Python ist großartig. Wir sagen "pip install" und höchstwahrscheinlich wird die erforderliche Bibliothek geliefert. Aber manchmal lautet die Antwort: "Kompilierung fehlgeschlagen", weil es Binärmodule gibt. Sie leiden in fast allen modernen Sprachen unter Schmerzen, weil es viele Architekturen gibt, etwas für eine bestimmte Maschine zusammengestellt werden muss, etwas mit anderen Bibliotheken verknüpft werden muss. Im Allgemeinen eine interessante, aber wenig untersuchte Frage: Wie können sie gemacht werden und welche Probleme gibt es? Dmitry Zhiltsov (
zaabjuda ) hat letztes Jahr bei MoscowPython Conf versucht, diese Frage zu beantworten.
Unter dem Schnitt befindet sich die Textversion von Dmitrys Bericht. Lassen Sie uns kurz darauf eingehen, wann Binärmodule benötigt werden und wann es besser ist, sie aufzugeben. Lassen Sie uns die Regeln diskutieren, die beim Schreiben befolgt werden sollten. Betrachten Sie fünf mögliche Implementierungsoptionen:
- Native C / C ++ - Erweiterung
- Swig
- Cython
- C-Typen
- Rost
Über den Sprecher : Dmitry Zhiltsov entwickelt sich seit mehr als 10 Jahren. Er arbeitet bei CIAN als Systemarchitekt, dh er ist verantwortlich für technische Lösungen und Zeitsteuerung. In meinem Leben habe ich es geschafft, Assembler, Haskell, C, auszuprobieren, und seit 5 Jahren programmiere ich aktiv in Python.
Über die Firma
Viele, die in Moskau leben und Wohnungen mieten, kennen CIAN wahrscheinlich. CYAN ist 7 Millionen Käufer und Mieter pro Monat. Alle diese Benutzer finden jeden Monat über unseren Service eine Unterkunft.
Ungefähr 75% der Moskauer kennen unser Unternehmen, und das ist sehr cool. In St. Petersburg und Moskau gelten wir praktisch als Monopolisten. Im Moment versuchen wir, in die Regionen einzudringen, und daher ist die Entwicklung in den letzten 3 Jahren achtmal gewachsen. Dies bedeutet, dass das Team um das Achtfache erhöht wurde, die Geschwindigkeit der Übermittlung von Werten an den Benutzer um das Achtfache erhöht wurde, d. H. von einer Produktidee bis hin zur Einführung eines Builds durch einen Ingenieur in der Produktion. Wir haben in unserem großen Team gelernt, uns sehr schnell zu entwickeln und sehr schnell zu verstehen, was gerade passiert, aber heute werden wir ein wenig über etwas anderes sprechen.
Ich werde über Binärmodule sprechen. Mittlerweile verfügen fast 50% der Python-Bibliotheken über Binärmodule. Und wie sich herausstellte, sind viele Menschen mit ihnen nicht vertraut und glauben, dass dies etwas Transzendentales, etwas Dunkles und Unnötiges ist. Und andere Leute schlagen vor, einen separaten Microservice besser zu schreiben und keine Binärmodule zu verwenden.
Der Artikel besteht aus zwei Teilen.
- Meine Erfahrung: Warum sie gebraucht werden, wann sie am besten verwendet werden und wann nicht.
- Tools und Technologien, mit denen Sie ein Binärmodul für Python implementieren können.
Warum werden Binärmodule benötigt?
Wir alle wissen genau, dass Python eine interpretierte Sprache ist. Es ist fast die schnellste der interpretierten Sprachen, aber leider reicht seine
Geschwindigkeit nicht immer für schwere mathematische Berechnungen aus. Sofort entsteht der Gedanke, dass C schneller sein wird.
Aber Python hat noch einen Schmerz - es ist
GIL . Es wurde eine große Anzahl von Artikeln über ihn geschrieben und es wurde berichtet, wie man um ihn herumkommt.
Wir benötigen auch binäre Erweiterungen,
um die Logik wiederzuverwenden . Zum Beispiel haben wir eine Bibliothek gefunden, die alle Funktionen bietet, die wir benötigen, und warum nicht. Das heißt, Sie müssen den Code nicht neu schreiben. Wir nehmen einfach den fertigen Code und verwenden ihn erneut.
Viele Leute glauben, dass man mit binären Erweiterungen
den Quellcode verbergen kann . Die Frage ist natürlich sehr, sehr kontrovers, mit Hilfe einiger wilder Perversionen kann dies erreicht werden, aber es gibt keine 100% ige Garantie. Das Maximum, das Sie erhalten können, besteht darin, den Client nicht dekompilieren zu lassen und zu sehen, was in dem von Ihnen übergebenen Code passiert.
Wann werden binäre Erweiterungen wirklich benötigt?
Über Geschwindigkeit und Python ist klar: Wenn eine Funktion sehr langsam arbeitet und 80% der Ausführungszeit des gesamten Codes einnimmt, beginnen wir über das Schreiben einer binären Erweiterung nachzudenken. Aber um solche Entscheidungen zu treffen, müssen Sie, wie ein berühmter Redner sagte, mit Ihrem Gehirn denken.
Um Erweiterungen zu schreiben, muss man berücksichtigen, dass dies erstens lang sein wird. Zuerst müssen Sie Ihre Algorithmen "lecken", d. H. Überprüfen Sie, ob Pfosten vorhanden sind.
In 90% der Fälle entfällt nach einer gründlichen Überprüfung des Algorithmus die Notwendigkeit, einige Erweiterungen zu schreiben.
Der zweite Fall, in dem binäre Erweiterungen wirklich benötigt werden, ist die
Verwendung von Multithreading für einfache Operationen . Nun, das ist nicht so relevant, aber es bleibt in einigen Systemintegratoren, in denen Python 2.6 noch geschrieben ist, immer noch im blutigen Unternehmen. Es gibt keine Asynchronität, und selbst bei einfachen Dingen, z. B. beim Hochladen einer Reihe von Bildern, steigt das Multithreading. Es scheint, dass dies anfangs keine Netzwerkkosten verursacht, aber wenn wir das Bild in den Puffer hochladen, kommt die unglückliche GIL und eine Art Bremse beginnt. Wie die Praxis zeigt, lassen sich solche Dinge am besten mit Bibliotheken lösen, von denen Python nichts weiß.
Wenn Sie ein bestimmtes Protokoll implementieren müssen, kann es praktisch sein, einfachen C / C ++ - Code zu erstellen und viel Schmerz loszuwerden. Ich habe dies in meiner Zeit bei einem Telekommunikationsbetreiber getan, da es keine fertige Bibliothek gab - ich musste sie selbst schreiben. Aber ich wiederhole, jetzt ist das nicht sehr relevant, weil es Asyncio gibt, und für die meisten Aufgaben ist dies genug.
Über offensichtlich
schwierige Operationen habe ich bereits im Voraus gesagt. Wenn Sie Abstürze, große Matrizen und dergleichen haben, ist es sinnvoll, eine Erweiterung für C / C ++ vorzunehmen. Ich möchte darauf hinweisen, dass einige Leute denken, dass wir hier keine binären Erweiterungen benötigen. Es ist besser, einen Microservice in einer „
superschnellen Sprache “ zu
erstellen und riesige Matrizen über das Netzwerk zu übertragen. Nein, das ist besser nicht.
Ein weiteres gutes Beispiel, wann sie überhaupt genommen werden können und sollten, ist, wenn Sie eine
etablierte Logik des Moduls haben . Wenn Sie eine Art Python-Modul in Ihrem Unternehmen haben oder eine Bibliothek bereits seit 3 Jahren vorhanden ist, werden diese einmal im Jahr und dann in zwei Zeilen geändert. Warum nicht eine normale C-Bibliothek erstellen, wenn freie Ressourcen und Zeit zur Verfügung stehen? Steigern Sie zumindest die Produktivität. Und es wird auch ein Verständnis dafür bestehen, dass wenn einige grundlegende Änderungen in der Bibliothek erforderlich sind, dies nicht so einfach ist und es sich möglicherweise lohnt, erneut mit dem Gehirn nachzudenken und diese Bibliothek auf eine andere Weise zu verwenden.
5 goldene Regeln
Ich habe diese Regeln in meiner Praxis abgeleitet. Sie betreffen nicht nur Python, sondern auch andere Sprachen, für die Sie binäre Erweiterungen verwenden können. Sie können mit ihnen streiten, aber Sie können auch denken und Ihre eigenen mitbringen.
- Nur Exportfunktionen . Das Erstellen von Klassen in Python in Binärbibliotheken ist sehr zeitaufwändig: Sie müssen viele Schnittstellen beschreiben und die Referenzintegrität im Modul selbst überprüfen. Es ist einfacher, eine kleine Schnittstelle für die Funktion zu schreiben.
- Verwenden Sie Wrapper-Klassen . Einige lieben OOP sehr und wollen wirklich Unterricht. Selbst wenn es sich nicht um Klassen handelt, ist es in jedem Fall besser, nur einen Python-Wrapper zu schreiben: Erstellen Sie eine Klasse, definieren Sie eine Klassenmethode oder eine reguläre Methode, rufen Sie native C / C ++ - Funktionen auf. Dies trägt zumindest dazu bei, die Integrität der Datenarchitektur aufrechtzuerhalten. Wenn Sie eine C / C ++ - Erweiterung eines Drittanbieters verwenden, die Sie nicht reparieren können, können Sie sie im Wrapper hacken, damit alles funktioniert.
- Sie können keine Argumente von Python an eine Erweiterung übergeben - dies ist nicht einmal eine Regel, sondern eine Anforderung. In einigen Fällen kann dies funktionieren, aber es ist normalerweise eine schlechte Idee. Daher müssen Sie in Ihrem Code zuerst einen Handler erstellen, der den Python-Typ in Typ C umwandelt. Rufen Sie erst danach eine native Funktion auf, die bereits mit Typ s funktioniert. Derselbe Handler empfängt eine Antwort von einer ausführbaren Funktion, wandelt sie in Python-Datentypen um und wirft sie in Python-Code.
- Berücksichtigen Sie die Speicherbereinigung . Python hat einen bekannten GC, den Sie nicht vergessen sollten. Zum Beispiel übergeben wir einen großen Text als Referenz und versuchen, ein Wort in der Bibliothek zu finden. Wir wollen dies parallelisieren, wir übergeben die Verknüpfung zu diesem Speicherbereich und zum Start mehrerer Threads. Zu diesem Zeitpunkt nimmt der GC einfach und entscheidet, dass sich nichts anderes auf dieses Objekt bezieht, und entfernt es aus dem Speicherbereich. Im selben Code erhalten wir nur eine Nullreferenz, und dies ist normalerweise ein Segmentierungsfehler. Wir dürfen eine solche Funktion des Garbage Collector nicht vergessen und die einfachsten Datentypen an char-Bibliotheken übergeben: char, integer usw.
Andererseits kann die Sprache, in der die Erweiterung geschrieben ist, einen eigenen Garbage Collector haben. Die Kombination von Python und der C # -Bibliothek ist in diesem Sinne ein Schmerz.
- Definieren Sie explizit die Argumente der exportierten Funktion . Damit möchte ich sagen, dass diese Funktionen qualitativ kommentiert werden müssen. Wenn wir die PyObject-Funktion akzeptieren und sie auf jeden Fall in unserer Bibliothek akzeptieren, müssen wir explizit angeben, welche Argumente zu welchen Typen gehören. Dies ist nützlich, da bei einer Übergabe des falschen Datentyps ein Fehler in der Bibliothek angezeigt wird. Das heißt, Sie brauchen es für Ihre Bequemlichkeit.
Binäre Erweiterungsarchitektur

Tatsächlich ist die Architektur von binären Erweiterungen nicht kompliziert. Es gibt Python, es gibt eine aufrufende Funktion, die auf einem Wrapper landet, der den Code nativ aufruft. Dieser Aufruf landet wiederum auf einer Funktion, die nach Python exportiert wird und die direkt aufgerufen werden kann. In dieser Funktion müssen Sie Datentypen in Datentypen Ihrer Sprache umwandeln. Und erst nachdem diese Funktion alles für uns übersetzt hat, rufen wir die native Funktion auf, die die Hauptlogik ausführt, das Ergebnis in die entgegengesetzte Richtung zurückgibt und es in Python wirft und die Datentypen zurück übersetzt.
Technologie und Werkzeuge
Die bekannteste Methode zum Schreiben von binären Erweiterungen ist die native C / C ++ - Erweiterung. Nur weil es sich um Standard-Python-Technologie handelt.
Native C / C ++ - Erweiterung
Python selbst ist in C implementiert und die Methoden und Strukturen von python.h werden zum Schreiben von Erweiterungen verwendet. Übrigens ist dieses Ding auch gut, weil es sehr einfach ist, es in ein bestehendes Projekt zu implementieren. Es reicht aus, xt_modules in setup.py anzugeben und zu sagen, dass Sie zum Erstellen des Projekts solche Quellen mit solchen Kompilierungsflags kompilieren müssen. Unten ist ein Beispiel.
name = 'DateTime.mxDateTime.mxDateTime' src = 'mxDateTime/mxDateTime.c' extra_compile_args=['-g3', '-o0', '-DDEBUG=2', '-UNDEBUG', '-std=c++11', '-Wall', '-Wextra'] setup ( ... ext_modules = [(name, { 'sources': [src], 'include_dirs': ['mxDateTime'] , extra_compile_args: extra_compile_args } )] )
Vorteile der nativen C / C ++ - Erweiterung
- Native Technologie.
- Es lässt sich leicht in die Projektbaugruppe integrieren.
- Die größte Menge an Dokumentation.
- Ermöglicht das Erstellen eigener Datentypen.
Nachteile der nativen C / C ++ - Erweiterung
- Hohe Eintrittsschwelle.
- Kenntnisse in C. sind erforderlich.
- Boost.Python.
- Segmentierungsfehler.
- Schwierigkeiten beim Debuggen.
Gemäß dieser Technologie wird eine große Menge an Dokumentation geschrieben, sowohl Standard- als auch Blog-Beiträge. Ein großes Plus ist, dass wir unsere eigenen Python-Datentypen erstellen und unsere Klassen erstellen können.
Dieser Ansatz hat große Nachteile. Erstens ist es die Eintrittsschwelle - nicht jeder kennt C genug, um für die Produktion zu codieren. Sie müssen verstehen, dass es dafür nicht ausreicht, das Buch zu lesen und auszuführen, um native Erweiterungen zu schreiben. Wenn Sie dies tun möchten, dann: lernen Sie zuerst C; Beginnen Sie dann mit dem Schreiben von Befehlsdienstprogrammen. Erst danach schreiben Sie Erweiterungen.
Boost.Python ist sehr gut für C ++, es ermöglicht Ihnen, fast vollständig von all diesen Wrappern zu abstrahieren, die wir in Python verwenden. Aber das Minus, denke ich, ist, dass Sie viel schwitzen müssen, um einen Teil davon zu nehmen und es in das Projekt zu importieren, ohne den gesamten Boost herunterzuladen.
Wenn ich die Schwierigkeiten beim Debuggen in den Minuspunkten aufführe, meine ich, dass jetzt jeder daran gewöhnt ist, einen grafischen Debugger zu verwenden, und mit Binärmodulen wird so etwas nicht funktionieren. Höchstwahrscheinlich müssen Sie GDB mit einem Plugin für Python installieren.
Schauen wir uns ein Beispiel an, wie wir dies erstellen.
#include <Python.h> static PyObject*addList_add(Pyobject* self, Pyobject* args){ PyObject * listObj; if (! PyARg_Parsetuple( args, "", &listObj)) return NULL; long length = PyList_Size(listObj) int i, sum =0; // return Py_BuildValue("i", sum); }
Zu Beginn enthalten wir die Python-Header-Dateien. Danach beschreiben wir die Funktion addList_add, die Python verwenden wird. Das Wichtigste ist, die Funktion korrekt zu benennen. In diesem Fall ist addList der Name des Moduls, _add ist der Name der Funktion, die in Python verwendet wird. Wir übergeben das PyObject-Modul selbst und übergeben die Argumente auch mit PyObject. Danach führen wir Standardprüfungen durch. In diesem Fall versuchen wir, das Tupelargument zu analysieren und zu sagen, dass es sich um ein Objekt handelt - das Literal "O" muss explizit angegeben werden. Danach wissen wir, dass wir listObj als Objekt übergeben haben, und wir versuchen, seine Länge mit Standard-Python-Methoden herauszufinden: PyList_Size. Beachten Sie, dass wir hier immer noch keine Aufrufe verwenden können, um die Länge dieses Vektors herauszufinden, sondern die Python-Funktionalität verwenden. Wir lassen die Implementierung weg, wonach alle Werte an Python zurückgegeben werden müssen. Rufen Sie dazu Py_BuildValue auf, geben Sie an, welchen Datentyp wir zurückgeben. In diesem Fall ist „i“ eine Ganzzahl und die Summenvariable selbst.
In diesem Fall versteht jeder - wir finden die Summe aller Elemente der Liste. Gehen wir noch etwas weiter.
for(i = 0; i< length; i++){
Dies ist das gleiche: Im Moment ist listObj ein Python-Objekt. In diesem Fall versuchen wir, die Listenelemente zu übernehmen. Python.h hat alles was Sie dazu brauchen.
Nachdem wir Temp bekommen haben, versuchen wir es zu lange zu besetzen. Und erst danach können Sie in C etwas tun.
Nachdem wir die gesamte Funktion implementiert haben, ist es notwendig, Dokumentation zu schreiben.
Die Dokumentation ist immer gut und dieses Toolkit bietet alles für eine bequeme Wartung. Gemäß der Namenskonvention benennen wir das Modul addList_docs und speichern dort die Beschreibung. Jetzt müssen Sie das Modul registrieren, dafür gibt es eine spezielle PyMethodDef-Struktur. Bei der Beschreibung der Eigenschaften sagen wir, dass die Funktion unter dem Namen "add" nach Python exportiert wird und diese Funktion PyCFunction aufruft. METH_VARARGS bedeutet, dass eine Funktion möglicherweise eine beliebige Anzahl von Variablen annehmen kann. Wir haben auch zusätzliche Zeilen aufgeschrieben und eine Standardprüfung beschrieben, falls wir das Modul gerade importiert haben, aber keine Methode verwendet haben, damit es nicht herunterfällt.
Nachdem wir dies alles angekündigt haben, versuchen wir ein Modul zu erstellen. Wir erstellen ein Moduledef und legen alles, was wir getan haben, dort ab.
static struct PyModuleDef moduledef = { PyModuleDef_HEAD_INIT, "addList example module", -1, adList_funcs, NULL, NULL, NULL, NULL };
PyModuleDef_HEAD_INIT ist eine Standard-Python-Konstante, die Sie immer verwenden sollten. -1 gibt an, dass in der Importphase kein zusätzlicher Speicher zugewiesen werden muss.
Wenn wir das Modul selbst erstellt haben, müssen wir es initialisieren. Python sucht immer nach init. Erstellen Sie daher eine PyInit_addList für addList. Aus der zusammengesetzten Struktur können Sie nun PyModule_Create aufrufen und schließlich das Modul selbst erstellen. Fügen Sie als Nächstes die Metainformationen hinzu und geben Sie das Modul selbst zurück.
PyInit_addList(void){ PyObject *module = PyModule_Create(&mdef); If (module == NULL) return NULL; PyModule_AddStringConstant(module, "__author__", "Bruse Lee<brus@kf.ch>:"); PyModule_addStringConstant (Module, "__version__", "1.0.0"); return module; }
Wie Sie bereits bemerkt haben, gibt es viele Dinge, die verändert werden müssen. Sie sollten sich immer an Python erinnern, wenn wir in C / C ++ schreiben.
Aus diesem Grund wurde vor etwa 15 Jahren die SWIG-Technologie eingeführt, um das Leben eines gewöhnlichen sterblichen Programmierers zu erleichtern.
Swig
Mit diesem Tool können Sie Python-Bindungen abstrahieren und nativen Code schreiben. Es hat die gleichen Vor- und Nachteile wie Native C / C ++, aber es gibt Ausnahmen.
SWIG-Profis:
- Stabile Technologie.
- Eine große Menge an Dokumentation.
- Abstracts von der Bindung an Python.
Nachteile von SWIG:
- Lange Einrichtung.
- Wissen C.
- Segmentierungsfehler.
- Schwierigkeiten beim Debuggen.
- Die Komplexität der Integration in die Montage des Projekts.
Das erste Minus ist, dass
Sie beim Einrichten den Verstand verlieren . Als ich es zum ersten Mal einrichtete, verbrachte ich anderthalb Tage damit, es überhaupt zu starten. Dann ist es natürlich einfacher. SWIG 3.x ist einfacher geworden.
Um nicht mehr in den Code einzusteigen, betrachten Sie das allgemeine Schema von SWIG.
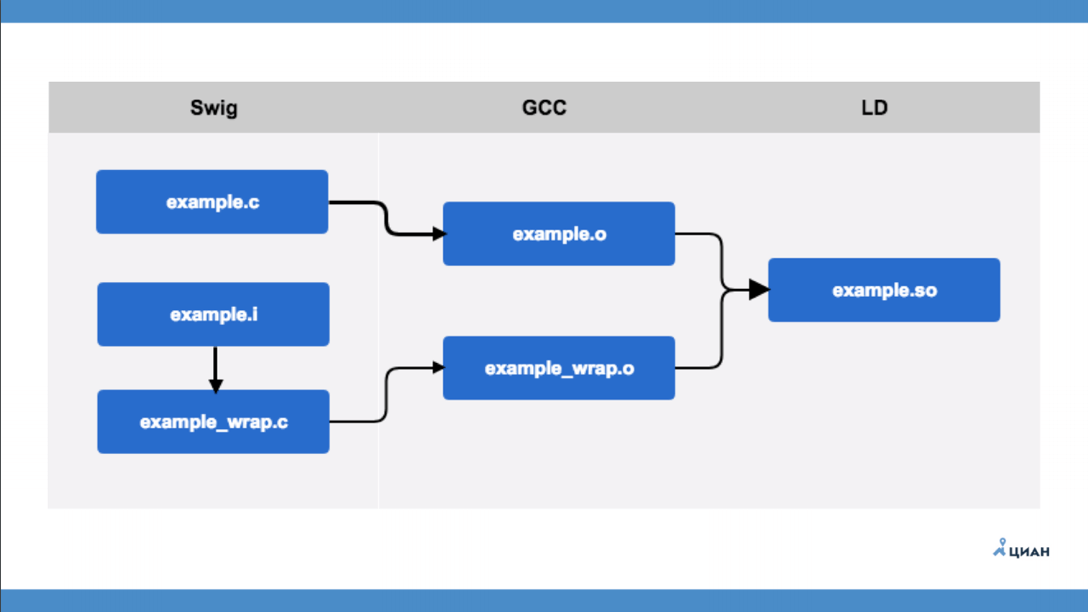
example.c ist ein C-Modul, das überhaupt nichts über Python weiß. Es gibt eine Schnittstellendatei example.i, die im SWIG-Format beschrieben wird. Führen Sie danach das Dienstprogramm SWIG aus, mit dem example_wrap.c aus der Schnittstellendatei erstellt wird. Dies ist derselbe Wrapper, den wir früher mit unseren Händen verwendet haben. Das heißt, SWIG erstellt für uns nur einen Datei-Wrapper, die sogenannte Brücke. Danach kompilieren wir mit GCC zwei Dateien und erhalten zwei Objektdateien (example.o und example_wrap.o). Erst dann erstellen wir unsere Bibliothek. Alles ist einfach und klar.
Cython
Andrey Svetlov hat auf der MoscowPython Conf einen hervorragenden
Bericht verfasst. Ich möchte nur sagen, dass dies eine beliebte Technologie mit guter Dokumentation ist.
Cython-Vorteile:
- Beliebte Technologie.
- Ziemlich stabil.
- Es lässt sich leicht in die Projektbaugruppe integrieren.
- Gute Dokumentation.
Nachteile von Cython:
- Eigene Syntax.
- Wissen C.
- Segmentierungsfehler.
- Schwierigkeiten beim Debuggen.
Nachteile sind wie immer. Die wichtigste ist die eigene Syntax, die C / C ++ und Python sehr ähnlich ist.
Ich möchte jedoch darauf hinweisen, dass Python-Code mit Cython durch Schreiben von nativem Code beschleunigt werden kann.

Wie Sie sehen können, gibt es viele Dekorateure, und das ist nicht sehr gut. Wenn Sie Cython verwenden möchten, lesen Sie den Bericht von Andrei Svetlov.
CTypes
CTypes ist die Standard-Python-Bibliothek, die mit der Fremdfunktionsschnittstelle zusammenarbeitet. FFI ist eine Bibliothek auf niedriger Ebene. Dies ist eine native Technologie, die sehr häufig im Code verwendet wird. Mit ihrer Hilfe ist es einfach, plattformübergreifend zu implementieren.
FFI ist jedoch mit viel Aufwand verbunden, da alle Bridges und alle Handler zur Laufzeit dynamisch erstellt werden. Das heißt, wir haben die dynamische Bibliothek geladen, und Python weiß derzeit nicht, was die Bibliothek ist. Nur wenn eine Bibliothek im Speicher aufgerufen wird, werden diese Brücken dynamisch aufgebaut.
Vorteile von CT-Typen:
- Native Technologie.
- Einfach im Code zu verwenden.
- Einfach plattformübergreifend zu implementieren.
- Sie können fast jede Sprache verwenden.
Nachteile CT-Typen:
- Trägt über Kopf.
- Schwierigkeiten beim Debuggen.
from ctypes import *
Sie nahmen adder.so und riefen es zur Laufzeit auf. Wir können sogar native Python-Typen übergeben.
Nach all dem lautet die Frage: "Es ist irgendwie kompliziert, überall C, was zu tun ist?".
Rost
Früher habe ich der Sprache nicht die richtige Aufmerksamkeit geschenkt, aber jetzt wende ich mich praktisch ihr zu.
Vorteile von Rust:
- Sichere Sprache.
- Leistungsstarke statische Garantien für korrektes Verhalten.
- Einfache Integration in Projektbuilds ( PyO3 ).
Nachteile von Rost:
- Hohe Eintrittsschwelle.
- Lange Einrichtung.
- Schwierigkeiten beim Debuggen.
- Es gibt wenig Dokumentation.
- In einigen Fällen Overhead.
Rust ist eine sichere Sprache mit automatischem Arbeitsnachweis. Die Syntax selbst und der Sprachpräprozessor selbst lassen keinen expliziten Fehler zu. Gleichzeitig konzentriert es sich auf die Variabilität, dh es muss jedes Ergebnis der Ausführung des Codezweigs verarbeiten.
Dank des PyO3-Teams gibt es gute Python-Ordner für Rust und Tools zur Integration in das Projekt.
Ich gehe davon aus, dass die Konfiguration für einen unvorbereiteten Programmierer sehr lange dauert. Nur wenige Dokumentationen, aber anstelle von Nachteilen haben wir keinen Segmentierungsfehler. In 99% der Fälle kann ein Programmierer in Rust in guter Weise nur dann einen Segmentierungsfehler erhalten, wenn er ausdrücklich das Auspacken angegeben und ihn nur bewertet hat.
Ein kleines Beispiel für Code, dasselbe Modul, das wir zuvor untersucht haben.
#![feature(proc_macro)] #[macro_use] extern crate pyo3; Use pyo3::prelude::*;
Der Code hat eine bestimmte Syntax, aber Sie gewöhnen sich sehr schnell daran. Tatsächlich ist hier alles gleich. Mit Makros erstellen wir modinit, das für uns die zusätzliche Arbeit erledigt, alle Arten von Bindemitteln für Python zu generieren. Denken Sie daran, ich sagte, Sie müssen einen Handler-Wrapper machen, hier ist es das gleiche. run_py konvertiert Typen, dann rufen wir den nativen Code auf.
Wie Sie sehen können, gibt es syntaktischen Zucker, um eine Funktion zu exportieren. Wir sagen nur, dass wir die Funktion add benötigen und keine Schnittstellen beschreiben. Wir akzeptieren eine Liste, die genau py_list und nicht Object ist, da Rust selbst zum Zeitpunkt der Kompilierung die erforderlichen Ordner einrichtet. Wenn wir den falschen Datentyp übergeben, wie bei Erweiterungserweiterungen, tritt ein TypeError auf. Nachdem wir die Liste erhalten haben, beginnen wir sie zu verarbeiten.
Lassen Sie uns genauer sehen, was er anfängt zu tun.
#[pyfn(m, "add", py_list="*")] fn add(_py: Python, py_list: &PyList) -> PyResult<i32> { match py_list.len() { 0 =>Err(EmptyListError::new("List is empty")), _ => { let mut sum : i32 = 0; for item in py_list.iter() { let temp:i32 = match item.extract() { Ok(v) => v, Err(_) => { let err_msg: String = format!("List item {} is not int", item); return Err(ItemListError::new(err_msg)) } }; sum += temp; } Ok(sum) } } }
Der gleiche Code wie in C / C ++ / Ctypes, jedoch nur in Rust. Dort habe ich versucht, PyObject auf eine Art Long zu besetzen. Was würde passieren, wenn wir auflisten müssten, außer Zahlen, würden wir eine Zeichenfolge bekommen? Ja, wir würden einen Systemfehler bekommen. In diesem Fall durch
let mut sum
: i32 = 0; Wir versuchen auch, einen Wert aus der Liste zu erhalten und ihn in i32 umzuwandeln. Das heißt, wir können diesen Code nicht ohne item.extract () unbewusst schreiben und in den gewünschten Typ umwandeln. Wenn wir i32 geschrieben haben, heißt es im Falle eines Rust-Fehlers in der Kompilierungsphase: "Behandeln Sie den Fall, wenn nicht i32". In diesem Fall geben wir, wenn wir i32 haben, einen Wert zurück. Wenn dies ein Fehler ist, lösen wir eine Ausnahme aus.
Was zu wählen
Nach dieser kurzen Tour werden wir uns überlegen, was wir am Ende auswählen sollen.
Die Antwort liegt wirklich in Ihrem Geschmack und Ihrer Farbe.
Ich werde keine bestimmte Technologie fördern.

Fassen Sie einfach zusammen, was gesagt wurde:
- Im Fall von SWIG und C / C ++ müssen Sie C / C ++ sehr gut kennen und verstehen, dass die Entwicklung dieses Moduls zusätzlichen Aufwand verursacht. Es wird jedoch ein Minimum an Tools verwendet, und wir werden mit der nativen Python-Technologie arbeiten, die von den Entwicklern unterstützt wird.
- Im Fall von Cython haben wir eine kleine Eingabeschwelle, eine hohe Entwicklungsgeschwindigkeit und auch dies ist ein gewöhnlicher Codegenerator.
- Auf Kosten von CTypes möchte ich Sie vor dem relativ hohen Overhead warnen. Das dynamische Laden von Bibliotheken kann zu großen Problemen führen, wenn wir nicht wissen, um welche Art von Bibliothek es sich handelt.
- Ich würde Rust raten, jemanden mitzunehmen, der C / C ++ nicht gut kennt. Rost in der Produktion bringt wirklich die geringsten Probleme mit sich.
Ruf nach Papieren
Wir akzeptieren Bewerbungen für Moscow Python Conf ++ bis zum 7. September. Schreiben Sie in dieser einfachen Form, dass Sie über Python Bescheid wissen, das Sie wirklich mit der Community teilen müssen.
Für diejenigen, die mehr am Zuhören interessiert sind, kann ich über coole Berichte sprechen.
- Donald Whyte spricht gerne über die Beschleunigung der Mathematik in Python und bereitet eine neue Geschichte für uns vor: Wie man Mathematik mit gängigen Bibliotheken, Tricks und Hinterlist 10-mal schneller macht, und der Code ist klar und unterstützt.
- Artyom Malyshev hat all seine langjährigen Erfahrungen in der Entwicklung von Django gesammelt und präsentiert einen Berichtsleitfaden zum Framework! Alles, was zwischen dem Empfang einer HTTP-Anfrage und dem Senden einer fertigen Webseite passiert: Aufdecken von Magie, eine Karte der internen Mechanismen des Frameworks und viele nützliche Tipps für Ihre Projekte.