In diesem Teil des Artikels werden wir weiterhin verschiedene Arten von Tests in der Produktion betrachten. Wer den ersten Teil übersprungen hat, kann ihn
hier lesen. Für den Rest - willkommen bei Katze.
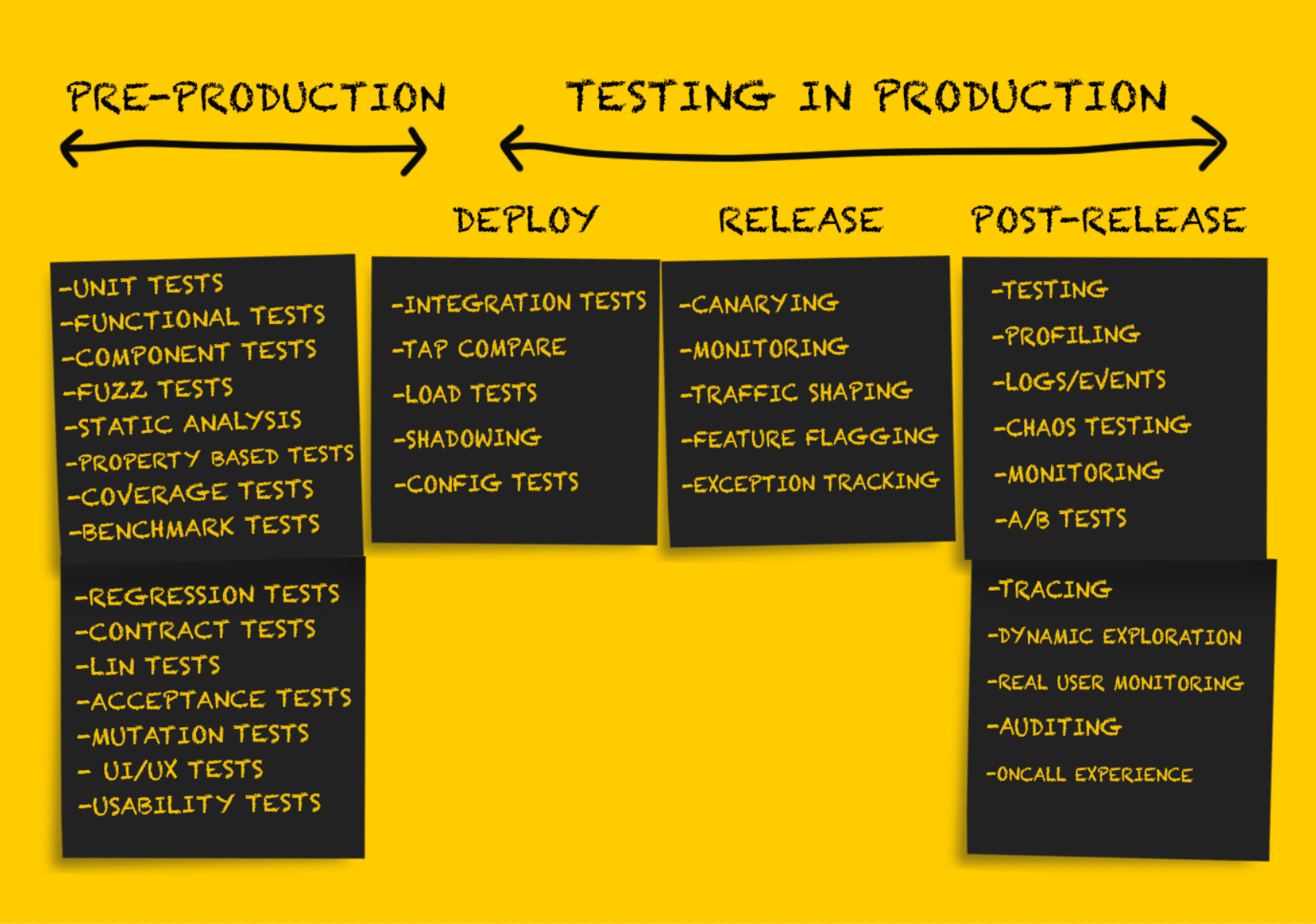
Produktionstests: Freigabe
Nach dem Testen des Dienstes nach der
Bereitstellung muss er für die
Freigabe vorbereitet werden.
Es ist wichtig zu beachten, dass zu diesem Zeitpunkt das Zurücksetzen von Änderungen nur in Situationen eines
nachhaltigen Scheiterns möglich ist, zum Beispiel:
- Service Failure Looping;
- Überschreiten der Wartezeit für eine signifikante Anzahl von Verbindungen im Upstream, was zu einem starken Anstieg der Fehlerhäufigkeit führt;
- Inakzeptable Konfigurationsänderungen, z. B. das Fehlen eines geheimen Schlüssels in einer Umgebungsvariablen, der eine Fehlfunktion des Dienstes verursacht (Umgebungsvariablen sind im Allgemeinen besser zu vermeiden, dies ist jedoch ein Thema für eine andere Diskussion).
Durch gründliche Tests in der
Bereitstellungsphase kann ich unangenehme Überraschungen in der
Release- Phase idealerweise minimieren oder vollständig vermeiden. Es gibt jedoch eine Reihe von Empfehlungen für die sichere Freigabe von neuem Code.
Kanarische Bereitstellung
Canary Deployment ist eine teilweise
Freigabe eines Dienstes in der Produktion. Während der grundlegenden Integritätsprüfung werden die kleinen Teile des aktuellen Verkehrs in der Produktionsumgebung an die freigegebenen Teile gesendet. Die Ergebnisse der Teile des Dienstes werden überwacht, während der Verkehr verarbeitet wird, die Indikatoren werden mit den Referenzindikatoren verglichen (die sich nicht auf kanarische beziehen), und wenn sie außerhalb der akzeptablen Schwellenwerte liegen, wird ein Rollback auf den vorherigen Zustand durchgeführt. Obwohl dieser Ansatz normalerweise bei der Freigabe von Serversoftware verwendet wird, werden auch
kanarische Tests von Client-Software immer häufiger.
Verschiedene Faktoren beeinflussen, welcher Verkehr für den Einsatz auf Kanarienvögeln verwendet wird. In einer Reihe von Unternehmen erhalten die freigegebenen Teile des Dienstes zunächst nur internen Benutzerverkehr (sogenanntes Hundefutter). Wenn keine Fehler festgestellt werden, wird ein kleiner Teil des Datenverkehrs in der Produktionsumgebung hinzugefügt. Anschließend wird eine vollständige Bereitstellung durchgeführt. Es wird
empfohlen, bei ungültigen Ergebnissen der kanarischen Bereitstellung
automatisch auf den vorherigen Status zurückzusetzen, und Tools wie
Spinnaker bieten integrierte Unterstützung für automatisierte Analyse- und Rollback-Funktionen.
Es gibt einige Probleme mit Kanarientests, und
dieser Artikel bietet einen ziemlich vollständigen Überblick über sie.
Überwachung
Die Überwachung ist in
jeder Phase der Produktbereitstellung in der Produktion ein absolut notwendiges Verfahren. Diese Funktion ist jedoch in der
Release- Phase besonders wichtig. Die Überwachung eignet sich gut, um Informationen über die allgemeine Systemleistung zu erhalten. Die Überwachung aller Daten auf der Welt ist jedoch möglicherweise nicht die beste Lösung.
Eine effektive Überwachung wird punktweise durchgeführt, sodass Sie eine kleine Anzahl von Modi für einen nachhaltigen Ausfall des Systems oder eine Reihe grundlegender Indikatoren identifizieren können. Beispiele für solche Fehlermodi können sein:
- Erhöhung der Fehlerrate;
- eine Verringerung der Gesamtgeschwindigkeit der Bearbeitung von Anfragen während des gesamten Dienstes an einem bestimmten Endpunkt oder, noch schlimmer, eine vollständige Einstellung der Arbeit;
- erhöhte Verzögerung.
Die Beobachtung eines dieser Modi für nachhaltiges Versagen ist die Grundlage für ein sofortiges Zurücksetzen auf einen früheren Status oder ein Zurücksetzen neuer
veröffentlichter Softwareversionen. Es ist wichtig zu bedenken, dass die Überwachung in dieser Phase wahrscheinlich nicht vollständig und indikativ ist. Viele glauben, dass die ideale Anzahl von Signalen, die während der Überwachung überwacht werden, zwischen 3 und 5 liegt, aber
definitiv nicht mehr als 7 bis 10. Das Kraken Facebook Whitepaper bietet folgende Lösung:
"Das Problem wird mithilfe einer einfach konfigurierbaren Überwachungskomponente gelöst, die über zwei grundlegende Indikatoren (das 99. Perzentil der Antwortzeit des Webservers und die Häufigkeit des Auftretens schwerwiegender HTTP-Fehler) informiert ist, die die Qualität der Benutzerinteraktion objektiv beschreiben."Der Satz von System- und Anwendungsindikatoren, die während der Freigabephase überwacht werden, wird am besten während des Systemdesigns bestimmt.
Ausnahmeverfolgung
Wir sprechen über das Verfolgen von Ausnahmen in der Release-Phase, obwohl es den Anschein hat, dass dies in der
Bereitstellungsphase und nach der Veröffentlichung nicht weniger nützlich wäre. Tools zur Ausnahmeverfolgung garantieren häufig nicht die gleiche Gründlichkeit, Genauigkeit und Massenabdeckung wie einige andere Tools zur Systemüberwachung, können jedoch dennoch sehr nützlich sein.
Open Source-Tools (wie
Sentry ) zeigen erweiterte Informationen zu eingehenden Anforderungen an und erstellen Stapel von Trace-Daten und lokalen Variablen. Dies vereinfacht den Debugging-Prozess, der normalerweise aus dem Anzeigen von Ereignisprotokollen besteht, erheblich. Die Ausnahmeverfolgung ist auch nützlich, wenn Probleme sortiert und priorisiert werden, für die kein vollständiger Rollback auf einen vorherigen Status erforderlich ist (z. B. ein Grenzfall, der eine Ausnahme auslöst).
Verkehrsgestaltung
Die Gestaltung des Verkehrs (Verkehrsumverteilung) ist weniger eine eigenständige Form des Testens als vielmehr ein Instrument zur Unterstützung des kanarischen Ansatzes und der schrittweisen Veröffentlichung neuen Codes. Tatsächlich wird die Verkehrsformung durch Aktualisieren der Load-Balancer-Konfiguration sichergestellt, sodass Sie schrittweise mehr Verkehr auf die neue
veröffentlichte Version umleiten können.
Diese Methode ist auch nützlich für die schrittweise Bereitstellung neuer Software (getrennt von der regulären Bereitstellung). Betrachten Sie ein Beispiel. Imgix musste im Juni 2016 eine grundlegend neue Infrastrukturarchitektur bereitstellen. Nach dem ersten Testen der neuen Infrastruktur mit einer bestimmten Menge an dunklem Datenverkehr wurde mit der Bereitstellung in der Produktion begonnen, wobei zunächst etwa 1% des Datenverkehrs in der Produktionsumgebung auf einen neuen Stapel umgeleitet wurde. Im Laufe mehrerer Wochen wurde dann das auf dem neuen Stapel ankommende Datenvolumen erhöht (um Probleme auf dem Weg zu lösen), bis 100% des Datenverkehrs verarbeitet wurden.
Die Popularität der Service-Mesh-Architektur hat ein neues Interesse an Proxy-Servern ausgelöst. Infolgedessen unterstützten sowohl die alten (nginx, HAProxy) als auch die neuen (Envoy, Conduit) Proxys neue Funktionen, um die Konkurrenz zu überholen. Es scheint mir, dass die Zukunft, in der die Verkehrsumverteilung von 0 auf 100% in der Phase der Produktfreigabe automatisch durchgeführt wird, vor der Tür steht.
Produktionstests: Nach der Freigabe
Tests
nach der Freigabe werden als Überprüfung durchgeführt, die
nach einer erfolgreichen
Freigabe des Codes durchgeführt wird. Zu diesem Zeitpunkt können Sie sicher sein, dass der gesamte Code korrekt ist, erfolgreich in der Produktion
freigegeben wurde und den Datenverkehr ordnungsgemäß verarbeitet. Der bereitgestellte Code wird direkt oder indirekt unter realen Bedingungen verwendet, um echte Kunden zu bedienen oder Aufgaben auszuführen, die erhebliche Auswirkungen auf das Geschäft haben.
Das Ziel aller Tests in dieser Phase besteht hauptsächlich darin, die Funktionsfähigkeit des Systems unter Berücksichtigung verschiedener möglicher Lasten und Verkehrsmuster zu überprüfen. Der beste Weg, dies zu tun, besteht darin, dokumentarische Beweise für alles zu sammeln, was in der Produktion passiert, und sie sowohl zum Debuggen als auch zum Erhalten eines vollständigen Bildes des Systems zu verwenden.
Feature-Flagging oder Dark Launch
Die älteste Veröffentlichung über die erfolgreiche Verwendung von Feature-Flags, die ich gefunden habe, wurde vor fast zehn Jahren veröffentlicht.
Featureflags.io bietet hierfür den umfassendsten Leitfaden.
„Feature-Flagging ist eine Methode, mit der Entwickler eine neue Funktion mithilfe von if-then-Anweisungen markieren, um mehr Kontrolle über ihre Veröffentlichung zu erhalten. Durch Markieren und Isolieren einer Funktion auf diese Weise kann der Entwickler diese Funktion unabhängig vom Bereitstellungsstatus ein- und ausschalten. Dies trennt die Freigabe der Funktion effektiv von der Bereitstellung des Codes. "Durch Markieren des neuen Codes können Sie dessen Leistung und Leistung in der Produktion nach Bedarf testen. Das Kennzeichnen von Merkmalen ist eine der allgemein akzeptierten Arten von Tests in der Produktion. Es ist allgemein bekannt und wird häufig in
verschiedenen Quellen beschrieben . Die Tatsache, dass diese Methode beim Testen der
Übertragung von Datenbanken oder Software für persönliche Systeme verwendet werden kann, ist viel weniger bekannt.
Was Autoren von Artikeln selten schreiben, sind die besten Methoden zum Entwickeln und Verwenden von Funktionsflags. Die unkontrollierte Verwendung von Flags kann ein ernstes Problem sein. Der Mangel an Disziplin beim Entfernen nicht verwendeter Flaggen nach einem bestimmten Zeitraum führt manchmal dazu, dass Sie eine vollständige Prüfung durchführen und veraltete Flaggen löschen müssen, die sich über Monate (wenn nicht über Jahre) der Arbeit angesammelt haben.
A / B-Tests
A / B-Tests werden häufig im Rahmen einer experimentellen Analyse durchgeführt und gelten nicht als Tests in der Produktion. Aus diesem Grund werden A / B-Tests nicht nur häufig (manchmal sogar
zweifelhaft ) verwendet, sondern auch
aktiv untersucht und
beschrieben (einschließlich Artikeln darüber,
was eine effektive Scorecard für Online-Experimente bestimmt). Viel seltener werden A / B-Tests verwendet, um verschiedene Hardwarekonfigurationen oder virtuelle Maschinen zu testen. Sie werden oft als "Tuning" bezeichnet (z. B. JVM-Tuning), werden jedoch nicht als typische A / B-Tests eingestuft (obwohl das Tuning als eine Art A / B-Test angesehen werden kann, der bei Messungen mit der gleichen Genauigkeit durchgeführt wird). .
Protokolle, Ereignisse, Indikatoren und Ablaufverfolgung
Hier
können Sie über die sogenannten „drei Wale der Beobachtbarkeit“
lesen - Protokolle, Indikatoren und verteilte Verfolgung.
Profilerstellung
In einigen Fällen ist es zur Diagnose von Leistungsproblemen erforderlich, Anwendungsprofile in der Produktion zu verwenden. Abhängig von den unterstützten Sprachen und Laufzeiten kann die Profilerstellung ein relativ einfaches Verfahren sein, bei dem der Anwendung nur eine Codezeile hinzugefügt wird (
import _ "net/http/pprof" im Fall von Go). Andererseits kann es erforderlich sein, viele Werkzeuge zu verwenden oder den Prozess mit der Black-Box-Methode zu testen und die Ergebnisse mit Werkzeugen wie
Flammengraphen zu überprüfen .
Tee-Test
Viele Leute betrachten solche Tests als eine Art Schattenverdoppelung von Daten, da in beiden Fällen der Datenverkehr in der Produktionsumgebung an Cluster oder Prozesse außerhalb der Produktion gesendet wird. Meiner Meinung nach unterscheidet sich die Verwendung von Datenverkehr zu Testzwecken etwas von der Verwendung zu
Debugging- Zwecken.
Etsy schrieb in seinem Blog über die Verwendung von Tee-Tests als Verifizierungswerkzeug (dieses Beispiel ähnelt wirklich der Schattenverdoppelung von Daten).
„Hier kann Tee als Tee- Befehl in der Befehlszeile verstanden werden. Wir haben eine iRule- Regel geschrieben, die auf einem vorhandenen F5-Load-Balancer basiert, um den an einen der Pools gerichteten HTTP-Verkehr zu klonen und in einen anderen Pool umzuleiten. Auf diese Weise konnten wir den Datenverkehr in der Produktionsumgebung verwenden, der an unseren API-Cluster geleitet wurde, und eine Kopie davon zum Vergleich an den experimentellen HHVM-Cluster sowie an einen isolierten PHP-Cluster senden.
Diese Technik hat sich als sehr effektiv erwiesen. Er erlaubte uns, die Leistung der beiden Konfigurationen anhand identischer Verkehrsprofile zu vergleichen. “Manchmal ist zum
Debuggen jedoch ein Abschlagstest erforderlich, der auf dem Datenverkehr in der Produktionsumgebung in einem autonomen System basiert. In solchen Fällen kann das autonome System geändert werden, um die Ausgabe zusätzlicher Diagnoseinformationen oder ein anderes Kompilierungsverfahren (z. B. mithilfe des Stream-Bereinigungstools) zu konfigurieren, was den Fehlerbehebungsprozess erheblich vereinfacht. In solchen Fällen sollten Tee-Tests eher als
Debugging-Tools als als
Verifizierung betrachtet werden .
Bisher waren solche Debugging-Arten in
imgix relativ selten, wurden jedoch weiterhin verwendet, insbesondere bei Problemen mit verzögerungsempfindlichen Debugging-Anwendungen.
Im Folgenden finden Sie beispielsweise eine analytische Beschreibung eines dieser Vorfälle im Jahr 2015. Fehler 400 trat so selten auf, dass er beim Versuch, das Problem zu reproduzieren, fast nicht gesehen wurde. Sie erschien in nur wenigen Fällen von einer Milliarde. Tagsüber gab es nur sehr wenige. Infolgedessen stellte sich heraus, dass es einfach unmöglich war, das Problem zuverlässig zu reproduzieren. Daher war es erforderlich, das Debuggen mithilfe des Arbeitsverkehrs durchzuführen, um das Auftreten dieses Fehlers verfolgen zu können. Das hat mein ehemaliger Kollege dazu geschrieben:
„Ich habe eine Bibliothek ausgewählt, die intern sein sollte, aber letztendlich musste ich meine eigene basierend auf der vom System bereitgestellten Bibliothek erstellen. In der vom System bereitgestellten Version trat regelmäßig ein Fehler auf, der bei geringem Datenverkehr in keiner Weise auftrat. Der abgeschnittene Name im Titel war jedoch das eigentliche Problem.
In den nächsten zwei Tagen habe ich das Problem im Zusammenhang mit der erhöhten Häufigkeit falscher Fehler 400 eingehend untersucht. Der Fehler hat sich in einer sehr geringen Anzahl von Anforderungen manifestiert, und Probleme dieser Art sind schwer zu diagnostizieren. All dies sah aus wie die berüchtigte Nadel im Heuhaufen: Das Problem trat in einem Fall pro Milliarde auf.
Der erste Schritt beim Auffinden der Fehlerquelle bestand darin, alle HTTP-Rohanforderungsdaten abzurufen, die zu einer falschen Antwort führten. Um einen Tee-Test des eingehenden Datenverkehrs bei Verbindung mit einem Socket durchzuführen, habe ich dem Render-Server den Unix-Domain-Socket-Endpunkt hinzugefügt. Die Idee war, es uns zu ermöglichen, den Fluss des dunklen Verkehrs schnell und einfach ein- und auszuschalten und Tests direkt auf dem Computer des Entwicklers durchzuführen. Um Produktionsprobleme zu vermeiden, musste die Verbindung unterbrochen werden, wenn ein Gegendruckproblem auftrat. Das heißt, Wenn das Duplikat die Aufgabe nicht bewältigen konnte, wurde die Verbindung getrennt. Dieser Sockel war in einigen Fällen während der Entwicklung sehr nützlich. Dieses Mal haben wir es jedoch verwendet, um eingehenden Datenverkehr auf den ausgewählten Servern zu sammeln, in der Hoffnung, genügend Anforderungen zu erhalten, um das Muster aufzudecken, das zum Auftreten falscher Fehler 400 führte. Mit dsh und netcat konnte ich den eingehenden Datenverkehr relativ einfach in eine lokale Datei ausgeben .
Der größte Teil der Umgebung wurde für das Sammeln dieser Daten aufgewendet. Sobald wir genug Daten hatten, konnte ich Netcat verwenden, um sie auf dem lokalen System abzuspielen, dessen Konfiguration geändert wurde, um eine große Menge an Debugging-Informationen anzuzeigen. Und alles lief perfekt. Der nächste Schritt besteht darin, die Daten mit der höchstmöglichen Geschwindigkeit abzuspielen. In diesem Fall hat die Schleife mit der Bedingungsprüfung die Rohanforderungen einzeln gesendet. Nach ungefähr zwei Stunden gelang es mir, das gewünschte Ergebnis zu erzielen. Die Daten in den Protokollen zeigten das Fehlen eines Headers!
Ich benutze rot-schwarzes Holz, um die Überschriften zu übermitteln. Solche Strukturen betrachten Vergleichbarkeit als Identität, was an sich sehr nützlich ist, wenn besondere Anforderungen an Schlüssel gestellt werden: In unserem Fall wurde bei den HTTP-Headern nicht zwischen Groß- und Kleinschreibung unterschieden. Zuerst dachten wir, dass das Problem im Blattknoten der verwendeten Bibliothek liegt. Die Reihenfolge der Addition wirkt sich wirklich auf die Reihenfolge der Konstruktion des Basisbaums aus, und das Ausbalancieren des rot-schwarzen Baums ist ein ziemlich komplizierter Prozess. Und obwohl diese Situation unwahrscheinlich war, war es nicht unmöglich. Ich wechselte zu einer anderen Implementierung aus rotem Ebenholz. Es wurde vor einigen Jahren behoben, daher habe ich beschlossen, es direkt in die Quelle einzubetten, um genau die Version zu erhalten, die benötigt wurde. Trotzdem hat die Baugruppe eine andere Version gewählt, und da ich mit einer neueren Version gerechnet habe, habe ich am Ende ein falsches Verhalten festgestellt.
Aus diesem Grund erzeugte das Visualisierungssystem 500 Fehler, die zur Unterbrechung des Zyklus führten. Aus diesem Grund trat der Fehler nur im Laufe der Zeit auf. Nach der zyklischen Verarbeitung mehrerer Assemblys wurde der Datenverkehr von diesen auf eine andere Route umgeleitet, was das Ausmaß des Problems auf diesem Server erhöhte. Meine Annahme, dass das Problem in der Bibliothek lag, stellte sich als falsch heraus, und der Rückwärtsschalter löste 500 Fehler.
Ich kehrte zu 400 Fehlern zurück: Es gab immer noch ein Problem mit dem Fehler, dessen Erkennung etwa zwei Stunden dauerte. Das Ändern der Bibliothek löste das Problem offensichtlich nicht, aber ich war mir sicher, dass die ausgewählte Bibliothek zuverlässig genug war. Da ich den Irrtum der Wahl nicht erkannte, änderte ich nichts. Nachdem ich die Situation genauer untersucht hatte, stellte ich fest, dass der richtige Wert in einem einstelligen Header gespeichert war (z. B. „h: 12345“). Endlich wurde mir klar, dass h das nachfolgende Zeichen des Content-Length-Headers ist. Beim erneuten Betrachten der Daten stellte ich fest, dass der Header für die Inhaltslänge leer war.
Infolgedessen war das Ganze beim Lesen der Header ein Bias-Fehler von eins. Der nginx / joyent HTTP-Analysator erstellt Teildaten, und jedes Mal, wenn sich herausstellte, dass das Teilheaderfeld ein Zeichen kürzer als erforderlich war, habe ich den Header ohne Wert gesendet und anschließend ein einstelliges Headerfeld mit dem richtigen Wert empfangen. Dies ist eine eher seltene Kombination, daher dauert der Betrieb so lange. Daher habe ich die Datenerfassung jedes Mal erhöht, wenn ein Header mit einem Zeichen angezeigt wurde, den vorgeschlagenen Fix angewendet und das Skript mehrere Stunden lang erfolgreich ausgeführt.
Natürlich konnten einige andere Fallstricke mit der erwähnten Fehlfunktion der Bibliothek erkannt werden, aber beide Fehler wurden behoben. “
Ingenieure, die an der Entwicklung verzögerungsempfindlicher Anwendungen beteiligt sind, müssen in der Lage sein, mithilfe des erfassten dynamischen Datenverkehrs zu debuggen, da häufig Fehler auftreten, die beim Testen von Einheiten nicht reproduziert oder mit einem Überwachungstool erkannt werden können (insbesondere, wenn die Protokollierung erheblich verzögert wird).
Chaos Engineering Ansatz
Chaos Engineering ist ein Ansatz, der auf Experimenten mit einem verteilten System basiert, um seine Fähigkeit zu bestätigen, den chaotischen Bedingungen der Produktionsumgebung standzuhalten.Die Chaos Engineering-Methode, die erstmals durch Netflix '
Chaos Monkey bekannt wurde , ist jetzt eine eigenständige Disziplin. Der Begriff Chaos Engineering tauchte kürzlich auf, aber Fehlertests sind eine langjährige Praxis.
Der Begriff "chaotisches Testen" bezieht sich auf die folgenden Techniken:
- Deaktivieren Sie beliebige Knoten, um festzustellen, wie widerstandsfähig das System gegen Ausfälle ist.
- Einführen von Fehlern (z. B. Erhöhen der Verzögerung), um zu bestätigen, dass das System sie korrekt verarbeitet;
- erzwungene Verletzung des Netzwerks, um die Antwort des Dienstes zu bestimmen.
Die meisten Unternehmen verwenden eine unzureichend komplexe und abgestufte Betriebsumgebung, um chaotische Tests effektiv durchzuführen. Es ist wichtig zu betonen, dass die Einführung von Fehlern im System am besten nach dem Einstellen der Grundfunktionen der Fehlertoleranz erfolgt.
Dieses Gremlin- Whitepaper enthält eine ziemlich umfassende Beschreibung der chaotischen Testprinzipien sowie Anweisungen zur Vorbereitung auf dieses Verfahren.
„Besonders wichtig ist die Tatsache, dass Chaos Engineering als wissenschaftliche Disziplin gilt. Innerhalb dieser Disziplin werden hochpräzise technische Verfahren angewendet.
Die Aufgabe von Chaos Engineering ist es, Benutzern durch Experimente etwas Neues über die Schwachstellen des Systems zu erzählen . Es ist notwendig, alle versteckten Probleme zu identifizieren, die in der Produktion auftreten können, noch bevor sie einen massiven Ausfall verursachen. Erst danach können Sie alle Schwachstellen im System effektiv beseitigen und es wirklich fehlertolerant machen. “Fazit
Der Zweck des Testens in der Produktion besteht nicht darin
, alle möglichen Fehler im System vollständig zu
beseitigen .
John Allspaw sagt:
„ Wir sehen, dass Systeme fehlertoleranter werden - und das ist großartig. Aber wir müssen zugeben: "mehr und mehr" ist nicht gleich "absolut". In jedem komplexen System kann (und wird) ein Fehler auf unvorhersehbare Weise auftreten. “
Das Testen in der Produktion scheint auf den ersten Blick eine ziemlich komplizierte Aufgabe zu sein, die weit über die Kompetenz der meisten Ingenieurbüros hinausgeht. Und obwohl solche Tests
keine leichte Aufgabe sind, die mit einigen Risiken verbunden ist, hilft es, wenn Sie alle Regeln befolgen, die Zuverlässigkeit komplexer verteilter Systeme zu erreichen, die heute überall zu finden sind.