Seit vielen Jahren veranstaltet Mail.ru Meisterschaften für maschinelles Lernen, jedes Mal, wenn die Aufgabe auf ihre eigene Weise interessant und auf ihre eigene Weise komplex ist. Dies ist meine vierte Teilnahme an Wettbewerben, ich mag die Plattform und Organisation sehr und mit Bootcamps begann mein Weg zum wettbewerbsorientierten maschinellen Lernen, aber ich schaffte es zum ersten Mal, den ersten Platz zu belegen. In dem Artikel werde ich Ihnen erklären, wie Sie ein stabiles Ergebnis ohne Umschulung in der öffentlichen Rangliste oder bei verzögerten Stichproben anzeigen können, wenn sich der Testteil erheblich vom Trainingsteil der Daten unterscheidet.
Herausforderung
Der vollständige Text der Aufgabe ist unter →
Link verfügbar. Kurz gesagt: Es gibt 10 GB Daten, wobei jede Zeile drei JSON-Typen von "Schlüssel: Zähler", eine bestimmte Kategorie, einen bestimmten Zeitstempel und eine bestimmte Benutzer-ID enthält. Mehrere Einträge können einem Benutzer entsprechen. Es muss festgelegt werden, zu welcher Klasse der Benutzer gehört, die erste oder die zweite. Die Qualitätsmetrik für das Modell ist ROC-AUC, darüber ist im Blog von Alexander Dyakonov
[1] gut geschrieben.
Beispiel Dateieintrag
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1} {"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39
Lösung
Die erste Idee eines Datenwissenschaftlers, der erfolgreich einen Datensatz heruntergeladen hat, besteht darin, JSON-Spalten in eine spärliche Matrix umzuwandeln. Zu diesem Zeitpunkt hatten viele Teilnehmer Probleme mit einem Mangel an RAM. Bei der Bereitstellung einer einzigen Spalte in Python war der Speicherverbrauch höher als bei einem durchschnittlichen Laptop.
Einige trockene Statistiken. Die Anzahl der eindeutigen Schlüssel in jeder Spalte beträgt 2053602, 20275, 1057788. Darüber hinaus gibt es im Zugteil und im Testteil nur 493866, 20268, 141931. 427994 eindeutige Benutzer im Zug und 181024 im Testteil. Ungefähr 4% der Klasse 1 im Trainingsteil.
Wie Sie sehen können, haben wir viele Schilder. Die Verwendung aller Schilder ist ein offensichtlicher Weg, um im Zug zu überpassen, da beispielsweise Entscheidungsbäume Kombinationen von Schildern verwenden und es noch einzigartigere Kombinationen einer so großen Anzahl von Schildern gibt und fast alle nur im Trainingsteil existieren Daten oder im Test. Eines der Grundmodelle, das ich hatte, war Lightgbm mit Colsample ~ 0.1 und sehr strenger Regularisierung. Trotz der enormen Parameter der Regularisierung zeigte sich jedoch ein instabiles Ergebnis im öffentlichen und privaten Bereich, wie sich nach dem Ende des Wettbewerbs herausstellte.
Der zweite Gedanke der Person, die sich für die Teilnahme an diesem Wettbewerb entschieden hat, wäre wahrscheinlich, den Zug zu sammeln und zu testen und Informationen nach Kennungen zu aggregieren. Zum Beispiel die Menge. Oder maximal. Und hier stellt sich heraus, dass Mail.ru zwei sehr interessante Dinge für uns erfunden hat. Erstens kann der Test mit sehr hoher Genauigkeit klassifiziert werden. Selbst laut Statistiken über die Anzahl der Einträge für cuid und die Anzahl der eindeutigen Schlüssel in json übertrifft der Test den Zug erheblich. Der Basisklassifikator ergab 0,9+ roc-auc bei der Testerkennung. Zweitens machen Zähler keinen Sinn, fast alle Modelle wurden besser, indem sie von Zählern zu binären Vorzeichen der Form wechselten: Es gibt / gibt keinen Schlüssel. Sogar die Bäume, die theoretisch nicht schlechter sein sollten, weil es anstelle einer Einheit eine bestimmte Anzahl gibt, scheinen für Zähler umgeschult zu werden.
Die Ergebnisse in der öffentlichen Rangliste übertrafen die Ergebnisse der Kreuzvalidierung bei weitem. Dies lag anscheinend daran, dass es für das Modell einfacher war, die Rangfolge von zwei Datensätzen im Test zu erstellen als im Zug, da eine größere Anzahl von Zeichen mehr Begriffe für die Rangfolge ergab.
Zu diesem Zeitpunkt wurde völlig klar, dass die Validierung in diesem Wettbewerb keine einfache Sache ist und weder öffentliche Informationen noch Lebensläufe anderer Teilnehmer, die im offiziellen Chat zur Verlockung verleitet werden könnten
[2] . Warum ist es passiert? Es scheint, dass der Zug und der Test durch die Zeit getrennt sind, was später von den Organisatoren bestätigt wurde.
Jedes erfahrene Kaggle-Mitglied wird sofort die gegnerische Validierung empfehlen
[3] , aber es ist nicht so einfach. Trotz der Tatsache, dass die Genauigkeit des Klassifikators für Zug und Test durch die Metrik roc-auc nahe 1 liegt, gibt es im Zug nicht viele ähnliche Einträge. Ich habe versucht, cuid-aggregierte Stichproben mit demselben Ziel zusammenzufassen, um die Anzahl der Datensätze mit einer großen Anzahl eindeutiger Schlüssel in json zu erhöhen. Dies führte jedoch sowohl bei der Kreuzvalidierung als auch in der Öffentlichkeit zu Nachteilen, und ich hatte Angst, solche Modelle zu verwenden.
Es gibt zwei Möglichkeiten: Suchen Sie mit unbeaufsichtigtem Lernen nach ewigen Werten oder versuchen Sie, Funktionen zu übernehmen, die für den Test wichtiger sind. Ich bin in beide Richtungen gegangen und habe TruncatedSVD verwendet, um unbeaufsichtigt zu sein und Funktionen nach Häufigkeit im Test auszuwählen.
Im ersten Schritt habe ich jedoch einen tiefen Autoencoder erstellt, aber ich habe mich geirrt, als ich zweimal dieselbe Matrix verwendet habe. Ich konnte den Fehler nicht beheben und den vollständigen Vorzeichensatz verwenden: Der Eingangstensor passte bei keiner dichten Schichtgröße in den GPU-Speicher. Ich habe einen Fehler gefunden und später nicht versucht, Funktionen zu codieren.
Ich habe SVD auf alle erdenklichen Arten generiert: auf dem Originaldatensatz mit cat_feature und der anschließenden Summierung durch cuid. Für jede Spalte separat. Von tf-idf auf json als Wortsack
[4] (hat nicht geholfen).
Für eine größere Vielfalt habe ich versucht, eine kleine Anzahl von Merkmalen im Zug auszuwählen, wobei A-NOVA für den Zugteil jeder Falte in der Kreuzvalidierung verwendet wurde.
Modelle
Die wichtigsten Basismodelle: lightgbm, vowpal wabbit, xgboost, SGD. Außerdem habe ich mehrere neuronale Netzwerkarchitekturen verwendet. Dmitry Nikitko, der an erster Stelle der öffentlichen Rangliste stand, empfahl die Verwendung von
HashEmbeddings . Dieses Modell zeigte nach einiger Auswahl von Parametern ein gutes Ergebnis und verbesserte das Ensemble.
Ein weiteres neuronales Netzwerkmodell mit der Suche nach Interaktionen (Faktorisierungsmaschinenstil) zwischen 3-4-5 Datenspalten (drei linke Eingaben), numerischen Statistiken (4 Eingaben), SVD-Matrix (5 Eingaben).
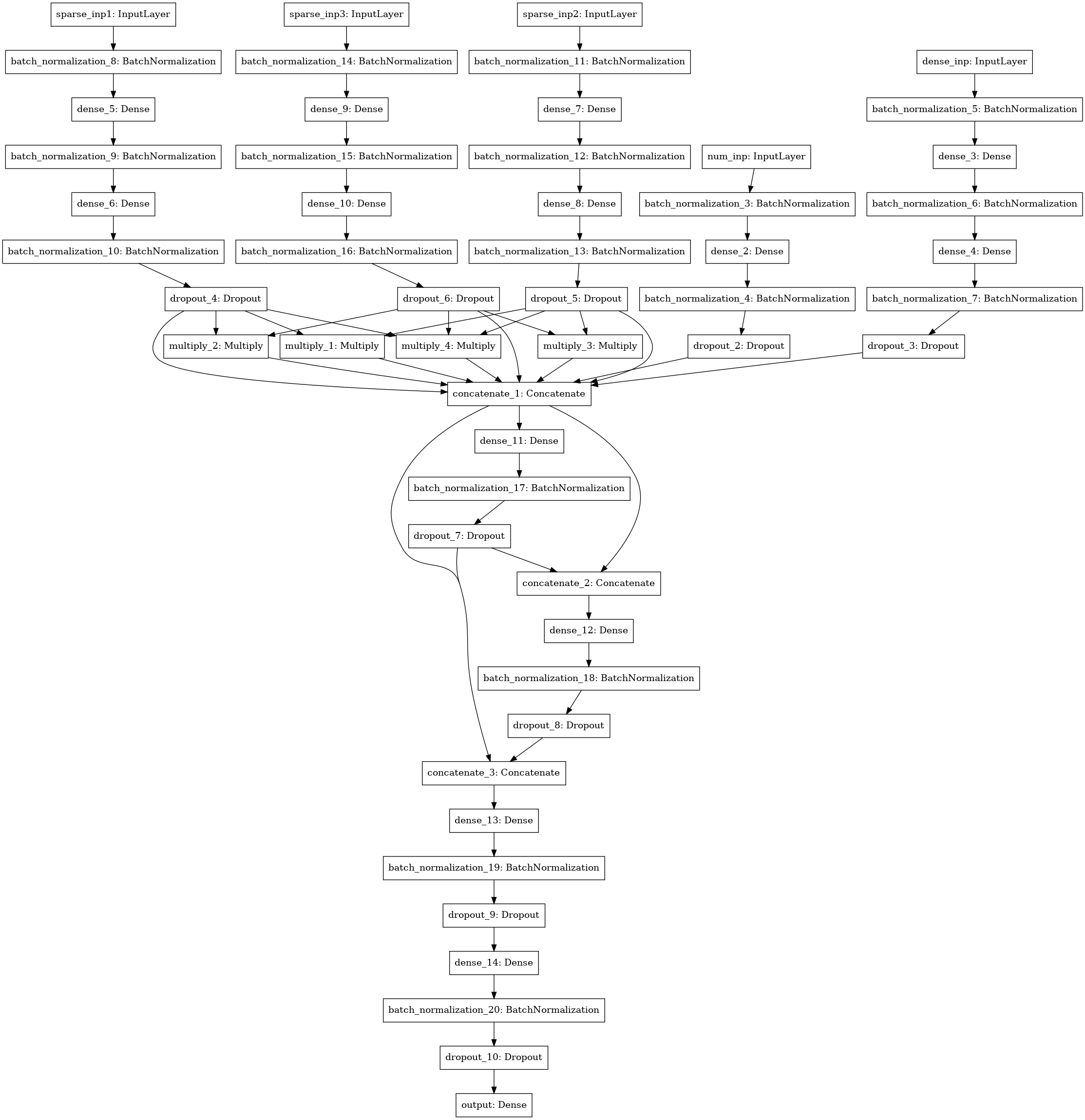
Ensemble
Ich habe alle Modelle nach Falten gezählt und die Testvorhersagen von Modellen gemittelt, die auf verschiedenen Falten trainiert wurden. Zugvorhersagen wurden zum Stapeln verwendet. Das beste Ergebnis zeigte der Level 1-Stack mit xgboost bei den Vorhersagen der Basismodelle und 250 Attributen aus jeder JSON-Spalte, die entsprechend der Häufigkeit ausgewählt wurden, mit der sich das Attribut im Test traf.
Ich habe ungefähr 30 Stunden meiner Zeit mit der Lösung verbracht und mich auf einen Server mit 4 Core-i7-Kernen, 64 Gigabyte RAM und einer GTX 1080 verlassen. Infolgedessen erwies sich meine Lösung als ziemlich stabil und ich wechselte vom dritten Platz in der öffentlichen Rangliste zum ersten privaten.
Ein wesentlicher Teil des Codes ist auf einem Bitbucket in Form von Laptops verfügbar
[5] .
Ich möchte Mail.ru für interessante Wettbewerbe und anderen Teilnehmern für die interessante Kommunikation in der Gruppe danken!
[1]
ROC-AUC auf dem Blog von Aleksandrov Dyakonov[2]
Offizieller Chat ML BootCamp Beamter[3]
Widersprüchliche Validierung[4]
Wortsack[5]
Quellcode für die meisten Modelle