Unser Unternehmen SberTech (Sberbank Technologies) verwendet derzeit HDFS 2.8.4, da es eine Reihe von Vorteilen bietet, wie das Hadoop-Ökosystem, die schnelle Arbeit mit großen Datenmengen, die gute Analyse und vieles mehr. Im Dezember 2017 veröffentlichte die Apache Software Foundation eine neue Version des Open-Source-Frameworks für die Entwicklung und Ausführung verteilter Programme - Hadoop 3.0.0, das eine Reihe bedeutender Verbesserungen gegenüber der vorherigen Hauptversionslinie (hadoop-2.x) enthält. Eines der wichtigsten und interessantesten Updates für uns ist die Unterstützung von Redundanzcodes (Erasure Coding). Daher wurde die Aufgabe festgelegt, diese Versionen miteinander zu vergleichen.
SberTech hat für diese Forschungsarbeit 10 virtuelle Maschinen mit jeweils 40 GB bereitgestellt. Da für die RS (10.4) -Codierungsrichtlinie mindestens 14 Computer erforderlich sind, funktioniert das Testen nicht.
Auf einem der Computer befindet sich NameNode zusätzlich zum DataNode. Die Tests werden mit den folgenden Codierungsrichtlinien durchgeführt:
- XOR (2.1)
- RS (3,2)
- RS (6,3)
Außerdem wird die Replikation mit einem Replikationsfaktor von 3 verwendet.
Die Datenblockgröße wurde gleich 32 MB gewählt.
Forschung
Datenratentest
Tests für Datenübertragungsraten wurden durchgeführt. Die Daten wurden vom lokalen Dateisystem in das verteilte Dateisystem übertragen. Die in diesem Test verwendete Dateigröße beträgt 292,2 MB.
Die folgenden Ergebnisse wurden erhalten:
Ein Diagramm der gruppierten empfangenen Werte der Dateiübertragungszeit wird ebenfalls erstellt:

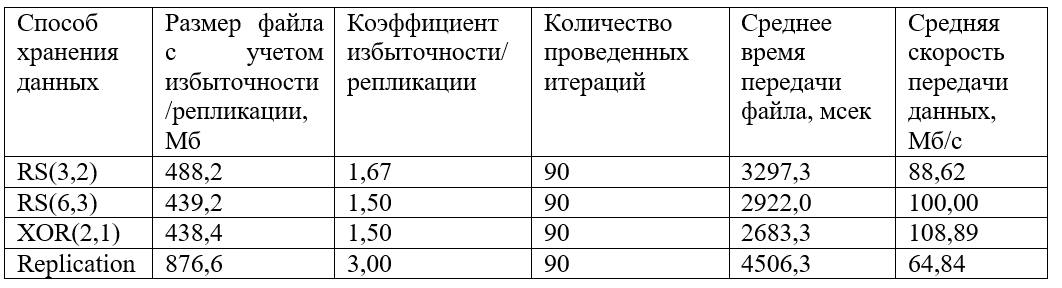
Und auch ein Diagramm der gruppierten empfangenen Datenraten:
Wie aus der Grafik ersichtlich ist, werden die schnellsten Daten mit XOR (2,1) codiert übertragen. Die Codierungen RS (6.3) und RS (3.2) zeigen ein ähnliches Verhalten, obwohl der durchschnittliche Geschwindigkeitswert für RS (6.3) etwas höher ist. Die Replikation verliert stark an Geschwindigkeit (etwa 1,5-mal weniger als XOR und 1,5-mal weniger als RS).
In Bezug auf die Speichereffizienz sind XOR (2.1) und RS (6.3) die rentabelsten Speichermethoden. Redundante Daten machen nur 50% aus. Die Replikation mit einem Replikationsverhältnis von 3 verliert erneut und speichert 200% der redundanten Daten.
Leistungstest
Im vorherigen Test wurde der Status der Server mit dem Grafana-Überwachungstool überwacht.
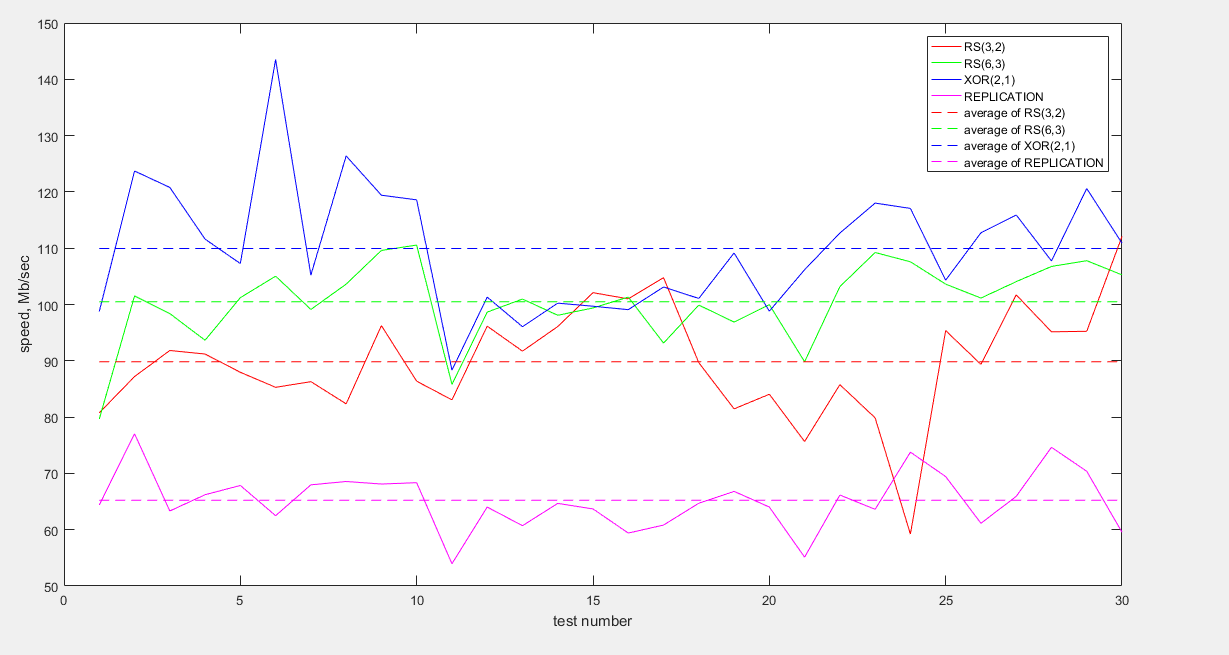
Unten sehen Sie eine Grafik, die die CPU-Auslastung während der Datenübertragungstests zeigt:
Wie aus der Grafik ersichtlich ist, verbraucht in diesem Test auch die RS (6.3) -Codierung die geringsten Ressourcen. Die Replikation zeigt erneut das schlechteste Ergebnis.
Ressourcenverbrauch bei der Datenwiederherstellung
Um diesen Test durchzuführen, wurde eine bestimmte Datenmenge in das verteilte Hadoop-Dateisystem hochgeladen. Dann wurden zwei Maschinen mit einem DataNode weggelassen.
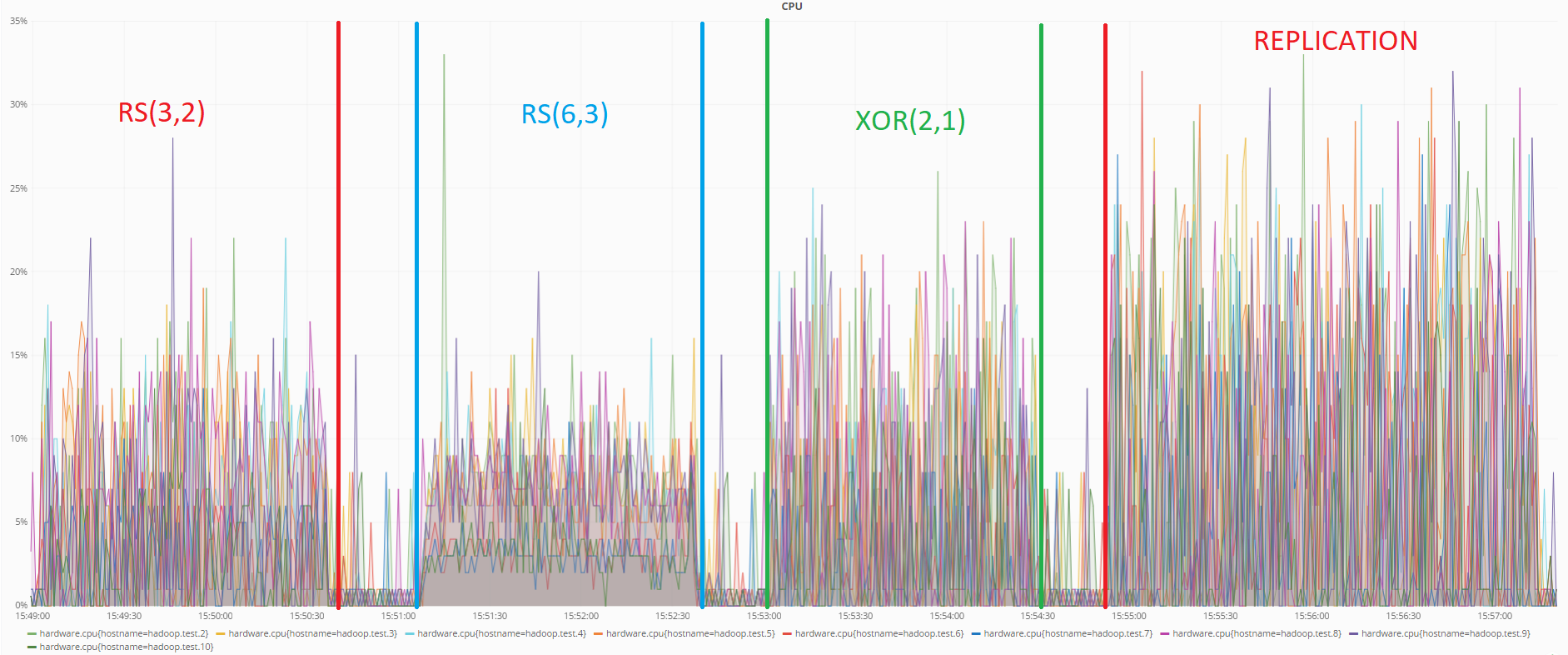
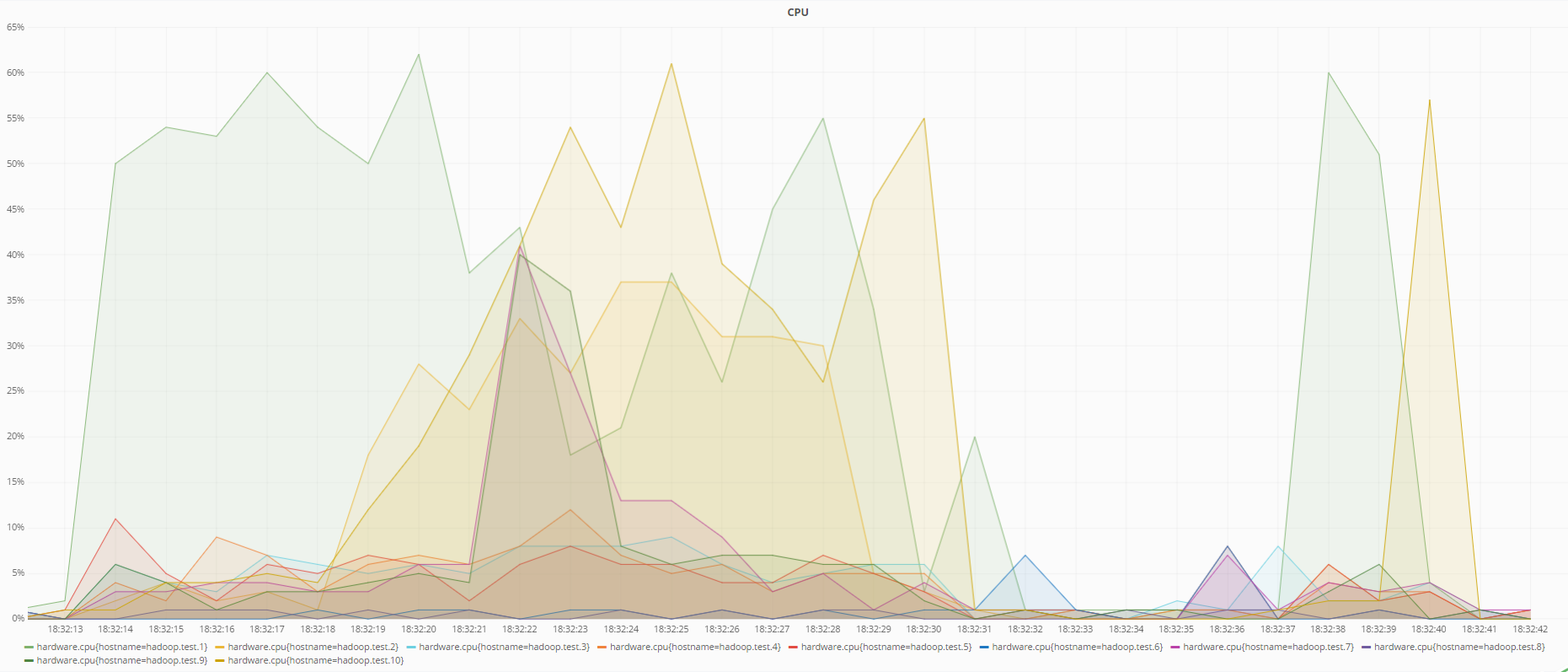
Nachfolgend finden Sie Diagramme zum Status der Computer zum Zeitpunkt der Datenwiederherstellung mit RS (6.3) -Codierung und bei Verwendung der Replikation:
Status des Prozessors während der Datenwiederherstellung mit RS-Codierung (6.3)

CPU-Status während der Datenwiederherstellung mithilfe der Replikation
Wie aus den Diagrammen ersichtlich ist, lädt die RS (6.3) -Codierung den Prozessor mehr als die Replikation während der Datenwiederherstellung, was logisch ist, da zur Wiederherstellung verlorener Daten unter Verwendung redundanter Codes die inverse Redundanzmatrix berechnet werden muss, die mehr Ressourcen als nur das Überschreiben verbraucht Daten von einem anderen DataNode im Falle einer Replikation.
Testergebnisse:
- Für Datenübertragungsraten ist es am besten, die XOR (2.1) - oder RS (6.3) -Codierung zu verwenden
- Bei der Datenübertragung lädt der Prozessor die Codierung RS (6.3) und RS (3.2) am wenigsten.
- Bei der Wiederherstellung von Daten wird der Prozessor am wenigsten durch die Verwendung der Replikation belastet.
- Die kompakteste Art, Daten zu speichern, sind RS (6.3) - und XOR (2.1) -Codierungen
Die zuverlässigste Speichermethode ist die RS (6.3) -Codierung, da Sie bis zu drei Computer ohne Datenverlust verlieren können und die Replikation mit einem Replikationskoeffizienten von 3 den Ausfall von bis zu zwei Computern unterstützt. XOR (2, 1) ist die unzuverlässigste Methode zum Speichern von Daten, da Sie maximal einen Computer verlieren können.
Fazit
Die Hauptziele der Verwendung des verteilten Dateisystems in SberTech sind:
- Hohe Zuverlässigkeit
- Minimierung der Kosten für die Wartung von Servern zur Datenspeicherung
- Bereitstellung von Datenanalysetools
Basierend auf den Ergebnissen der Analyse werden die folgenden Schlussfolgerungen gezogen:
- HDFS 3 übertrifft die Zuverlässigkeit gegenüber HDFS 2.
- HDFS 3 gewinnt durch Minimierung der Serverwartungskosten, da Daten kompakter gespeichert werden.
- HDFS 3 verfügt über dasselbe Toolset für die Datenanalyse wie HDFS 2.
In diesem Zusammenhang wurde der Schluss gezogen, dass HDFS 3 ein rationaler Ersatz für HDFS 2 ist.
Verwendete Quellen: