Sehr oft werden wir gefragt, warum wir keine Wettbewerbe für Datenwissenschaftler veranstalten. Tatsache ist, dass wir aus Erfahrung wissen, dass die darin enthaltenen Lösungen für Produkte überhaupt nicht anwendbar sind. Ja, und diejenigen einzustellen, die an den führenden Orten sein werden, ist nicht immer sinnvoll.
Solche Wettbewerbe werden oft mit Hilfe des sogenannten chinesischen Stapelns gewonnen, wenn alle möglichen Algorithmen und Hyperparameterwerte auf kombinatorische Weise erfasst werden und die resultierenden Modelle auf mehreren Ebenen ein Signal voneinander verwenden. Die üblichen Satelliten dieser Lösungen sind Komplexität, Instabilität, Schwierigkeiten beim Debuggen und Support, ein sehr hoher Ressourcenverbrauch beim Training und Prognosen sowie die Notwendigkeit einer sorgfältigen menschlichen Überwachung in jedem Zyklus des wiederholten Trainings von Modellen. Es ist sinnvoll, dies nur bei Wettbewerben zu tun - um der Zehntausendstel der lokalen Kennzahlen und Positionen in der Gesamtwertung willen.
Aber wir haben es versucht
Vor ungefähr einem Jahr haben wir uns entschlossen, das Stapeln in der Produktion zu verwenden. Es ist bekannt, dass lineare Modelle es ermöglichen, trotz der großen Dimension solcher Vektoren ein nützliches Signal aus Texten zu extrahieren, die als Wortsack dargestellt und mit tf-idf vektorisiert sind. Unser System hat bereits eine solche Vektorisierung durchgeführt, daher war es für uns nicht sehr schwierig, Vektoren für Lebensläufe und offene Stellen zu kombinieren und auf dieser Grundlage die logistische Regression zu lehren, so dass die Wahrscheinlichkeit vorhergesagt wird, dass ein Kandidat mit einem bestimmten Lebenslauf für eine bestimmte freie Stelle klickt.
Diese Prognose wird dann von den Hauptmodellen als zusätzliches Merkmal verwendet, da das Modell ein Metaattribut berücksichtigt. Das Schöne ist, dass selbst mit ROC AUC 0.7 das Signal von solchen Metaattributmodellen nützlich ist. Die Implementierung ergab ungefähr zweitausend Antworten pro Tag. Und vor allem haben wir erkannt, dass wir weitermachen können.
Das lineare Modell berücksichtigt nichtlineare Wechselwirkungen zwischen Merkmalen nicht. Beispielsweise kann nicht berücksichtigt werden, dass die Wahrscheinlichkeit einer Antwort sehr hoch wird, wenn sich im Lebenslauf ein „C“ und in der Vakanz ein „Systemprogrammierer“ befindet. Neben der Vakanz und dem Lebenslauf gibt es neben dem Text viele numerische und kategoriale Felder, und im Lebenslauf ist der Text in viele separate Blöcke unterteilt. Aus diesem Grund haben wir beschlossen, eine quadratische Erweiterung von Merkmalen für lineare Modelle hinzuzufügen und alle möglichen Kombinationen von tf-idf-Vektoren aus Feldern und Blöcken zu sortieren.
Wir haben Meta-Zeichen ausprobiert, die die Wahrscheinlichkeit einer Reaktion unter verschiedenen Bedingungen vorhersagen:
- In der Stellenbeschreibung gibt es eine Reihe von Begriffen und Kategorien.
- Im Textfeld der offenen Stelle und im Textfeld des Lebenslaufs werden bestimmte Begriffe gefunden.
- Im Textfeld der Stelle gab es eine Reihe von Begriffen, die im Textfeld des Lebenslaufs nicht übereinstimmten.
- bestimmte Begriffe erschienen in der Vakanz, der festgelegte Kategoriewert wurde im Lebenslauf erfüllt;
- Bei offenen Stellen und Lebensläufen wurde ein bestimmtes Paar von Kategoriewerten erfüllt.
Anschließend wählten sie mithilfe der Funktionsauswahl mehrere Dutzend Metaattribute aus, die maximale Wirkung zeigten, führten A / B-Tests durch und gaben sie für die Produktion frei.
Infolgedessen erhielten wir mehr als 23.000 neue Antworten pro Tag. Einige der Attribute haben die höchsten Attribute in der Stärke eingegeben.
In einem Empfehlungssystem sind beispielsweise die Hauptattribute
In einem logistischen Regressionsmodell werden geeignete Lebensläufe gefiltert:- geografische Region aus dem Lebenslauf;
- Berufsfeld aus dem Lebenslauf;
- der Unterschied zwischen Stellenbeschreibungen und jüngsten Berufserfahrungen;
- Unterschied der geografischen Regionen bei offenen Stellen und Lebensläufen;
- die Differenz zwischen dem Titel der offenen Stelle und dem Titel des Lebenslaufs;
- der Unterschied zwischen Spezialisierungen in offenen Stellen und in Lebensläufen;
- die Wahrscheinlichkeit, dass der Bewerber mit einem bestimmten Gehalt in einem Lebenslauf auf eine Stelle mit einem bestimmten Gehalt klickt (Meta-Zeichen für eine logistische Regression);
- die Wahrscheinlichkeit, dass eine Person mit einem bestimmten Namen des Lebenslaufs auf Stellen mit einer bestimmten Berufserfahrung klickt (Meta-Sign bei logistischer Regression);
In einem XGBoost-Modell werden relevante Lebensläufe gefiltert:- Wie ähnlich sind die offenen Stellen und Lebensläufe im Text?
- die Differenz zwischen dem Namen der offenen Stelle und dem Namen des Lebenslaufs und allen Positionen in der Erfahrung im Lebenslauf unter Berücksichtigung von Textinteraktionen;
- die Differenz zwischen dem Titel der offenen Stelle und dem Titel im Lebenslauf unter Berücksichtigung von Textinteraktionen;
- die Differenz zwischen dem Namen der offenen Stelle und dem Namen des Lebenslaufs und allen Positionen in der Erfahrung des Lebenslaufs, ohne Berücksichtigung von Textinteraktionen;
- die Wahrscheinlichkeit, dass ein Kandidat mit der angegebenen Berufserfahrung eine Stelle mit diesem Namen besetzt (Meta-Sign bei logistischer Regression);
- der Unterschied zwischen der Stellenbeschreibung und der vorherigen Berufserfahrung im Lebenslauf;
- Wie sehr unterscheiden sich die Vakanz und der Lebenslauf im Text?
- der Unterschied zwischen der Stellenbeschreibung und der vorherigen Berufserfahrung im Lebenslauf;
- die Wahrscheinlichkeit, dass eine Person eines bestimmten Geschlechts auf eine Stelle mit einem bestimmten Namen reagiert (ein Metazeichen für die logistische Regression).
im Ranking-Modell auf XGBoost:- die Wahrscheinlichkeit einer Antwort durch Begriffe, die im Namen der offenen Stelle enthalten sind und nicht im Titel und an der Position des Lebenslaufs enthalten sind (Meta-Sign bei logistischer Regression);
- Match Region von Vakanz und Lebenslauf
- die Wahrscheinlichkeit einer Antwort durch Begriffe, die in der Vakanz vorhanden sind und nicht im Lebenslauf enthalten sind (Meta-Sign zur logistischen Regression);
- vorhergesagte Attraktivität des Stellenangebots für den Nutzer (Meta-Tag auf ALS);
- die Wahrscheinlichkeit einer Antwort durch die Begriffe, die in der Vakanz vorhanden sind und wieder aufgenommen werden (Metazeichen auf der logistischen Regression);
- die Entfernung zwischen dem Namen der offenen Stelle und dem Titel + der Position vom Lebenslauf, wobei die Begriffe durch Benutzeraktionen gewichtet werden (Interaktion);
- Abstand zwischen Spezialisierungen von Stellenangebot und Lebenslauf;
- die Entfernung zwischen dem Titel der offenen Stelle und dem Namen des Lebenslaufs, wobei die Begriffe durch Benutzeraktionen gewichtet werden (Interaktion);
- die Wahrscheinlichkeit einer Antwort auf die Interaktion von tf-idf aus einer Vakanz und Spezialisierung aus einem Lebenslauf (Meta-Sign auf logistische Regression);
- Abstand zwischen Stellenangeboten und Lebenslauftexten;
- DSSM mit dem Namen der offenen Stelle und dem Namen des Lebenslaufs (Metaattribut im neuronalen Netzwerk).
Ein gutes Ergebnis zeigt, dass Sie aus dieser Richtung immer noch eine bestimmte Anzahl von Antworten und Einladungen pro Tag bei gleichen Marketingkosten extrahieren können.
Beispielsweise ist bekannt, dass eine logistische Regression bei einer großen Anzahl von Zeichen die Wahrscheinlichkeit einer Umschulung erhöht.
Verwenden wir für die Texte von Lebensläufen und offenen Stellen tf-idf vectorizer mit einem Wörterbuch von 10 Tausend Wörtern und Phrasen. Im Falle einer quadratischen Erweiterung in unserer logistischen Regression gibt es dann 2 * 10 000 + 10 000² Gewichte. Es ist klar, dass bei einer solchen Spärlichkeit sogar Einzelfälle jedes einzelne Gewicht erheblich beeinflussen können. "Im Lebenslauf gab es ein seltenes Wort so und so - in einer offenen Stelle so und so hat der Benutzer geklickt."
Daher versuchen wir jetzt, Metazeichen für die logistische Regression zu erstellen, bei denen die quadratischen Expansionskoeffizienten mithilfe von Faktorisierungsmaschinen komprimiert werden. Unsere 10.000 m² Gewichte werden als Matrix latenter Vektoren mit einer Dimension von beispielsweise 10.000 x 150 dargestellt (wobei wir die Dimension eines latenten Vektors von 150 gewählt haben). Gleichzeitig spielen einzelne Fälle während der Komprimierung keine große Rolle mehr, und das Modell beginnt, allgemeinere Muster besser zu berücksichtigen, anstatt sich an bestimmte Fälle zu erinnern.
Wir verwenden auch Metaattribute in den DSSM-Neuronalen Netzen, über die wir bereits
geschrieben haben , und in ALS, über die wir ebenfalls
geschrieben haben , jedoch auf vereinfachte Weise. Insgesamt hat uns (und unseren Kunden) durch die Einführung von Meta-Attributen bisher mehr als 44.000 zusätzliche Antworten (Leads) auf offene Stellen pro Tag gegeben.
Infolgedessen sieht das vereinfachte Modellstapelschema in Jobempfehlungen für Lebensläufe jetzt folgendermaßen aus:
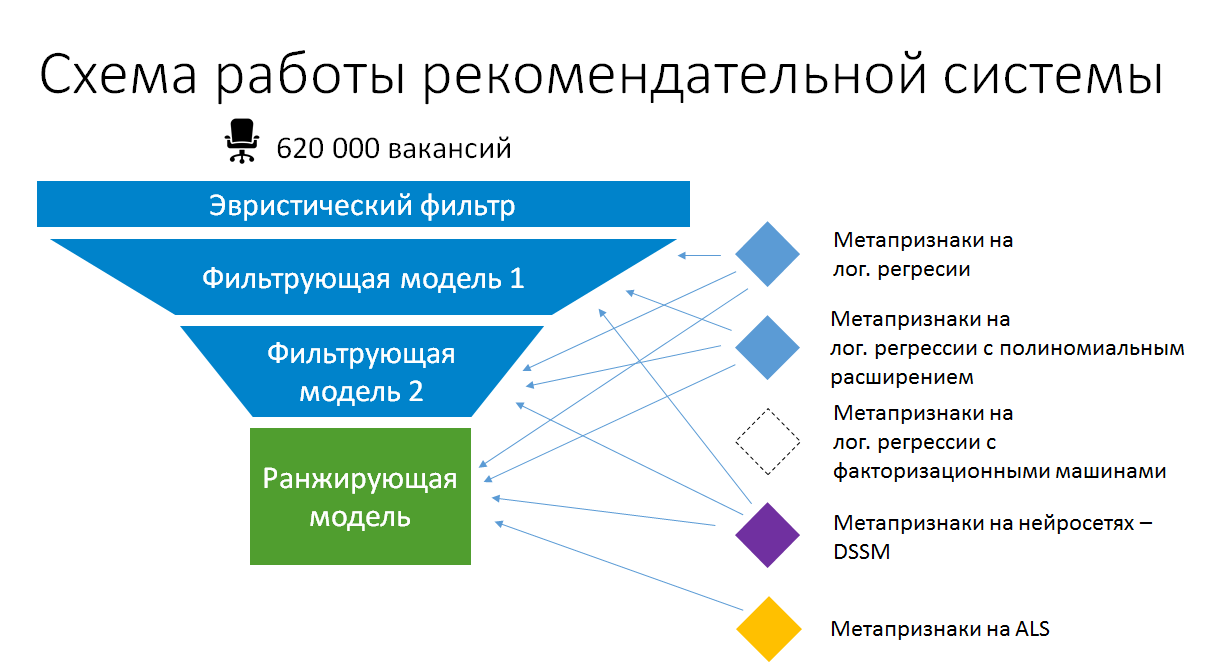
Das Stapeln in der Produktion ist also sinnvoll. Dies ist jedoch nicht das automatische kombinatorische Stapeln. Wir stellen sicher, dass die Modelle, auf deren Grundlage Metaattribute erstellt werden, einfach bleiben und vorhandene Daten und berechnete statische Attribute maximal nutzen. Nur so können sie in der Produktion bleiben, ohne sich allmählich in eine nicht unterstützte Black Box zu verwandeln, und in einem Zustand bleiben, in dem sie umgeschult und verbessert werden können.