moscow, 24-25 . , Early Bird-.