
Basierend auf den Ergebnissen zahlreicher betrieblicher Bewertungen von Rechenzentren auf der ganzen Welt stellte das Uptime Institute fest, dass der Personalbestand in Rechenzentren von Ort zu Ort sehr unterschiedlich ist. Diese Beobachtung ist etwas rätselhaft, aber nicht überraschend. Während die Personalausstattung eine wichtige Aktivität für Rechenzentren ist, die versuchen, die operative Exzellenz aufrechtzuerhalten, beeinflussen viele andere Faktoren die Entscheidungen der Unternehmen über den erforderlichen Personalbestand.
Unter den Faktoren, die sich auf den gesamten Personalbestand auswirken können, können die Komplexität des Rechenzentrums, die Fluktuation, die Anzahl der erforderlichen Arbeitszeiten für den technischen Support, die Anzahl der Verträge mit Auftragnehmern und die Geschäftsziele der Barrierefreiheit herausgearbeitet werden. Die Kosten sind ebenfalls problematisch, da jeder Mitarbeiter direkte Kosten für das Rechenzentrum verursacht. Aufgrund dieser vielen Faktoren ist es erforderlich, den Personalbestand von Rechenzentren ständig zu überprüfen, um eine effektive Unterstützung zu einem angemessenen Preis zu bieten.
Das Uptime Institute stellt häufig die Frage: "Wie hoch ist der Personalbestand für mein Rechenzentrum?" Leider gibt es keine präzise Antwort, die für jedes Rechenzentrum universell wäre. Die richtige Besetzung hängt von einer Reihe von Variablen ab.
Die Zeit, die erforderlich ist, um Wartungsaufgaben zu erledigen und sicherzustellen, dass die Schichten des technischen Supports abgeschlossen sind, sind zwei Hauptvariablen. Die Personalausstattung zur Erfüllung der Wartungsanforderungen ist ein relativ fester Faktor, hängt jedoch davon ab, welche Maßnahmen das Personal des Rechenzentrums ausführt und welche Funktionen den Auftragnehmern zugewiesen sind. Das Verschieben von Schichten des technischen Supports ist definiert als Personal zur Überwachung eines Rechenzentrums und zur Reaktion auf Vorfälle und Ereignisse. Die Besetzung der Schicht für technischen Support kann auf verschiedene Arten festgelegt werden. Jede Personalmethode hat potenzielle Auswirkungen auf den Betrieb, je nachdem, welche Prozesse vom technischen Support abgedeckt werden.
Trends verschieben
Das Hauptziel der ständigen Anwesenheit von qualifiziertem Personal besteht darin, das Risiko von Ausfällen aufgrund abnormaler Ereignisse zu minimieren, indem ein Vorfall verhindert, verhindert oder isoliert sowie seine Ausbreitung oder Auswirkung auf andere Systeme verhindert wird. In vielen Rechenzentren ist weiterhin ständig ein Team von qualifizierten Elektrikern, Maschinenbauingenieuren und anderen Technikern anwesend, die einen 24-Stunden-Betriebsmodus bereitstellen. Fernüberwachungstechnologien, die spezielle Anordnung von Gebäuden in Form eines Komplexes, der Wunsch nach Kostenausgleich und andere Gründe können Unternehmen jedoch dazu veranlassen, Mitarbeiter auf unterschiedliche Weise einzustellen.
Die Verwaltung eines Regimes für technischen Support ohne qualifiziertes Personal kann das Risiko aufgrund einer verzögerten Reaktion auf abnormale Vorfälle erhöhen. Letztendlich muss das Unternehmen eine Entscheidung mit einem akzeptablen Risiko treffen.
Weitere Modelle für den technischen Support mit vollständiger Abdeckung sind:
- Schulung des Sicherheitspersonals zur Reaktion auf Alarme und Durchführung von Verfahren zur Lösung von Problemen;
- Überwachung des Rechenzentrums durch ein lokales oder regionales Gebäudeüberwachungssystem (BMS) und Einbeziehung von Anruftechnikern;
- Verfügbarkeit des Personals vor Ort während der normalen Geschäftszeiten und nachts und am Wochenende auf Abruf;
- Die Arbeit mehrerer Rechenzentren in Form eines speziellen Gebäudekomplexes, dessen Team mehrere Rechenzentren unterstützt, ohne dass sie jederzeit in jedem einzelnen Rechenzentrum vorhanden sein müssen.
Diese und andere Methoden sollten individuell auf ihre Wirksamkeit hin bewertet werden. Um das Modell des technischen Supports bewerten zu können, muss das Rechenzentrum die potenziellen Risiken von Vorfällen im Rechenzentrum und deren potenzielle Auswirkungen auf das Geschäft ermitteln.
In den letzten 20 Jahren hat das Uptime Institute eine Datenbank mit abnormalen Vorfällen (Abnormal Incident Reports, AIRs) erstellt, in der Informationen von Mitgliedern des Uptime Institute Network verwendet wurden. Das Uptime Institute analysiert die Daten jährlich und präsentiert die Ergebnisse den Mitgliedern des Netzwerks. Die AIRs-Datenbank enthält interessante Informationen zu Personalproblemen und effektiven Personalmodellen für Rechenzentren.
Vorfälle ereignen sich außerhalb der Arbeitszeit
Im Jahr 2013 ereignete sich eine kleine Mehrheit der Vorfälle (von 277 Fällen) während der Geschäftszeiten. 44% der Vorfälle ereigneten sich jedoch zwischen Mitternacht und 8:00 Uhr, was die potenzielle Notwendigkeit eines technischen Support-Modus rund um die Uhr unterstreicht (siehe Abbildung 1).
Abbildung 1. Etwa die Hälfte der ungewöhnlichen Vorfälle im Jahr 2013 ereignete sich zwischen 8.00 Uhr und 12.00 Uhr, die andere Hälfte zwischen Mitternacht und 8.00 Uhr.
Vorfälle können zu jeder Jahreszeit auftreten. Eine vorrangige Fokussierung der Mitarbeiteraktivitäten auf eine bestimmte Jahreszeit gegenüber anderen wäre nicht produktiv (z. B. ein Urlaubsverbot). Die Vorfälle sind ziemlich gleichmäßig über das ganze Jahr verteilt.
Abbildung 2 zeigt die Verteilung der Vorfälle nach Wochentagen. Das Diagramm zeigt, dass jeder Wochentag einen nahezu gleichen Anteil hat, was darauf hindeutet, dass die Personalausstattung für die Schichten jedes Wochentags gleich sein sollte. Dies ist eine wichtige Schlussfolgerung, da einige Rechenzentren die Arbeitsressourcen ihres technischen Supports für den Zeitraum von Montag bis Freitag konzentriert haben und die freien Tage für die Fernüberwachung frei lassen (siehe Abb. 2).
Abbildung 2. Das Personal des Rechenzentrums muss jeden Tag der Woche bereit sein.Vorfälle nach Branchen
Abbildung 3 zeigt die Vorfälle in der Branche weiter und zeigt keinen signifikanten Unterschied in den Trends zwischen den Branchen. Die Grafik zeigt, dass die Finanzdienstleistungsbranche weitaus mehr Vorfälle gemeldet hat als andere Branchen. Dies spiegelt jedoch eher die Zusammensetzung der Stichprobe wider.
 Abbildung 3. Vorfälle in Rechenzentren ereignen sich das ganze Jahr über.
Abbildung 3. Vorfälle in Rechenzentren ereignen sich das ganze Jahr über.Fehlerursachen und Erkennungsmethoden
Wenn man weiß, wann Vorfälle auftreten, kann wenig darüber gesagt werden, welches Personal vorhanden sein sollte. Wenn Sie wissen, welche Vorfälle am häufigsten auftreten, können Sie die Schichtstruktur besser gestalten und herausfinden, wie Vorfälle am häufigsten erkannt werden. Abbildung 4 zeigt, dass die meisten Vorfälle elektrische Systeme betreffen, gefolgt von mechanischen Systemen. Im Gegensatz dazu verursachen kritische IT-Workloads eine relativ geringe Anzahl von Vorfällen.
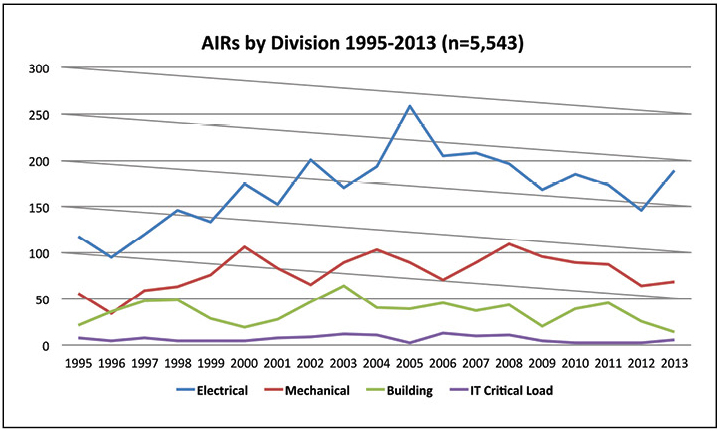 Abbildung 4. Mehr als die Hälfte der 2013 gemeldeten abnormalen Vorfälle hängt mit dem elektrischen System zusammen.
Abbildung 4. Mehr als die Hälfte der 2013 gemeldeten abnormalen Vorfälle hängt mit dem elektrischen System zusammen.Daher ist es sinnvoll, dass Teams aller Schichten über ausreichende Erfahrung verfügen, um auf die häufigsten Vorfälle in elektrischen Systemen zu reagieren. Das Support-Team sollte auch auf andere Arten von Vorfällen reagieren. Die gegenseitige Schulung von Elektrotechnikern zu Mechanik- und Gebäudesystemen kann eine ausreichende Abdeckung bieten, und Anrufbeantworter können relativ seltene IT-Vorfälle abdecken.
Die AIRs-Datenbank gibt auch Aufschluss darüber, wie Vorfälle erkannt werden. Abbildung 5 zeigt, dass mehr als die Hälfte der primären Informationen zu allen 2013 entdeckten Vorfällen von Alarmsystemen stammen. Mehr als 40% der Vorfälle werden von technischen Spezialisten vor Ort erkannt, was zusammen etwa 95% der Fälle ausmacht. Die größte Veränderung in den im Diagramm gezeigten Jahren ist das langsame Wachstum der durch Alarme erkannten Vorfälle.
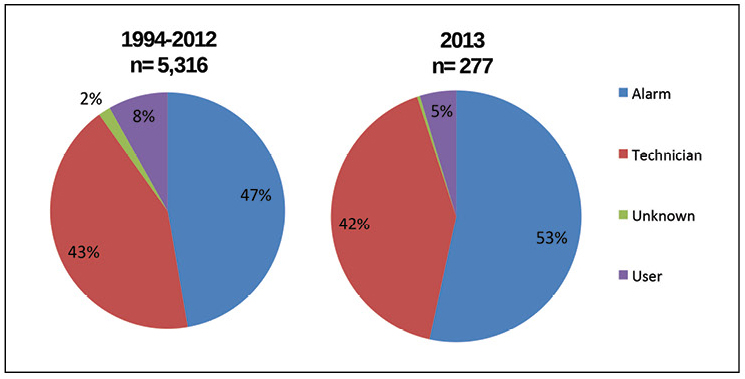 Abbildung 5. Mit Alarmen können jetzt die meisten Vorfälle erkannt werden. Zugänglichkeitsprobleme werden jedoch häufiger von technischen Experten festgestellt.
Abbildung 5. Mit Alarmen können jetzt die meisten Vorfälle erkannt werden. Zugänglichkeitsprobleme werden jedoch häufiger von technischen Experten festgestellt.Alarme können jedoch nicht auf Vorfälle reagieren oder Konsequenzen abmildern. Das Uptime Institute hat eine Reihe von Methoden kennengelernt, mit denen Rechenzentren Fehlfunktionen vermeiden und deren Auswirkungen verringern können. Bei diesen Methoden muss das Personal auf den Vorfall reagieren, Redundanz in kritischen Systemen schaffen und effektive vorausschauende Wartungsprogramme durchführen, um potenzielle Fehler vorherzusagen, bevor sie auftreten. Abbildung 6 zeigt, wie oft jede dieser Methoden Rechenzentren „rettet“.
 Abbildung 6. Die Redundanz der Geräte im Jahr 2013 trug zu mehr „Rettung“ bei als in den Vorjahren.
Abbildung 6. Die Redundanz der Geräte im Jahr 2013 trug zu mehr „Rettung“ bei als in den Vorjahren.Das Diagramm zeigt auch, dass in den letzten Jahren die Redundanz der Geräte und die vorbeugende Wartung effizienter geworden sind und Rechenzentren immer mehr Geld sparen. Hierfür gibt es mehrere mögliche Erklärungen, darunter die Erhöhung der Zuverlässigkeit von Systemen, die breitere Nutzung proaktiver Dienste und Budgetkürzungen, die zu einer Verringerung der Anzahl der Mitarbeiter oder ihrer Verlagerung außerhalb des Rechenzentrums führen.
Fehler im Zusammenhang mit der Grundursache
Die Daten zeigen, dass alle Zugänglichkeitsprobleme im Jahr 2013 durch Zwischenfälle mit dem elektrischen System verursacht wurden. Die meisten Fehler traten auf, weil die Wartungsarbeiten nicht ordnungsgemäß durchgeführt wurden. Diese Feststellung unterstreicht die Bedeutung angemessener Verfahren und gut ausgebildeten Personals.
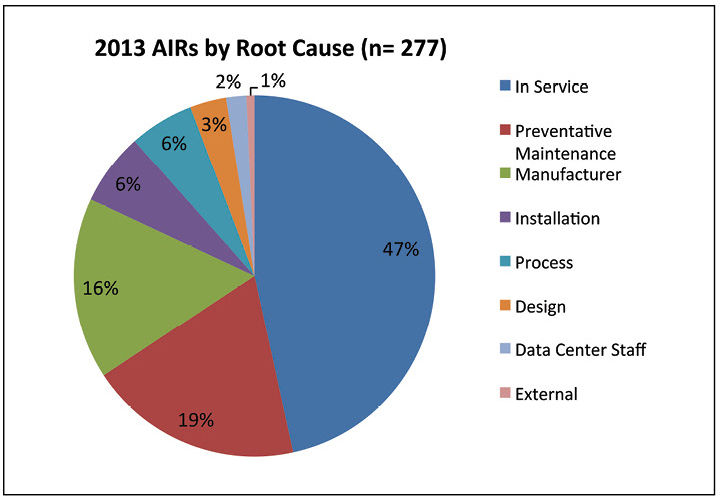 Abbildung 7. Fast die Hälfte der 2013 gemeldeten Fehler war auf Wartungsprobleme zurückzuführen.
Abbildung 7. Fast die Hälfte der 2013 gemeldeten Fehler war auf Wartungsprobleme zurückzuführen.In Abb. 7 erörtert weiter die Ursachen von Vorfällen im Jahr 2013. Etwa die Hälfte der Vorfälle wurde als „In Betrieb“ beschrieben, was als unzureichende Wartung, unsachgemäße Einrichtung der Geräte, Arbeitsausfall oder Fehlen einer bestimmten Grundursache definiert wird. Die Fälle von „vorbeugender Wartung“ beziehen sich tatsächlich auf vorbeugende Wartung, die nicht ordnungsgemäß durchgeführt wurde. Das Personal des Rechenzentrums verursachte nur 2% der Vorfälle, was zeigt, dass die Interaktion zwischen Personal und Ausrüstung nicht die Hauptursache für Vorfälle und Ausfälle war.
Fazit
Die zunehmende Komplexität der Verwaltung der Rechenzentrumsinfrastruktur (DCIM), der Gebäudemanagementsysteme (BMS) und der Gebäudeautomationssysteme (BAS) erschwert die Beantwortung der Frage, ob es möglich ist, die Anzahl der Mitarbeiter in Rechenzentren zu verringern. Die Fortschritte bei der Verbesserung dieser Systeme sind erheblich. Sie können die Leistung Ihres Rechenzentrums verbessern. Daten zeigen jedoch, dass zur Verhütung von Vorfällen häufig Personal vor Ort erforderlich ist. Aus diesem Grund ist es eine Richtlinie für Tier III- und Tier IV-zertifizierte Rechenzentren, weiterhin über Vollzeitäquivalent-Personal (FTE) zu verfügen.
Das Hauptziel besteht darin, eine schnelle Reaktionszeit bereitzustellen, um die Folgen von Vorfällen und Ereignissen zu mildern. Die Daten zeigen, dass bei Vorfällen keine temporären Muster beobachtet werden. Ihr Aussehen ist über alle 24 Stunden und alle 7 Tage der Woche ziemlich gut verteilt.
Hauptziel ist die Risikoprävention. Rechenzentren entwickeln sich weiter und ermöglichen die Verwaltung durch Remotezugriff und die Erhöhung der Hardware-Redundanz. Jedes Rechenzentrum ist einzigartig und hat seine eigenen Risiken. Der Tech-Support-Modus ist nur ein Faktor, aber sehr wichtig. Die Entscheidung, wie viel Personal in jede Schicht einbezogen werden soll und mit welchen Qualifikationen, kann einen großen Einfluss auf die Risikoprävention und die Verfügbarkeit von Rechenzentren haben. Treffen Sie kluge Entscheidungen.
Andere Cloud4Y-Blogartikel:→
Was sind die tatsächlichen Kosten für Ausfallzeiten der IT-Infrastruktur für kleine und mittlere Unternehmen? (externer Link)→
Die Blütezeit des Cloud Computing in der Automatisierung von Industrieunternehmen (externer Link)→
Was passiert mit den Preisen für Cloud Computing in den letzten Jahren (Habr)→
Wie man Proben für das einheitliche biometrische System erstellt und warum es gefährlich sein kann (Habr)