In einem früheren Artikel haben wir uns die in RabbitMQ verwendeten Muster und Topologien angesehen. In diesem Teil wenden wir uns an Kafka und vergleichen es mit RabbitMQ, um einige Ideen zu ihren Unterschieden zu erhalten. Es sollte berücksichtigt werden, dass ereignisorientierte Anwendungsarchitekturen eher verglichen werden als Datenverarbeitungs-Pipelines, obwohl die Grenze zwischen diesen beiden Konzepten in diesem Fall eher verschwommen ist. Im Allgemeinen ist dies eher ein Spektrum als eine klare Trennung. Unser Vergleich konzentriert sich lediglich auf den Teil dieses Spektrums, der sich auf ereignisgesteuerte Anwendungen bezieht.

Der erste Unterschied besteht darin, dass die von RabbitMQ für die Arbeit mit Nachrichten mit toten Buchstaben in Kafka verwendeten Mechanismen zum Wiederholen und Schlummern von Nachrichten bedeutungslos sind. In RabbitMQ sind Nachrichten temporär, werden übertragen und verschwinden. Daher ist das erneute Hinzufügen ein absolut realer Anwendungsfall. Und in Kafka steht das Magazin im Mittelpunkt. Das Lösen von Zustellungsproblemen durch erneutes Senden einer Nachricht an die Warteschlange ist nicht sinnvoll und schadet nur dem Journal. Einer der Vorteile ist die garantierte klare Verteilung der Nachrichten auf die Partitionen des Journals. Wiederholte Nachrichten verwirren ein gut organisiertes Schema. In RabbitMQ können Sie bereits Nachrichten an die Warteschlange senden, mit der ein Empfänger arbeitet, und auf der Kafka-Plattform gibt es ein Journal für alle Empfänger. Verzögerungen bei der Zustellung und Probleme bei der Zustellung von Nachrichten schaden dem Betrieb des Journals nicht sehr, aber Kafka enthält keine integrierten Verzögerungsmechanismen.
Wie Sie Nachrichten auf der Kafka-Plattform erneut übermitteln, wird im Abschnitt über Messaging-Schemata erläutert.
Der zweite große Unterschied, der sich auf mögliche Messaging-Schemata auswirkt, besteht darin, dass RabbitMQ Nachrichten viel weniger speichert als Kafka. Wenn eine Nachricht bereits in RabbitMQ an den Empfänger übermittelt wurde, wird sie gelöscht, ohne eine Spur ihrer Existenz zu hinterlassen. In Kafka wird jede Nachricht in einem Protokoll gespeichert, bis sie gelöscht wird. Die Häufigkeit der Bereinigung hängt von der verfügbaren Datenmenge, dem Speicherplatz ab, den Sie ihnen zuweisen möchten, und den von Ihnen bereitgestellten Messaging-Schemata. Sie können das Zeitfenster verwenden, in dem Nachrichten für einen bestimmten Zeitraum gespeichert werden: die letzten Tage / Wochen / Monate.
Auf diese Weise ermöglicht Kafka dem Empfänger, frühere Nachrichten erneut anzuzeigen oder zu erfassen. Es sieht aus wie eine Technologie zum Senden von Nachrichten, obwohl es nicht ganz so funktioniert wie in RabbitMQ.
Wenn RabbitMQ Nachrichten verschiebt und leistungsstarke Elemente zum Erstellen komplexer Routing-Schemata bereitstellt, speichert Kafka den aktuellen und vorherigen Status des Systems. Diese Plattform kann als Quelle für zuverlässige historische Daten verwendet werden, da RabbitMQ dies nicht kann.
Beispiel für ein Messaging-Schema auf der Kafka-Plattform
Das einfachste Beispiel für die Verwendung von RabbitMQ und Kafka ist die Verbreitung von Informationen gemäß dem Schema „Herausgeber-Abonnent“. Ein oder mehrere Herausgeber fügen dem partitionierten Protokoll Nachrichten hinzu, und diese Nachrichten werden vom Abonnenten einer oder mehrerer Abonnentengruppen empfangen.

Abbildung 1. Mehrere Herausgeber senden Nachrichten an das partitionierte Protokoll, und mehrere Empfängergruppen empfangen sie.
Wenn Sie nicht näher darauf eingehen, wie der Herausgeber Nachrichten an die erforderlichen Abschnitte des Journals sendet und wie Empfängergruppen untereinander koordiniert werden, unterscheidet sich dieses Schema nicht von der in RabbitMQ verwendeten Fanout-Topologie (Forked Exchange).
In einem früheren Artikel wurden alle RabbitMQ-Messaging-Schemata und -Topologien erläutert. Vielleicht dachten Sie irgendwann: "Ich brauche nicht alle diese Schwierigkeiten, ich möchte nur Nachrichten in der Warteschlange senden und empfangen", und die Tatsache, dass Sie das Magazin auf frühere Positionen zurückspulen können, sprach über die offensichtlichen Vorteile von Kafka.
Für Menschen, die an die traditionellen Funktionen von Warteschlangensystemen gewöhnt sind, ist die Möglichkeit, die Uhr zurückzustellen und das Ereignisprotokoll in die Vergangenheit zurückzuspulen, erstaunlich. Diese Eigenschaft (verfügbar über das Protokoll anstelle der Warteschlange) ist sehr nützlich, um Fehler zu beheben. Ich (der Autor des englischen Artikels) habe vor 4 Jahren als technischer Manager der Server-System-Support-Gruppe angefangen, für meinen derzeitigen Kunden zu arbeiten. Wir hatten mehr als 50 Anwendungen, die über MSMQ Echtzeitinformationen zu Geschäftsereignissen erhielten, und das Übliche war, dass das System einen Fehler in der Anwendung erst am nächsten Tag erkannte. Leider verschwanden die Nachrichten häufig, aber normalerweise konnten wir die Anfangsdaten von einem Drittanbieter-System abrufen und Nachrichten nur an den „Abonnenten“ weiterleiten, der das Problem hatte. Dazu mussten wir eine Messaging-Infrastruktur für die Empfänger erstellen. Und wenn wir die Kafka-Plattform hätten, wäre es nicht schwieriger, einen solchen Job zu erledigen, als den Link zum Speicherort der zuletzt empfangenen Nachricht für die Anwendung zu ändern, in der der Fehler aufgetreten ist.
Datenintegration in ereignisorientierten Anwendungen und Systemen
Dieses Schema ist in vielerlei Hinsicht ein Mittel zum Generieren von Ereignissen, obwohl es sich nicht auf eine einzelne Anwendung bezieht. Es gibt zwei Ebenen der Ereignisgenerierung: Software und System. Das vorliegende Schema ist mit letzterem verbunden.
Generierung von Ereignissen auf Programmebene
Die Anwendung verwaltet ihren eigenen Status durch eine unveränderliche Folge von Änderungsereignissen, die im Ereignisspeicher gespeichert sind. Um den aktuellen Status der Anwendung zu erhalten, sollten Sie die Ereignisse in der richtigen Reihenfolge abspielen oder kombinieren. Normalerweise kann in einem solchen Modell das CQRS Kafka- Modell als dieses System verwendet werden.
Interaktion zwischen Anwendungen auf Systemebene.
Anwendungen oder Dienste können ihren Status auf eine Weise verwalten, die der Entwickler beispielsweise in einer regulären relationalen Datenbank verwalten möchte.
Anwendungen benötigen jedoch häufig Daten über einander. Dies führt zu suboptimalen Architekturen, z. B. allgemeinen Datenbanken, Verwischen von Entitätsgrenzen oder unbequemen REST-APIs.
Ich (der Autor des englischen Artikels) habe mir den Podcast „ Software Engineering Daily “ angehört, der ein ereignisorientiertes Szenario für die Serviceprofile in sozialen Netzwerken beschreibt. Es gibt eine Reihe verwandter Dienste im System, wie z. B. die Suche, ein System sozialer Diagramme, eine Empfehlungsmaschine usw., die alle über eine Änderung des Status eines Benutzerprofils informiert sein müssen. Als ich (der Autor des englischen Artikels) als Architekt der Architektur für ein System im Zusammenhang mit dem Luftverkehr arbeitete, hatten wir zwei große Softwaresysteme mit einer Vielzahl verwandter kleiner Dienste. Für den Support sind Bestell- und Flugdaten erforderlich. Jedes Mal, wenn eine Bestellung erstellt oder geändert wurde, wenn ein Flug verspätet oder storniert wurde, mussten diese Dienste aktiviert werden.
Es erforderte eine Technik zum Erzeugen von Ereignissen. Aber zuerst schauen wir uns einige häufige Probleme an, die in großen Softwaresystemen auftreten, und sehen, wie die Generierung von Ereignissen diese lösen kann.
Ein großes integriertes Unternehmenssystem entwickelt sich normalerweise organisch. Es werden Migrationen zu neuen Technologien und neuen Architekturen durchgeführt, die möglicherweise nicht 100% des Systems betreffen. Die Daten werden an verschiedene Teile der Institution verteilt, Anwendungen legen Datenbanken für die öffentliche Nutzung offen, damit die Integration so schnell wie möglich erfolgt und niemand mit Sicherheit vorhersagen kann, wie alle Elemente des Systems interagieren werden.
Zufällige Datenverteilung
Daten werden an verschiedenen Orten verteilt und an verschiedenen Orten verwaltet. Daher ist es schwer zu verstehen:
- wie sich Daten in Geschäftsprozessen bewegen;
- wie sich Änderungen in einem Teil des Systems auf andere Teile auswirken können;
- Was tun mit Datenkonflikten, die aufgrund der Tatsache entstehen, dass sich viele Kopien von Daten langsam verbreiten?
Wenn es keine klaren Grenzen für Domänenentitäten gibt, sind die Änderungen teuer und riskant, da sie viele Systeme gleichzeitig betreffen.
Zentralisierte verteilte Datenbank
Eine öffentlich geöffnete Datenbank kann verschiedene Probleme verursachen:
- Es ist nicht für jede Anwendung einzeln optimiert. Höchstwahrscheinlich enthält diese Datenbank einen übermäßig vollständigen Datensatz für die Anwendung. Außerdem ist sie so normalisiert, dass Anwendungen sehr komplexe Abfragen ausführen müssen, um sie zu empfangen.
- Mithilfe einer gemeinsamen Datenbank können sich Anwendungen gegenseitig auf die Arbeit auswirken.
- Änderungen in der logischen Struktur der Datenbank erfordern eine umfassende Koordination und Arbeit an der Datenmigration, und die Entwicklung einzelner Dienste wird für die Dauer dieses gesamten Prozesses gestoppt.
- Niemand möchte die Speicherstruktur ändern. Die Veränderungen, auf die alle warten, sind zu schmerzhaft.
Verwenden der unbequemen REST-API
Das Abrufen von Daten von anderen Systemen über die REST-API erhöht einerseits die Bequemlichkeit und Isolation, ist jedoch möglicherweise nicht immer erfolgreich. Jede solche Schnittstelle kann ihren eigenen speziellen Stil und ihre eigenen Konventionen haben. Das Abrufen der erforderlichen Daten kann viele HTTP-Anforderungen erfordern und recht kompliziert sein.
Wir bewegen uns immer mehr in Richtung API-Zentrizität, und solche Architekturen bieten viele Vorteile, insbesondere wenn die Dienste selbst außerhalb unserer Kontrolle liegen. Momentan gibt es so viele bequeme Möglichkeiten, eine API zu erstellen, dass wir nicht so viel Code schreiben müssen, wie zuvor benötigt wurde. Dies ist jedoch nicht das einzige verfügbare Tool, und es gibt Alternativen für die interne Architektur des Systems.
Kafka als Event-Repository
Wir geben ein Beispiel. Es gibt ein System, das Reservierungen in einer relationalen Datenbank verwaltet. Das System nutzt alle Garantien für Atomizität, Konsistenz, Isolation und Haltbarkeit, die die Datenbank bietet, um ihre Eigenschaften effektiv zu verwalten, und alle sind zufrieden. Die Aufteilung der Verantwortung in Teams und Anforderungen, die Erzeugung von Ereignissen, Microservices fehlt im Allgemeinen ein traditionell gebauter Monolith. Es gibt jedoch eine Vielzahl von Support-Services (möglicherweise Microservices) im Zusammenhang mit Reservierungen: Push-Benachrichtigungen, E-Mail-Verteilung, Betrugsbekämpfungssystem, Treueprogramm, Abrechnung, Stornierungssystem usw. Die Liste geht weiter und weiter. Für alle diese Dienste sind Reservierungsdaten erforderlich, und es gibt viele Möglichkeiten, sie zu erhalten. Diese Dienste selbst erzeugen Daten, die für andere Anwendungen nützlich sein können.

Abbildung 2. Verschiedene Arten der Datenintegration.
Alternative Architektur basierend auf Kafka. Jedes Mal, wenn Sie eine neue Reservierung vornehmen oder eine vorherige Reservierung ändern, sendet das System vollständige Daten über den aktuellen Status dieser Reservierung an Kafka. Durch die Konsolidierung des Journals können Sie die Nachrichten so kürzen, dass nur noch Informationen zum letzten Buchungsstatus darin verbleiben. In diesem Fall wird die Größe des Journals gesteuert.
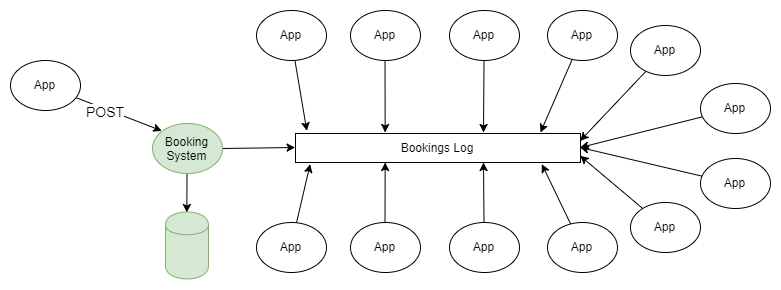
Abbildung 3. Kafka-basierte Datenintegration als Grundlage für die Ereignisgenerierung
Für alle Anwendungen, für die dies erforderlich ist, sind diese Informationen die Quelle der Wahrheit und die einzige Datenquelle. Plötzlich wechseln wir von einem integrierten Netzwerk von Abhängigkeiten und Technologien zum Senden und Empfangen von Daten zu / von Kafka-Themen.
Kafka als Event-Repository:
- Wenn es kein Problem mit dem Speicherplatz gibt, kann Kafka den gesamten Ereignisverlauf speichern, dh eine neue Anwendung kann bereitgestellt werden und alle erforderlichen Informationen aus dem Journal herunterladen. Aufzeichnungen von Ereignissen, die die Eigenschaften von Objekten vollständig widerspiegeln, können durch Kompilieren des Protokolls komprimiert werden, wodurch dieser Ansatz für viele Szenarien gerechtfertigter wird.
- Was ist, wenn Events in der richtigen Reihenfolge gespielt werden müssen? Solange die Aufzeichnungen von Ereignissen korrekt verteilt sind, können Sie die Reihenfolge ihrer Wiedergabe festlegen und Filter, Konvertierungswerkzeuge usw. anwenden, sodass die Datenwiedergabe immer mit den erforderlichen Informationen endet. Abhängig von der Möglichkeit der Datenverteilung ist es möglich, deren stark parallelisierte Verarbeitung in der richtigen Reihenfolge sicherzustellen.
- Möglicherweise ist eine Änderung des Datenmodells erforderlich. Beim Erstellen einer neuen Filter- / Transformationsfunktion muss möglicherweise eine Aufzeichnung aller Ereignisse oder Ereignisse der letzten Woche wiedergegeben werden.
Nachrichten können nicht nur von Anwendungen Ihres Unternehmens an Kafka gesendet werden, die Nachrichten über alle Änderungen ihrer Eigenschaften (oder die Ergebnisse dieser Änderungen) senden, sondern auch von Diensten von Drittanbietern, die in Ihr System integriert sind. Dies geschieht auf folgende Weise:
- Regelmäßiger Export, Transfer, Import von Daten, die von Drittanbieterdiensten empfangen wurden, und deren Download an Kafka.
- Herunterladen von Daten von Drittanbieterdiensten in Kafka.
- Daten aus CSV und anderen Formaten, die von Diensten Dritter hochgeladen wurden, werden auf Kafka hochgeladen.
Kehren wir zu den Fragen zurück, die wir zuvor betrachtet haben. Die Kafka-basierte Architektur vereinfacht die Datenverteilung. Wir wissen, wo die Quelle der Wahrheit liegt, wir wissen, wo sich ihre Datenquellen befinden, und alle Zielanwendungen arbeiten mit Kopien, die aus diesen Daten abgeleitet wurden. Die Daten gehen vom Absender zum Empfänger. Die Quelldaten gehören nur dem Absender, andere können jedoch mit ihren Projektionen arbeiten. Sie können sie filtern, transformieren, mit Daten aus anderen Quellen ergänzen und in ihren eigenen Datenbanken speichern.
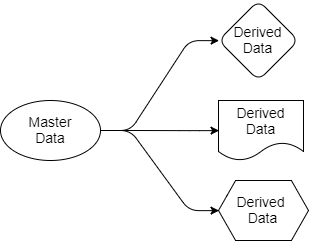
Abb. 4. Quell- und Ausgabedaten
Jede Anwendung, die Reservierungs- und Flugdaten benötigt, erhält diese für sich, da sie die Abschnitte von Kafka „abonniert“ hat, die diese Daten enthalten. Für diese Anwendung können sie SQL, Cypher, JSON oder eine andere Abfragesprache verwenden. Eine Anwendung kann dann nach eigenem Ermessen Daten in ihrem System speichern. Das Datenverteilungsschema kann geändert werden, ohne den Betrieb anderer Anwendungen zu beeinträchtigen.
Es kann sich die Frage stellen, warum dies alles nicht mit RabbitMQ möglich ist. Die Antwort ist, dass RabbitMQ verwendet werden kann, um Ereignisse in Echtzeit zu verarbeiten, jedoch nicht als Grundlage für die Generierung von Ereignissen. RabbitMQ ist eine Komplettlösung nur für die Reaktion auf Ereignisse, die gerade stattfinden. Wenn eine neue Anwendung hinzugefügt wird, die einen eigenen Teil der Reservierungsdaten in einem für die Aufgaben dieser Anwendung optimierten Format benötigt, kann RabbitMQ nicht helfen. Mit RabbitMQ kehren wir zu gemeinsam genutzten Datenbanken oder zur REST-API zurück.
Zweitens ist die Reihenfolge wichtig, in der Ereignisse verarbeitet werden. Wenn Sie mit RabbitMQ arbeiten und einen zweiten Empfänger zur Warteschlange hinzufügen, geht die Garantie für die Einhaltung der Bestellung verloren. Somit wird die richtige Reihenfolge beim Senden von Nachrichten nur für einen Empfänger eingehalten, aber dies reicht natürlich nicht aus.
Im Gegensatz dazu kann Kafka alle Daten bereitstellen, die diese Anwendung benötigt, um eine eigene Kopie der Daten zu erstellen und die Daten auf dem neuesten Stand zu halten, während Kafka die Reihenfolge einhält, in der Nachrichten gesendet werden.
Nun zurück zu den API-zentrierten Architekturen. Werden diese Schnittstellen immer die beste Wahl sein? Wenn Sie den schreibgeschützten Datenzugriff öffnen möchten, würde ich eine Architektur bevorzugen, die Ereignisse ausgibt. Dies verhindert Kaskadierungsfehler und verkürzt die Lebensdauer, die mit einer Zunahme der Anzahl von Abhängigkeiten von anderen Diensten verbunden ist. Es wird mehr Möglichkeiten für eine kreative und effiziente Organisation von Daten innerhalb von Systemen geben. Manchmal müssen Sie jedoch Daten sowohl in Ihrem System als auch in einem anderen System synchron ändern. In einer solchen Situation sind API-zentrierte Systeme hilfreich. Viele bevorzugen sie gegenüber anderen asynchronen Methoden. Ich denke, das ist Geschmackssache.
Sensible Anwendungen mit hohem Datenverkehr und Ereignisverarbeitung.
Vor nicht allzu langer Zeit trat ein Problem mit einem der Empfänger von RabbitMQ auf, der Dateien in der Warteschlange von einem Drittanbieter-Dienst erhielt. Die gesamte Dateigröße war groß, und die Anwendung wurde speziell für den Empfang eines solchen Datenvolumens konfiguriert. Das Problem war, dass die Daten inkonsistent eingingen, was viele Probleme verursachte.
Außerdem gab es manchmal ein Problem darin, dass manchmal zwei Dateien für dasselbe Ziel bestimmt waren und sich ihre Ankunftszeit um einige Sekunden unterschied. Beide haben die Verarbeitung durchlaufen und mussten auf einen Server hochgeladen werden. Und nachdem die zweite Nachricht auf dem Server aufgezeichnet wurde, überschreibt die erste Nachricht, die darauf folgt, die zweite. Somit endete alles mit dem Speichern ungültiger Daten. RabbitMQ hat seine Rolle erfüllt und Nachrichten in der richtigen Reihenfolge gesendet, aber trotzdem ist in der Anwendung selbst alles in der falschen Reihenfolge gelandet.
Dieses Problem wurde gelöst, indem der Zeitstempel aus vorhandenen Datensätzen gelesen wurde und keine Antwort erfolgte, wenn die Nachricht alt war. Darüber hinaus wurde während des Datenaustauschs konsistentes Hashing angewendet und die Warteschlange wie bei derselben Partitionierung auf der Kafka-Plattform aufgeteilt.
Als Teil der Partition speichert Kafka Nachrichten in der Reihenfolge, in der sie an sie gesendet wurden. Die Nachrichtenreihenfolge existiert nur innerhalb der Partition. Im obigen Beispiel mussten wir mit Kafka die Hash-Funktion auf die ID des Ziels anwenden, um die gewünschte Partition auszuwählen. Wir mussten eine Reihe von Partitionen erstellen, von denen mehr vorhanden sein sollten, als der Client benötigte. Die Reihenfolge der Nachrichtenverarbeitung sollte erreicht worden sein, da jede Partition nur für einen Empfänger bestimmt ist. Einfach und effektiv.
Kafka hat im Vergleich zu RabbitMQ einige Vorteile, die mit der Aufteilung von Nachrichten mithilfe von Hashing verbunden sind. Auf der RabbitMQ-Plattform gibt es nichts, was Empfängerkonflikte in derselben Warteschlange verhindern könnte, die im Rahmen des Datenaustauschs mithilfe von konsistentem Hashing generiert wird. RabbitMQ hilft nicht dabei, Empfänger zu koordinieren, sodass nur ein Empfänger aus der gesamten Warteschlange die Nachricht verwendet. Kafka bietet all dies durch die Verwendung von Empfängergruppen und eines Koordinatorknotens. Auf diese Weise können Sie sicherstellen, dass nur ein Empfänger in diesem Abschnitt die Nachricht garantiert verwendet und dass die Datenverarbeitungsreihenfolge garantiert ist.
Datenlokalität
Kafka verwendet eine Hash-Funktion zum Verteilen von Daten auf Partitionen und bietet Datenlokalität. Beispielsweise sollten Nachrichten vom Benutzer mit der ID 1001 immer an den Empfänger 3 gehen. Da die Ereignisse des Benutzers 1001 immer an den Empfänger 3 gehen, kann der Empfänger 3 einige Vorgänge effektiv ausführen, die viel schwieriger wären, wenn ein regelmäßiger Zugriff auf eine externe Datenbank oder andere Systeme erforderlich wäre Daten. Wir können Daten lesen, Aggregationen durchführen usw. direkt mit Informationen im Speicher des Empfängers. Hier beginnen sich ereignisorientierte Anwendungen und Daten-Streaming zu verbinden.
Wie stellt Kafka die Datenlokalität bereit? Zunächst ist zu beachten, dass Kafka es nicht erlaubt, die Anzahl der Partitionen elastisch zu erhöhen und zu verringern. Erstens können Sie die Anzahl der Partitionen überhaupt nicht reduzieren: Wenn 10 vorhanden sind, können Sie die Anzahl nicht auf 9 reduzieren. Dies ist jedoch nicht erforderlich. Jeder Empfänger kann entweder eine oder mehrere Partitionen verwenden, daher ist es kaum erforderlich, seine Anzahl zu reduzieren. Die Erstellung zusätzlicher Partitionen in Kafka führt zu einer Verzögerung zum Zeitpunkt des Neuausgleichs. Daher versuchen wir, die Anzahl der Partitionen unter Berücksichtigung der Spitzenlasten zu skalieren.
Wenn wir jedoch die Anzahl der Partitionen und Empfänger noch erhöhen müssen, um skalieren zu können, benötigen wir nur einmalige indirekte Kosten, wenn ein Neuausgleich erforderlich ist. Es ist zu beachten, dass beim Skalieren alte Daten auf denselben Partitionen verbleiben, auf denen sie sich befanden. Neue eingehende Nachrichten werden jedoch bereits anders weitergeleitet, und neue Partitionen erhalten neue Nachrichten. Nachrichten von Benutzer 1001 können jetzt an Empfänger 4 gesendet werden (da sich Daten über Benutzer 1001 jetzt in zwei Abschnitten befinden).
Weiterhin werden wir die Übermittlungssemantik von Übermittlungsnachrichten in beiden Systemen vergleichen und vergleichen. Das Thema Neuausrichtung und Partitionierung verdient einen separaten Artikel, den wir im nächsten Teil behandeln werden.