Vielleicht gibt es heute keine andere Technologie, um die es so viele Mythen, Lügen und Inkompetenzen geben würde. Journalisten, die über Technologielüge sprechen, Politiker, die über erfolgreiche Implementierung sprechen, lügen, die meisten Technologieverkäufer lügen. Jeden Monat sehe ich die Konsequenzen, wie Menschen versuchen, die Gesichtserkennung in Systemen zu implementieren, die nicht damit arbeiten können.

Das Thema dieses Artikels wurde vor langer Zeit schmerzhaft, aber es war irgendwie zu faul, um es zu schreiben. Viel Text, den ich schon zwanzig Mal für verschiedene Leute wiederholt habe. Aber nachdem ich eine weitere Packung Müll gelesen hatte, entschied ich, dass es Zeit war. Ich werde einen Link zu diesem Artikel geben.
Also. In dem Artikel werde ich einige einfache Fragen beantworten:
- Kann man dich auf der Straße erkennen? Und wie automatisch / zuverlässig?
- Vorgestern haben sie geschrieben, dass Kriminelle in der Moskauer U-Bahn festgehalten werden , und gestern haben sie geschrieben, dass sie nicht in London sein könnten . Und auch in China erkennen sie jeden, jeden auf der Straße. Und hier heißt es, 28 US-Kongressabgeordnete seien Kriminelle. Oder sie haben einen Dieb gefangen .
- Wer veröffentlicht jetzt Gesichtserkennungslösungen, was ist der Unterschied zwischen Lösungen und Technologiefunktionen?
Die meisten Antworten werden evidenzbasiert sein, mit einem Link zur Forschung, in der die Schlüsselparameter der Algorithmen + mit der Berechnungsmathematik gezeigt werden. Ein kleiner Teil basiert auf den Erfahrungen mit der Implementierung und dem Betrieb verschiedener biometrischer Systeme.
Ich werde nicht näher darauf eingehen, wie die Gesichtserkennung jetzt implementiert wird. Auf Habré gibt es viele gute Artikel zu diesem Thema:
a ,
b ,
c (es gibt natürlich noch viel mehr davon, die im Gedächtnis auftauchen). Dennoch einige Punkte, die unterschiedliche Entscheidungen betreffen - ich werde beschreiben. Das Lesen mindestens eines der oben genannten Artikel vereinfacht das Verständnis dieses Artikels. Fangen wir an!
Einleitung, Basis
Biometrie ist eine exakte Wissenschaft. Es gibt keinen Platz für die Sätze "funktioniert immer" und "ideal". Alles ist sehr gut überlegt. Und um zu berechnen, müssen Sie nur zwei Größen kennen:
- Fehler der ersten Art - eine Situation, in der sich eine Person nicht in unserer Datenbank befindet, wir sie jedoch als in der Datenbank vorhandene Person identifizieren (in biometrics FAR (falsche Zugriffsrate)).
- Fehler der zweiten Art - Situationen, in denen sich eine Person in der Datenbank befindet, wir sie jedoch vermisst haben. (In der Biometrie FRR (Falschabstoßungsrate))
Diese Fehler können eine Reihe von Funktionen und Anwendungskriterien haben. Wir werden unten darüber sprechen. In der Zwischenzeit werde ich Ihnen sagen, wo Sie sie bekommen können.
Eigenschaften
Die erste Option . Es war einmal, als die Hersteller selbst Fehler veröffentlichten. Aber hier ist die Sache: Sie können dem Hersteller nicht vertrauen. Unter welchen Bedingungen und wie er diese Fehler gemessen hat - weiß niemand. Und ob überhaupt gemessen oder die Marketingabteilung gezeichnet.
Die zweite Option. Offene Basen erschienen. Die Hersteller begannen, Fehler auf den Basen anzuzeigen. Der Algorithmus kann für bekannte Datenbanken geschärft werden, so dass sie für sie eine hervorragende Qualität aufweisen. In der Realität funktioniert ein solcher Algorithmus jedoch möglicherweise nicht.
Die dritte Option sind offene Wettbewerbe mit einer geschlossenen Lösung. Der Veranstalter prüft die Entscheidung. Im Wesentlichen kaggle. Das bekannteste davon ist
MegaFace . Die ersten Plätze in diesem Wettbewerb gaben einst große Popularität und Ruhm. Zum Beispiel haben sich N-Tech und Vocord auf MegaFace weitgehend einen Namen gemacht.
Alles wäre gut, aber ehrlich. Hier können Sie die Lösung anpassen. Das ist viel schwieriger, länger. Sie können jedoch Personen berechnen, die Basis manuell markieren usw. Und vor allem - es hat nichts damit zu tun, wie das System mit realen Daten arbeitet. Sie können sehen, wer jetzt bei MegaFace führend ist, und dann im nächsten Absatz nach den Lösungen dieser Typen suchen.
Die vierte Option . Bis heute das ehrlichste. Ich weiß nicht, wie ich dort schummeln soll. Obwohl ich sie nicht ausschließe.
Ein großes und weltberühmtes Institut erklärt sich bereit, ein unabhängiges Lösungstestsystem einzusetzen. Von Herstellern wird ein SDK erhalten, das geschlossenen Tests unterzogen wird, an denen der Hersteller nicht teilnimmt. Das Testen hat viele Parameter, die dann offiziell veröffentlicht werden.
Jetzt werden solche
Tests vom NIST - dem American National Institute of Standards and Technologies - durchgeführt. Solche Tests sind die ehrlichsten und interessantesten.
Ich muss sagen, dass NIST einen tollen Job macht. Sie entwickelten fünf Fälle, veröffentlichten alle paar Monate neue Updates, verbesserten sich ständig und schlossen neue Hersteller ein. Hier finden Sie die neueste Ausgabe der Studie.
Es scheint, dass diese Option ideal für die Analyse ist. Aber nein! Der Hauptnachteil dieses Ansatzes besteht darin, dass wir nicht wissen, was sich in der Datenbank befindet. Schauen Sie sich diese Tabelle hier an:

Dies sind die Daten von zwei Unternehmen, für die Tests durchgeführt wurden. Die x-Achse ist der Monat, y ist der Prozentsatz der Fehler. Ich habe den Test "Wilde Gesichter" gemacht (direkt unter der Beschreibung).
Eine plötzliche Erhöhung der Genauigkeit um das Zehnfache in zwei unabhängigen Unternehmen (im Allgemeinen starteten alle dort). Woher?
Im NIST-Protokoll heißt es: "Die Datenbank war zu kompliziert, wir haben sie vereinfacht." Und es gibt weder für die alte noch für die neue Basis Beispiele. Meiner Meinung nach ist dies ein schwerwiegender Fehler. Auf der alten Basis war der Unterschied zwischen den Herstelleralgorithmen sichtbar. Auf dem neuen alle 4-8% der Pässe. Und beim alten waren es 29-90%. Meine Kommunikation mit der Gesichtserkennung auf CCTV-Systemen besagt, dass 30% früher - dies war das eigentliche Ergebnis von Großmeister-Algorithmen. Auf solchen Fotos ist es schwer zu erkennen:

Und natürlich scheint 4% Genauigkeit nicht auf sie. Ohne die NIST-Basis zu sehen, ist es jedoch zu 100% unmöglich, solche Aussagen zu treffen. Aber es ist NIST, das die wichtigste unabhängige Datenquelle ist.
In dem Artikel beschreibe ich die für Juli 2018 relevante Situation. Gleichzeitig verlasse ich mich laut der alten Personendatenbank auf Genauigkeit bei Tests im Zusammenhang mit der Aufgabe „Gesichter in freier Wildbahn“.
Es ist möglich, dass sich in einem halben Jahr alles komplett ändern wird. Oder vielleicht wird es in den nächsten zehn Jahren stabil sein.
Also brauchen wir diese Tabelle:
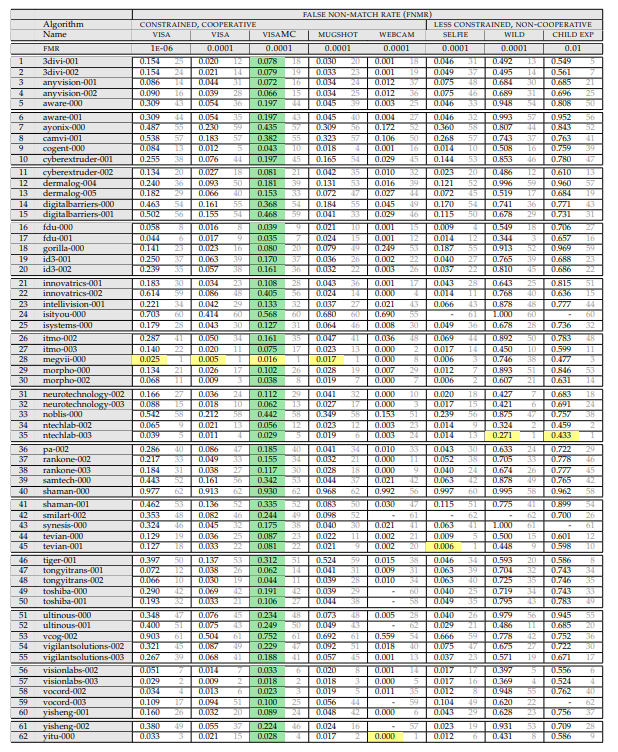
(April 2018, weil Wild hier angemessener ist)
Schauen wir uns an, was darin geschrieben steht und wie es gemessen wird.
Oben ist eine Liste von Experimenten. Das Experiment besteht aus:
Derjenige, an dem das Set gemessen wird. Sets sind:
- Passfoto (ideal, frontal). Der Hintergrund ist weiß, ideale Aufnahmesysteme. Dies kann manchmal am Kontrollpunkt gefunden werden, aber sehr selten. Normalerweise sind solche Aufgaben ein Vergleich einer Person am Flughafen mit der Basis.

- Fotografie ist ein gutes System, aber ohne Spitzenqualität. Es gibt Hintergründe im Hintergrund, eine Person steht möglicherweise nicht gleichmäßig / schaut an der Kamera vorbei usw.

- Selfies von einem Smartphone / einer Computerkamera. Wenn der Benutzer kooperiert, die Aufnahmebedingungen jedoch schlecht sind. Es gibt zwei Untergruppen, aber sie haben nur viele Fotos in Selfies.

- "Gesichter in freier Wildbahn" - Aufnahmen von fast jeder Seite / versteckte Aufnahmen. Die maximalen Drehwinkel des Gesichts zur Kamera betragen 90 Grad. Hier hat NIST die Basis stark vereinfacht.

- Kinder. Alle Algorithmen funktionieren bei Kindern schlecht.
Außerdem wird gemessen, auf welcher Fehlerstufe Fehler der ersten Art gemessen werden (dieser Parameter wird nur für Passfotos berücksichtigt):
- 10 ^ -4 - FAR (ein falsches Positiv der ersten Art) für 10 Tausend Vergleiche mit der Basis
- 10 ^ -6 - FAR (ein falsches Positiv der ersten Art) pro Million Vergleiche mit der Basis
Das Ergebnis des Experiments ist der FRR-Wert. Die Wahrscheinlichkeit, dass wir die Person in der Datenbank verpasst haben.
Und schon hier konnte der aufmerksame Leser den ersten interessanten Punkt bemerken. "Was bedeutet FAR 10 ^ -4?" Und das ist der interessanteste Moment!
Haupt-Setup
Was bedeutet ein solcher Fehler in der Praxis? Dies bedeutet, dass auf der Basis von 10.000 Personen ein irrtümlicher Zufall auftritt, wenn eine durchschnittliche Person darauf überprüft wird. Das heißt, wenn wir eine Basis von 1000 Kriminellen haben und 10.000 Menschen pro Tag damit vergleichen, werden wir durchschnittlich 1000 Fehlalarme haben. Braucht das wirklich jemand?
In Wirklichkeit ist nicht alles so schlecht.
Wenn Sie ein Diagramm über die Abhängigkeit eines Fehlers der ersten Art von einem Fehler der zweiten Art erstellen, erhalten Sie ein so cooles Bild (hier sofort für ein Dutzend verschiedener Unternehmen, für die Option Wild, passiert dies an der U-Bahn-Station, wenn Sie die Kamera irgendwo platzieren, damit die Leute sie nicht sehen). ::
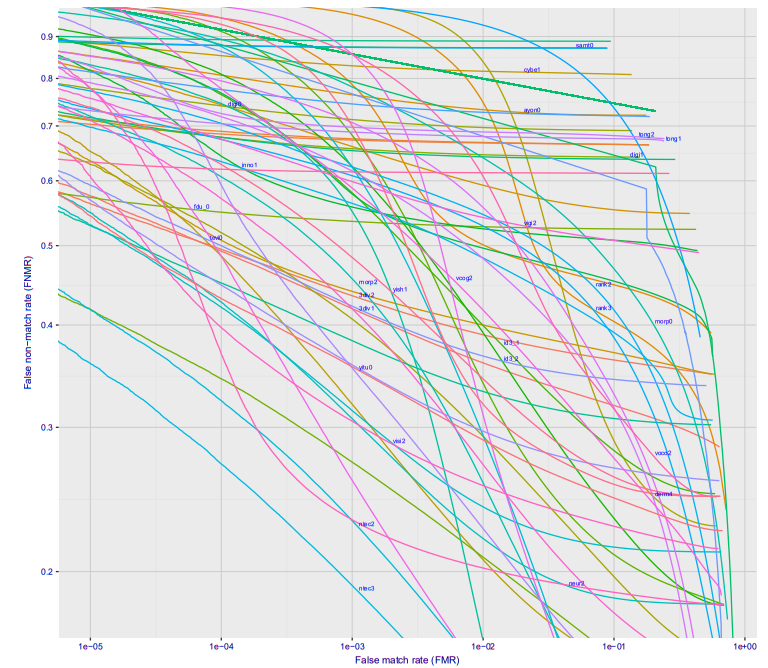
Mit einem 10 ^ -4 Fehler 27% der nicht erkannten Personen. 10 ^ -5 ungefähr 40%. Höchstwahrscheinlich wird ein Verlust von 10 ^ -6 ungefähr 50% betragen
Was bedeutet das in reellen Zahlen?
Es ist am besten, vom Paradigma zu gehen, "wie viele Fehler ein Tag gemacht werden kann". Wir haben einen Strom von Leuten am Bahnhof. Wenn das System alle 20 bis 30 Minuten ein falsches Positiv ausgibt, wird es niemand ernst nehmen. Wir korrigieren die zulässige Anzahl von Fehlalarmen an der U-Bahn-Station auf 10 Personen pro Tag (wenn es gut ist, dass das System nicht als störend ausgeschaltet wird, benötigen Sie noch weniger). Der Fluss einer Station der Moskauer U-Bahn
20-120 Tausend Passagiere pro Tag. Der Durchschnitt liegt bei 60 Tausend.
Der feste Wert von FAR sei 10 ^ -6 (Sie können ihn nicht unten angeben, wir verlieren 50% der Kriminellen, wenn wir optimistisch sind). Dies bedeutet, dass wir 10 Fehlalarme mit einer Basisgröße von 160 Personen zulassen können.
Ist es viel oder wenig? Die Größe der Basis auf der Fahndungsliste des Bundes beträgt ~
300.000 Personen . Interpol 35 Tausend. Es ist logisch anzunehmen, dass etwa 30.000 Moskauer gesucht werden.
Dies führt zu einer unrealistischen Anzahl von Fehlalarmen.
Es ist erwähnenswert, dass 160 Personen eine ausreichende Basis sein können, wenn das System online arbeitet. Wenn Sie nach denen suchen, die am letzten Tag ein Verbrechen begangen haben, ist dies bereits ein ziemliches Arbeitsvolumen. Gleichzeitig können Sie sich mit schwarzen Brillen / Mützen usw. verkleiden. Aber wie viele tragen sie in der U-Bahn?
Der zweite wichtige Punkt. Es ist einfach, ein System in der U-Bahn zu erstellen, das ein Foto von höherer Qualität liefert. Setzen Sie zum Beispiel den Rahmen des Drehkreuzes der Kamera auf. Es wird bereits nicht 50% der Verluste um 10 ^ -6 geben, sondern nur 2-3%. Und um 10 ^ -7 5-10%. Hier die Genauigkeit aus der Grafik auf Visa, bei echten Kameras wird sicherlich alles viel schlechter sein, aber ich denke bei 10 ^ -6 können Sie diesen 10% Verlust belassen:

Auch hier zieht das System nicht die Basis von 30.000, aber alles, was in Echtzeit geschieht, ermöglicht die Erkennung.
Erste Fragen
Es scheint an der Zeit, den ersten Teil der Fragen zu beantworten:
Liksutov
sagte, dass 22 gesuchte Personen identifiziert wurden. Ist das wahr?
Hier ist die Hauptfrage, was diese Personen begangen haben, wie viele unerwünschte Personen überprüft wurden, wie viel Gesichtserkennung bei der Inhaftierung dieser 22 Personen geholfen hat.
Wenn es sich um die Personen handelt, nach denen der Plan zum „Abfangen“ gesucht hat, handelt es sich höchstwahrscheinlich wirklich um Häftlinge. Und das ist ein gutes Ergebnis. Aufgrund meiner bescheidenen Annahmen kann ich jedoch sagen, dass mindestens 2-3.000 Personen überprüft wurden, um dieses Ergebnis zu erzielen, sondern etwa zehntausend.
Es schlägt sehr gut mit den Nummern, die in
London angerufen wurden. Nur dort werden diese Zahlen ehrlich veröffentlicht, da die Leute
protestieren . Und wir schweigen ...
Gestern gab es auf Habré einen Artikel über
falsche Gesichter bei der Gesichtserkennung. Dies ist jedoch ein Beispiel für eine Manipulation in die entgegengesetzte Richtung. Amazon hatte noch nie ein gutes Gesichtserkennungssystem. Plus die Frage, wie man Schwellenwerte festlegt. Ich kann mindestens 100% der Erdnüsse machen, indem ich die Einstellungen verdrehe;)
Über die Chinesen, die jeden auf der Straße erkennen - eine offensichtliche Fälschung. Wenn sie jedoch eine kompetente Nachverfolgung durchgeführt haben, können Sie dort eine adäquatere Analyse durchführen. Aber um ehrlich zu sein, glaube ich nicht, dass dies bisher erreichbar ist. Eher ein Satz Stecker.
Was ist mit meiner Sicherheit? Auf der Straße, bei der Kundgebung?
Gehen wir weiter. Lassen Sie uns einen weiteren Moment bewerten. Suchen Sie nach einer Person mit einer bekannten Biografie und einem guten Profil in sozialen Netzwerken.
NIST überprüft die Erkennung von Angesicht zu Angesicht. Zwei Gesichter derselben / verschiedener Personen werden aufgenommen und verglichen, wie nahe sie beieinander sind. Wenn die Nähe größer als der Schwellenwert ist, ist dies eine Person. Wenn weiter - anders. Es gibt jedoch einen anderen Ansatz.
Wenn Sie die Artikel lesen, die ich zu Beginn empfohlen habe, wissen Sie, dass beim Erkennen eines Gesichts ein Hash-Code des Gesichts generiert wird, der seine Position im N-dimensionalen Raum anzeigt. Normalerweise ist dies ein Raum mit 256/512 Dimensionen, obwohl alle Systeme unterschiedliche Möglichkeiten haben.
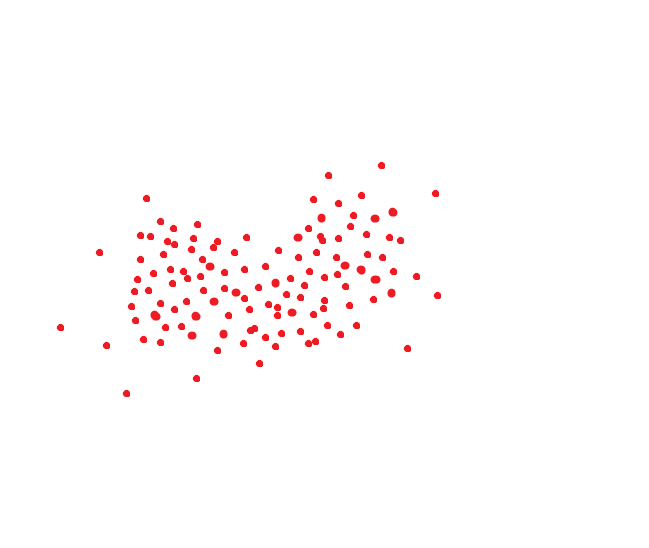
Ein ideales Gesichtserkennungssystem übersetzt dasselbe Gesicht in denselben Code. Es gibt jedoch keine idealen Systeme. Ein und dieselbe Person nimmt normalerweise einen bestimmten Raum ein. Wenn der Code beispielsweise zweidimensional wäre, könnte er ungefähr so aussehen:
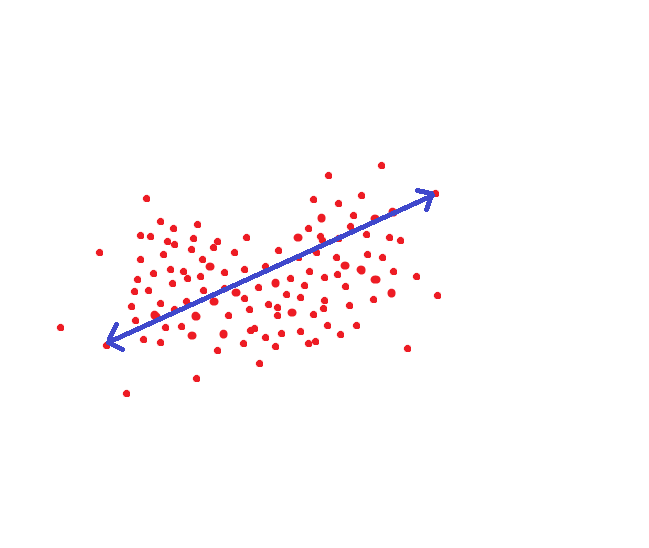
Wenn wir uns an der von NIST angewandten Methode orientieren, wäre diese Entfernung eine Zielschwelle, damit wir eine Person mit einerseits derselben Wahrscheinlichkeit als ein und dieselbe Person erkennen können:
Aber du kannst es anders machen. Konfigurieren Sie für jede Person den Hyperraumbereich, in dem die für sie gültigen Werte gespeichert sind:

Dann verringert sich der Schwellenabstand unter Beibehaltung der Genauigkeit um ein Vielfaches.
Nur brauchen wir viele Fotos für jede Person.
Wenn eine Person ein Profil in sozialen Netzwerken / die Basis ihrer Bilder unterschiedlichen Alters hat, kann die Erkennungsgenauigkeit sehr stark erhöht werden. Ich weiß nicht genau, wie FAR | FRR wächst. Und es ist schon falsch, solche Mengen zu bewerten. Jemand in dieser Datenbank hat 2 Fotos, jemand hat 100. Eine Menge Verpackungslogik. Es scheint mir, dass die maximale Bewertung eineinhalb Bestellungen beträgt. Auf diese Weise können Sie 10 ^ -7 zu Fehlern hinzufügen, mit einer Wahrscheinlichkeit, dass 20-30% nicht erkannt werden. Aber es ist spekulativ und optimistisch.
Im Allgemeinen gibt es natürlich nicht wenige Probleme bei der Verwaltung dieses Bereichs (Alterschips, Bildeditorchips, Rauschchips, Schärfechips), aber meines Wissens wurden die meisten von ihnen bereits von großen Unternehmen erfolgreich gelöst, die eine Lösung benötigten.
Warum mache ich das? Darüber hinaus ermöglicht die Verwendung von Profilen eine mehrfache Erhöhung der Genauigkeit von Erkennungsalgorithmen. Aber es ist alles andere als absolut. Profile erfordern viel manuelle Arbeit. Es gibt viele ähnliche Leute. Wenn Sie jedoch anfangen, Einschränkungen für Alter, Standort usw. festzulegen, können Sie mit dieser Methode eine gute Lösung finden. Als Beispiel dafür, wie sie eine Person nach dem Prinzip "Profil nach Foto suchen" gefunden haben -> "Profil verwenden, um nach einer Person zu suchen", habe ich am Anfang einen
Link angegeben .
Meiner Meinung nach ist dies jedoch ein hoch skalierbarer Prozess. Und wieder, Menschen mit einer großen Anzahl von Bildern im Profil, Gott verbietet 40-50% in unserem Land. Ja, und viele von ihnen sind Kinder, bei denen alles schlecht funktioniert.
Aber auch dies ist eine Einschätzung.
Also. Über Ihre Sicherheit. Je weniger Profilfotos Sie haben, desto besser. Je größer die Rallye, wohin Sie gehen, desto besser. Niemand wird 20.000 Fotos manuell analysieren. Für diejenigen, die sich um ihre Sicherheit und Privatsphäre kümmern - ich würde Ihnen raten, keine Profile mit Ihren Bildern zu erstellen.
Bei einer Kundgebung in einer Stadt mit 100.000 Einwohnern finden sie Sie leicht, wenn sie sich 1-2 Spiele ansehen. In Moskau stecken sie ein wenig fest.
Vor etwa einem halben Jahr hielt
Vasyutka , mit dem wir zusammenarbeiten, einen
Vortrag zu diesem Thema:
Übrigens über soziale Netzwerke
Dann erlaube ich mir einen kleinen Ausflug zur Seite. Die Qualität des Trainings für den Gesichtserkennungsalgorithmus hängt von drei Faktoren ab:
- Die Qualität des Gesichts.
- Verwendete Metrik der Nähe von Personen während des Trainings Triplettverlust, Mittenverlust, sphärischer Verlust usw.
- Basisgröße
Nach Anspruch 2 scheint das Limit nun erreicht zu sein. Grundsätzlich entwickelt sich die Mathematik in solchen Dingen sehr schnell. Und nach dem Triplettverlust ergab der Rest der Verlustfunktionen keine dramatische Zunahme, sondern nur eine sanfte Verbesserung und Abnahme der Größe der Basis.
Die Gesichtsextraktion ist schwierig, wenn Sie Gesichter aus allen Winkeln finden müssen, die einen Bruchteil eines Prozent verloren haben. Das Erstellen eines solchen Algorithmus ist jedoch ein ziemlich vorhersehbarer und gut verwalteter Prozess. Je blauer alles ist, desto besser werden große Winkel richtig verarbeitet:

Und vor sechs Monaten war es so:

Es ist zu sehen, dass sich immer mehr Unternehmen langsam auf diese Weise bewegen und Algorithmen immer mehr gedrehte Gesichter erkennen.
Aber mit der Größe der Basis ist alles interessanter. Offene Basen sind klein. Gute Basis für maximal ein paar Zehntausende Menschen. Diejenigen, die groß sind, sind seltsam strukturiert / schlecht (
Megaface ,
MS-Celeb-1M ).
Woher haben die Entwickler der Algorithmen diese Datenbanken?
Kleiner Hinweis. Das erste NTech-Produkt, das derzeit eingeführt wird
, ist Find Face, eine Kontaktsuche nach Personen. Ich denke, es ist keine Erklärung erforderlich. Kontaktkämpfe mit Bots, die alle offenen Profile entleeren. Aber soweit ich gehört habe, zittern die Leute immer noch. Und Klassenkameraden. Und instagram.
Es scheint wie bei Facebook - dort ist alles komplizierter. Aber ich bin mir fast sicher, dass auch etwas erfunden wurde.
Also ja, wenn dein Profil offen ist - du kannst stolz sein, es wurde verwendet, um Algorithmen zu lernen;)
Über Lösungen und über Unternehmen
Hier können Sie stolz sein. Von den 5 führenden Unternehmen der Welt sind zwei jetzt Russen. Dies sind N-Tech und VisionLabs. Vor einem halben Jahr waren NTech und Vocord die Anführer, die ersteren arbeiteten viel besser auf gedrehten Gesichtern, die letzteren auf den vorderen.
Jetzt hat der Rest der Führer - 1-2 chinesische Unternehmen und 1 Amerikaner, Vocord etwas in den Ratings bestanden.
Immer noch russisch in der Rangliste von itmo, 3divi, Intellivision. Synesis ist eine belarussische Firma, obwohl einige einmal in Moskau waren, hatten sie vor ungefähr 3 Jahren einen Blog über Habré. Ich kenne auch einige Lösungen, die ausländischen Unternehmen gehören, aber die Entwicklungsbüros befinden sich auch in Russland. Es gibt immer noch mehrere russische Unternehmen, die nicht im Wettbewerb stehen, aber gute Lösungen zu haben scheinen. Zum Beispiel haben die MDGs. Natürlich haben Odnoklassniki und Vkontakte auch ihre eigenen guten, aber sie sind für den internen Gebrauch.
Kurz gesagt, ja, wir und die Chinesen sind meistens auf unseren Gesichtern bewegt.
NTech war im Allgemeinen das erste Unternehmen auf der Welt, das gute Parameter auf einem neuen Niveau zeigte. Irgendwann
Ende 2015 . VisionLabs hat nur NTech eingeholt. 2015 waren sie Marktführer. Aber ihre Lösung war von der letzten Generation und sie begannen erst Ende 2016 zu versuchen, NTech einzuholen.
Um ehrlich zu sein, mag ich diese beiden Unternehmen nicht. Sehr aggressives Marketing. Ich sah Leute, die eine eindeutig unangemessene Lösung hatten, die ihre Probleme nicht löste.
Auf dieser Seite mochte ich Vocord viel mehr. Irgendwie riet er den Leuten, denen Vokord sehr ehrlich sagte: "Ihr Projekt wird mit solchen Kameras und Installationspunkten nicht funktionieren." NTech und VisionLabs versuchten glücklich zu verkaufen. Aber etwas Vokord ist kürzlich verschwunden.
Schlussfolgerungen
In den Schlussfolgerungen möchte ich Folgendes sagen.
Die Gesichtserkennung ist ein sehr gutes und leistungsstarkes Werkzeug. Es erlaubt Ihnen wirklich, heute Kriminelle zu finden. Die Implementierung erfordert jedoch eine sehr genaue Analyse aller Parameter. Es gibt Anwendungen, in denen genügend OpenSource-Lösungen vorhanden sind. Es gibt Anwendungen (Anerkennung in Stadien in einer Menschenmenge), in denen Sie nur VisionLabs | Ntech installieren und ein Service-, Analyse- und Entscheidungsteam führen müssen. Und OpenSource wird Ihnen hier nicht helfen.Heute kann man nicht allen Geschichten glauben, dass man alle Kriminellen fangen oder alle in der Stadt beobachten kann. Es ist jedoch wichtig, sich daran zu erinnern, dass solche Dinge dazu beitragen können, Kriminelle zu fangen. Zum Beispiel, um in der U-Bahn nicht alle anzuhalten, sondern nur diejenigen, die das System für ähnlich hält. Positionieren Sie die Kameras so, dass Gesichter besser erkannt werden, und schaffen Sie dafür eine geeignete Infrastruktur. Obwohl ich zum Beispiel dagegen bin. Für den Preis eines Fehlers kann es zu hoch sein, wenn Sie als jemand anderes erkannt werden.