Wir haben bereits im
ersten Artikel unseres Unternehmensblogs darüber geschrieben, wie der Algorithmus zur Erkennung übertragbarer Kredite funktioniert. Nur ein paar Absätze in diesem Artikel widmen sich dem Thema des Vergleichens von Texten, obwohl die Idee eine viel detailliertere Beschreibung verdient. Wie Sie wissen, kann man jedoch nicht sofort über alles erzählen, obwohl man es wirklich will.
Oleg_Bakhteev und ich haben diese Rezension geschrieben, um diesem Thema und der Architektur des Netzwerks namens "
Auto-Encoder ", dem wir sehr herzliche Gefühle entgegenbringen,
Tribut zu zollen .

Quelle:
Deep Learning für NLP (ohne Magie)Wie wir in diesem Artikel erwähnt haben, war der Vergleich von Texten „semantisch“ - wir haben nicht die Textfragmente selbst verglichen, sondern die ihnen entsprechenden Vektoren. Solche Vektoren wurden als Ergebnis des Trainings eines neuronalen Netzwerks erhalten, das ein Textfragment beliebiger Länge in einen Vektor einer großen, aber festen Dimension zeigte. Wie man eine solche Zuordnung erhält und wie man dem Netzwerk beibringt, die gewünschten Ergebnisse zu erzielen, ist ein separates Thema, das weiter unten erörtert wird.
Was ist ein Auto-Encoder?
Formal wird ein neuronales Netzwerk als Auto-Encoder (oder Auto-Encoder) bezeichnet, der trainiert, um am Netzwerkeingang empfangene Objekte wiederherzustellen.
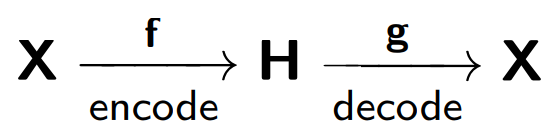
Der Auto-Encoder besteht aus zwei Teilen: einem Encoder
f , der die Probe
X in seine interne Darstellung
H codiert, und einem Decoder
g , der die ursprüngliche Probe wiederherstellt. Daher versucht der Autocoder, die wiederhergestellte Version jedes Beispielobjekts mit dem ursprünglichen Objekt zu kombinieren.
Beim Training eines Auto-Encoders wird die folgende Funktion minimiert:
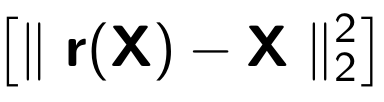
Wobei
r für die wiederhergestellte Version des Originalobjekts steht:

Betrachten Sie das Beispiel in
blog.keras.io :

Das Netzwerk empfängt ein Objekt
x als Eingabe (in unserem Fall die Nummer 2).
Unser Netzwerk verschlüsselt dieses Objekt in einen verborgenen Zustand. Dann wird gemäß dem latenten Zustand die Rekonstruktion des Objekts
r wiederhergestellt, die x ähnlich sein sollte. Wie wir sehen, ist das wiederhergestellte Bild (rechts) verschwommener geworden. Dies erklärt sich aus der Tatsache, dass wir versuchen, nur die wichtigsten Zeichen des Objekts in einer verborgenen Ansicht zu halten, sodass das Objekt mit Verlusten wiederhergestellt wird.
Das Autocoder-Modell ist nach dem Prinzip eines beschädigten Telefons trainiert, bei dem eine Person (Encoder) Informationen
(x ) an die zweite Person (Decoder) überträgt und diese wiederum an die dritte Person
(r (x)) weiterleitet .
Einer der Hauptzwecke solcher Auto-Encoder besteht darin, die Dimension des Quellraums zu verringern. Wenn es sich um Auto-Encoder handelt, merkt sich das Auto-Encoder durch das Trainingsverfahren für neuronale Netze selbst die Hauptmerkmale von Objekten, von denen es einfacher ist, die ursprünglichen Beispielobjekte wiederherzustellen.
Hier können wir eine Analogie zur
Methode der Hauptkomponenten ziehen : Dies ist eine Methode zur Reduzierung der Dimension, deren Ergebnis die Projektion der Probe auf einen Unterraum ist, in dem die Varianz dieser Probe maximal ist.
In der Tat ist der Auto-Encoder eine Verallgemeinerung der Hauptkomponentenmethode: Wenn wir uns auf die Betrachtung linearer Modelle beschränken, geben der Auto-Encoder und die Hauptkomponentenmethode die gleichen Vektordarstellungen. Der Unterschied ergibt sich, wenn wir komplexere Modelle, beispielsweise mehrschichtige, vollständig verbundene neuronale Netze, als Codierer und Decodierer betrachten.
Ein Beispiel für einen Vergleich der Hauptkomponentenmethode und des Auto-Encoders finden Sie im Artikel
Reduzieren der Dimensionalität von Daten mit neuronalen Netzen :
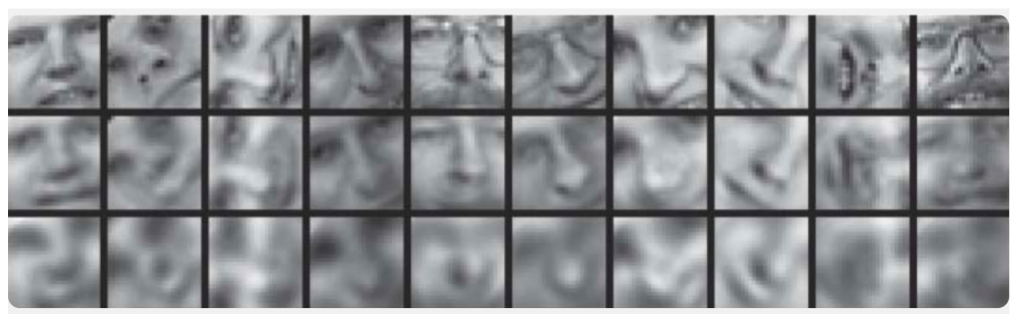
Hier werden die Ergebnisse des Trainings des Auto-Encoders und der Hauptkomponentenmethode zum Abtasten von Bildern menschlicher Gesichter demonstriert. Die erste Zeile zeigt die Gesichter von Personen aus der Kontrollprobe, d.h. aus einem speziell zurückgestellten Teil der Stichprobe, der von den Algorithmen im Lernprozess nicht verwendet wurde. In der zweiten und dritten Zeile befinden sich die wiederhergestellten Bilder aus den verborgenen Zuständen des Auto-Encoders bzw. der Hauptkomponentenmethode derselben Dimension. Hier können Sie deutlich sehen, wie viel besser der Auto-Encoder funktioniert hat.
Im selben Artikel ein weiteres anschauliches Beispiel: Vergleich der Ergebnisse des Auto-Encoders und der
LSA- Methode für die Aufgabe des Informationsabrufs. Die LSA-Methode ist wie die Hauptkomponentenmethode eine klassische Methode des maschinellen Lernens und wird häufig bei Aufgaben im Zusammenhang mit der Verarbeitung natürlicher Sprache verwendet.

Die Abbildung zeigt eine 2D-Projektion mehrerer Dokumente, die mit dem Auto-Encoder und der LSA-Methode erstellt wurden. Farben geben das Thema des Dokuments an. Es ist ersichtlich, dass die Projektion vom Auto-Encoder Dokumente gut nach Themen aufschlüsselt, während der LSA ein viel lauteres Ergebnis erzeugt.
Eine weitere wichtige Anwendung von Auto-
Encodern ist das Netzwerk-Pre-Training . Das Netzwerk-Pre-Training wird verwendet, wenn das optimierte Netzwerk tief genug ist. In diesem Fall kann es ziemlich schwierig sein, das Netzwerk „von Grund auf neu“ zu trainieren. Daher wird zunächst das gesamte Netzwerk als eine Kette von Encodern dargestellt.
Der Pre-Training-Algorithmus ist recht einfach: Für jede Schicht trainieren wir unseren eigenen Auto-Encoder und stellen dann ein, dass der Ausgang des nächsten Encoders gleichzeitig der Eingang für die nächste Netzwerkschicht ist. Das resultierende Modell besteht aus einer Kette von Encodern, die darauf trainiert sind, die wichtigsten Merkmale von Objekten eifrig auf ihrer eigenen Ebene zu erhalten. Das Vorschulungsprogramm wird im Folgenden vorgestellt:
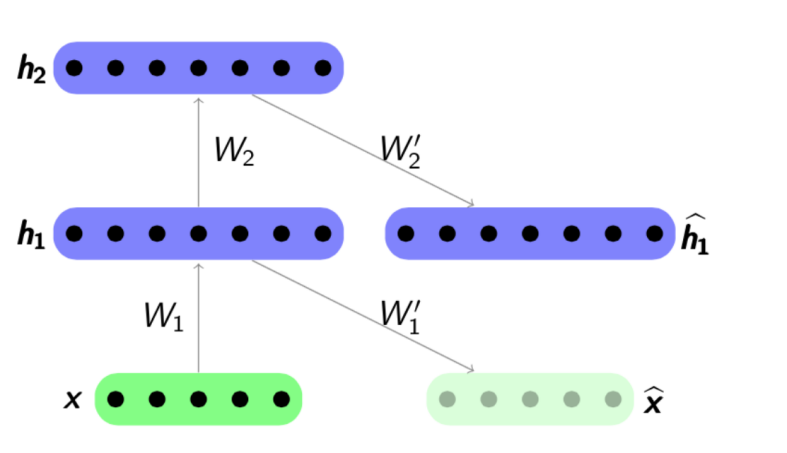
Quelle:
psyyz10.imtqy.comDiese Struktur wird als gestapelter Autoencoder bezeichnet und häufig als „Übertaktung“ verwendet, um das vollständige Deep-Network-Modell weiter zu trainieren. Die Motivation für ein solches Training eines neuronalen Netzwerks besteht darin, dass ein tiefes neuronales Netzwerk eine nicht konvexe Funktion ist: Während des Trainings eines Netzwerks kann die Optimierung von Parametern in einem lokalen Minimum „stecken bleiben“. Durch das gierige Vortraining von Netzwerkparametern können Sie einen guten Ausgangspunkt für das endgültige Training finden und versuchen, solche lokalen Minima zu vermeiden.
Natürlich haben wir nicht alle möglichen Strukturen berücksichtigt, da es
Sparse Autoencoder ,
Denoising Autoencoder ,
Contractive Autoencoder und
Reconstruction Contractive Autoencoder gibt . Sie unterscheiden sich untereinander durch die Verwendung verschiedener Fehlerfunktionen und Strafbegriffe. Alle diese Architekturen verdienen unserer Meinung nach eine gesonderte Prüfung. In unserem Artikel zeigen wir zunächst das allgemeine Konzept von Auto-Encodern und die spezifischen Aufgaben der Textanalyse, die damit gelöst werden.
Wie funktioniert es in Texten?
Wir wenden uns nun spezifischen Beispielen für die Verwendung von Autocodern für Textanalyse-Aufgaben zu. Wir interessieren uns für beide Seiten der Anwendung - beide Modelle zum Erhalten interner Darstellungen und die Verwendung dieser internen Darstellungen als Attribute, zum Beispiel für das weitere Klassifizierungsproblem. In Artikeln zu diesem Thema werden häufig Aufgaben wie die Stimmungsanalyse oder die Erkennung von Umformulierungen behandelt. Es gibt jedoch auch Arbeiten, die die Verwendung von Auto-Encodern zum Vergleichen von Texten in verschiedenen Sprachen oder zur maschinellen Übersetzung beschreiben.
Bei den Aufgaben der Textanalyse ist das Objekt meistens der Satz, d.h. geordnete Folge von Wörtern. Somit empfängt der Auto-Encoder genau diese Folge von Wörtern oder vielmehr Vektordarstellungen dieser Wörter, die aus einem zuvor trainierten Modell stammen. Was sind Vektordarstellungen von Wörtern, wurde Habré beispielsweise
hier hinreichend detailliert betrachtet. Daher muss der Auto-Encoder, der eine Folge von Wörtern als Eingabe verwendet, eine interne Darstellung des gesamten Satzes trainieren, die den für uns wichtigen Merkmalen entspricht, basierend auf der Aufgabe. Bei Problemen der Textanalyse müssen wir Sätze Vektoren so zuordnen, dass sie im Sinne einer Distanzfunktion nahe sind, meistens ein Kosinusmaß:
Quelle:
Deep Learning für NLP (ohne Magie)Einer der ersten Autoren, der den erfolgreichen Einsatz von Auto-Encodern in der Textanalyse zeigte, war
Richard Socher .
In seinem Artikel
Dynamisches Pooling und Entfalten rekursiver Autoencoder für die Paraphrase-Erkennung beschreibt er eine neue Autocodierungsstruktur - Entfalten rekursiver Autoencoder (Unfolding RAE) (siehe Abbildung unten).

RAE entfalten
Es wird angenommen, dass die Satzstruktur von einem
syntaktischen Parser definiert wird. Die einfachste Struktur wird betrachtet - die Struktur eines Binärbaums. Ein solcher Baum besteht aus Blättern - Wörtern eines Fragments, internen Knoten (Verzweigungsknoten) - Phrasen und einem Endscheitelpunkt. Unter Verwendung der Folge von Wörtern (x
1 , x
2 , x
3 ) als Eingabe (drei Vektordarstellungen von Wörtern in diesem Beispiel) codiert der Autocoder in diesem Fall sequentiell von rechts nach links Vektordarstellungen von Satzwörtern in Vektordarstellungen von Phrasen und dann in Vektoren Präsentation des gesamten Angebots. Insbesondere verketten wir in diesem Beispiel zuerst die Vektoren x
2 und x
3 und multiplizieren sie dann mit der Matrix
W e mit der
verborgenen Dimension
× 2 , wobei
versteckt die Größe der verborgenen internen Darstellung ist,
sichtbar ist die Dimension des
Wortvektors . Daher reduzieren wir die Dimension und fügen dann mithilfe der tanh-Funktion Nichtlinearität hinzu. Im ersten Schritt erhalten wir eine versteckte Vektordarstellung für die Phrase zwei Wörter
x 2 und
x 3 :
h 1 =
tanh (W e [x 2 , x 3 ] + b e ) . Im zweiten kombinieren wir es und das verbleibende Wort
h 2 =
tanh (W e [h 1 , x 1 ] + b e ) und erhalten eine Vektordarstellung für den gesamten Satz -
h 2 . Wie oben erwähnt, müssen wir bei der Definition eines Auto-Encoders den Fehler zwischen Objekten und ihren wiederhergestellten Versionen minimieren. In unserem Fall sind dies Wörter. Nachdem wir die endgültige Vektordarstellung des gesamten Satzes
h 2 erhalten haben , werden wir seine wiederhergestellten Versionen (x
1 ', x
2 ', x
3 ') dekodieren. Der Decoder arbeitet hier nach dem gleichen Prinzip wie der Encoder, nur die Parametermatrix und der Verschiebungsvektor unterscheiden sich hier:
W d und
b d .
Mit der Struktur eines Binärbaums können Sie Sätze beliebiger Länge in einen Vektor fester Dimension codieren. Wir kombinieren immer ein Vektorpaar derselben Dimension mit derselben Parametermatrix
W e . Im Fall eines nicht-binären Baums müssen Sie die Matrizen nur im Voraus initialisieren, wenn Sie mehr als zwei Wörter kombinieren möchten - 3, 4, ... n. In diesem Fall hat die Matrix nur die
verborgene Dimension
× unsichtbar .
Es ist bemerkenswert, dass in diesem Artikel trainierte Vektordarstellungen von Phrasen nicht nur zur Lösung des Klassifizierungsproblems verwendet werden - einige Sätze werden umformuliert oder nicht. Die Daten eines Experiments zur Suche nach den nächsten Nachbarn werden ebenfalls dargestellt - nur basierend auf dem empfangenen Angebotsvektor werden die nächsten Vektoren in der Stichprobe gesucht, deren Bedeutung nahe beieinander liegt:

Niemand stört uns jedoch, andere Netzwerkarchitekturen zum Codieren und Decodieren zu verwenden, um Wörter nacheinander zu Sätzen zu kombinieren.
Hier ist ein Beispiel aus einem NIPS 2017-Artikel -
Deconvolutional Paragraph Representation Learning :

Wir sehen, dass die Codierung der Probe
X in die verborgene Darstellung
h unter Verwendung eines
Faltungs-Neuronalen Netzwerks erfolgt und der Decodierer nach dem gleichen Prinzip arbeitet.
Oder hier ist ein Beispiel für die Verwendung von
GRU-GRU im Artikel
Überspringen von Gedankenvektoren .
Ein interessantes Merkmal hierbei ist, dass das Modell mit dreifachen Sätzen arbeitet: (
s i-1 , s i , s i + 1 ). Der Satz
s i wird unter Verwendung von Standard-GRU-Formeln codiert, und der Decodierer versucht unter Verwendung der internen Darstellungsinformationen
s i ,
s i-1 und
s i + 1 ebenfalls unter Verwendung von GRU zu decodieren.

Das Funktionsprinzip ähnelt in diesem Fall dem Standardmodell der
maschinellen Übersetzung neuronaler Netze , das nach dem Encoder-Decoder-Schema arbeitet. Da wir hier jedoch keine zwei Sprachen haben, senden wir eine Phrase in einer Sprache an die Eingabe unserer Codiereinheit und versuchen, sie wiederherzustellen. Während des Lernprozesses werden einige interne Qualitätsfunktionen minimiert (dies ist nicht immer ein Rekonstruktionsfehler). Bei Bedarf werden vorab trainierte Vektoren als Merkmale in einem anderen Problem verwendet.
In einem weiteren
Artikel ,
Zweisprachige rekursive Autoencoder für die statistische maschinelle Übersetzung , wird eine Architektur vorgestellt, die einen neuen Blick auf die maschinelle Übersetzung wirft. Zunächst werden rekursive Autocoder für zwei Sprachen separat trainiert (gemäß dem oben beschriebenen Prinzip - wo Unfolding RAE eingeführt wurde). Dann wird zwischen ihnen ein dritter Auto-Encoder trainiert - eine Zuordnung zwischen zwei Sprachen. Eine solche Architektur hat einen klaren Vorteil: Wenn Sie Texte in verschiedenen Sprachen in einem gemeinsamen verborgenen Raum anzeigen, können Sie sie vergleichen, ohne die maschinelle Übersetzung als Zwischenschritt zu verwenden.
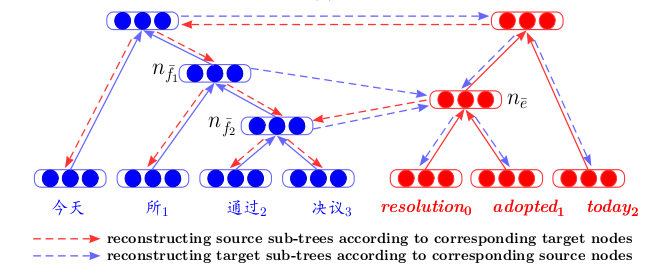
Das Training von Auto-Encodern für Textfragmente findet sich häufig in Artikeln zum
Ranking-Training . Auch hier ist die Tatsache wichtig, dass wir die endgültige Funktion der Qualität des Rankings trainieren. Wir trainieren zuerst den Auto-Encoder, um die Vektoren der an die Netzwerkeingabe gesendeten Anforderungen und Antworten besser zu initialisieren.

Und natürlich können wir
Variational Autoencoder oder
VAEs nur als generative Modelle erwähnen. Am besten sehen Sie sich natürlich nur
diesen Vortragseintrag von Yandex an . Es reicht aus, Folgendes zu sagen: Wenn wir Objekte aus dem verborgenen Raum eines herkömmlichen Auto-Encoders
erzeugen möchten, ist die Qualität einer solchen Erzeugung gering, da wir nichts über die Verteilung der verborgenen Variablen wissen. Sie können den Auto-Encoder jedoch sofort auf die Generierung trainieren und eine Verteilungsannahme einführen.
Und dann können Sie mit VAE Texte aus diesem verborgenen Raum generieren, wie es beispielsweise die Autoren des Artikels
Generieren von Sätzen aus einem kontinuierlichen Raum oder
einem hybriden Faltungsvariations-Autoencoder für die Texterzeugung tun .
Die generativen Eigenschaften von VAE eignen sich auch gut für Aufgaben, bei denen Texte in verschiedenen Sprachen verglichen werden.
Ein Ansatz zur variablen automatischen Codierung zur Induzierung mehrsprachiger Worteinbettungen ist ein hervorragendes Beispiel dafür.
Abschließend möchten wir eine kleine Prognose abgeben.
Repräsentationslernen - Das Training in internen Repräsentationen mit genau VAE, insbesondere in Verbindung mit den
Generative Adversarial Networks , ist einer der am weitesten entwickelten Ansätze der letzten Jahre. Dies lässt sich anhand der häufigsten
Artikelthemen der neuesten Top-
ICLR 2018-Konferenzen zum maschinellen Lernen beurteilen und
ICML 2018 . Dies ist ziemlich logisch, da seine Verwendung dazu beigetragen hat, die Qualität bei einer Reihe von Aufgaben zu verbessern, und nicht nur bei Texten. Aber das ist das Thema einer ganz anderen Rezension ...