Hinweis perev. : Dieser Artikel wurde im offiziellen Kubernetes-Blog veröffentlicht und von zwei Intel-Mitarbeitern verfasst, die direkt an der Entwicklung von CPU Manager beteiligt sind, einer neuen Funktion in Kubernetes, über die wir in der Version 1.8- Rezension geschrieben haben. Im Moment (d. H. Für K8s 1.11) hat diese Funktion den Beta-Status und lesen Sie später in der Notiz mehr über ihren Zweck.Die Veröffentlichung befasst sich mit dem
CPU Manager , einer Beta-Funktion in Kubernetes. Mit dem CPU-Manager können Sie Workloads in Kubelet besser verteilen, d. H. auf dem Kubernetes-Hostagenten durch Zuweisen dedizierter CPUs zu Containern eines bestimmten Herdes.
Hört sich toll an! Aber hilft mir der CPU-Manager?
Hängt von der Arbeitsbelastung ab. Der einzige Rechenknoten im Kubernetes-Cluster kann viele Herde ausführen, und einige von ihnen können Lasten ausführen, die im CPU-Verbrauch aktiv sind. In diesem Szenario können die Herde um die auf diesem Knoten verfügbaren Prozessressourcen konkurrieren. Wenn dieser Wettbewerb eskaliert, kann sich die Arbeitslast auf andere CPUs verlagern, je nachdem, ob sie
gedrosselt wurde und welche CPUs zum Zeitpunkt der Planung verfügbar waren. Darüber hinaus kann es Fälle geben, in denen die Arbeitslast für Kontextwechsel empfindlich ist. In all diesen Szenarien kann die Workload-Leistung beeinträchtigt werden.
Wenn Ihre Arbeitslast für solche Szenarien empfindlich ist, können Sie CPU Manager aktivieren, um eine bessere Leistungsisolation zu erzielen, indem Sie der Last bestimmte CPUs zuweisen.
Der CPU-Manager kann beim Laden mit den folgenden Funktionen helfen:
- Empfindlich gegenüber CPU-Drosseleffekten
- empfindlich gegenüber Kontextwechseln;
- Prozessor-Cache-Fehler;
- Profitieren von der Aufteilung der Prozessorressourcen (z. B. Datencache und Anweisungen);
- speicherempfindlicher Speicher zwischen Prozessorsockeln (eine ausführliche Erklärung der Autoren finden Sie im Unix Stack Exchange - ca. übersetzt ) ;
- Hyperthreads, die von demselben physischen Kern der CPU empfindlich sind oder diesen benötigen.
Ok! Wie benutzt man es?
Die Verwendung des CPU-Managers ist einfach.
Aktivieren Sie es zunächst mithilfe der statischen Richtlinie in Kubelet, die auf den Rechenknoten des Clusters ausgeführt wird. Konfigurieren Sie dann die
QoS- Klasse
( Guaranteed Quality of Service) für den Herd. Fordern Sie eine ganzzahlige Anzahl von CPU-Kernen (z. B.
1000m oder
4000m 1000m ) für Container an, die dedizierte Kerne benötigen. Erstellen Sie nach der vorherigen Methode (z. B.
kubectl create -f pod.yaml ) ... und voila - der CPU-Manager weist jedem Herdcontainer je nach CPU-Anforderungen dedizierte Prozessorkerne zu.
apiVersion: v1 kind: Pod metadata: name: exclusive-2 spec: containers: - image: quay.io/connordoyle/cpuset-visualizer name: exclusive-2 resources: # Pod is in the Guaranteed QoS class because requests == limits requests: # CPU request is an integer cpu: 2 memory: "256M" limits: cpu: 2 memory: "256M"
Spezifikation eines Herdes, der 2 dedizierte CPUs anfordert.Wie funktioniert der CPU Manager?
Wir betrachten drei Arten der CPU-Ressourcensteuerung, die in den meisten Linux-Distributionen verfügbar sind und für Kubernetes und die Zwecke dieser Veröffentlichung relevant sind. Die ersten beiden sind CFS-Freigaben (was ist mein gewichteter „ehrlicher“ Anteil an der CPU-Zeit im System) und CFS-Kontingent (was ist die maximale CPU-Zeit, die mir für den Zeitraum zugewiesen wurde). Der CPU-Manager verwendet auch eine dritte, die als CPU-Affinität bezeichnet wird (auf welchen logischen CPUs ich Berechnungen durchführen darf).
Standardmäßig können alle Pods und Container, die auf dem Kubernetes-Clusterknoten ausgeführt werden, auf allen verfügbaren Systemkernen ausgeführt werden. Die Gesamtzahl der zugewiesenen Freigaben und Kontingente wird durch die für
Kubernetes und Systemdämonen reservierten CPU-Ressourcen begrenzt. Die Grenzen der verwendeten CPU-Zeit können jedoch unter Verwendung der
Grenzen der CPU in der Herdspezifikation bestimmt werden . Kubernetes verwendet das
CFS-Kontingent , um CPU-Grenzwerte für Herdcontainer durchzusetzen.
Wenn Sie den CPU-Manager mit einer
statischen Richtlinie aktivieren, verwaltet er einen dedizierten Pool von CPUs. Zu Beginn enthält dieser Pool die gesamte CPU des Rechenknotens. Wenn Kubelet einen Container im Herd mit einer garantierten Anzahl dedizierter Prozessorkerne erstellt, werden ihm die diesem Container zugewiesenen CPUs für seine Lebensdauer zugewiesen und aus dem gemeinsam genutzten Pool entfernt. Lasten von den verbleibenden Containern werden von diesen dedizierten Kernen auf andere übertragen.
Alle Container ohne dedizierte CPUs (
Burstable ,
BestEffort und
Garantiert mit nicht ganzzahligen CPUs ) werden auf Kerneln ausgeführt, die im gemeinsam genutzten Pool
verbleiben . Wenn ein Container mit dedizierten CPUs nicht mehr funktioniert, kehren seine Kernel zum gemeinsam genutzten Pool zurück.
Weitere Details bitte ...

Das obige Diagramm zeigt die Anatomie des CPU-Managers. Es verwendet die
UpdateContainerResources Methode von der Container Runtime Interface (CRI), um die CPUs zu ändern, auf denen die Container ausgeführt werden.
Der Manager vergleicht cgroupfs regelmäßig mit dem aktuellen Status der CPU-Ressourcen für jeden ausgeführten Container.
Der CPU-Manager verwendet
Richtlinien , um über die Zuweisung von CPU-Kernen zu entscheiden. Es sind zwei Richtlinien implementiert:
Keine und
Statisch . Ab Kubernetes Version 1.10 wird es standardmäßig mit der Richtlinie
Keine aktiviert.
Die
statische Richtlinie weist der garantierten QoS-Klasse CPU-zugewiesene Pod-Container zu, die eine ganzzahlige Anzahl von Kernen anfordert. Die
statische Richtlinie versucht, die CPU in der besten topologischen Weise und in der folgenden Reihenfolge zu bestimmen:
- Weisen Sie alle CPUs einem Prozessorsockel zu, falls verfügbar, und der Container benötigt eine CPU in Höhe von mindestens einem gesamten CPU-Sockel.
- Weisen Sie alle logischen CPUs (Hyperthreads) eines physischen CPU-Kerns zu, falls verfügbar, und der Container benötigt eine CPU mit mindestens dem gesamten Kern.
- Weisen Sie alle verfügbaren logischen CPUs mit einer Präferenz für CPUs aus einem einzelnen Socket zu.
Wie verbessert der CPU-Manager die Rechenisolation?
Wenn die
statische Richtlinie im CPU-Manager aktiviert ist, können Workloads aus einem der folgenden Gründe eine bessere Leistung erzielen:
- Dedizierte CPUs können einem Container mit einer Workload zugewiesen werden, anderen Containern jedoch nicht. Diese (anderen) Container verwenden nicht dieselben CPU-Ressourcen. Infolgedessen erwarten wir eine bessere Leistung aufgrund der Isolation im Falle des Auftretens eines „Angreifers“ (CPU-anspruchsvolle Prozesse - ca. übersetzt ) oder einer angrenzenden Arbeitslast.
- Es gibt weniger Wettbewerb um Ressourcen, die von der Arbeitslast verwendet werden, da wir die CPU durch die Arbeitslast selbst aufteilen können. Diese Ressourcen können nicht nur die CPU, sondern auch die Cache-Hierarchien und die Speicherbandbreite umfassen. Dies verbessert die Gesamtleistung der Arbeitslast.
- Der CPU-Manager weist die CPU in einer topologischen Reihenfolge zu, basierend auf den besten verfügbaren Optionen. Wenn der gesamte Socket frei ist, werden alle seine CPUs der Arbeitslast zugewiesen. Dies verbessert die Workload-Leistung aufgrund des fehlenden Datenverkehrs zwischen Sockets.
- Container in Pods mit garantierter QoS unterliegen dem CFS-Kontingent. Arbeitslasten, die zu plötzlichen Ausbrüchen neigen, können geplant werden und ihre Quote vor dem Ende ihres zugewiesenen Zeitraums überschreiten, wodurch sie gedrosselt werden . Die zu diesem Zeitpunkt beteiligten CPUs können sowohl bedeutende als auch wenig nützliche Arbeit leisten. Solche Container unterliegen jedoch keiner CFS-Drosselung, wenn die Kontingent-CPU durch eine dedizierte CPU-Zuweisungsrichtlinie ergänzt wird.
Ok! Hast du irgendwelche Ergebnisse?
Um die Leistungsverbesserungen und die Isolation zu sehen, die durch die Aufnahme des CPU-Managers in Kubelet erzielt wurden, haben wir Experimente an einem Rechenknoten mit zwei Sockeln (Intel Xeon CPU E5-2680 v3) und aktiviertem Hyperthreading durchgeführt. Der Knoten besteht aus 48 logischen CPUs (24 physische Kerne mit jeweils Hyperthreading). Die Leistungs- und Isolationsvorteile des CPU-Managers, die durch Benchmark- und reale Workloads in drei verschiedenen Szenarien erfasst werden, sind nachstehend aufgeführt.
Wie interpretiere ich Diagramme?
Für jedes Szenario werden Diagramme angezeigt (
Span-Diagramme , Box-Plots), die die normalisierte Ausführungszeit und ihre Variabilität beim Starten eines Benchmarks oder einer realen Last bei ein- und ausgeschaltetem CPU-Manager veranschaulichen. Die Laufzeit wird auf die Starts mit der besten Leistung normalisiert (1,00 auf der Y-Achse steht für die beste Startzeit: Je niedriger der Wert des Diagramms, desto besser). Die Höhe des Diagramms in der Grafik zeigt die Variabilität der Leistung. Wenn es sich bei der Site beispielsweise um eine Linie handelt, gibt es bei diesen Starts keine Leistungsunterschiede. In diesen Bereichen selbst ist die Mittellinie der Median, die Oberseite das 75. Perzentil und die Unterseite das 25. Perzentil. Die Höhe des Diagramms (d. H. Die Differenz zwischen dem 75. und dem 25. Perzentil) ist als Interquartilbereich (IQR) definiert. "Moustache" zeigt Daten außerhalb dieses Intervalls und Punkte zeigen Ausreißer. Emissionen sind alle Daten, die sich 1,5-mal vom IQR unterscheiden - weniger oder mehr als das entsprechende Quartil. Jedes Experiment wurde 10 Mal durchgeführt.
Aggressiver Schutz
Wir haben sechs Benchmark'ov aus einer
Reihe von PARSEC (Workloads - "Opfer") gestartet
[mehr über Workloads von Opfern finden Sie beispielsweise hier - ca. perev. ] neben dem Container, der die CPU lädt ("Aggressor" -Arbeitslast), während der CPU-Manager ein- und ausgeschaltet ist.
Der Aggressor-Container wird
wie unter mit der
Burstable QoS-Klasse gestartet, die 23 CPU-Flag
--cpus 48 . Benchmarks werden
als Pods mit der Klasse "
Garantierte QoS" ausgeführt, für die ein Satz CPUs von einem vollen Socket (d. H. 24 CPUs auf diesem System) erforderlich ist. Die folgenden Grafiken zeigen die normalisierte Startzeit des Pods mit einem Benchmark neben dem Pod-Angreifer, mit
statischer CPU-Manager-Richtlinie und ohne diesen. In allen Testfällen können Sie bei aktivierter Richtlinie eine verbesserte Leistung und eine geringere Leistungsvariabilität feststellen.

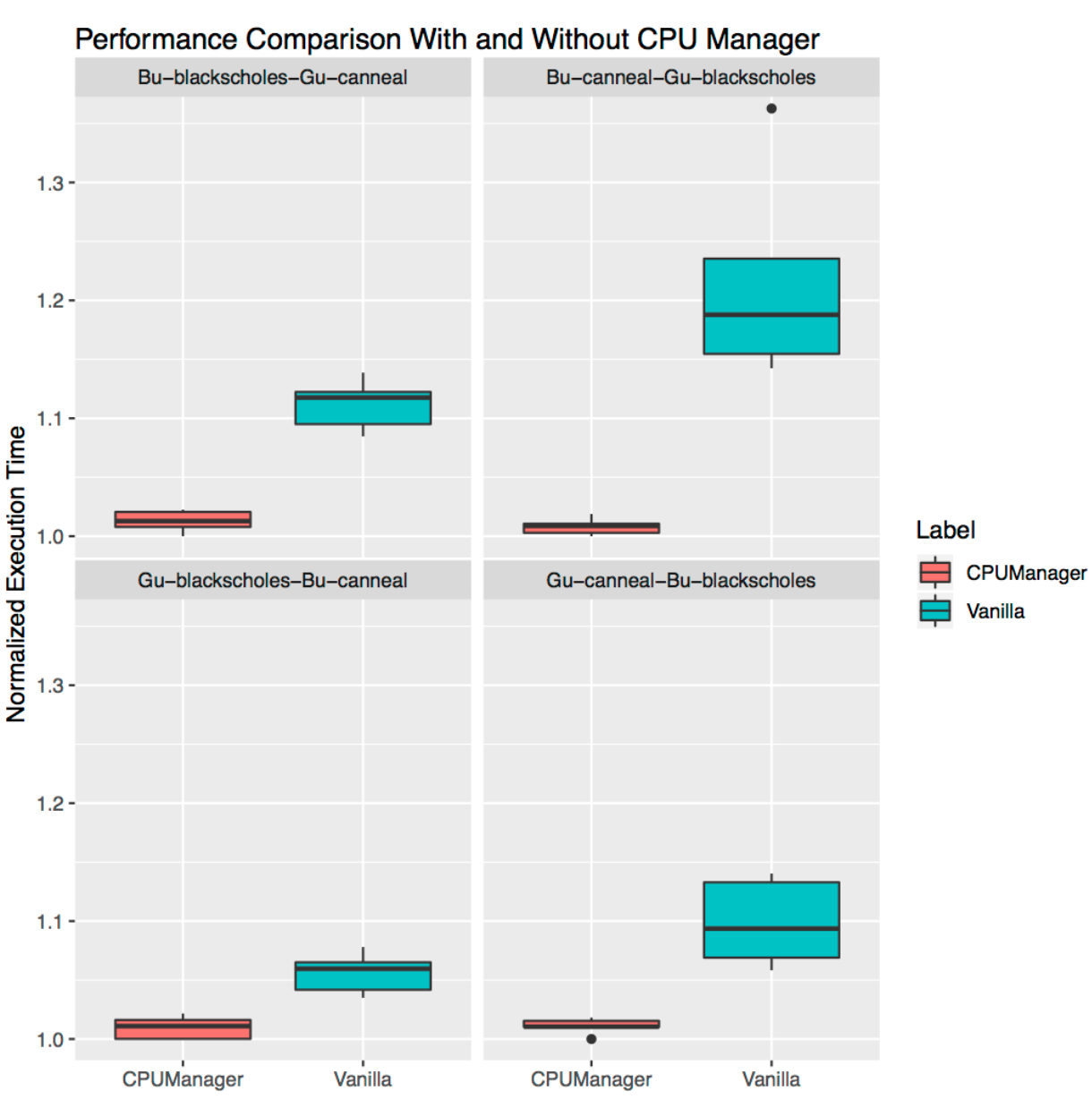
Isolierung für benachbarte Lasten
Dies zeigt, wie nützlich der CPU-Manager für viele am selben Standort befindliche Workloads sein kann. Die folgenden Span-Diagramme zeigen die Leistung von zwei Benchmarks aus dem PARSEC-Satz (
Blackscholes und
Canneal ), die für die
nebeneinander liegenden QoS-Klassen
Garantiert (Gu) und
Burstable (Bu) gestartet wurden, wobei die
statische Richtlinie
aktiviert und
deaktiviert ist .
Ausgehend von der Grafik oben links im Uhrzeigersinn sehen wir die Leistung von
Blackscholes für Bu QoS (oben links),
Canneal für Bu QoS (oben rechts),
Canneal für Gu QoS (unten rechts) und
Blackscholes für Gu QoS (unten links). In jedem Diagramm befinden sie sich (wieder im Uhrzeigersinn) zusammen mit
Canneal für Gu QoS (oben links),
Blackscholes für Gu QoS (oben rechts),
Blackscholes für Bu QoS (unten rechts) und
Canneal für Bu QoS (unten links). entsprechend. Das
Bu-blackscholes-Gu-canneal-Diagramm (oben links) zeigt beispielsweise die Leistung von
Blackscholes, die mit Bu QoS ausgeführt werden und sich neben
Canneal mit der Gu QoS-Klasse befinden. In jedem Fall erfordert unter mit der Klasse Gu QoS ein vollständiger Socket-Kern (d. H. 24 CPUs) und unter mit der Klasse Bu QoS - 23 CPUs.
In allen Tests gibt es für beide benachbarten Workloads eine bessere Leistung und weniger Leistungsschwankungen. Schauen Sie sich zum Beispiel
Bu-blackscholes-Gu-canneal (oben links) und
Gu-canneal-Bu-blackscholes (unten rechts) an. Sie zeigen die Leistung von
Blackscholes und
Canneal bei
ein- und
ausgeschaltetem CPU-Manager. In diesem Fall empfängt
Canneal mehr dedizierte Kerne vom CPU-Manager, da es zur Gu QoS-Klasse gehört und eine ganzzahlige Anzahl von CPU-Kernen anfordert.
Blackscholes erhält jedoch auch einen dedizierten Satz von CPUs, da dies die einzige Arbeitslast im gemeinsam genutzten Pool ist. Infolgedessen nutzen sowohl
Blackscholes als auch
Canneal die
Lastisolation bei Verwendung von CPU Manager.
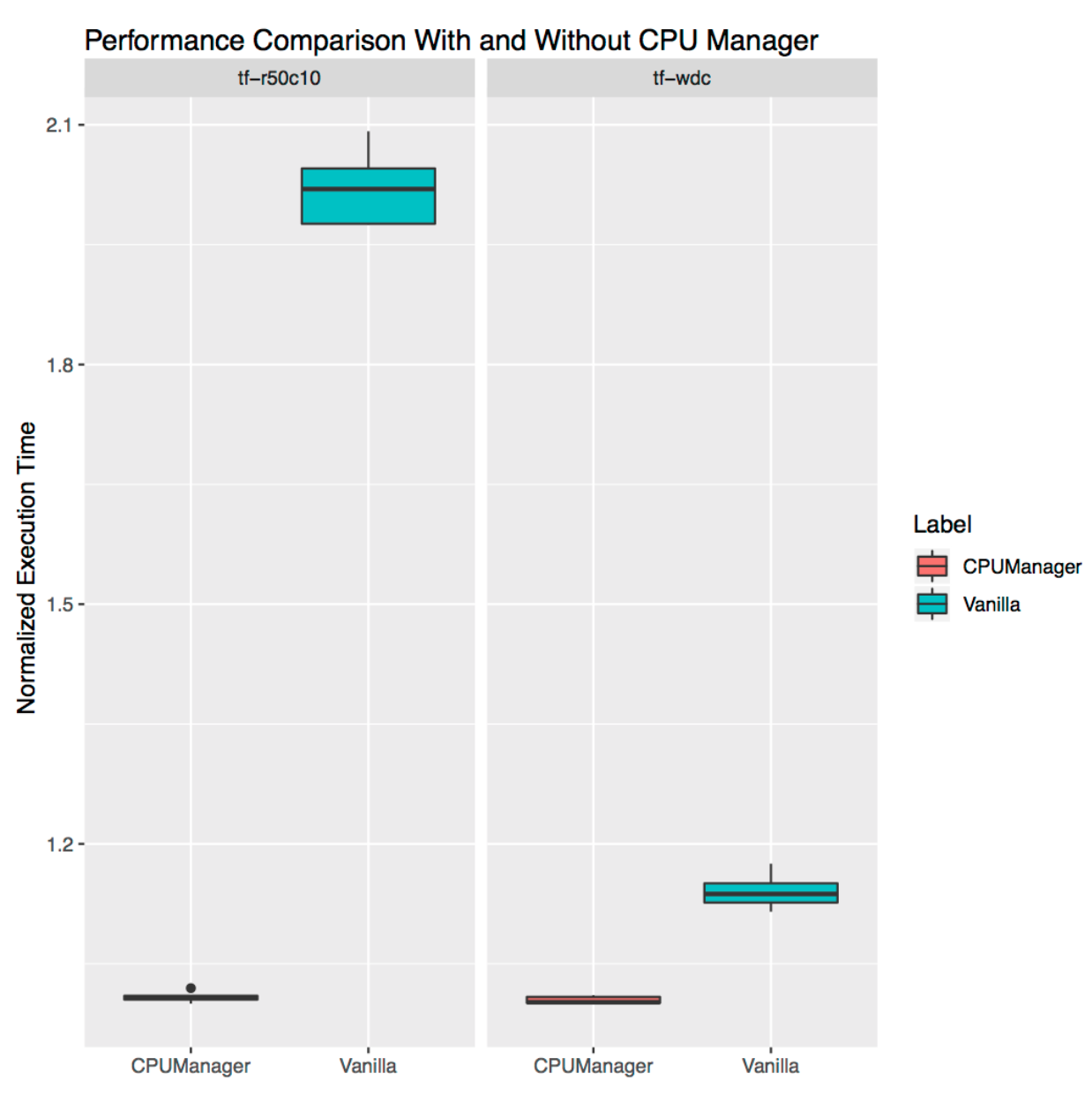
Isolierung für freistehende Lasten
Es zeigt, wie nützlich CPU Manager für eigenständige Workloads aus dem realen Leben sein kann. Wir haben zwei Ladungen von den
offiziellen TensorFlow-Modellen genommen :
breit und tief und
ResNet . Für sie werden typische Datensätze verwendet (Volkszählung bzw. CIFAR10). In beiden Fällen benötigen
Herde (
breit und tief ,
ResNet ) 24 CPUs, was einem vollen Sockel entspricht. Wie in den Diagrammen gezeigt, bietet der CPU-Manager in beiden Fällen eine bessere Isolation.
Einschränkungen
Benutzer möchten möglicherweise CPUs auf einem Socket in der Nähe des Busses zuweisen lassen, der mit einem externen Gerät wie einem Beschleuniger oder einer Hochleistungsnetzwerkkarte verbunden ist, um Datenverkehr zwischen Sockets zu vermeiden. Diese Art der Konfiguration wird im CPU-Manager noch nicht unterstützt. Da der CPU-Manager die bestmögliche Zuordnung von CPUs bietet, die zu einem Socket oder physischen Kern gehören, reagiert er empfindlich auf Extremfälle und kann zu Fragmentierung führen. Der CPU-Manager berücksichtigt den Boot-Parameter des
isolcpus Linux-Kernels nicht, obwohl er in einigen Fällen als gängige Praxis verwendet wird
(weitere Einzelheiten zu diesem Parameter finden Sie beispielsweise hier - ca. Transl. ) .
PS vom Übersetzer
Lesen Sie auch in unserem Blog: