Hallo allerseits, mein Name ist Semyon Levenson, ich arbeite als Teamleiter am Stream- Projekt der Rambler Group und möchte über unsere Erfahrungen mit Apollo sprechen.
Ich werde erklären, was der "Stream" ist. Dies ist ein automatisierter Service für Unternehmer, mit dem Sie Kunden aus dem Internet für das Geschäft gewinnen können, ohne sich auf Werbung einzulassen, und schnell einfache Websites erstellen können, ohne ein Experte für Layout zu sein.
Der Screenshot zeigt einen der Schritte zum Erstellen einer Zielseite.
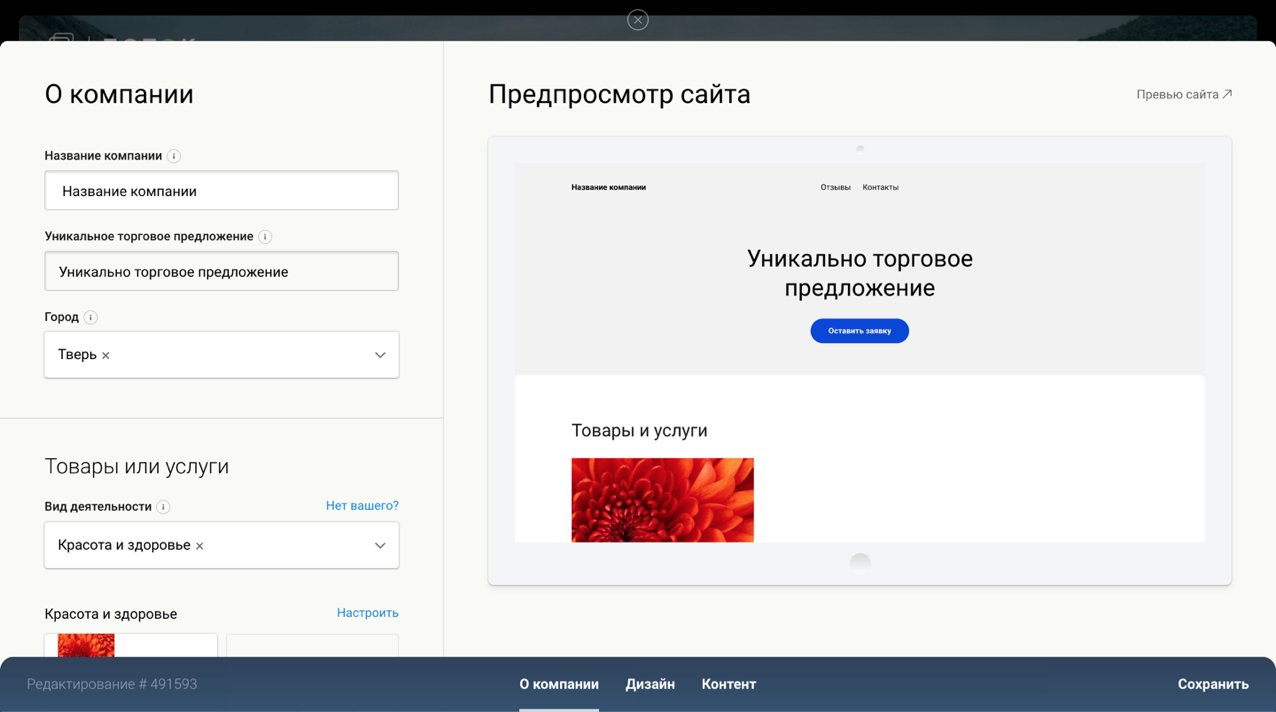
Was war der Anfang?
Und am Anfang gab es MVP, viele Twig, jQuery und sehr enge Fristen. Aber wir gingen einen nicht standardmäßigen Weg und beschlossen, ein Redesign vorzunehmen. Das Redesign ist nicht im Sinne von "gepatchten Stilen", sondern hat beschlossen, das System vollständig zu überprüfen. Und dies war eine gute Bühne für uns, um das perfekte Frontend zusammenzustellen. Schließlich unterstützen wir als Entwicklungsteam dies weiterhin und setzen auf dieser Grundlage weitere Aufgaben um, um neue vom Produktteam gesetzte Ziele zu erreichen.
Unsere Abteilung hat bereits genügend Fachwissen in der Verwendung von React gesammelt. Ich wollte keine 2 Wochen damit verbringen, das Webpack einzurichten, deshalb habe ich mich für CRA (Create React App) entschieden. Für Stile wurde Styled Components verwendet , und wo ohne Eingabe - sie nahmen Flow . Sie haben Redux für das State Management genommen, aber als Ergebnis stellte sich heraus, dass wir es überhaupt nicht brauchen, aber dazu später mehr.
Wir stellten unser perfektes Frontend zusammen und stellten fest, dass wir etwas vergessen hatten. Wie sich herausstellte, haben wir das Backend oder vielmehr die Interaktion damit vergessen. Als Sie darüber nachdachten, wie wir diese Interaktion organisieren können, fiel Ihnen als Erstes natürlich Ruhe ein. Nein, wir haben uns nicht ausgeruht (lächeln), sondern über die RESTful-API gesprochen. Im Prinzip ist die Geschichte bekannt, erstreckt sich über eine lange Zeit, aber wir kennen auch die Probleme damit. Wir werden darüber reden.
Das erste Problem ist die Dokumentation. RESTful sagt natürlich nicht aus, wie die Dokumentation zu organisieren ist. Hier besteht die Möglichkeit, dieselbe Prahlerei zu verwenden, aber tatsächlich ist es die Einführung einer zusätzlichen Entität und die Komplikation von Prozessen.
Das zweite Problem besteht darin, die Unterstützung für die Versionierung der API zu organisieren.
Das dritte wichtige Problem ist eine große Anzahl von Abfragen oder benutzerdefinierten Endpunkten, die wir belohnen können. Angenommen, wir müssen Beiträge für diese Beiträge anfordern - Kommentare und weitere Autoren dieser Kommentare. Im klassischen Rest müssen wir mindestens 3 Abfragen machen. Ja, wir können benutzerdefinierte Endpunkte belohnen, und all dies kann auf eine Anfrage reduziert werden, aber dies ist bereits eine Komplikation.
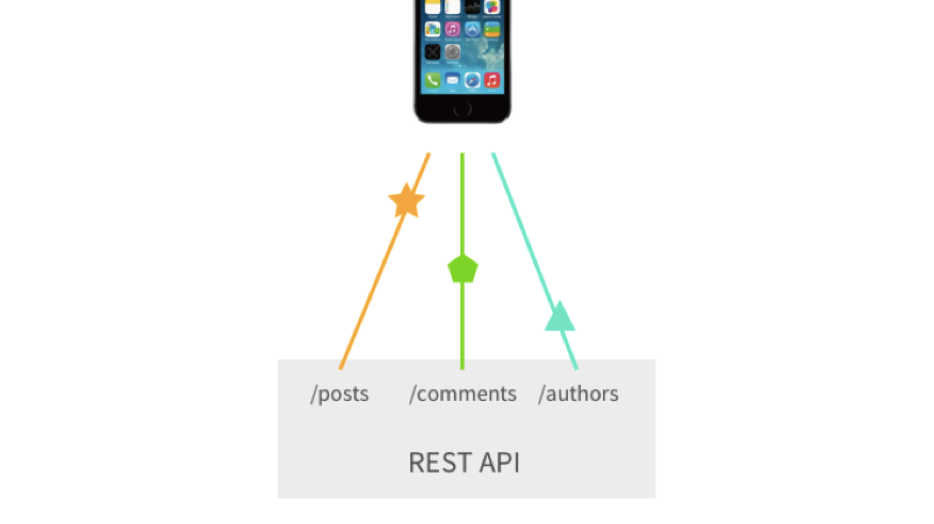
Vielen Dank an Sashko Stubailo für die Illustration .
Lösung
Und in diesem Moment hilft uns Facebook mit GraphQL. Was ist GraphQL? Dies ist eine Plattform, aber heute werden wir uns einen ihrer Teile ansehen - dies ist die Abfragesprache für Ihre API, nur eine Sprache und eine ziemlich primitive. Und es funktioniert so einfach wie möglich - da wir eine Art Entität anfordern, bekommen wir es auch.
Anfrage:
{ me { id isAcceptedFreeOffer balance } }
Die Antwort lautet:
{ "me": { "id": 1, "isAcceptedFreeOffer": false, "balance": 100000 } }
Bei GraphQL geht es aber nicht nur ums Lesen, sondern auch um das Ändern von Daten. Dazu gibt es Mutationen in GraphQL. Mutationen sind insofern bemerkenswert, als wir die gewünschte Antwort vom Backend mit einer erfolgreichen Änderung deklarieren können. Es gibt jedoch einige Nuancen. Zum Beispiel, wenn unsere Mutation Daten außerhalb der Grenzen des Diagramms beeinflusst.
Ein Beispiel für eine Mutation, bei der wir ein kostenloses Angebot verwenden:
mutation { acceptOffer (_type: FREE) { id isAcceptedFreeOffer } }
Als Antwort erhalten wir die gleiche Struktur, die angefordert wurde
{ "acceptOffer": { "id": 1, "isAcceptedFreeOffer": true } }
Die Interaktion mit dem GraphQL-Backend kann mithilfe des regulären Abrufs erfolgen.
fetch('/graphql', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ query: '{me { id balance } }' }) });
Was sind die Vorteile von GraphQL?
Das erste und sehr coole Plus, das Sie zu Beginn Ihrer Arbeit zu schätzen wissen, ist, dass diese Sprache stark typisiert und selbstdokumentierend ist. Durch das Entwerfen des GraphQL-Schemas auf dem Server können Typen und Attribute sofort direkt im Code beschrieben werden.

Wie oben erwähnt, hat RESTful ein Versionsproblem. GraphQL hat dafür eine sehr elegante Lösung implementiert - veraltet.
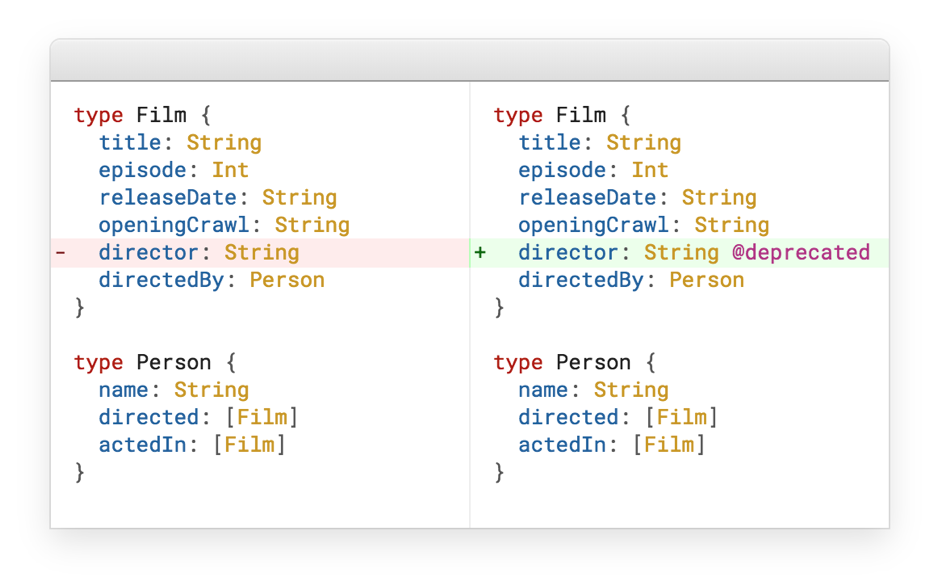
Angenommen, wir haben einen Film, wir erweitern ihn, also haben wir einen Regisseur. Und irgendwann machen wir den Regisseur einfach zu einem separaten Typ. Die Frage ist, was mit dem letzten Director-Feld zu tun ist. Es gibt zwei Antworten: Entweder löschen wir dieses Feld oder wir markieren es als veraltet und es verschwindet automatisch aus der Dokumentation.
Wir entscheiden unabhängig, was wir brauchen.
Wir erinnern uns an das vorherige Bild, in dem alles mit REST ging, aber hier ist alles in einer Anfrage zusammengefasst und erfordert keine Anpassung durch die Backend-Entwicklung. Sobald sie es alle beschrieben haben und wir uns drehen, drehen, jonglieren.
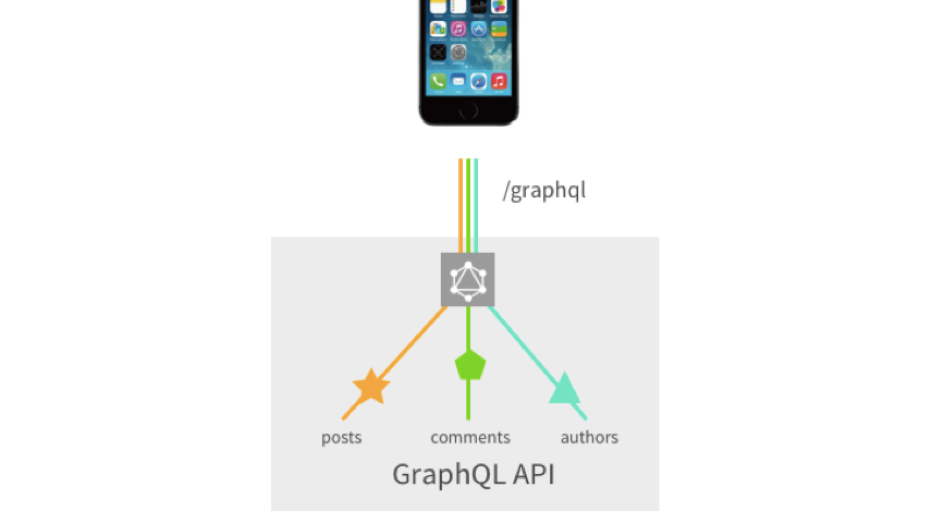
Aber nicht ohne eine Fliege in der Salbe. Grundsätzlich weist GraphQL im Frontend nicht so viele Nachteile auf, da es ursprünglich entwickelt wurde, um Frontend-Probleme zu lösen. Aber das Backend läuft nicht so reibungslos ... Sie haben ein Problem wie N + 1. Nehmen Sie die Abfrage als Beispiel:
{ landings(_page: 0, limit: 20) { nodes { id title } totalCount } }
Eine einfache Anfrage, wir fordern 20 Websites und die Anzahl der Websites, die wir haben. Im Backend können daraus 21 Datenbankabfragen werden. Dieses Problem ist bekannt, gelöst. Für Node JS gibt es ein Datenlader- Paket von Facebook. Für andere Sprachen können Sie Ihre eigenen Lösungen finden.
Es gibt auch das Problem der tiefen Verschachtelung. Zum Beispiel haben wir Alben, diese Alben haben Songs und durch den Song können wir auch Alben bekommen. Stellen Sie dazu folgende Abfragen:
{ album(id: 42) { songs { title artists } } }
{ song(id: 1337) { title album { title } } }
Somit erhalten wir eine rekursive Abfrage, die uns auch elementar eine Basis legt.
query evil { album(id: 42) { songs { album { songs { album {
Dieses Problem ist ebenfalls bekannt. Die Lösung für Node JS ist die GraphQL-Tiefenbegrenzung. Für andere Sprachen gibt es ebenfalls Lösungen.
Daher haben wir uns für GraphQL entschieden. Es ist Zeit, eine Bibliothek auszuwählen, die mit der GraphQL-API funktioniert. Das oben gezeigte Beispiel in einigen Zeilen mit Abruf ist nur ein Transport. Dank des Schemas und der Deklarativität können wir aber auch Abfragen an der Vorderseite zwischenspeichern und mit dem GraphQL-Backend mit höherer Leistung arbeiten.
Wir haben also zwei Hauptakteure - Relay und Apollo.
Relais
Relay ist eine Facebook-Entwicklung, die sie selbst nutzen. Wie Oculus, Circle CI, Arsti und Friday.
Was sind die Vorteile von Relay?
Das unmittelbare Plus ist, dass der Entwickler Facebook ist. React, Flow und GraphQL sind Facebook-Entwicklungen, bei denen es sich um Puzzles handelt, die auf einander zugeschnitten sind. Wo sind wir ohne Sterne auf Github, Relay hat fast 11.000, Apollo hat 7600 zum Vergleich. Das Coole, was Relay hat, ist Relay-Compiler, ein Tool, das Ihre GraphQL-Abfragen auf Build-Ebene Ihres Projekts optimiert und analysiert . Wir können davon ausgehen, dass dies nur für GraphQL hässlich ist:
# Relay-compiler foo { # type FooType id ... on FooType { # matches the parent type, so this is extraneous id } } # foo { id }
Was sind die Nachteile von Relay?
Das erste Minus * ist das Fehlen einer sofort einsatzbereiten SSR. Github hat noch ein offenes Problem . Warum unter dem Sternchen - weil es bereits Lösungen gibt, diese aber von Drittanbietern stammen und darüber hinaus ziemlich zweideutig sind.
Auch hier ist Relais eine Spezifikation. Tatsache ist, dass GraphQL bereits eine Spezifikation ist und Relay eine Spezifikation über einer Spezifikation ist.
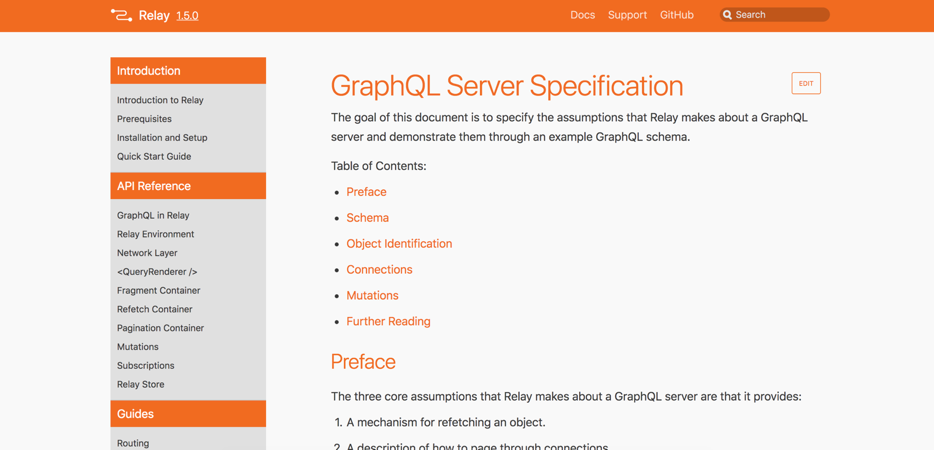
Beispielsweise wird die Relay-Paginierung anders implementiert. Hier werden Cursor angezeigt.
{ friends(first: 10, after: "opaqueCursor") { edges { cursor node { id name } } pageInfo { hasNextPage } } }
Wir verwenden nicht mehr die üblichen Offsets und Limits. Für Feeds im Feed ist dies ein großartiges Thema, aber wenn wir anfangen, alle Arten von Gittern zu erstellen, gibt es Schmerzen.
Facebook löste sein Problem, indem es eine Bibliothek für React schrieb. Es gibt Lösungen für andere Bibliotheken, zum Beispiel für vue.js - vue-Relay . Aber wenn wir auf die Anzahl der Sterne und Commits achten, dann ist auch hier nicht alles so glatt und kann instabil sein. Beispielsweise verhindert die Create React App aus dem CRA-Feld, dass Sie den Relay-Compiler verwenden können. Sie können diese Einschränkung jedoch mit React-App-Rewired umgehen .
Apollo
Unser zweiter Kandidat ist Apollo . Entwickelt von seinem Team Meteor . Apollo verwendet so bekannte Befehle wie: AirBnB, Ticketmaster, Opentable usw.
Was sind die Vorteile von Apollo?
Das erste bedeutende Plus ist, dass Apollo als Framework-Agnostic-Bibliothek entwickelt wurde. Wenn wir jetzt beispielsweise alles auf Angular neu schreiben möchten, ist dies kein Problem. Apollo arbeitet damit. Und Sie können sogar alles in Vanille schreiben.
Apollo hat eine coole Dokumentation, es gibt fertige Lösungen für häufig auftretende Probleme.

Ein weiteres Plus Apollo - eine leistungsstarke API. Im Prinzip finden diejenigen, die mit Redux gearbeitet haben, hier gemeinsame Ansätze: Es gibt ApolloProvider (wie Provux für Redux), und anstelle von Apollo wird dies als Client bezeichnet:
import { ApolloProvider } from 'react-apollo'; import { ApolloClient } from './ApolloClient'; const App = () => ( <ApolloProvider client={ApolloClient}> ... </ApolloProvider> );
Auf der Ebene der Komponente selbst haben wir graphql HOC als Verbindung bereitgestellt. Und wir schreiben die GraphQL-Abfrage bereits in MapStateToProps in Redux.
import { graphql } from 'react-apollo'; import gql from 'graphql-tag'; import { Landing } from './Landing'; graphql(gql` { landing(id: 1) { id title } } `)(Landing);
Wenn wir jedoch MapStateToProps in Redux ausführen, erfassen wir die lokalen Daten. Wenn keine lokalen Daten vorhanden sind, geht Apollo selbst zum Server. Sehr praktische Requisiten fallen in die Komponente selbst.
function Landing({ data, loading, error, refetch, ...other }) { ... }
Das:
• Daten;
• Download-Status;
• ein Fehler, wenn er aufgetreten ist;
Hilfsfunktionen wie Refetch zum erneuten Laden von Daten oder FetchMore zum Paginieren. Es gibt auch ein großes Plus für Apollo und Relay, nämlich die optimistische Benutzeroberfläche. Sie können das Rückgängigmachen / Wiederherstellen auf Anforderungsebene festlegen:
this.props.setNotificationStatusMutation({ variables: { … }, optimisticResponse: { … } });
Zum Beispiel klickte der Benutzer auf die Schaltfläche "Gefällt mir" und das "Gefällt mir" zählte sofort. In diesem Fall wird im Hintergrund eine Anfrage an den Server gesendet. Wenn während des Sendevorgangs ein Fehler auftritt, kehren die veränderlichen Daten von selbst in ihren ursprünglichen Zustand zurück.
Das serverseitige Rendern ist gut implementiert, wir setzen ein Flag auf dem Client und alles ist bereit.
new ApolloClient({ ssrMode: true, ... });
Aber hier möchte ich über den Anfangszustand sprechen. Wenn Apollo es selbst kocht, funktioniert alles gut.
<script> window.__APOLLO_STATE__ = client.extract(); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link });
Wir haben jedoch kein serverseitiges Rendering und das Backend verschiebt eine bestimmte GraphQL-Abfrage in die globale Variable. Hier benötigen Sie eine kleine Krücke, Sie müssen eine Transformationsfunktion schreiben, damit die GraphQL-Antwort vom Backend bereits das für Apollo benötigte Format annimmt.
<script> window.__APOLLO_STATE__ = transform({…}); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link });
Ein weiteres Plus von Apollo ist, dass es gut anpassbar ist. Wir alle erinnern uns an Middleware von Redux, hier ist alles gleich, nur das nennt man Link.

Ich möchte zwei Links separat erwähnen: den Apollo-Link-Status , der zum Speichern des lokalen Status in Abwesenheit von Redux benötigt wird, und den Apollo-Link-Rest , wenn wir GraphQL-Abfragen in die Rest-API schreiben möchten. Bei letzteren müssen Sie jedoch äußerst vorsichtig sein, weil Es können bestimmte Probleme auftreten.
Apollo hat auch Nachteile
Schauen wir uns ein Beispiel an. Es gab ein unerwartetes Leistungsproblem: 2.000 Elemente wurden im Frontend angefordert (es war ein Verzeichnis), und Leistungsprobleme wurden gestartet. Nachdem es im Debugger angezeigt wurde, stellte sich heraus, dass Apollo beim Lesen viele Ressourcen verschlingt. Das Problem ist im Grunde genommen geschlossen. Jetzt ist alles in Ordnung, aber es gab eine solche Sünde.
Auch das erneute Abrufen erwies sich als sehr offensichtlich ...
function Landing({ loading, refetch, ...other }) { ... }
Es scheint, dass bei einer erneuten Datenanforderung das Laden wahr werden sollte, wenn die vorherige Anforderung mit einem Fehler endete. Aber nein!
Dazu müssen Sie notifyOnNetworkStatusChange: true im graphql-HOC angeben oder den Neuabrufstatus lokal speichern.
Apollo vs. Relais
So haben wir einen solchen Tisch bekommen, wir haben alle gewogen, gezählt und wir hatten 76% hinter Apollo.
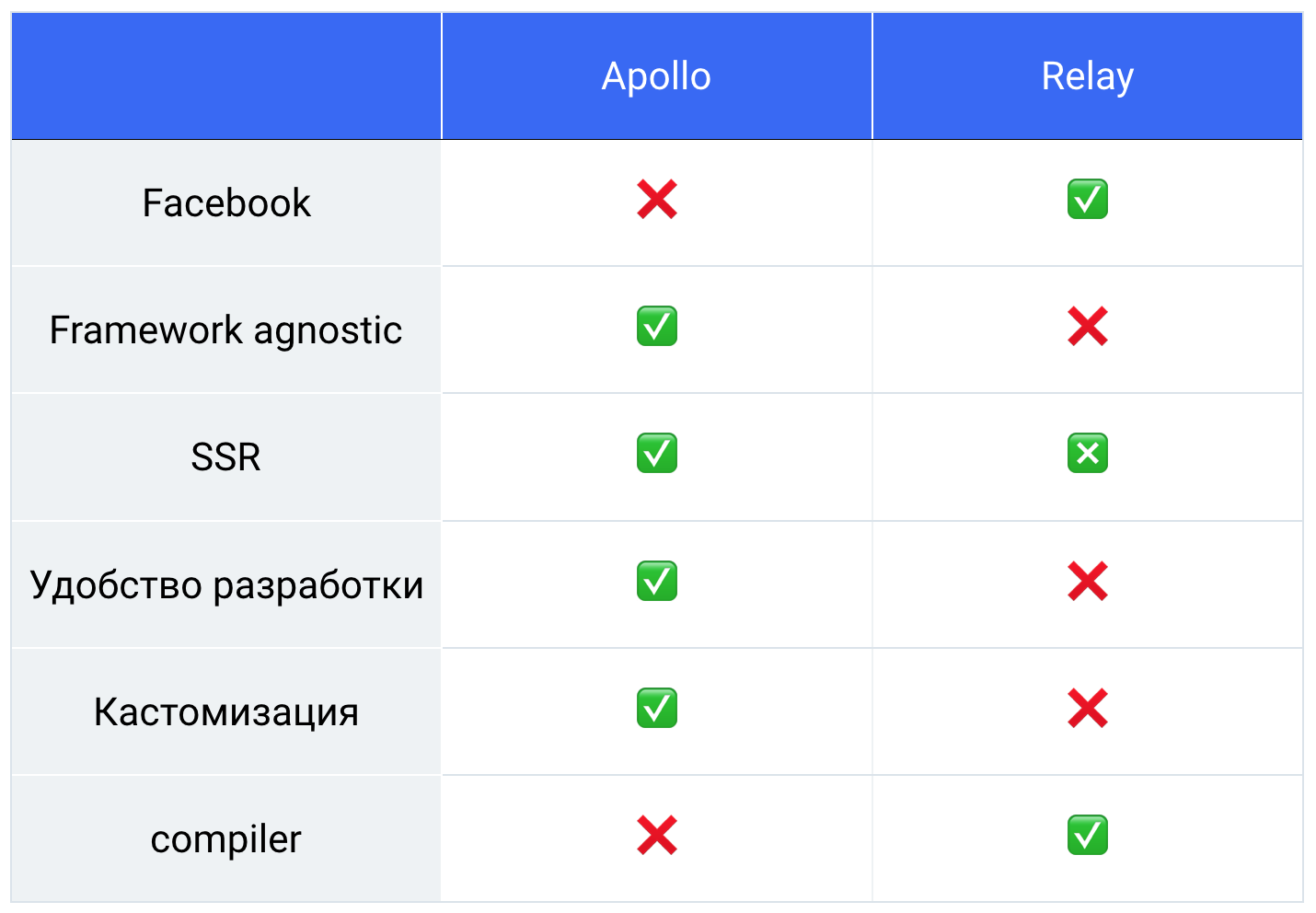
Also haben wir uns für die Bibliothek entschieden und sind zur Arbeit gegangen.
Aber ich möchte mehr über die Toolchain sagen.
Hier ist alles sehr gut, es gibt verschiedene Add-Ons für Redakteure, irgendwo besser, irgendwo schlechter. Es gibt auch Apollo-Codegen, das nützliche Dateien, z. B. Flusstypen, generiert und das Schema grundsätzlich aus der GraphQL-API abruft.
Die Überschrift "Crazy Hands" oder was wir zu Hause gemacht haben
Das erste, was uns begegnete, war, dass wir grundsätzlich Daten anfordern müssen.
graphql(BalanceQuery)(BalanceItem)
Wir haben gemeinsame Bedingungen: Laden, Fehlerbehandlung. Wir haben unseren eigenen Falken (asyncCard) geschrieben, der über die Zusammensetzung von graqhql und asyncCard verbunden ist.
compose( graphql(BalanceQuery), AsyncCard )(BalanceItem)
Ich möchte auch über Fragmente sprechen. Es gibt eine LandingItem-Komponente, die weiß, welche Daten sie von der GraphQL-API benötigt. Wir haben die Fragment-Eigenschaft festgelegt, in der wir die Felder der Landing-Entität angegeben haben.
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... } `;
Auf der Ebene der Komponentennutzung verwenden wir nun das Fragment in der endgültigen Anforderung.
query LandingsDashboard { landings(...) { nodes { ...LandingItem } totalCount } ${LandingItem.Fragment} }
Nehmen wir an, eine Aufgabe fliegt ein, um dieser Zielseite den Status hinzuzufügen - kein Problem. Wir fügen dem Rendering und dem Fragment eine Eigenschaft hinzu. Und alles ist fertig. Prinzip der Einzelverantwortung in seiner ganzen Pracht.
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … <LandingItemStatus … /> </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... status } `;
Welches andere Problem hatten wir?
Wir haben eine Reihe von Widgets auf unserer Website, die ihre individuellen Anfragen gestellt haben.
Während des Tests stellte sich heraus, dass dies alles langsamer wird. Wir haben sehr lange Sicherheitskontrollen und jede Anfrage ist sehr teuer. Dies stellte sich auch als kein Problem heraus, es gibt Apollo-Link-Batch-http
new BatchHttpLink({ batchMax: 10, batchInterval: 10 });
Es ist wie folgt konfiguriert: Wir übergeben die Anzahl der Anforderungen, die wir kombinieren können, und wie lange dieser Link wartet, nachdem die erste Anforderung angezeigt wurde.
Und es stellte sich so heraus: Gleichzeitig wird alles geladen und gleichzeitig kommt alles. Es ist anzumerken, dass, wenn während dieser Zusammenführung eine der Unterabfragen mit einem Fehler zurückgegeben wird, der Fehler nur bei ihm und nicht bei der gesamten Anforderung auftritt.
Ich möchte separat sagen, dass es im letzten Herbst ein Update vom ersten Apollo zum zweiten gab
Am Anfang waren Apollo und Redux
'react-apollo' 'redux'
Dann wurde Apollo modularer und erweiterbarer, diese Module können unabhängig voneinander entwickelt werden. Das gleiche Apollo-Cache-Gedächtnis.
'react-apollo' 'apollo-client' 'apollo-link-batch-http' 'apollo-cache-inmemory' 'graphql-tag'
Es ist erwähnenswert, dass Redux nicht benötigt wird und wie sich herausstellte, im Prinzip nicht benötigt wird.
Schlussfolgerungen:
- Die Bereitstellungszeit für Funktionen hat sich verringert. Wir verschwenden keine Zeit damit, Aktionen zu beschreiben, Redux zu reduzieren und das Backend weniger zu berühren
- Antifragilität erschien, weil Durch die statische Analyse der API können Sie die Probleme aufheben, wenn das Frontend eine Sache erwartet und das Backend eine völlig andere zurückgibt.
- Wenn Sie mit GraphQL arbeiten - versuchen Sie es mit Apollo. Seien Sie nicht enttäuscht.
PS Sie können sich auch ein Video von meiner Präsentation auf Rambler Front & Meet up # 4 ansehen