Massachusetts Institute of Technology. Vorlesung # 6.858. "Sicherheit von Computersystemen." Nikolai Zeldovich, James Mickens. 2014 Jahr
Computer Systems Security ist ein Kurs zur Entwicklung und Implementierung sicherer Computersysteme. Die Vorträge behandeln Bedrohungsmodelle, Angriffe, die die Sicherheit gefährden, und Sicherheitstechniken, die auf jüngsten wissenschaftlichen Arbeiten basieren. Zu den Themen gehören Betriebssystemsicherheit, Funktionen, Informationsflussmanagement, Sprachsicherheit, Netzwerkprotokolle, Hardwaresicherheit und Sicherheit von Webanwendungen.
Vorlesung 1: „Einführung: Bedrohungsmodelle“
Teil 1 /
Teil 2 /
Teil 3Vorlesung 2: „Kontrolle von Hackerangriffen“
Teil 1 /
Teil 2 /
Teil 3Vorlesung 3: „Pufferüberläufe: Exploits und Schutz“
Teil 1 /
Teil 2 /
Teil 3Vorlesung 4: „Trennung von Privilegien“
Teil 1 /
Teil 2 /
Teil 3Vorlesung 5: „Woher kommen Sicherheitssysteme?“
Teil 1 /
Teil 2Vorlesung 6: „Chancen“
Teil 1 /
Teil 2 /
Teil 3Vorlesung 7: „Native Client Sandbox“
Teil 1 /
Teil 2 /
Teil 3 In Regel
C4 gibt es eine Einschränkung. Sie können nicht über das Ende eines Programms "springen". Das Letzte, zu dem Sie springen können, ist die letzte Anweisung. Diese Regel garantiert also, dass bei der Ausführung des Programms in der Prozess-Engine keine Diskrepanz auftritt.
Regel
C5 besagt, dass es keine Anweisungen geben darf, die größer als 32 Byte sind. Wir haben eine bestimmte Version dieser Regel in Betracht gezogen, als wir über die Vielzahl der Befehlsgrößen bis 32 Byte gesprochen haben. Andernfalls können Sie in die Mitte des Befehls springen und ein Problem mit dem Systemaufruf verursachen, der sich dort "verstecken" kann.
Regel
C6 besagt, dass alle verfügbaren Anweisungen von Anfang an zerlegt werden können. Dies stellt somit sicher, dass wir jede Anweisung sehen und alle Anweisungen überprüfen können, die ausgeführt werden, wenn das Programm ausgeführt wird.
Regel
C7 besagt, dass alle direkten Sprünge korrekt sind. Sie springen beispielsweise direkt zu dem Teil der Anweisung, in dem das Ziel angegeben ist, und obwohl es kein Vielfaches von 32 ist, ist es immer noch die richtige Anweisung, auf die die Demontage von links nach rechts angewendet wird.
 Teilnehmerin:
Teilnehmerin: Was ist der Unterschied zwischen
C5 und
C3 ?
Professor: Ich denke,
C5 sagt, dass ein Multibyte-Befehl die Grenzen benachbarter Adressen nicht überschreiten kann. Angenommen, ich habe einen Befehlsstrom und es gibt eine Adresse 32 und eine Adresse 64. Ein Befehl kann also das Grenzmultiplikator von 32 Bytes nicht überschreiten, dh er darf nicht mit einer Adresse kleiner als 64 beginnen und mit einer Adresse größer als 64 enden.

Dies ist, was Regel
C5 sagt. Denn andernfalls können Sie nach einem Sprung der Multiplizität 32 in die Mitte eines anderen Befehls gelangen, bei dem nicht bekannt ist, was passiert.
Und Regel
C3 ist ein Analogon zu diesem Verbot auf der Seite des Sprunges. Es besagt, dass bei jedem Sprung die Länge Ihres Sprungs ein Vielfaches von 32 sein muss.
C5 behauptet auch, dass alles im Adressbereich, das ein Vielfaches von 32 ist, eine sichere Anweisung ist.
Nachdem ich die Liste dieser Regeln gelesen hatte, hatte ich ein gemischtes Gefühl, da ich nicht beurteilen konnte, ob diese Regeln ausreichend sind, dh die Liste ist minimal oder vollständig.
Denken wir also über die Hausaufgaben nach, die Sie erledigen müssen. Ich denke, dass tatsächlich ein Fehler im Betrieb des
nativen Clients vorliegt, wenn einige komplizierte Anweisungen in der Sandbox ausgeführt werden. Ich glaube, dass sie nicht die richtige Längencodierung hatten, was zu etwas Schlechtem führen könnte, aber ich kann mich nicht genau erinnern, was der Fehler war.
Angenommen, ein Sandbox-Validator erhält fälschlicherweise die Länge einer Anweisung. Was kann in diesem Fall passieren? Wie würden Sie diesen Slip verwenden?
Zielgruppe: Sie können beispielsweise den Systemaufruf oder die return-Anweisung
ret ausblenden.
Professor: Ja. Angenommen, es gibt eine ausgefallene Version der
AND- Anweisung, die Sie aufgeschrieben haben. Es ist möglich, dass der Validator sich geirrt hat und angenommen hat, dass seine Länge 6 Bytes mit der tatsächlichen Länge von 5 Bytes beträgt.
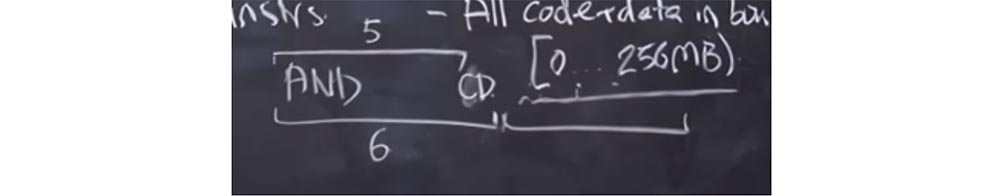
Was wird passieren? Der Validator betrachtet die Länge dieses Befehls als 6 Bytes und hat einen anderen gültigen Befehl dahinter. Der Prozessor verwendet jedoch beim Starten des Codes die tatsächliche Länge des Befehls, d. H. 5 Bytes. Infolgedessen haben wir am Ende der
AND- Anweisung ein freies Byte, in das wir einen Systemaufruf einfügen und zu unserem Vorteil verwenden können. Und wenn wir hier ein
CD- Byte einlegen, ist dies wie der Beginn einer anderen Anweisung. Als nächstes werden wir etwas in die nächste 6-Byte-Spanne einfügen, und es wird wie eine Anweisung aussehen, die mit dem
CD- Byte beginnt, obwohl es tatsächlich Teil der
AND- Anweisung ist. Danach können wir einen Systemaufruf tätigen und aus der Sandbox "entkommen".
Daher muss der
Native Client- Validator seine Aktionen mit den Aktionen der
CPU synchronisieren, dh genau erraten, wie der Prozessor jeden Befehl interpretiert. Und dies sollte auf jeder Ebene der Sandbox sein, was ziemlich schwierig zu implementieren ist.
In der Tat gibt es andere interessante Fehler im
Native Client . Eine davon ist die falsche Bereinigung der Prozessorumgebung beim Sprung in die
Trusted Service Runtime . Ich denke, wir werden gleich darüber sprechen. Die
Trusted Service Runtime funktioniert jedoch grundsätzlich mit denselben
CPU- Registern, mit denen nicht vertrauenswürdige Module ausgeführt werden können. Wenn der Prozessor vergisst, etwas zu löschen oder neu zu starten, kann die Laufzeit dadurch beeinträchtigt werden, dass das unzuverlässige Modul als vertrauenswürdige Anwendung betrachtet wird und etwas getan wird, das nicht hätte getan werden sollen oder das nicht die Absicht der Entwickler war.
Wo sind wir jetzt? Im Moment verstehen wir, wie man alle Anweisungen zerlegt und wie man die Ausführung verbotener Anweisungen verhindert. Nun wollen wir sehen, wie wir Speicher und Links für Code und Daten im
Native Client- Modul speichern.
Aus Leistungsgründen beginnen die
Native Client- Mitarbeiter, Hardware-Unterstützung zu verwenden, um sicherzustellen, dass das Speichern von Speicher und Links nicht wirklich viel Aufwand verursacht. Bevor ich jedoch über die von ihnen verwendete Hardwareunterstützung nachdenke, möchte ich Vorschläge hören. Wie könnte ich dasselbe ohne die Hardwareunterstützung tun? Können wir nur Zugriff auf alle Speicherprozesse innerhalb der zuvor von der Maschine festgelegten Grenzen gewähren?
Zielgruppe: Sie können Anweisungen instrumentieren, um alle hohen Bits zu löschen.
 Professor:
Professor: Ja, das ist richtig. Tatsächlich sehen wir, dass wir diese
UND- Anweisung hier haben, und jedes Mal, wenn wir zum Beispiel irgendwohin springen, werden die niedrigen Bits gelöscht. Wenn wir jedoch den gesamten möglichen Code behalten möchten, der innerhalb der niedrigen 256 MB ausgeführt wird, können wir einfach das erste Attribut
f durch
0 ersetzen und
$ 0x0fffffe0 anstelle von
$ 0xffffffe0 erhalten . Dies löscht die unteren Bits und legt eine Obergrenze von 256 MB fest.
Dies macht also genau das, was Sie anbieten, und stellt sicher, dass Sie sich bei jedem Sprung innerhalb von 256 MB befinden. Und die Tatsache, dass wir die Demontage durchführen, ermöglicht es auch zu überprüfen, ob alle direkten Sprünge in Reichweite sind.
Der Grund, warum sie dies für ihren Code nicht tun, ist, dass Sie auf der
x86- Plattform
AND sehr effektiv codieren können, wobei alle oberen Bits 1 sind. Dies führt zur Existenz eines 3-Byte-Befehls für
AND und eines 2-Byte-Befehls für den Sprung. Somit haben wir einen zusätzlichen Aufwand von 3 Bytes. Wenn Sie jedoch ein High-Bit ohne Einheit benötigen, wie diese
0 anstelle von
f , haben Sie plötzlich einen 5-Byte-Befehl. Daher denke ich, dass sie sich in diesem Fall Sorgen um den Overhead machen.
Zielgruppe: Gibt es ein Problem mit der Existenz einiger Anweisungen, die die Version erhöhen, die Sie erhalten möchten? Das heißt, Sie können sagen, dass Ihre Anweisung eine konstante Tendenz oder so etwas haben kann?
Professor: Ich denke schon. Sie werden wahrscheinlich Anweisungen verbieten, die zu einer komplexen Adressformel springen, und nur Anweisungen unterstützen, die direkt zu diesem Wert springen, und dieser Wert erhält immer
AND .
Zielgruppe: Für den Zugriff auf den Speicher ist mehr erforderlich als ...
Professor: Ja, weil es nur Code ist. Und für den Zugriff auf Speicher auf der
x86- Plattform gibt es viele seltsame Möglichkeiten, auf einen bestimmten Speicherort zuzugreifen. Normalerweise müssen Sie zuerst den Speicherort berechnen, dann ein zusätzliches
UND hinzufügen und erst dann darauf zugreifen. Ich denke, dies ist der wahre Grund für ihre Besorgnis über den Leistungsabfall aufgrund der Verwendung dieses Toolkits.
Auf der
x86- Plattform oder zumindest auf der im Artikel beschriebenen 32-Bit-Plattform verwenden sie Hardwareunterstützung, anstatt die Code- und Adressdaten einzuschränken, die auf nicht vertrauenswürdige Module verweisen.
Lassen Sie uns sehen, wie es aussieht, bevor wir herausfinden, wie das
NaCl- Modul in einer Sandbox verwendet wird. Diese Hardware wird als Segmentierung bezeichnet. Es entstand noch bevor die
x86- Plattform eine Auslagerungsdatei bekam. Auf der
x86- Plattform ist während des Vorgangs eine unterstützte Hardwaretabelle vorhanden. Wir nennen es die Tabelle der Segmentdeskriptoren. Es handelt sich um eine Reihe von Segmenten, die von 0 bis zum Ende einer Tabelle beliebiger Größe nummeriert sind. Dies ist so etwas wie ein Dateideskriptor unter
Unix , außer dass jeder Eintrag aus zwei Werten besteht: der
Basisbasis und der Länge.
Diese Tabelle sagt uns, dass wir ein Paar von Segmenten haben, und jedes Mal, wenn wir uns auf ein bestimmtes Segment beziehen, bedeutet dies in gewissem Sinne, dass es sich um ein Stück Speicher handelt, das an der Basisadresse der
Basis beginnt und sich über die Länge
erstreckt .

Dies hilft uns, die Speichergrenzen auf der
x86- Plattform
beizubehalten , da jeder Befehl, der auf den Speicher zugreift, auf ein bestimmtes Segment in dieser Tabelle verweist.
Wenn wir beispielsweise
mov (% eax) (% ebx) ausführen
, dh den Speicherwert von einem im
EAX- Register gespeicherten Zeiger auf einen anderen im
EBX- Register gespeicherten Zeiger verschieben, weiß das Programm, wie die Start- und Endadressen lauten im Hinblick auf und speichert den Wert in der zweiten Adresse.
Tatsächlich gibt es auf der
x86- Plattform, wenn wir über Speicher sprechen, eine implizite Sache, die als Segmentdeskriptor bezeichnet wird, ähnlich einem Dateideskriptor in
Unix . Dies ist nur ein Index in der Deskriptortabelle. Sofern nicht anders angegeben, enthält jeder Operationscode ein Standardsegment.
Wenn Sie
mov (% eax) ausführen, bezieht sich dies daher auf
% ds oder auf das Datensegmentregister, das ein spezielles Register in Ihrem Prozessor ist. Wenn ich mich richtig erinnere, ist es eine 16-Bit-Ganzzahl, die auf diese Deskriptortabelle verweist.
Das Gleiche gilt für
(% ebx) - es bezieht sich auf denselben
% ds- Segmentselektor. Tatsächlich haben wir in
x86 eine Gruppe von 6 Code-Selektoren:
CS, DS, ES, FS, GS und
SS . Der
CS-Anrufwähler wird implizit zum Empfangen von Anweisungen verwendet. Wenn Ihr Anweisungszeiger also auf etwas zeigt, bezieht er sich auf denjenigen, der den
CS- Segment-Selektor ausgewählt hat.
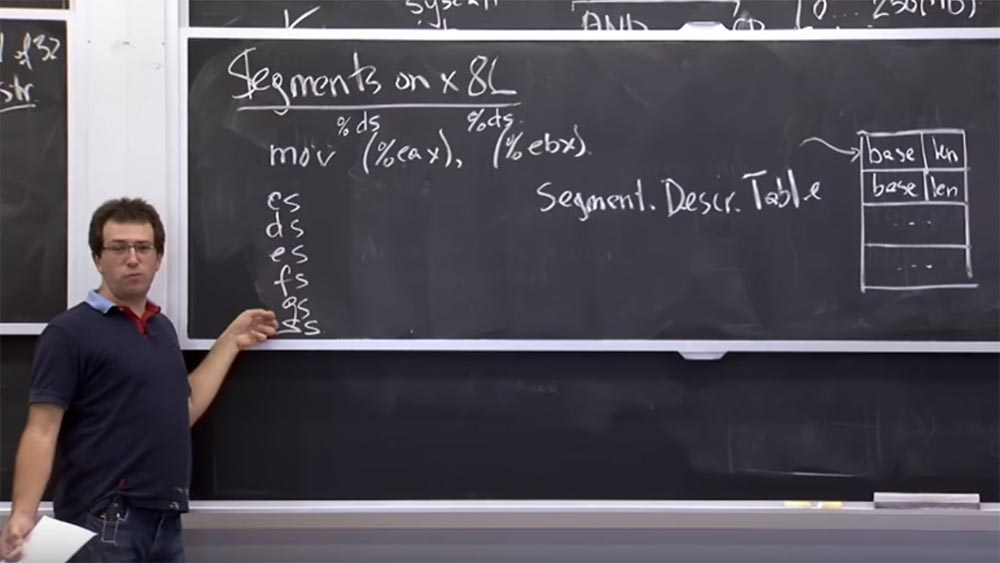
Die meisten Datenreferenzen verwenden implizit
DS oder
ES ,
FS und
GS weisen auf einige besondere Dinge hin, und
SS wird immer für Stapeloperationen verwendet. Und wenn Sie
Push & Pop ausführen, stammen diese implizit aus dieser Segmentauswahl. Dies ist eine ziemlich archaische Mechanik, die sich jedoch in diesem speziellen Fall als äußerst nützlich herausstellt.
Wenn Sie beispielsweise im Selektor
% ds: addr Zugriff auf eine Adresse erhalten,
leitet die Hardware diese mit der Tabelle
adrr + T [% ds] .base an die Operation
weiter . Dies bedeutet, dass die Adresslänge des Moduls aus derselben Tabelle stammt. Jedes Mal, wenn Sie auf den Speicher zugreifen, verfügt er über eine Datenbank mit Segmentselektoren in Form von Deskriptortabelleneinträgen. Die von Ihnen angegebene Adresse wird mit der Länge des entsprechenden Segments abgeglichen.
Zielgruppe: Warum wird es beispielsweise nicht zum Schutz des Puffers verwendet?
Professor: Ja, das ist eine gute Frage! Könnten wir dies zum Schutz vor Pufferüberläufen verwenden? Zum Beispiel können Sie für jeden Puffer, den wir haben, die Pufferbasis hier und dort die Puffergröße einfügen.
Teilnehmerin: Was ist, wenn Sie es nicht in eine Tabelle legen müssen, bevor Sie es schreiben möchten? Sie müssen nicht ständig da sein.
Professor: Ja. Daher denke ich, dass der Grund dafür, dass dieser Ansatz nicht oft zum Schutz vor Pufferüberläufen verwendet wird, darin besteht, dass die Anzahl der Datensätze in dieser Tabelle 2 in der 16. Potenz nicht überschreiten kann, da Deskriptoren 16 Bit lang sind, aber tatsächlich Tatsächlich werden ein paar weitere Bits für andere Dinge verwendet. Tatsächlich können Sie in dieser Tabelle nur 2 in der 13. Potenz der Datensätze platzieren. Wenn Sie in Ihrem Code ein Datenarray haben, das größer als 2
13 ist , kann es daher zu einem Überlauf dieser Tabelle kommen.
Darüber hinaus wäre es für den Compiler seltsam, diese Tabelle direkt zu verwalten, da sie normalerweise mithilfe von Systemaufrufen bearbeitet wird. Sie können nicht direkt in diese Tabelle schreiben. Zuerst müssen Sie einen Systemaufruf an das Betriebssystem senden. Danach legt das Betriebssystem den Datensatz in dieser Tabelle ab. Daher denke ich, dass die meisten Compiler einfach nicht mit einem so komplexen Speicherpuffer-Managementsystem umgehen wollen.

Übrigens verwendet
Multex diesen Ansatz: Es verfügt über 2
18 Datensätze für verschiedene Segmente und 2
18 Datensätze für mögliche Offsets. Und jedes gemeinsame Bibliotheksfragment oder Speicherfragment sind separate Segmente. Sie werden alle auf Reichweite geprüft und können daher nicht auf variabler Ebene verwendet werden.
Zielgruppe: Vermutlich verlangsamt die ständige Notwendigkeit, den Kernel zu verwenden, den Prozess.
Professor: Ja, das ist richtig. Wir haben also Overhead aufgrund der Tatsache, dass wir, wenn plötzlich ein neuer Puffer auf dem Stapel erstellt wird, einen Systemaufruf ausführen müssen, um ihn hinzuzufügen.
Wie viele dieser Elemente verwenden tatsächlich den Segmentierungsmechanismus? Sie können sich vorstellen, wie es funktioniert. Ich denke, standardmäßig haben alle diese Segmente in
x86 eine Basis gleich 0 und die Länge liegt zwischen 2 und 32. Auf diese Weise können Sie auf den gesamten gewünschten Speicherbereich zugreifen. Daher codieren sie für
NaCl die Basis 0 und setzen die Länge auf 256 Megabyte. Dann zeigen sie auf alle Register von 6 Segmentselektoren in diesem Datensatz für den 256-MB-Bereich. Wenn das Gerät auf den Speicher zugreift, ändert es ihn mit einem Offset von 256 MB. Die Möglichkeit, das Modul zu ändern, ist daher auf 256 MB beschränkt.
Ich denke, Sie verstehen jetzt, wie diese Hardware unterstützt wird und wie sie funktioniert, sodass Sie möglicherweise diese Segmentselektoren verwenden.
Was kann also schief gehen, wenn wir diesen Plan nur umsetzen? Können wir in einem nicht vertrauenswürdigen Modul aus der Segmentauswahl herausspringen? Ich denke, eine Sache, mit der man vorsichtig sein muss, ist, dass diese Register wie reguläre Register sind und man Werte in sie hinein und aus ihnen heraus verschieben kann. Daher müssen Sie sicherstellen, dass das nicht vertrauenswürdige Modul diese Segmentauswahlregister nicht verzerrt. Denn irgendwo in der Deskriptortabelle befindet sich möglicherweise ein Datensatz, der auch der Quellensegmentdeskriptor für einen Prozess ist, der eine Basis von 0 und eine Länge von bis zu 2
32 hat .

Wenn also ein unzuverlässiges Modul
CS ,
DS oder
ES oder einen dieser Selektoren so ändern konnte, dass sie auf dieses ursprüngliche Betriebssystem verweisen, das Ihren gesamten Adressraum abdeckt, können Sie eine Speicherverknüpfung zu diesem Segment herstellen und " aus dem Sandkasten springen.
Daher musste der
native Client dieser verbotenen Liste einige weitere Anweisungen hinzufügen. Ich denke, dass sie alle Anweisungen wie
mov% ds, es und so weiter verbieten. Daher können Sie in der Sandbox nicht das Segment ändern, auf das sich einige Dinge beziehen, die sich darauf beziehen. Auf der
x86- Plattform
sind Anweisungen zum Ändern der Segmentdeskriptortabelle privilegiert, aber das Ändern der
ds, es selbst usw. Der Tisch ist völlig unprivilegiert.
Zielgruppe: Können Sie die Tabelle so initialisieren, dass in allen nicht verwendeten Slots die Länge Null platziert wird?
Professor: Ja. Sie können die Tabellenlänge für etwas festlegen, bei dem keine nicht verwendeten Slots vorhanden sind. Es stellt sich heraus, dass Sie diesen zusätzlichen Steckplatz mit 0 und 2
32 wirklich benötigen, da die
vertrauenswürdige Laufzeitumgebung in diesem Segment beginnen und Zugriff auf den gesamten Speicherbereich erhalten sollte. Dieser Eintrag ist also erforderlich, damit die vertrauenswürdige
Laufzeitumgebung funktioniert.
Zielgruppe: Was wird benötigt, um die Länge der Ausgabe der Tabelle zu ändern?
Professor: Sie müssen Root-Rechte haben.
Linux hat tatsächlich ein System namens
modify_ldt () für die lokale Deskriptortabelle, mit dem jeder Prozess seine eigene Tabelle ändern kann,
dh es gibt tatsächlich eine Tabelle für jeden Prozess. Auf der
x86- Plattform ist dies jedoch komplizierter. Es gibt sowohl eine globale als auch eine lokale Tabelle. Eine lokale Tabelle für einen bestimmten Prozess kann geändert werden.
Versuchen wir nun herauszufinden, wie wir vom
Native Client- Ausführungsprozess springen oder springen oder aus der Sandbox springen. Was bedeutet es, aus uns herauszuspringen?

Wir müssen also diesen vertrauenswürdigen Code ausführen, und dieser vertrauenswürdige Code "lebt" irgendwo über der Grenze von 256 MB. Um dorthin zu gelangen, müssen wir alle vom
Native Client installierten Schutzfunktionen rückgängig machen. Grundsätzlich kommt es darauf an, diese sechs Selektoren zu ändern. Ich denke, dass unser Validator nicht die gleichen Regeln für Dinge anwenden wird, die sich oberhalb der 256-MB-Grenze befinden, daher ist dies recht einfach.
Aber dann müssen wir irgendwie in die
vertrauenswürdige Laufzeit-Laufzeit springen und die Segment-Selektoren auf die richtigen Werte für dieses riesige Segment neu installieren, wobei der Adressraum des gesamten Prozesses abgedeckt wird - dieser Bereich liegt zwischen 0 und 2
32 . Sie nannten solche Mechanismen, die in den
Native Client- Trampolinen und
Trittbrettern vorhanden sind . Sie leben in einem niedrigen 64k-Modul. Das Coolste ist, dass diese „Trampoline“ und „Sprünge“ Codeteile sind, die in den unteren 64 KB des Prozessraums liegen. Dies bedeutet, dass dieses unzuverlässige Modul dorthin springen kann, da es sich um eine gültige Codeadresse handelt, die innerhalb der Grenzen von 32 Bit und innerhalb von 256 MB liegt. Sie können also auf dieses Trampolin springen.
Native Client «» - . ,
Native Client «», trampoline
trusted runtime . ,
DS, CS , .
, , -
malo , «», «» 32- .
, 4096 + 32 , . , ,
mov %ds, 7 ,
ds , 7 0 2
32 .
CS trusted service runtime , 256 .

, , ,
trusted service runtime , . , . DS , , , , - .
, ? , «»? , ?
: 64.
: , , . malo, 64, 32 . , , , .
, 32- , . , , 32 , 32- , . «»
trusted runtime 32 .

. , ,
DS, CS . , 256- ,
trusted runtime , . .
«»,
trusted runtime 256
Native Client . «»
DS , ,
mov %ds, 7 , ,
trusted runtime . . , «», - .
halt 32- «». «», .
trusted service runtime , 1 .
 trusted service runtime
trusted service runtime , , .
: «» ?
: «» 0 256 . 64- , , «», - -.
Native Client .
: ?
: , ? , «»? ?
: , ?
: , -
%eax ,
trusted runtime : «, »!
EAX ,
mov , «»
EAX ,
trusted runtime . , «»?
: , , . …
: , , — , , 0 2
32 . . «», 256 .
, «», . , «» , . , «» .
: «» 256 ?
: , . ,
CS - . «»,
halt , mov,
CS , , 256 .
, , «». ,
DS , ,
CSund irgendwo springen.Wenn Sie es versuchen würden, könnten Sie wahrscheinlich eine Folge von x86- Anweisungen entwickeln , die dies außerhalb der Grenzen des Adressraums des Native Client- Moduls tun könnten .Wir sehen uns also nächste Woche und sprechen über Web-Sicherheit.Die Vollversion des Kurses finden Sie hier .Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder sie Ihren Freunden empfehlen.
Habr-Benutzer erhalten 30% Rabatt auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s bis Dezember kostenlos, wenn Sie für einen Zeitraum von sechs Monaten bezahlen, können Sie hier bestellen .Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?