
Neue Sprache in Data Science. Julia ist eine eher seltene Sprache in Russland, obwohl sie seit 5 Jahren im Ausland verwendet wird (sie haben mich auch überrascht). Da es keine Quellen auf Russisch gibt, habe ich mich entschlossen, auf Julia hinzuweisen, die einem wunderbaren Buch entnommen ist. Der beste Weg, eine Sprache zu lernen, besteht darin, etwas darin zu schreiben.
Verwenden Sie maschinelles Lernen, um auch Aufmerksamkeit zu erregen.Hallo habrozhitelam.
Vor einiger Zeit begann ich die neue Sprache von Julia zu lernen. Nun, wie neu. Dies ist etwas zwischen Matlab und Python, die Syntax ist sehr ähnlich und die Sprache selbst ist in C / C ++ geschrieben. Im Allgemeinen ist die Geschichte der Schöpfung, was, warum und warum auf Wikipedia und in einigen Artikeln über Habré.
Das erste, was mein Studium der Sprache begann - richtig, Google auf Coursera Google
Online-Kurs in Englisch. Dort wird parallel zur Basissyntax + ein Miniprojekt zur Vorhersage von Krankheiten in Afrika geschrieben. Grundlagen und sofort üben. Wenn Sie ein Zertifikat benötigen, kaufen Sie die Vollversion. Ich ging kostenlos. Der Unterschied zwischen dieser Version besteht darin, dass niemand Ihre Tests und DZ überprüft. Es war mir wichtiger, mich kennenzulernen als ein Zertifikat. (Lesen Sie gestaute 50 Dollar)
Danach beschloss ich, ein Buch über Julia zu lesen. Google hat eine Liste mit Büchern herausgegeben und Rezensionen und Rezensionen weiter untersucht, eines davon ausgewählt und bei Amazon bestellt. Buchversionen sind immer besser zu lesen und mit Bleistift zu zeichnen.
Das Buch heißt
Julia for Data Science von Zacharias Voulgaris, PhD. Der Auszug, den ich präsentieren möchte, enthält viele Tippfehler in dem Code, den ich korrigiert habe, und zeigt daher die Arbeitsversion + meine Ergebnisse.
kNN
Dies ist ein Beispiel für die Anwendung des Klassifizierungsalgorithmus für die Methode der nächsten Nachbarn. Wahrscheinlich einer der ältesten Algorithmen für maschinelles Lernen. Der Algorithmus hat keine Lernphase und ist ziemlich schnell. Die Bedeutung ist recht einfach: Um ein neues Objekt zu klassifizieren, müssen Sie ähnliche "Nachbarn" aus dem Datensatz (Datenbank) finden und dann die Klasse durch Abstimmung bestimmen.
Ich werde sofort reservieren, dass Julia fertige Pakete hat, und es ist besser, sie zu verwenden, um Zeit zu sparen und Fehler zu reduzieren. Aber dieser Code ist in gewisser Weise ein Hinweis auf die Julia-Syntax. Es ist für mich bequemer, eine neue Sprache anhand von Beispielen zu lernen, als trockene Auszüge der allgemeinen Form einer Funktion zu lesen.
Also, was wir am Eingang haben:
Trainingsdaten X (Trainingsmuster),
Trainingsdatenetiketten x (entsprechende Etiketten), Testdaten
Y (Testauswahl),
Anzahl der Nachbarn k (Anzahl der Nachbarn).
Sie benötigen 3 Funktionen:
Entfernungsberechnungsfunktion, Klassifizierungsfunktion und
Hauptfunktion .
Die Quintessenz lautet: Nehmen Sie ein Element des Testarrays und berechnen Sie den Abstand zu den Elementen des Trainingsarrays. Dann wählen wir die Indizes der
k Elemente aus, die sich als so nah wie möglich herausstellten. Wir ordnen das zu testende Element der Klasse zu, die unter
k nächsten Nachbarn am häufigsten vorkommt.
function CalculateDistance{T<:Number}(x::Array{T,1}, y::Array{T,1}) dist = 0 for i in 1:length(x) dist += (x[i] - y[i])^2 end dist = sqrt(dist) return dist end
Die Hauptfunktion des Algorithmus. Die Matrix der Abstände zwischen den Objekten der Trainings- und Testmuster, die Beschriftungen des Trainingssatzes und die Anzahl der nächsten "Nachbarn" kommen zur Eingabe. Die Ausgabe sind die vorhergesagten Beschriftungen für neue Objekte und die Wahrscheinlichkeiten jeder Beschriftung.
function Classify{T<:Any}(distances::Array{Float64,1}, labels::Array{T,1}, k::Int) class = unique(labels) nc = length(class) #number of classes indexes = Array(Int,k) #initialize vector of indexes of the nearest neighbors M = typemax(typeof(distances[1])) #the largest possible number that this vector can have class_count = zeros(Int, nc) for i in 1:k indexes[i] = indmin(distances) #returns index of the minimum element in a collection distances[indexes[i]] = M #make sure this element is not selected again end klabels = labels[indexes] for i in 1:nc for j in 1:k if klabels[j] == class[i] class_count[i] +=1 end end end m, index = findmax(class_count) conf = m/k #confidence of prediction return class[index], conf end
Und natürlich alle Funktionen.
Wir haben einen Trainingssatz
X am Eingang, Trainingssatzmarkierungen
x , Testsatz
Y und die Anzahl der „Nachbarn“
k .
Am Ausgang erhalten wir die vorhergesagten Etiketten und die entsprechenden Wahrscheinlichkeiten für die Vergabe jeder Klasse.
function main{T1<:Number, T2<:Any}(X::Array{T1,2}, x::Array{T2,1}, Y::Array{T1,2}, k::Int) N = size(X,1) n = size(Y,1) D = Array(Float64,N) #initialize distance matrix z = Array(eltype(x),n) #initialize labels vector c = Array(Float64, n) #confidence of prediction for i in 1:n for j in 1:N D[j] = CalculateDistance(X[j,:], vec(Y[i,:])) end z[i], c[i] = Classify(D,x,k) end return z, c end
Testen
Testen wir, was wir haben. Der Einfachheit halber speichern wir den Algorithmus in der Datei kNN.jl.
Die Basis stammt aus dem
Open Machine Learning Course . Der Datensatz heißt Samsung Human Activity Recognition. Die Daten stammen von den Beschleunigungsmessern und Gyroskopen von Samsung Galaxy S3-Mobiltelefonen, und die Art der Aktivität einer Person mit einem Telefon in der Tasche ist ebenfalls bekannt - ob sie die Treppe ging, stand, lag, saß oder ging. Wir werden das Problem der genauen Bestimmung der Art der körperlichen Aktivität als Klassifizierungsproblem lösen.
Tags entsprechen den folgenden:
1 - zu Fuß
2 - die Treppe hinaufsteigen
3 - die Treppe hinunter
4 - Sitz
5 - Zu dieser Zeit stand eine Person
6 - die Person hat gelogen
include("kNN.jl") training = readdlm("samsung_train.txt"); training_label = readdlm("samsung_train_labels.txt"); testing = readdlm("samsung_test.txt"); testing_label = readdlm("samsung_test_labels.txt"); training_label = map(Int, training_label) testing_label = map(Int, testing_label) z = main(training, vec(training_label), testing, 7) n = length(testing_label) println(sum(testing_label .== z[1]) / n)
Ergebnis: 0,9053274516457415Die Qualität wird anhand des Verhältnisses korrekt vorhergesagter Objekte zur gesamten Testprobe bewertet. Es scheint nicht so schlimm zu sein. Aber mein Ziel ist es eher, Julia zu zeigen, dass er einen Platz in Data Science hat.
Visualisierung
Als nächstes wollte ich versuchen, die Klassifizierungsergebnisse zu visualisieren. Dazu müssen Sie ein zweidimensionales Bild mit 561 Zeichen erstellen und nicht wissen, welche davon die wichtigsten sind. Um die Dimensionalität und das anschließende Daten-Design im orthogonalen Unterraum von Merkmalen zu verringern, wurde daher die Verwendung der
Hauptkomponentenanalyse (PCA) beschlossen. In Julia wie in Python gibt es fertige Pakete, so dass wir unser Leben ein wenig vereinfachen.
using MultivariateStats #for PCA A = testing[1:10,:] #PCA for A M_A = fit(PCA, A'; maxoutdim = 2) Jtr_A = transform(M_A, A'); #PCA for training M = fit(PCA, training'; maxoutdim = 2) Jtr = transform(M, training'); using Gadfly #shows training points and uncertain point pl1 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:], Geom.point)) #predicted values for uncertain points from testing data z1 = main(training, vec(training_label), A, 7) pl2 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:],color = z[1], Geom.point)) vstack(pl1, pl2)
In der ersten Abbildung sind der Trainingssatz und mehrere Objekte aus dem Testsatz markiert, die ihrer Klasse zugeordnet werden müssen. Dementsprechend zeigt die zweite Figur, dass diese Objekte markiert wurden.

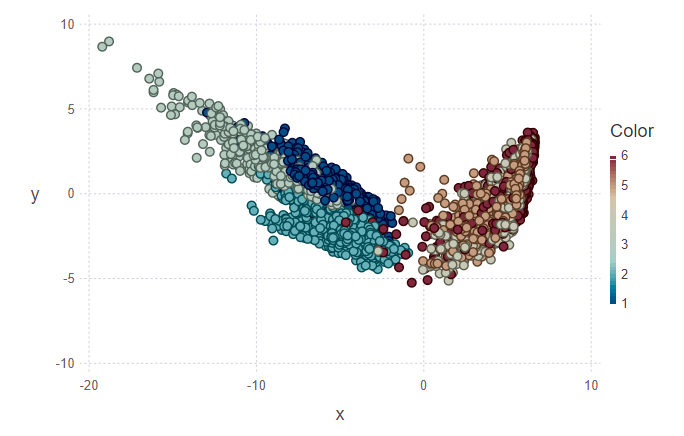
println(z[1][1:10], z[2][1:10]) > [5, 5, 5, 5, 5, 5, 5, 5, 5, 4][1.0, 0.888889, 0.888889, 0.888889, 1.0, 1.0, 1.0, 1.0, 0.777778, 0.555556]
Wenn ich mir die Bilder anschaue, möchte ich die Frage stellen, warum solche Cluster hässlich sind. Ich werde es erklären. Einzelne Cluster sind aufgrund der Art der Daten und der Verwendung von PCA nicht sehr klar abgegrenzt. Für die PCA ist das Gehen und Treppensteigen wie eine Klasse - die Bewegungsklasse. Dementsprechend ist die zweite Klasse die Ruheklasse (Sitzen, Stehen, Liegen, die untereinander nicht sehr unterscheidbar sind). Daher kann eine klare Trennung in zwei statt in sechs Klassen verfolgt werden.
Fazit
Für mich ist dies nur ein erstes Eintauchen in Julia und die Verwendung dieser Sprache beim maschinellen Lernen. Übrigens, in dem ich eher ein Amateur als ein Profi bin. Aber während ich interessiert bin, werde ich diese Angelegenheit weiter vertiefen. Viele ausländische Quellen setzen auf Julia. Nun, abwarten und sehen.
PS: Wenn es interessant ist, kann ich Ihnen in den folgenden Beiträgen über die Funktionen der Syntax, über die IDE, mit deren Installation ich Probleme hatte, berichten.