Hallo! Mein Name ist Denis Kiryanov, ich arbeite bei Sberbank und beschäftige mich mit den Problemen der Verarbeitung natürlicher Sprache (NLP). Einmal mussten wir einen syntaktischen Parser für die Arbeit mit der russischen Sprache auswählen. Zu diesem Zweck haben wir uns mit der Wildnis der Morphologie und Tokenisierung befasst, verschiedene Optionen getestet und ihre Anwendung bewertet. Wir teilen unsere Erfahrungen in diesem Beitrag.

Vorbereitung zur Auswahl
Beginnen wir mit den Grundlagen: Wie funktioniert es? Wir nehmen den Text, führen die Tokenisierung durch und erhalten eine Reihe von Pseudo-Token. Die Stufen der weiteren Analyse passen in eine Pyramide:
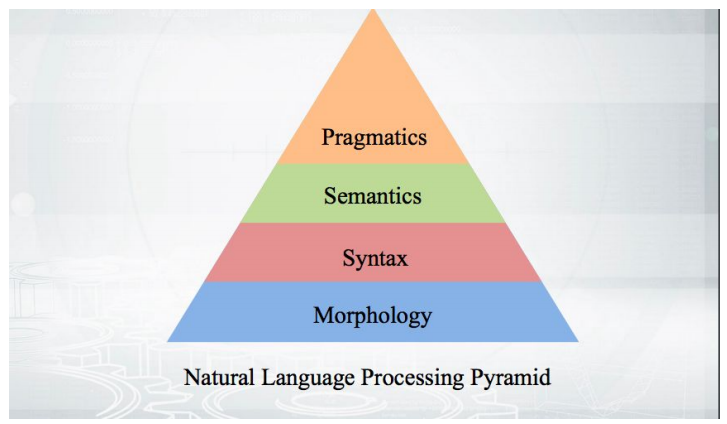
Alles beginnt mit der Morphologie - mit einer Analyse der Form eines Wortes und seiner grammatikalischen Kategorien (Geschlecht, Fall usw.). Die Morphologie basiert auf Syntax - Beziehungen jenseits der Grenzen eines Wortes zwischen Wörtern. Die syntaktischen Parser, die diskutiert werden, analysieren den Text und geben die Struktur der Abhängigkeiten der Wörter voneinander an.
Grammatik der Abhängigkeiten und Grammatik der unmittelbaren Komponenten
Es gibt zwei Hauptansätze für das Parsen, die in der Sprachtheorie gleichberechtigt existieren.

In der ersten Zeile wird der Satz als Teil der Abhängigkeitsgrammatik analysiert. Dieser Ansatz wird in der Schule gelehrt. Jedes Wort in einem Satz ist irgendwie mit anderen verbunden. "Seifen" - ein Prädikat, von dem das Fach "Mutter" abhängt (hier weicht die Grammatik der Abhängigkeiten von der Schule ab, in der das Prädikat vom Fach abhängt). Das Thema hat eine abhängige Definition von "meins". Das Prädikat hat einen abhängigen direkten Komplement- "Rahmen". Und die direkte Ergänzung zum "Rahmen" - die Definition von "schmutzig".
In der zweiten Zeile entspricht die Analyse der Grammatik der Komponenten selbst.
Ihr zufolge ist der Satz in Gruppen von Wörtern (Phrasen) unterteilt. Wörter innerhalb einer Gruppe sind enger miteinander verbunden. Die Wörter "meine" und "Mutter" sind enger verwandt, "Rahmen" und "schmutzig" - auch. Und es gibt noch eine separate "Seife".
Der zweite Ansatz zum automatischen Parsen der russischen Sprache ist schlecht anwendbar, da darin eng verwandte Wörter (Mitglieder derselben Gruppe) sehr oft nicht hintereinander stehen. Wir müssten sie mit seltsamen Klammern kombinieren - in ein oder zwei Worten. Daher ist es beim automatischen Parsen der russischen Sprache üblich, auf der Grundlage der Grammatik der Abhängigkeiten zu arbeiten. Dies ist auch deshalb praktisch, weil jeder mit einem solchen „Rahmen“ in der Schule vertraut ist.
Abhängigkeitsbaum
Wir können eine Reihe von Abhängigkeiten in eine Baumstruktur übersetzen. Die Spitze ist das Wort "Seife", einige Wörter hängen direkt davon ab, andere hängen von seinen Süchtigen ab. Hier ist die
Definition des Abhängigkeitsbaums aus dem Lehrbuch von Martin und Zhurafsky:
Der Abhängigkeitsbaum ist ein gerichteter Graph, der die folgenden Einschränkungen erfüllt:- Es gibt einen einzelnen festgelegten Wurzelknoten ohne eingehende Bögen.
- Mit Ausnahme des Wurzelknotens hat jeder Scheitelpunkt genau einen eingehenden Bogen.
- Es gibt einen eindeutigen Pfad vom Wurzelknoten zu jedem Scheitelpunkt in V.
Es gibt einen Knoten der obersten Ebene - ein Prädikat. Daraus können Sie jedes Wort erreichen. Jedes Wort hängt von einem anderen ab, aber nur von einem. Der Abhängigkeitsbaum sieht ungefähr so aus:

In diesem Baum werden Kanten mit einer bestimmten Art von syntaktischer Beziehung signiert. In der Grammatik der Abhängigkeiten wird nicht nur die Tatsache der Verbindung zwischen Wörtern analysiert, sondern auch die Art dieser Verbindung. Zum Beispiel ist "genommen" fast eine Verbform, "Inventar" ist das Thema für "genommen". Dementsprechend haben wir eine "Ist" -Kante in die eine und die andere Richtung. Dies sind nicht die gleichen Verbindungen, sie sind unterschiedlicher Natur, daher müssen sie unterschieden werden.
Im Folgenden betrachten wir einfache Fälle, in denen Mitglieder eines Satzes anwesend sind, nicht impliziert. Es gibt Strukturen und Markierungen, um mit Pässen umzugehen. Im Baum erscheint etwas, das keinen oberflächlichen Ausdruck hat - ein Wort. Dies ist jedoch Gegenstand einer anderen Studie, aber wir müssen uns immer noch auf unsere eigenen konzentrieren.
Universal Dependencies Project
Um die Auswahl eines Parsers zu erleichtern, haben wir unsere Aufmerksamkeit auf das
Universal Dependencies- Projekt und den
CoNLL Shared Task- Wettbewerb gerichtet, der kürzlich in seinem Rahmen stattfand.
Universal Dependencies ist ein Projekt zur Vereinheitlichung des Markups syntaktischer Korpusse (Tribanks) im Rahmen der Abhängigkeitsgrammatik. Im Russischen ist die Anzahl der Arten syntaktischer Links begrenzt - Betreff, Prädikat usw. Auf Englisch das gleiche, aber das Set ist schon anders. Dort erscheint beispielsweise ein Artikel, der auch irgendwie beschriftet werden muss. Wenn wir einen magischen Parser schreiben wollten, der alle Sprachen beherrscht, würden wir schnell auf Probleme beim Vergleich verschiedener Grammatiken stoßen. Den heldenhaften Schöpfern von Universal Dependencies gelang es, sich zu einigen und alle Gebäude, die ihnen zur Verfügung standen, in einem einzigen Format zu markieren. Es ist nicht sehr wichtig, wie sie sich einig waren. Hauptsache, wir haben am Ausgang ein bestimmtes einheitliches Format für die Präsentation dieser ganzen Geschichte erhalten -
mehr als 100 Tribanks für 60 Sprachen .
CoNLL Shared Task ist ein Wettbewerb zwischen Entwicklern von Parsing-Algorithmen, der im Rahmen des Universal Dependencies-Projekts durchgeführt wird. Die Organisatoren nehmen eine bestimmte Anzahl von Tribanks und teilen sie in drei Teile - Training, Validierung und Test. Der erste Teil wird den Teilnehmern des Wettbewerbs zur Verfügung gestellt, damit sie ihre Modelle darauf trainieren können. Der zweite Teil wird auch von den Teilnehmern verwendet, um die Funktionsweise des Algorithmus nach dem Training zu bewerten. Die Teilnehmer können das Training und die Bewertung iterativ wiederholen. Dann geben sie ihren besten Algorithmus an die Organisatoren weiter, die ihn auf dem Testteil ausführen, der für die Teilnehmer geschlossen ist. Die Ergebnisse der Modelle auf den Testteilen der Tribanks sind die Ergebnisse des Wettbewerbs.
Qualitätsmetriken
Wir haben Verbindungen zwischen Wörtern und ihren Typen. Wir können bewerten, ob das Wort oben korrekt gefunden wurde - die UAS-Metrik (Unlabeled Attachment Score). Oder um zu bewerten, ob sowohl der Scheitelpunkt als auch die Art der Abhängigkeit korrekt gefunden wurden - die LAS-Metrik (Labeled Attachment Score).

Es scheint, dass sich hier eine Genauigkeitsbewertung anbietet - wir überlegen, wie oft wir von der Gesamtzahl der Fälle erhalten haben. Wenn wir 5 Wörter haben und für 4 die Spitze korrekt bestimmt haben, erhalten wir 80%.
Die tatsächliche Bewertung des Parsers in seiner reinen Form ist jedoch problematisch. Entwickler, die die Probleme der automatischen Analyse lösen, verwenden häufig Rohtext als Eingabe, der gemäß der Analysepyramide die Phasen der Tokenisierung und morphologischen Analyse durchläuft. Fehler aus diesen früheren Schritten können die Qualität des Parsers beeinträchtigen. Dies gilt insbesondere für das Tokenisierungsverfahren - Wortzuweisung. Wenn wir die falschen Einheitswörter identifiziert haben, können wir die syntaktischen Beziehungen zwischen ihnen nicht mehr richtig bewerten - schließlich waren die Einheiten in unserem ursprünglich beschrifteten Korps unterschiedlich.
Daher ist die Bewertungsformel in diesem Fall das f-Maß, wobei Genauigkeit der Anteil genauer Treffer an der Gesamtzahl der Vorhersagen und Vollständigkeit der Anteil genauer Treffer an der Anzahl der Links in den markierten Daten ist.
Wenn wir in Zukunft Schätzungen abgeben, müssen wir berücksichtigen, dass die verwendeten Metriken nicht nur die Syntax, sondern auch die Qualität der Tokenisierung beeinflussen.
Russische Sprache bei Universal Dependencies
Damit der Parser Sätze, die er noch nicht gesehen hat, syntaktisch markieren kann, muss er den markierten Korpus für das Training füttern. Für die russische Sprache gibt es mehrere solcher Fälle:

Die zweite Spalte gibt die Anzahl der Token - Wörter an. Je mehr Token, desto mehr Trainingskorps und desto besser der endgültige Algorithmus (wenn dies gute Daten sind). Offensichtlich werden alle Experimente mit SynTagRus (entwickelt von IPPI RAS) durchgeführt, in dem sich mehr als eine Million Token befinden. Alle Algorithmen werden darauf trainiert, was später besprochen wird.
Parser für Russisch in CoNLL Shared Task
Nach den Ergebnissen des letztjährigen
Wettbewerbs erreichten Modelle, die auf demselben SynTagRus trainiert wurden, die folgenden LAS-Indikatoren:

Die Ergebnisse von Parsern für Russisch sind beeindruckend - sie sind besser als die von Parsern für Englisch, Französisch und andere seltenere Sprachen. Wir hatten aus zwei Gründen gleichzeitig großes Glück. Erstens machen die Algorithmen einen guten Job mit der russischen Sprache. Zweitens haben wir SynTagRus - ein großes und markiertes Gehäuse.
Der Wettbewerb von 2018 ist übrigens bereits vorbei, aber wir haben unsere Forschung im Frühjahr dieses Jahres durchgeführt, sodass wir uns auf die Ergebnisse der Strecke des letzten Jahres verlassen. Mit Blick auf die Zukunft stellen wir fest, dass die
neue Version von UDPipe (Future) in diesem Jahr noch höher ausfiel.
Syntaxnet, ein Google-Parser, ist nicht auf der Liste. Was ist los mit ihm? Die Antwort ist einfach: Syntaxnet begann erst mit dem Stadium der morphologischen Analyse. Er nahm eine vorgefertigte ideale Tokenisierung und baute bereits eine Verarbeitung darauf auf. Daher ist es unfair, es auf Augenhöhe mit dem Rest zu bewerten - der Rest hat die Aufteilung in Token mit eigenen Algorithmen durchgeführt, was die Ergebnisse in der nächsten Stufe der Syntax verschlechtern könnte. Die Stichprobe 2017 von Syntaxnet hat ein besseres Ergebnis als die gesamte obige Liste, aber direkte Vergleiche sind nicht fair.
Die Tabelle enthält zwei Versionen von UDPipe an 12 und 15 Stellen. Dieselben Personen, die aktiv am Universal Dependencies-Projekt teilgenommen haben, entwickeln diesen Parser.
UDPipe-Updates werden regelmäßig angezeigt (etwas seltener wird übrigens auch das Layout der Fälle aktualisiert). Nach dem Wettbewerb im letzten Jahr wurde UDPipe aktualisiert (dies waren Commits für Version 2.0, die noch nicht veröffentlicht wurden. Der Einfachheit halber werden wir uns in Zukunft grob auf das UDPipe 2.0-Commit beziehen, das wir übernommen haben, obwohl dies streng genommen nicht der Fall ist). Natürlich gibt es keine derartigen Aktualisierungen in der Wettbewerbstabelle. Das Ergebnis von „unserem“ Commit liegt ungefähr auf dem siebten Platz.
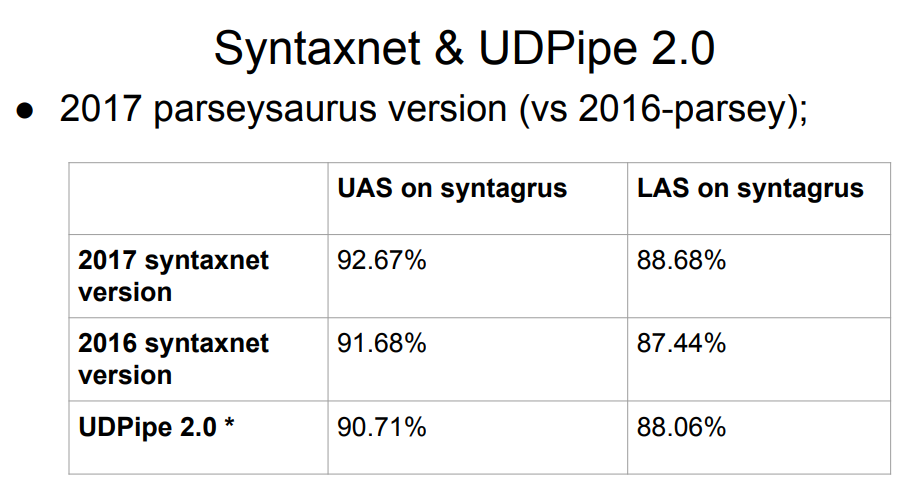
Wir müssen also einen Parser für die russische Sprache auswählen. Als erste Daten haben wir die Platte oben mit dem führenden Syntaxnet und mit UDPipe 2.0 irgendwo auf dem 7. Platz.
Wählen Sie ein Modell
Wir machen es einfach: Wir beginnen mit dem Parser mit den höchsten Raten. Wenn etwas mit ihm nicht stimmt, gehen Sie unten. Nach den folgenden Kriterien stimmt möglicherweise etwas nicht - vielleicht sind sie nicht perfekt, aber sie sind auf uns zugekommen:
- Arbeitsgeschwindigkeit . Unser Parser sollte schnell genug arbeiten. Die Syntax ist natürlich weit entfernt von dem einzigen Modul "unter der Haube" eines Echtzeitsystems, daher sollten Sie nicht mehr als ein Dutzend Millisekunden dafür aufwenden.
- Die Qualität der Arbeit . Der Parser selbst basiert mindestens auf Daten in russischer Sprache. Die Anforderung ist offensichtlich. Für die russische Sprache haben wir ziemlich gute morphologische Analysatoren, die in unsere Pyramide integriert werden können. Wenn wir sicherstellen können, dass der Parser selbst ohne Morphologie kühl funktioniert, passt dies zu uns - wir werden die Morphologie später verschieben.
- Verfügbarkeit eines Schulungscodes und vorzugsweise eines gemeinfreien Modells . Wenn wir einen Trainingscode haben, können wir die Ergebnisse des Autors des Modells wiederholen. Dazu müssen sie offen sein. Darüber hinaus müssen wir die Bedingungen für die Verteilung von Fällen und Modellen sorgfältig überwachen. Müssen wir eine Lizenz erwerben, um sie zu verwenden, wenn wir sie als Teil unserer Algorithmen verwenden?
- Starten Sie ohne zusätzlichen Aufwand . Dieser Artikel ist sehr subjektiv, aber wichtig. Was bedeutet das? Dies bedeutet, dass wir diesen Parser nicht auswählen können, wenn wir drei Tage sitzen und etwas starten, es aber nicht startet, selbst wenn es von perfekter Qualität ist.
Alles, was im Parser-Diagramm höher als UDPipe 2.0 war, passte nicht zu uns. Wir haben ein Python-Projekt und einige Parser aus der Liste sind nicht in Python geschrieben. Um sie im Python-Projekt zu implementieren, müssten die sehr großen Anstrengungen unternommen werden. In anderen Fällen waren wir mit Closed Source Code, akademischen und industriellen Entwicklungen konfrontiert - im Allgemeinen werden Sie nicht auf den Grund gehen.
Star Syntaxnet verdient eine separate Geschichte über die Qualität der Arbeit. Hier passte er nicht zu uns für die Geschwindigkeit der Arbeit. Die Zeit seiner Antwort auf einige einfache Sätze, die in Chats häufig vorkommen, beträgt 100 Millisekunden. Wenn wir so viel für Syntax ausgeben, haben wir nicht genug Zeit für etwas anderes. Gleichzeitig analysiert UDPipe 2.0 ~ 3 ms lang. Infolgedessen fiel die Wahl auf UDPipe 2.0.
UDPipe 2.0
UDPipe ist eine Pipeline, die Tokenisierung, Lemmatisierung, morphologische Markierung und Analyse der Abhängigkeitsgrammatik lernt. Wir können ihm das alles oder etwas separat beibringen. Erstellen Sie damit beispielsweise einen weiteren morphologischen Analysator für die russische Sprache. Oder trainieren und verwenden Sie UDPipe als Tokenizer.
UDPipe 2.0 ist detailliert dokumentiert. Es gibt eine
Beschreibung der Architektur , ein
Repository mit einem Trainingscode , ein
Handbuch . Am interessantesten sind die
vorgefertigten Modelle , auch für die russische Sprache. Herunterladen und ausführen. Auch auf dieser Ressource wurden die für jeden Sprachkorpus ausgewählten Trainingsparameter veröffentlicht. Für jedes dieser Modelle werden ungefähr 60 Trainingsparameter benötigt, und mit ihrer Hilfe können Sie unabhängig voneinander dieselben Qualitätsindikatoren wie in der Tabelle erzielen. Sie sind möglicherweise nicht optimal, aber wir können zumindest sicher sein, dass die Pipeline ordnungsgemäß funktioniert. Darüber hinaus ermöglicht uns das Vorhandensein einer solchen Referenz, ruhig mit dem Modell selbst zu experimentieren.
So funktioniert UDPipe 2.0
Zunächst wird der Text in Sätze und Sätze in Wörter unterteilt. UDPipe erledigt dies alles auf einmal mit Hilfe eines gemeinsamen Moduls - eines neuronalen Netzwerks (einschichtige zweiseitige GRU), das für jedes Zeichen vorhersagt, ob es das letzte in einem Satz oder in einem Wort ist.
Dann beginnt der Tagger mit der Arbeit - eine Sache, die die morphologischen Eigenschaften des Tokens vorhersagt: In welchem Fall ist das Wort, in welcher Zahl. Basierend auf den letzten vier Zeichen jedes Wortes generiert ein Tagger Hypothesen bezüglich eines Teils der Sprache und morphologischer Tags dieses Wortes und wählt dann mit Hilfe eines Perzeptrons die beste Option aus.
UDPipe hat auch einen Lemmatizer, der die ursprüngliche Form für Wörter auswählt. Er lernt das gleiche Prinzip kennen, nach dem ein Nicht-Muttersprachler versuchen könnte, das Lemma eines unbekannten Wortes zu bestimmen. Wir schneiden das Präfix und das Ende des Wortes ab, fügen ein „t“ hinzu, das in der Anfangsform des Verbs vorhanden ist usw. So werden die Kandidaten generiert, aus denen das beste Perzeptron auswählt.
Das morphologische Markierungsschema (Bestimmung der Anzahl, des Falls und alles andere) und die Vorhersagen der Deckspelzen sind sehr ähnlich. Sie können zusammen vorhergesagt werden, aber besser getrennt - die Morphologie der russischen Sprache ist zu reich. Sie können auch Ihre Liste der Deckspelzen verbinden.
Kommen wir zum interessantesten Teil - dem Parser. Es gibt mehrere Abhängigkeitsparser-Architekturen. UDPipe ist eine übergangsbasierte Architektur: Sie funktioniert schnell und durchläuft alle Token einmal in einer linearen Zeit.
Das syntaktische Parsen in einer solchen Architektur beginnt mit einem Stapel (wo am Anfang nur root steht) und einer leeren Konfiguration. Es gibt drei Standardmethoden zum Ändern:
- LeftArc - gilt, wenn das zweite Element des Stapels nicht root ist. Es behält die Beziehung zwischen dem Token oben im Stapel und dem zweiten Token bei und wirft auch das zweite Token aus dem Stapel aus.
- RightArc ist das gleiche, aber die Abhängigkeit wird in die andere Richtung erstellt und die Spitze wird verworfen.
- Shift - überträgt das nächste Wort aus dem Puffer auf den Stapel.
Unten finden Sie ein Beispiel für den Parser (
Quelle ). Wir haben den Satz "Buche mir den Morgenflug" und verbinden uns wieder damit:

Hier ist das Ergebnis:

Der klassische übergangsbasierte Parser verfügt über die drei oben aufgeführten Operationen: Einwegpfeil, Einwegpfeil und Verschiebung. Es gibt auch eine Swap-Operation, die in den grundlegenden übergangsbasierten Parser-Architekturen nicht verwendet wird, aber in UDPipe enthalten ist. Swap gibt das zweite Element des Stapels an den Puffer zurück, um das nächste aus dem Puffer zu entnehmen (sofern sie beabstandet sind). Dies hilft, ein paar Wörter zu überspringen und die richtige Verbindung wiederherzustellen.
Es gibt einen guten Artikel über den
Link der Person, die sich die Tauschoperation ausgedacht hat. Wir heben einen Punkt hervor: Trotz der Tatsache, dass wir wiederholt den anfänglichen Token-Puffer durchlaufen (d. H. Unsere Zeit ist nicht mehr linear), können diese Operationen so optimiert werden, dass die Zeit sehr nahe an linear zurückgegeben wird. Das heißt, vor uns ist nicht nur eine aus sprachlicher Sicht sinnvolle Operation, sondern auch ein Werkzeug, das die Arbeit des Parsers nicht wesentlich verlangsamt.
Anhand des obigen Beispiels haben wir die Operationen gezeigt, als Ergebnis erhalten wir eine Konfiguration - den Token-Puffer und die Verbindungen zwischen ihnen. Wir geben diese Konfiguration im aktuellen Schritt an den übergangsbasierten Parser weiter und damit sollte sie die Konfiguration im nächsten Schritt vorhersagen. Durch Vergleichen der Eingabevektoren und Konfigurationen bei jedem Schritt wird das Modell trainiert.
Deshalb haben wir einen Parser ausgewählt, der alle unsere Kriterien erfüllt, und sogar verstanden, wie er funktioniert. Wir fahren mit den Experimenten fort.
UDPipe-Probleme
Fragen wir einen kleinen Satz: "Übertragen Sie hundert Rubel an Mama". Das Ergebnis lässt Sie Ihren Kopf greifen.
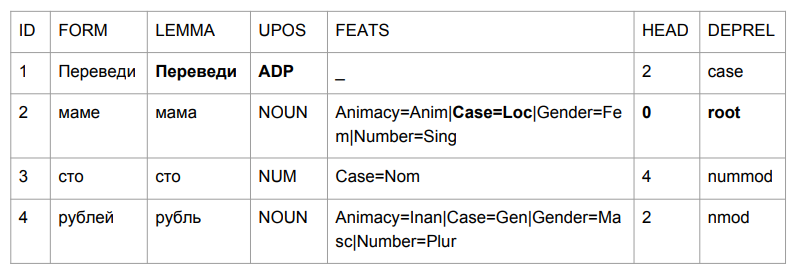
"Übersetzen" stellte sich als Ausrede heraus, aber das ist ziemlich logisch. Wir bestimmen die Grammatik der Wortform durch die letzten vier Zeichen. "Blei" ist so etwas wie "in der Mitte", daher ist die Wahl relativ logisch. Bei "Mama" ist es interessanter: "Mama" war im Präpositionalfall und wurde zum Höhepunkt dieses Satzes.
Wenn wir versuchen, alles basierend auf den Ergebnissen des Parsens zu interpretieren, erhalten wir so etwas wie "inmitten einer Mutter (deren Mutter? Wer ist diese Mutter?) Hunderte von Rubel". Nicht ganz das, was es am Anfang war. Wir müssen irgendwie damit umgehen. Und wir haben uns ausgedacht, wie.
In der Analysepyramide basiert die Syntax auf der Morphologie, basierend auf morphologischen Tags. Hier ist ein Lehrbuchbeispiel eines Linguisten L.V. Shcherby in dieser Hinsicht:
"Gloky Cuzdra Shteko Budlanula Bokra und lockiger kleiner Junge."Die Analyse dieses Vorschlags verursacht keine Probleme. Warum? Weil wir als UDPipe-Tagger das Ende eines Wortes betrachten und verstehen, auf welchen Teil der Sprache es sich bezieht und welche Form es hat. Die Geschichte mit „übersetzen“ als Ausrede widerspricht völlig unserer Intuition, aber es stellt sich als logisch heraus, wenn wir versuchen, dasselbe mit unbekannten Worten zu tun. Eine Person könnte genauso denken.
Wir werden den UDPipe-Tagger separat auswerten. Wenn es uns nicht passt, nehmen wir einen anderen Tagger, um das Parsing auf einem anderen morphologischen Markup aufzubauen.
Tagging aus einfachem Text (CoNLL17 F1-Punktzahl)- Goldformen: 301639 ,
- upostag: 98,15% ,
- xpostag: 99,89% ,
- Kunststücke: 93,97% ,
- Alltags: 93,44% ,
- Deckspelzen: 96,68%
Die Morphologiequalität von UDPipe 2.0 ist nicht schlecht. Aber für die russische Sprache ist es erreichbar besser. Der Mystem-Analysator (die
Entwicklung von Yandex ) erzielt bessere Ergebnisse bei der Bestimmung von Sprachteilen als UDPipe. Darüber hinaus sind andere Analysegeräte in einem Python-Projekt schwieriger zu implementieren und arbeiten langsamer mit einer mit Mystem vergleichbaren Qualität. ,
.
UDPipe. . , Mystem . , « » «» — «», «». . , «», (), , . :
- « » —
- « » — ..
- « - » — (- )
In solchen Fällen gibt Mystem ehrlich die gesamte Kette:
m.analyze(" ")
[{'analysis': [{'lex': '', 'gr': 'PART='}], 'text': ''},
{'text': ' '},
{'analysis': [{'lex': '', 'gr': 'S,,=(,|,|,)'}],
'text': ''},
{'text': '\n'}]
Wir können jedoch nicht die gesamte Pipe-Kette an UDPipe senden, sondern müssen ein besseres Tag angeben. Wie wähle ich es aus? Wenn Sie nichts anfassen, möchte ich das erste nehmen, vielleicht funktioniert es. Die Tags sind jedoch alphabetisch nach den englischen Namen sortiert, sodass unsere Auswahl nahezu zufällig ist und einige Parses fast die Chance verlieren, die Ersten zu sein.
Es gibt einen Analysator, der die beste Option bietet - Pymorphy2. Aber mit einer Analyse der Morphologie ist er schlimmer. Außerdem gibt er das beste Wort aus dem Zusammenhang. Pymorphy2 gibt nur eine Analyse für "kein Regisseur", "siehe Regisseur" und "Regisseur" aus. Es wird nicht zufällig sein, aber wirklich die beste Wahrscheinlichkeit, die in pymorphy2 in einem separaten Textkörper berücksichtigt wurde. Ein gewisser Prozentsatz falscher Analysen von Kampftexten wird jedoch garantiert, einfach weil sie Sätze mit unterschiedlichen realen Formen enthalten können: sowohl "Ich sehe den Regisseur" als auch "Die Direktoren sind zu dem Treffen gekommen" und "Es gibt keinen Regisseur". Eine kontextlose Parsing-Wahrscheinlichkeit passt nicht zu uns.
Wie erhalte ich kontextuell die besten Tags? Verwendung des
RNNMorph- Analysators. Nur wenige Leute hörten von ihm, aber letztes Jahr gewann er den Wettbewerb unter morphologischen Analysatoren, der im Rahmen der Dialogkonferenz abgehalten wurde.
RNNMorph hat sein eigenes Problem: Es hat keine Tokenisierung. Wenn Mystem Rohtext tokenisieren kann, benötigt RNNMorph eine Liste von Token an der Eingabe. Um zur Syntax zu gelangen, müssen Sie zuerst einen externen Tokenizer verwenden, dann das Ergebnis an RNNMorph weitergeben und erst dann die resultierende Morphologie dem Syntaxparser zuführen.
Hier sind die Optionen, die wir haben. Wir werden die kontextlose Analyse von pymorphy2 vorerst nicht über umstrittene Fälle im Mystem ablehnen - plötzlich wird sie nicht weit hinter RNNMorph zurückbleiben. Wenn wir sie jedoch nur auf der Ebene der Qualität des morphologischen
Markups vergleichen (Daten von
MorphoRuEval-2017 ), ist der Verlust signifikant - etwa 15%, wenn wir die Genauigkeit gemäß den Worten nehmen.
Als nächstes müssen wir die Ausgabe von Mystem in das Format konvertieren, das UDPipe versteht - conllu. Und wieder ist dies ein Problem, sogar bis zu zwei. Rein technisch - die Linien stimmen nicht überein. Und konzeptionell - es ist nicht immer ganz klar, wie man sie vergleicht. Bei zwei verschiedenen Markups von Sprachdaten werden Sie mit ziemlicher Sicherheit auf das Problem des Tag-Abgleichs stoßen (siehe die folgenden Beispiele). Die Antworten auf die Frage „Welches Tag ist hier richtig?“ Können unterschiedlich sein, und wahrscheinlich hängt die richtige Antwort von der Aufgabe ab. Aufgrund dieser Inkonsistenz ist das Anpassen von Markup-Systemen an sich keine leichte Aufgabe.
Wie konvertiere ich? Es gibt
das Paket russian_tagsets _ - ein Paket für Python, das verschiedene Formate konvertieren kann. Es gibt keine Übersetzung aus dem Format der Ausgabe von Mystem an Conllu, das in Universal Dependencies akzeptiert wird, aber es gibt eine Übersetzung an conllu, beispielsweise aus dem Markup-Format des nationalen Korpus der russischen Sprache (und umgekehrt). Der Autor des Pakets (er ist übrigens der Autor von pymorphy2) hat eine wunderbare Sache direkt in die Dokumentation geschrieben: "Wenn Sie dieses Paket nicht verwenden können, verwenden Sie es nicht." Er tat dies nicht, weil der krivorukov-Programmierer (er ist ein ausgezeichneter Programmierer!), Sondern weil Sie, wenn Sie einen in einen anderen konvertieren müssen, aufgrund sprachlicher Inkonsistenzen der Markup-Konventionen Probleme bekommen könnten.
Hier ist ein Beispiel. Der Schule wurde die "Kategorie der Bedingung" (kalt, notwendig) beigebracht. Einige sagen, es sei ein Adverb, andere sagen ein Adjektiv. Sie müssen dies konvertieren und einige Regeln hinzufügen, aber dennoch keine eindeutige Entsprechung zwischen einem Format und einem anderen erzielen.
Ein weiteres Beispiel: ein Versprechen (entweder hat jemand etwas getan oder etwas mit jemandem getan). "Petya hat jemanden getötet" oder "Petya wurde getötet". "Vasya macht Bilder" - "Vasya macht Bilder" (das heißt, "Vasya wird fotografiert"). Es gibt auch eine mediale Garantie in SynTagRus - wir werden nicht einmal untersuchen, was es ist und warum. Aber in Mystem ist es nicht. Wenn Sie ein Format irgendwie in ein anderes bringen müssen, ist dies eine Sackgasse.
Wir haben den Rat des Autors des Pakets russian_tagsets mehr oder weniger ehrlich befolgt - haben seine Entwicklung nicht genutzt, weil wir das erforderliche Paar nicht in der Liste der Korrespondenzformate gefunden haben. Als Ergebnis haben wir unseren benutzerdefinierten Konverter von Mystem nach Conllu geschrieben und sind weitergegangen.
Wir verbinden den Tagger von Drittanbietern und den UDPipe-Parser
Nach all den Abenteuern haben wir drei Algorithmen verwendet, die oben beschrieben wurden:
- Basis-UDPipe
- Mym mit Tag-Disambiguierung von pymorphy2
- RNNMorph
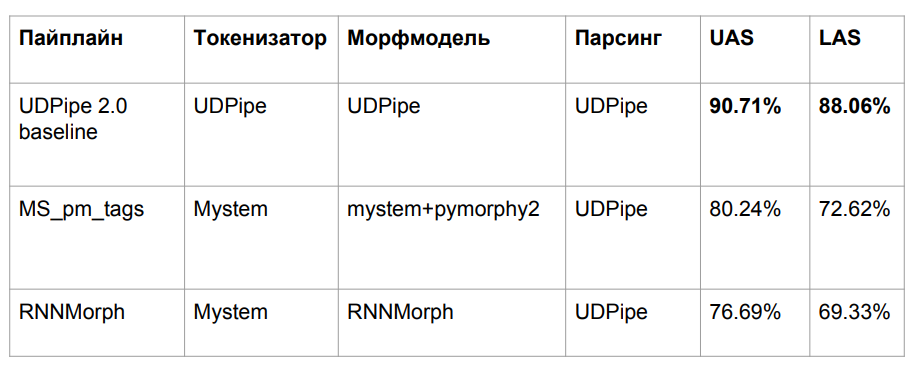
Wir haben aus einem ziemlich offensichtlichen Grund an Qualität verloren. Wir haben das UDPipe-Modell verwendet, das auf einer Morphologie trainiert wurde, aber eine andere Morphologie auf eine Eingabe verschoben. Das klassische Problem der Dateninkongruenz zwischen Zug und Test ist das Ergebnis eines Qualitätsverlusts.
Wir haben versucht, unsere automatischen morphologischen Markierungswerkzeuge an dem manuell markierten SynTagRus-Markup auszurichten. Es ist uns nicht gelungen, daher werden wir im SynTagRus-Trainingsfall alle manuellen morphologischen Markierungen durch diejenigen ersetzen, die in einem Fall von Mystem und pymorphy2 und in einem anderen von RNNMorph erhalten wurden. In einem validierten Fall, der von Hand markiert wurde, müssen wir die manuelle Markierung auf automatisch ändern, da wir im Kampf niemals eine manuelle Markierung erhalten.
Aus diesem Grund haben wir den UDPipe-Parser (nur den Parser) mit denselben Hyperparametern wie die Basislinie trainiert. Was für die Syntax verantwortlich war - die Scheitelpunkt-ID, von der die Art der Verbindung abhängt - wir sind gegangen, wir haben alles andere geändert.
Ergebnisse
Weiter werde ich uns mit Syntaxnet und anderen Algorithmen vergleichen. Die Organisatoren von CoNLL Shared Task haben die SynTagRus-Partition (train / dev / test 80/10/10) vorgestellt. Wir haben zunächst einen anderen genommen (Zug / Test 70/30), daher stimmen die Daten nicht immer mit uns überein, obwohl sie im selben Fall eingegangen sind. Darüber hinaus haben wir die neueste Version (Stand Februar-März) aus dem SynTagRus-Repository übernommen - diese Version unterscheidet sich geringfügig von der im Wettbewerb. Die Daten für das, was nicht gestartet ist, sind in Artikeln angegeben, in denen die Aufteilung dieselbe war wie im Wettbewerb. Solche Algorithmen sind in der Tabelle mit einem Sternchen gekennzeichnet.
Hier sind die Endergebnisse:
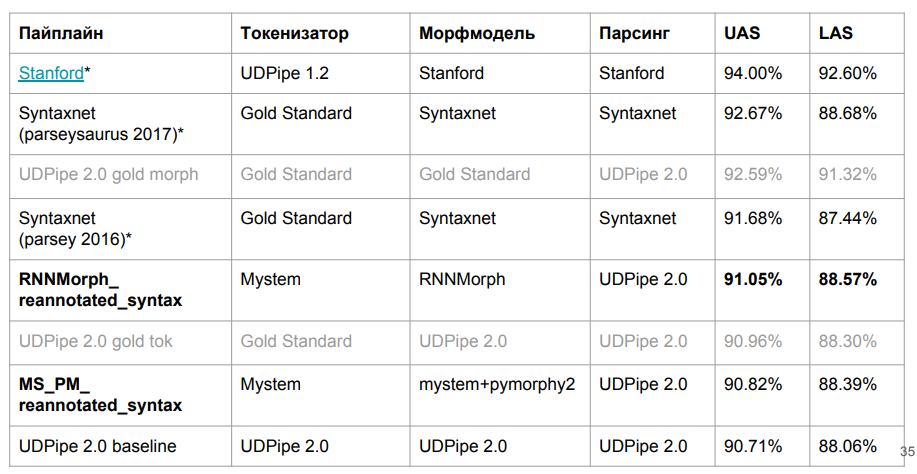
RNNMorph erwies sich wirklich als besser - nicht im absoluten Sinne, sondern als Hilfsmittel zum Erhalten einer gemeinsamen Metrik gemäß den Ergebnissen der Analyse (im Vergleich zu Mystem + Pymorphie2). Das heißt, je besser die Morphologie, desto besser die Syntax, aber die "syntaktische" Trennung ist viel geringer als die morphologische. Beachten Sie auch, dass wir nicht sehr weit vom Basismodell entfernt waren, was bedeutet, dass es in der Morphologie wirklich nicht so viel gab, wie wir erwartet hatten.
Ich frage mich, wie viel überhaupt über Morphologie liegt. Ist es aufgrund der idealen Morphologie möglich, eine grundlegende Verbesserung des syntaktischen Parsers zu erreichen? Um diese Frage zu beantworten, haben wir UDPipe 2.0 zu Tokenisierung und Morphologie gefahren, die perfekt kalibriert waren (unter Verwendung des Standardstandards für manuelles Markup). Wir haben einen bestimmten Spielraum (siehe die Zeile über Gold Morph in der Tabelle; es ergibt sich + 1,54% aus RNNMorph_reannotated_syntax) von dem, was wir hatten, auch unter dem Gesichtspunkt der korrekten Bestimmung der Art der Verbindung. Wenn jemand jemals einen absolut perfekten morphologischen Analysator der russischen Sprache schreibt, werden wahrscheinlich auch die Ergebnisse wachsen, die wir mit einem abstrakten syntaktischen Parser erhalten. Und wir verstehen ungefähr die Decke (zumindest die Decke für diese Architektur und für die Kombination von Parametern, die wir für UDPipe verwendet haben - sie wird in der dritten Zeile der obigen Tabelle gezeigt).
Interessanterweise haben wir die Syntaxnet-Version in der LAS-Metrik fast erreicht. Es ist klar, dass wir leicht unterschiedliche Daten haben, aber im Prinzip sind sie immer noch vergleichbar. Syntaxnet-Tokenisierung ist "Gold" und für uns - von Mystem. Wir haben den oben genannten Wrapper an Mystem geschrieben, aber das Parsen erfolgt immer noch automatisch. wahrscheinlich irrt sich Mystem auch irgendwo. Aus der Zeile der Tabelle „UDPipe 2.0 Gold Token“ geht hervor, dass Syntaxnet-2017 immer noch ein wenig verliert, wenn Sie die Standard-UDPipe- und Gold-Tokenisierung verwenden. Aber es funktioniert viel schneller.
Was niemand erreicht hat, ist der
Stanford-Parser . Es ist auf die gleiche Weise wie Syntaxnet konzipiert, funktioniert also lange. In UDPipe gehen wir einfach den Stapel entlang. Die Architektur des Stanford-Parsers und des Syntaxnet hat ein anderes Konzept: Zuerst erzeugen sie einen vollständig orientierten Graphen, und dann verlässt der Algorithmus das Skelett (minimaler Spanning Tree), das am wahrscheinlichsten ist. Dazu durchläuft er Kombinationen, und diese Suche ist nicht mehr linear, da Sie sich mehr als einmal einem Wort zuwenden. Trotz der Tatsache, dass es sich aus Sicht der reinen Wissenschaft, zumindest für die russische Sprache, lange Zeit um eine effizientere Architektur handelt. Wir haben versucht, diese akademische Entwicklung für zwei Tage zu fördern - leider hat es nicht geklappt. Aufgrund seiner Architektur ist jedoch klar, dass es nicht schnell funktioniert.
Was unseren Ansatz angeht - obwohl wir formal fast nicht durch Metriken gestiegen sind, ist jetzt alles in Ordnung mit der „Mutter“.
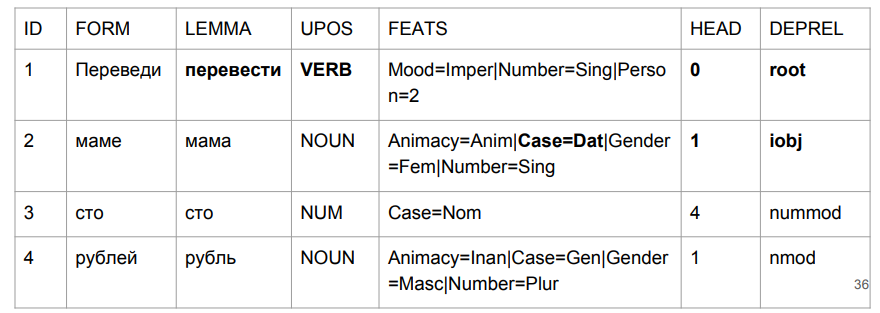
In der Phrase "übersetze hundert Rubel an Mama" ist "übersetzen" wirklich ein Verb in der imperativen Stimmung. "Mom" hat seinen Dativ. Und das Wichtigste für uns ist unser Label (iobj), ein indirektes Objekt (Ziel). Obwohl das Zahlenwachstum vernachlässigbar ist, haben wir das Problem, mit dem die Aufgabe begann, gut bewältigt.
Bonustrack: Interpunktion
Wenn wir zu den realen Daten zurückkehren, stellt sich heraus, dass die Syntax von der Interpunktion abhängt. Nehmen Sie den Satz "Sie können keine Gnade ausführen." Was genau nicht getan werden kann - um „auszuführen“ oder „Gnade zu haben“ - hängt davon ab, wo das Komma steht. Selbst wenn wir den Linguisten damit beauftragen, die Daten zu markieren, benötigt er Interpunktion als eine Art Hilfsmittel. Er konnte nicht ohne sie auskommen.
Nehmen wir die Sätze „Peter hallo“ und „Peter hallo“ und betrachten ihre Analyse anhand des Baseline-UDPipe-Modells. Wir lassen die Probleme aus, die nach diesem Modell dann:
1) "Petya" ist ein weibliches Substantiv;
2) "Petya" ist (nach dem Satz von Tags zu urteilen) die ursprüngliche Form, aber gleichzeitig ist sein Lemma angeblich nicht "Petya".
Auf diese Weise ändert sich das Ergebnis aufgrund des Kommas. Mit seiner Hilfe erhalten wir etwas Ähnliches wie die Wahrheit.
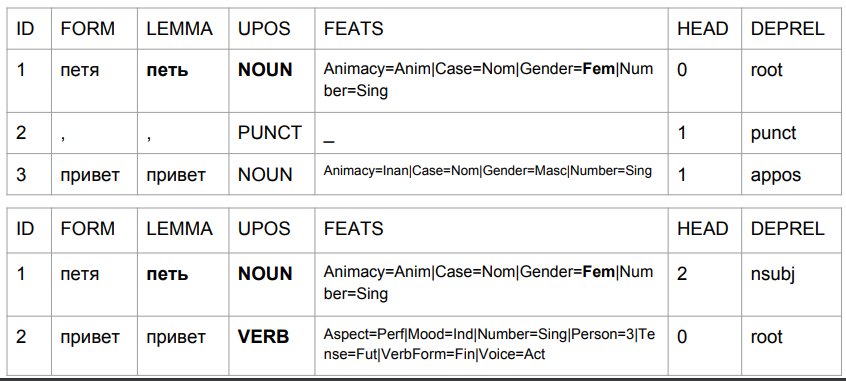
Im zweiten Fall ist „Petya“ ein Thema und „Hallo“ ein Verb. Zurück zur Vorhersage der Form eines Wortes anhand der letzten vier Zeichen. Bei der Interpretation des Algorithmus handelt es sich nicht um „Petya-Grüße“, sondern um „Petya-Grüße“. Geben Sie "Petya singt" oder "Petya wird kommen" ein. Die Analyse ist durchaus verständlich: Auf Russisch darf zwischen dem Subjekt und dem Prädikat kein Komma stehen. Wenn das Komma lautet, ist dies das Wort "Hallo", und wenn es kein Komma gibt, kann es sich durchaus um "Petya Liguster" handeln.
Wir werden dies in der Produktion ziemlich oft antreffen, weil Rechtschreibprüfungen die Rechtschreibung korrigieren, aber keine Interpunktion. Um die Sache noch schlimmer zu machen, kann der Benutzer Kommas falsch setzen, und unser Algorithmus berücksichtigt sie beim Verständnis der natürlichen Sprache. Was sind hier die möglichen Lösungen? Wir sehen zwei Möglichkeiten.
Die erste Möglichkeit besteht darin, das zu tun, was manchmal bei der Übersetzung von Sprache in Text der Fall ist. In einem solchen Text gibt es zunächst keine Interpunktion, daher wird er über das Modell wiederhergestellt. Die Ausgabe ist relativ kompetent in Bezug auf die Regeln der russischen Sprache, was dem syntaktischen Parser hilft, korrekt zu arbeiten.
Die zweite Idee ist etwas mutiger und widerspricht dem Schulunterricht der russischen Sprache. Es geht darum, ohne Interpunktion zu arbeiten: Wenn die Eingabe plötzlich Interpunktion ist, werden wir sie von dort entfernen. Wir werden auch absolut alle Satzzeichen aus dem Trainingskorps entfernen. Wir gehen davon aus, dass die russische Sprache ohne Interpunktion existiert. Nur Punkte zum Teilen in Sätze.
Technisch ist es ziemlich einfach, da wir die Endknoten im Syntaxbaum nicht ändern. Wir können nicht so haben, dass das Interpunktionszeichen oben ist. Dies ist immer ein Endknoten, mit Ausnahme des% -Zeichens, das aus irgendeinem Grund in SynTagRus der Scheitelpunkt für die vorherige Ziffer ist (50% in SynTagRus sind als% -Vertex und 50-abhängig markiert).
Testen wir mit dem Mystem-Modell (+ Pymorphie 2).

Für uns ist es von entscheidender Bedeutung, das Interpunktionstextmodell nicht ohne Interpunktion anzugeben. Wenn wir den Text jedoch immer ohne Interpunktion angeben, stehen wir in der obersten Zeile und erzielen zumindest akzeptable Ergebnisse. Wenn der Text ohne Interpunktion und das Modell ohne Interpunktion arbeiten, beträgt der Abfall in Bezug auf die ideale Interpunktion und das Interpunktionsmodell nur etwa 3%.
Was tun? Wir können uns mit diesen Zahlen befassen - erhalten mit dem interpunktionsfreien Modell und der Reinigung der Interpunktion. Oder überlegen Sie sich einen Klassifikator, um die Interpunktion wiederherzustellen. Wir werden keine idealen Zahlen erreichen (solche mit Interpunktion im Interpunktionsmodell), da der Interpunktionswiederherstellungsalgorithmus mit einigen Fehlern arbeitet und die "idealen" Zahlen auf absolut reinem SynTagRus berechnet wurden. Aber wenn wir ein Modell schreiben, das die Interpunktion wiederherstellt, zahlt der Fortschritt dann unsere Kosten zurück? Die Antwort ist noch nicht offensichtlich.
Wir können lange über die Architektur des Parsers nachdenken, aber wir müssen uns daran erinnern, dass es tatsächlich keinen großen syntaktisch markierten Korpus von Webtexten gibt. Seine Existenz würde helfen, echte Probleme besser zu lösen. Bisher studieren wir das Korps absolut gebildeter, bearbeiteter Texte - und wir verlieren an Qualität, indem wir benutzerdefinierte Texte in den Kampf ziehen, die oft als Analphabeten geschrieben werden.
Fazit
Wir untersuchten die Verwendung verschiedener syntaktischer Parsing-Algorithmen basierend auf der Abhängigkeitsgrammatik, wie sie auf die russische Sprache angewendet werden. Es stellte sich heraus, dass sich UDPipe in Bezug auf Geschwindigkeit, Komfort und Qualität der Arbeit als das beste Werkzeug herausstellte. Das Basismodell kann verbessert werden, wenn die Stufen der Tokenisierung und morphologischen Analyse anderen Analysatoren von Drittanbietern zugewiesen werden: Dieser Trick ermöglicht es, das falsche Verhalten des Taggers und damit des Parsers in wichtigen Fällen für die Analyse zu korrigieren.
Wir haben auch das Problem der Beziehung zwischen Interpunktion und Analyse analysiert und sind zu dem Schluss gekommen, dass in unserem Fall die Interpunktion vor der syntaktischen Analyse besser zu entfernen ist.
Wir hoffen, dass die in unserem Artikel beschriebenen Anwendungspunkte Ihnen dabei helfen, mithilfe der syntaktischen Analyse Ihre Probleme so effizient wie möglich zu lösen.
Der Autor dankt Nikita Kuznetsova und Natalya Filippova für die Hilfe bei der Vorbereitung des Artikels. für die Unterstützung in der Studie - Anton Alekseev, Nikita Kuznetsov, Andrei Kutuzov, Boris Orekhov und Mikhail Popov.