Mitautor des Artikels: Mike Cheng
Die Google Cloud-Plattform enthält jetzt Images von virtuellen Maschinen in ihrem Portfolio, die speziell für diejenigen entwickelt wurden, die an Deep Learning beteiligt sind. Heute werden wir darüber sprechen, was diese Bilder darstellen, welche Vorteile sie Entwicklern und Forschern bieten und wie man natürlich eine darauf basierende virtuelle Maschine erstellt.
Lyrischer Exkurs: Zum Zeitpunkt des Schreibens befand sich das Produkt noch in der Beta, es gelten keine SLAs.
Was für ein Biest ist das, Bilder von virtuellen Maschinen für Deep Learning von Google?
Virtual Machine-Images für Deep Learning von Google sind Debian 9-Images, die sofort alles enthalten, was Deep Learning benötigt. Derzeit gibt es Versionen von Bildern mit TensorFlow-, PyTorch- und Allzweckbildern. Jede Version ist in der Edition nur für CPU- und GPU-Instanzen vorhanden. Um besser zu verstehen, welches Bild Sie benötigen, habe ich einen kleinen Spickzettel gezeichnet:
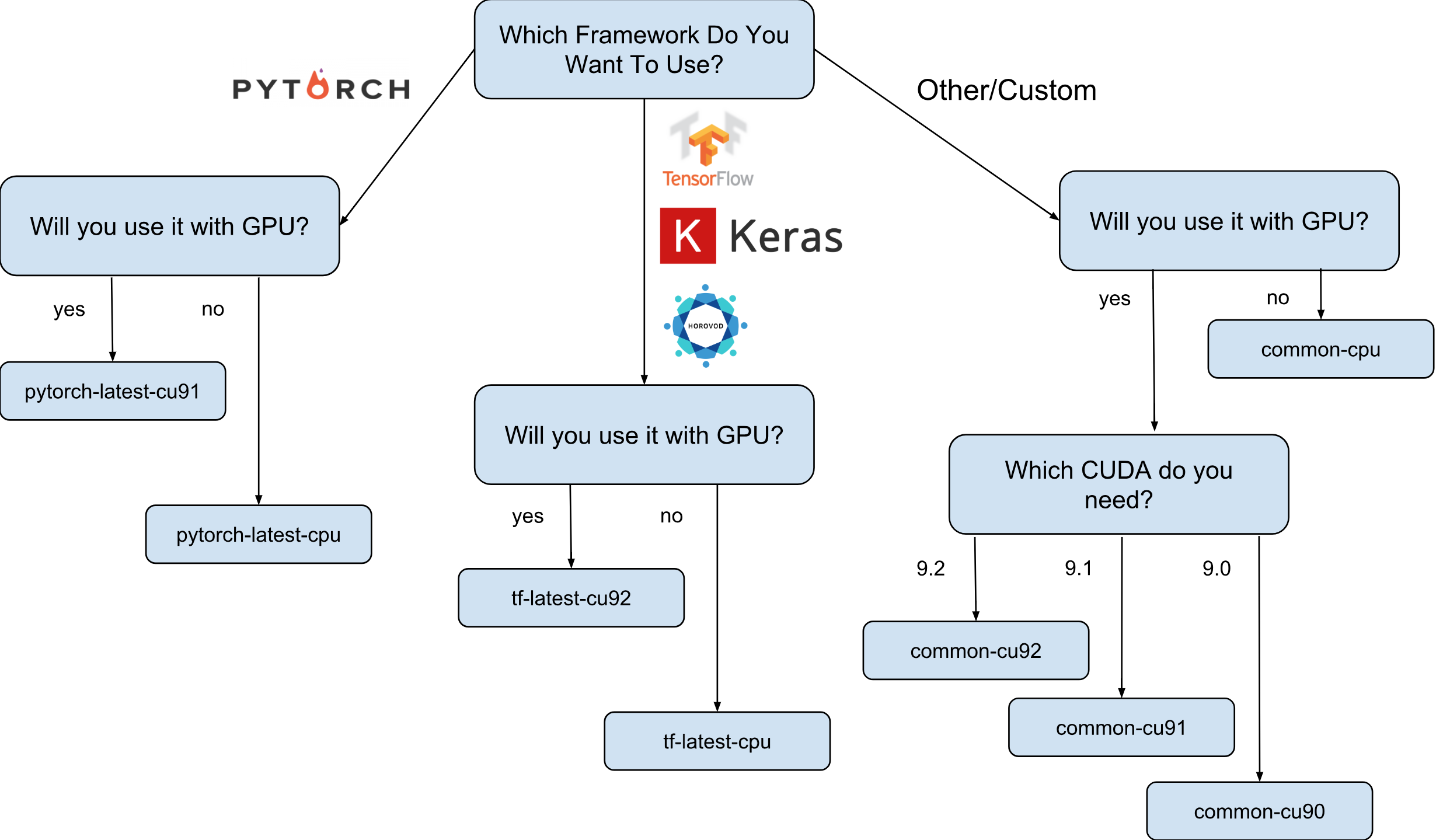
Wie auf dem Spickzettel gezeigt, gibt es 8 verschiedene Bildfamilien. Wie bereits erwähnt, basieren sie alle auf Debian 9.
Was genau ist auf den Bildern vorinstalliert?
Alle Images haben Python 2.7 / 3.5 mit den folgenden vorinstallierten Paketen:
- numpy
- sklearn
- scipy
- Pandas
- nltk
- Kissen
- Jupyter-Umgebungen (Labor und Notebook)
- und vieles mehr.
Konfigurierter Stack von Nvidia (nur in GPU-Images):
- CUDA 9. *
- CuDNN 7.1
- NCCL 2. *
- neuester nvidia treiber
Die Liste wird ständig aktualisiert, bleiben Sie also auf der offiziellen Seite auf dem Laufenden .
Und warum werden diese Bilder tatsächlich benötigt?
Angenommen, Sie müssen ein neuronales Netzwerkmodell mit Keras (mit TensorFlow) trainieren. Die Lerngeschwindigkeit ist Ihnen wichtig und Sie entscheiden sich für die Verwendung der GPU. Um die GPU verwenden zu können, müssen Sie den Nvidia-Stack (Nvidia-Treiber + CUDA + CuDNN + NCCL) installieren und konfigurieren. Dieser Prozess ist nicht nur an sich ziemlich kompliziert (insbesondere wenn Sie kein Systemingenieur, sondern ein Forscher sind), sondern umso komplizierter, als Sie die binären Abhängigkeiten Ihrer Version der TensorFlow-Bibliothek berücksichtigen müssen. Beispielsweise wird die offizielle TensorFlow 1.9-Distribution mit CUDA 9.0 kompiliert und funktioniert nicht, wenn Sie einen Stack mit CUDA 9.1 oder 9.2 installiert haben. Das Einrichten dieses Stapels kann ein "lustiger" Prozess sein. Ich denke, niemand kann damit streiten (insbesondere diejenigen, die es getan haben).
Nehmen wir nun an, dass nach mehreren schlaflosen Nächten alles eingerichtet ist und funktioniert. Frage: Ist diese Konfiguration, die Sie konfigurieren konnten, für Ihre Hardware am besten geeignet? Stimmt es beispielsweise, dass das installierte CUDA 9.0 und das offizielle TensorFlow 1.9-Binärpaket die schnellste Geschwindigkeit auf einer Instanz mit einem SkyLake-Prozessor und einer Volta V100-GPU aufweisen?
Es ist fast unmöglich zu antworten, ohne mit anderen Versionen von CUDA zu testen. Um sicher zu antworten, müssen Sie TensorFlow in verschiedenen Konfigurationen manuell neu erstellen und Ihre Tests ausführen. All dies muss auf der teuren Hardware durchgeführt werden, auf der das Modell anschließend trainiert werden soll. Nun, und das allerletzte, all diese Messungen können weggeworfen werden, sobald die neue Version von TensorFlow oder der Nvidia-Stack veröffentlicht wird. Es kann mit Sicherheit festgestellt werden, dass die meisten Forscher dies einfach nicht tun und einfach die Standard-TensorFlow-Baugruppe verwenden, die keine optimale Geschwindigkeit aufweist.
Hier erscheinen die Bilder von Deep Learning von Google in der Szene. Bilder mit TensorFlow verfügen beispielsweise über eine eigene TensorFlow-Baugruppe, die für die in der Google Cloud Engine verfügbare Hardware optimiert ist. Sie werden mit einer anderen Konfiguration des Nvidia-Stacks getestet und basieren auf der Konfiguration mit der höchsten Leistung (Spoiler: Dies ist nicht immer die neueste). Gut und vor allem - fast alles, was Sie für die Forschung benötigen, ist bereits vorinstalliert!
Wie kann ich eine Instanz basierend auf einem der Bilder erstellen?
Es gibt zwei Möglichkeiten, eine neue Instanz basierend auf diesen Bildern zu erstellen:
- Verwenden der Google Cloud Marketplace-Weboberfläche
- Mit gcloud
Da ich ein großer Fan der Terminal- und CLI-Dienstprogramme bin, werde ich in diesem Artikel über diese Option sprechen. Wenn Sie die Benutzeroberfläche mögen, gibt es außerdem eine recht gute Dokumentation, in der beschrieben wird, wie Sie eine Instanz mithilfe der Web-Benutzeroberfläche erstellen .
Bevor Sie fortfahren, installieren Sie das gcloud- Tool (falls Sie es noch nicht installiert haben). Optional können Sie die Google Cloud Shell verwenden . Beachten Sie jedoch, dass die WebPreview- Funktion in der Google Cloud Shell derzeit nicht unterstützt wird und Sie daher das Jupyter Lab oder Notebook dort nicht verwenden können.
Der nächste Schritt ist die Auswahl einer Bildfamilie. Ich werde mir noch einmal erlauben, den Spickzettel mit der Wahl einer Bilderfamilie mitzubringen.
Wir gehen beispielsweise davon aus, dass Ihre Wahl auf tf-latest-cu92 gefallen ist, und werden sie später im Text verwenden.
Warten Sie, aber was ist, wenn ich eine bestimmte Version von TensorFlow anstelle der „neuesten“ Version benötige?
Angenommen, wir haben ein Projekt, für das TensorFlow 1.8 erforderlich ist, aber gleichzeitig wurde bereits 1.9 veröffentlicht, und die Bilder in der neuesten tf-Familie haben bereits 1.9. Für diesen Fall haben wir eine Familie von Bildern, die immer eine bestimmte Version des Frameworks hat (in unserem Fall tf-1-8-cpu und tf-1-8-cu92). Diese Bildfamilien werden aktualisiert, die Version von TensorFlow ändert sich jedoch nicht.
Da dies nur eine Beta-Version ist, unterstützen wir jetzt nur noch TensorFlow 1.8 / 1.9 und PyTorch 0.4. Wir planen, zukünftige Versionen zu unterstützen, können jedoch derzeit die Frage, wie lange alte Versionen unterstützt werden, nicht eindeutig beantworten.
Was ist, wenn ich einen Cluster erstellen oder dasselbe Image verwenden möchte?
In der Tat kann es viele Fälle geben, in denen es erforderlich ist, dasselbe Bild immer wieder zu verwenden (und nicht eine Familie von Bildern). Genau genommen ist die direkte Verwendung von Bildern fast immer die bevorzugte Option. Wenn Sie beispielsweise einen Cluster mit mehreren Instanzen ausführen, wird in diesem Fall nicht empfohlen, Bildfamilien direkt in Ihren Skripten anzugeben, da bei einer Aktualisierung der Familie zum Zeitpunkt der Ausführung des Skripts wahrscheinlich unterschiedliche Clusterinstanzen aus unterschiedlichen Bildern erstellt werden (und kann verschiedene Versionen von Bibliotheken haben!). In solchen Fällen ist es vorzuziehen, zuerst einen bestimmten Namen für das Bild ihrer Familie zu erhalten und erst dann einen bestimmten Namen zu verwenden.
Wenn Sie sich für dieses Thema interessieren, können Sie meinen Artikel „So verwenden Sie Bildfamilien richtig“ lesen.
Sie können den Namen des letzten Bildes in der Familie mit einem einfachen Befehl anzeigen:
gcloud compute images describe-from-family tf-latest-cu92 \ --project deeplearning-platform-release
Angenommen, der Name eines bestimmten Bildes lautet tf-latest-cu92-1529452792. Sie können es bereits überall verwenden:
Zeit, unsere erste Instanz zu erstellen!
Führen Sie einfach einen einfachen Befehl aus, um eine Instanz aus einer Familie von Bildern zu erstellen:
export IMAGE_FAMILY="tf-latest-cu92"
Wenn Sie den Bildnamen und nicht die Bildfamilie verwenden, müssen Sie "- image-family = $ IMAGE_FAMILY" durch "- image = $ IMAGE-NAME" ersetzen.
Wenn Sie eine Instanz mit einer GPU verwenden, müssen Sie die folgenden Umstände beachten:
Sie müssen die richtige Zone auswählen . Wenn Sie eine Instanz mit einer bestimmten GPU erstellen, müssen Sie sicherstellen, dass dieser GPU-Typ in der Zone verfügbar ist, in der Sie die Instanz erstellen. Hier finden Sie die Entsprechung von Zonen zu GPU-Typen. Wie Sie sehen können, ist us-west1-b die einzige Zone, in der es alle drei möglichen Arten von GPUs gibt (K80 / P100 / V100).
Stellen Sie sicher, dass Sie über genügend Kontingente verfügen, um eine Instanz mit der GPU zu erstellen . Selbst wenn Sie die richtige Region ausgewählt haben, bedeutet dies nicht, dass Sie über ein Kontingent zum Erstellen einer Instanz mit einer GPU in dieser Region verfügen. Standardmäßig ist das GPU-Kontingent in allen Regionen auf Null festgelegt, sodass alle Versuche, eine Instanz mit der GPU zu erstellen, fehlschlagen. Eine gute Erklärung zur Erhöhung der Quote finden Sie hier .
Stellen Sie sicher, dass sich in der Zone genügend GPUs befinden, um Ihre Anfrage zu erfüllen . Selbst wenn Sie die richtige Region ausgewählt haben und ein Kontingent für GPUs in dieser Region haben, bedeutet dies nicht, dass in dieser Zone eine für Sie interessante GPU vorhanden ist. Leider weiß ich nicht, wie Sie sonst die Verfügbarkeit der GPU überprüfen können, außer als Versuch, eine Instanz zu erstellen und zu sehen, was passiert =)
Wählen Sie die richtige Anzahl von GPUs (abhängig vom GPU-Typ) . Tatsache ist, dass das "Beschleuniger" -Flag in unserem Team für den Typ und die Anzahl der GPUs verantwortlich ist, die der Instanz zur Verfügung stehen: d.h. "- Accelerator = 'type = nvidia-tesla-v100, count = 8'" erstellt eine Instanz mit acht verfügbaren Nvidia Tesla V100 (Volta) -GPUs. Jeder GPU-Typ verfügt über eine gültige Liste von Zählwerten. Hier ist die Liste für jeden GPU-Typ:
- nvidia-tesla-k80 kann zählen: 1, 2, 4, 8
- nvidia-tesla-p100 kann zählen: 1, 2, 4
- nvidia-tesla-v100 kann zählen: 1, 8
Geben Sie Google Cloud die Berechtigung, den Nvidia-Treiber zum Zeitpunkt des Starts der Instanz in Ihrem Namen zu installieren . Der Fahrer aus Nvidia ist ein Muss. Aus Gründen, die über den Rahmen dieses Artikels hinausgehen, ist auf den Images kein Nvidia-Treiber vorinstalliert. Sie können Google Cloud jedoch das Recht einräumen, es beim ersten Start der Instanz in Ihrem Namen zu installieren. Dies erfolgt durch Hinzufügen des Flags "- metadata = 'install-nvidia-driver = True'". Wenn Sie dieses Flag nicht angeben, werden Sie beim ersten Herstellen einer Verbindung über SSH aufgefordert, den Treiber zu installieren.
Leider dauert der Treiberinstallationsprozess beim ersten Start einige Zeit, da dieser Treiber heruntergeladen und installiert werden muss (und dies beinhaltet auch einen Neustart der Instanz). Insgesamt sollte dies nicht länger als 5 Minuten dauern. Wir werden etwas später darüber sprechen, wie Sie die erste Startzeit reduzieren können.
Stellen Sie über SSH eine Verbindung zu einer Instanz her
Dies ist einfacher als eine Rübe und kann mit einem Befehl ausgeführt werden:
gcloud compute ssh $INSTANCE_NAME
gcloud erstellt ein Schlüsselpaar und lädt es automatisch in die neu erstellte Instanz hoch sowie erstellt Ihren Benutzer darauf. Wenn Sie diesen Vorgang noch einfacher gestalten möchten, können Sie eine Funktion verwenden, die dies ebenfalls vereinfacht:
function gssh() { gcloud compute ssh $@ } gssh $INSTANCE_NAME
Übrigens finden Sie hier alle meine gcloud-Bash-Funktionen. Bevor wir uns der Frage zuwenden, wie schnell diese Bilder sind oder was damit gemacht werden kann, möchte ich das Problem mit der Geschwindigkeit des Startens von Instanzen klären.
Wie kann ich die Zeit des ersten Starts verkürzen?
Technisch gesehen ist der Zeitpunkt des ersten Starts nichts. Aber Sie können:
- Erstellen Sie die billigste n1-Standard-1-Instanz mit einem K80.
- Warten Sie, bis der erste Download abgeschlossen ist.
- Stellen Sie sicher, dass der Nvidia-Treiber installiert ist (dies kann durch Ausführen von "nvidia-smi" erfolgen).
- Stoppen Sie die Instanz
- Erstellen Sie Ihr eigenes Image aus einer gestoppten Instanz
- Gewinn - Alle aus Ihrem abgeleiteten Image erstellten Instanzen haben eine legendäre Startzeit von 15 Sekunden.
Aus dieser Liste wissen wir bereits, wie eine neue Instanz erstellt und eine Verbindung hergestellt wird. Außerdem wissen wir, wie die Treiber auf ihre Funktionsfähigkeit überprüft werden. Es bleibt nur zu besprechen, wie die Instanz gestoppt und daraus ein Image erstellt werden kann.
Führen Sie den folgenden Befehl aus, um die Instanz zu stoppen:
function ginstance_stop() { gcloud compute instances stop - quiet $@ } ginstance_stop $INSTANCE_NAME
Und hier ist der Befehl zum Erstellen des Bildes:
export IMAGE_NAME="my-awesome-image" export IMAGE_FAMILY="family1" gcloud compute images create $IMAGE_NAME \ --source-disk $INSTANCE_NAME \ --source-disk-zone $ZONE \ --family $IMAGE_FAMILY
Herzlichen Glückwunsch, jetzt haben Sie Ihr eigenes Image mit den installierten Nvidia-Treibern.
Wie wäre es mit Jupyter Lab?
Sobald Ihre Instanz ausgeführt wird, besteht der nächste logische Schritt darin, Jupyter Lab zu starten, um direkt zur Sache zu kommen :) Mit neuen Images ist dies sehr einfach. Jupyter Lab wird bereits seit dem Start der Instanz ausgeführt. Sie müssen lediglich eine Verbindung zur Instanz herstellen und den Port weiterleiten, den Jupyter Lab überwacht. Und das ist Port 8080. Dies geschieht mit dem folgenden Befehl:
gssh $INSTANCE_NAME -- -L 8080:localhost:8080
Alles ist fertig, jetzt können Sie einfach Ihren Lieblingsbrowser öffnen und zu http: // localhost: 8080 gehen
Wie viel schneller ist TensorFlow von Bildern?
Eine sehr wichtige Frage, da die Geschwindigkeit des Trainings des Modells echtes Geld ist. Die vollständige Antwort auf diese Frage ist jedoch die längste, die bereits in diesem Artikel geschrieben wurde. Also musst du auf den nächsten Artikel warten :)
In der Zwischenzeit werde ich Sie mit einigen Zahlen verwöhnen, die ich in meinem kleinen persönlichen Experiment erhalten habe. Die Trainingsgeschwindigkeit in ImageNet betrug also 6100 Bilder pro Sekunde (ResNet-50-Netzwerk). Mein persönliches Budget erlaubte es mir nicht, das Modell vollständig zu trainieren. Bei dieser Geschwindigkeit gehe ich jedoch davon aus, dass es möglich ist, mit ein wenig Genauigkeit von 5% in 5 Stunden zu erreichen.
Wo bekomme ich Hilfe?
Wenn Sie Informationen zu neuen Bildern benötigen, können Sie:
- Stellen Sie eine Frage zum Stackoverflow mit dem Tag google-dl-platform.
- Schreiben Sie an die öffentliche Google-Gruppe .
- kann mir per Mail oder auf Twitter schreiben.
Ihr Feedback ist sehr wichtig. Wenn Sie etwas zu den Bildern zu sagen haben, können Sie mich gerne auf eine für Sie geeignete Weise kontaktieren oder einen Kommentar unter diesem Artikel hinterlassen.