Vom 19. bis 21. April fand in St. Petersburg die Konferenz C ++ Russia 2018 statt. Von Jahr zu Jahr werden Organisation und Verhalten um eine Ebene höher, was eine gute Nachricht ist. Dank an den ständigen Organisator von C ++ Russia, Sergey Platonov, für seinen Beitrag zur Entwicklung dieses Gebiets.
Am 19. April waren Meisterkurse geplant, an denen wir leider nicht teilnehmen konnten, und am 20. und 21. fand das Hauptprogramm der Konferenz statt, an dem wir mit großem Interesse teilnahmen. Sergey
sermp hat einen tollen Job gemacht und mehrere bemerkenswerte ausländische Sprecher als Redner angezogen. Der erste Tag der Konferenz wurde von Jon Kalb, dem Organisator von CppCon und Autor von C ++ Today: The Beast is Back, eröffnet. Der zweite Tag begann mit einer Präsentation von Daveed Vandevoorde, Mitglied des Standardisierungsausschusses, einem der Autoren von C ++ - Vorlagen: The Complete Guide. Andrei Alexandrescu stand im Mittelpunkt der Aufmerksamkeit, der nach seinem Bericht über Ausnahmen einmal eine ganze Menge von Menschen versammelte, die ein Autogramm bekommen und ein gemeinsames Foto machen wollten. Zum ersten Mal wurde auf Skype ein Herb Sutter-Vortrag über den Raumschiff-Betreiber für C ++ 20 ausgestrahlt.
Obwohl die Konferenz vor mehr als drei Monaten stattfand, wurde das Video (
vollständige Wiedergabeliste ) gerade darauf veröffentlicht. Es ist also an der Zeit, Ihre Erinnerungen aufzufrischen und in die erstaunlichen Funktionen von C ++ einzutauchen.
In diesem Vortrag wird erläutert, warum Ingenieure, die nach Leistung suchen, C ++ wählen. Jon präsentiert eine historische Perspektive von C ++ und konzentriert sich darauf, was gerade in der C ++ - Community vor sich geht und wohin die Sprache und ihre Benutzerbasis führen. Mit einem erneuten Interesse an Leistung sowohl für Rechenzentren als auch für mobile Geräte und dem Erfolg von Open Source-Softwarebibliotheken ist C ++ zurück und es ist heiß. In diesem Vortrag wird erklärt, warum C ++ für die Leistung die Sprache der meisten Softwareentwickler ist. Sie erhalten eine grobe historische Skizze, die C ++ relativiert und die Höhen und Tiefen seiner Popularität abdeckt.

Iteratorpaare sind in der gesamten C ++ - Bibliothek allgegenwärtig. Es ist allgemein anerkannt, dass das Kombinieren eines solchen Paares zu einer einzigen Entität, die üblicherweise als Range bezeichnet wird, einen präziseren und lesbareren Code liefert. Die genaue Semantik eines solchen Range-Konzepts zu definieren, erweist sich jedoch als überraschend schwierig. Theoretische Überlegungen stehen im Widerspruch zu praktischen. Einige Entwurfsziele sind insgesamt nicht miteinander kompatibel.
Wir sind uns alle bewusst, dass wir die STL-Algorithmen kennen sollten. Wenn wir sie in unsere Entwürfe aufnehmen, können wir unseren Code ausdrucksvoller und robuster gestalten. Und manchmal auf spektakuläre Weise.
Aber kennen Sie Ihre STL-Algorithmen?
In diesem Vortrag stellt der Autor 105 Algorithmen vor, über die die STL derzeit verfügt, einschließlich der in C ++ 11 und C ++ 17 hinzugefügten. In diesem Vortrag geht es jedoch nicht nur um eine Auflistung, sondern auch darum, die verschiedenen Gruppen von Algorithmen, die Muster, die sie in der STL bilden, und die Beziehung zwischen den Algorithmen darzustellen.
Diese Art von Gesamtbild ist der beste Weg, um sich tatsächlich an alle zu erinnern, und stellt eine Toolbox dar, die voller Möglichkeiten ist, unseren Code ausdrucksvoller und robuster zu machen.
Wollten Sie schon immer einen Wert ändern oder eine Anweisung ausführen, während Ihr C ++ - Programm ausgeführt wird, um etwas zu testen - nicht trivial oder mit einem Debugger möglich? Skriptsprachen haben eine REPL (Read-Eval-Print-Loop). Das Nächste, was C ++ hat, ist das Festhalten (entwickelt von Forschern am CERN), aber es basiert auf LLVM und ist sehr umständlich einzurichten. RCRL (Read-Compile-Run-Loop) ist ein Demo-Projekt, das einen innovativen Ansatz für die plattform- und compilerunabhängige C ++ - Kompilierung zur Laufzeit zeigt, der einfach eingebettet werden kann. In dieser Präsentation wird gezeigt, wie es verwendet wird, wie es funktioniert und wie es geändert und in jede Anwendung und jeden Workflow integriert werden kann.

Wäre es nicht schön, wenn wir einen Standard-C ++ - Typ zur Darstellung von Zeichenfolgen hätten? Oh, warte ... wir machen: std :: string. Wäre es nicht schön, wenn wir diesen Standardtyp für unsere gesamte Anwendung / unser gesamtes Projekt verwenden könnten? Nun ... wir können nicht! Es sei denn, wir schreiben eine Konsolen-App oder einen Dienst. Wenn wir jedoch eine App mit GUI schreiben oder mit modernen Betriebssystem-APIs interagieren, müssen wir uns wahrscheinlich mit mindestens einem anderen nicht standardmäßigen C ++ - Zeichenfolgentyp befassen. Je nach Plattform und Projekt kann es sich um CString von MFC oder ATL, Platform :: String von WinRT, QString von Qt, wxString von wxWidgets usw. handeln. Oh, vergessen wir nicht unseren alten Freund const char *, besser noch const wchar_t * für die C-Familie von APIs ...
Wir haben also zwei Zeichenfolgentypen in unserer Codebasis gefunden. OK, das ist überschaubar: Wir bleiben bei std :: string für den gesamten plattformunabhängigen Code und konvertieren bei der Interaktion mit System-APIs oder GUI-Code hin und her in den anderen XString. Wir werden einige unnötige Kopien machen, wenn wir diese Brücke überqueren, und am Ende werden wir einige komisch aussehende Funktionen haben, die zwei Arten von Saiten jonglieren. aber das ist doch klebercode ... richtig?
Es ist ein guter Plan ... bis unser Projekt wächst und wir viele String-Dienstprogramme und Algorithmen sammeln. Beschränken wir diese algorithmischen Extras auf std :: string? Greifen wir auf den gemeinsamen Nenner const char * zurück und verlieren die Typ- / Speichersicherheit unseres C ++ - Typs? Ist C ++ 17 std :: string_view die Antwort auf alle unsere String-Probleme?
Der Autor versucht, die Optionen zusammen mit einer Fallstudie zu einer 15 Jahre alten Windows-Anwendung zu untersuchen: Advanced Installer (www.advancedinstaller.com) - ein aktiv entwickeltes C ++ - Projekt, das dank Clang-Tidy auf C ++ 17 modernisiert wurde und "Clang Power Tools" (
www.clangpowertools.com) ...
Das Schreiben von Code, der bei Fehlern stabil ist, war in allen Sprachen schon immer ein Problem. Ausnahmen sind das politisch korrekte Mittel, um Fehler in C ++ zu signalisieren. Viele Anwendungen greifen jedoch aus Gründen des besseren Verständnisses, der einfachen Handhabung von Fehlern vor Ort und der Effizienz des generierten Codes immer noch auf Fehlercodes zurück.
Dieser Vortrag zeigt, wie verschiedene theoretische und praktische Artefakte miteinander kombiniert werden können, um Fehlercodes und Ausnahmen in einem gesunden, einfachen Paket zu beheben. Der generische Typ Expected kann sowohl für lokale (Fehlercode-Stil) als auch für zentralisierte (Ausnahme-Stil) Manieren verwendet werden, wobei die jeweiligen Stärken berücksichtigt werden.

Software mit sehr komplexer Geschäftslogik wie Spiele, CAD-Systeme und Unternehmenssysteme muss häufig zur Laufzeit Objekte erstellen und ändern, um beispielsweise eine Methode in einem vorhandenen Objekt hinzuzufügen oder zu überschreiben. Standard C ++ hat starre Typen, die zur Kompilierungszeit definiert werden und dies erschweren. Sprachen mit dynamischen Typen wie Lua, Python und JavaScript machen dies jedoch sehr einfach. Daher verwenden viele Projekte solche Sprachen neben C ++, um den Code lesbar und wartbar zu halten und komplexe Anforderungen an die Geschäftslogik zu erfüllen. Einige Nachteile dieses Ansatzes sind die zusätzliche Komplexität in einer Sprachbindungsschicht, der Leistungsverlust durch die Verwendung einer interpretierten Sprache und die unvermeidliche Codeduplizierung für viele kleine Dienstprogrammfunktionen.
DynaMix ist eine Bibliothek, die versucht, die Notwendigkeit einer separaten Skriptsprache zu beseitigen oder zumindest stark zu reduzieren, indem die Benutzer zur Laufzeit in C ++ polymorphe Objekte erstellen und ändern können. In diesem Vortrag wird dieses Problem näher erläutert und potenziellen Benutzern oder Personen, die von dem Ansatz profitieren könnten, die Bibliothek und ihre Hauptfunktionen anhand eines kommentierten Beispiels und einer kleinen Demo vorgestellt.

In C ++ können Sie eine einzelne Aufgabe auf mehrere Arten lösen. Der Autor wählt eine tatsächliche Aufgabe aus der Produktion aus und untersucht, wie sie mit einer Reihe von Tools gelöst werden kann, die C ++ bereitstellt: STL-Container, boost.range, C ++ 20-Bereiche, Coroutinen. Er vergleicht auch API-Einschränkungen und die Leistung verschiedener Lösungen und wie sie leicht von einer zur anderen konvertiert werden können, wenn der Code gut strukturiert ist. Währenddessen untersucht der Autor auch Anwendungen einiger nützlicher C ++ 17-Funktionen wie constexpr if, Auswahlanweisungen mit Initialisierer, std :: not_fn usw. Besonderes Augenmerk wird auf themenbezogene Standardalgorithmen gelegt.

Parallele Programmierung ist ein sehr facettenreiches und tiefgreifendes Thema. Im Laufe der Jahrzehnte der Forschung wurde eine Vielzahl von Ansätzen, Praktiken und Werkzeugen entwickelt, aber wir können kaum davon ausgehen, dass die C ++ - Sprache mit diesen Trends Schritt gehalten hat. Beginnend mit dem C ++ 11-Standard wurden Konzepte wie std :: thread, std :: atomic, std :: future und std :: mutex eingeführt, und es wird erwartet, dass in Zukunft Coroutinen, ein Modell für asynchrone Berechnungen, hinzugefügt werden. Nun, das sind alles interessante Dinge, die es zu studieren gilt, aber der Bericht wird sich auf eine ganz andere Idee konzentrieren.
Software Transactional Memory (STM) - das Konzept eines transaktionsveränderlichen Datenmodells - existiert seit langem und verfügt über eine Reihe von Implementierungen für alle Sprachen. Mit STM drücken Sie Ihr Datenmodell aus und starten es, um es wettbewerbsfähig über mehrere Threads hinweg zu ändern, ohne sich um die Thread-Synchronisierung, den gültigen Datenstatus oder Sperren kümmern zu müssen. STM wird alles für Sie tun. Das klingt sehr gut, aber nicht alle STM-Bibliotheken sind gleich nützlich. Herkömmliche imperative STMs sind sehr komplex, anfällig für nicht triviale Multithread-Fehler und schwierig zu verwenden. Andererseits gibt es in der Welt der funktionalen Programmierung seit langem das Konzept des kombinatorischen STM, Transaktionen, bei denen es sich um zusammensetzbare Bausteine handelt, aus denen Sie Transaktionen auf einer höheren Ebene erstellen. Der kombinatorische Ansatz für STM ermöglicht es Ihnen, ein wettbewerbsfähiges Datenmodell flexibler, klarer und zuverlässiger auszudrücken. Parallele Programmierung kann auch Spaß machen!
In dem Bericht wird der Autor über die Funktionen von kombinatorischem STM sprechen, wie es verwendet wird und wie es in C ++ 17 implementiert werden kann.

Während der gesamten Geschichte der Programmierung war und ist die sequentielle elementweise Verarbeitung verschiedener Arten von Sammlungen eine der häufigsten praktischen Aufgaben. Die interne Darstellung der Sammlungen sowie der Algorithmus zum Abrufen nachfolgender Elemente können in einem sehr großen Bereich variieren: Array, verknüpfte Liste, Baum, Hash-Tabelle, Datei et al. Hinter der Vielfalt der Redewendungen, Standardbibliotheksfunktionen und Ad-hoc-Lösungen kann man jedoch die Essenz aufdecken, die für diese ganze Klasse von Aufgaben unveränderlich bleibt. Dieser Vortrag soll einen schrittweisen Übergang von Algorithmen auf der Grundlage einer expliziten Beschreibung von Aktionen über einzelne Elemente hin zu deklarativen Verarbeitungswerkzeugen auf hoher Ebene zeigen, die eine Sammlung als Einheit behandeln und die Logik der Domäne angemessen offenlegen.
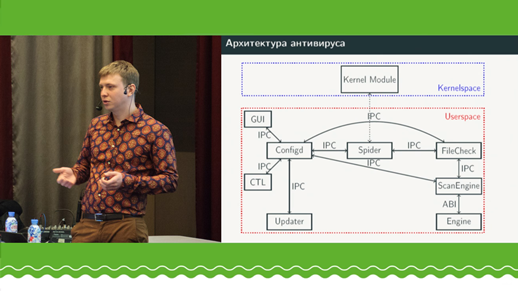
Der Autor wird über seine Erfahrungen bei der Entwicklung einer Antiviren-Engine in C ++ in Form einer gemeinsam genutzten Bibliothek berichten. Ein einzigartiges Merkmal ist das Fehlen externer Abhängigkeiten (Laufzeit C ++ oder C). Diese ganze Reihe basiert auf der Verwendung einer benutzerdefinierten Toolchain in GCC für ein spezielles Ziel, das libc newlib für dasselbe Ziel verwenden wird, auf dem libstdc ++ basiert. Dementsprechend wird die gemeinsam genutzte Bibliothek über eine benutzerdefinierte Toolchain mit benutzerdefinierten libgcc_s, libc, libcstdc ++ zusammengestellt (Änderungen nur in der Assembly). Die gesamte Interaktion mit der Laufzeit erfolgt über die gemeinsam genutzte Bibliothek ABI. Somit behält die Bibliothek die Möglichkeit, vollwertiges modernes C ++ ohne Einschränkungen (RTTI, Ausnahmen, iostream usw.) zu verwenden, das an libstdc ++ libc (newlib) | geht l ibgcc-ABI. Ein ähnlicher Ansatz wurde mit den Toolketten GCC / newlib / libstdc ++ für Linux und clang / newlib / libc ++ für MacOS getestet. Der Bericht ist möglicherweise für diejenigen von Interesse, die C ++ in gemeinsam genutzten Bibliotheken verwenden möchten, kann ihn sich jedoch aufgrund externer Abhängigkeiten nicht leisten.

In den letzten anderthalb Jahren hat der Autor die Coursera-Spezialisierung für modernes C ++ geleitet. Die Spezialisierung besteht aus fünf Kursen, von denen zwei bereits laufen und ein weiterer fast fertig ist.
Der Bericht wird sagen:
- Welche Probleme können bei der Arbeit an Kursen auftreten (zum Beispiel haben die Entwickler nach 3 Monaten Arbeit alle Materialien weggeworfen und erneut begonnen)
- wie der Lehrplan gebildet wird und warum genau (zum Beispiel, warum das Wort "Zeiger" in den ersten beiden Kursen nicht einmal geklungen hat)
Darüber hinaus wurde während der Spezialisierungsarbeit eine Reihe von Grundsätzen entwickelt, die in der täglichen Arbeit anwendbar sind:
- bei der Integration eines neuen Mitarbeiters in das Projekt
- während der Codeüberprüfung
- bei der Einstellung
Daher möchte der Autor nicht nur erzählen, wie er sich spezialisiert, sondern auch versuchen, die gesammelten Erfahrungen auf alltägliche Aufgaben zu übertragen.
Es ist kein Geheimnis, dass die Entwicklung in C / C ++ viel höhere Anforderungen an die Codequalität stellt als die Entwicklung in Java. Die Wahrscheinlichkeit, einen fatalen Fehler zu machen, ist viel höher. Gleichzeitig ist das Sammeln von Informationen über solche Fehler selbst für erfahrene Programmierer keine triviale Aufgabe.
Im ersten Teil des Berichts werden wir kurz auf die bestehenden Entwicklungen eingehen: Wie der integrierte Android-Debugger funktioniert, welche Lösungen bereits existieren. Der zweite Teil ist der Geschichte gewidmet, wie es "unter der Haube" funktioniert: wie man den Status des Prozessors zum Zeitpunkt des Fehlers erhält, wie man den Aufrufstapel abwickelt, wie man die Zeilennummern im Quellcode herausfindet. Es wird eine Übersicht über Stack-Promotion-Bibliotheken wie libcorkscrew, libunwind, libunwindstack gegeben.
Der Bericht wird sowohl für Android-Entwickler, deren Anwendungen NDK verwenden, als auch für alle anderen von Interesse sein, um ihren Horizont zu erweitern.
int * ptr = new int;
* ptr = 42;
ptr löschen;
Was passiert eigentlich, wenn diese 3 Codezeilen ausgeführt werden? Wir werden uns den Speicherzuweiser, das Betriebssystem und die moderne Hardware ansehen, um eine umfassende Antwort auf diese Frage zu geben.
Im Jahr 2017 verliert das Problem der Auswahl eines Allokators in C ++ nicht an Relevanz. Sie haben dem Standard eine neue Methode hinzugefügt, um einen lokalen Allokator für Container (std :: pmr), globales tcmalloc und jemalloc sowie die Kernel-Schnittstellen, auf die sie sich verlassen, auszuwählen. Dieser Bericht ist der "unteren Etage" dieses Entwurfs gewidmet: den Funktionen von mmap und madvise im Linux-Kernel und den Auswirkungen dieser Funktionen auf die Leistung von Allokatoren.

Das neue Raumschiff wurde kürzlich als Sprachfunktion für C ++ 20 übernommen. In diesem Vortrag gibt der Designer und Autor des Raumschiffvorschlags einen Überblick über das Feature, diskutiert dessen Motivation und Design und geht durch Beispiele für dessen Verwendung. Er legt besonderen Wert darauf, wie die Funktion das Schreiben und Lesen von C ++ - Code sauberer macht, schneller durch Vermeidung redundanter Arbeit und robuster, indem mehrere wichtige, aber subtile Fallstricke in dem spröderen Code vermieden werden, den wir zuvor ohne diese Funktion von Hand schreiben mussten.

Wenn Sie sich Vorlagen, Reflexion, Codegenerierung in der Kompilierungsphase und Metaklassen ansehen, haben Sie das Gefühl, dass C ++ es sich zur Aufgabe gemacht hat, den endgültigen Code so weit wie möglich vor dem Entwickler zu „verbergen“. Eine nicht triviale Verwendung des Präprozessors (und zahlreicher Zweige) kann die Programmsequenz sehr offensichtlich machen. Diese Ansätze ersparen Entwicklern natürlich das endlose Kopieren und Einfügen ähnlicher Teile der Codebasis, erfordern jedoch eine erweiterte Unterstützung in den Entwicklungstools.
Ist es möglich, Code zu debuggen, ohne ihn kontinuierlich neu zu starten, ohne einen Debugger und sogar ohne eine einfache Kompilierung der gesamten Codebasis? Ist es möglich, Fehler im Code zu finden, die nicht zusammengestellt oder auf dem lokalen Computer ausgeführt werden können? Da ist! Integrierte Entwicklungsumgebungen (IDEs) verfügen über umfassende Kenntnisse und Kenntnisse in Bezug auf benutzerdefinierten Code und können die entsprechenden Tools bereitstellen.
Dieser Bericht zeigt, wie man durch typedef verschachtelte Makrosubstitutionen „debuggen“, die Variablentypen (die in modernem C ++ häufig „versteckt“ sind) verstehen, verschiedene Zweige der Überladung von Präprozessoren oder Operatoren debuggen und vieles mehr mithilfe eines wirklich intelligenten Geräts IDE Einige der Funktionen sind bereits in CLion und ReSharper C ++ verfügbar, andere sind nur interessante Ideen für die Zukunft, die mit dem Publikum diskutiert werden könnten.

Die Assembly eines C ++ - Projekts kann in den Docker-Container verschoben werden. Anstatt die erforderlichen Bibliotheken und Abhängigkeiten im Hostsystem zu installieren, können sie entweder direkt im Docker-Image (z. B. Cuda) oder mit dem C ++ - Manager der Conan-Bibliothek (z. B.) installiert werden. Boost). Dies führt zu einer isolierten kontrollierten (und jedes Mal gleichen) Umgebung für die Assembly, in die Sie den Conan-Cache einbinden können, sodass verschiedene Projekte, die dieselben Bibliotheken verwenden, dieselben Assemblys verwenden. Außerdem hängt der Build nicht mehr von der Linux-Distribution ab, in der das Projekt erstellt wird. Hauptsache, Sie können Docker auf dieser Distribution ausführen.

Im Verlauf des Berichts werden wir eine kleine Arbeitsbibliothek mit std :: tuple schreiben. Mit dieser Bibliothek kompilieren wir die Kompilierungszeit in eine heterogene Hash-Tabelle. Weiter - auf seiner Basis werden wir ein kleines RPC-Framework schreiben, wobei wir die Tatsache verwenden, dass wir keine Typlöschung haben.
In C ++ 17 wird es viele constexpr-Berechnungen, Vorlagen und neue Funktionen geben (insbesondere wenn constexpr).
Reflexion ist häufig erforderlich, um Serialisierungsalgorithmen zu verallgemeinern. Implementierung verschiedener Protokolle, Arbeit mit Datenbanken. Um solche Probleme zu lösen, haben wir einen Homebrew-IDL-Compiler zum Generieren von C ++ - Strukturen und eine Bibliothek zur Interaktion mit dem Ergebnis geschrieben. Protobuf mit Pedalen und ob es sich gelohnt hat.
Vor einiger Zeit hat das C ++ - Standardisierungskomitee eine Untergruppe "SG-7" erstellt, um zu untersuchen, wie der Sprache Reflexionsfunktionen hinzugefügt werden können. In jüngerer Zeit hat diese Gruppe ihrer Platte "Metaprogrammierung" hinzugefügt und einige wichtige Entscheidungen hinsichtlich der Form der möglichen Lösung getroffen. In diesem Vortrag untersucht der Autor die Vergangenheit, die uns hierher gebracht hat, und untersucht einen möglichen Weg für C ++ 's erstklassige Unterstützung der "reflektierenden Metaprogrammierung".
Mit der Hinzufügung von Konzepten zur nächsten Version von C ++ wird erwartet, dass neue Konzepte definiert werden. Jedes Konzept definiert eine Reihe von Operationen, die von generischem Code verwendet werden. Eine solche Verwendung könnte ein generischer Test sein, der überprüft, ob alle Teile eines Konzepts definiert sind, und generische Interaktionen zwischen den Operationen eines Konzepts überprüft. Im Idealfall funktioniert ein solcher Test sogar mit Klassen, die ein Konzept nur teilweise modellieren, um die Implementierung von Klassen zu steuern.
Diese Präsentation verwendet nicht die eigentlichen Konzepterweiterungen, sondern zeigt, wie generische Tests mit den Funktionen von C ++ 17 erstellt werden können. Für die generischen Tests werden die Erkennungssprache und der Kontext verwendet, um die Verfügbarkeit der erforderlichen Operationen zu bestimmen und die Abwesenheit von Operationen ordnungsgemäß zu behandeln. Die generischen Tests sollten in der Lage sein, die Grundlagen von Klassen zu erfassen, die ein Konzept modellieren. Offensichtlich erfordert ein spezifisches Verhalten für Klassen immer noch entsprechende Tests.

Parallele Programmierung kann verwendet werden, um Multi-Core- und heterogene Architekturen zu nutzen und die Leistung von Software erheblich zu steigern. Modernes C ++ hat viel dazu beigetragen, die parallele Programmierung einfacher und zugänglicher zu machen. Bereitstellung von Abstraktionen auf hoher und niedriger Ebene. C ++ 17 geht noch einen Schritt weiter und bietet parallele Algorithmen auf hoher Ebene. In C ++ 20 wird noch viel mehr erwartet. Dieser Vortrag gibt einen Überblick über die derzeit verfügbaren Parallelitätsdienstprogramme und gibt einen Überblick über die Zukunft, wie GPUs und heterogene Systeme durch neue Standardbibliotheksfunktionen und andere Standards wie SYCL unterstützt werden können.
Die C ++ - Sprache und die damit verbundene Infrastruktur entwickeln sich weiter, was diese Sprache derzeit zu einem der effektivsten Tools macht. Ich möchte drei Faktoren hervorheben, die die C ++ - Sprache jetzt so attraktiv machen.
- Erstens: Innovationen im Sprachstandard, mit denen Sie effizienten Code schreiben können.
- Zweitens: die Reife der Entwicklungswerkzeuge und eine Beschleunigung der Montage von Projekten.
- Drittens: ausgereifte Support-Tools, mit denen Sie die Qualität des Codes und andere Aspekte des Projektlebenszyklus steuern können.
Dieser Bericht ist eine Ode an die Programmiersprache C ++!

Auf dem Gebiet der Entwicklung hoch geladener Multithread- oder verteilter Anwendungen kann man zunehmend Gespräche über asynchronen Code hören, einschließlich Spekulationen über die Notwendigkeit (mangelnde Notwendigkeit), die Asynchronität im Code zu berücksichtigen, über die Verständlichkeit (Unverständlichkeit) von asynchronem Code und dessen Effizienz (Ineffizienz). In diesem Bericht werden wir versuchen, tiefer in den Themenbereich einzutauchen: Wir werden analysieren, was Asynchronität ist; wenn es entsteht; wie sich dies auf den von uns geschriebenen Code und die von uns verwendete Programmiersprache auswirkt. Wir werden versuchen herauszufinden, was Zukunft und Versprechen damit zu tun haben. Lassen Sie uns ein wenig über Coroutinen und Schauspieler sprechen. Wir werden JavaScript und Betriebssysteme beeinflussen. Der Zweck des Berichts besteht darin, die Kompromisse, die sich aus dem einen oder anderen Ansatz bei der Entwicklung von Multithread- oder verteilter Software ergeben, deutlicher zu machen.

In dem Bericht wird der aktuelle Status von WebAssembly in Bezug auf reale Produkte erörtert. Wir werden über unsere Erfahrungen mit der Portierung der Anwendung sprechen, darüber, welche Probleme aufgetreten sind und wie wir sie gelöst haben.
Zu den behandelten Themen gehören:
- Unterstützung für den Standard auf verschiedenen Plattformen und Browsern.
- Leistung und Build-Größe im Vergleich zu asm.js.
- Interaktionen mit dem Browser.
- Build stürzt vom Benutzer ab.
- VM-Funktionen.
Das CMake-Build-System wird allmählich zum De-facto-Standard für die plattformübergreifende C ++ - Programmierung. Es wird jedoch häufig fair kritisiert, unter anderem wegen der unbequemen Skriptsprache, der veralteten Dokumentation und der Tatsache, dass dieselben Aufgaben auf unterschiedliche Weise ausgeführt werden können und es ziemlich schwierig sein kann zu verstehen, welche in einer bestimmten Situation korrekter ist . Der Autor wird sagen:- häufige populäre Anti-Muster und warum sie schlecht sind,
- Auf welchen Abstraktionsebenen funktioniert CMake und wann „lecken“ sie?
- Was ist "Modern CMake" und was sind seine Vorteile?
- Lokalisieren und Debuggen von Problemen in CMake-Skripten (einschließlich einiger eher exotischer).
Die klare Architektur des Projekts, einfache Abstraktionen auf jeder Ebene ist der Traum eines jeden Teams. Um diesen Traum zu verwirklichen, wurden viele objektorientierte Techniken erfunden. Von OOP mitgenommen, vergessen Entwickler, die Sauberkeit des Codes an der Kreuzung von C und C ++ zu überwachen. Hier hilft der prozedurale Stil dabei, die Ordnung wiederherzustellen, bequeme und sichere Abstraktionen zu erstellen, die leicht in den objektorientierten Code des Projekts passen. Wir werden herausfinden:- Warum müssen Sie die C-API isolieren (z. B. Winapi, POSIX, SQLite, OpenGL, OpenSSL)?
- Warum arbeitet OOP in diesem Geschäft schlecht?
- Wie schreibe ich eine Abstraktionsschicht über die API im C-Stil?
- Umgang mit Rückrufen, Fehlerbehandlung und Ressourcenverwaltung, um traditionell komplexen und verwirrenden Code auch für Junioren verständlich zu machen
Seine beruflichen Interessen sind die Semantik von Programmiersprachen, das Design und die Implementierung von Compilern von YaP und anderen sprachorientierten Tools. Zu den wichtigsten Errungenschaften zählen die Teilnahme an Projekten wie die Erstellung eines Compilers des vollständigen C ++ - Sprachstandards (Interstron, Moskau, 2000), die Implementierung des Zonnon-Sprachcompilers für .NET (ETH Zürich, 2005) und die Implementierung des Prototyps Swift-Compiler für die Tizen-Plattform ( Samsung Research Institute, Moskau, 2015).C ++ hatte schon immer eine leistungsstarke Subsprache für die Meta-Programmierung, die es Bibliotheksentwicklern ermöglichte, magische Leistungen wie statische Selbstbeobachtung auszuführen, um eine polymorhpische Ausführung ohne Vererbung zu erreichen. Das Problem war, dass die Syntax umständlich und unnötig ausführlich war, was das Erlernen der Metaprogrammierung zu einer entmutigenden Aufgabe machte.Mit den jüngsten Verbesserungen des Standards und den für C ++ 20 geplanten Funktionen ist die Metaprogrammierung viel einfacher geworden, und Metaprogramme sind leichter zu verstehen und zu verstehen.In diesem Vortrag stellt der Autor einige moderne Techniken der Metaprogrammierung vor, wobei der Schwerpunkt auf der magischen Metafunktion void_t liegt.Der Autor des Berichts ist seit 16 Jahren für die Entwicklung des Open-Source-SObjectizer-Frameworks verantwortlich. Dies ist eines der wenigen Live- und plattformübergreifenden Akteur-Frameworks für C ++. Die Entwicklung von SObjectizer begann im Jahr 2002, als C ++ zu den beliebtesten und gebräuchlichsten Programmiersprachen gehörte. In der letzten Zeit hat sich C ++ stark verändert, und die Einstellung zu C ++ hat sich noch mehr verändert. In dem Bericht wird erörtert, wie sich diese Änderungen auf die Entwicklung eines Tools mit einer 16-jährigen Geschichte auswirkten und wie einfach und bequem es war, ein solches Tool für die C ++ - Sprache zu erstellen. Und ob es notwendig war, ein solches Tool für C ++ im Allgemeinen zu erstellen.
- Üben Sie die Verwendung des Model-View-Presenter-Musters
- Document Lifecycle Management
- Smart Pointers-Dateispeicherung
Hier und da tauchen regelmäßig Nachrichten über die nächste Sicherheitslücke auf. Die Kollateralverluste von $ sind in der Regel enorm. Anstatt Schwachstellen zu beheben, sollten sie daher nicht angezeigt werden.
Eine Möglichkeit, mit Codefehlern umzugehen, ist die statische Analyse. Aber wie geeignet ist es, nach Schwachstellen zu suchen? Und gibt es wirklich einen großen Unterschied zwischen einfachen Fehlern und Code-Schwachstellen?
Wir werden diese Probleme während des Berichts erörtern und gleichzeitig darüber sprechen, wie statische Analysen verwendet werden, um das Beste daraus zu machen.
PSIch möchte Sie alleine auf die Mini-Intrige um
std :: string aufmerksam machen, die sich auf die Berichte meines Kollegen Andrei Karpov bezieht. Also in der Reihenfolge:
- Ein Fragment von Andrei's Bericht (C ++ Russia 2016) "Private Geschichten von Code Analyzer-Entwicklern" von 30:05 - Link .
- Einfaches Trolling von Menschen wie uns von Anton Polukhin (C ++ Russland 2017) im Bericht „Wie man es nicht macht: C ++ Fahrradbau für Profis“ ab 2:00 - Link .
- Andreys Geschichte auf der C ++ Russia 2018 Konferenz, dass wir keine Dinosaurier sind und etwas Neues lernen: "Effective C ++" ab 12:21 - Link .
Das ist alles! Viel Spaß mit Ihren Berichten.