Hallo Habr!
Vor drei Jahren habe ich auf der Website von Leonid Zhukov einen Link zum Verlauf der Analyse von Netzwerken durch Yure Leskovek cs224w gesetzt, und jetzt werden wir ihn zusammen mit allen in unserem komfortablen Chat im Kanal # class_cs224w aufnehmen. Unmittelbar nach dem Aufwärmen mit einem offenen maschinellen Lernkurs , der in wenigen Tagen beginnt.

Frage: Was lesen sie dort?
Antwort: Moderne Mathematik. Wir zeigen ein Beispiel für die Verbesserung des Prozesses der IT-Rekrutierung.
Unter der Katze des Lesers gibt es eine Geschichte darüber, wie diskrete Mathematik einen Projektmanager zu neuronalen Netzen führte, warum ERP- und Produktmanager das Bioinformatik-Magazin lesen sollten, wie die Aufgabe, Verbindungen zu empfehlen, gelöst und gelöst wurde, wer Graph-Einbettungen benötigt und woher sie kamen, sowie die Meinung dazu wie man aufhört, sich bei den Interviews vor Fragen zu Bäumen zu fürchten, und was dies alles kosten kann. Lass uns gehen!
Unser Plan lautet wie folgt:
1) Was ist cs224w
2) Kariert oder reiten
3) Wie bin ich zu all dem gekommen?
4) Warum das Bioinformatik-Magazin lesen?
5) Was ist das Einbetten von Graphen und woher kommt es?
6) Zufälliger Kinderwagen in Matrixform
7) Die Rückkehr eines zufälligen Kinderwagens und die Stärke der Bindungen
8) Der Pfad eines zufälligen Vagabunden und die Spitze im Vektor
9) Unsere Tage sind ein zufälliger Trampel für alle und jeden
10) Wie und wo werden solche Daten gespeichert und wo werden sie abgerufen?
11) Was zu fürchten
12) Notiz an den Spieler
Was ist cs224w
Der Kurs von Yure Leskovek Analysis of Networks sticht in der Galaxie der Bildungsprodukte der Fakultät für Computerwissenschaften der Stanford University heraus. Der Unterschied zu den anderen besteht darin, dass das Programm ein sehr breites Spektrum von Themen abdeckt. Es ist die Interdisziplinarität, die das Abenteuer zu einer Herausforderung macht. Der Preis ist die universelle Sprache für die Beschreibung komplexer Systeme - Graphentheorie, die in zehn Wochen behandelt werden kann.

Der Kurs kostet sich nicht so viel, öffnet aber das Graduate Certificate- Programm für Mining Massive Data Sets , das noch viele Extras enthält.
Zweiter im Abenteuer ist Andrew Euns CS229 Machine Learning, für das unnötigerweise geworben wird.
Es folgen die massiven CS246 Mining-Datensätze Jure Leskoveka, in denen diejenigen, die dies wünschen, eingeladen werden, sich auf MapReduce und Spark auszuruhen.
Chris Manning beendet das Bankett CS276 Information Retrieval und Web Search.
Als Bonus wurden die massiven CS246H Mining-Datensätze: Hadoop Labs speziell für diejenigen entwickelt, die nur wenige waren. Wieder Yure besuchen.
Im Allgemeinen versprechen sie, dass diejenigen, die das Programm bestanden haben, Fähigkeiten und Kenntnisse erwerben, die ausreichen, um im Internet nach Informationen zu suchen (ohne Google und andere wie sie).
Fahrt oder Kontrolleure
Es war einmal mein damaliger Leiter und Mentor - STO im ukrainischen Nestlé -, der mir jung und ehrgeizig erklärte und versuchte, einen MBA zu einem Star zu machen, die Wahrheit, dass Erfahrung und Wissen auf dem Arbeitsmarkt kaufen und verkaufen und nicht Diplome und Testergebnisse.
Die oben beschriebene Spezialisierung kann online für symbolische 18.900 USD abgeschlossen werden.
Im Durchschnitt dauert ein Abenteuer 1-2 Jahre, jedoch nicht länger als 3. Um ein Zertifikat zu erhalten, müssen Sie alle Kurse mit einer Bewertung von mindestens B (3,0) abschließen.
Es gibt noch einen anderen Weg.
Alle Materialien der Kurse von Jure Leskovek werden offen und sehr schnell veröffentlicht. Daher können diejenigen, die dies wünschen, jederzeit leiden und die Belastung mit den Fähigkeiten abstimmen. Besonders begabt empfehle ich den Abenteuermodus "Das ist Stanford, Schatz!" - parallel zum Kurs verlaufen - Videos von Vorlesungen werden innerhalb weniger Tage veröffentlicht, zusätzliche Literatur ist sofort verfügbar, Hausaufgaben und Lösungen werden schrittweise geöffnet.
In dieser Saison werden wir nach dem Ende des Open Machine Learning-Kurses auf Habré , der zum Aufwärmen nützlich ist, ein Rennen in der speziellen Kanalklasse # cs_cs224w ods.ai organisieren.
Es wird empfohlen, über die folgenden Fähigkeiten zu verfügen:
- Grundlagen der Computerwissenschaften auf einem Niveau, das ausreicht, um nicht triviale Programme zu schreiben.
- Grundlagen der Wahrscheinlichkeitstheorie.
- Grundlagen der linearen Algebra.
Wie bin ich zu all dem gekommen?
Er lebte für sich selbst, kümmerte sich nicht darum. Verwaltete SAP- Implementierungsprojekte. Zuweilen - er war in seiner Hauptspezialisierung als Spieltrainer tätig - und CRM verdreht die Nüsse. Man kann sagen, fast hat niemand berührt. Ich war in der Selbstbildung beschäftigt. Irgendwann entschied ich mich, mich auf den Bereich der Geschäftstransformation zu spezialisieren (oder organisatorische Änderungen vorzunehmen). Die Analyse von Organisationen vor und nach Veränderungen ist ein wichtiger Bestandteil dieser Arbeit. Zu wissen, wo und wo man sich ändert, hilft sehr. Das Verständnis der Beziehungen zwischen Menschen ist ein wesentlicher Erfolgsfaktor. Er verbrachte mehrere Jahre damit, die "weichen" Methoden für die Erforschung von Organisationen zu studieren, konnte sich aber immer noch nicht mit der Frage zufrieden geben: "Wer wird wen abholen: der Oberbefehlshaber des Hauptbuchhalters, oder ist sie stärker als der Rest des Lagerhauses?" Ich habe mich seit mehreren Jahren hintereinander gefragt. Ich suche nach einer Möglichkeit, sicher zu messen.
2014 war ein Wendepunkt, als ich meine Träume vom MBA aufgab und Statistik und Informationsmanagement an der neuen Universität von Lissabon (der ersten und jetzt lebenden Telekommunikationsabteilung der bereits bestehenden Fakultät für Luft- und Raumfahrtsysteme der Polytechnischen Universität Kiew) als zweithöchste auswählte (ich höre das Trommelwirbel). + Kommunikationsabteilung beim Militär).
Im ersten Semester der zweiten Magistratur versuchte er die Analyse sozialer Netzwerke - eine der Anwendungen der Graphentheorie. Damals erfuhr ich, dass es Algorithmen gibt, die Probleme lösen, wie zum Beispiel, wer mit jemandem gegen die Implementierung neuer Technologien befreundet sein wird, aber ich wusste es vorher nicht und trocknete meinen Kopf und analysierte die Verbindungen von Menschen in meinem Kopf - es schwillt wirklich an. Es stellte sich zufällig heraus, dass die Analyse von Netzwerken nach den ersten Schritten ein kontinuierliches Ausgraben von Daten und maschinellem Lernen ist, entweder mit oder ohne Lehrer.
Anfangs gab es genug Klassiker.
Ich wollte mehr. Um mich mit Einbettungen zu befassen (und Marinka Zhitniks Arbeit auf ihre Aufgaben zu beschränken), musste ich mich mit tiefem Lernen befassen, was durch den Deep-Learning-Kurs an den Fingern sehr hilfreich war. Angesichts der Geschwindigkeit, mit der die Leskovek-Gruppe neues Wissen schafft, reicht es aus, ihre Arbeit einfach zu überwachen, um Managementaufgaben automatisch zu lösen.
Teambuilding ist keine leichte Aufgabe. Wer nicht mit einem in dasselbe Boot gesetzt werden sollte, ist eines der dringenden Probleme. Besonders wenn die Gesichter neu sind. Und die Gegend ist unbekannt. Und um zu fernen Ufern zu gelangen, braucht man nicht ein Boot, sondern eine ganze Flottille. Unterwegs ist eine enge Interaktion sowohl in Booten als auch zwischen ihnen erforderlich. Übliche Arbeitstage der SAP- Implementierung, an denen der Kunde ein für seine Besonderheiten konfiguriertes System aus einer Reihe von Modulen liefern muss und der Projektplan aus Tausenden von Zeilen besteht. Für all seine Arbeit hat er nie jemanden eingestellt - sie haben immer ein Team zusammengestellt. Sie sind ein Projektmanager, Sie haben Befugnisse und drehen sich um. Irgendwie so. Verdreht.
Lebensbeispiel:
Ich selbst habe nicht interviewt, aber ich habe Timlids dafür zugewiesen. Und für Ressourcen - Nachfrage von mir. Die Integration neuer Teammitglieder liegt ebenfalls in der Verantwortung des Projektmanagers. Ich glaube, dass viele zustimmen werden, dass der Prozess für alle Teilnehmer umso angenehmer ist, je besser die Kandidatenliste vorbereitet ist. Wir werden diese Aufgabe im Detail betrachten.
Natürliche Faulheit erforderlich - finden Sie einen Weg zur Automatisierung. Fand es. Ich teile.
Ein bisschen Managementtheorie. Die Adizes-Methodik basiert auf einem Grundprinzip: Organisationen haben wie lebende Organismen ihren eigenen Lebenszyklus und zeigen vorhersehbare und sich wiederholende Verhaltensmanifestationen während Wachstum und Alterung. In jeder Phase der Organisationsentwicklung erwartet das Unternehmen eine Reihe spezifischer Probleme. Wie gut das Management des Unternehmens mit ihnen umgeht, wie erfolgreich es die für einen gesunden Übergang von Stufe zu Stufe erforderlichen Änderungen vornimmt und den endgültigen Erfolg oder Misserfolg dieser Organisation bestimmt.
Ich bin seit ungefähr zehn Jahren mit den Ideen von Yitzhak Adizes vertraut und stimme in vielerlei Hinsicht zu.
Persönlichkeiten von Mitarbeitern - wie Vitamine - beeinflussen unter bestimmten Bedingungen den Erfolg. Es gibt bekannte Beispiele dafür, wie erfolgreiche Führungskräfte, die aus einer Branche kamen, in einer anderen gescheitert sind. Es passiert schlimmer. Zum Beispiel hat Marissa Mayer, die eine Google-Suche ausgelöst hat, Yahoo fallen lassen. Warren Buffett sagt, es wäre ihm kaum gelungen, in Bangladesch geboren zu werden. Die Umgebung und die Art der Interaktion darin sind ein wichtiger Faktor.
Es wäre schön, Komplikationen vor Experimenten an einem lebenden vorherzusagen, oder?
In dieser Übersicht liegt die nächste Studie von Marinka itnik, die in der Zeitschrift Bioinformatics veröffentlicht wurde. Die Aufgabe, Nebenwirkungen bei kombiniertem Drogenkonsum vorherzusagen, liegt mathematisch nahe am Management. Alles dank der Vielseitigkeit der Grafiksprache. Betrachten wir es genauer.

Decagon Graph Convolutional Network - ein Tool zur Vorhersage von Verbindungen in multimodalen Netzwerken.
Das Verfahren besteht darin, ein multimodales Diagramm von Protein-Protein-, Arzneimittel-Protein-Wechselwirkungen und Nebenwirkungen aus einer Kombination von Arzneimitteln zu erstellen, bei denen es sich um Arzneimittel-Arzneimittel-Beziehungen handelt, wobei jede der Nebenwirkungen eine Kante eines bestimmten Typs darstellt. Decagon sagt eine bestimmte Art von Nebenwirkung voraus, die im Krankheitsbild auftritt.
Die Abbildung zeigt ein Beispiel eines Diagramms der Nebenwirkungen, die aus Genom- und Populationsdaten erhalten wurden. Insgesamt - 964 verschiedene Arten von Nebenwirkungen (angezeigt durch Rippen vom Typ ri, i = 1, ..., 964). Zusätzliche Informationen im Modell werden in Form von Vektoren der Eigenschaften von Proteinen und Arzneimitteln dargestellt.
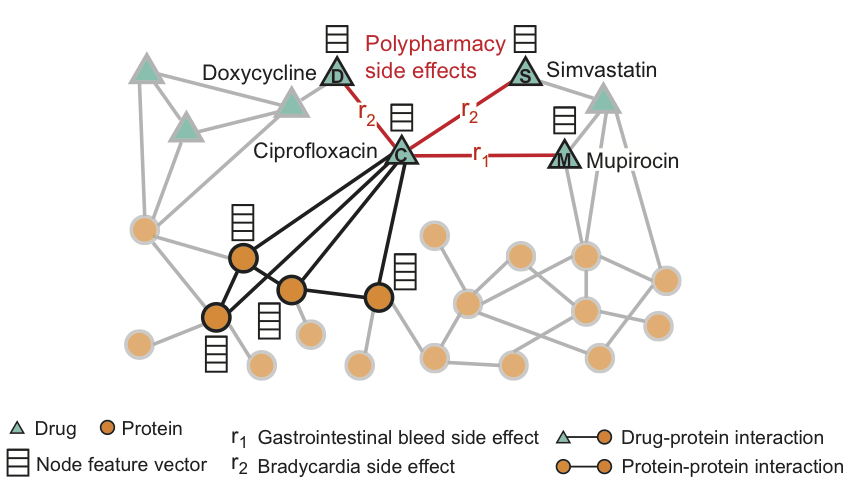
Für das Medikament Ciprofloxacin (Knoten C) spiegeln die hervorgehobenen Nachbarn in der Grafik die Auswirkungen auf vier Proteine und drei andere Medikamente wider. Wir sehen, dass Ciprofloxacin (Knoten C), das gleichzeitig mit Doxycyclin (Knoten D) oder Simvastatin (Knoten S) eingenommen wird, das Risiko einer Nebenwirkung einer Verlangsamung der Herzfrequenz (eine Nebenwirkung wie r2) und einer Kombination mit Mupirocin (M) erhöht - erhöht das Blutungsrisiko des Magen-Darm-Trakts (Nebenwirkungsart r1).
Decagon sagt Assoziationen zwischen Arzneimittelpaaren und Nebenwirkungen (rot dargestellt) voraus, um Nebenwirkungen bei gleichzeitiger Anwendung zu identifizieren, d. H. diese Nebenwirkungen, die mit keinem der Medikamente des Paares separat assoziiert werden können.
Decagon Convolutional Neural Network Graph Architektur:
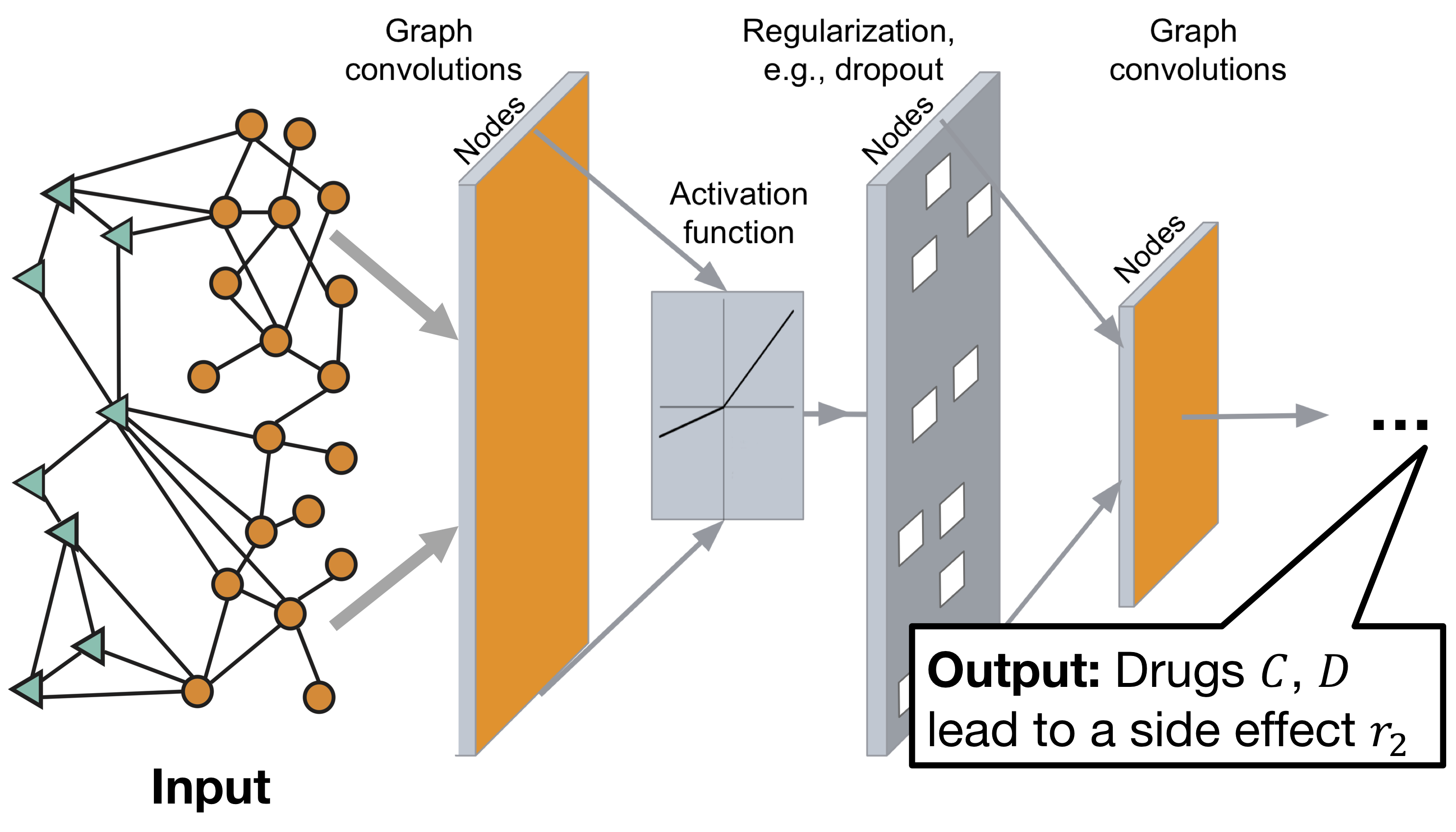
Das Modell besteht aus zwei Teilen:
Encoder: Graph Convolutional Network (GCN), das einen Graph empfängt und für Knoten einbettet,
Decoder: Ein Tensorfaktorisierungsmodell, das diese Einbettungen verwendet, um Nebenwirkungen zu erkennen.
Weitere Informationen finden Sie auf der Projektwebsite oder unten.
Großartig, aber wie kann man das mit Teambuilding verbinden?
So etwas in der Art .
Hier lohnt es sich, den Granit der Wissenschaft auszugraben, um sich auf dem ähnlich beschriebenen Forschungsgebiet wohl zu fühlen. Das Graben wird zwar intensiv stattfinden - die Graphentheorie entwickelt sich aktiv weiter. Deshalb ist es die Speerspitze des Fortschritts - nur wenige Menschen fühlen sich dort wohl.
Um die Details der Funktionsweise von Decagon zu verstehen, werden wir einen Ausflug in die Geschichte machen.
Was ist das Einbetten von Graphen und woher kommt es?
Ich habe in den letzten vier Jahren eine Änderung in der Reihe der fortgeschrittenen Methoden zur Lösung von Problemen bei der Vorhersage von Verbindungen in Diagrammen beobachtet. Das hat Spaß gemacht. Fast wie in einem Märchen - je weiter, desto schlimmer. Die Evolution folgte dem Weg von der Heuristik, die die Umgebung für den oberen Rand des Diagramms bestimmte, zu zufälligen Kinderwagen, dann erschienen spektrale Methoden (Matrixanalyse) und nun neuronale Netze.
Wir formulieren das Problem der Vorhersage von Beziehungen:
Betrachten Sie ein ungerichtetes Diagramm $ inline $ \ begin {align *} G (V, E) \ end {align *} $ inline $ wo
$ inline $ \ begin {align *} V \ end {align *} $ inline $ - viele Gipfel $ inline $ \ begin {align *} v \ end {align *} $ inline $ ,
$ inline $ \ begin {align *} E \ end {align *} $ inline $ - viele Rippen $ inline $ \ begin {align *} e (u, v) \ end {align *} $ inline $ die Spitzen verbinden $ inline $ \ begin {align *} u \ end {align *} $ inline $ und $ inline $ \ begin {align *} v \ end {align *} $ inline $ .
Wir definieren die Menge aller möglichen Kanten $ inline $ E ^ {\ diamant} $ inline $ seine Macht
$ inline $ \ begin {align *} | E ^ {\ diamant} | & = \ frac {| V | * (| V | - 1)} {2} \\ \ end {align *} $ inline $ wo
$ inline $ \ begin {align *} | V | = n \ end {align *} $ inline $ Ist die Anzahl der Eckpunkte.
Offensichtlich können viele nicht existierende Kanten ausgedrückt werden als $ inline $ \ begin {align *} \ overline {E} = E ^ {\ diamant} - E \ end {align *} $ inline $ .
Wir gehen davon aus, dass im Set $ inline $ \ begin {align *} \ overline {E} \ end {align *} $ inline $ Es gibt verpasste Links oder Links, die in Zukunft erscheinen werden, und wir möchten sie finden.
Die Lösung besteht darin, eine Funktion zu definieren $ inline $ \ begin {align *} D (u, v) \ end {align *} $ inline $ Der Abstand zwischen den Scheitelpunkten des Diagramms, der die Struktur des Diagramms berücksichtigt $ inline $ \ begin {align *} G (t_0, t_0 ^ \ star) \ end {align *} $ inline $ über einen bestimmten Zeitraum eingestellt $ inline $ \ begin {align *} (t_0, t_0 ^ \ star) \ end {align *} $ inline $ das Auftreten von Kanten vorhersagen $ inline $ \ begin {align *} G (t_1, t_1 ^ \ star) \ end {align *} $ inline $ im Bereich $ inline $ \ begin {align *} (t_1, t_1 ^ \ star) \ end {align *} $ inline $ .
Eine der ersten Veröffentlichungen , die vorschlug, vom Clustering zur Vorhersage von Beziehungen im Zusammenhang mit der Untersuchung der gemeinsamen Genexpression überzugehen, erschien im Jahr 2000 in der Zeitschrift Bioinformatics (wie Sie sich vorstellen können). Bereits 2003 wurde ein Artikel von John Kleinberg mit einem Überblick über relevante Methoden zur Lösung des Problems der Vorhersage von Verbindungen in einem sozialen Netzwerk veröffentlicht. Sein Buch " Netzwerke, Menschenmengen und Märkte: Überlegungen zu einer stark vernetzten Welt " ist ein Lehrbuch, das während des cs224w-Kurses gelesen werden sollte. Die meisten Kapitel sind im erforderlichen Leseabschnitt aufgeführt.
Ein Artikel kann als Wissensscheibe in einem engen Bereich betrachtet werden, wie wir sehen, war zunächst die Auswahl an Methoden klein und umfasste:
- Methoden, die auf Graphnachbarn basieren - und die offensichtlichste davon ist die Anzahl der gemeinsamen Nachbarn.
Wir geben die Definition:
Oben $ inline $ u $ inline $ ist ein Graphnachbar für die Spitze $ inline $ v $ inline $ wenn Rippe $ inline $ e (u, v) \ in E $ inline $ .
Wir bezeichnen $ inline $ \ Gamma (u) $ inline $ viele Nachbarn Gipfel $ inline $ u $ inline $ ,
dann der Abstand zwischen den Spitzen $ inline $ u $ inline $ und $ inline $ v $ inline $ kann geschrieben werden als
$ inline $ D_ {CN} (u, v) = \ Gamma (u) \ cap \ Gamma (v) $ inline $ .
Je größer der Schnittpunkt der Nachbarn zweier Gipfel ist, desto wahrscheinlicher ist intuitiv die Verbindung zwischen ihnen. Beispielsweise treten die meisten neuen Bekanntschaften mit Freunden von Freunden auf.
Fortgeschrittenere Heuristiken - Jacquard-Koeffizient $ inline $ D_J (u, v) = \ frac {\ Gamma (u) \ cap \ Gamma (v)} {\ Gamma (u) \ cup \ Gamma (v)} $ inline $ (die bereits hundert Jahre alt war) und vor kurzem (zu dieser Zeit) die vorgeschlagene Entfernung Adamik / Adar $ inline $ D_ {AA} (u, v) = \ sum_ {x \ in \ Gamma (u) \ cap \ Gamma (v)} \ frac {1} {\ log | \ Gamma (x) |} $ inline $ Entwickeln Sie die Idee durch einfache Transformationen.
- Methoden, die auf Pfaden entlang eines Diagramms basieren - die Idee ist, dass der kürzeste Pfad zwischen zwei Scheitelpunkten in einem Diagramm der Wahrscheinlichkeit einer Verbindung zwischen ihnen entspricht - je kürzer der Pfad, desto höher die Wahrscheinlichkeit. Sie können weiter gehen und nicht nur den kürzesten Pfad berücksichtigen, sondern auch alle anderen möglichen Pfade zwischen Spitzenpaaren, z. B. die Pfade wiegen, wie dies bei der Katz-Entfernung der Fall ist. Bereits dann wird die erwartete Pfadlänge eines zufälligen Vagabunden erwähnt - der Vorläufer der Empfehlungsmethode für Facebook-Freunde.
Schätzen Sie die Qualität der Prognose:
- Für jedes Eckpunktpaar $ inline $ (u, v) $ inline $ jede nicht vorhandene Rippe $ inline $ e (u, v) \ in \ overline {E} $ inline $ Berechnen Sie die Entfernung $ inline $ D (u, v) $ inline $ in der Grafik $ inline $ G (t_0, t_0 ^ \ star) $ inline $ .
- Sortieren Sie die Paare $ inline $ (u, v) $ inline $ absteigende Entfernung $ inline $ D (u, v) $ inline $ .
- Zum Mitnehmen $ inline $ m $ inline $ Paare mit den höchsten Werten ist unsere Prognose.
- Mal sehen, wie viele der vorhergesagten Kanten in erschienen sind $ inline $ G (t_1, t_1 ^ \ star) $ inline $ .
Es ist wichtig, sich daran zu erinnern, dass die Anzahl der gemeinsamen Nachbarn und der Adamik / Adar-Abstand leistungsstarke Methoden sind, die das grundlegende Niveau der Prognosequalität nur für die Linkstruktur angeben. Wenn Ihr Empfehlungssystem ein schwächeres Ergebnis zeigt, stimmt etwas nicht.
Im Allgemeinen sind Diagrammeinbettungen eine Möglichkeit, Diagramme für maschinelle Lernaufgaben mithilfe der Transformationsfunktion kompakt darzustellen $ inline $ \ begin {align *} \ phi: G (V, E) \ longmapsto \ mathbb {R} ^ d \ end {align *} $ inline $ .
Wir haben mehrere dieser Funktionen untersucht, die effektivste der ersten. Eine breitere Liste wird in einem Artikel von Kleinberg beschrieben. Wie wir aus der Übersicht sehen können, begannen sie bereits damals, Methoden auf hoher Ebene anzuwenden, wie z. B. Matrixzerlegung, vorläufige Clusterbildung und Werkzeuge aus dem Arsenal der Computerlinguistik. Vor fünfzehn Jahren fing alles gerade erst an. Einbettungen waren eindimensional.
Matrixförmiger Kinderwagen
Der nächste Meilenstein auf dem Weg zu denselben Graph-Einbettungen war die Entwicklung von Random-Walk-Methoden. Neue Formeln zur Berechnung der Entfernung zu erfinden und zu rechtfertigen, wurde offenbar zu einer Pause. In einigen Anwendungen scheint es, dass Sie sich nur auf den Zufall verlassen und den Landstreichern vertrauen müssen.
Wir geben die Definition:
Graph Adjazenzmatrix $ inline $ g $ inline $ mit einer endlichen Anzahl von Eckpunkten $ inline $ n $ inline $ (nummeriert von 1 bis $ inline $ n $ inline $ ) Ist eine quadratische Matrix $ inline $ a $ inline $ die Größe $ inline $ n \ times n $ inline $ in dem der Wert des Elements $ inline $ a_ {ij} $ inline $ gleich dem Gewicht $ inline $ w_ {ij} $ inline $ Rippen $ inline $ e (i, j) $ inline $ .
Hinweis: Hier entfernen wir uns absichtlich von den zuvor verwendeten Scheitelpunktindikatoren $ inline $ u, v $ inline $ und wir werden die der linearen Algebra bekannte Notation verwenden und im Allgemeinen mit Matrizen arbeiten $ inline $ i, j $ inline $ .
Wir veranschaulichen die betrachteten Konzepte:
Lass $ inline $ g $ inline $ - Grafik von vier Eckpunkten $ inline $ \ {A, B, C, D \} $ inline $ durch Rippen verbunden.
Um die Konstruktionen zu vereinfachen, nehmen wir an, dass die Kanten unseres Graphen bidirektional sind, d. H. $ inline $ \ forall e (i, j) \ in E, \ existiert e (j, i) \ in E \ land w_ {ij} = w_ {ji} $ inline $ .
$ inline $ e (A, B), w_ {AB} = 1; \\ e (B, C), w_ {BC} = 2; \\ e (A, C), w_ {AC} = 3; \ \ e (B, C), w_ {BC} = 1. $ inline $
Wir repräsentieren die Sätze von Kanten: $ inline $ E $ inline $ - in blau und $ inline $ \ overline {E} $ inline $ - in grün.

$ inline $ \ begin {align *} A = \ left [\ begin {matrix} 0 & 1 & 3 & 0 \\ 1 & 0 & 2 & 1 \\ 3 & 2 & 0 & 0 \\ 0 & 1 & 0 & 0 \ end {matrix} \ right] \ end {align *} $ inline $
Das Schreiben eines Diagramms in Matrixform eröffnet interessante Möglichkeiten. Um sie zu demonstrieren, werfen Sie einen Blick auf die Arbeit von Sergey Brin und Larry Page und sehen Sie, wie PageRank, ein Algorithmus zum Ranking von Diagrammscheitelpunkten, immer noch ein wichtiger Bestandteil der Google-Suche ist.
PageRank - geprägt, um die besten Seiten im Internet zu suchen. Eine Seite gilt als gut, wenn sie von anderen guten Seiten geschätzt (verlinkt) wird. Je mehr Seiten Links dazu enthalten und je höher ihre Bewertung ist, desto höher ist der PageRank für eine bestimmte Seite.
Betrachten Sie die Interpretation der Methode unter Verwendung von Markov-Ketten .
Wir geben eine Definition: Der
Grad eines Scheitelpunkts (Grad) ist die Kraft vieler Nachbarn:
,
Unterscheiden Sie zwischen In-Grad und Out-Grad. In unserem Beispiel sind sie gleichwertig.
Wir konstruieren eine gewichtete Adjazenzmatrix, die sich an der Regel orientiert:
, 1 (.. — " "). .
PageRank , . PageRank wie
, PageRank, (.. PageRank), .
PageRank — :
-, ( ). , , — .
Wir bezeichnen , zur Zeit . — , 1.
, — , und — , . ,
. . + M_{in}p_n(t)$$display$$
,
- , , — . , PageRank . — PageRank — !
PageRank . , , , .. wo — . ( , — , ). Page Rank . , 20-30 .
.

"" :
- .. " " — , — , PageRank . . .
- — — PageRank . - . Vektor .
20 ,
- , — . , .. - 5-7 . — . PageRank :
( , )
,
. . , , 37-38 14- cs224w 2017 , , Pinterest ( ).
. ?
:
PageRank. , , - , - .
— .
.
, . - ? 2006 .
:
, - , - .
.

, , , .
, , . - . , — (, ). , IT- , ( ) — .
, , — , , und — .
, — .
- , Kaggle Hackerrank, , , (, ).
:
, ::
:
, . PageRank — . , — .
80% Pinterest.
, , genannt Random Walks with Restarts - Kinderwagen kommen zurück und kehren zu einem für uns interessanten Höhepunkt zurück. Als Ergebnis erhalten wir ein Maß für die Nähe für jeden Scheitelpunkt des Graphen in Bezug auf diesen nur einen. Dies löst das Problem, Verbindungen besser vorherzusagen, als es der Abstand zwischen Adamik und Adar zulässt.
Weitere Verbesserungen hinzufügen:
Denken Sie daran, dass die Rippen $ inline $ \ begin {align *} e (i, j) \ in E \ in G \ end {align *} $ inline $ Unsere Grafik hat Gewichte $ inline $ \ begin {align *} w_ {ji} \ end {align *} $ inline $ .
Auf diese Weise können Sie eine gewichtete Matrix angeben $ inline $ \ begin {align *} M ^ w \ end {align *} $ inline $ Übergangswahrscheinlichkeiten:
$ inline $ \ begin {align *} M ^ {w} _ {ij} = \ left \ {\ begin {matrix} \ frac {w_ {ij}} {\ sum_ {j} w_ {ij}} & \ forall i, j \ iff e (i, j) \ in E, \\ 0 & \ forall i, j \ iff e (i, j) \ notin E. \ end {matrix} \ right. \ end {align *} $ inline $
Der Tramp wird nach wie vor versehentlich Übergänge machen, aber es ist nicht mehr gleich wahrscheinlich!
Ein aufmerksamer Leser hat sich bereits gefragt, wie man diese Gewichte misst.
Facebook war 2011 von der gleichen Sache verwirrt. Es war notwendig, ein Empfehlungssystem für Freunde von Freunden von Freunden aufzubauen, um die Schaffung neuer Verbindungen zu maximieren. Der erste Schritt bestand darin, ein gewichtetes Diagramm der Verbindungen zwischen Benutzern anhand von Informationen in ihren Profilen und im Interaktionsverlauf (Likes, Nachrichten, gemeinsame Fotos usw.) zu erstellen. Messen Sie irgendwie die Kraft der Freundschaft im Internet.
$$ display $$ w_ {ij} = f ^ w (i, j) = e ^ {- \ sum_ {z} {\ xi_z x_ {ij} [z]}}, $$ display $$
wo $ inline $ \ begin {align *} x_ {ij} \ end {align *} $ inline $ Ist der Vektor der Eigenschaften der Eckpunkte und der sie verbindenden Kanten, d.h. $ inline $ \ begin {align *} x_ {ij} = f ^ {(i)} \ cup f ^ {(j)} \ cup f ^ {e (ij)} \ end {align *} $ inline $ und $ inline $ \ begin {align *} \ xi \ end {align *} $ inline $ Ist der Vektor der Gewichte aus den Daten zu lernen.
Hier wird ein geschulter Leser ein lineares Modell erkennen , und ein unvorbereiteter Leser wird darüber nachdenken, dass es sich lohnt, einen offenen maschinellen Lernkurs zu absolvieren, um sich mit dem Gradientenabstieg zu befassen, mit dem wir die Werte von Gewichten in einem Vektor lernen $ inline $ x_ {ij} $ inline $ - Sie zeigen, wie sich Likes und Nachrichten auf Freundschaften im Internet auswirken.
Warum brauchen wir das alles?
Neben der Tatsache, dass der betrachtete Ansatz es uns ermöglicht, Verbindungen noch besser vorherzusagen, können wir die Regeln für eine erfolgreiche Teambildung lernen. Und finden Sie heraus, wonach Sie in Zukunft suchen müssen.
Erinnern Sie sich an die Bedingungen unserer Übung. Wir beobachten die Entwicklung der Zusammenarbeit (gemeinsame Teilnahme an Wettbewerben) in einer Gruppe von bedingten Datasaentisten in der Zwischenzeit $ inline $ \ begin {align *} (t_0, t_0 ^ \ star) \ end {align *} $ inline $ (zum Beispiel ein Kalendermonat) und wir möchten die Teambildung in dem Intervall vorhersagen $ inline $ \ begin {align *} (t_1, t_1 ^ \ star) \ end {align *} $ inline $ (noch ein Monat). Neben der Teilnahme an Wettbewerben verfolgen wir die Kommunikation in Foren, Kerneln und anderen Themen. Alle gesammelten Informationen werden in einer Matrix gespeichert $ inline $ X ^ {\ star} \ in \ mathbb {R} ^ {(2k + l) \ times | E |} $ inline $ (Ihre Spalten sind Vektoren $ inline $ x_ {ij} $ inline $ , $ inline $ k, l $ inline $ - Dimensionen der Vektoren der Eigenschaften von Eckpunkten und Kanten $ inline $ f ^ {(i)}, f ^ {e (ij)} $ inline $ jeweils) und die Grafik $ inline $ \ begin {align *} G \ end {align *} $ inline $ für zwei Zeitintervalle.
Bereiten wir die Daten für das maschinelle Lernen vor.
Für jeden Scheitelpunkt $ inline $ \ begin {align *} i \ end {align *} $ inline $ ::
1) Definieren Sie viele Freunde von Freunden:
$$ Anzeige $$ \ Gamma ^ {fof} (i) = \ bigcup_ {j \ in \ Gamma (i)} \ Gamma (j) - \ Gamma (i) $$ Anzeige $$
2) und Subgraphen konstruieren $ inline $ \ begin {align *} G ^ {fof} (i) \ end {align *} $ inline $ Verbindungen zu Freunden und Freunden von Freunden, $ inline $ \ begin {align *} \ forall e (x, y) \ in E, e (x, y) \ in G ^ {fof} (i) \ iff x, y \ in \ Gamma ^ {fof} (i) \ cup \ Gamma (i) \ end {align *} $ inline $
3) Wählen Sie den Satz von Eckpunkten aus. $ inline $ \ begin {align *} D_i: \ {d_1, ..., d_k \} \ end {align *} $ inline $ mit wem wir Verbindungen geknüpft haben, sind unsere positiven Beispiele für das Lernen,
4) alle nicht zufälligen Verbindungen aus dem Satz $ inline $ \ begin {align *} \ overline {D_i} = \ Gamma ^ {fof} (i) - D_i \ end {align *} $ inline $ - Dies sind unsere negativen Beispiele für das Training.

Unsere Aufgabe ist es, einen solchen Gewichtsvektor auszuwählen $ inline $ \ begin {align *} \ xi \ end {align *} $ inline $ in denen positive Beispiele aus dem Set $ inline $ \ begin {align *} D_i \ end {align *} $ inline $ erhält einen höheren personalisierten PageRank-Wert im Vergleich zu $ inline $ \ begin {align *} i \ end {align *} $ inline $ als negative Beispiele.
Dazu definieren wir die Verlustfunktion, die wir minimieren:
$$ display $$ L = \ sum_ {i} \ sum_ {d \ in D_i, \ overline {d} \ in \ overline {D_i}} h (r _ {\ overline {d}} - r_ {d}) + \ lambda || \ xi || ^ 2, $$ display $$
wo $ inline $ h (x) = 0 \ iff x <0; h (x) = x ^ 2 \ iff x \ geqslant 0; $ inline $ - Strafe für Verstöße gegen die Bestimmungen, $ inline $ \ lambda $ inline $ - Macht $ inline $ L_2 $ inline $ Regularisierung von Gewichten $ inline $ \ xi $ inline $ , $ inline $ r $ inline $ Ist ein Vektor mit Lösungen der Gleichung $ inline $ r = M ^ wr $ inline $ in Bezug auf $ inline $ r $ inline $ für eine Untergrafik von Freunden von Freunden eines einzelnen Tops $ inline $ i $ inline $ .
Ein lustiges Detail - der Gradient dieser Funktion wird auf die gleiche Weise wie der PageRank nach der Power-Methode berechnet. Details finden Sie in der 17. Vorlesung der Ausgabe 2014, Folien 9-27.
So sah die Speerspitze des Fortschritts zum Zeitpunkt meiner ersten Bekanntschaft mit dem cs224w-Kurs aus.
Zufälliger Kinderwagenweg und Spitze im Vektor
Und dann kam der Triumph der Faulheit!
Es ist bekannt, dass die Theorie der Graphen von Leonard Euler erfunden wurde, als er gelangweilt war, das unlösbare Problem der Brücken zu lösen, die sich jetzt in Kaliningrad befinden. Anstatt seinen Kopf umsonst zu trocknen, erfand er einen mathematischen Apparat, mit dem er die grundsätzliche Unmöglichkeit beweisen kann, das Rätsel zu lösen.
In den besten Traditionen der Computerwissenschaften werden wir auch faul sein und uns die Aufgabe stellen, eine Funktion zu finden, die es uns ermöglicht, uns von eindimensionalen Darstellungen von Knoten zu entfernen und zu mehrdimensionalen Eigenschaftsvektoren zu wechseln.

Hier lernen wir Grapheneinbettungen im modernen Sinne kennen.
Formal wollen wir:
1) Definieren Sie einen Encoder (eine ENC-Konformitätsfunktion, die eine Knotentransformation definiert $ inline $ u $ inline $ im Vektor $ inline $ z_u $ inline $ );
2) Bestimmen Sie die Ähnlichkeitsfunktion von Knoten (ein Maß für die Nähe im Diagramm, das wir auf den Eingang des Encoders anwenden werden);
3) Optimieren Sie die Encoderparameter so, dass:
$$ Anzeige $$ Ähnlichkeit (u, v) \ ca. z_ {v} ^ {T} z_v $$ Anzeige $$

Wir bemühen uns sicherzustellen, dass Scheitelpunkte, die im Diagramm eng beieinander liegen, eine enge Darstellung in der Vektorkartierung erhalten. Mit anderen Worten, so dass der Winkel zwischen den beiden erhaltenen Vektoren minimal ist.
Großartig, aber wie kann man diese Nähe in der Grafik bestimmen?
Zum Beispiel nehmen wir an, dass das Gewicht der Rippe ein gutes Maß für die Nähe ist und ungefähr als gleich dem Skalarprodukt für die Einbettung von zwei Knoten angesehen werden kann. Die Verlustfunktion für diesen Fall hat folgende Form:
$$ Anzeige $$ L = \ sum _ {(u, v) \ in V \ mal V} || z_ {u} ^ {T} z_v - A_ {u, v} || ^ 2, $$ display $$
es bleibt zu finden (zum Beispiel Gradientenabstieg) die Matrix $ inline $ Z \ in \ mathbb {R} ^ {d \ times | V |} $ inline $ was minimiert $ inline $ L $ inline $ .
Ein alternativer Ansatz besteht darin, die Umgebung zu bestimmen. $ inline $ N (v) $ inline $ denn der Gipfel ist breiter als viele Nachbarn.

Dies wird uns helfen, um die Grafik herumzugehen. Das erste Projekt, das diesen Ansatz verwendet, ist DeepWalk . Das Wesentliche der Methode ist, dass wir einen Tramp starten, um zufällig von jedem Scheitelpunkt aus um den Graphen herumzulaufen $ inline $ v $ inline $ und füttere kurze Sequenzen fester Länge von Peaks, die während seines Spaziergangs in word2vec besucht wurden.
Die Intuition hier ist, dass die Wahrscheinlichkeitsverteilung beim Besuch der Eckpunkte des Graphen - ein Potenzgesetz - der Wahrscheinlichkeitsverteilung des Auftretens von Wörtern in menschlichen Sprachen sehr ähnlich ist. Und da word2vec für Wörter funktioniert, kann es für Grafiken. Wir haben es versucht - es hat funktioniert!
In DeepWalk implementiert ein Tramp einen Markov-Prozess erster Ordnung - von jedem Scheitelpunkt gehen wir zum Nachbarn, entsprechend den Wahrscheinlichkeiten einer gewichteten Adjazenzmatrix $ inline $ M $ inline $ (oder seine Derivate, wie $ inline $ M ^ w $ inline $ ) Wo wir oben angekommen sind, hat keinen Einfluss auf die Wahl des nächsten Schritts.
Um den Walk zu implementieren, benötigen Sie einen Pseudozufallszahlengenerator und ein bisschen Algebra . Es ist Zeit, den Block für Anführungszeichen für den beabsichtigten Zweck zu verwenden.
„Jeder, der mit den arithmetischen Methoden der Erzeugung einverstanden ist, ist natürlich sündig. Wie wiederholt gezeigt wurde, gibt es keine Zufallszahl - es gibt nur Methoden zum Erstellen solcher Zahlen, und ein striktes arithmetisches Verfahren ist natürlich keine solche Methode ... Wir beschäftigen uns nur mit Rezepten zum Erstellen von Zahlen ... "
- John von Neumann
Es bleibt denjenigen zu raten, die nach einem gerechten Leben streben, das Album „Black and White Noise“ zum Verkauf zu finden - 1995 schrieb George Marsaglia auf die CD eine Reihe von Bytes, die durch Digitalisieren des Rauschens des Verstärkers während des Spielens des Rap-Künstlers empfangen wurden, und benannte es entsprechend.
Die Entwicklung der Methode ist node2vec , in der der Markov-Prozess zweiter Ordnung implementiert ist - wir schauen uns an, woher er stammt, und dies beeinflusst die Wahrscheinlichkeit, die Richtung des nächsten Schritts zu wählen. Mal sehen, wie es funktioniert.
Nehmen wir an, wir starten einen Tramp, der von oben um die Grafik herumgeht $ inline $ u $ inline $ neben der Spitze $ inline $ s_1 $ inline $ Spitzen $ inline $ s_2 $ inline $ und $ inline $ w $ inline $ - in zwei Schritten und $ inline $ s_3 $ inline $ - in drei. Nach jedem Schritt können wir eine von drei möglichen Aktionen ausführen: 1) näher an $ inline $ u $ inline $ ;; 2) erkunden Sie die Gipfel in der gleichen Entfernung von $ inline $ u $ inline $ als derjenige, in dem wir jetzt sind; 3) weg von $ inline $ u $ inline $ .

Diese Strategie wird mit zwei Parametern implementiert:
$ inline $ p $ inline $ - legt die Wahrscheinlichkeit fest, zum vorherigen Scheitelpunkt zurückzukehren;
$ inline $ q $ inline $ - legt das Gleichgewicht zwischen der Suche in der Breite und der Suche in der Tiefe fest.
Diese Parameter bestimmen die nicht normalisierten Übergangswahrscheinlichkeiten wie folgt:
Nehmen wir an, wir sind an der Spitze $ inline $ w $ inline $ und kam von oben hinein $ inline $ s_1 $ inline $ . Für Rippe $ inline $ e (w, s_1) $ inline $ wir werden Gewicht zuweisen (nicht normalisierte Wahrscheinlichkeit) $ inline $ 1 / p $ inline $ . Für Rippe $ inline $ e (w, s_2) $ inline $ - - $ inline $ 1 $ inline $ (wie für alle anderen Kanten, die zu Scheitelpunkten mit gleichem Abstand von führen $ inline $ u $ inline $ ) Für das Weggehen von $ inline $ u $ inline $ Rippen $ inline $ e (w, s_3) $ inline $ - - $ inline $ 1 / q $ inline $ .
Dann normalisieren wir die Wahrscheinlichkeiten (so dass die Summe gleich 1 ist) und machen den nächsten Schritt.
Wir sind an der Abfolge der besuchten Peaks interessiert - wir senden sie an word2vec ( dieser Artikel hilft Ihnen beim Umgang damit oder an Vorlesung 8 aus dem Deep Learning-Kurs an den Fingern ). Die Auswahl von Strategien für den Landstreicher, die zur Lösung spezifischer Probleme optimal sind, ist ein Bereich aktiver Forschung. Zum Beispiel ist node2vec, das wir überprüft haben, ein Champion bei der Klassifizierung von Peaks (zum Beispiel bei der Bestimmung der Toxizität von Drogen oder des Geschlechts / Alters / der Rasse eines Mitglieds eines sozialen Netzwerks).
Wir werden die Wahrscheinlichkeit des Auftretens von Spitzen auf dem Weg des Vagabunden, die Verlustfunktion, optimieren:
$$ Anzeige $$ L = \ sum_ {u \ in V} \ sum_ {v \ in N_ {R} (u)} -log (P (v | z_u)) $$ Anzeige $$
in seiner expliziten Form eine ziemlich teure Rechenlast
$$ display $$ L = \ sum_ {u \ in V} \ sum_ {v \ in N_ {R} (u)} -log (\ frac {e ^ {z_ {u} ^ {T} z_v}} { \ sum_ {n \ in V} e ^ {z_ {u} ^ {T} z_n}}), $$ display $$
was durch einen Zufall durch negative Probenahme gelöst wird, weil
$$ Anzeige $$ Protokoll (\ frac {e ^ {z_ {u} ^ {T} z_v}} {\ sum_ {n \ in V} e ^ {z_ {u} ^ {T} z_n}}) \ ca. log (\ sigma (z_ {u} ^ {T} z_v)) - \ sum_ {i = 1} ^ {k} log (\ sigma (z_ {u} ^ {T} z_ {n_i})), \\ Dabei ist \, \, \, n_i \ sim P_V, \ sigma (x) = \ frac {1} {1 + e ^ {- x}}. $$ display $$
Also haben wir herausgefunden, wie man eine Vektordarstellung der Eckpunkte erhält. Das Ding ist der Hut!

So bereiten Sie Einbettungen für Rippen vor:
Wir müssen einen Operator definieren, der jedes Scheitelpunktpaar zulässt $ inline $ u $ inline $ und $ inline $ v $ inline $ Vektordarstellung erstellen $ inline $ z _ {(u, v)} = g (z_u, z_v) $ inline $ , unabhängig davon, ob sie im Diagramm verbunden sind. Ein solcher Bediener kann sein:
a) arithmetisches Mittel: $ inline $ [z_u \ oplus z_v] _i = \ frac {z_u (i) + z_v (i)} {2} $ inline $ ;;
b) die Arbeit von Hadamard: $ inline $ [z_u \ odot z_v] _i = z_u (i) * z_v (i) $ inline $ ;;
c) gewichtete L1-Norm: $ inline $ || z_u - z_v || _ {\ overline {1} i} = | z_u (i) - z_v (i) | $ inline $ ;;
d) gewichtete L2-Rate: $ inline $ || z_u - z_v || _ {\ overline {2} i} = | z_u (i) - z_v (i) | ^ 2 $ inline $ .
In Experimenten verhält sich die Arbeit von Hadamard am stetigsten.
Denken Sie für alle Fälle an den Satz zum freien Mittagessen:
Kein Algorithmus ist universell - es lohnt sich, mehrere Methoden auszuprobieren.
Die Entwicklung von node2vec ist das OhmNet- Projekt, mit dem Sie mehrere Diagramme zu einer Hierarchie kombinieren und Scheitelpunkteinbettungen für verschiedene Hierarchieebenen erstellen können. Es wurde ursprünglich entwickelt, um die Bindungen zwischen Proteinen in verschiedenen Organen zu modellieren (und sie verhalten sich je nach Standort unterschiedlich).

Ein kluger Leser wird Ähnlichkeiten mit der Organisationsstruktur und den Geschäftsprozessen erkennen.
Und wir - wir werden auf ein Beispiel aus dem Bereich der IT-Rekrutierung zurückkommen - die Auswahl der Personen, die für das bereits vorhandene Team am besten geeignet sind. Zuvor haben wir unimodale Diagramme von Beziehungen bedingter Datasaentisten betrachtet, die aus der Geschichte der Interaktion erhalten wurden (im unimodalen Diagramm des Scheitelpunkts und der Verbindung - vom gleichen Typ). In Wirklichkeit ist die Anzahl der sozialen Kreise, in die eine Person aufgenommen werden kann, mehr als eins.
Angenommen, wir haben neben der Geschichte der gemeinsamen Teilnahme an Wettbewerben auch Informationen darüber gesammelt, wie Rechenzentren in unserem gemütlichen Chat kommuniziert haben. Jetzt haben wir bereits zwei Diagramme von Verbindungen, und OhmNet ist perfekt, um das Problem der Erstellung von Einbettungen aus mehreren Strukturen zu lösen.
Nun - über die Mängel von Methoden, die auf flachen Codierern basieren - gibt es in word2vec nur eine verborgene Schicht, deren Gewichtung die Codierung codiert. Am Ausgang erhalten wir eine Vertex-Vektor-Korrespondenztabelle. Alle diese Ansätze weisen die folgenden Einschränkungen auf:
- Jeder Scheitelpunkt wird von einem eindeutigen Vektor codiert, und das Modell impliziert keine gemeinsame Nutzung von Parametern.
- Wir können nur die Scheitelpunkte codieren, die das Modell während des Trainings gesehen hat. Wir können nichts für die neuen Scheitelpunkte tun (außer wie der Encoder erneut trainiert wird).
- Vertex-Eigenschaftsvektoren werden in keiner Weise berücksichtigt.
Graph-Faltungsnetzwerke sind frei von den angegebenen Mängeln. Wir sind im Zehneck!
Unsere Tage sind ein zufälliger Trampel für alle und jeden
In Bezug auf Landstreicher hatte ich das Glück, meinen ersten Master-Abschluss zu schreiben und ihn 2003 zu verteidigen, aber mit tiefem Training musste ich den klassischen Weg gehen, um herauszufinden, was sich unter der Haube befand. Und dort ist es lustig.
Lassen Sie uns zunächst sehen, warum die Standardmethoden für tiefes Lernen nicht zu den Diagrammen passen.
Grafen sind keine Katzen für dich!
Die modernen Deep-Learning-Tools (mehrschichtige, faltungsbezogene und wiederkehrende Netzwerke) sind für die Lösung von Problemen mit relativ einfachen Daten - Sequenzen und Gittern - optimiert. Ein Graph ist eine kompliziertere Struktur. Eines der Probleme, die uns daran hindern, die Adjazenzmatrix zu nehmen und an das neuronale Netzwerk zu senden, ist der Isomorphismus .
In unserer Spielzeugsäule $ inline $ g $ inline $ bestehend aus Eckpunkten $ inline $ \ {A, B, C, D \} $ inline $ , um eine Adjazenzmatrix zu konstruieren $ inline $ a $ inline $ schlugen wir eine End-to-End-Nummerierung vor $ inline $ \ {1,2,3,4 \} $ inline $ . Es ist leicht zu erkennen, dass wir beispielsweise die Eckpunkte unterschiedlich nummerieren können $ inline $ \ {1,3,2,4 \} $ inline $ oder $ inline $ \ {4,1,3,2 \} $ inline $ - jedes Mal, wenn eine neue Adjazenzmatrix desselben Graphen empfangen wird.
$ inline $ \ begin {align *} A = \ left [\ begin {matrix} 0 & 1 & 3 & 0 \\ 1 & 0 & 2 & 1 \\ 3 & 2 & 0 & 0 \\ 0 & 1 & 0 & 0 \ end {matrix} \ right], \, A ^ {\ {1,3,2,4 \}} = \ left [\ begin {matrix} 0 & 3 & 1 & 0 \\ 3 & 0 & 2 & 0 \\ 1 & 2 & 0 & 1 \\ 0 & 0 & 1 & 0 \ end {matrix} \ right], \, A ^ {\ {4,1,3,2 \}} = \ left [\ begin {matrix} 0 & 1 & 2 & 1 \\ 1 & 0 & 0 & 0 \\ 2 & 0 & 0 & 3 \\ 1 & 0 & 3 & 0 \ end {matrix} \ right]. \ end {align *} $ inline $
Bei Siegeln müsste unser Netzwerk lernen, sie für alle möglichen Permutationen von Zeilen und Spalten zu erkennen - das ist ein weiteres Problem. Versuchen Sie als Übung, die Nummerierung der Punkte im Bild unten so zu ändern, dass Sie eine Katze erhalten, wenn Sie sie in Reihe schalten.

Das nächste Problem für Graphen mit gewöhnlichen neuronalen Netzen ist die Standardeingabedimension. Wenn wir mit Bildern arbeiten, normalisieren wir immer die Größe des Bildes, um es an den Netzwerkeingang zu senden - es ist eine feste Größe. Solche Diagramme funktionieren nicht mit Diagrammen - die Anzahl der Scheitelpunkte kann beliebig sein -, eine weitere Herausforderung besteht darin, die Konnektivitätsmatrix auf eine bestimmte Dimension zu drücken, ohne Informationen zu verlieren.
Lösung - Wir werden neue Architekturen erstellen, die von der Struktur der Diagramme inspiriert sind.

Dazu verwenden wir eine einfache zweistufige Strategie:
- Für jeden Scheitelpunkt erstellen wir einen Berechnungsgraphen unter Verwendung eines Vagabunden.
- Wir sammeln und transformieren Informationen über Nachbarn.
Denken Sie daran, dass wir die Eigenschaften von Eckpunkten in Vektoren speichern $ inline $ f ^ {(u)} $ inline $ - Matrixspalten $ inline $ X \ in \ mathbb {R} ^ {k \ times | V |} $ inline $ und unsere Aufgabe ist für jeden Scheitelpunkt $ inline $ u $ inline $ Sammeln Sie Eigenschaften benachbarter Eckpunkte $ inline $ f ^ {(v \ in N (u))} $ inline $ Einbettungsvektoren zu erhalten $ inline $ z_ {u} $ inline $ . Ein Rechengraph kann eine beliebige Tiefe haben. Betrachten Sie eine zweischichtige Option.

Die Nullschicht ist die Eigenschaft der Eckpunkte, die erste ist eine Zwischenaggregation unter Verwendung einer Funktion (angezeigt durch ein Fragezeichen), die zweite ist die endgültige Aggregation, die die für uns interessanten Einbettungsvektoren erzeugt.
Und was ist in den Kisten?
Im einfachen Fall eine Schicht von Neuronen und Nichtlinearität:
$$ display $$ h ^ 0_v = x_v (= f ^ {(v)}); \\ h ^ k_v = \ sigma (W_k \ sum_ {u \ in N (v)} \ frac {h ^ {k-1} _v} {| N (v) |} + B_k h ^ {k-1} _v), \ forall k \ in \ {1, ..., K \}; \\ z_v = h ^ K_v, $$ display $$
wo $ inline $ W_k $ inline $ und $ inline $ B_k $ inline $ - die Gewichte des Modells, die wir durch Gradientenabstieg unter Anwendung einer der betrachteten Verlustfunktionen lernen werden, und $ inline $ \ sigma $ inline $ - Nichtlinearität, zum Beispiel RELU: $ inline $ \ sigma (x) = max (0, x) $ inline $ .
Und hier befinden wir uns an einem Scheideweg - je nach Aufgabe können wir:
- ohne Lehrer zu lernen und eine der zuvor betrachteten Verlustfunktionen zu nutzen - Landstreicher oder das Gewicht der Kanten. Die resultierenden Gewichte werden so optimiert, dass Vektoren ähnlicher Eckpunkte kompakt platziert werden.
- Beginnen Sie beispielsweise mit einem Lehrer, um das Klassifizierungsproblem zu lösen, und fragen Sie sich, ob das Medikament toxisch ist.
Für das binäre Klassifizierungsproblem hat die Verlustfunktion die Form:
$$ Anzeige $$ L = \ sum_ {v \ in V} y_v Protokoll (\ Sigma (z_v ^ T \ Theta)) + (1-y_v) Protokoll (1- \ Sigma (z_v ^ T \ Theta)), $ $ display $$
wo $ inline $ y_v $ inline $ - Scheitelpunktklasse $ inline $ v $ inline $ , $ inline $ \ theta $ inline $ Ist der Vektor der Gewichte und $ inline $ \ sigma $ inline $ - Nichtlinearität, zum Beispiel ein Sigmoid: $ inline $ \ sigma (x) = \ frac {1} {1 + e ^ {- x}} $ inline $ .
Hier erkennt ein geschulter Leser die Entropie und die logistische Regression, während ein unvorbereiteter Leser über einen offenen Kurs für maschinelles Lernen nachdenkt, um sich mit der Klassifizierungsaufgabe , einfachen und fortgeschritteneren Algorithmen zur Lösung (einschließlich Gradientenverstärkung) vertraut zu machen .
Und wir werden weitermachen und überlegen, wie GraphSAGE , der Vorbote von Decagon, funktioniert.

Für jeden Scheitelpunkt $ inline $ v $ inline $ Wir werden Informationen von Nachbarn sammeln $ inline $ u \ in N (v) $ inline $ und sie selbst.
$$ display $$ h ^ k_v = \ sigma ([W_k \ cdot AGG (\ {h ^ {k-1} _u, \ forall u \ in N (v) \}), B_k h ^ {k-1} _v]), $$ display $$
wo $ inline $ AGG $ inline $ - eine verallgemeinerte Bezeichnung der Aggregationsfunktion - vor allem - differenzierbar.
Mittelwertbildung: Nehmen Sie einen gewichteten Durchschnitt von den Nachbarn
$$ Anzeige $$ AGG = \ sum_ {u \ in N (v)} \ frac {h ^ {k-1} _u} {| N (v) |}. $$ Anzeige $$
Pooling: elementweiser Durchschnitts- / Maximalwert
$$ display $$ AGG = \ gamma (\ {Qh ^ {k-1} _u, \ forall u \ in N (v) \}). $$ display $$
LSTM: Schütteln Sie die Umgebung (nicht mischen!) Und führen Sie LSTM aus
$$ display $$ AGG = LSTM ([h ^ {k-1} _u, \ forall u \ in \ pi (N (v))]). $$ display $$
Pinterest, , PinSAGE .
LSTM ( ). IT-.
:
, — . , . , , , . (/) , , , — — , 30 .
.
— (multi-label node
classification task) — . — . () ( — — 42% ). GraphSAGE, , — .
!
, — , , . , .
- , Decagon. , -, -, , -, — ri . . - 964 ( ) .

— , -, -.

,
— , RELU. , Decagon — . , , GraphSAGE. , .

, .
— , . -. , :
, :
, (end-to-end) -, : (i) — , (ii) — - -, (iii) — , (iv) — .
— - .
— .
— , , : 1) — — ; 2) " , , , " — - . , , , .
— — .
, ( ) , . , , GenBank 1 , , - — , . — , - ( ) , SNAP .
.
Neo4j , (property graph).

, . , , — (i) -, (ii) , (iii) , — — . .
— :

Darüber hinaus leistet Neo4j einen Beitrag zur Industrie, indem er die deklarative Cypher- Sprache erstellt , die ein Diagrammmodell mit Eigenschaften implementiert und in einer SQL-ähnlichen Form mit den folgenden Datentypen arbeitet: Eckpunkte, Relationen, Wörterbücher, Listen, Ganzzahlen, Gleitkomma- und Binärzahlen sowie Saiten. Eine Beispielabfrage, die eine Liste von Filmen mit Nicole Kidman zurückgibt:
MATCH (nicole:Actor {name: 'Nicole Kidman'})-[:ACTED_IN]->(movie:Movie) WHERE movie.year < $yearParameter RETURN movie
Mit Krücken kann Neo4j dazu gebracht werden, im Speicher zu arbeiten.
Erwähnenswert ist auch Gephi - ein praktisches Tool zum Visualisieren und Anlegen von Grafiken in einer Ebene - das erste Netzwerkanalyse-Tool, das von persönlich getestet wurde. Mit einer Dehnung können wir davon ausgehen, dass es in Gephi möglich ist, ein Diagramm mit den Eigenschaften von Scheitelpunkten und Kanten zu implementieren, obwohl die Arbeit damit nicht sehr praktisch ist und der Satz von Algorithmen für die Analyse begrenzt ist. Dies beeinträchtigt nicht die Vorzüge des Pakets - für mich steht es an erster Stelle unter den Visualisierungswerkzeugen. Indem Sie das interne GEXF- Speicherformat beherrschen , können Sie beeindruckende Bilder erstellen. Es bietet die Möglichkeit, problemlos ins Web zu exportieren sowie Eigenschaften für Scheitelpunkte und Kanten rechtzeitig festzulegen und dadurch komplizierte Animationen zu erhalten. Er erstellte die Routen für reisende Verkäufer aus Verkaufsdaten. Alles dank des Layouts der Diagramme auf der Karte anhand der Koordinaten der Eckpunkte - dem Standardteil des Pakets.
Jetzt führe ich den größten Teil der Forschung analytisch durch und zeichne Bilder im Ziel.
Meine Suche nach Werkzeugen und Methoden zur Datenverarbeitung in komplex verbundenen Systemen geht weiter. Vor drei Jahren habe ich eine Lösung für die Arbeit mit multimodalen Graphen gefunden. Die SNAP- Bibliothek von Jure Leskovek ist ein Tool, das er für sich selbst entwickelt hat und das bereits viele Dinge gemessen hat. Ich verwende Snap.py - die Version für Python (Proxy für in C ++ implementierte SNAP-Funktionen) und eine Reihe von ungefähr dreihundert verfügbaren Operationen reichen mir in den meisten Fällen aus.
Kürzlich veröffentlichte Marinka Zhitnik MAMBO - eine Reihe von Tools (inside - SNAP) für die Arbeit mit multimodalen Netzwerken und ein Tutorial in Form einer Reihe von Jupyter-Notizbüchern mit einer beispielhaften Analyse genetischer Mutationen.
Schließlich gibt es das SAP-HANA-Diagramm - dort in ML, SQL, OpenCypher - alles, was Ihr Herz begehrt.
Für SAP HANA ist die Tatsache, dass das Graben wahrscheinlich zu gut strukturierten Transaktionsdaten aus ERP führt, während reine Daten viel wert sind. Ein weiteres Plus - leistungsstarke Tools zum Auffinden von Subgraphen anhand vorgegebener Muster - eine nützliche und schwierige Aufgabe, deren Implementierung in anderen Paketen spezielle Programme nicht erfüllt und verwendet hat . Eine kostenlose Lizenz für den Entwickler bietet eine 1-GB-Datenbank - gerade genug, um mit ausreichend großen Netzwerken zu spielen. Ein lustiger Aufruf - eine Reihe von sofort einsatzbereiten Analysealgorithmen - ist klein. PageRank muss unabhängig implementiert werden. Dazu müssen Sie GraphScript , eine neue Programmiersprache, beherrschen, aber das ist eine Kleinigkeit. Wie mein Ruderslalomtrainer sagte, für den Meister - es ist Staub!
Nun erfahren Sie, woher Sie die Daten beziehen, um daraus Diagramme zu erstellen. Ein paar Ideen:
- Öffentliche Repositories der Universität: Stanford - General and Biomedical , Colorado ;
- Kombinieren Sie den Projektplan mit der Organisationsstruktur und dem Risikoregister.
- Identifizieren Sie die Beziehung zwischen Produktstruktur, Technologie und Benutzerwünschen.
- Führen Sie eine soziografische Studie in einem Team durch.
- Überlegen Sie sich etwas Eigenes, inspiriert von den cs224w-Kursprojekten des letzten Jahres.
Was zu fürchten
Wir können sagen, dass hier die letzte Warnung vor den mit dieser Partei verbundenen Risiken sein wird.

Wie Sie wissen, meine Damen und Herren, besteht das Ziel des Programms darin, den Stand der Dinge an der Spitze einer sehr produktiven und großzügig finanzierten Forschungsgruppe widerzuspiegeln. Dies ist wie in Leningrad , nur in Bezug auf die moderne Mathematik. Mögliche Nebenwirkungen:
- Mahn-Krüger , modifiziert, ohne die Euphorie eines Anfängers und ein Plateau der Exzellenz. Leskovek versucht aufzuholen.
- Langeweile in einer Provinz am Meer. Von den 400 Teilnehmern des Kurses, die den Apparat erhielten, ließen sie mich ein Projekt schreiben und die Prüfung in der ersten Sitzung während meines zweiten Masterstudiengangs bestehen. Die Anzahl betrug eineinhalb. Die Lehrkräfte in ihren Forschungsaktivitäten sind auf der Ebene der Modularitäts- und Zentralitätsmaßnahmen geblieben. Auf Mitaps über Python und Daten ist auch traurig. Im Allgemeinen habe ich Sie gewarnt, wenn Sie nicht wissen, wie Sie sich unterhalten sollen.
- Stolz auf einen slawischen Akzent in der englischen Sprache.
Memo wiedergeben
Hallo Reproduzent!
In dem Abenteuer, das Jura Leskovek uns gegeben hat, brauchen Sie Freizeit. Der Kurs besteht aus 20 Vorlesungen, vier Hausaufgaben, von denen jede empfohlen wird, etwa 20 Stunden zuzuweisen, empfohlener Literatur sowie einer umfangreichen Liste zusätzlicher Materialien, die es ermöglichen, einen ersten Eindruck vom Stand der Dinge zu gewinnen, der bei allen behandelten Themen an vorderster Front steht.
Um die Aufgaben zu erledigen, wird dringend empfohlen, die SNAP-Bibliothek zu verwenden (in gewissem Sinne kann der gesamte Kurs als Überblick über seine Funktionen betrachtet werden).
Außerdem können Sie versuchen, Ihr eigenes Projekt zu implementieren oder ein Tutorial zu einem Thema zu schreiben, das Ihnen gefällt.
Zusammenfassung der Vorlesungen 2017:1. Einführung und Diagrammstruktur
Die Netzwerkanalyse ist eine universelle Sprache zur Beschreibung komplexer Systeme und jetzt ist es an der Zeit, sich damit zu befassen. Der Kurs konzentriert sich auf drei Bereiche: Netzwerkeigenschaften, Modelle und Algorithmen. Beginnen wir mit der Darstellung von Objekten: Knoten, Kanten und deren Organisation.
2. World Wide Web und Random Graph Model
Wir werden lernen, warum das Internet wie ein Schmetterling ist, und uns mit dem Konzept stark verwandter Komponenten vertraut machen. So messen Sie Netzwerke - grundlegende Eigenschaften: Gradverteilung der Knoten, Pfadlänge und Clustering-Koeffizient. Und lernen Sie das Modell des zufälligen Grafen Erdos-Rainey kennen.
3. Das Phänomen der kleinen Welt
Wir messen die Haupteigenschaften eines Zufallsgraphen. Vergleichen Sie es mit realen Netzwerken. Sprechen wir über die Anzahl der Erdosh und wie klein die Welt ist. Erinnern Sie sich an Stanley Milgram und ungefähr sechs Handschläge. Schließlich beschreiben wir alles, was mathematisch geschieht (das Watts-Strogatz-Modell).
4. Dezentrale Suche in der kleinen Welt und Piercing-Netzwerke
So navigieren Sie in einem verteilten Netzwerk. Und wie Torrents funktionieren. Alles zusammen - Eigenschaften, Modelle und Algorithmen.
5. Anwendungen zur Analyse sozialer Netzwerke
Maßnahmen der Zentralität. Menschen im Internet - wie jemand wen bewertet. Der Effekt der Ähnlichkeit. Status Theorie des strukturellen Gleichgewichts.
6. Netzwerke mit mehrdeutigen Kanten
Netzwerkbilanz. Gegenseitige Vorlieben und Status. Wie man die Trolle füttert.
7. Kaskaden: entscheidungsbasierte Modelle
Verbreitung in Netzwerken: Verbreitung von Innovationen, Netzwerkeffekten, Epidemien. Kollektives Aktionsmodell. Entscheidungen und Spieltheorie in Netzwerken.
8. Kaskaden: probabilistische Modelle der Informationsverbreitung
Zufällige baumbasierte epidemische Ausbreitungsmodelle. Die Ausbreitung von Wunden. Unabhängige Kaskaden. Die Mechanismen des viralen Marketings. Wir simulieren die Wechselwirkungen zwischen Infektionen.
9. Einfluss maximieren
So erstellen Sie große Kaskaden. Wie schwierig ist die Aufgabe im Allgemeinen? Die Ergebnisse der Experimente.
10. Erkennung einer Infektion
Was haben Ansteckung und Nachrichten gemeinsam? Wie man mit den interessantesten Schritt hält. Und wo die Sensoren in der Wasserversorgung platziert werden sollen.
11. Studienrecht und bevorzugte Zugehörigkeit
Netzwerkwachstumsprozess. Skaleninvariante Netzwerke. Mathematik der Energieverteilungsfunktion. Folgen: Netzwerkstabilität. Das bevorzugte Beitrittsmodell - die Reichen werden reicher.
12. Wachsende Netzwerkmodelle
Schwänze messen: exponentiell versus exponentiell. Die Entwicklung sozialer Netzwerke. All dies aus der Vogelperspektive.
13. Kronecker-Diagramme
Wir setzen den Flug fort. Waldbrandmodell. Rekursive Graphengenerierung. Stochastische Kronecker-Graphen. Experimente mit realen Netzwerken.
14. Linkanalyse: HITS und PageRank
Wie organisiere ich das Internet? Hubs und Behörden. Der Fund von Sergey Brin und Larry Page. Betrunkener Landstreicher mit Teleport. Empfehlungen geben - Pinterest erleben.
15. Die Stärke schwacher Bindungen und der Gemeinschaftsstruktur in Netzwerken
Triaden und Informationsströme. Wie kann man Communities hervorheben? Die Hirvan-Newman-Methode. Modularität.
16. Community Discovery: Spektrales Clustering
Willkommensmatrix! Suchen Sie nach dem optimalen Abschnitt. Motive (Graflets). Nahrungsketten. Genexpression.
17. Biologische Netzwerke
Proteinwechselwirkungen. Identifizierung von Ketten schmerzhafter Reaktionen. Bestimmung molekularer Eigenschaften wie Proteinfunktionen in Zellen. Was machen Gene? Wir haben Verknüpfungen erstellt.
18. Crossover-Netzwerke
Verschiedene soziale Kreise. Von Clustern zu sich überschneidenden Gemeinschaften.
19. Studiendarstellungen studieren
Die automatische Feature-Bildung ist nur ein Fest für die Faulen. Diagrammeinbettungen. Node2vec. Von einzelnen Graphen bis zu komplexen hierarchischen Strukturen - OhmNet.
20. Netzwerke: ein paar Spaß
Lebenszyklus eines abstrakten Community-Teilnehmers. Und wie man das Verhalten der Community mit Abzeichen verwaltet.
Ich denke, nach dem Eintauchen in die Graphentheorie werden Fragen zu Bäumen nicht mehr beängstigend sein. Dies ist jedoch nur die Meinung eines Amateurs, der noch nie in seinem Leben die Position eines Entwicklers eingenommen hat, der nicht interviewt wurde.