Hallo Habr! In jüngerer Zeit haben wir
kurz über Natural Language Interfaces gesprochen. Nun, heute haben wir nicht kurz. Unter dem Ausschnitt finden Sie eine vollständige Geschichte zum Erstellen von NL2API für die Web-API. Unsere Kollegen von Research haben einen einzigartigen Ansatz zur Erfassung von Trainingsdaten für das Framework ausprobiert. Jetzt mitmachen!

Anmerkung
Während sich das Internet zu einer serviceorientierten Architektur entwickelt, werden Software-Schnittstellen (APIs) immer wichtiger, um den Zugriff auf Daten, Dienste und Geräte zu ermöglichen. Wir arbeiten an der Erstellung einer Schnittstelle in natürlicher Sprache für die API (NL2API) mit Schwerpunkt auf Webdiensten. NL2API-Lösungen bieten viele potenzielle Vorteile, beispielsweise die Vereinfachung der Integration von Webdiensten in virtuelle Assistenten.
Wir bieten die erste umfassende Plattform (Framework), mit der Sie NL2API für eine bestimmte Web-API erstellen können. Die Hauptaufgabe besteht darin, Daten für das Training zu sammeln, dh die Paare „NL-Befehl - API-Aufruf“, sodass NL2API die Semantik beider NL-Befehle untersuchen kann, die kein streng definiertes Format und formalisierte API-Aufrufe haben. Wir bieten unseren eigenen einzigartigen Ansatz für die Erfassung von Trainingsdaten für NL2API mithilfe von Crowdsourcing - und ziehen viele Remote-Mitarbeiter an, um verschiedene NL-Teams zu generieren. Wir optimieren den Crowdsourcing-Prozess selbst, um die Kosten zu senken.
Insbesondere bieten wir ein grundlegend neues hierarchisches Wahrscheinlichkeitsmodell an, mit dessen Hilfe wir das Budget für Crowdsourcing verteilen können, hauptsächlich zwischen API-Aufrufen, die für das Erlernen von NL2API von hohem Wert sind. Wir wenden unser Framework auf echte APIs an und zeigen, dass Sie damit hochwertige Trainingsdaten zu minimalen Kosten erfassen und leistungsstarke NL2API von Grund auf neu erstellen können. Wir zeigen auch, dass unser Crowdsourcing-Modell die Effizienz dieses Prozesses verbessert, dh die im Rahmen des Frameworks gesammelten Trainingsdaten bieten eine höhere NL2API-Leistung, die die Basislinie erheblich übertrifft.
Einführung
Anwendungsprogrammierschnittstellen (APIs) spielen sowohl in der virtuellen als auch in der physischen Welt dank der Entwicklung von Technologien wie serviceorientierter Architektur (SOA), Cloud Computing und Internet der Dinge (IoT) eine immer wichtigere Rolle. Beispielsweise stellen in der Cloud gehostete Webdienste (Wetter, Sport, Finanzen usw.) über die Web-API Daten und Dienste für Endbenutzer bereit, und IoT-Geräte ermöglichen anderen Netzwerkgeräten, ihre Funktionen zu nutzen.
 Abbildung 1. Die Paare "NL-Befehl (links) und API-Aufruf (rechts)" wurden zusammengestellt
Abbildung 1. Die Paare "NL-Befehl (links) und API-Aufruf (rechts)" wurden zusammengestellt
unser Framework und Vergleich mit IFTTT. GET-Messages und GET-Events sind zwei Web-APIs zum Auffinden von E-Mails bzw. Kalenderereignissen. API kann mit verschiedenen Parametern aufgerufen werden. Wir konzentrieren uns auf vollständig parametrisierte API-Aufrufe, während IFTTT auf APIs mit einfachen Parametern beschränkt ist.In der Regel werden APIs in einer Vielzahl von Software verwendet: Desktop-Anwendungen, Websites und mobile Anwendungen. Sie dienen Benutzern auch über eine grafische Benutzeroberfläche (GUI). Die grafische Benutzeroberfläche hat einen großen Beitrag zur Popularisierung von Computern geleistet, aber im Zuge der Weiterentwicklung der Computertechnologie werden ihre zahlreichen Einschränkungen zunehmend deutlich. Einerseits steigen die Anforderungen an die grafische Anzeige auf dem Bildschirm ständig, wenn Geräte kleiner, mobiler und intelligenter werden, beispielsweise bei tragbaren Geräten oder Geräten, die an das Internet der Dinge angeschlossen sind.
Andererseits müssen sich Benutzer für verschiedene Dienste und Geräte an verschiedene spezialisierte GUIs anpassen. Mit zunehmender Anzahl verfügbarer Dienste und Geräte steigen auch die Kosten für Schulung und Benutzeranpassung. Natural Language Interfaces (NLIs) wie die virtuellen Assistenten von Apple Siri und Microsoft Cortana, auch Conversational oder Conversational Interfaces (CUIs) genannt, weisen als ein einziges intelligentes Tool für eine Vielzahl von Serverdiensten und -geräten ein erhebliches Potenzial auf.
In diesem Artikel betrachten wir das Problem der Erstellung einer Schnittstelle in natürlicher Sprache für die API (NL2API). Im Gegensatz zu virtuellen Assistenten handelt es sich hierbei jedoch nicht um Allzweck-NLIs.
Wir entwickeln Ansätze zum Erstellen von NLIs für bestimmte Web-APIs, d. h. Webdienst-APIs wie den ESPN1-Multisportdienst. Solche NL2APIs können das Skalierbarkeitsproblem von Allzweck-NLIs lösen, indem sie eine verteilte Entwicklung ermöglichen. Der Nutzen eines virtuellen Assistenten hängt weitgehend von der Breite seiner Funktionen ab, dh von der Anzahl der unterstützten Dienste.
Die Integration von Webdiensten in einen virtuellen Assistenten ist jedoch unglaublich mühsam. Wenn einzelne Webdienstanbieter eine kostengünstige Möglichkeit hätten, NLIs für ihre APIs zu erstellen, würden die Integrationskosten erheblich reduziert. Ein virtueller Assistent müsste nicht unterschiedliche Schnittstellen für unterschiedliche Webdienste verarbeiten. Es würde für ihn ausreichen, einfach einzelne NL2APIs zu integrieren, die dank der natürlichen Sprache Einheitlichkeit erreichen. Andererseits kann NL2API auch die Ermittlung von Webdiensten sowie Programmierempfehlungs- und -unterstützungssystemen für APIs vereinfachen, sodass Sie sich nicht mehr an die große Anzahl verfügbarer Web-APIs und deren Syntax erinnern müssen.
Beispiel 1. In Abbildung 1 sind zwei Beispiele dargestellt. Die API kann mit verschiedenen Parametern aufgerufen werden. Bei der E-Mail-Such-API können Benutzer E-Mails nach bestimmten Eigenschaften filtern oder nach E-Mails nach Schlüsselwörtern suchen. Die Hauptaufgabe von NL2API besteht darin, NL-Befehle den entsprechenden API-Aufrufen zuzuordnen.
Herausforderung. Die Erfassung von Trainingsdaten ist eine der wichtigsten Aufgaben im Zusammenhang mit der Erforschung der Entwicklung von NLI-Schnittstellen und ihrer praktischen Anwendung. NLIs verwenden kontrollierte Trainingsdaten, die im Fall von NL2API aus Paaren von "NL-Befehl - API-Aufruf" bestehen, um die Semantik zu untersuchen und NL-Befehle eindeutig den entsprechenden formalisierten Darstellungen zuzuordnen. Die natürliche Sprache ist sehr flexibel, sodass Benutzer den API-Aufruf auf syntaktisch unterschiedliche Weise beschreiben können, dh es findet eine Paraphrasierung statt.
Betrachten Sie das zweite Beispiel in Abbildung 1. Benutzer können diese Frage wie folgt umformulieren: „Wo findet das nächste Meeting statt?“ Oder „Suchen Sie einen Ort für das nächste Meeting“. Daher ist es äußerst wichtig, ausreichende Trainingsdaten zu sammeln, damit das System solche Optionen weiter erkennt. Bestehende NLIs halten sich bei der Datenerfassung normalerweise an das „bestmögliche“ Prinzip. Das nächste Analogon unserer Methode zum Vergleichen von NL-Befehlen mit API-Aufrufen verwendet beispielsweise das Konzept von IF-This-Then-That (IFTTT) - „Wenn ja, dann“ (Abbildung 1). Trainingsdaten stammen direkt von der IFTTT-Website.
Wenn die API jedoch nicht oder nicht vollständig unterstützt wird, kann die Situation nicht behoben werden. Darüber hinaus sind die auf diese Weise gesammelten Trainingsdaten nicht anwendbar, um erweiterte Befehle mit mehreren Parametern zu unterstützen. Zum Beispiel haben wir anonymisierte Microsoft API-Anrufprotokolle analysiert, um nach E-Mails für den Monat zu suchen, und festgestellt, dass etwa 90% von ihnen zwei oder drei Parameter (ungefähr die gleiche Menge) verwenden, und diese Parameter sind sehr unterschiedlich. Daher bemühen wir uns, die API-Parametrisierung vollständig zu unterstützen und erweiterte NL-Befehle zu implementieren. Das Problem der Bereitstellung eines aktiven und anpassbaren Prozesses zum Sammeln von Trainingsdaten für eine bestimmte API bleibt derzeit ungelöst.
Die Probleme bei der Verwendung von NLI in Kombination mit anderen formalisierten Darstellungen wie relationalen Datenbanken, Wissensdatenbanken und Webtabellen wurden recht gut gelöst, während der Entwicklung von NLI für Web-APIs fast keine Aufmerksamkeit geschenkt wurde. Wir bieten die erste umfassende Plattform (Framework), mit der Sie NL2API für eine bestimmte Web-API von Grund auf neu erstellen können. Bei der Implementierung der Web-API umfasst unser Framework drei Phasen: (1) Präsentation. Das ursprüngliche HTTP-Web-API-Format enthält viele redundante und daher ablenkende Details aus Sicht des NLI.
Wir empfehlen die Verwendung einer semantischen Zwischendarstellung für die Web-API, um das NLI nicht mit unnötigen Informationen zu überladen. (2) Eine Reihe von Trainingsdaten. Wir bieten einen neuen Ansatz, um kontrollierte Trainingsdaten basierend auf Crowdsourcing zu erhalten. (3) NL2API. Wir bieten auch zwei NL2API-Modelle an: ein sprachbasiertes Extraktionsmodell und ein wiederkehrendes neuronales Netzwerkmodell (Seq2Seq).
Eines der wichtigsten technischen Ergebnisse dieser Arbeit ist ein grundlegend neuer Ansatz für die aktive Erfassung von Trainingsdaten für NL2API auf der Basis von Crowdsourcing. Wir verwenden Remote-Führungskräfte, um API-Aufrufe beim Vergleich mit NL-Befehlen mit Anmerkungen zu versehen. Auf diese Weise können Sie drei Entwurfsziele erreichen, indem Sie Folgendes bereitstellen: (1) Anpassbarkeit. Sie müssen angeben können, welche Parameter für welche API verwendet werden sollen und wie viele Trainingsdaten erfasst werden sollen. (2) Niedrige Kosten. Die Dienstleistungen von Crowdsourcing-Mitarbeitern sind um eine Größenordnung billiger als die von spezialisierten Spezialisten, weshalb sie eingestellt werden sollten. (3) Hohe Qualität. Die Qualität der Trainingsdaten sollte nicht verringert werden.
Bei der Gestaltung dieses Ansatzes treten zwei Hauptprobleme auf. Erstens sind API-Aufrufe mit erweiterter Parametrisierung, wie in Abbildung 1 dargestellt, für den Durchschnittsbenutzer nicht nachvollziehbar. Daher müssen Sie entscheiden, wie das Anmerkungsproblem formuliert werden soll, damit Crowdsourcing-Mitarbeiter problemlos damit umgehen können. Wir beginnen mit der Entwicklung einer semantischen Zwischendarstellung für die Web-API (siehe Abschnitt 2.2), mit der wir nahtlos API-Aufrufe mit den erforderlichen Parametern generieren können.
Dann überlegen wir uns die Grammatik für die automatische Konvertierung jedes API-Aufrufs in einen kanonischen NL-Befehl, was ziemlich umständlich sein kann, aber für den durchschnittlichen Crowdsourcing-Mitarbeiter klar ist (siehe Abschnitt 3.1). Die Darsteller müssen das kanonische Team nur umformulieren, damit es natürlicher klingt. Mit diesem Ansatz können Sie viele Fehler bei der Erfassung von Schulungsdaten vermeiden, da die Umformulierungsaufgabe für den durchschnittlichen Crowdsourcing-Mitarbeiter viel einfacher und verständlicher ist.
Zweitens müssen Sie verstehen, wie Sie nur diejenigen API-Aufrufe definieren und mit Anmerkungen versehen, die für das Erlernen von NL2API von echtem Wert sind. Die „kombinatorische Explosion“, die während der Parametrierung auftritt, führt dazu, dass die Anzahl der Aufrufe selbst für eine API sehr groß sein kann. Es ist nicht sinnvoll, alle Anrufe mit Anmerkungen zu versehen. Wir bieten ein grundlegend neues hierarchisches Wahrscheinlichkeitsmodell für die Implementierung des Crowdsourcing-Prozesses an (siehe Abschnitt 3.2). In Analogie zur Sprachmodellierung zum Abrufen von Informationen gehen wir davon aus, dass NL-Befehle basierend auf den entsprechenden API-Aufrufen generiert werden. Daher sollte das Sprachmodell für jeden API-Aufruf verwendet werden, um diesen „generativen“ Prozess zu registrieren.
Unser Modell basiert auf der Zusammensetzung von API-Aufrufen oder formalisierten Darstellungen der semantischen Struktur als Ganzes. Auf einer intuitiven Ebene können wir einen API-Aufruf erstellen, wenn er aus einfacheren Aufrufen besteht (z. B. "ungelesene E-Mails über einen Kandidaten für einen naturwissenschaftlichen Abschluss" = "ungelesene E-Mails" + "E-Mails für einen Kandidaten für einen naturwissenschaftlichen Abschluss") Sprachmodell aus einfachen API-Aufrufen, auch ohne Annotation. Durch Annotieren einer kleinen Anzahl von API-Aufrufen können wir das Sprachmodell für alle anderen berechnen.
Natürlich sind die berechneten Sprachmodelle alles andere als ideal, sonst hätten wir das Problem der Erstellung von NL2API bereits gelöst. Eine solche Extrapolation des Sprachmodells auf nicht kommentierte API-Aufrufe gibt uns jedoch eine ganzheitliche Sicht auf den gesamten Bereich der API-Aufrufe sowie auf das Zusammenspiel der natürlichen Sprache und der API-Aufrufe, wodurch wir den Crowdsourcing-Prozess optimieren können. In Abschnitt 3.3 beschreiben wir einen Algorithmus zum selektiven Kommentieren von API-Aufrufen, um die Unterscheidbarkeit von API-Aufrufen zu verbessern, dh um die Diskrepanz zwischen ihren Sprachmodellen zu maximieren.
Wir wenden unser Framework auf zwei bereitgestellte APIs aus dem Microsoft Graph API2-Paket an. Wir zeigen, dass qualitativ hochwertige Trainingsdaten zu minimalen Kosten gesammelt werden können, wenn der vorgeschlagene Ansatz verwendet wird3. Wir zeigen auch, dass unser Ansatz das Crowdsourcing verbessert. Zu ähnlichen Kosten sammeln wir bessere Trainingsdaten, die die Basislinie deutlich überschreiten. Infolgedessen bieten unsere NL2API-Lösungen eine höhere Genauigkeit.
Im Allgemeinen umfasst unser Hauptbeitrag drei Aspekte:
- Wir waren eine der ersten, die sich mit den Problemen von NL2API befasst haben, und haben einen umfassenden Rahmen für die Erstellung von NL2API von Grund auf vorgeschlagen.
- Wir haben einen einzigartigen Ansatz für die Erfassung von Trainingsdaten mithilfe von Crowdsourcing und ein grundlegend neues hierarchisches Wahrscheinlichkeitsmodell vorgeschlagen, um diesen Prozess zu optimieren.
- Wir haben unser Framework auf echte Web-APIs angewendet und gezeigt, dass eine ausreichend effektive NL2API-Lösung von Grund auf neu erstellt werden kann.
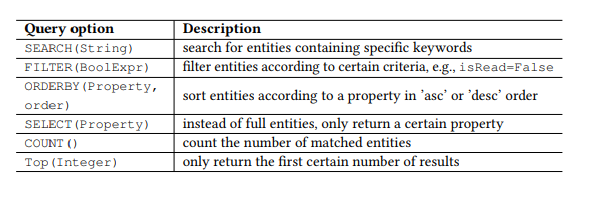 Tabelle 1. OData-Abfrageparameter.
Tabelle 1. OData-Abfrageparameter.Präambel
RESTful API
In letzter Zeit werden Web-APIs, die dem REST-Architekturstil entsprechen, d. H. Der RESTful-API, aufgrund ihrer Einfachheit immer beliebter. RESTful-APIs werden auch auf Smartphones und IoT-Geräten verwendet. Die Restful-APIs arbeiten mit Ressourcen, die über URIs angesprochen werden, und bieten einer Vielzahl von Clients mithilfe einfacher HTTP-Befehle Zugriff auf diese Ressourcen: GET, PUT, POST usw. Wir werden hauptsächlich mit der RESTful-API arbeiten, aber die grundlegenden Methoden können verwendet werden und andere APIs.
Nehmen Sie beispielsweise das beliebte Open Data Protocol (OData) für die RESTful-API und zwei Web-APIs aus dem Microsoft Graph API-Paket (Abbildung 1), die jeweils zur Suche nach E-Mails und Benutzerkalenderereignissen verwendet werden. Ressourcen in OData sind Entitäten, von denen jede einer Liste von Eigenschaften zugeordnet ist. Beispielsweise verfügt die Nachrichtenentität - eine E-Mail - über Eigenschaften wie Betreff (Betreff), von (von), isRead (Lesen), receiveDateTime (Datum und Uhrzeit des Empfangs) usw.
Darüber hinaus definiert OData eine Reihe von Abfrageparametern, mit denen Sie erweiterte Manipulationen an Ressourcen durchführen können. Mit dem Parameter FILTER können Sie beispielsweise nach E-Mails eines bestimmten Absenders oder nach Briefen suchen, die an einem bestimmten Datum eingegangen sind. Die Anforderungsparameter, die wir verwenden werden, sind in Tabelle 1 aufgeführt. Wir rufen jede Kombination des HTTP-Befehls und der Entität (oder einer Gruppe von Entitäten) als API auf, z. B. GET-Nachrichten, um nach E-Mails zu suchen. Jede parametrisierte Anforderung, z. B. FILTER (isRead = False), wird als Parameter bezeichnet, und ein API-Aufruf ist eine API mit einer Liste von Parametern.
NL2API
Die Hauptaufgabe von NLI besteht darin, eine Anweisung (einen Befehl in einer natürlichen Sprache) mit einer bestimmten formalisierten Darstellung zu vergleichen, z. B. logischen Formularen oder SPARQL-Abfragen für Wissensdatenbanken oder Web-APIs in unserem Fall. Wenn es notwendig ist, sich auf die semantische Abbildung zu konzentrieren, ohne von irrelevanten Details abgelenkt zu werden, wird normalerweise eine semantische Zwischendarstellung verwendet, um nicht direkt mit dem Ziel zu arbeiten. Beispielsweise wird die kombinatorische kategoriale Grammatik häufig zum Erstellen von NLIs für Datenbanken und Wissensdatenbanken verwendet. Ein ähnlicher Ansatz zur Abstraktion ist auch für NL2API sehr wichtig. Viele Details, einschließlich URL-Konventionen, HTTP-Header und Antwortcodes, können die NL2API von der Lösung des Hauptproblems - der semantischen Zuordnung - "ablenken".
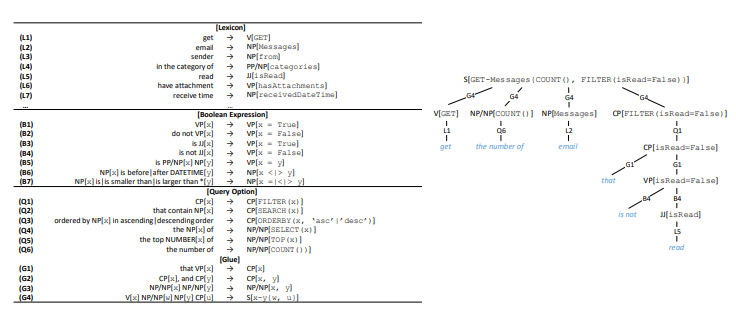
Daher erstellen wir eine Zwischenansicht für RESTful-APIs (Abbildung 2) mit dem Namen API-Frame. Diese Ansicht spiegelt die Semantik des Frames wider. Der API-Frame besteht aus fünf Teilen. HTTP-Verb (HTTP-Befehl) und Ressource sind die Grundelemente für eine RESTful-API. Mit Return Type können Sie zusammengesetzte APIs erstellen, dh mehrere API-Aufrufe kombinieren, um eine komplexere Operation auszuführen. Erforderliche Parameter werden am häufigsten bei PUT- oder POST-Aufrufen in der API verwendet. Beispielsweise sind Adresse, Header und Nachrichtentext erforderliche Parameter für das Senden von E-Mails. Optionale Parameter sind häufig in GET-Aufrufen in der API vorhanden. Sie helfen dabei, die Informationsanforderung einzugrenzen.
Wenn die erforderlichen Parameter fehlen, serialisieren wir den API-Frame, zum Beispiel: GET-messages {FILTER (isRead = False), SEARCH („PhD application“), COUNT ()}. Ein API-Frame kann deterministisch sein und in einen echten API-Aufruf konvertiert werden. Während des Konvertierungsprozesses werden die erforderlichen Kontextdaten hinzugefügt, einschließlich Benutzer-ID, Ort, Datum und Uhrzeit. Im zweiten Beispiel (Abbildung 1) wird der Now-Wert im Parameter FILTER durch das Datum und die Uhrzeit der Ausführung des entsprechenden Befehls während der Konvertierung des API-Frames in einen echten API-Aufruf ersetzt. Ferner werden die Konzepte eines API-Rahmens und eines API-Aufrufs austauschbar verwendet.
 Abbildung 2. Der API-Frame. Oben: Team in natürlicher Sprache. In der Mitte: Frame API. Unten: API-Aufruf.
Abbildung 2. Der API-Frame. Oben: Team in natürlicher Sprache. In der Mitte: Frame API. Unten: API-Aufruf.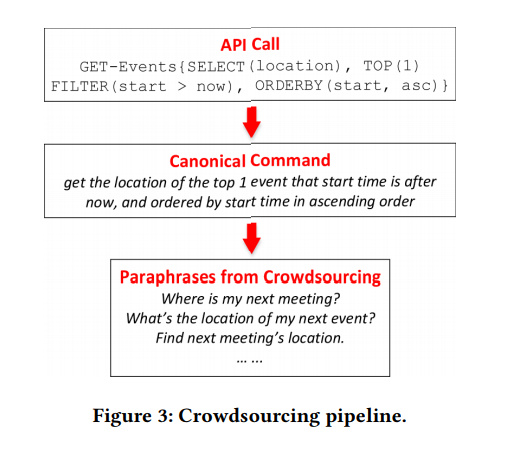 3. .
3. .NL2API . API , ( 3.1), ( 3). API, ( 3.2), ( 3.3).
 4. . : . : .
4. . : . : .API
API API. , , API, API . , Boolean, (True/False).
, Datetime, , today this_week receivedDateTime. , API (, ) API API.
, API . . , TOP, ORDERBY. , Boolean, isRead, ORDERBY . « » API API.
API. API . API API ( 4). ( HTTP, , ). , ⟨sender → NP[from]⟩ , from «sender», — (NP), .
(V), (VP), (JJ), - (CP), , (NP/NP), (PP/NP), (S) . .
, API , RESTful API OData — « » . 17 4 API, ( 5).
, API. ⟨t1, t2, ..., tn → c[z]⟩,
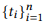
, z API, cz — . 4. API , S, G4, API . C , , - «that is not read».
, . , VP[x = False] B2, B4, x. x VP, B2 (, x is hasAttachments → «do not have attachment»); JJ, B4 (, x is isRead → «is not read»). («do not read» or «is not have attachment») .
Mit dem oben beschriebenen Ansatz können wir eine große Anzahl von API-Aufrufen generieren, aber das Annotieren aller Aufrufe mithilfe von Crowdsourcing ist wirtschaftlich nicht machbar. Daher schlagen wir ein hierarchisches Wahrscheinlichkeitsmodell für Crowdsourcing vor, mit dessen Hilfe Sie entscheiden können, welche API-Aufrufe mit Anmerkungen versehen werden sollen. Soweit wir wissen, ist dies das erste probabilistische Modell für die Verwendung von Crowdsourcing zur Erstellung von NLI-Schnittstellen, mit dem wir die einzigartige und faszinierende Aufgabe der Modellierung der Interaktion zwischen Darstellungen natürlicher Sprache und formalisierten semantischen Strukturdarstellungen lösen können. Formalisierte Darstellungen der semantischen Struktur im Allgemeinen und API-Aufrufe im Besonderen sind kompositorischer Natur. Zum Beispiel besteht z12 = GET-Nachrichten {COUNT (), FILTER (isRead = False)} aus z1 = GET-Nachrichten {FILTER (isRead = False)} und z2 = GET-Nachrichten {COUNT ()} (diese Beispiele sind detaillierter weiter diskutieren).
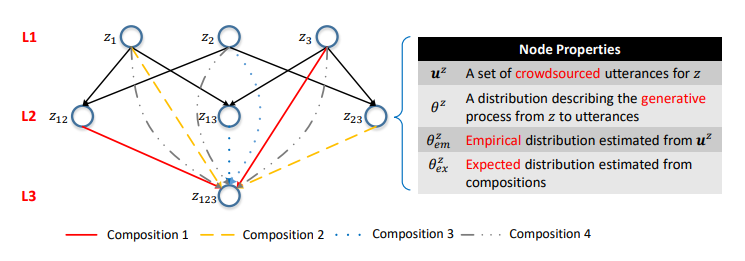 Abbildung 5. Das semantische Netzwerk. Die i-te Schicht besteht aus API-Aufrufen mit i-Parametern. Rippen sind Kompositionen. Die Wahrscheinlichkeitsverteilungen an den Eckpunkten charakterisieren die entsprechenden Sprachmodelle.
Abbildung 5. Das semantische Netzwerk. Die i-te Schicht besteht aus API-Aufrufen mit i-Parametern. Rippen sind Kompositionen. Die Wahrscheinlichkeitsverteilungen an den Eckpunkten charakterisieren die entsprechenden Sprachmodelle.Eines der wichtigsten Ergebnisse unserer Studie war die Bestätigung, dass eine solche Zusammensetzung zur Modellierung des Crowdsourcing-Prozesses verwendet werden kann.
Zunächst definieren wir die Zusammensetzung basierend auf einer Reihe von API-Aufrufparametern.
Definition 3.1 (Zusammensetzung). Nehmen Sie eine API und eine Reihe von API-Aufrufen
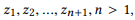
Wenn wir r (z) als einen Satz von Parametern für z definieren, dann
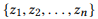
ist eine Komposition
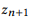
genau dann, wenn
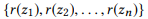
ist ein Teil
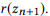
Basierend auf den Zusammensetzungsbeziehungen von API-Aufrufen können Sie alle API-Aufrufe in einer einzigen hierarchischen Struktur organisieren. API-Aufrufe mit der gleichen Anzahl von Parametern werden als Eckpunkte einer Ebene dargestellt, und Kompositionen werden als dargestellt
gerichtete Rippen zwischen den Schichten. Wir nennen diese Struktur ein sematisches Netzwerk (oder SeMesh).
In Analogie zu dem Ansatz, der auf der Sprachmodellierung beim Abrufen von Informationen basiert, nehmen wir an, dass Anweisungen, die einem API-z-Aufruf entsprechen, unter Verwendung eines stochastischen Prozesses generiert werden, der durch ein Sprachmodell gekennzeichnet ist
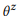
. Zur Vereinfachung konzentrieren wir uns daher auf die Wahrscheinlichkeiten von Wörtern

wo
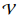
bezeichnet ein Wörterbuch.
Aus Gründen, die etwas später deutlich werden, empfehlen wir anstelle des Standard-Sprach-Unigramm-Modells die Verwendung einer Reihe von Bernoulli-Verteilungen (Bag of Bernoulli, BoB). Jede Bernoulli-Verteilung entspricht einer Zufallsvariablen W, die bestimmt, ob das Wort w in dem auf der Grundlage von z erzeugten Satz erscheint, und die BoB-Verteilung ist eine Menge von Bernoulli-Verteilungen für alle Wörter

. Wir werden verwenden
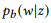
als Kurznotation für
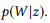
.
Angenommen, wir haben eine (Mehrfach-) Menge von Anweisungen gebildet

für z,
Mit der Maximum Likelihood Estimation (MLE) für die BoB-Verteilung können Sie Anweisungen auswählen, die w enthalten:
 Beispiel 2.
Beispiel 2. In Bezug auf den obigen API-Aufruf z1 nehmen wir an, wir haben zwei Anweisungen: u1 = "ungelesene E-Mails finden" und u2 = "nicht gelesene E-Mails", dann u = {u1, u2}. pb ("E-Mails" | z) = 1.0, da "E-Mails" in beiden Anweisungen vorhanden sind. In ähnlicher Weise ist pb ("ungelesen" | z) = 0,5 und pb ("Treffen" | z) = 0,0.
Im semantischen Netzwerk gibt es drei grundlegende Operationen auf der Scheitelpunktebene:
Anmerkung, Layout und Interpolation.
ANNOTATE (zu kommentieren) bedeutet, Aussagen zu sammeln
den kanonischen Befehl des Scheitelpunkts z mithilfe von Crowdsourcing zu paraphrasieren und die empirische Verteilung zu bewerten
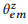
Maximum-Likelihood-Methode.
COMPOSE (compose) versucht, ein auf Kompositionen basierendes Sprachmodell abzuleiten, um die erwartete Verteilung zu berechnen
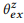
. Wie wir experimentell zeigen,
Ist eine Komposition für z. Wenn wir von der Annahme ausgehen, dass die entsprechenden Aussagen durch denselben kompositorischen Zusammenhang gekennzeichnet sind, dann
sollte angelegt werden

::

wobei f eine kompositorische Funktion ist. Für die BoB-Verteilung sieht die Kompositionsfunktion folgendermaßen aus:
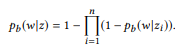
Mit anderen Worten, wenn ui eine Aussage zi ist, ist u eine Aussage
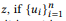
kompositorisch bildet u, dann gehört das Wort w nicht zu u. Genau dann, wenn es keiner Benutzeroberfläche gehört. Wenn z viele Zusammensetzungen hat, wird θe x separat berechnet und dann gemittelt. Das Standard-Sprach-Unigramm-Modell führt nicht zu einer natürlichen Kompositionsfunktion. Bei der Normalisierung der Wortwahrscheinlichkeiten wird die Länge der Sätze berücksichtigt, was wiederum die Komplexität der API-Aufrufe berücksichtigt und die Zerlegung in Gleichung (2) verletzt. Deshalb bieten wir den BoB-Vertrieb an.
Beispiel 3. Angenommen, wir haben eine Annotation für die zuvor erwähnten API-Aufrufe z1 und z2 erstellt, von denen jede zwei Anweisungen enthält:
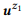
= {"Ungelesene E-Mails suchen", "E-Mails, die nicht gelesen werden"} und
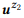
= {"Wie viele E-Mails habe ich?", "Anzahl der E-Mails ermitteln"}. Wir haben Sprachmodelle bewertet
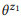
und
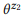
. Die Kompositionsoperation versucht zu bewerten
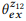
ohne zu fragen
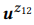
. Zum Beispiel ist für das Wort "E-Mails" pb ("E-Mails" | z1) = 1,0 und pb ("E-Mails" | z2) = 1,0, so dass aus Gleichung (3) folgt, dass pb ("E-Mails" | z12) = 1.0, das heißt, wir glauben, dass dieses Wort in jeder Aussage von z12 enthalten sein wird. In ähnlicher Weise ist pb ("find" | z1) = 0,5 und pb ("find" | z2) = 0,5, so dass pb ("find" | z12) = 0,75 ist. Ein Wort hat eine gute Chance, aus einem beliebigen z1 oder z2 generiert zu werden, daher sollte seine Wahrscheinlichkeit für z12 höher sein.
Natürlich werden Aussagen nicht immer kompositorisch kombiniert. Beispielsweise können mehrere Elemente in einer formalisierten Darstellung einer semantischen Struktur in einem einzigen Wort oder einer Phrase in einer natürlichen Sprache vermittelt werden. Dieses Phänomen wird als sublexische Kompositionalität bezeichnet. Ein solches Beispiel ist in Abbildung 3 dargestellt, in der die drei Parameter TOP (1), FILTER (Start> jetzt) und ORDERBY (Start, aufsteigend) durch das einzelne Wort „next“ dargestellt werden. Es ist jedoch unmöglich, solche Informationen zu erhalten, ohne den API-Aufruf mit Anmerkungen zu versehen, sodass das Problem selbst dem Problem von Hühnchen und Eiern ähnelt. In Ermangelung solcher Informationen ist es vernünftig, die Standardannahme einzuhalten, dass Anweisungen durch dieselbe Zusammensetzungsbeziehung wie API-Aufrufe gekennzeichnet sind.
Dies ist eine plausible Annahme. Es ist erwähnenswert, dass diese Annahme nur zur Modellierung des Crowdsourcing-Prozesses mit dem Ziel der Datenerfassung verwendet wird. In der Testphase entsprechen die Aussagen realer Benutzer möglicherweise nicht dieser Annahme. Die Schnittstelle in natürlicher Sprache wird in der Lage sein, solche nicht kompositorischen Situationen zu bewältigen, wenn sie durch die gesammelten Trainingsdaten abgedeckt sind.
INTERPOLATE (Interpolation) kombiniert alle verfügbaren Informationen über z, dh kommentierte Äußerungen z und Informationen, die aus den Kompositionen erhalten wurden, und erhält eine genauere Schätzung
durch Interpolation
und
.
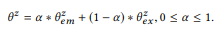
Der Balance-Parameter α steuert die Kompromisse zwischen Anmerkungen
Stromspitzen, die genau, aber ausreichend sind, und Informationen, die aus Zusammensetzungen erhalten werden, die auf der Annahme der Zusammensetzung beruhen, sind möglicherweise nicht so genau, bieten jedoch eine breitere Abdeckung. In gewissem Sinne
dient dem gleichen Zweck wie Anti-Aliasing in der Sprachmodellierung, das eine bessere Schätzung der Wahrscheinlichkeitsverteilung mit unzureichenden Daten (Anmerkungen) ermöglicht. Mehr als
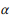
je mehr Gewicht in
. Für einen Wurzelscheitelpunkt, der keine Zusammensetzung hat,
=
. Für ein nicht kommentiertes Top
=
.
Als nächstes beschreiben wir den semantischen Netzwerkaktualisierungsalgorithmus, d. H. Berechnungen
für alle z (Algorithmus 1), auch wenn nur ein kleiner Teil der Eckpunkte mit Anmerkungen versehen wurde. Wir gehen davon aus, dass der Wert
Bereits für alle kommentierten Websites aktualisiert. Wir gehen von oben nach unten und berechnen nacheinander
und
für jeden Scheitelpunkt z. Zunächst müssen Sie die oberen Ebenen aktualisieren, damit Sie die erwartete Verteilung der Scheitelpunkte der unteren Ebene berechnen können. Wir haben alle Wurzelscheitelpunkte mit Anmerkungen versehen, damit wir berechnen können
für alle Eckpunkte.
Algorithmus 1. Aktualisieren Sie die Knotenverteilungen des semantischen Netzes
3.3 Crowdsourcing-Optimierung
Das semantische Netzwerk bildet eine ganzheitliche Ansicht des gesamten Raums von API-Aufrufen sowie der Interaktion von Anweisungen und Aufrufen. Basierend auf dieser Ansicht können wir nur eine Teilmenge hochwertiger API-Aufrufe selektiv mit Anmerkungen versehen. In diesem Abschnitt beschreiben wir unsere Differenzverteilungsstrategie zur Optimierung des Crowdsourcing.
Stellen Sie sich ein semantisches Netzwerk mit vielen Eckpunkten Z vor. Unsere Aufgabe besteht darin, eine Teilmenge von Eckpunkten innerhalb des iterativen Prozesses zu bestimmen
von Crowdsourcing-Mitarbeitern kommentiert werden. Die zuvor mit Anmerkungen versehenen Scheitelpunkte werden als Statusstatus bezeichnet.
dann müssen wir politische Richtlinien finden

um jeden nicht kommentierten Scheitelpunkt basierend auf dem aktuellen Status zu bewerten.
Bevor wir uns mit der Diskussion von Ansätzen zur Berechnung effektiver Richtlinien befassen, nehmen wir an, dass wir bereits einen haben, und geben eine allgemeine Beschreibung unseres Crowdsourcing-Algorithmus (Algorithmus 2), um die zugehörigen Methoden zu beschreiben. Insbesondere kommentieren wir zuerst alle Wurzelscheitelpunkte, um die Verteilung für alle Scheitelpunkte in Z (Zeile 3) zu bewerten. Bei jeder Iteration aktualisieren wir die Scheitelpunktverteilung (Zeile 5), berechnen
Wählen Sie eine Richtlinie aus, die auf dem aktuellen Status des semantischen Netzwerks basiert (Zeile 6), wählen Sie den nicht kommentierten Scheitelpunkt mit der maximalen Bewertung aus (Zeile 7) und kommentieren Sie den Scheitelpunkt und das Ergebnis im neuen Status (Zeile 8). In der Praxis können Sie im Rahmen einer Iteration mehrere Scheitelpunkte mit Anmerkungen versehen, um die Effizienz zu steigern.
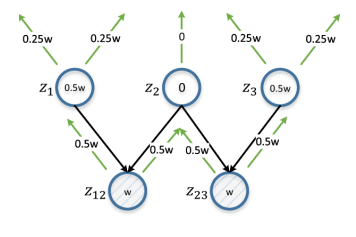 Abbildung 6. Differentialverteilung. z12 und z23 repräsentieren das untersuchte Eckpunktpaar. w ist eine Schätzung, die auf der Grundlage von d (z12, z23) berechnet wird und sich iterativ von unten nach oben ausbreitet und in jeder Iteration verdoppelt wird. Die Schätzung für den Scheitelpunkt ist die absolute Differenz seiner Schätzungen von z12 und z23 (daher differenziell). z2 erhält eine Punktzahl von 0, da es die gemeinsame übergeordnete Entität für z12 und z23 ist. Anmerkungen sind in diesem Fall von geringem Nutzen, um die Unterscheidbarkeit von z12 und z23 sicherzustellen.
Abbildung 6. Differentialverteilung. z12 und z23 repräsentieren das untersuchte Eckpunktpaar. w ist eine Schätzung, die auf der Grundlage von d (z12, z23) berechnet wird und sich iterativ von unten nach oben ausbreitet und in jeder Iteration verdoppelt wird. Die Schätzung für den Scheitelpunkt ist die absolute Differenz seiner Schätzungen von z12 und z23 (daher differenziell). z2 erhält eine Punktzahl von 0, da es die gemeinsame übergeordnete Entität für z12 und z23 ist. Anmerkungen sind in diesem Fall von geringem Nutzen, um die Unterscheidbarkeit von z12 und z23 sicherzustellen.Im weitesten Sinne können die Aufgaben, die wir lösen, auf das Problem des aktiven Lernens zurückgeführt werden. Wir haben uns zum Ziel gesetzt, eine Teilmenge von Beispielen für Anmerkungen zu identifizieren, um ein Trainingsset zu erhalten, das die Lernergebnisse verbessern kann. Einige wesentliche Unterschiede erlauben jedoch nicht die direkte Anwendung klassischer aktiver Lehrmethoden, wie z. B. „Stichprobenunsicherheit“. Während des aktiven Lernens versucht der Schüler, in unserem Fall die NLI-Schnittstelle, normalerweise, die Zuordnung f: X → Y zu untersuchen, wobei X die Eingangsraumprobe ist, die aus einem kleinen Satz markierter und einer großen Anzahl nicht markierter Proben besteht, und Y normalerweise ein Satz Markierungen Klasse.
Der Student bewertet den informativen Wert unbeschrifteter Beispiele und wählt den informativsten aus, um von Crowdsourcing-Mitarbeitern eine Y-Note zu erhalten. Im Rahmen des Problems, das wir lösen, wird das Annotationsproblem jedoch anders gestellt. Wir müssen eine Instanz aus Y, einem großen API-Aufrufraum, auswählen und Crowdsourcing-Mitarbeiter bitten, sie zu kennzeichnen, indem sie Muster in X, dem Satzraum, angeben. Darüber hinaus sind wir nicht an einen bestimmten Auszubildenden gebunden. Daher schlagen wir eine neue Lösung für das vorliegende Problem vor. Wir lassen uns von zahlreichen Quellen zum aktiven Lernen inspirieren.
Zunächst bestimmen wir das Ziel, anhand dessen der Informationsgehalt der Knoten ausgewertet wird. Natürlich möchten wir, dass verschiedene API-Aufrufe unterscheidbar sind. Im semantischen Netzwerk bedeutet dies, dass die Verteilung
Unterschiedliche Peaks weisen offensichtliche Unterschiede auf. Zunächst präsentieren wir jede Distribution
wie ein n-dimensionaler Vektor

wobei n = |
| - die Größe des Wörterbuchs. Mit einer bestimmten Metrik des Vektorabstands d (in unseren Experimenten verwenden wir den Abstand zwischen den Vektoren pL1) meinen wir

Das heißt, der Abstand zwischen zwei Eckpunkten ist gleich dem Abstand zwischen ihren Verteilungen.
Das offensichtliche Ziel besteht darin, den Gesamtabstand zwischen allen Scheitelpunktpaaren zu maximieren. Die Optimierung aller paarweisen Abstände kann jedoch für Berechnungen zu kompliziert sein, und selbst dies ist nicht erforderlich. Ein Paar entfernter Spitzen weist bereits genügend Unterschiede auf, sodass eine weitere Erhöhung der Entfernung keinen Sinn ergibt. Stattdessen können wir uns auf die Eckpunktpaare konzentrieren, die am meisten Verwirrung stiften, dh der Abstand zwischen ihnen ist am geringsten.
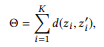
wo
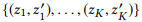
zeigt auf die ersten K Eckpunktpaare, wenn wir alle Knotenpaare nach Entfernung in aufsteigender Reihenfolge ordnen.
Algorithmus 2. Kommentieren Sie ein semantisches Netz iterativ mit einer Richtlinie Algorithmus 3. Berechnen Sie die Richtlinie basierend auf der differentiellen Ausbreitung
Algorithmus 3. Berechnen Sie die Richtlinie basierend auf der differentiellen Ausbreitung Algorithmus 4. Propagieren Sie eine Punktzahl rekursiv von einem Quellknoten auf alle übergeordneten Knoten
Algorithmus 4. Propagieren Sie eine Punktzahl rekursiv von einem Quellknoten auf alle übergeordneten Knoten
Scheitelpunkte mit höherem Informationsgehalt nach der Annotation erhöhen möglicherweise den Wert von Θ. Zur Quantifizierung in diesem Fall schlagen wir die Verwendung einer Differenzverteilungsstrategie vor. Wenn der Abstand zwischen einem Scheitelpunktpaar klein ist, untersuchen wir alle übergeordneten Scheitelpunkte: Wenn der übergeordnete Scheitelpunkt für ein Scheitelpunktpaar gleich ist, sollte er eine niedrige Bewertung erhalten, da Anmerkungen für beide Scheitelpunkte zu ähnlichen Änderungen führen.
Andernfalls muss der Scheitelpunkt hoch bewertet werden. Je näher das Scheitelpunktpaar ist, desto höher ist die Bewertung. Wenn beispielsweise der Abstand zwischen den Scheitelpunkten von "ungelesenen E-Mails zur Promotion" und "Wie viele E-Mails zur Promotion" gering ist, ist das Kommentieren des übergeordneten Scheitelpunkts "E-Mails zur Promotion" unter dem Gesichtspunkt der Unterscheidung dieser Scheitelpunkte nicht sehr sinnvoll. Es ist ratsamer, übergeordnete Knoten mit Anmerkungen zu versehen, die ihnen nicht gemeinsam sind: "ungelesene E-Mails" und "wie viele E-Mails".
Ein Beispiel für eine solche Situation ist in Abbildung 6 dargestellt. Der Algorithmus ist Algorithmus 3. Als Schätzung nehmen wir den Kehrwert der durch eine Konstante begrenzten Knotenentfernung (Linie 6), sodass die nächsten Eckpunktpaare den größten Einfluss haben. Wenn Sie mit einem Scheitelpunktpaar arbeiten, weisen wir allen übergeordneten Scheitelpunkten gleichzeitig eine Bewertung jedes Scheitelpunkts zu (Zeile 9, 10 und Algorithmus 4). Eine Schätzung eines nicht kommentierten Scheitelpunkts ist die absolute Differenz der Schätzungen des entsprechenden Scheitelpunktpaars mit Summation über alle Scheitelpunktpaare (Zeile 12).
Schnittstelle in natürlicher Sprache
Um den vorgeschlagenen Rahmen zu bewerten, müssen die NL2API-Modelle anhand der gesammelten Daten trainiert werden. Derzeit ist das fertige NL2API-Modell nicht verfügbar. Wir passen jedoch zwei getestete NLI-Modelle aus anderen Bereichen an, um sie auf die API anzuwenden.
Sprachmodell-Extraktionsmodell
Basierend auf den jüngsten Entwicklungen auf dem Gebiet des NLI für Wissensdatenbanken können wir die Schaffung von NL2API im Kontext des Problems der Informationsextraktion in Betracht ziehen, um das auf dem Sprachmodell (LM) basierende Extraktionsmodell an unsere Bedingungen anzupassen.
Um u zu sagen, müssen Sie einen API z-Aufruf im semantischen Netzwerk finden, der am besten zu u passt. Zuerst transformieren wir die Verteilung von BoB

jeder Aufruf der API z an das Sprach-Unigramm-Modell:
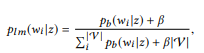
wo wir additive Glättung verwenden und 0 ≤ β ≤ 1 der Glättungsparameter ist. Höherer Wert
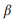
Je größer das Gewicht der Wörter ist, die noch nicht analysiert wurden. API-Aufrufe können nach ihrer logarithmischen Wahrscheinlichkeit eingestuft werden:
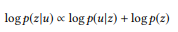
(vorbehaltlich einer einheitlichen a priori Wahrscheinlichkeitsverteilung)
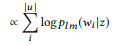
Der API-Aufruf mit der höchsten Bewertung wird als Simulationsergebnis verwendet.
Seq2Seq-Umformulierungsmodul
Neuronale Netze werden als Modelle für NLI immer weiter verbreitet, während das Seq2Seq-Modell für diesen Zweck besser ist als die anderen, da Sie auf natürliche Weise Eingabe- und Ausgabesequenzen variabler Länge verarbeiten können. Wir passen dieses Modell für NL2API an.
Für die Eingabesequenz e

Das Modell schätzt die bedingte Wahrscheinlichkeitsverteilung p (y | x) für alle möglichen Ausgabesequenzen
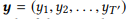
. Die Längen T und T 'können variieren und einen beliebigen Wert annehmen. In NL2API ist x die Ausgabeanweisung. y kann ein serialisierter API-Aufruf oder sein kanonischer Befehl sein. Wir werden kanonische Befehle als Zielausgabesequenzen verwenden, was unser Problem tatsächlich in ein Umformulierungsproblem verwandelt.
Ein Encoder, der als wiederkehrendes neuronales Netzwerk (RNN) mit gesteuerten Wiederholungseinheiten (GRU) implementiert ist, repräsentiert zuerst x als einen Vektor fester Größe.

Dabei ist RN N eine kurze Darstellung zum Anwenden von GRU auf die gesamte Eingabesequenz, Marker für Marker, gefolgt von der Ausgabe des letzten verborgenen Zustands.
Der Decodierer, der auch ein RNN mit GRU ist, nimmt h0 als Anfangszustand und verarbeitet die Ausgangssequenz y Marker für Marker, um eine Sequenz von Zuständen zu erzeugen.

Die Ausgabeschicht nimmt jeden Decoderzustand als Eingabewert und generiert eine Wörterbuchverteilung
als Ausgabewert. Wir verwenden nur die affine Transformation, gefolgt von der Multi-Variablen-Logistikfunktion softmax:
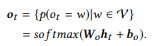
Die endgültige bedingte Wahrscheinlichkeit, mit der wir bewerten können, wie gut der kanonische Befehl y die Eingabeanweisung x umformuliert, ist

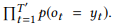
. API-Aufrufe werden dann nach der bedingten Wahrscheinlichkeit ihres kanonischen Befehls eingestuft. Wir empfehlen Ihnen, sich mit der Quelle vertraut zu machen, in der der Modelllernprozess ausführlicher beschrieben wird.
Experimente
Experimentell untersuchen wir die folgenden Forschungsthemen: [PI1]: Können wir den vorgeschlagenen Rahmen verwenden, um qualitativ hochwertige Trainingsdaten zu einem angemessenen Preis zu sammeln? [PI2]: Bietet das semantische Netzwerk eine genauere Bewertung von Sprachmodellen als die Bewertung der maximalen Wahrscheinlichkeit? [PI3]: Verbessert eine differenzierte Vertriebsstrategie die Crowdsourcing-Effizienz?
Crowdsourcing
-API Microsoft — GET-Events GET-Messages — . API, API ( 3.1) . API 2. , Amazon Mechanical Turk. , API .
. API 10 , 10 . 201 , . 44 , 82 , 8,2 , , , . , 400 , 17,4 %.
(, ORDERBY a COUNT parameter) (, , ). . NLI. , , [1] . .
, , , , API (. 3). API . , . 61 API 157 GET-Messages, 77 API 190 GET-Events. , , API (, ) , , .
 2. API.
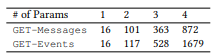
2. API. 3. : ().
3. : ()., , . , α = 0,3, LM β = 0,001. K, , 100 000. , , Seq2Seq — 500. ( ).
NLI, . .
. , , . LM: , . , . ROOT — . TOP2 = ROOT + 2; TOP3 = TOP2 + 3. .
4. LM (MLE) ,
, . , , , MLE .
MLE,

,

- , . API . 16 API (ROOT) LM SeMesh Seq2Seq API (TOP2) , 500 API (TOP3).
, , , , ( 3.2) . , GET-Events , GET-Messages. , GET-Events
, , , .
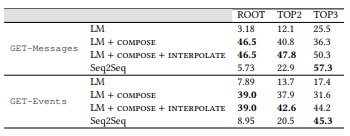 4. . LM, Seq2Seq, . , .
4. . LM, Seq2Seq, . , .LM + , ,
θem with
.
und
, , ROOT,
und
. , , . MLE. , , [2] .
0,45 0,6: , NLI . , API. API (. 7) , RNN , . .
. : |u | α. - LM ( 7). , |u | < 10, 10 . GET-Events, GET-Messages .
, , , . , , . , α, ([0.1, 0.7]). α , , .
(DP) . API . 50 API, , NL2API .
, . LM, . . , ( 5.1), API .
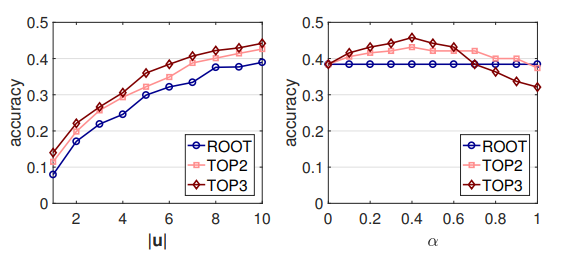
7. .
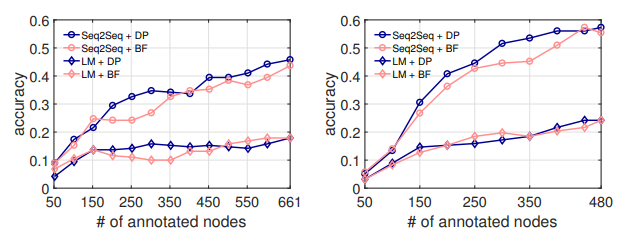
8. . : GET-Events. : GET-Messages
breadth first (BF), . . . API , API .
8. NL2API API DP . 300 API, Seq2Seq, DP 7 % API. , . , DP API, NL2API. , , [3] .
- . - (NLI) . NLI . , , . .
NLI , -, API . NL2API : API , - , . . API REST .
NLI. NLI « ». , Google Suggest API, API IFTTT. NLI, . , .
NLI, . NLI , . , , .
API . , -API. .
-API. , -API. , -API API, -API . NL2API , , API.
- -API (NL2API) NL2API . NL2API . : (1) . , , ? (2) .
? (3) NL2API. , API. (4) API. API? (5) : NL2API ?