
In den letzten Jahren hat das Thema künstliche Intelligenz und maschinelles Lernen aufgehört, etwas für Menschen aus dem Bereich der Fiktion zu sein, und ist fest in den Alltag eingetreten. Soziale Netzwerke bieten die Teilnahme an Veranstaltungen an, die für uns von Interesse sind, Autos auf den Straßen, die gelernt haben, sich ohne Fahrer zu bewegen, und ein Sprachassistent am Telefon teilt mit, wann es besser ist, das Haus zu verlassen, um Staus zu vermeiden, und ob Sie einen Regenschirm mitnehmen sollten.
In diesem Artikel werden wir die von Apple-Entwicklern angebotenen Tools für maschinelles Lernen betrachten, analysieren, was das Unternehmen auf der WWDC18 in diesem Bereich neu gezeigt hat, und versuchen zu verstehen, wie Sie all dies in die Praxis umsetzen können.
Maschinelles Lernen
Maschinelles Lernen ist also ein Prozess, bei dem ein System mithilfe bestimmter Datenanalysealgorithmen und der Verarbeitung einer Vielzahl von Beispielen Muster identifiziert und diese zur Vorhersage der Eigenschaften neuer Daten verwendet.
Maschinelles Lernen entstand aus der Theorie heraus, dass Computer selbstständig lernen können und noch nicht für bestimmte Aktionen programmiert sind. Mit anderen Worten, im Gegensatz zu herkömmlichen Programmen mit vordefinierten Anweisungen zur Lösung spezifischer Probleme kann das System beim maschinellen Lernen lernen, wie man Muster unabhängig erkennt und Vorhersagen trifft.
BNNS und CNN
Apple setzt seit geraumer Zeit maschinelle Lerntechnologien auf seinen Geräten ein: Mail identifiziert Spam-E-Mails, Siri hilft Ihnen, schnell Antworten auf Ihre Fragen zu finden, Fotos erkennen Gesichter in Bildern.
Auf der WWDC16 stellte das Unternehmen zwei auf neuronalen Netzen basierende APIs vor - Basic Neural Network Subroutines (BNNS) und Convolutional Neural Networks (CNN). BNNS ist Teil des Accelerate-Systems, das die Grundlage für schnelle Berechnungen auf der CPU bildet, und CNN ist die Metal Performance Shaders-Bibliothek, die die GPU verwendet. Hier erfahren Sie beispielsweise mehr über diese Technologien.
Core ML und Turi erstellen
Im vergangenen Jahr kündigte Apple ein Framework an, das die Arbeit mit Technologien für maschinelles Lernen erheblich erleichtert - Core ML. Es basiert auf der Idee, ein vorab trainiertes Datenmodell in nur wenigen Codezeilen in Ihre Anwendung zu integrieren.
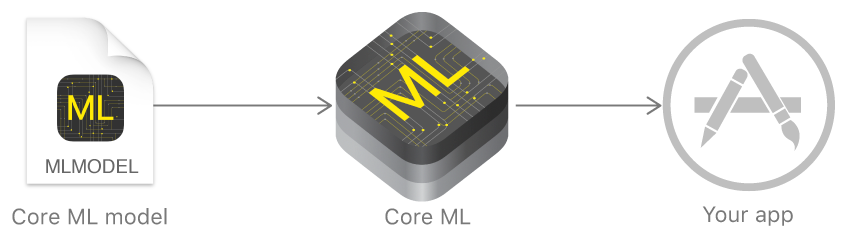
Mit Core ML können Sie viele Funktionen implementieren:
- Definition von Objekten in einem Foto und Video;
- prädiktive Texteingabe;
- Gesichtsverfolgung und -erkennung;
- Bewegungsanalyse;
- Barcode-Definition;
- Verständnis und Anerkennung von Text;
- Echtzeit-Bilderkennung;
- Bildstilisierung;
- und vieles mehr.
Core ML verwendet wiederum Low-Level-Metal, Accelerate und BNNS, und daher sind die Ergebnisse der Berechnungen sehr schnell.
Der Kernel unterstützt neuronale Netze, verallgemeinerte lineare Modelle, Feature-Engineering, baumbasierte Entscheidungsalgorithmen (Baumensembles), Support-Vektor-Maschinen-Methode und Pipeline-Modelle.
Apple zeigte jedoch zunächst keine eigenen Technologien zum Erstellen und Trainieren von Modellen, sondern entwickelte nur einen Konverter für andere beliebte Frameworks: Caffe, Keras, Scikit-Learn, XGBoost, LIBSVM.
Die Verwendung von Tools von Drittanbietern war oft nicht die einfachste Aufgabe, die trainierten Modelle waren ziemlich groß und das Training selbst nahm viel Zeit in Anspruch.
Ende des Jahres führte das Unternehmen Turi Create ein - ein Modell-Lern-Framework, dessen Hauptidee die Benutzerfreundlichkeit und Unterstützung für eine Vielzahl von Szenarien war - Bildklassifizierung, Definition von Objekten, Empfehlungssysteme und viele andere. Trotz seiner relativ einfachen Bedienung unterstützte Turi Create nur Python.
Erstellen Sie ML
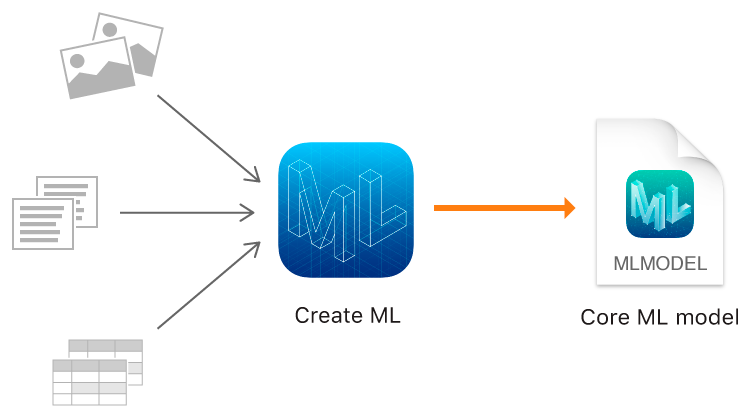
In diesem Jahr zeigte Apple neben Core ML 2 endlich ein eigenes Tool für Trainingsmodelle - das Create ML Framework mit den nativen Technologien von Apple - Xcode und Swift.
Es funktioniert schnell und das Erstellen von Modellmodellen mit Create ML ist wirklich einfach.
Auf der WWDC wurde die beeindruckende Leistung von Create ML und Core ML 2 am Beispiel der Memrise-Anwendung angekündigt. Wenn das Trainieren eines Modells mit 20.000 Bildern früher 24 Stunden gedauert hat, reduziert Create ML diese Zeit auf dem MacBook Pro auf 48 Minuten und auf dem iMac Pro auf bis zu 18 Minuten. Die Größe des trainierten Modells verringerte sich von 90 MB auf 3 MB.
Mit ML erstellen können Sie Bilder, Texte und strukturierte Objekte als Tabellen verwenden, z. B. als Quelldaten.
Bildklassifizierung
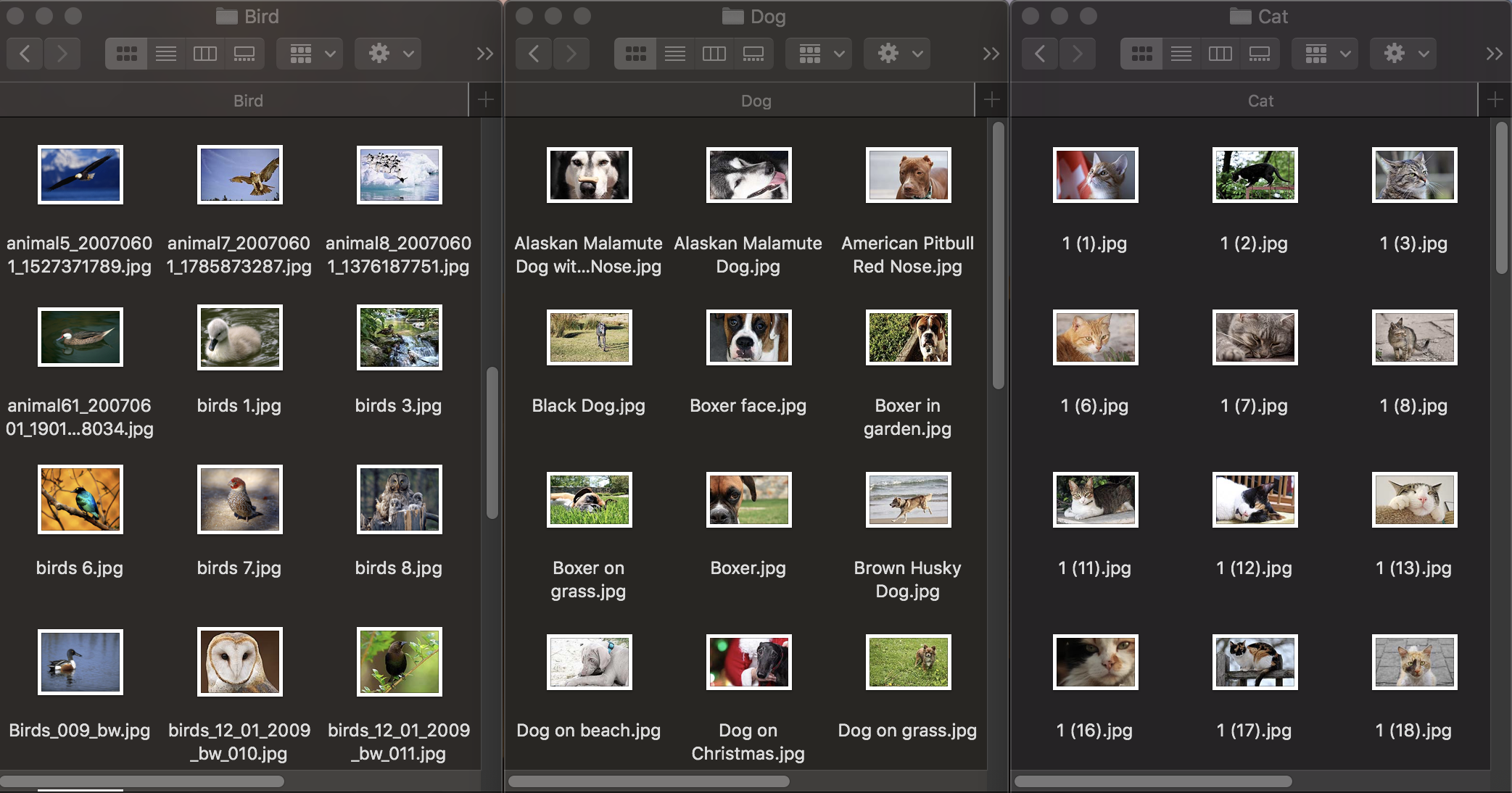
Lassen Sie uns zunächst sehen, wie die Bildklassifizierung funktioniert. Um das Modell zu trainieren, benötigen wir einen ersten Datensatz: Wir machen drei Gruppen von Tierfotos: Hunde, Katzen und Vögel und verteilen sie in Ordnern mit den entsprechenden Namen, die zu den Namen der Kategorien des Modells werden. Jede Gruppe enthält 100 Bilder mit einer Auflösung von bis zu 1920 × 1080 Pixel und einer Größe von bis zu 1 MB. Fotos sollten so unterschiedlich wie möglich sein, damit sich das trainierte Modell nicht auf Zeichen wie die Farbe im Bild oder den umgebenden Raum stützt.
Um zu überprüfen, wie gut ein trainiertes Modell mit der Objekterkennung umgehen kann, benötigen Sie einen Testdatensatz - Bilder, die nicht im Originaldatensatz enthalten sind.
Apple bietet zwei Möglichkeiten zur Interaktion mit Create ML: Verwenden der Benutzeroberfläche auf dem MacOS Playground Xcode und programmgesteuertes Verwenden von CreateMLUI.framework und CreateML.framework. Mit der ersten Methode reicht es aus, ein paar Codezeilen zu schreiben, die ausgewählten Bilder in den angegebenen Bereich zu übertragen und zu warten, bis das Modell lernt.

Auf dem Macbook Pro 2017 in der maximalen Konfiguration dauerte das Training 29 Sekunden für 10 Iterationen, und die Größe des trainierten Modells betrug 33 KB. Es sieht beeindruckend aus.
Versuchen wir herauszufinden, wie wir solche Indikatoren erreicht haben und was „unter der Haube“ liegt.
Die Aufgabe, Bilder zu klassifizieren, ist eine der beliebtesten Anwendungen von Faltungs-Neuronalen Netzen. Zunächst lohnt es sich zu erklären, was sie sind.
Eine Person, die ein Bild eines Tieres sieht, kann es anhand von Unterscheidungsmerkmalen schnell einer bestimmten Klasse zuordnen. Ein neuronales Netzwerk verhält sich ähnlich, indem es nach grundlegenden Merkmalen sucht. Unter Verwendung des anfänglichen Pixelarrays als Eingabe werden Informationen nacheinander durch Gruppen von Faltungsschichten geleitet und zunehmend komplexere Abstraktionen erstellt. Auf jeder nachfolgenden Ebene lernt sie, bestimmte Merkmale hervorzuheben - zuerst Linien, dann Liniensätze, geometrische Formen, Körperteile usw. Auf der letzten Ebene erhalten wir den Abschluss einer Klasse oder Gruppe wahrscheinlicher Klassen.
Im Fall von Create ML wird das Training des neuronalen Netzwerks nicht von Grund auf neu durchgeführt. Das Framework verwendet ein neuronales Netzwerk, das zuvor auf einem riesigen Datensatz trainiert wurde, der bereits eine große Anzahl von Schichten enthält und eine hohe Genauigkeit aufweist.
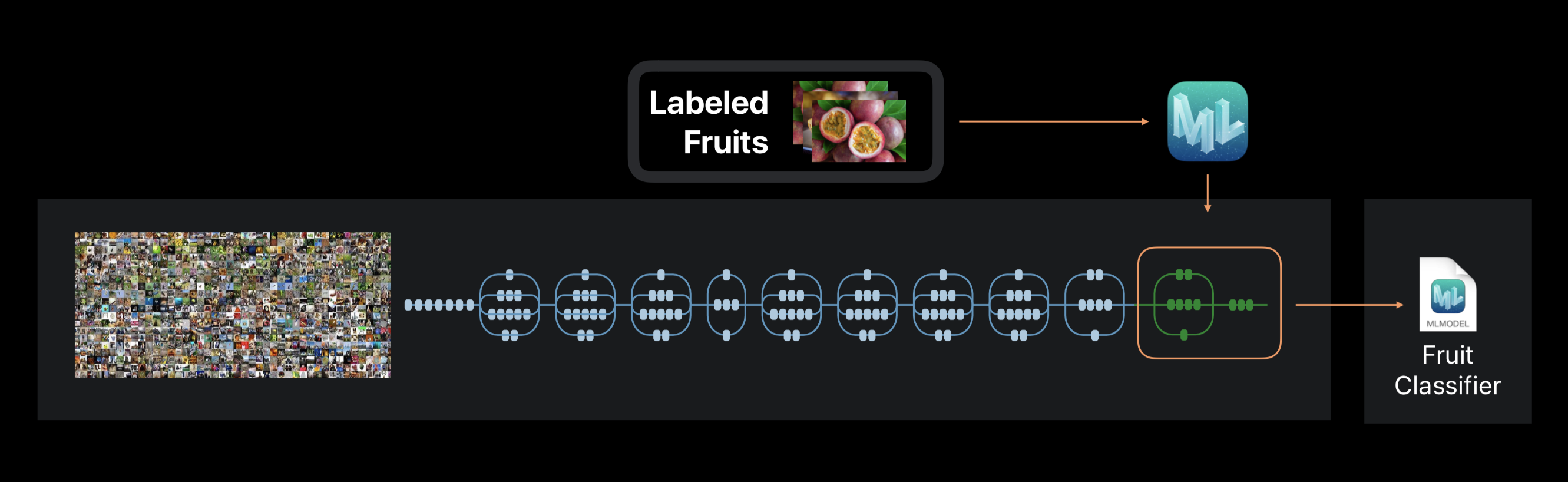
Diese Technologie wird als Transferlernen bezeichnet. Damit können Sie die Architektur eines vorab geschulten Netzwerks so ändern, dass es zur Lösung eines neuen Problems geeignet ist. Das geänderte Netzwerk wird dann auf einem neuen Datensatz trainiert.
Erstellen Sie während des Trainings Auszüge aus dem Foto mit etwa 1000 Unterscheidungsmerkmalen. Dies kann die Form von Objekten, die Farbe von Texturen, die Position der Augen, Größen und viele andere sein.
Es ist zu beachten, dass der ursprüngliche Datensatz, auf dem das verwendete neuronale Netzwerk wie unser trainiert wird, möglicherweise Fotos von Katzen, Hunden und Vögeln enthält, diese Kategorien jedoch nicht speziell zugeordnet sind. Alle Kategorien bilden eine Hierarchie. Daher ist es einfach unmöglich, dieses Netzwerk in seiner reinen Form anzuwenden - es ist notwendig, es auf unsere Daten umzuschulen.
Am Ende des Prozesses sehen wir, wie genau unser Modell nach mehreren Iterationen trainiert und getestet wurde. Um die Ergebnisse zu verbessern, können wir die Anzahl der Bilder im Originaldatensatz erhöhen oder die Anzahl der Iterationen ändern.
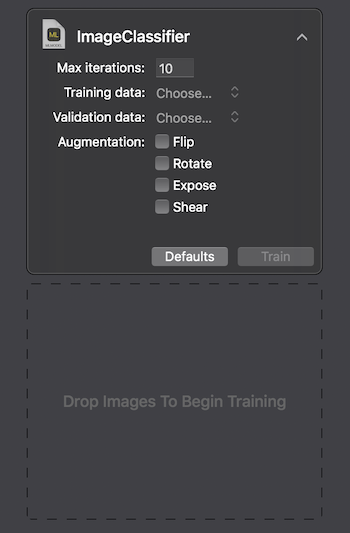
Als nächstes können wir das Modell selbst an einem Testdatensatz testen. Die darin enthaltenen Bilder müssen eindeutig sein, d. H. Geben Sie den Quellensatz nicht ein.
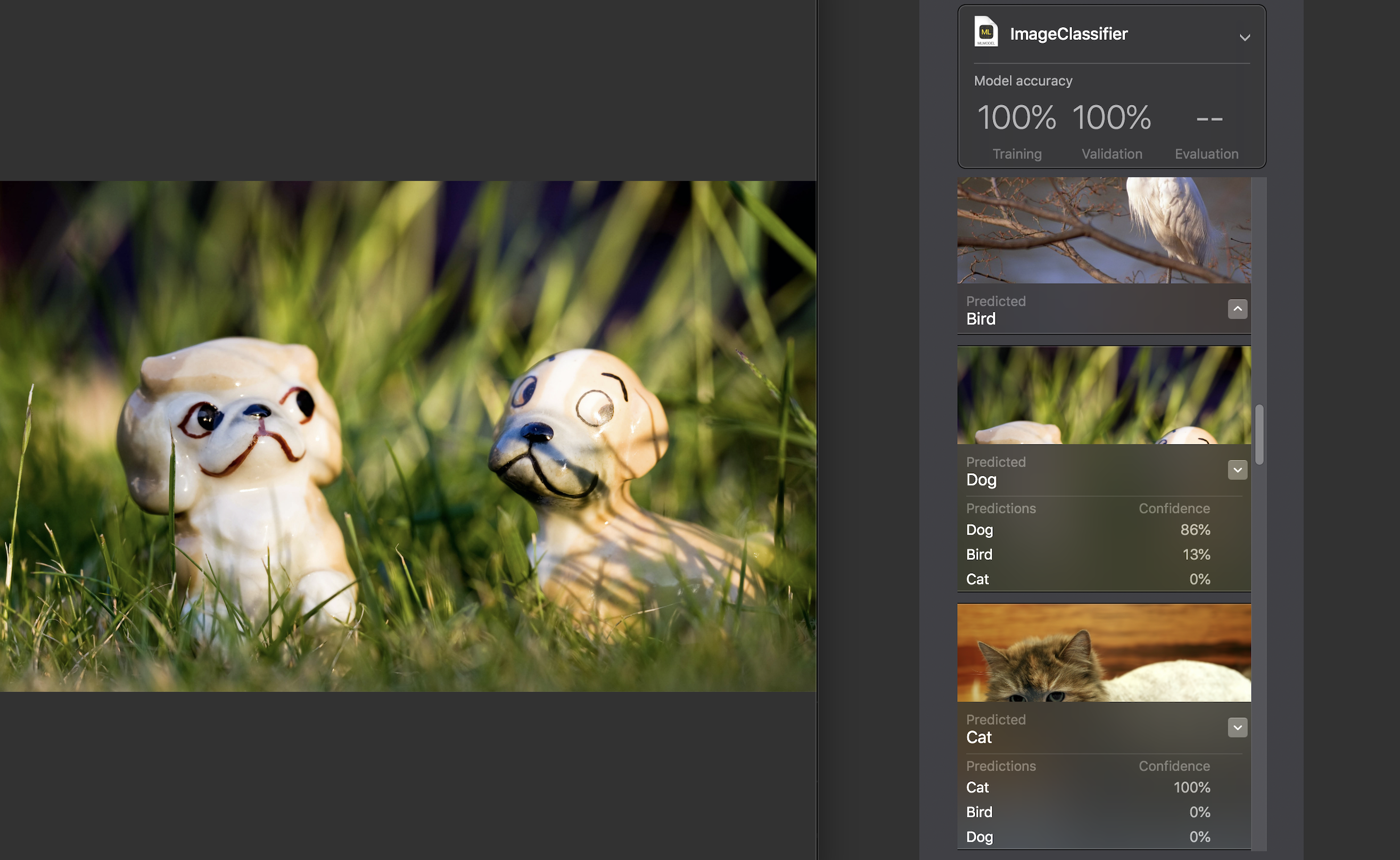
Für jedes Bild wird ein Vertrauensindikator angezeigt - wie genau mit Hilfe unseres Modells die Kategorie erkannt wurde.
Bei fast allen Fotos, mit seltenen Ausnahmen, lag diese Zahl bei 100%. Ich habe speziell das Bild, das Sie oben sehen, zum Testdatensatz hinzugefügt und, wie Sie sehen können, 86% des Hundes und 13% des Vogels darin ML erkannt.
Die Modellschulung ist abgeschlossen. Sie müssen lediglich die * .mlmodel-Datei speichern und Ihrem Projekt hinzufügen.
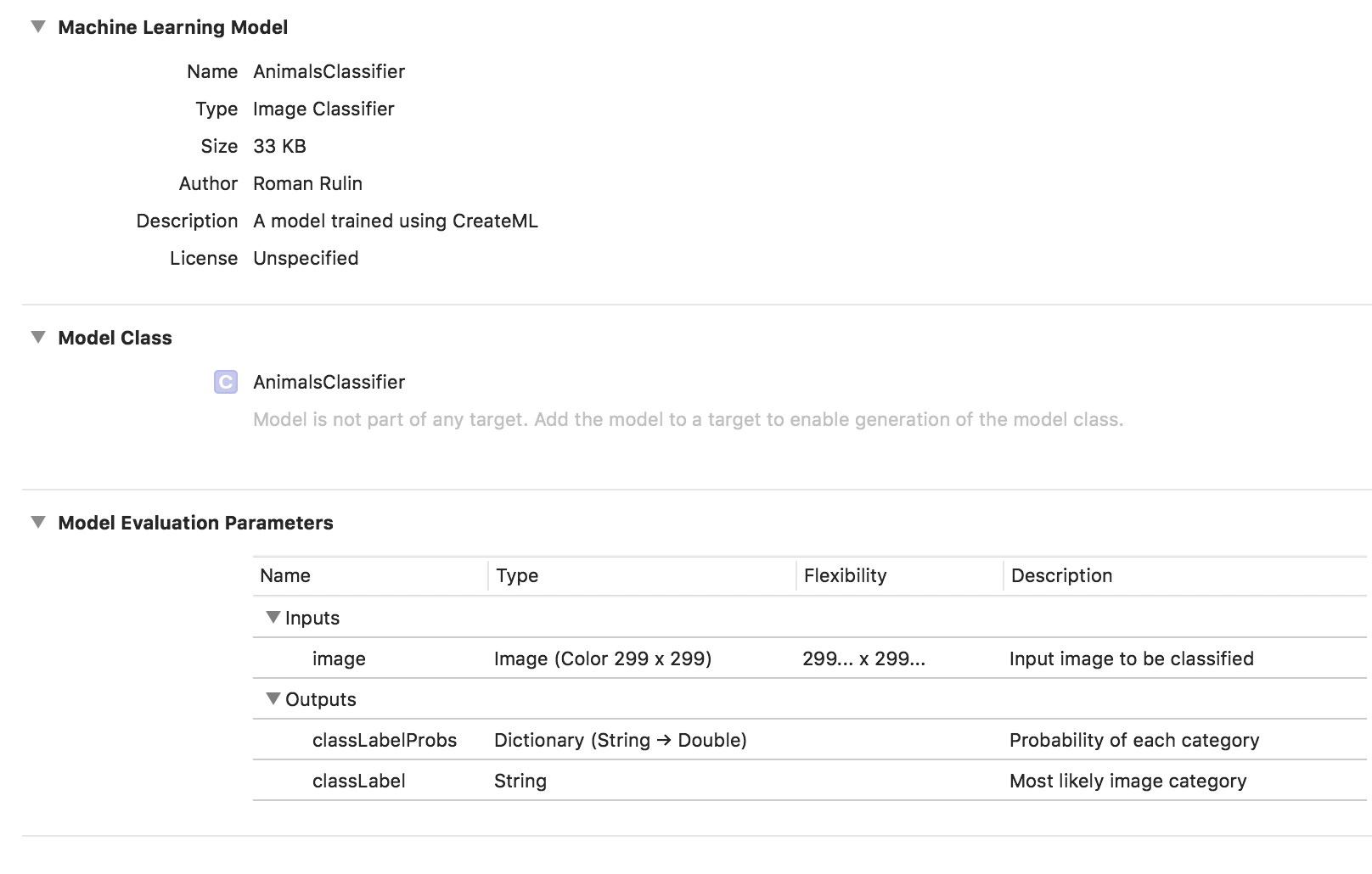
Um das Modell zu testen, habe ich eine einfache Anwendung mit dem Vision-Framework geschrieben. Sie können mit Core ML-Modellen arbeiten und Probleme damit lösen, z. B. Bildklassifizierung oder Objekterkennung.
Unsere Anwendung erkennt das Bild von der Kamera des Geräts und zeigt die Kategorie und den Prozentsatz des Vertrauens in die Klassifizierung an.
Wir initialisieren das Core ML-Modell für die Arbeit mit Vision und konfigurieren die Abfrage:
func setupVision() { guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model) else { fatalError("Can't load VisionML model") } let request = VNCoreMLRequest(model: visionModel) { (request, error) in guard let results = request.results else { return } self.handleRequestResults(results) } requests = [request] }
Fügen Sie eine Methode hinzu, die die Ergebnisse von VNCoreMLRequest verarbeitet. Wir zeigen nur diejenigen mit einem Vertrauensindikator von mehr als 70%:
func handleRequestResults(_ results: [Any]) { let categoryText: String? defer { DispatchQueue.main.async { self.categoryLabel.text = categoryText } } guard let foundObject = results .compactMap({ $0 as? VNClassificationObservation }) .first(where: { $0.confidence > 0.7 }) else { categoryText = nil return } let category = categoryTitle(identifier: foundObject.identifier) let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%" categoryText = "\(category) \(confidence)" }
Und das letzte - wir werden die Delegatenmethode AVCaptureVideoDataOutputSampleBufferDelegate hinzufügen, die mit jedem neuen Bild von der Kamera aufgerufen wird, und die Anforderung ausführen:
func captureOutput( _ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } var requestOptions: [VNImageOption: Any] = [:] if let cameraIntrinsicData = CMGetAttachment( sampleBuffer, key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, attachmentModeOut: nil) { requestOptions = [.cameraIntrinsics:cameraIntrinsicData] } let imageRequestHandler = VNImageRequestHandler( cvPixelBuffer: pixelBuffer, options: requestOptions) do { try imageRequestHandler.perform(requests) } catch { print(error) } }
Lassen Sie uns überprüfen, wie gut das Modell mit seiner Aufgabe zurechtkommt:

Die Kategorie wird mit ziemlich hoher Genauigkeit bestimmt. Dies ist besonders überraschend, wenn man bedenkt, wie schnell das Training verlief und wie klein der ursprüngliche Datensatz war. Vor einem dunklen Hintergrund zeigt das Modell regelmäßig Vögel, aber ich denke, dies kann leicht gelöst werden, indem die Anzahl der Bilder im Originaldatensatz erhöht oder das akzeptable Mindestmaß an Vertrauen erhöht wird.
Wenn Sie das Modell neu trainieren möchten, um eine andere Kategorie zu klassifizieren, fügen Sie einfach eine neue Gruppe von Bildern hinzu und wiederholen Sie den Vorgang - dies dauert einige Minuten.
Als Experiment habe ich einen weiteren Datensatz erstellt, in dem ich alle Fotos von Katzen auf dem Foto einer Katze aus verschiedenen Blickwinkeln geändert habe, jedoch auf demselben Hintergrund und in derselben Umgebung. In diesem Fall machte das Modell fast immer Fehler und erkannte die Kategorie in einem leeren Raum, wobei es sich anscheinend auf Farbe als Schlüsselmerkmal stützte.
Ein weiteres interessantes Feature, das erst in diesem Jahr in Vision eingeführt wurde, ist die Fähigkeit, Objekte im Bild in Echtzeit zu erkennen. Es wird durch die VNRecognizedObjectObservation-Klasse dargestellt, mit der Sie die Kategorie eines Objekts und seine Position abrufen können - boundingBox.

Mit Create ML können jetzt keine Modelle zur Implementierung dieser Funktionalität erstellt werden. Apple schlägt in diesem Fall die Verwendung von Turi Create vor. Der Vorgang ist nicht viel komplizierter als der oben beschriebene: Sie müssen Kategorieordner mit Fotos und einer Datei vorbereiten, in der für jedes Bild die Koordinaten des Rechtecks angegeben werden, in dem sich das Objekt befindet.
Verarbeitung natürlicher Sprache
Die nächste Funktion zum Erstellen von ML besteht darin, Modelle zu trainieren, um Texte in natürlicher Sprache zu klassifizieren - beispielsweise um die emotionale Färbung von Sätzen zu bestimmen oder Spam zu erkennen.
Um ein Modell zu erstellen, müssen wir eine Tabelle mit dem Originaldatensatz - Sätzen oder ganzen Texten, die einer bestimmten Kategorie zugeordnet sind - sammeln und das Modell mithilfe des MLTextClassifier-Objekts trainieren:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json")) let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5) let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label") try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))
In diesem Fall ist das trainierte Modell vom Typ Text Classifier:
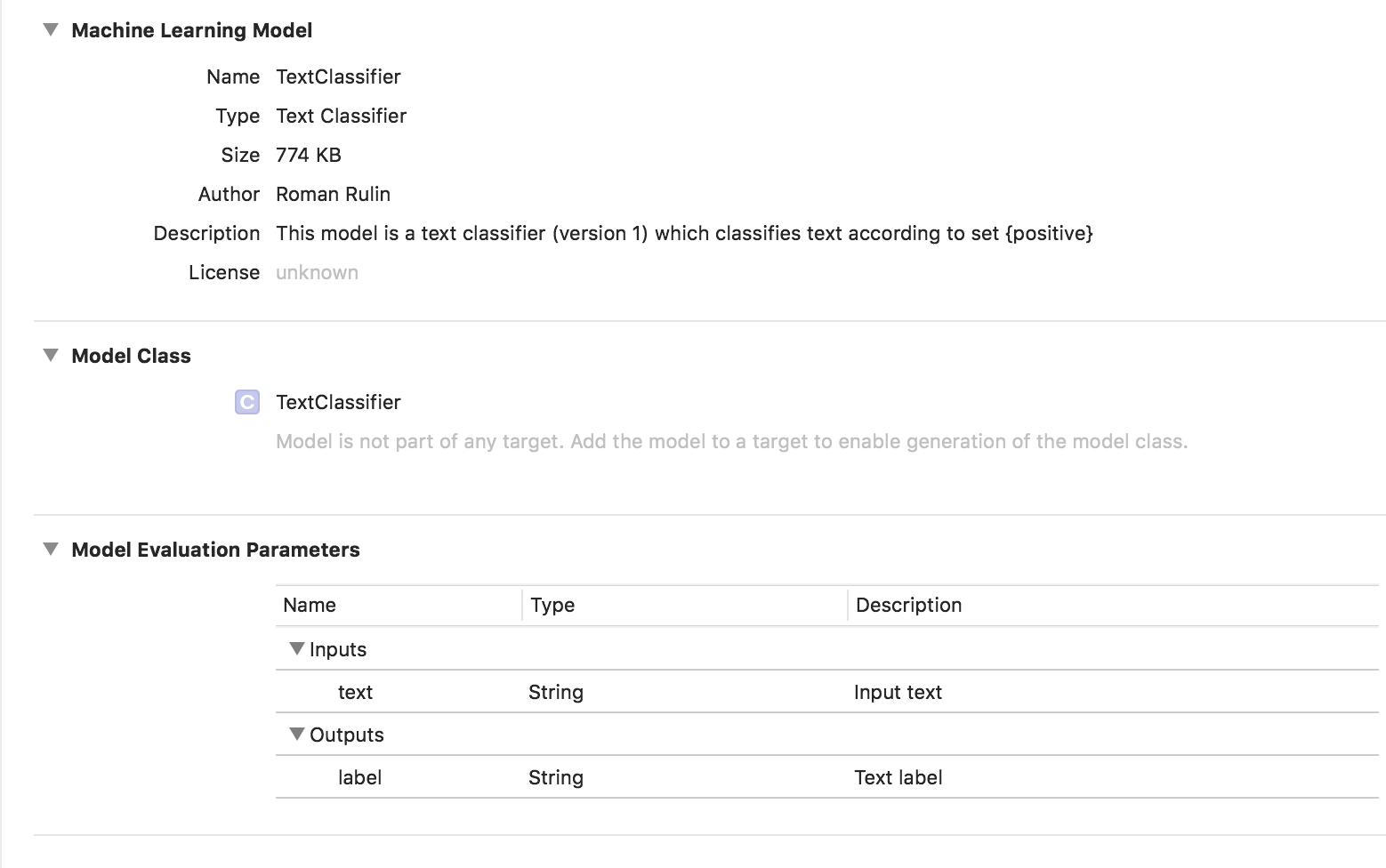
Tabellarische Daten
Schauen wir uns eine weitere Funktion von Create ML genauer an - das Trainieren eines Modells unter Verwendung strukturierter Daten (Tabellen).
Wir werden eine Testanwendung schreiben, die den Preis einer Wohnung basierend auf ihrem Standort auf der Karte und anderen angegebenen Parametern vorhersagt.
Wir haben also eine Tabelle mit abstrakten Daten zu Wohnungen in Moskau in Form einer CSV-Datei: Die Fläche jeder Wohnung, Etage, Anzahl der Räume und Koordinaten (Breite und Länge) sind bekannt. Darüber hinaus sind die Kosten für jede Wohnung bekannt. Je näher am Zentrum oder je größer die Fläche, desto höher der Preis.
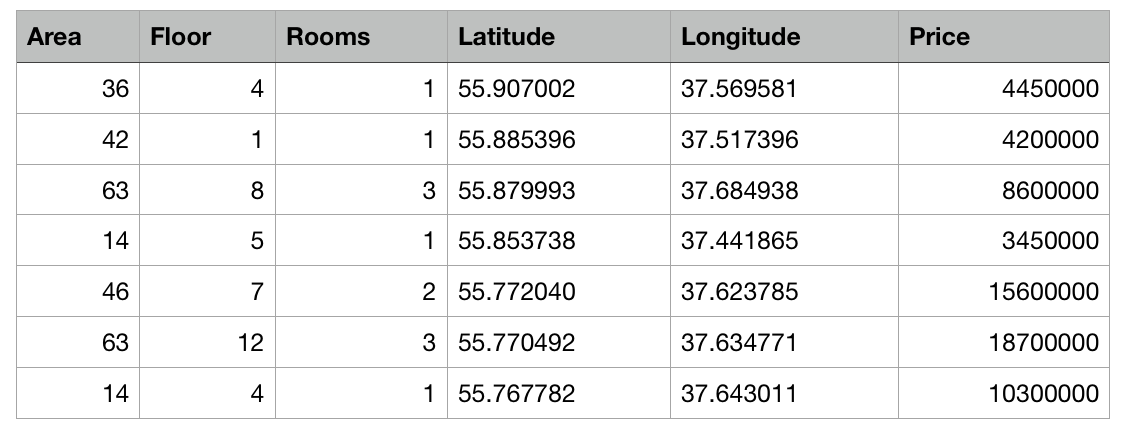
Die Aufgabe von Create ML besteht darin, ein Modell zu erstellen, mit dem der Preis einer Wohnung anhand dieser Merkmale vorhergesagt werden kann. Eine solche Aufgabe beim maschinellen Lernen wird als Regressionsaufgabe bezeichnet und ist ein klassisches Beispiel für das Lernen mit einem Lehrer.
Create ML unterstützt viele Modelle - lineare Regression, Entscheidungsbaumregression, Baumklassifizierer, logistische Regression, zufälliger Waldklassifizierer, verstärkte Baumregression usw.
Wir werden das MLRegressor-Objekt verwenden, das basierend auf den Eingabedaten die beste Option auswählt.
Initialisieren Sie zunächst das MLDataTable-Objekt mit dem Inhalt unserer CSV-Datei:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv") let apartmentsData = try MLDataTable(contentsOf: trainingFile)
Wir teilen den anfänglichen Datensatz in Daten für Modelltraining und -tests in einem Prozentsatz von 80/20 auf:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)
Wir erstellen das MLRegressor-Modell, das die Daten für das Training und den Namen der Spalte angibt, deren Werte wir vorhersagen möchten. Der aufgabenspezifische Regressortyp (linear, Entscheidungsbaum, verstärkter Baum oder zufällige Gesamtstruktur) wird basierend auf der Untersuchung der Eingabedaten automatisch ausgewählt. Wir können auch Feature-Spalten angeben - spezifische Parameterspalten für die Analyse. In diesem Beispiel ist dies jedoch nicht erforderlich. Wir verwenden alle Parameter. Speichern Sie am Ende das trainierte Modell und fügen Sie es dem Projekt hinzu:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price") let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel") try model.write(to: modelPath, metadata: nil)
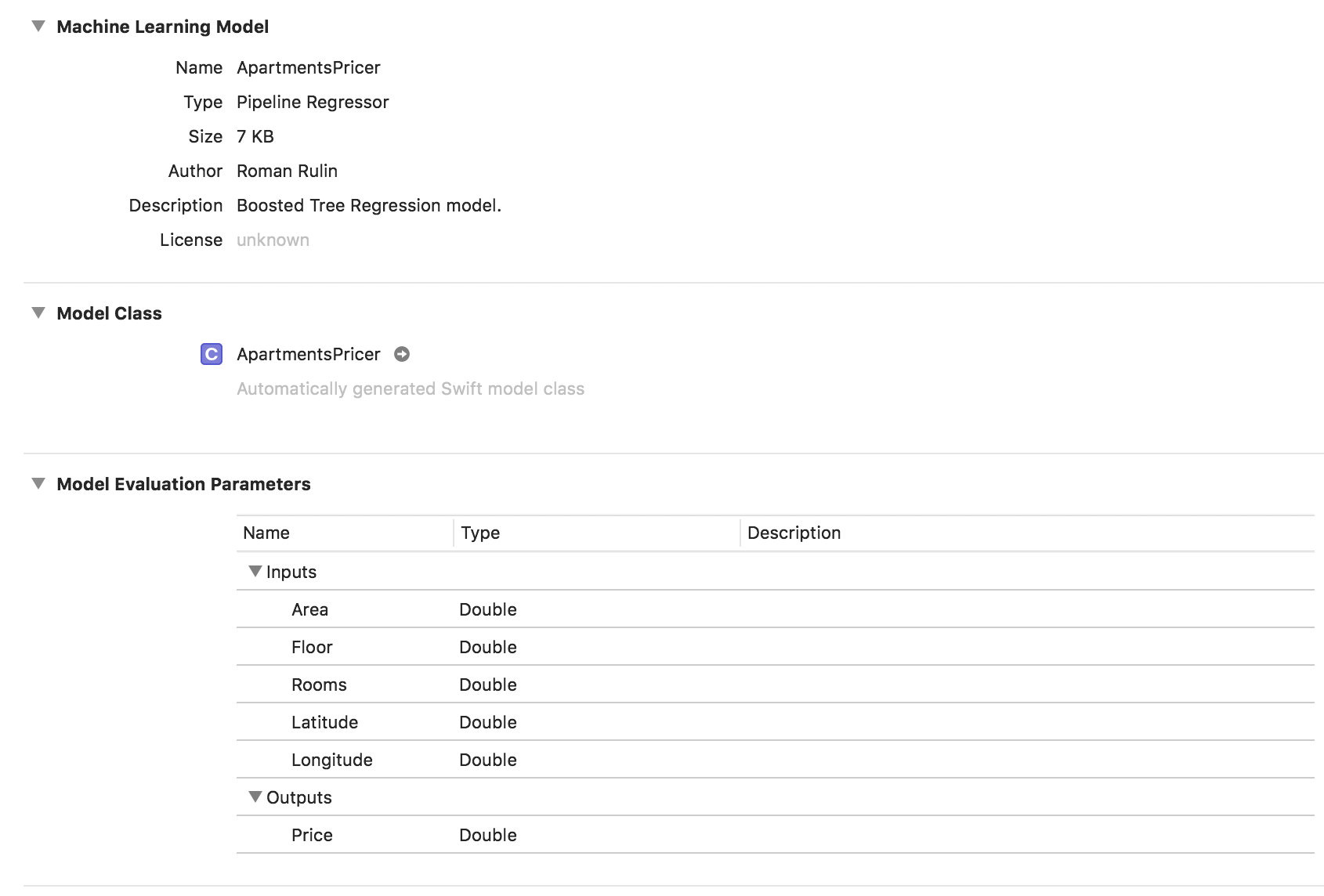
In diesem Beispiel sehen wir, dass der Modelltyp bereits Pipeline-Regressor ist und das Feld Beschreibung den automatisch ausgewählten Regressortyp - Boosted Tree Regression Model - enthält. Die Parameter Inputs und Outputs entsprechen den Spalten der Tabelle, ihr Datentyp wurde jedoch Double.
Überprüfen Sie nun das Ergebnis.
Initialisieren Sie das Modellobjekt:
let model = ApartmentsPricer()
Wir rufen die Vorhersagemethode auf und übergeben die angegebenen Parameter an sie:
let area = Double(areaSlider.value) let floor = Double(floorSlider.value) let rooms = Double(roomsSlider.value) let latitude = annotation.coordinate.latitude let longitude = annotation.coordinate.longitude let prediction = try? model.prediction( area: area, floor: floor, rooms: rooms, latitude: latitude, longitude: longitude)
Wir zeigen den prognostizierten Wert der Kosten an:
let price = prediction?.price priceLabel.text = formattedPrice(price)
Wenn Sie einen Punkt auf der Karte oder Parameterwerte ändern, erhalten wir den Wohnungspreis ziemlich nahe an unseren Testdaten:
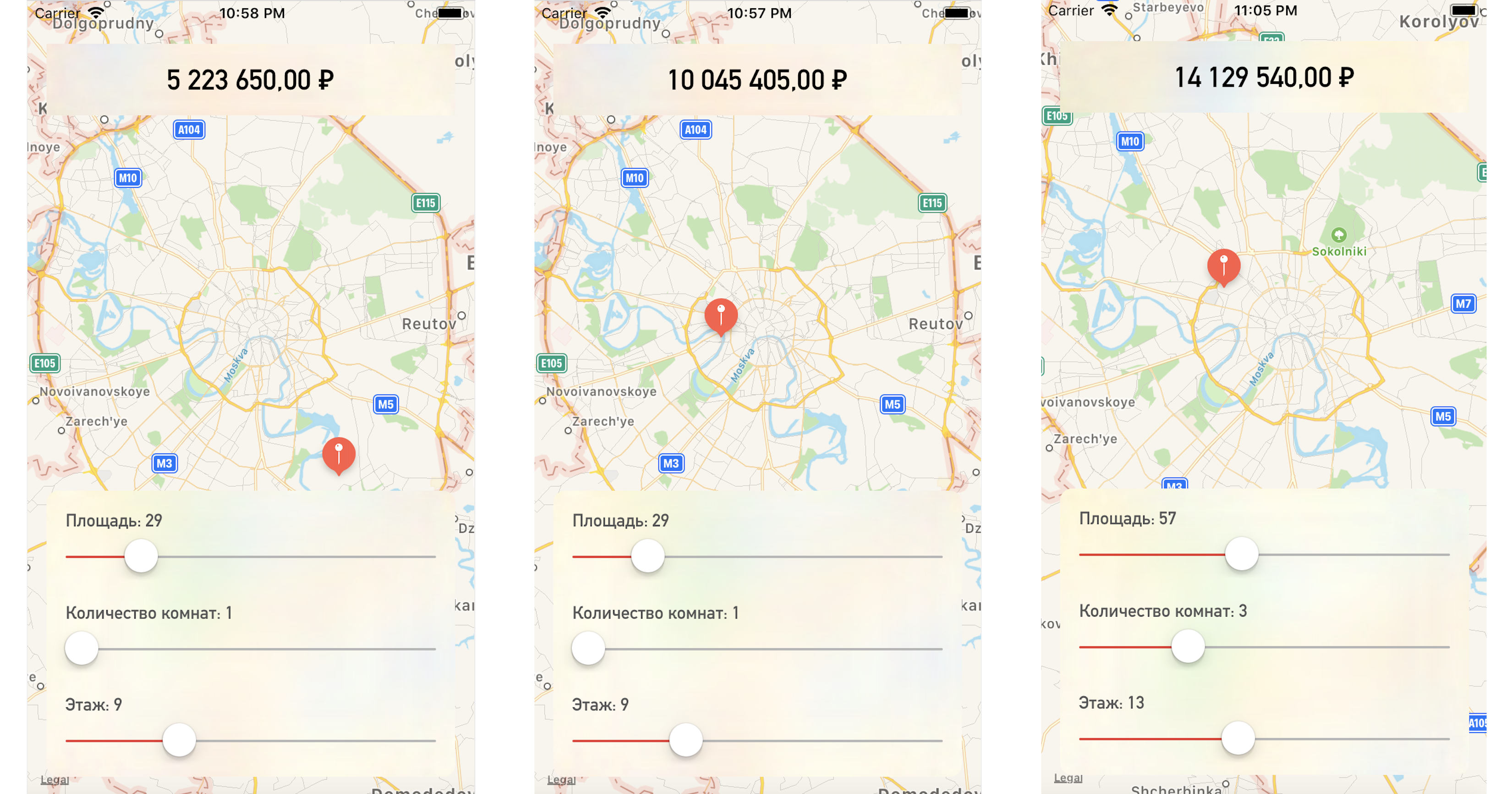
Fazit
Das Create ML-Framework ist jetzt eine der einfachsten Möglichkeiten, mit Technologien für maschinelles Lernen zu arbeiten. Es ist noch nicht möglich, Modelle zur Lösung einiger Probleme zu erstellen: Erkennung von Objekten in einem Bild, Stilisierung eines Fotos, Bestimmung ähnlicher Bilder, Erkennung physikalischer Aktionen anhand von Daten eines Beschleunigungsmessers oder Gyroskops, die beispielsweise von Turi Create verarbeitet werden.
Es ist jedoch anzumerken, dass Apple im vergangenen Jahr in diesem Bereich ernsthafte Fortschritte erzielt hat, und wir werden mit Sicherheit bald die Entwicklung der beschriebenen Technologien sehen.