Dieser Artikel beschreibt verschiedene Arten von Tests in der Produktion und die Bedingungen, unter denen jede von ihnen am nützlichsten ist, und beschreibt auch, wie sichere Tests verschiedener Dienstleistungen in der Produktion organisiert werden.
Es ist anzumerken, dass der Inhalt dieses Artikels nur für die
Dienste gilt , deren Bereitstellung von den Entwicklern gesteuert wird. Darüber hinaus sollten Sie sofort warnen, dass die Verwendung einer der hier beschriebenen Testarten keine leichte Aufgabe ist, die häufig schwerwiegende Änderungen am Design, der Entwicklung und dem Testen von Systemen erfordert. Und trotz des Titels des Artikels denke ich nicht, dass eine der Arten von Tests in der Produktion absolut zuverlässig ist. Es gibt nur eine Meinung, dass solche Tests das Risiko in Zukunft erheblich reduzieren können und die Investitionskosten gerechtfertigt sind.
(Hinweis: Da der Originalartikel Longrid ist, ist er der Einfachheit halber in zwei Teile unterteilt.)Warum sind Tests in der Produktion erforderlich, wenn sie in der Inszenierung durchgeführt werden können?
Die Bedeutung des Staging-Clusters (oder der Staging-Umgebung) durch verschiedene Personen wird unterschiedlich wahrgenommen. Für viele Unternehmen ist die Bereitstellung und das Testen eines Produkts in Staging ein wesentlicher Schritt vor seiner endgültigen Veröffentlichung.
Viele bekannte Organisationen betrachten die Bereitstellung als Miniaturkopie der Arbeitsumgebung. In solchen Fällen muss die maximale Synchronisation sichergestellt werden. In diesem Fall ist es normalerweise erforderlich, den Betrieb verschiedener Instanzen von Stateful-Systemen wie Datenbanken sicherzustellen und Daten aus der Produktionsumgebung regelmäßig mit Staging zu synchronisieren. Die Ausnahme bilden nur vertrauliche Informationen, mit denen Sie die Identität des Benutzers feststellen können (dies ist erforderlich, um die Anforderungen von
GDPR ,
PCI ,
HIPAA und anderen Vorschriften zu erfüllen).
Das Problem bei diesem Ansatz (meiner Erfahrung nach) besteht darin, dass der Unterschied nicht nur in der Verwendung einer separaten Instanz der Datenbank besteht, die die tatsächlichen Produktionsumgebungsdaten enthält. Oft erstreckt sich der Unterschied auf folgende Aspekte:
- Die Größe des Staging-Clusters (wenn Sie es als "Cluster" bezeichnen können - manchmal ist es nur ein Server, der als Cluster getarnt ist);
- Die Tatsache, dass beim Staging normalerweise ein viel kleinerer Cluster verwendet wird, bedeutet auch, dass die Konfigurationseinstellungen für fast jeden Dienst variieren. Dies gilt für Konfigurationen von Load Balancern, Datenbanken und Warteschlangen, z. B. die Anzahl der offenen Dateideskriptoren, die Anzahl der offenen Datenbankverbindungen, die Größe des Thread-Pools usw. Wenn die Konfiguration in einer Datenbank oder einem Schlüsselwert-Datenspeicher gespeichert ist (z. Zookeeper oder Consul) müssen diese Hilfssysteme auch in der Staging-Umgebung vorhanden sein.
- Die Anzahl der vom zustandslosen Dienst verarbeiteten Online-Verbindungen oder die Methode zur Wiederverwendung von TCP-Verbindungen durch einen Proxyserver (sofern dieses Verfahren überhaupt ausgeführt wird).
- Fehlende Überwachung bei der Inszenierung. Aber selbst wenn eine Überwachung durchgeführt wird, können sich einige Signale als völlig ungenau herausstellen, da eine andere Umgebung als die Arbeitsumgebung überwacht wird. Selbst wenn Sie beispielsweise die Latenz oder Antwortzeit von MySQL-Abfragen überwachen, ist es schwierig zu bestimmen, ob der neue Code eine Abfrage enthält, die einen vollständigen Tabellenscan in MySQL initiieren kann, da es viel schneller (und manchmal sogar vorzuziehen) ist, einen vollständigen Scan der im Test verwendeten kleinen Tabelle durchzuführen Eine Datenbank anstelle einer Produktionsdatenbank, in der eine Abfrage ein völlig anderes Leistungsprofil haben kann.
Obwohl anzunehmen ist, dass alle oben genannten Unterschiede keine ernsthaften Argumente gegen die Verwendung der Inszenierung als solche sind, im Gegensatz zu Antimustern, die vermieden werden sollten. Gleichzeitig erfordert der Wunsch, alles richtig zu machen, häufig die enormen Arbeitskosten der Ingenieure, um ein einheitliches Umfeld zu gewährleisten. Die Produktion ändert sich ständig und wird von verschiedenen Faktoren beeinflusst. Der Versuch, dieses Match zu erreichen, ist also wie ein Nirgendwo.
Selbst wenn die Bedingungen für die Bereitstellung der Arbeitsumgebung so ähnlich wie möglich sind, gibt es andere Arten von Tests, die auf der Grundlage realer Produktionsinformationen besser zu verwenden sind. Ein gutes Beispiel wäre ein Tränktest, bei dem die Zuverlässigkeit und Stabilität eines Dienstes über einen längeren Zeitraum bei realen Multitasking- und Lastniveaus getestet wird. Es wird verwendet, um Speicherlecks zu erkennen, die Dauer von Pausen im GC, die Prozessorauslastung und andere Indikatoren für einen bestimmten Zeitraum zu bestimmen.
Keiner der oben genannten Punkte deutet darauf hin, dass Staging
völlig nutzlos ist (dies wird deutlich, wenn Sie den Abschnitt über die Schattenverdoppelung von Daten beim Testen von Diensten lesen). Dies weist nur darauf hin, dass sie häufig stärker als erforderlich auf die Bereitstellung angewiesen sind, und in vielen Organisationen bleibt dies die
einzige Art von Tests, die vor der vollständigen Veröffentlichung des Produkts durchgeführt werden.
Die Kunst des Testens in der Produktion
Historisch gesehen ist das Konzept des „Testens in der Produktion“ mit bestimmten Stereotypen und negativen Konnotationen verbunden („Guerilla-Programmierung“, Fehlen oder Fehlen von Unit- und Integrationstests, Nachlässigkeit oder Unaufmerksamkeit für die Wahrnehmung des Produkts durch den Endbenutzer).
Tests in der Produktion verdienen sicherlich einen solchen Ruf, wenn sie nachlässig und schlecht durchgeführt werden. Es ersetzt in keiner Weise
das Testen in der Vorproduktionsphase und ist unter keinen Umständen eine
einfache Aufgabe . Darüber hinaus argumentiere ich, dass
erfolgreiche und
sichere Tests in der Produktion einen erheblichen Automatisierungsgrad, ein gutes Verständnis der etablierten Praktiken und den Entwurf von Systemen erfordern, die sich zunächst an dieser Art von Tests orientieren.
Um einen umfassenden und sicheren Prozess zum effektiven Testen von Dienstleistungen in der Produktion zu organisieren, ist es wichtig, ihn nicht als verallgemeinernden Begriff zu betrachten, der eine Reihe verschiedener Werkzeuge und Techniken bezeichnet. Leider wurde dieser Fehler auch von mir gemacht -
in meinem vorherigen Artikel wurde keine ganz wissenschaftliche Klassifizierung von Testmethoden vorgestellt, und im Abschnitt "Testen in der Produktion" wurden verschiedene Methoden und Werkzeuge gruppiert.
Aus dem Hinweis Testen von Microservices auf vernünftige Weise ("Ein intelligenter Ansatz zum Testen von Microservices")Seit der Veröffentlichung des Hinweises Ende Dezember 2017 habe ich seinen Inhalt und allgemein das Thema des Testens in der Produktion mit mehreren Personen diskutiert.
Im Verlauf dieser Diskussionen und auch nach einer Reihe getrennter Gespräche wurde mir klar, dass das Thema Testen in der Produktion nicht auf mehrere oben aufgeführte Punkte reduziert werden kann.
Das Konzept des „Testens in der Produktion“ umfasst eine ganze Reihe von Techniken, die
in drei verschiedenen Phasen angewendet werden. Welche - lass uns verstehen.
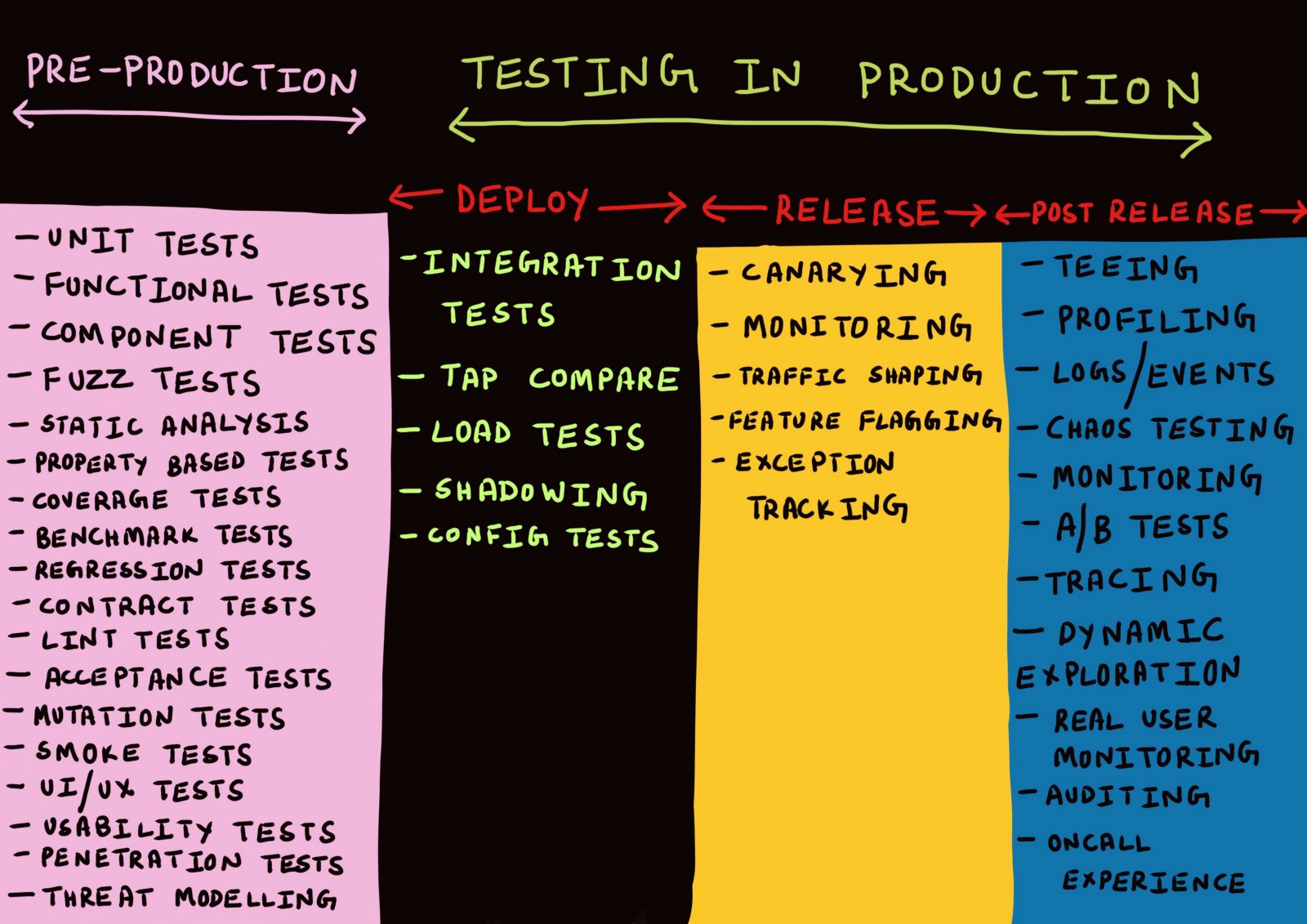
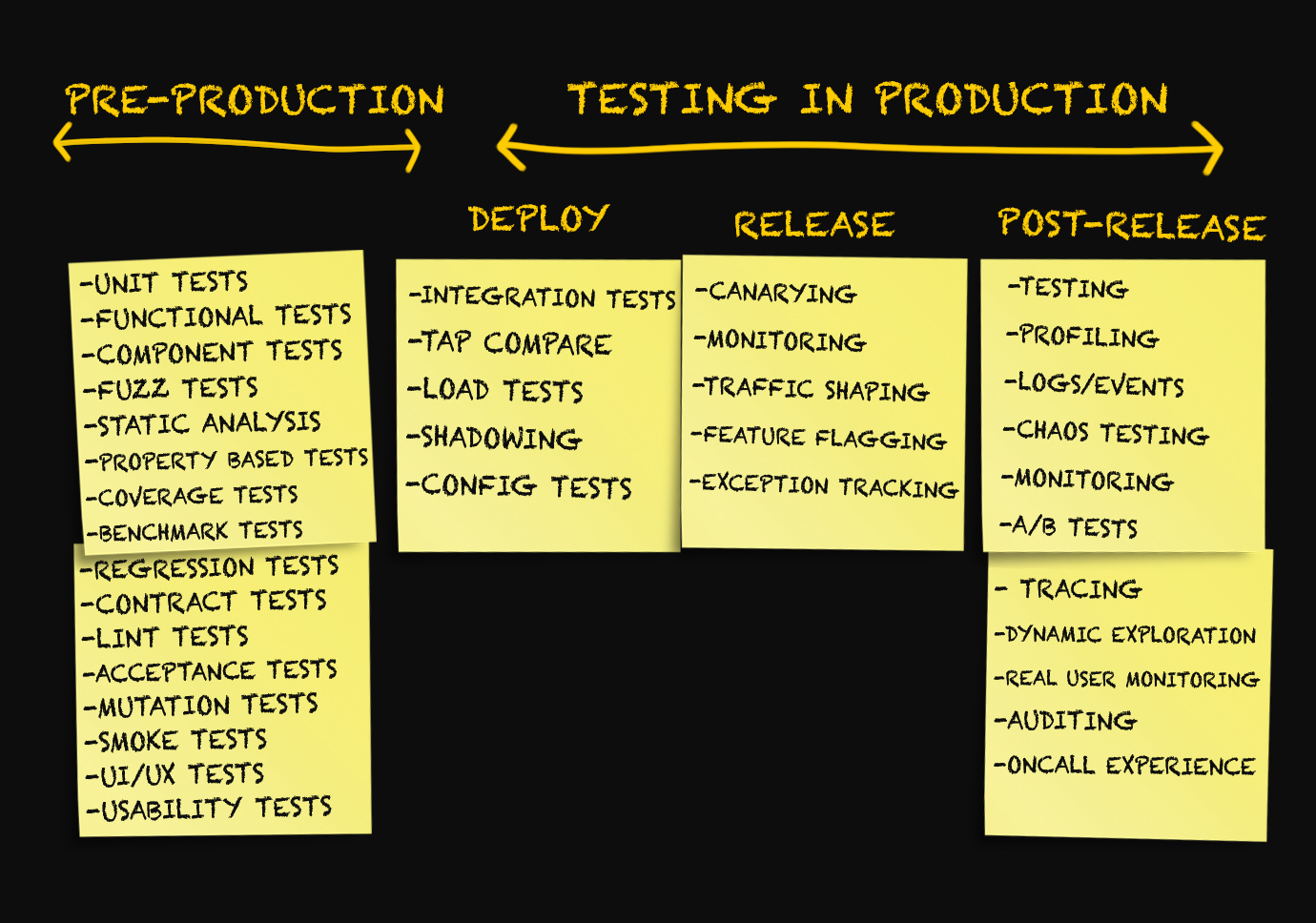
Drei Produktionsstufen
In der Regel werden Diskussionen über die Produktion nur im Zusammenhang mit der Bereitstellung von Code in der Produktion, Überwachung oder in Notsituationen geführt, in denen ein Fehler aufgetreten ist.
Ich selbst habe bisher Begriffe wie "Bereitstellung", "Freigabe", "Lieferung" usw. als Synonyme verwendet, ohne über deren Bedeutung nachzudenken. Vor einigen Monaten wurden alle Versuche, zwischen diesen Begriffen zu unterscheiden, von mir als etwas Unbedeutendes abgelehnt.
Nachdem ich darüber nachgedacht hatte, kam ich auf die Idee, dass
es wirklich notwendig ist, zwischen den verschiedenen Produktionsstufen zu unterscheiden.
Phase 1. Bereitstellung
Wenn das Testen (auch in der Produktion) eine Überprüfung der Erreichung der
bestmöglichen Indikatoren ist , wird die Genauigkeit des Testens (und tatsächlich aller Überprüfungen) nur unter der Bedingung sichergestellt, dass die Methode zur Durchführung von Tests so nah wie möglich an der Art und Weise ist, wie der Service tatsächlich in der Produktion verwendet wird.
Mit anderen Worten, Tests müssen in einer Umgebung ausgeführt werden,
die eine Arbeitsumgebung am besten simuliert .
Und die
beste Nachahmung des Arbeitsumfelds ist ... das Arbeitsumfeld selbst. Um die maximal mögliche Anzahl von Tests in einer Produktionsumgebung durchzuführen, muss das erfolglose Ergebnis eines dieser Tests den Endbenutzer nicht beeinträchtigen.
Dies ist wiederum nur möglich,
wenn Benutzer beim Bereitstellen des Dienstes in einer Produktionsumgebung keinen direkten Zugriff auf diesen Dienst erhalten .
In diesem Artikel habe ich mich für die Terminologie aus dem Artikel
Deploy! = Release von
Turbine Labs entschieden . Es definiert den Begriff "Bereitstellung" wie folgt:
„Die Bereitstellung ist die Installation einer neuen Version des Serviceprogrammcodes in der Produktionsinfrastruktur durch eine Arbeitsgruppe. Wenn wir sagen, dass eine neue Version der Software
bereitgestellt wurde , bedeutet dies, dass sie irgendwo im Rahmen der funktionierenden Infrastruktur ausgeführt wird. Dies kann eine neue EC2-Instanz in AWS oder ein Docker-Container sein, der im Herd eines Kubernetes-Clusters ausgeführt wird. Der Dienst wurde erfolgreich gestartet, hat eine Integritätsprüfung bestanden und ist bereit (Sie hoffen!), Produktionsumgebungsdaten zu verarbeiten, empfängt jedoch möglicherweise keine Daten. Dies ist ein wichtiger Punkt, ich betone ihn noch einmal:
Für die Bereitstellung ist es nicht erforderlich, dass Benutzer Zugriff auf die neue Version Ihres Dienstes erhalten . In Anbetracht dieser Definition kann die Bereitstellung als Prozess mit nahezu null Risiko bezeichnet werden. “
Die Worte „Null-Risiko-Prozess“ sind einfach ein Balsam für die Seele vieler Menschen, die unter erfolglosen Einsätzen gelitten haben. Die Möglichkeit, Software
in einer realen Umgebung zu installieren, ohne dass Benutzer dies zulassen, bietet beim Testen eine Reihe von Vorteilen.
Erstens wird die Notwendigkeit, separate Umgebungen für Entwicklung, Test und Staging zu unterhalten, die zwangsläufig mit der Produktion synchronisiert werden müssen, minimiert (und kann sogar vollständig verschwinden).
Darüber hinaus ist es in der Phase des Entwurfs von Diensten erforderlich, diese voneinander zu isolieren, damit das Versäumnis, eine bestimmte Instanz des Dienstes in der Produktion zu testen,
nicht dazu führt, dass Benutzer den Ausfall anderer Dienste kaskadieren oder beeinträchtigen. Eine Lösung hierfür kann der Entwurf eines Datenmodells und eines Datenbankschemas sein, in denen nicht idempotente Abfragen (hauptsächlich
Schreibvorgänge ) Folgendes können:
- Wird in Bezug auf die Produktionsumgebungsdatenbank während eines Teststarts des Dienstes in der Produktion durchgeführt (ich bevorzuge diesen Ansatz);
- Auf Anwendungsebene sicher abgelehnt werden, bis sie die Schreib- oder Speicherebene erreicht haben;
- Auf Datensatz- oder Speicherebene zugewiesen oder isoliert werden (z. B. durch Speichern zusätzlicher Metadaten).
Stufe 2. Freigabe
Hinweis
Deploy! = Release definiert den Begriff Release wie folgt:
„Wenn wir sagen, dass die
Veröffentlichung der Serviceversion stattgefunden hat, bedeutet dies, dass die Datenverarbeitung in der Produktionsumgebung erfolgt. Mit anderen Worten, eine
Version ist ein Prozess, der Produktionsumgebungsdaten an eine neue Softwareversion weiterleitet. In Anbetracht dieser Definition beziehen sich alle Risiken, die mit dem Senden neuer Datenströme verbunden sind (Unterbrechungen, Unzufriedenheit der Kunden, giftige Notizen im
Register ), auf die
Veröffentlichung neuer Software und nicht auf deren Bereitstellung (in einigen Unternehmen wird diese Phase auch als
Veröffentlichung bezeichnet) . In diesem Artikel verwenden wir den Begriff "
Release ". "
In Googles Buch über SRE wird der Begriff "Release" im
Kapitel zum Organisieren eines Software-Releases verwendet, um es zu beschreiben .
„Ein
Problem ist ein logisches Element der Arbeit, das aus einer oder mehreren separaten Aufgaben besteht. Unser Ziel ist es, den Bereitstellungsprozess mit dem Risikoprofil dieses Dienstes zu koordinieren .
In Entwicklungs- oder Vorproduktionsumgebungen können wir jede Stunde erstellen und Releases automatisch verteilen, nachdem wir alle Tests bestanden haben. Bei großen benutzerorientierten Diensten können wir die Version mit einem Cluster starten und dann die Skalierung erhöhen, bis alle Cluster aktualisiert sind.
Für wichtige Infrastrukturelemente können wir den Implementierungszeitraum auf mehrere Tage verlängern und ihn wiederum in verschiedenen geografischen Regionen ausführen. “In dieser Terminologie bedeuten die Wörter "Release" und "Release", was sich das allgemeine Vokabular auf "Deployment" bezieht, und die Begriffe, die häufig zur Beschreibung verschiedener
Deployment- Strategien verwendet werden (z. B. blau-grüne Deployment oder kanarische Deployment), beziehen sich auf die
Freigabe eines neuen Software.
Darüber hinaus kann eine erfolglose
Freigabe von Anwendungen zu teilweisen oder erheblichen Arbeitsunterbrechungen führen. Zu diesem Zeitpunkt wird auch ein
Rollback oder
Hotfix durchgeführt, wenn sich herausstellt, dass die
veröffentlichte neue Version des Dienstes instabil ist.
Der
Freigabeprozess funktioniert am besten, wenn er automatisiert ist und
schrittweise ausgeführt wird . Ebenso ist ein
Rollback oder
Hotfix eines Dienstes nützlicher, wenn die Fehlerrate und die Anforderungshäufigkeit automatisch mit der Basislinie korreliert werden.
Stufe 3. Nach der Veröffentlichung
Wenn die Veröffentlichung
reibungslos verlief und die neue Version des Dienstes die Daten der Produktionsumgebung ohne offensichtliche Probleme verarbeitet, können wir dies als erfolgreich betrachten. Auf eine erfolgreiche Veröffentlichung folgt eine Phase, die als "nach der Veröffentlichung" bezeichnet werden kann.
Jedes ausreichend komplexe System befindet sich
immer in einem Zustand allmählichen Leistungsverlusts. Dies bedeutet nicht, dass ein
Rollback oder
Hotfix erforderlich ist . Stattdessen ist es notwendig, eine solche Verschlechterung (für verschiedene betriebliche und betriebliche Zwecke) zu überwachen und gegebenenfalls zu debuggen. Aus diesem Grund ähnelt das Testen nach der Veröffentlichung nicht mehr den Routinen, sondern dem
Debuggen oder Sammeln von Analysedaten.
Generell bin ich der Meinung, dass jede Komponente des Systems unter Berücksichtigung der Tatsache erstellt werden sollte, dass kein einziges großes System zu 100% einwandfrei funktioniert und dass Fehlfunktionen in den Phasen Design, Entwicklung, Test, Bereitstellung und Überwachung der Software erkannt und berücksichtigt werden sollten Bereitstellung.
Nachdem wir die drei Produktionsstufen identifiziert haben, schauen wir uns die verschiedenen Testmechanismen an, die für jede von ihnen verfügbar sind. Nicht jeder hat die Möglichkeit, an neuen Projekten zu arbeiten oder Code von Grund auf neu zu schreiben. In diesem Artikel habe ich versucht, die Methoden zu identifizieren, die bei der Entwicklung neuer Projekte am besten funktionieren, und darüber zu sprechen, was wir sonst noch tun können, um die vorgeschlagenen Methoden zu nutzen, ohne wesentliche Änderungen an Arbeitsprojekten vorzunehmen.
Bereitstellungstests
Wir haben die Bereitstellungs- und Freigabestufen voneinander getrennt und betrachten nun einige Arten von Tests, die nach der Bereitstellung des Codes in der Produktionsumgebung angewendet werden können.
Integrationstests
In der Regel werden Integrationstests von einem kontinuierlichen Integrationsserver in einer isolierten Testumgebung für jeden Git-Zweig durchgeführt. Eine Kopie der
gesamten Diensttopologie (einschließlich Datenbanken, Warteschlangen, Proxys usw.) wird für Testsuiten
aller Dienste bereitgestellt, die zusammenarbeiten.
Ich glaube, dass dies aus mehreren Gründen nicht besonders effektiv ist. Erstens kann die Testumgebung wie die Staging-Umgebung nicht so bereitgestellt werden, dass sie
mit der tatsächlichen Produktionsumgebung
identisch ist,
selbst wenn die Tests in demselben Docker-Container ausgeführt werden, der in der Produktion verwendet wird. Dies gilt insbesondere dann, wenn in einer Testumgebung nur die Tests selbst ausgeführt werden.
Unabhängig davon, ob der Test als Docker-Container oder als POSIX-Prozess ausgeführt wird, stellt er höchstwahrscheinlich
eine oder mehrere Verbindungen zu einem überlegenen Dienst, einer Datenbank oder einem Cache her. Dies ist selten, wenn sich der Dienst in einer Produktionsumgebung befindet, in der er gleichzeitig ausgeführt werden kann mehrere gleichzeitige Verbindungen verarbeiten und häufig inaktive TCP-Verbindungen wiederverwenden (dies wird als Wiederverwendung von HTTP-Verbindungen bezeichnet).
Das Problem wird auch durch die Tatsache verursacht, dass die meisten Tests bei jedem Start eine neue Datenbanktabelle oder einen neuen Cache-Schlüsselbereich auf
demselben Knoten erstellen, auf
dem dieser Test durchgeführt wird (auf diese Weise werden die Tests von Netzwerkfehlern isoliert). Diese Art des Testens kann bestenfalls zeigen, dass das System mit einer ganz bestimmten Anforderung korrekt funktioniert. Es ist selten effektiv bei der Simulation schwerwiegender, gut verteilter Arten von Fehlern, ganz zu schweigen von den verschiedenen Arten von Teilfehlern.
Es gibt umfassende Studien , die bestätigen, dass verteilte Systeme häufig ein
unvorhersehbares Verhalten aufweisen , das durch eine Analyse, die anders als für das gesamte System durchgeführt wird, nicht vorhergesehen werden kann.
Dies bedeutet jedoch nicht, dass Integrationstests
grundsätzlich nutzlos sind. Wir können nur sagen, dass die Durchführung von Integrationstests in einer
künstlichen, vollständig isolierten Umgebung in der Regel keinen Sinn ergibt. Integrationstests sollten weiterhin durchgeführt werden, um sicherzustellen, dass die neue Version des Dienstes:
- Beeinträchtigt nicht die Interaktion mit vor- oder nachgelagerten Diensten;
- Beeinträchtigt nicht die Ziele höherer oder niedrigerer Dienstleistungen.
Die erste kann bis zu einem gewissen Grad durch Vertragstests bereitgestellt werden.
Aufgrund der Tatsache, dass die
Schnittstellen zwischen den Diensten ordnungsgemäß funktionieren, ist das
Testen von Verträgen eine effektive Methode zum Entwickeln und Testen einzelner Dienste in
der Vorproduktionsphase , für die nicht die gesamte Diensttopologie bereitgestellt werden muss.
Clientorientierte Vertragstestplattformen wie
Pact unterstützen derzeit nur die Interoperabilität zwischen Diensten über RESTful JSON RPC, obwohl wahrscheinlich daran
gearbeitet wird, die asynchrone Interaktion über Web-Sockets, Nicht-Server-Anwendungen und Nachrichtenwarteschlangen zu unterstützen . Die Unterstützung für die gRPC- und GraphQL-Protokolle wird voraussichtlich in Zukunft hinzugefügt, ist jedoch noch nicht verfügbar.
Vor der
Veröffentlichung einer neuen Version muss jedoch möglicherweise nicht nur die ordnungsgemäße Funktion der
Schnittstellen überprüft
werden . , , , RPC- . , , , .
,
, — ,
, ( , ).
:
?
. – , : - - ( C) MySQL ( D) memcache ( B).
, ( ), stateful- stateless- .
,
.
service discovery
( ),
.
.
,
C .
,
, , . , , . ,
, .
Google
Just Say No to More End-to-End Tests (« »), :
«
( ) . , ? , .
, , , »., :
. , A .
,
C MySQL, .
( , , «» ,
).
MySQL , , .
— -. , . -, .
, -
, /:
, (, ).
, ,
. IP- , , , , , , , , .
, , , , . . Facebook,
Kraken , :
«
— , . - , . , . - , , , »., , , , , .
- . service mesh . -. -, , , :
Wenn wir Service B testen, kann sein ausgehender Proxyserver so konfiguriert werden, dass jeder
X-ServiceB-Test ein spezieller
X-ServiceB-Test Header hinzugefügt wird. In diesem Fall kann der eingehende Proxyserver des übergeordneten Dienstes C:
- Erkennen Sie diesen Header und senden Sie eine Standardantwort an Service B;
- Teilen Sie Service C mit, dass die Anforderung ein Test ist .
Integrationstests der Interaktion der bereitgestellten Version von Dienst B mit der freigegebenen Version von Dienst C, bei der Schreibvorgänge niemals die Datenbank erreichenWenn Sie Integrationstests auf diese Weise durchführen, können Sie auch die Interaktion von Service B mit höheren Services testen,
wenn diese normale Produktionsumgebungsdaten verarbeiten. Dies ist wahrscheinlich eine genauere Nachahmung des Verhaltens von Service B bei der
Freigabe in die Produktion.
Es wäre auch schön, wenn jeder Dienst in dieser Architektur echte API-Aufrufe im Test- oder Mock-Modus unterstützen würde, sodass Sie die Ausführung von Dienstverträgen mit nachgeschalteten Diensten testen können, ohne die realen Daten zu ändern. Dies wäre gleichbedeutend mit Vertragstests, jedoch auf Netzwerkebene.
Duplizierung von Schattendaten (Testen des dunklen Datenstroms oder Spiegeln)
Die Duplizierung von Schatten (in dem Artikel im Google-Blog heißt sie
Dark Launch , und der Begriff
Spiegelung wird in
Istio verwendet ) hat in vielen Fällen mehr Vorteile als Integrationstests.
Die
Prinzipien der Chaos-Technik besagen Folgendes:
„
Systeme verhalten sich je nach Umgebung und Datenübertragungsschema unterschiedlich. Da sich der Nutzungsmodus jederzeit ändern kann , ist das
Abtasten realer Daten der einzig zuverlässige Weg, um den Anforderungspfad festzulegen. “Die Duplizierung von Schattendaten ist eine Methode, mit der der Datenstrom der Produktionsumgebung, der in einen bestimmten Dienst eingeht, erfasst und in einer neuen
bereitgestellten Version des Dienstes reproduziert wird. Dieser Vorgang kann entweder in Echtzeit ausgeführt werden, wenn der eingehende Datenstrom aufgeteilt und sowohl an die
freigegebene als auch an die
bereitgestellte Version des Dienstes gesendet wird, oder asynchron, wenn eine Kopie zuvor erfasster Daten im
bereitgestellten Dienst wiedergegeben wird.
Als ich bei
imgix arbeitete (einem Startup mit 7 Ingenieuren, von denen nur vier Systemingenieure waren), wurden dunkle Datenströme aktiv verwendet, um Änderungen in unserer
Bildvisualisierungsinfrastruktur zu testen. Wir haben einen bestimmten Prozentsatz aller eingehenden Anforderungen registriert und an den Kafka-Cluster gesendet. Wir haben die HAProxy-Zugriffsprotokolle an die
Heka- Pipeline übergeben, die wiederum den analysierten Anforderungsfluss an den Kafka-Cluster weitergeleitet hat. Vor der
Release- Phase
wurde eine neue Version unserer Bildverarbeitungsanwendung in einem erfassten dunklen Datenstrom getestet. Auf diese Weise konnte überprüft werden, ob die Anforderungen korrekt verarbeitet wurden. Unser Bildvisualisierungssystem war jedoch im Großen und Ganzen ein zustandsloser Dienst, der für diese Art von Tests besonders gut geeignet war.
Einige Unternehmen ziehen es vor, nicht einen Teil des Datenstroms zu erfassen, sondern eine
vollständige Kopie dieses Datenstroms an die neue Version der Anwendung zu übertragen.
Der McRouter (memcached Proxy) von
Facebook unterstützt diese Art der Schattenverdoppelung des Memcache-Datenstroms.
„
Beim Testen einer neuen Installation für den Cache fanden wir es sehr praktisch, eine vollständige Kopie des Datenstroms von Clients umleiten zu können. McRouter unterstützt flexible Einstellungen für die Schattenverdopplung. Es ist möglich, eine Schattenkopie eines Pools verschiedener Größen durchzuführen (durch erneutes Zwischenspeichern des Schlüsselraums), nur einen Teil des Schlüsselraums zu kopieren oder Parameter während des Betriebs dynamisch zu ändern . “
Der negative Aspekt der Schattenverdoppelung des gesamten Datenstroms für einen
bereitgestellten Dienst in einer Produktionsumgebung besteht darin, dass bei Ausführung im Moment maximaler Datenübertragungsintensität möglicherweise doppelt so viel Strom benötigt wird.
Proxys wie Envoy unterstützen die Schatten-Duplizierung des Datenflusses zu einem anderen Cluster im Fire-and-Forget-Modus. Die
Dokumentation lautet:
„
Ein Router kann den Datenfluss von einem Cluster zum anderen im Schatten duplizieren. Derzeit ist der Fire-and-Forget-Modus implementiert, bei dem der Envoy-Proxyserver nicht auf eine Antwort vom Schattencluster wartet, bevor er eine Antwort vom Hauptcluster zurückgibt. Für den Schattencluster werden alle üblichen Statistiken gesammelt, was zu Testzwecken nützlich ist. Bei der Schattenverdoppelung wird die Option -shadow zum Host- / Berechtigungsheader hinzugefügt. Dies ist nützlich für die Protokollierung. Zum Beispiel verwandelt sich cluster1-shadow in cluster1-shadow . "
Es ist jedoch häufig unpraktisch oder unmöglich, eine Replik eines mit der Produktion synchronisierten Clusters zum Testen zu erstellen (aus dem gleichen Grund, aus dem es problematisch ist, einen synchronisierten Staging-Cluster zu organisieren). Wenn zum Testen eines neuen
bereitgestellten Dienstes mit vielen Abhängigkeiten eine Schatten-Duplizierung verwendet wird, kann dies zu unvorhergesehenen Änderungen des Status übergeordneter Dienste in Bezug auf den getesteten Dienst führen. Eine Schatten-Duplizierung des täglichen Volumens von Benutzerregistrierungen in der
bereitgestellten Version des Dienstes mit Aufzeichnung in der Produktionsdatenbank kann zu einer Erhöhung der Fehlerrate um bis zu 100% führen, da der Schattendatenstrom als wiederholte Registrierungsversuche wahrgenommen und abgelehnt wird.
Meine persönliche Erfahrung zeigt, dass die Duplizierung von Schatten am besten zum Testen nicht idempotenter Anforderungen oder zustandsloser Dienste mit serverseitigen Stubs geeignet ist. In diesem Fall wird die Schattenverdoppelung von Daten häufiger zum Testen von Last, Stabilität und Konfigurationen verwendet. Gleichzeitig können Sie mithilfe von Integrationstests oder Staging testen, wie der Dienst mit einem statusbehafteten Server interagiert, wenn Sie mit nicht idempotenten Anforderungen arbeiten.
TAP-Vergleich
Die einzige Erwähnung dieses Begriffs findet sich in einem
Artikel aus dem Twitter-Blog, der sich mit der Einführung von Diensten mit hoher Servicequalität befasst.
„Um die Richtigkeit der neuen Implementierung des vorhandenen Systems zu überprüfen, haben wir eine Methode namens Tap-Vergleich verwendet . Unser Tap-Vergleichstool reproduziert die Probenproduktionsdaten im neuen System und vergleicht die empfangenen Antworten mit den Ergebnissen des alten. Die erzielten Ergebnisse haben uns geholfen, Fehler im System zu finden und zu beheben, noch bevor Endbenutzer auf sie gestoßen sind. “Ein anderer Twitter-Blog-Beitrag definiert Tap-Vergleiche wie folgt:
"Senden von Anforderungen an Service-Instanzen sowohl in der Produktion als auch in Staging-Umgebungen mit Überprüfung der Ergebnisse und Bewertung der Leistungsmerkmale."Der Unterschied zwischen Tap-Vergleich und Schatten-Duplizierung besteht darin, dass im ersten Fall die von der
freigegebenen Version zurückgegebene Antwort mit der von der
bereitgestellten Version zurückgegebenen Antwort verglichen wird und im zweiten Fall die Anforderung im Offline-Modus wie Fire-and-Forget auf die
bereitgestellte Version dupliziert wird.
Ein weiteres Werkzeug für die Arbeit in diesem Bereich ist die auf GitHub verfügbare
Wissenschaftlerbibliothek . Dieses Tool wurde zum Testen von Ruby-Code entwickelt, dann aber in
mehrere andere Sprachen portiert. Es ist für einige Arten von Tests nützlich, weist jedoch eine Reihe ungelöster Probleme auf. Folgendes hat ein GitHub-Entwickler in einer professionellen Slack-Community geschrieben:
„Dieses Tool führt einfach zwei Codezweige aus und vergleicht die Ergebnisse. Sie sollten mit dem Code dieser Zweige vorsichtig sein. Es muss sichergestellt werden, dass Datenbankabfragen nicht dupliziert werden, wenn dies zu Problemen führt. Ich denke, dass dies nicht nur für einen Wissenschaftler gilt, sondern auch für jede Situation, in der Sie zweimal etwas tun und dann die Ergebnisse vergleichen. Das Wissenschaftler-Tool wurde erstellt, um zu überprüfen, ob das neue Berechtigungssystem genauso funktioniert wie das alte. Zu bestimmten Zeiten wurde es verwendet, um die Daten zu vergleichen, die für praktisch jede Rails-Anforderung typisch sind. Ich denke, dass der Prozess mehr Zeit in Anspruch nehmen wird, da die Verarbeitung nacheinander ausgeführt wird, aber dies ist ein Ruby-Problem, bei dem keine Threads verwendet werden.
In den meisten mir bekannten Fällen wurde das Wissenschaftler-Tool verwendet, um mit Lese- und nicht mit Schreiboperationen zu arbeiten, um beispielsweise herauszufinden, ob neue, verbesserte Abfragen und Berechtigungsschemata dieselbe Antwort erhalten wie alte. Beide Optionen werden in einer Produktionsumgebung (auf Replikaten) ausgeführt. Wenn die getesteten Ressourcen Nebenwirkungen haben, müssen die Tests meiner Meinung nach auf Anwendungsebene durchgeführt werden. “Diffy ist ein von Scala geschriebenes Open Source-Tool, das 2015 von Twitter eingeführt wurde.
Ein Artikel aus dem Twitter-Blog mit dem Titel
Testen ohne Tests zu schreiben ist wahrscheinlich die beste Quelle, um zu verstehen, wie Tap-Vergleiche in der Praxis funktionieren.
„Diffy erkennt potenzielle Fehler im Dienst, indem gleichzeitig eine neue und eine alte Version des Codes gestartet werden. Dieses Tool fungiert als Proxyserver und sendet alle empfangenen Anforderungen an jede der ausgeführten Instanzen. Anschließend vergleicht er die Antworten der Instanzen und meldet alle beim Vergleich festgestellten Abweichungen. Diffy basiert auf der folgenden Idee: Wenn zwei Implementierungen eines Dienstes dieselben Antworten mit einem ausreichend großen und unterschiedlichen Satz von Anforderungen zurückgeben, können diese beiden Implementierungen als gleichwertig angesehen werden, und die neuere von ihnen ohne Leistungseinbußen. Die innovative Rauschunterdrückungstechnik von Diffy unterscheidet es von anderen Tools zur vergleichenden Regressionsanalyse. “Der Tap-Vergleich ist großartig, wenn Sie überprüfen müssen, ob zwei Versionen die gleichen Ergebnisse liefern. Laut Mark McBride
„Das Diffy-Tool wurde häufig bei der Neugestaltung von Systemen verwendet. In unserem Fall haben wir die Rails-Quellcodebasis in mehrere mit Scala erstellte Dienste unterteilt, und eine große Anzahl von API-Clients hat Funktionen verwendet, die anders waren als erwartet. Funktionen wie die Datumsformatierung waren besonders gefährlich. “Der Tap-Vergleich ist nicht die beste Option zum Testen der Benutzeraktivität oder der Identität des Verhaltens von zwei Versionen des Dienstes bei maximaler Auslastung. Wie bei der Schattenverdoppelung bleiben Nebenwirkungen ein ungelöstes Problem, insbesondere wenn sowohl die bereitgestellte Version als auch die Produktionsversion Daten in dieselbe Datenbank schreiben. Wie bei Integrationstests besteht eine Möglichkeit, dieses Problem zu umgehen, darin, Vergleichstests mit nur einer begrenzten Anzahl von Konten zu verwenden.
Lasttest
Für diejenigen, die mit Stresstests nicht vertraut sind, kann
dieser Artikel als guter Ausgangspunkt dienen. An Tools und Plattformen für Open Source-Lasttests mangelt es nicht. Die beliebtesten von ihnen sind
Apache Bench ,
Gatling ,
wrk2 ,
Tsung , geschrieben in Erlang,
Siege ,
Iago von Twitter, geschrieben in Scala (das die Protokolle eines HTTP-Servers, Proxyservers oder Netzwerkpaketanalysators in einer Testinstanz reproduziert). Einige Experten glauben, dass das beste Tool zum Generieren von Last
mzbench ist , das eine Vielzahl von Protokollen unterstützt, darunter MySQL, Postgres, Cassandra, MongoDB, TCP usw. Die
NDBench von Netflix ist ein weiteres Open-Source-Tool zum Testen von Last-Data-Warehouses. , die die meisten bekannten Protokolle unterstützt.
Der offizielle Twitter-Blog von
Iago beschreibt detaillierter, welche Funktionen ein guter Lastgenerator haben sollte:
„Nicht blockierende Anforderungen werden mit einer bestimmten Häufigkeit basierend auf einer internen benutzerdefinierten statistischen Verteilung generiert ( der Poisson-Prozess wird standardmäßig modelliert). Die Häufigkeit von Anforderungen kann nach Bedarf geändert werden, um beispielsweise den Cache vor der Arbeit unter Volllast vorzubereiten.
Im Allgemeinen liegt der Schwerpunkt auf der Häufigkeit von Anfragen gemäß dem Gesetz von Little und nicht auf der Anzahl gleichzeitiger Benutzer, die je nach Verzögerung dieses Dienstes variieren können. Aus diesem Grund ergeben sich neue Möglichkeiten, die Ergebnisse mehrerer Tests zu vergleichen und eine Verschlechterung des Betriebs zu verhindern, wodurch der Betrieb des Lastgenerators verlangsamt wird.
Mit anderen Worten, das Iago-Tool versucht, ein System zu simulieren, in dem Anforderungen empfangen werden, unabhängig von der Fähigkeit Ihres Dienstes, diese zu verarbeiten. Dies unterscheidet sich von Lastgeneratoren, die geschlossene Systeme simulieren, in denen Benutzer geduldig mit der vorhandenen Verzögerung arbeiten. Dieser Unterschied ermöglicht es uns, die Fehlermodi, die in der Produktion auftreten können, ziemlich genau zu modellieren. "Eine andere Art der Lastprüfung ist die Belastungsprüfung durch Umverteilung des Datenflusses. Das Wesentliche ist: Der gesamte Datenfluss aus der Produktionsumgebung wird an einen kleineren Cluster geleitet als den für den Service vorbereiteten. Bei Problemen wird der Datenstrom zurück zum größeren Cluster übertragen. Diese Technik wird von Facebook verwendet, wie in einem der
Artikel in seinem offiziellen Blog beschrieben :
„Wir leiten speziell einen größeren Datenfluss an einzelne Cluster oder Knoten um, messen den Ressourcenverbrauch auf diesen Knoten und bestimmen die Grenzen der Servicestabilität. Diese Art des Testens ist insbesondere nützlich, um die CPU-Ressourcen zu ermitteln, die zur Unterstützung der maximalen Anzahl gleichzeitiger Übertragungen von Facebook Live erforderlich sind. “Folgendes schreibt ein ehemaliger LinkedIn-Ingenieur in der professionellen Slack-Community:
"LinkedIn verwendete auch Redline-Tests in der Produktion - Server wurden aus dem Load Balancer entfernt, bis die Last Schwellenwerte erreichte oder Fehler auftraten."In der Tat bietet eine Google-Suche einen Link zu einem
vollständigen Whitepaper und einem LinkedIn-Blogartikel zu diesem Thema:
„Die Redliner-Lösung für Messungen verwendet einen realen Datenstrom der Produktionsumgebung, wodurch Fehler vermieden werden, die genaue Leistungsmessungen im Labor verhindern.
Redliner leitet einen Teil des Datenstroms an den zu testenden Dienst weiter und analysiert dessen Leistung in Echtzeit. Diese Lösung wurde in Hunderten von internen LinkedIn-Diensten implementiert und wird täglich für verschiedene Arten von Leistungsanalysen verwendet.
Redliner unterstützt die parallele Testausführung für kanarische und Produktionsinstanzen. Auf diese Weise können Ingenieure dieselbe Datenmenge auf zwei verschiedene Dienstinstanzen übertragen: 1) eine Dienstinstanz, die Innovationen wie neue Konfigurationen, Eigenschaften oder neuen Code enthält; 2) eine Dienstinstanz der aktuellen Arbeitsversion."Die Ergebnisse von Lasttests werden bei Entscheidungen berücksichtigt und verhindern die Bereitstellung von Code, was zu einer schlechten Leistung führen kann."Facebook hat dank des Kraken-Systems Lasttests mit realen Datenströmen auf ein völlig neues Niveau gebracht, und auch die
Beschreibung ist lesenswert.
Das Testen wird implementiert, indem der Datenstrom neu verteilt wird, wenn Gewichtswerte (aus dem verteilten Konfigurationsspeicher gelesen) für
Grenzgeräte und Cluster in der
Proxygen- Konfiguration (Facebook Load Balancer)
geändert werden . Diese Werte bestimmen das Volumen der realen Daten, die an einem bestimmten Anwesenheitspunkt an jeden Cluster und jede Region gesendet werden.
Daten aus dem Kraken White PaperDas Überwachungssystem (
Gorilla ) zeigt Indikatoren für verschiedene Dienste an (wie in der obigen Tabelle gezeigt). Basierend auf den Überwachungsdaten und Schwellenwerten wird entschieden, ob Daten gemäß den Gewichtswerten weiter gesendet werden sollen oder ob die Übertragung von Daten an einen bestimmten Cluster reduziert oder sogar vollständig gestoppt werden muss.
Konfigurationstests
Eine neue Welle von Open-Source-Infrastruktur-Tools hat es möglich gemacht, alle Änderungen in der Infrastruktur in Form von Code zu erfassen, aber auch relativ
einfach . Es ist auch in unterschiedlichem Maße möglich geworden, diese Änderungen zu
testen , obwohl die meisten Infrastruktur-als-Code-Tests in der Vorproduktionsphase nur die korrekten Spezifikationen und Syntax bestätigen können.
Darüber hinaus wurde die Weigerung, die neue Konfiguration vor der
Veröffentlichung des Codes zu testen, zu einer
erheblichen Anzahl von Unterbrechungen .
Für das ganzheitliche Testen von Konfigurationsänderungen ist es wichtig, zwischen verschiedenen Arten von Konfigurationen zu unterscheiden. Fred Hebert schlug einmal vor, den folgenden Quadranten zu verwenden:
Diese Option ist natürlich nicht universell, aber mit dieser Unterscheidung können Sie entscheiden, wie und zu welchem Zeitpunkt die einzelnen Konfigurationen am besten getestet werden sollen. Die Konfiguration der Erstellungszeit ist sinnvoll, wenn Sie die tatsächliche Wiederholbarkeit von Baugruppen sicherstellen können. Nicht alle Konfigurationen sind statisch, aber auf modernen Plattformen ist eine dynamische Konfigurationsänderung unvermeidlich (selbst wenn es sich um eine „permanente Infrastruktur“ handelt).
, , blue-green , . (
Jamie Wilkinson ), Google ,
:
« , , , - . . - , — , , . ., . , , — ».Facebook :
« . — , . . , .
. Facebook , . , .
(, JSON). , . .
(, Facebook Thrift) . , .
, , - . . — A/B-, 1 % . A/B-, . A/B- . , , , , . , A/B- . , A/B-. Facebook .
, A/B- 1% , 1% , ( « »). , . , .
Facebook . , . , , . , , .- Einfache und bequeme Stornierung von Änderungen
In einigen Fällen wird trotz aller vorbeugenden Maßnahmen die Bereitstellung einer nicht funktionsfähigen Konfiguration durchgeführt. Das schnelle Auffinden und Zurücksetzen von Änderungen ist entscheidend, um ein solches Problem anzugehen. "In unserem Konfigurationssystem sind Tools zur Versionskontrolle verfügbar, die das Rückgängigmachen von Änderungen erheblich vereinfachen."
Fortsetzung folgt!UPD: hier fortgesetzt .