Wie kann ich einen fortlaufenden Strom von Nachrichten von Twitter mit ein paar Codezeilen drucken, indem ich Wetterdaten zu den Orten hinzufüge, an denen ihre Autoren leben? Und wie können Sie die Geschwindigkeit von Anfragen an den Wetteranbieter begrenzen, damit dieser uns nicht auf die schwarze Liste setzt?
Heute erklären wir Ihnen, wie es geht, aber zuerst lernen wir die Akka Streams-Technologie kennen, die das Arbeiten mit Echtzeitdatenströmen so einfach macht wie das Programmieren mit LINQ-Ausdrücken, ohne dass einzelne Akteure oder Reactive Streams-Schnittstellen implementiert werden müssen .
Der Artikel basiert auf einer Abschrift des
Berichts von Vagif Abilov von unserer Dezember-Konferenz DotNext 2017 in Moskau.
Mein Name ist Vagif, ich arbeite für die norwegische Firma Miles. Heute werden wir über die Akka Streams-Bibliothek sprechen.
Akka und Reactive Streams sind der Schnittpunkt ziemlich enger Mengen, und man könnte den Eindruck gewinnen, dass dies eine solche Nische ist, dass man einige große Kenntnisse haben muss, um einzutreten, aber genau das Gegenteil. Dieser Artikel soll zeigen, dass Sie durch die Verwendung von Akka-Streams die einfache Programmierung vermeiden können, die bei der Verwendung von Reactive Streams und Akka.NET erforderlich ist. Mit Blick auf die Zukunft kann ich sofort sagen: Wenn wir zu Beginn unseres Projekts, für das wir Akka verwenden, von der Existenz von Akka Streams wüssten, würden wir viel anders schreiben, wir würden sowohl Zeit als auch Code sparen.
"Vielleicht ist das Schlimmste, was Sie tun können, Menschen, die keine Schmerzen haben, dazu zu bringen, Ihr Aspirin einzunehmen."
Max Kreminski
"Geschlossene Türen, Kopfschmerzen und intellektuelle Bedürfnisse"
Bevor wir auf die technischen Details eingehen, ein wenig darüber, wie sich Ihr Weg zu Akka Streams herausstellen könnte und was Sie dorthin führen kann. Eines Tages stieß ich auf Max Kreminskis Blog, in dem er Programmierern eine solche philosophische Frage stellte: Wie oder warum ist es für einen Programmierer unmöglich zu erklären, was Monaden sind. Er erklärte es so: Sehr oft gehen die Leute sofort zu den technischen Details und erklären, wie schön funktionale Programmierung ist und wie viel Sinn in der Monade steckt, ohne sich zu fragen, warum der Programmierer sie überhaupt braucht. Wenn man eine Analogie zieht, ist es so, als würde man versuchen, Aspirin zu verkaufen, ohne herauszufinden, ob Ihr Patient Schmerzen hat.
Mit dieser Analogie möchte ich die folgende Frage stellen: Wenn Akka Streams Aspirin ist, was sollte dann der Schmerz sein, der Sie dazu führen wird?
Datenströme
Lassen Sie uns zunächst über Datenströme sprechen. Die Strömung kann recht einfach und linear sein.
Hier haben wir einen bestimmten Datenkonsumenten (ein Kaninchen im Video). Es verbraucht Daten mit einer Geschwindigkeit, die zu ihm passt. Dies ist die ideale Interaktion des Verbrauchers mit dem Stream: Sie legt die Bandbreite fest und die Daten fließen leise dorthin. Dieser einfache Datenstrom kann unendlich sein oder enden.
Der Fluss kann jedoch komplexer sein. Wenn Sie mehrere Kaninchen nebeneinander pflanzen, haben wir bereits eine Parallelisierung der Flüsse. Was Reactive Streams zu lösen versucht, ist genau, wie wir mit Strömungen auf einer konzeptionelleren Ebene kommunizieren können, d. H. Unabhängig davon, ob es sich nur um eine Art Temperatursensormessung handelt, bei der lineare Messungen eingehen oder wir haben kontinuierliche Messungen von Tausenden von Temperatursensoren, die über RabbitMQ-Warteschlangen in das System gelangen und in Systemprotokollen gespeichert werden. Alle oben genannten können als ein zusammengesetzter Strom betrachtet werden. Wenn Sie noch weiter gehen, kann das automatisierte Produktionsmanagement (z. B. durch einen Online-Shop) auch auf einen Datenstrom reduziert werden, und es wäre großartig, wenn wir über die Planung eines solchen Stroms sprechen könnten, egal wie kompliziert er ist.

Für moderne Projekte ist die Thread-Unterstützung nicht sehr gut. Wenn ich mich richtig erinnere, wollte Aaron Stannard, dessen Tweet Sie auf dem Bild sehen, einen Stream einer Multi-Gigabyte-Datei mit CSV erhalten, d. H. Es stellte sich heraus, dass es nichts gibt, das Sie sofort ausführen und verwenden können, ohne eine Reihe zusätzlicher Aktionen. Aber er konnte einfach keinen Strom von CSV-Werten bekommen, was ihn traurig machte. Es gibt nur wenige Lösungen (mit Ausnahme einiger spezieller Bereiche), viel wird durch die alten Methoden realisiert. Wenn wir all dies öffnen, mit dem Lesen beginnen und puffern, erhalten wir im schlimmsten Fall so etwas wie einen Notizblock, der besagt, dass die Datei zu groß ist.
Auf einer hohen konzeptionellen Ebene beschäftigen wir uns alle mit der Verarbeitung von Datenströmen, und Akka Streams hilft Ihnen, wenn:
- Sie sind mit Akka vertraut, möchten sich aber die Details ersparen, die mit dem Schreiben von Schauspielercode und deren Koordination verbunden sind.
- Sie sind mit Reactive Streams vertraut und möchten eine vorgefertigte Implementierung ihrer Spezifikation verwenden.
- Akka Streams-Blockelemente für Stufen eignen sich zur Modellierung Ihres Prozesses.
- Sie möchten den Gegendruck (Gegendruck) von Akka Streams nutzen, um die Durchsatzstufen Ihres Workflows zu verwalten und dynamisch zu verfeinern.
Von Schauspielern zu Akka Streams

Der erste Weg führt von Schauspielern zu Akka Streams, mein Weg.
Das Bild zeigt, warum wir das Schauspielermodell verwendet haben. Wir waren erschöpft von der manuellen Steuerung der Flüsse, dem gemeinsamen Zustand, das ist alles. Jeder, der mit großen Systemen mit Multithread-Systemen gearbeitet hat, weiß, wie viel Zeit dies kostet und wie einfach es ist, Fehler zu machen, die für den gesamten Prozess fatal sein können. Dies führte uns zum Modell der Schauspieler. Wir bedauern die getroffene Entscheidung nicht, aber wenn Sie anfangen zu arbeiten und mehr zu programmieren, weicht die anfängliche Begeisterung natürlich nicht etwas anderem, sondern Sie erkennen, dass etwas noch effektiver gemacht werden kann.
„Standardmäßig werden Empfänger ihrer Nachrichten in den Code der Akteure eingetragen. Wenn ich einen Schauspieler A erstelle, der eine Nachricht an Schauspieler B sendet, und Sie den Empfänger durch Schauspieler C ersetzen möchten, funktioniert dies im Allgemeinen nicht für Sie. “
Noel Welch (underscore.io)
Schauspieler kritisiert, weil sie nicht komponiert haben. Einer der ersten, der in seinem Blog darüber schrieb, war Noel Welch, einer der Entwickler von Underscore. Er bemerkte, dass das System der Schauspieler ungefähr so aussieht:

Wenn Sie keine zusätzlichen Dinge wie die Abhängigkeitsinjektion verwenden, wird die Adresse des Empfängers in den Akteur eingenäht.

Wenn sie anfangen, sich gegenseitig Nachrichten zu senden, programmieren Sie die Akteure im Voraus. Und ohne zusätzliche Tricks wird ein solches starres System erhalten.
Einer der Entwickler von Akka, Roland Kuhn,
erklärte, was im Allgemeinen unter schlechtem Layout zu verstehen ist. Die Basis für das Senden von Akteursnachrichten ist die Tell-Methode, dh unidirektionale Nachrichten: Sie ist vom Typ void, dh sie gibt je nach Sprache nichts (oder keine Einheit) zurück. Daher ist es unmöglich, aus einer Kette von Akteuren eine Beschreibung des Prozesses zu erstellen. Also hast du Tell geschickt, was dann? Hör auf Wir wurden nichtig. Sie können es beispielsweise mit LINQ-Ausdrücken vergleichen, bei denen jedes Element des Ausdrucks IQueryable, IEnumerable zurückgibt und all dies einfach kompiliert werden kann. Schauspieler geben keine solche Gelegenheit. Gleichzeitig beanstandete Roland Kuhn die Tatsache, dass sie, wie sie sagen, nicht im Prinzip komponieren, sondern dass sie tatsächlich auf andere Weise zusammengestellt werden, in dem Sinne, in dem sich die menschliche Gesellschaft für das Layout eignet. Es klingt wie ein philosophisches Argument, aber wenn Sie darüber nachdenken, macht die Analogie Sinn - ja, die Schauspieler senden sich gegenseitig unidirektionale Botschaften, aber wir kommunizieren auch miteinander und sprechen unidirektionale Botschaften aus, aber gleichzeitig interagieren wir ziemlich effektiv, dh wir schaffen komplexe Systeme. Trotzdem gibt es eine solche Kritik an den Akteuren.
public class SampleActor : ReceiveActor { public SampleActor() { Idle(); } protected override void PreStart() { } private void Idle() { Receive<Job>(job => ); } private void Working() { Receive<Cancel>(job => ); } }
Darüber hinaus erfordert die Implementierung des Akteurs mindestens das Schreiben einer Klasse, wenn Sie in C # arbeiten, oder Funktionen, wenn Sie in F # arbeiten. Im obigen Beispiel - Boilerplate-Code, den Sie auf jeden Fall schreiben müssen. Obwohl es nicht sehr groß ist, ist es eine bestimmte Anzahl von Zeilen, die Sie immer auf dieser niedrigen Ebene schreiben müssen. Fast der gesamte Code, der hier vorhanden ist, ist eine Art Zeremonie. Was passiert, wenn ein Schauspieler direkt eine Nachricht empfängt, wird hier überhaupt nicht angezeigt. Und das alles muss geschrieben werden. Dies ist natürlich nicht sehr viel, aber dies ist ein Beweis dafür, dass wir mit Akteuren auf niedriger Ebene zusammenarbeiten und solche nichtigen Methoden entwickeln.
Was wäre, wenn wir auf eine andere, höhere Ebene gehen und uns Fragen zur Modellierung unseres Prozesses stellen könnten, einschließlich der Verarbeitung von Daten aus verschiedenen Quellen, die gemischt, konvertiert und übertragen werden?
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
Ein Analogon zu diesem Ansatz kann das sein, was wir alle seit zehn Jahren an LINQ gewöhnt sind. Wir wundern uns nicht, wie Join funktioniert. Wir wissen, dass es einen solchen LINQ-Anbieter gibt, der all dies für uns erledigt, und wir sind auf einer höheren Ebene daran interessiert, die Anfrage zu erfüllen. Und wir können hier im Allgemeinen Datenbanken mischen, wir können Verteilungsanfragen senden. Was wäre, wenn Sie den Prozess so beschreiben könnten?
HttpGet pageUrl |> fun s -> Regex.Replace(s, "[^A-Za-z']", " ") |> fun s -> Regex.Split(s, " +") |> Set.ofArray |> Set.filter (fun word -> not (Spellcheck word)) |> Set.iter (fun word -> printfn " %s" word)
(Quelle)Oder zum Beispiel funktionale Transformationen. Was viele Leute an der funktionalen Programmierung mögen, ist, dass Sie Daten durch eine Reihe von Transformationen leiten können und einen ziemlich klaren kompakten Code erhalten, unabhängig davon, in welcher Sprache Sie ihn schreiben. Es ist leicht zu lesen. Der Code auf dem Bild ist speziell in F # geschrieben, aber im Allgemeinen versteht wahrscheinlich jeder, was hier passiert.
val in = Source(1 to 10) val out = Sink.ignore val bcast = builder.add(Broadcast[Int](2)) val merge = builder.add(Merge[Int](2)) val f1,f2,f3,f4 = Flow[Int].map(_ + 10) source ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> sink bcast ~> f4 ~> merge ~>
(Quelle)Wie wäre es dann damit? Im obigen Beispiel haben wir eine Quellendatenquelle, die aus Ganzzahlen von 1 bis 10 besteht. Dies ist die sogenannte grafische DSL (domänenspezifische Sprache). Die Elemente der Domänensprache im obigen Beispiel sind unidirektionale Pfeilsymbole. Dies sind zusätzliche Operatoren, die von Sprachwerkzeugen definiert werden, die die Richtung des Streams grafisch anzeigen. Wir durchlaufen Source durch eine Reihe von Transformationen - zur Vereinfachung der Demonstration addieren alle nur eine Zehn zur Zahl. Als nächstes kommt Broadcast: Wir multiplizieren die Kanäle, dh jede Zahl gibt zwei Kanäle ein. Dann addieren wir erneut 10, mischen unsere Datenströme, erhalten einen neuen Stream, fügen ebenfalls 10 hinzu, und all dies geht in unseren Datenstrom, in dem nichts passiert. Dies ist der eigentliche Code, der in Scala, einem Teil von Akka Streams, geschrieben und in dieser Sprache implementiert ist. Das heißt, Sie geben die Phasen der Transformation Ihrer Daten an, geben an, was mit ihnen zu tun ist, geben die Quelle, den Bestand und einige Prüfpunkte an und erstellen dann mithilfe der grafischen DSL ein solches Diagramm. Dies ist alles Code für ein einzelnes Programm. Einige Codezeilen zeigen, was dabei vor sich geht.
Vergessen wir, wie der Definitionscode für einzelne Akteure geschrieben wird, und lernen stattdessen die übergeordneten Layout-Grundelemente, mit denen die erforderlichen Akteure in sich selbst erstellt und verbunden werden. Wenn wir ein solches Diagramm ausführen, erstellt das System, das Akka Streams bereitstellt, den erforderlichen Akteur selbst, sendet alle diese Daten dorthin, verarbeitet sie wie gewünscht und gibt sie schließlich an den endgültigen Empfänger weiter.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
Das obige Beispiel zeigt, wie dies in C # aussehen könnte. Der einfachste Weg: Wir haben eine Datenquelle - dies sind Zahlen von 1 bis 1000 (wie Sie sehen können, kann in Akka Streams jede IEnumerable zu einer Quelle des Datenflusses werden, was sehr praktisch ist). Wir führen eine einfache Berechnung durch, beispielsweise multiplizieren wir mit zwei, und dann wird im Datenstrom all dies auf dem Bildschirm angezeigt.
var graph = GraphDsl.Create(builder => { var bcast = builder.Add(new Broadcast<int>(2)); var merge = builder.Add(new Merge<int, int>(2)); var count = Flow.FromFunction(new Func<int, int>(x => 1)); var sum = Flow.Create<int>().Sum((x, y) => x + y); builder.From(bcast.Out(0)).To(merge.In(0)); builder.From(bcast.Out(1)).Via(count).Via(sum).To(merge.In(1)); return new FlowShape<int, int>(bcast.In, merge.Out); });
Was im obigen Beispiel gezeigt wird, wird als "grafisches DSL in C #" bezeichnet. Tatsächlich gibt es hier keine Grafiken, es ist ein Port mit Scala, aber in C # gibt es keine Möglichkeit, Operatoren auf diese Weise zu definieren. Daher sieht es etwas umständlicher aus, ist aber dennoch kompakt genug, um zu verstehen, was hier passiert. Wir erstellen also ein bestimmtes Diagramm (es gibt verschiedene Arten von Diagrammen, hier wird es FlowShape genannt) aus verschiedenen Komponenten, in denen es eine Datenquelle und einige Transformationen gibt. Wir senden Daten an einen Kanal, in dem wir die Anzahl generieren, dh die Anzahl der zu übertragenden Datenelemente, und in dem anderen generieren wir die Summe und mischen dann alles. Als nächstes sehen wir interessantere Beispiele als nur die Verarbeitung von ganzen Zahlen.
Dies ist der erste Pfad, der Sie zu Akka Streams führen kann, wenn Sie Erfahrung mit einem Schauspieler-Modell haben und darüber nachgedacht haben, ob Sie jeden manuell schreiben sollen, selbst den einfachsten Schauspieler. Der zweite Weg, zu dem Akka Streams kommen, sind reaktive Streams.
Von reaktiven Streams zu Akka-Streams
Was sind
reaktive Streams ? Dies ist eine gemeinsame Initiative zur Entwicklung eines Standards für die asynchrone Verarbeitung von Datenströmen. Es definiert den Mindestsatz an Schnittstellen, Methoden und Protokollen, die die zur Erreichung des Ziels erforderlichen Vorgänge und Entitäten beschreiben - die asynchrone Verarbeitung von Daten in Echtzeit mit nicht blockierendem Gegendruck (Gegendruck). Es ermöglicht verschiedene Implementierungen mit verschiedenen Programmiersprachen.
Mit Reactive Streams können Sie eine möglicherweise unbegrenzte Anzahl von Elementen in einer Sequenz verarbeiten und Elemente asynchron zwischen Komponenten mit nicht blockierendem Gegendruck übertragen.
Die Liste der Initiatoren für die Erstellung von Reactive Streams ist beeindruckend: Hier sind Netflix, Oracle und Twitter.
Die Spezifikation ist sehr einfach, um die Implementierung in verschiedenen Sprachen und Plattformen so zugänglich wie möglich zu machen. Die Hauptkomponenten der Reactive Streams-API:
- Herausgeber
- Abonnent
- Abonnement
- Prozessor
Im Wesentlichen bedeutet diese Spezifikation nicht, dass Sie manuell mit der Implementierung dieser Schnittstellen beginnen. Es versteht sich, dass es einige Bibliotheksentwickler gibt, die dies für Sie tun. Und Akka Streams ist eine der Implementierungen dieser Spezifikation.
public interface IPublisher<out T> { void Subscribe(ISubscriber<T> subscriber); } public interface ISubscriber<in T> { void OnSubscribe(ISubscription subscription); void OnNext(T element); void OnError(Exception cause); void OnComplete(); }
Die Schnittstellen sind, wie Sie dem Beispiel entnehmen können, wirklich sehr einfach: Beispielsweise enthält Publisher nur eine Methode - "Abonnieren". Der Abonnent Abonnent enthält nur wenige Reaktionen auf das Ereignis.
public interface ISubscription { void Request(long n); void Cancel(); } public interface IProcessor<in T1, out T2> : ISubscriber<T1>, IPublisher<T2> { }
Schließlich enthält das Abonnement zwei Methoden - "Start" und "Ablehnen". Der Prozessor definiert überhaupt keine neuen Methoden, er kombiniert einen Herausgeber und einen Abonnenten.
Was unterscheidet Reactive Streams von anderen Stream-Implementierungen? Reactive Streams kombiniert Push- und Pull-Modelle. Für den Support ist dies das effizienteste Leistungsszenario. Angenommen, Sie haben einen langsamen Datenabonnenten. In diesem Fall kann es fatal sein, auf ihn zu drängen: Wenn Sie ihm eine große Datenmenge senden, kann er diese nicht verarbeiten. Es ist besser, Pull zu verwenden, damit der Abonnent selbst die Daten vom Herausgeber abruft. Wenn der Herausgeber jedoch langsam ist, stellt sich heraus, dass der Abonnent ständig blockiert ist und ständig wartet. Eine Zwischenlösung kann die Konfiguration sein: Wir haben eine Konfigurationsdatei, in der wir bestimmen, welche davon schneller ist. Und wenn sich ihre Geschwindigkeiten ändern?
Die eleganteste Implementierung ist also eine, bei der wir Push- und Pull-Modelle dynamisch ändern können.
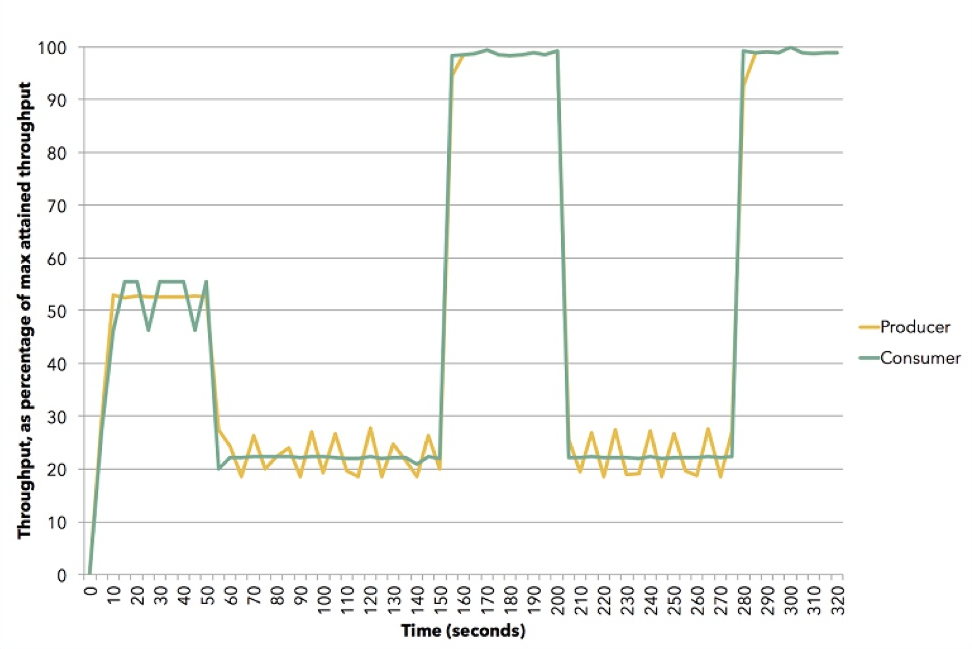 (Quelle (Apache Flink))
(Quelle (Apache Flink))Das Diagramm zeigt, wie dies geschehen kann. Diese Demo verwendet Apache Flink. Yellow ist ein Verlag, Datenproduzent, er wurde auf etwa 50% seiner Fähigkeiten festgelegt. Der Abonnent versucht, die beste Strategie zu wählen - es stellt sich heraus, dass es sich um einen Push handelt. Dann setzen wir den Teilnehmer auf eine Geschwindigkeit von ungefähr 20% zurück und er schaltet auf Ziehen um. Dann gehen wir zu 100%, geben wieder 20% zum Pull-Modell usw. zurück. All dies geschieht in der Dynamik. Sie müssen den Dienst nicht beenden, sondern etwas in die Konfiguration eingeben. Dies ist ein Beispiel dafür, wie der Gegendruck in Akka Streams funktioniert.
Akka Streams Prinzipien
Natürlich würden Akka Streams nicht an Popularität gewinnen, wenn es keine eingebauten Blöcke gäbe, die sehr einfach zu bedienen sind. Es gibt viele von ihnen. Sie sind in drei Hauptgruppen unterteilt:
- Datenquelle (Quelle) - Verarbeitungsstufe mit einer Ausgabe.
- Waschbecken ist ein Verarbeitungsschritt mit einem Eintrag.
- Checkpoint (Flow) - Verarbeitungsstufe mit einem Eingang und einem Ausgang. Funktionale Transformationen finden hier statt und nicht unbedingt im Speicher: Es kann sich beispielsweise um einen Aufruf eines Webdienstes, einiger Parallelitätselemente mit mehreren Threads handeln.
Von diesen drei Typen können Graphen gebildet werden. Dies sind bereits komplexere Verarbeitungsstufen, die aus Quellen, Abflüssen und Kontrollpunkten aufgebaut sind. Es kann jedoch nicht jeder Graph ausgeführt werden: Wenn darin Löcher vorhanden sind, dh offene Ein- und Ausgänge, wird dieser Graph nicht ausgeführt.
Ein Diagramm ist ein ausführbares Diagramm. Wenn es geschlossen ist, dh für jede Eingabe gibt es eine Ausgabe: Wenn die Daten eingegeben wurden, müssen sie irgendwohin gegangen sein.

Akka Streams verfügt über integrierte Quellen: Auf dem Bild sehen Sie, wie viele davon vorhanden sind. Ihre Namen sind eins zu eins und spiegeln wider, was Scala oder die JVM haben, mit Ausnahme einiger .NET-spezifischer nützlicher Quellen. Die ersten beiden (FromEnumerator und From) sind einige der wichtigsten: Jede Nummerierung, jede ienumerable kann in eine Stream-Quelle umgewandelt werden.

Es gibt integrierte Drains: Einige davon ähneln LINQ-Methoden, z. B. First, Last, FirstOrDefault. Natürlich können Sie alles, was Sie erhalten, in Dateien und Streams speichern, nicht in Akka-Streams, sondern in .NET-Streams. Wenn Sie Akteure in Ihrem System haben, können Sie diese sowohl am Eingang als auch am Ausgang des Systems verwenden, dh, wenn Sie möchten, in Ihr fertiges System einbetten.

Und es gibt eine große Anzahl integrierter Checkpoints, die vielleicht noch mehr an LINQ erinnern, denn hier gibt es Select, SelectMany und GroupBy, also alles, womit wir in LINQ arbeiten.
Zum Beispiel heißt Select in Scala SelectAsync: Es ist leistungsfähig genug, da es die Parallelität als eines der Argumente verwendet. Das heißt, Sie können angeben, dass beispielsweise Select Daten in zehn Threads parallel an einen Webdienst sendet. Anschließend werden alle Daten gesammelt und weitergeleitet. Tatsächlich bestimmen Sie den Skalierungsgrad des Prüfpunkts mit einer Codezeile.
Eine Flow-Deklaration ist ihr Ausführungsplan, dh ein Graph, auch ein Run-Plan, kann nicht einfach so ausgeführt werden - er muss materialisiert werden. Es muss ein instanziiertes System geben, ein Akteursystem, Sie müssen ihm einen Stream geben, diesen Ausführungsplan, und dann wird er ausgeführt. Darüber hinaus ist es zur Laufzeit stark optimiert, ähnlich wie beim Senden eines LINQ-Ausdrucks an eine Datenbank: Ein Anbieter kann Ihr SQL für eine effizientere Datenausgabe optimieren und im Wesentlichen den Abfragebefehl durch einen anderen ersetzen. Das Gleiche gilt für Akka Streams: Ab Version 2.0 können Sie eine bestimmte Anzahl von Prüfpunkten festlegen, und das System wird verstehen, dass einige davon kombiniert werden können, sodass sie von einem Akteur ausgeführt werden (Operator Fusion). Checkpoints behalten in der Regel die Reihenfolge der Verarbeitungselemente bei.
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
Die Stream-Materialisierung kann mit dem letzten ToList-Element im LINQ-Ausdruck im obigen Beispiel verglichen werden. Wenn wir keine ToList schreiben, erhalten wir einen nicht materialisierten LINQ-Ausdruck, der nicht dazu führt, dass die Daten an den SQL Server oder Oracle übertragen werden, da die meisten LINQ-Anbieter die sogenannte verzögerte Abfrageausführung (verzögerte Abfrageausführung) unterstützen, t d.h. die Anforderung wird nur ausgeführt, wenn ein Befehl gegeben wird, um ein Ergebnis zu liefern. Je nachdem, was angefordert wird - eine Liste oder das erste Ergebnis - wird das effektivste Team gebildet. Wenn wir ToList sagen, bitten wir den LINQ-Anbieter, uns das fertige Ergebnis zu geben.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
Akka Streams funktioniert genauso. Auf dem Bild sehen Sie unser gestartetes Diagramm, das aus einer Quelle von Prüfpunkten und Abflüssen besteht. Wir möchten es jetzt ausführen.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString)); var system = ActorSystem.Create("MyActorSystem"); using (var materializer = ActorMaterializer.Create(system)) { await runnable.Run(materializer); }
Damit dies geschieht, müssen wir ein System von Akteuren erstellen, in dem sich ein Materialisierer befindet, unser Diagramm an ihn weitergeben und er wird es ausführen. Wenn wir es neu erstellen, wird es erneut ausgeführt, und es können andere Ergebnisse erzielt werden.
Neben der Materialisierung des Flusses, die über den materiellen Teil von Akka Streams spricht, sind die materialisierten Werte zu erwähnen.
var output = new List<int>(); var source1 = Source.From(Enumerable.Range(1, 1000)); var sink1 = Sink.ForEach<int>(output.Add); IRunnableGraph<NotUsed> runnable1 = source1.To(sink1); var source2 = Source.From(Enumerable.Range(1, 1000)); var sink2 = Sink.Sum<int>((x,y) => x + y); IRunnableGraph<Task<int>> runnable2 = source2.ToMaterialized(sink2, Keep.Right);
Wenn wir einen Stream haben, der von der Quelle über die Checkpoints zum Drain fließt, stehen uns diese nicht zur Verfügung, wenn wir keine Zwischenwerte anfordern, da dieser auf die effizienteste Weise ausgeführt wird. Es ist wie eine Black Box. Es kann jedoch für uns interessant sein, einige Zwischenwerte herauszuholen, da an jedem Punkt links einige Werte eingehen, andere Werte rechts herauskommen und Sie ein Diagramm angeben können, um anzugeben, woran Sie interessiert sind. Im obigen Beispiel zeigt uns ein Einlaufdiagramm, in dem NotUsed angegeben ist, dh keine materialisierten Werte. Im Folgenden erstellen wir es mit dem Hinweis, dass auf der rechten Seite des Abflusses, dh nachdem alle Transformationen abgeschlossen wurden, materialisierte Werte ausgegeben werden müssen. Wir erhalten die Diagrammaufgabe - eine Aufgabe, nach deren Abschluss wir ein int erhalten, dh was am Ende dieses Diagramms passiert. Sie können in jedem Absatz angeben, dass Sie eine Art von materialisierten Werten benötigen. All dies wird nach und nach gesammelt.
Um Daten in Akka Streams-Streams zu übertragen oder dort herauszuholen, ist natürlich eine Art Interaktion mit der Außenwelt erforderlich. Eingebettete Quellstufen enthalten eine Vielzahl reaktiver Datenströme:
- Mit Source.FromEnumerator und Source.From können Sie Daten von jeder Quelle übertragen, die IEnumerable implementiert.
- Unfold und UnfoldAsync generieren die Ergebnisse von Funktionsberechnungen, sofern sie Werte ungleich Null zurückgeben.
- FromInputStream transformiert einen Stream.
- FromFile analysiert den Inhalt der Datei in den reaktiven Stream.
- ActorPublisher konvertiert Actor-Nachrichten.
Wie ich bereits sagte, ist es für .NET-Entwickler sehr produktiv, Enumerator oder IEnumerable zu verwenden, aber manchmal ist es eine zu primitive, zu ineffiziente Art, auf Daten zuzugreifen. Komplexere Quellen, die eine große Datenmenge enthalten, erfordern spezielle Konnektoren. Solche Anschlüsse sind geschrieben. Es gibt ein Open-Source-Projekt Alpakka, das ursprünglich in Scala erschien und jetzt in .NET ist. Darüber hinaus verfügt Akka über sogenannte persistente Akteure und über eigene Streams, die verwendet werden können (z. B. bildet die Akka-Persistenzabfrage den Inhaltsfluss des Akka-Ereignisjournals).

Wenn Sie mit Scala arbeiten, ist der einfachste Weg für Sie: Es gibt eine große Anzahl von Anschlüssen, und Sie werden sicherlich etwas nach Ihrem Geschmack finden. Zur Information, Kafka ist das sogenannte Reactive Kafka, nicht Kafka Streams. Kafka Streams unterstützt meines Wissens keinen Gegendruck. Reactive Kafka ist eine Stream-Implementierung von Kafka, die Reactive Streams unterstützt.
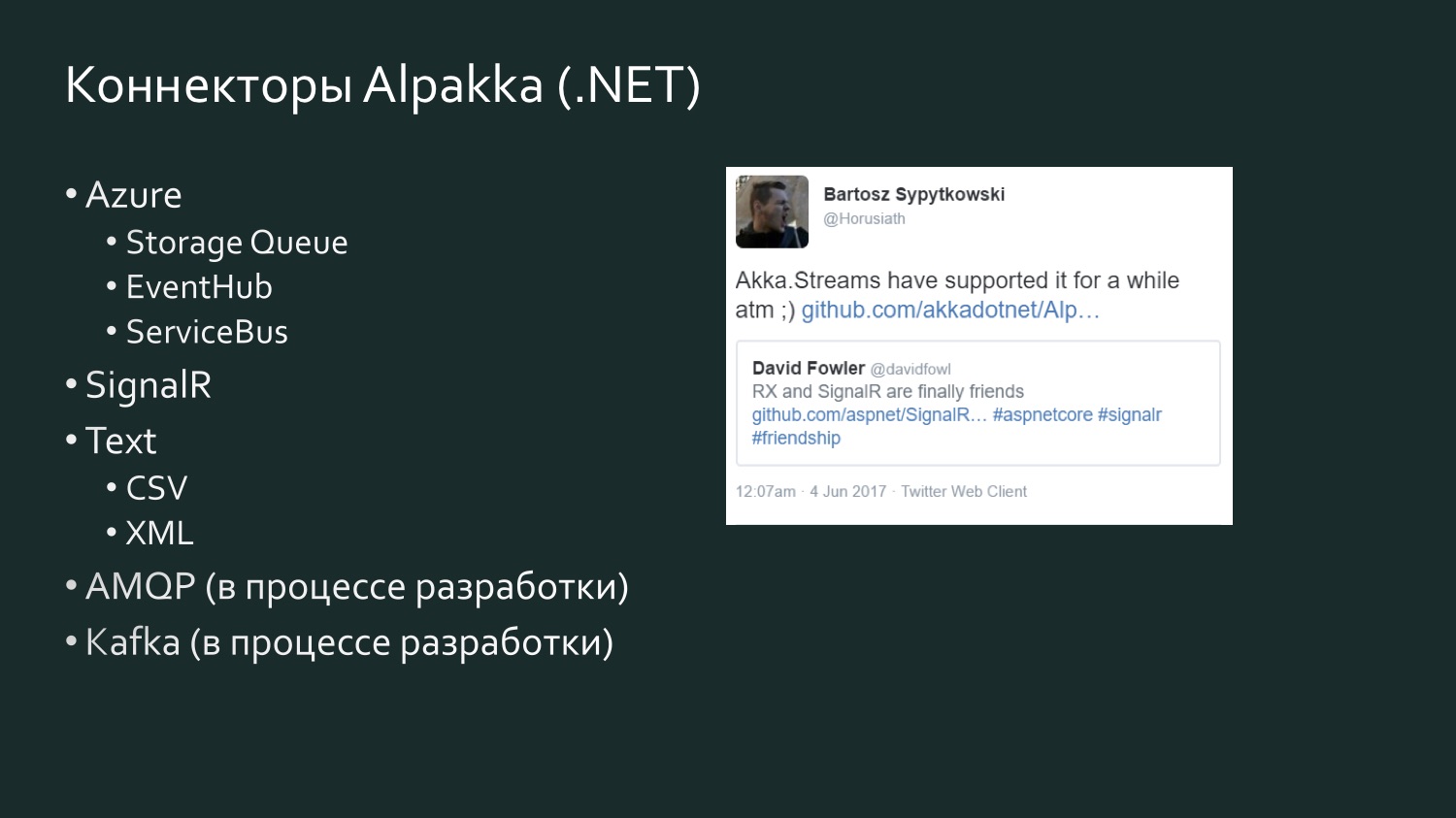
Die Liste der Alpakka .NET-Konnektoren ist bescheidener, wird jedoch aufgefüllt, und es gibt ein Wettbewerbselement. Es gibt einen halbjährigen Tweet von David Fowler von Microsoft, der sagte, dass SignalR jetzt Daten mit Reactive Extensions austauschen kann, und einer der Akka-Entwickler antwortete, dass es tatsächlich seit einiger Zeit in Akka Streams war. Akka unterstützt verschiedene Dienste von Microsoft Azure. CSV ist das Ergebnis von Aaron Stannards Frustration, als er entdeckte, dass es keinen guten Stream für CSV gibt: Jetzt hat Akka einen eigenen Stream für CSV XML. Es gibt AMQP (in Wirklichkeit RabbitMQ), es befindet sich in der Entwicklung, ist aber verfügbar, es funktioniert. Kafka befindet sich ebenfalls in der Entwicklung. Diese Liste wird weiter erweitert.
Ein paar Worte zu den Alternativen, denn wenn Sie mit Datenströmen arbeiten, ist Akka Streams natürlich nicht die einzige Möglichkeit, mit diesen Streams umzugehen. In Ihrem Projekt hängt die Wahl der Implementierung von Threads höchstwahrscheinlich von vielen anderen Faktoren ab, die möglicherweise von entscheidender Bedeutung sind. Wenn Sie beispielsweise viel mit Microsoft Azure arbeiten und Orleans durch die Unterstützung virtueller Akteure oder, wie sie genannt werden, Körner organisch in die Anforderungen Ihres Projekts integriert ist, verfügen sie über eine eigene Implementierung, die nicht der Spezifikation für reaktive Streams entspricht - Orleans Streams es wird für Sie am nächsten sein, und es ist sinnvoll, dass Sie darauf achten. Wenn Sie viel mit TPL arbeiten, gibt es TPL DataFlow - dies ist möglicherweise die engste Analogie zu Akka Streams: Es enthält auch Grundelemente zum Erstellen von Datenströmen sowie Tools zur Pufferung und Bandbreitenbegrenzung (BoundedCapacity, MaxMessagePerTask). Wenn Ihnen die Ideen des Schauspielermodells nahe stehen, können Sie mit Akka Streams dies beheben und viel Zeit sparen, ohne jeden Schauspieler manuell schreiben zu müssen.
Implementierungsbeispiel: Ereignisprotokollstrom
Schauen wir uns einige Implementierungsbeispiele an.
Das erste Beispiel ist nicht die direkte Implementierung eines Streams, sondern die Verwendung eines Streams. Dies war unsere erste Erfahrung mit Akka Streams, als wir entdeckten, dass wir tatsächlich einen Stream abonnieren können, der uns sehr vereinfacht.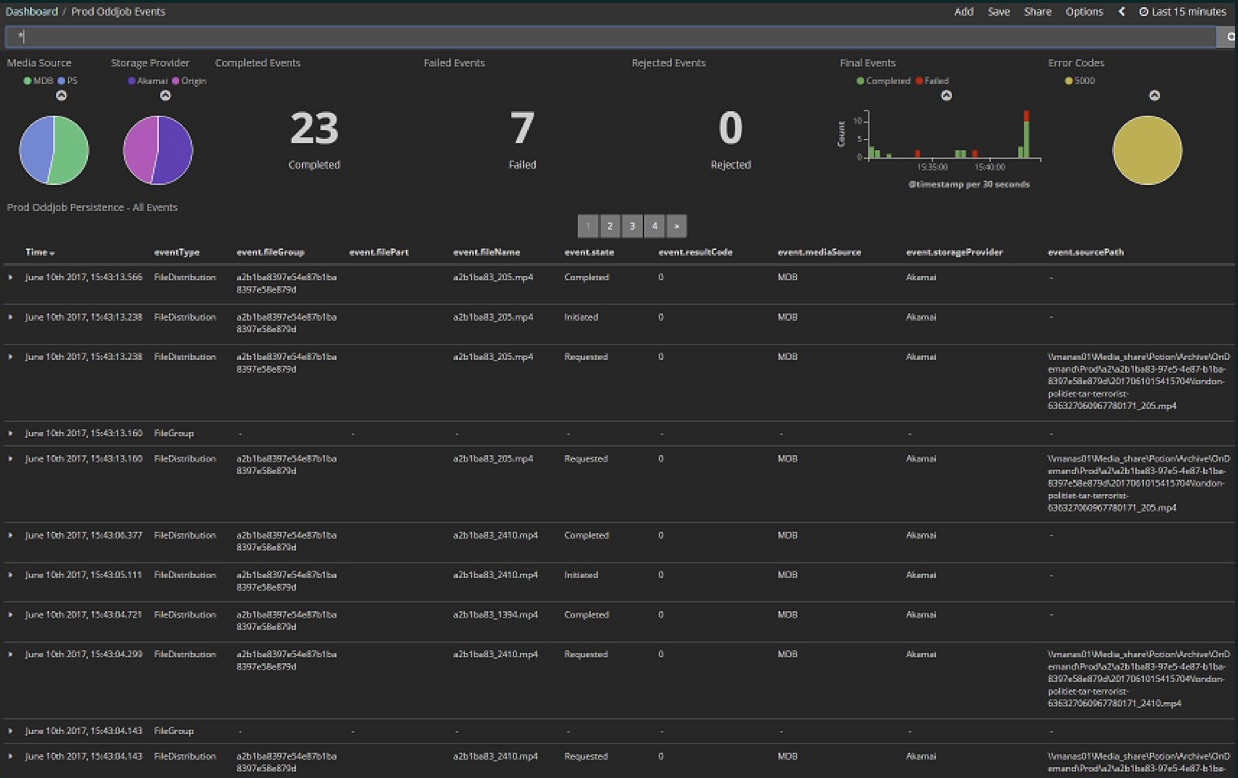 Wir laden verschiedene Mediendateien in die Cloud hoch. Dies war eine frühe Phase des Projekts: hier in den letzten 15 Minuten 23 Dateien, davon 7 Fehler. Jetzt gibt es praktisch keine Fehler mehr und die Anzahl der Dateien ist viel größer - Hunderte gehen alle paar Minuten durch. All dies ist im Kibana Dashboard enthalten.Kibana liest Daten aus Elasticsearch. Da in Elasticsearch eher sekundäre als primäre Daten gespeichert sind, mussten Sie sie bei der Implementierung dieses Indexers löschen und einen Befehl ausgeben, um sie erneut zu füllen. Da sich das Projekt in der Entwicklung befindet, können wir Datenformate ändern und um neue Werte erweitern, d. H. Der Index muss ständig aktualisiert werden. Es wird mit dem Inhalt des Ereignisjournals Akka aufgefüllt, das in der Microsoft SQL Server-Datenbank gespeichert ist. Sowohl zuvor gespeicherte Ereignisse als auch Echtzeitereignisse sollten im aktuellen Bedienfeld angezeigt werden.
Wir laden verschiedene Mediendateien in die Cloud hoch. Dies war eine frühe Phase des Projekts: hier in den letzten 15 Minuten 23 Dateien, davon 7 Fehler. Jetzt gibt es praktisch keine Fehler mehr und die Anzahl der Dateien ist viel größer - Hunderte gehen alle paar Minuten durch. All dies ist im Kibana Dashboard enthalten.Kibana liest Daten aus Elasticsearch. Da in Elasticsearch eher sekundäre als primäre Daten gespeichert sind, mussten Sie sie bei der Implementierung dieses Indexers löschen und einen Befehl ausgeben, um sie erneut zu füllen. Da sich das Projekt in der Entwicklung befindet, können wir Datenformate ändern und um neue Werte erweitern, d. H. Der Index muss ständig aktualisiert werden. Es wird mit dem Inhalt des Ereignisjournals Akka aufgefüllt, das in der Microsoft SQL Server-Datenbank gespeichert ist. Sowohl zuvor gespeicherte Ereignisse als auch Echtzeitereignisse sollten im aktuellen Bedienfeld angezeigt werden. CREATE TABLE EventJournal ( Ordering BIGINT IDENTITY(1,1) PRIMARY KEY NOT NULL, PersistenceID NVARCHAR(255) NOT NULL, SequenceNr BIGINT NOT NULL, Timestamp BIGINT NOT NULL, IsDeleted BIT NOT NULL, Manifest NVARCHAR(500) NOT NULL, Payload VARBINARY(MAX) NOT NULL, Tags NVARCHAR(100) NULL CONSTRAINT QU_EventJournal UNIQUE (PersistenceID, SequenceNr) )
Um dies zu erreichen, müssen wir einerseits die Daten aus SQL Server neu schreiben, der einige persistente Akteure des Eventstores enthält. Akka, eventJournal. Das Bild zeigt einen typischen Eventstore.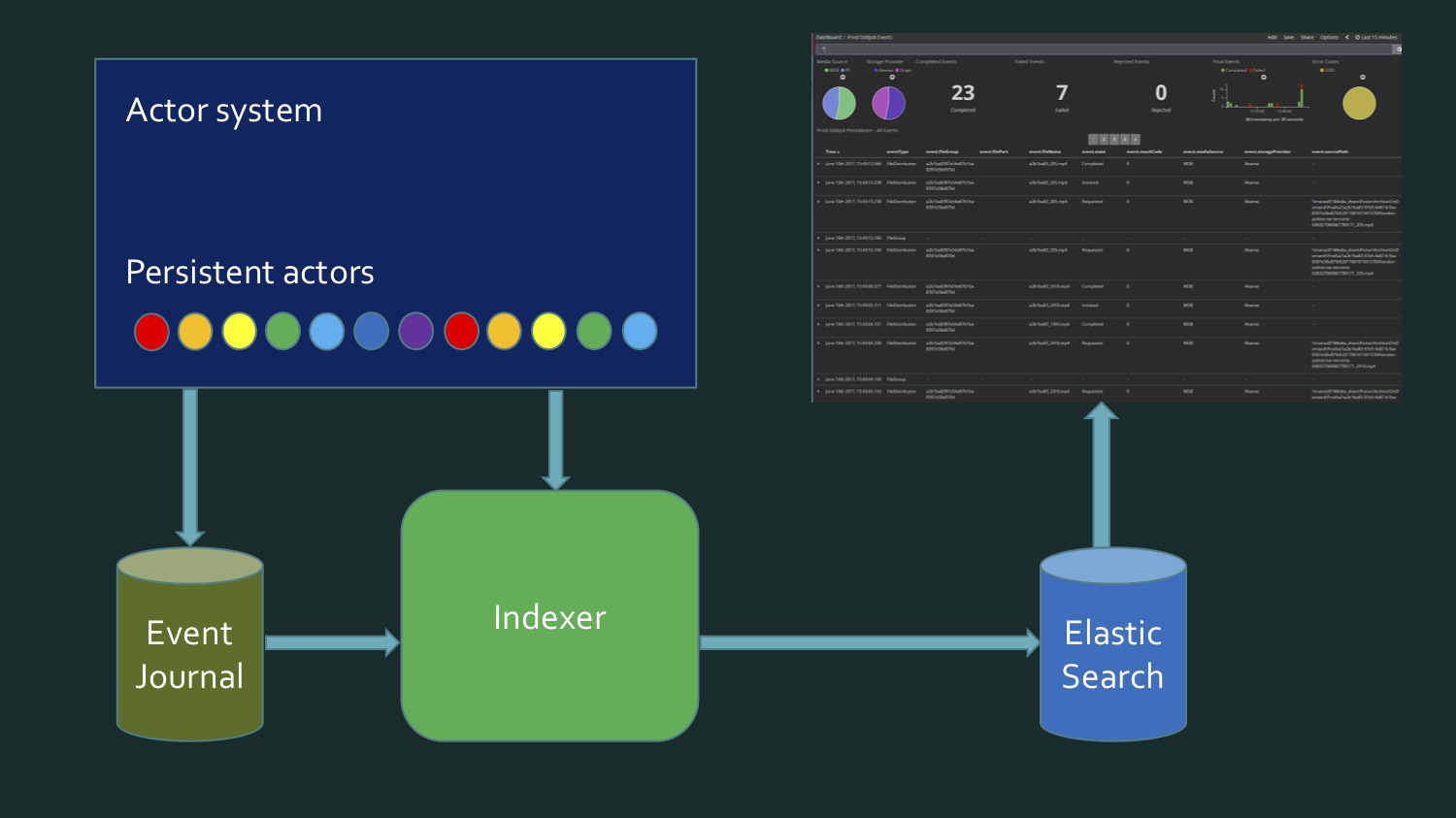 Andererseits kommen die Daten in Echtzeit. Und es stellt sich heraus, dass wir zum Schreiben eines Index Daten aus der Datenbank lesen müssen und Echtzeitdaten eintreffen, und irgendwann müssen wir verstehen: Hier endeten die Daten von hier, das ist neu. Dieser Grenzmoment erfordert eine zusätzliche Überprüfung, um nichts zu verlieren und nichts zweimal aufzuzeichnen. Das heißt, es stellte sich irgendwie ziemlich kompliziert heraus. Mein Kollege und ich waren nicht zufrieden mit dem, was los war. Es ist kein so komplexer Code, nur ziemlich trostlos. Bis wir uns daran erinnerten, dass persistente Akteure in Akka die Persistenzabfrage unterstützen.
Andererseits kommen die Daten in Echtzeit. Und es stellt sich heraus, dass wir zum Schreiben eines Index Daten aus der Datenbank lesen müssen und Echtzeitdaten eintreffen, und irgendwann müssen wir verstehen: Hier endeten die Daten von hier, das ist neu. Dieser Grenzmoment erfordert eine zusätzliche Überprüfung, um nichts zu verlieren und nichts zweimal aufzuzeichnen. Das heißt, es stellte sich irgendwie ziemlich kompliziert heraus. Mein Kollege und ich waren nicht zufrieden mit dem, was los war. Es ist kein so komplexer Code, nur ziemlich trostlos. Bis wir uns daran erinnerten, dass persistente Akteure in Akka die Persistenzabfrage unterstützen.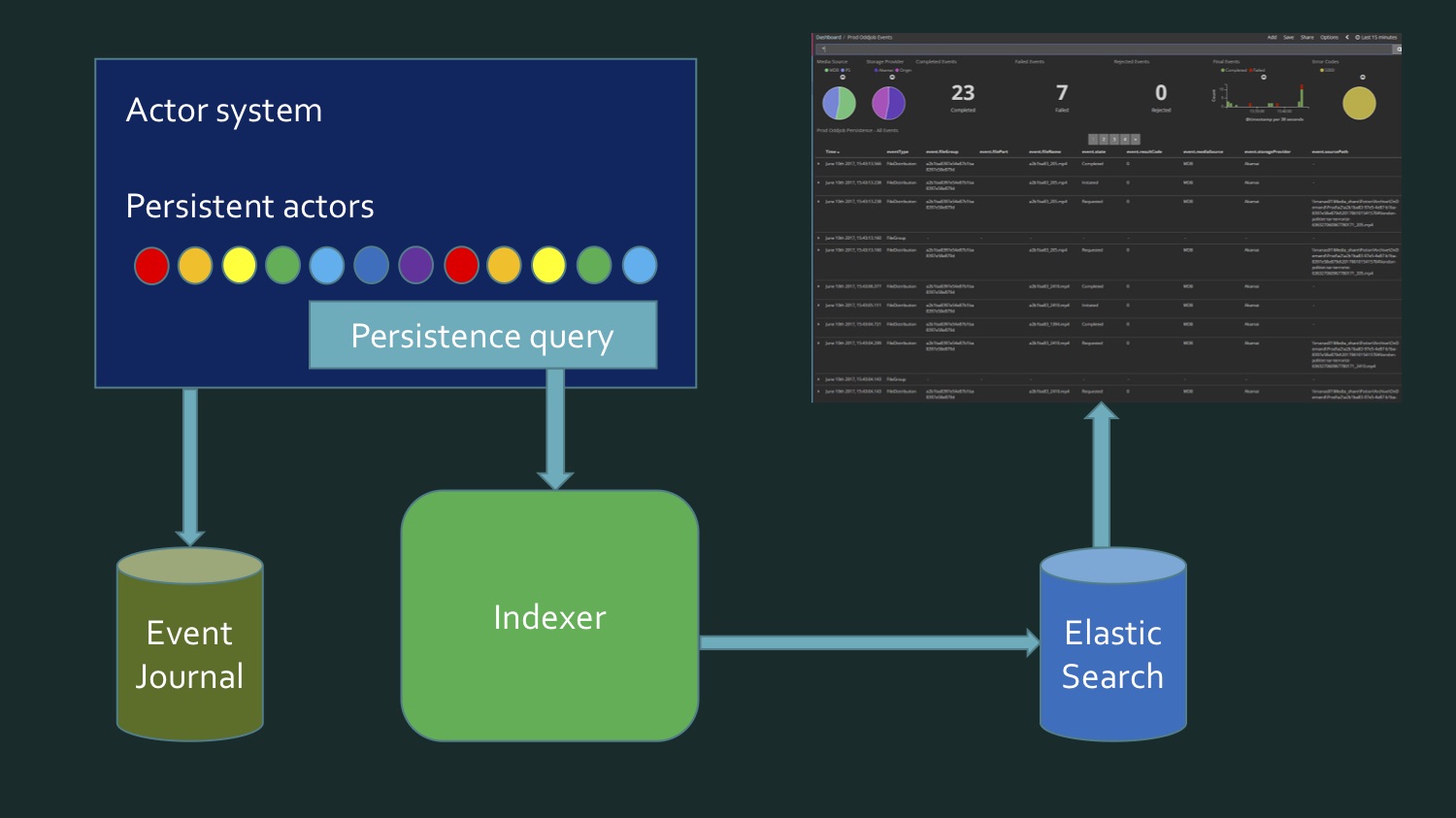 Dies ist nur die Möglichkeit, sie in Form eines über der Quelle abstrahierten Datenstroms abzurufen, sie stammen aus der Datenbank oder werden in Echtzeit abgerufen.Integrierte Abfragen (Persistenzabfragen):
Dies ist nur die Möglichkeit, sie in Form eines über der Quelle abstrahierten Datenstroms abzurufen, sie stammen aus der Datenbank oder werden in Echtzeit abgerufen.Integrierte Abfragen (Persistenzabfragen):- Allpersistencelds
- CurrentPersistencelds
- EventsByPersistenceld
- CurrentEventsByPersistenceld
- EventsByTag
- CurrentEventsByTag
Und es gibt eine Reihe von Methoden, die wir verwenden können, zum Beispiel die Current-Methode - dies ist eine Momentaufnahme, Daten historisch bis zu einem bestimmten Zeitpunkt. Und ohne dieses Präfix zuerst und einschließlich realer. Wir brauchten EventsByTag. let system = mailbox.Context.System let queries = PersistenceQuery.Get(system) .ReadJournalFor<SqlReadJournal>(SqlReadJournal.Identifier) let mat = ActorMaterializer.Create(system) let offset = getCurrentOffset client config let ks = KillSwitches.Shared "persistence-elastic" let task = queries.EventsByTag(PersistenceUtils.anyEventTag, offset) .Select(fun e -> ElasticTypes.EventEnvelope.FromAkka e) .GroupedWithin(config.BatchSize, config.BatchTimeout) .Via(ks.Flow()) .RunForeach((fun batch -> processItems client batch), mat) .ContinueWith(handleStreamError mailbox, TaskContinuationOptions.OnlyOnFaulted) |> Async.AwaitTaskVoid
Und es stellte sich heraus, dass wir genug Code hatten. Es wurde in F # geschrieben, aber in C # war es ungefähr der gleiche Kompakt. Wir erhalten EventsByTag, verwenden integrierte Akka Streams-Blöcke und daraus erhalten wir die Daten, die wir in Elasticsearch unterstützen. Das heißt, wir haben die Implementierung des Datenstroms durch eine andere Person ausgenutzt, sodass wir vergessen konnten, wo sich unsere Daten befinden, woher sie stammen - aus der Datenbank oder in Echtzeit. Diese Implementierung gab uns all dies mit einer einzigen Anfrage.Aber hier waren wir Verbraucher dieser Daten. Wenn wir solche Daten selbst erstellen möchten, wird das Beispiel interessanter und wir betrachten es anhand realer Daten, da Twitter einer der Initiatoren dieser Spezifikation war und Tweets für jeden zugänglich sind, den wir alle verstehen . Dies ist ein Standardbeispiel für die Funktionsweise von Akka Streams.Implementierungsbeispiel: Jet Tweets
Es gibt ein Beispiel für Akka für Scala, für Akka.NET, aber ich fand diese Beispiele unzureichend, da sie ein spezifisches Beispiel dafür zeigen, wie Daten herausgezogen werden und was damit gemacht wird, aber ich wollte eine allmähliche Komplikation betrachten, dh mit einem einfachen Stream beginnen und fügen Sie weiterhin einige neue Designs hinzu. Zu diesem Zweck verwenden wir die Tweetinvi- Bibliothek - dies ist eine Open-Source-Bibliothek, die Daten von Twitter bereitstellt und lediglich die Ausgabe von Daten in Form eines Streams unterstützt. Dieser Stream entspricht nicht der Spezifikation für reaktive Streams, das heißt, wir können ihn nicht sofort übernehmen, aber er ist sogar gut, da wir damit zeigen können, wie wir mit allgemein primitivem Akka unseren eigenen Stream basierend darauf schreiben können diese Spezifikation erfüllt. Jetzt haben wir eine bestimmte Quelle von Tweets, die wir in zwei Kanäle parallelisieren, d. H. Dies ist ein Broadcast-Grundelement. Im ersten Kanal formatieren wir einfach die Tweets, wählen den Namen des Autors des Tweets aus und mischen sie dann mit den Daten des zweiten Kanals. Und im zweiten Kanal werden wir etwas Komplizierteres tun: Wir werden die Bandbreite dieses Streams begrenzen, dann die Tweet-Daten an den Stellen, an denen diese Tweets geschrieben wurden, mit Wetterdaten erweitern, alles mit der Temperatur formatieren, mit dem ersten Kanal mischen und alles auf dem Bildschirm drucken.All dies befindet sich in meinem GitHub-Konto in AkkaStreamsDemo . Öffnen Sie und sehen (oder kann beobachten Post starten Sie den Report von diesem Moment ).
Jetzt haben wir eine bestimmte Quelle von Tweets, die wir in zwei Kanäle parallelisieren, d. H. Dies ist ein Broadcast-Grundelement. Im ersten Kanal formatieren wir einfach die Tweets, wählen den Namen des Autors des Tweets aus und mischen sie dann mit den Daten des zweiten Kanals. Und im zweiten Kanal werden wir etwas Komplizierteres tun: Wir werden die Bandbreite dieses Streams begrenzen, dann die Tweet-Daten an den Stellen, an denen diese Tweets geschrieben wurden, mit Wetterdaten erweitern, alles mit der Temperatur formatieren, mit dem ersten Kanal mischen und alles auf dem Bildschirm drucken.All dies befindet sich in meinem GitHub-Konto in AkkaStreamsDemo . Öffnen Sie und sehen (oder kann beobachten Post starten Sie den Report von diesem Moment ).Beginnen wir mit einem einfachen.
Zunächst möchte ich Daten von Twitter direkt lesen: in der Datei Program.cs var useCachedTweets = false
Falls ich von Twitter gebannt werde, habe ich Tweets zwischengespeichert, sie sind schneller. Zu Beginn erstellen wir RunnableGraph. public static IRunnableGraph<IActorRef> CreateRunnableGraph() { var tweetSource = Source.ActorRef<ITweet>(100, OverflowStrategy.DropHead); var formatFlow = Flow.Create<ITweet>().Select(Utils.FormatTweet); var writeSink = Sink.ForEach<string>(Console.WriteLine); return tweetSource.Via(formatFlow).To(writeSink); }
( Quelle )Wir haben hier eine Quelle für Tweets, die von einem Schauspieler stammt. Ich werde Ihnen zeigen, wie wir diese Tweets dort abrufen, formatieren (das Tweet-Format gibt dem Autor nur einen Tweet) und ihn dann auf den Bildschirm schreiben.StartTweetStream - hier verwenden wir die Tweetinvi-Bibliothek. public static void StartTweetStream(IActorRef actor) { var stream = Stream.CreateSampleStream(); stream.TweetReceived += (_, arg) => { arg.Tweet.Text = arg.Tweet.Text.Replace("\r", " ").Replace("\n", " "); var json = JsonConvert.SerializeObject(arg.Tweet); File.AppendAllText("tweets.txt", $"{json}\r\n"); actor.Tell(arg.Tweet); }; stream.StartStream(); }
( Quelle )Über CreateSampleStream erhalten wir Beispiel-Tweets, die mit einer nicht sehr hohen Geschwindigkeit ausgegeben werden. Aus all dem wählen wir aus, was wir brauchen, und erstellen einen Schauspieler, der sagt: "Akzeptiere diesen Tweet." Als nächstes müssen wir IEnumerable bekommen, damit wir am Ende die Quelle bekommen.Und TweetEnumerator sieht sehr einfach aus: Wir haben eine Sammlung von Tweets und müssen Current, MoveNext, Reset und Dispose implementieren, um gute Bürger zu sein. Wenn wir dies ausführen, sehen wir ein Echtzeitbeispiel. Es wird viel nicht gedruckt, da es aus verschiedenen nicht-lateinischen Ländern stammt. Dies ist die einfachste Version unseres Programms.Jetzt ändern wir den Wert von useCachedTweets in true, und hier beginnen die Komplikationen. CashedTweets ist das gleiche, nur habe ich dort eine Datei mit 50.000 Tweets, die ich bereits ausgewählt, gespeichert habe, wir werden sie verwenden. Ich habe versucht, Tweets auszuwählen, die Daten zu den geografischen Koordinaten ihrer Autoren enthalten, die wir benötigen werden. Der nächste Schritt ist, dass wir die Tweets parallelisieren wollen. Nach der Ausführung haben wir zuerst den Besitzer des Tweets in der Liste und dann die Koordinaten.TweetsWithBroadcast: var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
( Quelle )Wenn es Scala wäre, würde es wirklich wie ein grafisches DSL aussehen. Hier erstellen wir Broadcast mit zwei Kanälen - out (0), out (1) - und in einem Fall drucken wir CreatedBy, in dem anderen drucken wir die Koordinaten, dann mischen wir alles und senden es an den Bestand. Auch vorerst einfach genug.Der nächste Schritt in unserer Demo besteht darin, die Dinge etwas zu komplizieren. Beginnen wir mit der Änderung der Bandbreite. var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });}
( Quelle )Im ersten Kanal haben wir eine Bandbreitenbeschränkung von bis zu 10 Tweets pro Sekunde, im zweiten Kanal haben wir bis zu einem Tweet pro Sekunde mit einem Puffer von 10. Wenn wir den Puffer angeben, müssen wir die Strategie angeben, was zu tun ist, wenn der Puffer voll ist. Dies unterscheidet übrigens Akka Streams und Reactive Streams im Allgemeinen: Die Wahl dieser Strategie ist ein Muss. In vielen Fällen wissen wir bei der Arbeit mit Threads nicht, was passieren wird, wenn bei uns etwas überläuft. Hier können wir zum Beispiel auswählen, ob dies kritische Daten sind, dann kann der gesamte Stream eine Fehlermeldung geben und enden. Sie können die neuesten Daten entfernen, Sie können beginnen, Daten vom Ende zu entfernen. Dies ist unsere Wahl, aber es ist ein bestimmter Vertrag, den wir hier abschließen. Hier ist es in Buffer (10, OverFlowStrategy.DropHead). Wenn wir dieses Programm jetzt ausführen,Wir erhalten Tweets dieser Kanäle mit unterschiedlichen Geschwindigkeiten. Wir haben hier ungefähr 10 Tweets mit dem Namen des Besitzers, einen Tweet mit der Koordinate, da wir eine solche Bandbreite eingestellt haben. Natürlich möchte ich etwas mit den Koordinaten tun, nämlich Sie können versuchen, sie auf einen Dienst hochzuladen, der uns beispielsweise Aufschluss darüber gibt, wie das Wetter ist, d. H. In welcher Stimmung der Tweet-Autor je nach Wetter war. Sehen Sie, wie einfach die Implementierung jetzt sein wird.In welcher Stimmung war der Autor des Tweets je nach Wetterlage? Sehen Sie, wie einfach die Implementierung jetzt sein wird.In welcher Stimmung war der Autor des Tweets je nach Wetterlage? Sehen Sie, wie einfach die Implementierung jetzt sein wird. var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(Flow.Create<ICoordinates>().SelectAsync(5, Utils.GetWeatherAsync)) .Via(formatTemperature) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
( Quelle )Hier haben wir den zweiten Kanal, SelectAsync, in dem wir das Wetter erhalten. Wir senden dies nicht nur an den Wetterlieferdienst, wir sagen auch, dass dieser Code mit einer Parallelisierungsstufe von 5 ausgeführt wird: Dies bedeutet, dass 5 parallele Threads erstellt werden, wenn dieser Dienst langsam genug ist, in dem dieser Dienst das Wetter anfordert. Der Dienst selbst ist hier implementiert, es ist auch sinnvoll zu zeigen, wie einfach dieser Code aussieht. public static async Task<decimal> GetWeatherAsync(ICoordinates coordinates) { var httpClient = new HttpClient(); var requestUrl = $"http://api.met.no/weatherapi/locationforecast/1.9/?lat={coordinates.Latitude};lon={coordinates.Latitude}"; var result = await httpClient.GetStringAsync(requestUrl); var doc = XDocument.Parse(result); var temp = doc.Root.Descendants("temperature").First().Attribute("value").Value; return decimal.Parse(temp); }
( Quelle ) Hier istalles ganz einfach. Ich habe den ersten Webdienst gefunden, der das aktuelle Wetter anhand von Koordinaten anzeigt. Es war eine Art norwegischer Meteo-Anbieter. Es handelt sich lediglich um eine Anfrage, die hier über HttpClient gesendet wurde, und Wetterdaten können aus dem XML extrahiert werden, das ich erhalte.Wenn wir jetzt unsere Demonstration durchführen und dieser Dienst jetzt aktiviert ist, werden die Temperaturdaten zu spät angezeigt. Ungefähr einmal in 10 Tweets haben wir 10 Nachrichten mit dem Namen des Besitzers, und sobald wir die Temperatur in Grad Celsius erhalten, wurde der Tweet geschrieben.Es ist beeindruckend genug, wie einfach es ist, einen solchen Prozess zu beschreiben, einschließlich der Angabe des Parallelitätsgrades. Dies sind nur einige der Blöcke, die in Akka Streams verwendet werden können. Ich habe bereits gesagt, dass es viele davon gibt. Die Chancen, dass Sie viele davon nutzen können, sind sehr hoch.Wenn ich das Schauspielermodell verwenden würde, wahrscheinlich vor einem Jahr, als ich mit Akka Streams nicht vertraut war, würde ich jeden Schauspieler dafür separat schreiben. Wie Sie sehen, müssen Sie nicht für jeden Prüfpunkt Code schreiben. All dies kann mit Akka Streams-Tools durchgeführt werden. Insgesamt sind in C # mehrere zehn Codezeilen erforderlich, sodass wir unsere Kontrolle und unsere Aufmerksamkeit auf eine höhere Ebene der Prozessorganisation konzentrieren können. und nicht auf den Mikrodetails, den Innenseiten des Datenstroms.Letzte Überlegungen
 Welche Ideen zu Akka Streams möchte ich, dass Sie sich nach dem Lesen dieses Artikels selbst machen? Auf der DotNext 2017 in Moskau war ich auf einer Präsentation von Alex ThyssenInformationen zu Azure-Funktionen. In gewissem Sinne ist dies eine Änderung in der Idee, wie Code für die Bereitstellung geschrieben werden soll. Anstatt uns auf die Konfiguration von Maschinen zu konzentrieren, installieren wir solche Programme auf dieser Maschine, die mit diesen Diensten kommunizieren und diese Daten empfangen. Wir konzentrieren uns direkt auf den Funktionsteil und diesen Funktionshelm in die Cloud. Wir denken nicht genau darüber nach, welche Maschinenknoten diesen Code ausführen, sondern darüber, wie unsere Funktionen miteinander kooperieren sollen. Eine ähnliche Analogie kann zwischen einem System gezogen werden, das unter Verwendung von Akteursmodellen, jedoch manuell, und Akka-Streams geschrieben wurde, d. H. Wir vergessen, wie man Schauspieler manuell schreibt und konzentrieren uns stattdessen auf die gesamte Prozessbeschreibung.In einem wesentlichen Teil der Szenarien schaffen wir es, auf einem relativ hohen Niveau zu bleiben und gleichzeitig die Skalierbarkeit und Systemleistung aufrechtzuerhalten.Da Akka Streams nicht die einzige Alternative für diesen Ansatz ist, sollten Sie sich überlegen, ob Sie eine Ebene höher gehen können, wenn Sie überlegen, wie Sie Ihren Prozess simulieren können. Bei all den Vorteilen, die Microservices uns gegenüber dem monolithischen Ansatz bieten, gibt es gewisse Bedenken, dass wir uns zu sehr auf Microservices konzentrieren, Mikrotasks erhalten und bei alledem nicht den gesamten Wald sehen. Und jetzt ist Akka Streams ein Weg, ohne zur monolithischen Ebene zurückzukehren und dennoch zur Ebene der allgemeinen Idee des Prozesses zurückzukehren.Schließlich habe ich für Sie ein kleines Lied, das über einige der eingebauten Akka Streams-Blöcke spricht und "Akka Stream Rap" heißt. Es gibt Wörter unter dem Video , Sie können es einschalten und mitsingen.
Welche Ideen zu Akka Streams möchte ich, dass Sie sich nach dem Lesen dieses Artikels selbst machen? Auf der DotNext 2017 in Moskau war ich auf einer Präsentation von Alex ThyssenInformationen zu Azure-Funktionen. In gewissem Sinne ist dies eine Änderung in der Idee, wie Code für die Bereitstellung geschrieben werden soll. Anstatt uns auf die Konfiguration von Maschinen zu konzentrieren, installieren wir solche Programme auf dieser Maschine, die mit diesen Diensten kommunizieren und diese Daten empfangen. Wir konzentrieren uns direkt auf den Funktionsteil und diesen Funktionshelm in die Cloud. Wir denken nicht genau darüber nach, welche Maschinenknoten diesen Code ausführen, sondern darüber, wie unsere Funktionen miteinander kooperieren sollen. Eine ähnliche Analogie kann zwischen einem System gezogen werden, das unter Verwendung von Akteursmodellen, jedoch manuell, und Akka-Streams geschrieben wurde, d. H. Wir vergessen, wie man Schauspieler manuell schreibt und konzentrieren uns stattdessen auf die gesamte Prozessbeschreibung.In einem wesentlichen Teil der Szenarien schaffen wir es, auf einem relativ hohen Niveau zu bleiben und gleichzeitig die Skalierbarkeit und Systemleistung aufrechtzuerhalten.Da Akka Streams nicht die einzige Alternative für diesen Ansatz ist, sollten Sie sich überlegen, ob Sie eine Ebene höher gehen können, wenn Sie überlegen, wie Sie Ihren Prozess simulieren können. Bei all den Vorteilen, die Microservices uns gegenüber dem monolithischen Ansatz bieten, gibt es gewisse Bedenken, dass wir uns zu sehr auf Microservices konzentrieren, Mikrotasks erhalten und bei alledem nicht den gesamten Wald sehen. Und jetzt ist Akka Streams ein Weg, ohne zur monolithischen Ebene zurückzukehren und dennoch zur Ebene der allgemeinen Idee des Prozesses zurückzukehren.Schließlich habe ich für Sie ein kleines Lied, das über einige der eingebauten Akka Streams-Blöcke spricht und "Akka Stream Rap" heißt. Es gibt Wörter unter dem Video , Sie können es einschalten und mitsingen.This is the Akka Stream.
This is the Source that feeds the Akka Stream.
This is the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Streams.
This is the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the source that feeds the Akka Streams.
Dies ist die Senke, die aus dem Bidiflow gefüllt wird, der die Drossel zurückdreht, die das TakeWhile zurückdreht, das aus dem Drop gezogen wird, der aus dem Zip entfernt wird, der aus dem Gleichgewicht entfernt wird, das den FilterNot teilt, der aus der Zusammenführung auswählt, die aus dem Broadcast gesammelt wird Gabelt den MapAsync, der von der Quelle abgebildet wird, die den Akka-Stream speist.
Minute der Werbung. Wenn Ihnen der Bericht gefallen hat und Sie noch etwas Ähnliches wünschen, findet vom 22. bis 23. November die nächste DotNext 2018 in Moskau statt , die für Sie dort möglicherweise nicht weniger interessant ist. Beeilen Sie sich , um Tickets zum Juli-Preis zu erhalten (ab dem 1. August steigen die Ticketkosten).