
Das Speichern und Zugreifen auf Daten ist für jedes Informationssystem ein Problem. Selbst ein gut konzipiertes Speichersystem (im Folgenden als SHD bezeichnet) während des Betriebs zeigt Probleme, die mit einer verringerten Leistung verbunden sind. Besondere Aufmerksamkeit sollte einer Reihe von Skalierungsproblemen gewidmet werden, wenn sich die Menge der beteiligten Ressourcen den von Speicherentwicklern festgelegten Grenzwerten nähert.
Der Hauptgrund für das Auftreten dieser Probleme ist die traditionelle Architektur, die auf einer engen Bindung an die Hardwareeigenschaften der verwendeten Speichergeräte basiert. Die meisten Kunden wählen nach wie vor die Methode zum Speichern und Zugreifen auf Daten, wobei die Merkmale der physischen Schnittstellen (SAS / SATA / SCSI) und nicht die tatsächlichen Anforderungen der verwendeten Anwendungen berücksichtigt werden.
Vor einem Dutzend Jahren war dies eine logische Entscheidung. Systemadministratoren wählten sorgfältig Informationsspeichergeräte mit den erforderlichen Spezifikationen aus, z. B. SATA / SAS, und rechneten damit, ein Leistungsniveau zu erreichen, das auf den Hardwarefunktionen von Festplattencontrollern basiert. Der Kampf ging um das Volumen der RAID-Controller-Caches und um Optionen, die Datenverlust verhindern. Dieser Ansatz zur Lösung des Problems ist nicht optimal.
In der aktuellen Umgebung ist es bei der Auswahl von Speichersystemen sinnvoll, nicht von physischen Schnittstellen auszugehen, sondern von der in IOPS ausgedrückten Leistung (Anzahl der E / A-Vorgänge pro Sekunde). Durch die Verwendung der Virtualisierung können Sie vorhandene Hardwareressourcen flexibel nutzen und das erforderliche Leistungsniveau gewährleisten. Wir für unseren Teil sind bereit, Ressourcen mit den Eigenschaften bereitzustellen, die für die Anwendung wirklich notwendig sind.
Speichervirtualisierung
Mit der Entwicklung von Virtualisierungssystemen war es notwendig, eine innovative Lösung zum Speichern und Zugreifen auf Daten zu finden und gleichzeitig die Fehlertoleranz sicherzustellen. Dies war der Ausgangspunkt für die Erstellung von SDS (Software-Defined Storage). Um den geschäftlichen Anforderungen gerecht zu werden, wurden diese Repositorys mit der Trennung von Software und Hardware entwickelt.
Die SDS-Architektur unterscheidet sich grundlegend von der traditionellen. Die Speicherlogik wurde auf Softwareebene abstrahiert. Die Organisation des Speichers ist aufgrund der Vereinheitlichung und Virtualisierung jeder der Komponenten eines solchen Systems einfacher geworden.
Was ist der Hauptfaktor, der die Implementierung von Sicherheitsdatenblättern überall behindert? Dieser Faktor ist meistens eine falsche Bewertung der Bedürfnisse der verwendeten Anwendungen und eine falsche Risikobewertung. Für ein Unternehmen hängt die Wahl der Lösung von den Implementierungskosten ab, basierend auf den aktuell verbrauchten Ressourcen. Nur wenige Leute denken - was passiert, wenn die Informationsmenge und die erforderliche Leistung die Fähigkeiten der ausgewählten Architektur überschreiten. Das Denken auf der Grundlage des methodischen Prinzips „man sollte nicht ohne Notwendigkeit existieren“, besser bekannt als „Occams Klinge“, entscheidet über die Wahl traditioneller Lösungen.
Nur wenige verstehen, dass die Notwendigkeit der Skalierbarkeit und Zuverlässigkeit der Datenspeicherung wichtiger ist, als es auf den ersten Blick scheint. Informationen sind eine Ressource, und daher muss das Risiko ihres Verlusts versichert sein. Was passiert, wenn ein herkömmliches Speichersystem ausfällt? Sie müssen die Garantie nutzen oder neue Geräte kaufen. Und wenn das Speichersystem eingestellt wird oder die "Lebensdauer" (das sogenannte EOL - End-of-Life) beendet ist? Dies kann ein schwarzer Tag für jedes Unternehmen sein, das seine eigenen vertrauten Dienste nicht weiter nutzen kann.
Es gibt keine Systeme, die keinen einzigen Fehlerpunkt haben. Es gibt jedoch Systeme, die den Ausfall einer oder mehrerer Komponenten problemlos überstehen können. Sowohl virtuelle als auch traditionelle Speichersysteme wurden unter Berücksichtigung der Tatsache erstellt, dass früher oder später ein Fehler auftreten wird. Dies ist nur die "Festigkeitsgrenze" herkömmlicher Speichersysteme, die in der Hardware festgelegt sind, aber in virtuellen Speichersystemen wird sie in der Softwareschicht festgelegt.
Integration
Dramatische Änderungen in der IT-Infrastruktur sind immer ein unerwünschtes Phänomen, das mit Ausfallzeiten und Geldverlusten behaftet ist. Nur die reibungslose Implementierung neuer Lösungen ermöglicht es, negative Folgen zu vermeiden und die Arbeit der Dienste zu verbessern. Aus diesem Grund hat Selectel
die Cloud basierend auf VMware entwickelt und
eingeführt , einem anerkannten Marktführer im Bereich Virtualisierung. Mit dem von uns erstellten Service kann jedes Unternehmen alle Infrastrukturaufgaben einschließlich der Datenspeicherung lösen.
Wir werden Ihnen genau sagen, wie wir uns für ein Speichersystem entschieden haben und welche Vorteile uns diese Wahl gebracht hat. Natürlich wurden sowohl traditionelle Speichersysteme als auch Sicherheitsdatenblätter berücksichtigt. Um alle Aspekte des Betriebs und der Risiken klar zu verstehen, bieten wir einen tieferen Einblick in das Thema.
In der Entwurfsphase wurden folgende Anforderungen an Speichersysteme gestellt:
- Fehlertoleranz;
- Leistung
- Skalierung
- die Fähigkeit, Geschwindigkeit zu garantieren;
- korrekter Betrieb im VMware-Ökosystem.
Die Verwendung herkömmlicher Hardwarelösungen konnte nicht das erforderliche Maß an Skalierbarkeit bieten, da es aufgrund architektonischer Einschränkungen unmöglich ist, das Speichervolumen ständig zu erhöhen. Die Reservierung auf der Ebene eines gesamten Rechenzentrums war ebenfalls sehr schwierig. Deshalb haben wir unsere Aufmerksamkeit auf SDS gerichtet.
Es gibt verschiedene Softwarelösungen auf dem SDS-Markt, die für den Aufbau einer Cloud auf Basis von VMware vSphere geeignet sind. Unter diesen Lösungen können festgestellt werden:
- Dell EMC ScaleIO;
- Hyperkonvergentes virtuelles SAN für Datencore;
- HPE StoreVirtual.
Diese Lösungen sind für die Verwendung mit VMware vSphere geeignet. Sie lassen sich jedoch nicht in den Hypervisor integrieren und werden separat ausgeführt. Daher wurde die Wahl zugunsten von VMware vSAN getroffen. Lassen Sie uns im Detail betrachten, wie die virtuelle Architektur einer solchen Lösung aussieht.
Architektur
Bild aus der offiziellen DokumentationIm Gegensatz zu herkömmlichen Speichersystemen werden nicht alle Informationen an einem bestimmten Punkt gespeichert. Die Daten der virtuellen Maschine werden gleichmäßig auf alle Hosts verteilt. Die Skalierung erfolgt durch Hinzufügen von Hosts oder Installieren zusätzlicher Festplattenlaufwerke. Es werden zwei Konfigurationsoptionen unterstützt:
- AllFlash-Konfiguration (nur Solid-State-Laufwerke, sowohl für die Datenspeicherung als auch für den Cache);
- Hybridkonfiguration (magnetischer Speicher und Solid State Cache).
Das Verfahren zum Hinzufügen von Speicherplatz erfordert keine zusätzlichen Einstellungen, z. B. das Erstellen einer LUN (Logical Unit Number, Logical Disk Numbers) und das Festlegen des Zugriffs darauf. Sobald der Host zum Cluster hinzugefügt wird, steht sein Speicherplatz für alle virtuellen Maschinen zur Verfügung. Dieser Ansatz hat mehrere wesentliche Vorteile:
- mangelnde Bindung an den Gerätehersteller;
- erhöhte Fehlertoleranz;
- Gewährleistung der Datenintegrität im Falle eines Fehlers;
- einzelnes Kontrollzentrum über die vSphere-Konsole;
- bequeme horizontale und vertikale Skalierung.
Diese Architektur stellt jedoch hohe Anforderungen an die Netzwerkinfrastruktur. Um einen maximalen Durchsatz zu gewährleisten, basiert das Netzwerk in unserer Cloud auf dem Spine-Leaf-Modell.
Netzwerk
Das traditionelle dreistufige Netzwerkmodell (Kern / Aggregation / Zugriff) weist eine Reihe erheblicher Nachteile auf. Ein bemerkenswertes Beispiel sind die Einschränkungen der Spanning-Tree-Protokolle.
Das Spine-Leaf-Modell verwendet nur zwei Ebenen, was die folgenden Vorteile bietet:
- vorhersehbarer Abstand zwischen Geräten;
- Der Verkehr verläuft auf der besten Route.
- einfache Skalierung;
- Ausschluss von L2-Protokollbeschränkungen.
Ein wesentliches Merkmal einer solchen Architektur ist, dass sie für den Durchgang von "horizontalem" Verkehr optimiert ist. Datenpakete durchlaufen nur einen Sprung, was eine klare Schätzung der Verzögerungen ermöglicht.
Eine physische Verbindung wird über mehrere 10-GbE-Verbindungen pro Server bereitgestellt, deren Bandbreite mithilfe des Aggregationsprotokolls kombiniert wird. Somit erhält jeder physische Host Hochgeschwindigkeitszugriff auf alle Speicherobjekte.
Der Datenaustausch wird mithilfe eines von VMware erstellten proprietären Protokolls implementiert, das einen schnellen und zuverlässigen Betrieb des Speichernetzwerks beim Ethernet-Transport (ab 10 GbE) ermöglicht.
Der Übergang zum Objektmodell der Datenspeicherung ermöglichte eine flexible Anpassung der Speichernutzung an die Anforderungen der Kunden. Alle Daten werden in Form von Objekten gespeichert, die auf bestimmte Weise auf die Cluster-Hosts verteilt werden. Wir klären die Werte einiger Parameter, die gesteuert werden können.
Fehlertoleranz
- FTT (Fehler zu tolerieren). Gibt die Anzahl der Hostfehler an, die der Cluster verarbeiten kann, ohne den regulären Betrieb zu unterbrechen.
- FTM (Fehlertoleranzmethode). Die Methode zur Gewährleistung der Fehlertoleranz auf Plattenebene.
a. Spiegeln
Bild aus dem VMware-Blog.
Stellt eine vollständige Vervielfältigung eines Objekts dar, und Replikate befinden sich immer auf verschiedenen physischen Hosts. Das dieser Methode am nächsten liegende Analogon ist RAID-1. Durch seine Verwendung kann der Cluster routinemäßig bis zu drei Fehler von Komponenten (Festplatten, Hosts, Netzwerkverlust usw.) verarbeiten. Dieser Parameter wird durch Einstellen der FTT-Option konfiguriert.
Standardmäßig hat diese Option den Wert 1, und für das Objekt wird 1 Replikat erstellt (nur 2 Instanzen auf verschiedenen Hosts). Mit zunehmendem Wert beträgt die Anzahl der Kopien N + 1. Bei einem Maximalwert von FTT = 3 befinden sich 4 Instanzen des Objekts auf verschiedenen Hosts.
Mit dieser Methode können Sie maximale Leistung auf Kosten der Speicherplatzeffizienz erzielen. Es kann sowohl in Hybrid- als auch in AllFlash-Konfigurationen verwendet werden.
b. Löschcodierung (analog zu RAID 5/6).
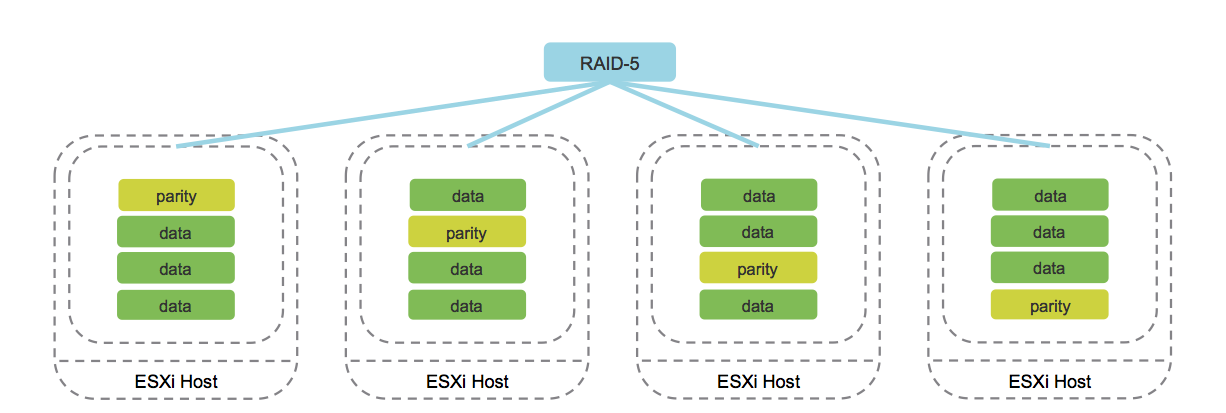
Bild aus dem Blog von cormachogan.com.
Die Arbeit dieser Methode wird ausschließlich in AllFlash-Konfigurationen unterstützt. Bei der Aufzeichnung jedes Objekts werden die entsprechenden Paritätsblöcke berechnet, die im Falle eines Fehlers die eindeutige Wiederherstellung von Daten ermöglichen. Dieser Ansatz spart im Vergleich zur Spiegelung erheblich Speicherplatz.
Natürlich erhöht der Betrieb dieses Verfahrens den Overhead, was sich in einer Verringerung der Produktivität äußert. Angesichts der Leistung der AllFlash-Konfiguration ist dieser Nachteil jedoch ausgeglichen, sodass die Verwendung der Löschcodierung für die meisten Aufgaben eine akzeptable Option ist.
Darüber hinaus führt VMware vSAN das Konzept der „Fehlerdomänen“ ein, bei denen es sich um eine logische Gruppierung von Server-Racks oder Festplattenkörben handelt. Sobald die erforderlichen Elemente gruppiert sind, führt dies zur Verteilung der Daten auf verschiedene Knoten unter Berücksichtigung der Fehlerdomänen. Auf diese Weise kann der Cluster den Verlust einer gesamten Domäne überleben, da sich alle entsprechenden Replikate der Objekte auf anderen Hosts in einer anderen Fehlerdomäne befinden.
Die kleinste Fehlerdomäne ist eine Datenträgergruppe, bei der es sich um ein logisch verbundenes Laufwerk handelt. Jede Datenträgergruppe enthält zwei Arten von Medien - Cache und Kapazität. Als Cache-Medium erlaubt das System die Verwendung nur von Solid-State-Disks, und sowohl Magnet- als auch Solid-State-Disks können als Kapazitätsträger fungieren. Durch das Zwischenspeichern von Medien können Magnetplatten beschleunigt und die Latenz beim Zugriff auf Daten verringert werden.
Implementierung
Lassen Sie uns darüber sprechen, welche Einschränkungen in der VMware vSAN-Architektur bestehen und warum sie benötigt werden. Unabhängig von den verwendeten Hardwareplattformen bietet die Architektur die folgenden Einschränkungen:
- nicht mehr als 5 Plattengruppen pro Host;
- nicht mehr als 7 Kapazitätsträger in einer Plattengruppe;
- nicht mehr als 1 Cache-Träger in einer Plattengruppe;
- nicht mehr als 35 Kapazitätsträger pro Host;
- nicht mehr als 9000 Komponenten pro Host (einschließlich Zeugenkomponenten);
- nicht mehr als 64 Hosts in einem Cluster;
- Nicht mehr als 1 vSAN-Datenspeicher pro Cluster.
Warum wird das benötigt? Bis die angegebenen Grenzwerte überschritten werden, arbeitet das System mit der angegebenen Kapazität und hält ein Gleichgewicht zwischen Leistung und Speicherkapazität aufrecht. Auf diese Weise können Sie den korrekten Betrieb des gesamten virtuellen Speichersystems als Ganzes gewährleisten.
Zusätzlich zu diesen Einschränkungen sollte ein wichtiges Merkmal beachtet werden. Es wird nicht empfohlen, mehr als 70% des gesamten Speichervolumens zu füllen. Tatsache ist, dass bei Erreichen von 80% der Neuausgleichsmechanismus automatisch gestartet wird und das Speichersystem beginnt, Daten auf alle Cluster-Hosts zu verteilen. Das Verfahren ist sehr ressourcenintensiv und kann die Leistung des Festplattensubsystems erheblich beeinträchtigen.
Um den Anforderungen einer Vielzahl von Kunden gerecht zu werden, haben wir drei Speicherpools implementiert, um die Verwendung in verschiedenen Szenarien zu vereinfachen. Schauen wir uns jeden von ihnen der Reihe nach an.
Schneller Plattenpool
Die Priorität beim Erstellen dieses Pools bestand darin, Speicher zu erhalten, der maximale Leistung für das Hosten hoch ausgelasteter Systeme bietet. Server aus diesem Pool verwenden ein Paar Intel P4600 als Cache und 10 Intel P3520 als Datenspeicher. Der Cache in diesem Pool wird verwendet, damit Daten direkt vom Medium gelesen werden und Schreibvorgänge über den Cache ausgeführt werden.
Um die Nutzkapazität zu erhöhen und die Fehlertoleranz sicherzustellen, wird ein Datenspeichermodell namens Erasure Coding verwendet. Dieses Modell ähnelt einem normalen RAID 5/6-Array, jedoch auf der Ebene der Objektspeicherung. Um die Wahrscheinlichkeit einer Datenbeschädigung auszuschließen, verwendet vSAN einen Prüfsummenberechnungsmechanismus für jeden 4K-Datenblock.
Die Validierung wird im Hintergrund während Lese- / Schreibvorgängen sowie für „kalte“ Daten durchgeführt, auf die im Laufe des Jahres kein Zugriff angefordert wurde. Wenn eine Nichtübereinstimmung der Prüfsumme festgestellt wird und daher eine Datenbeschädigung festgestellt wird, stellt vSAN Dateien automatisch durch Überschreiben wieder her.
Hybrid-Laufwerkpool
Bei diesem Pool besteht seine Hauptaufgabe darin, eine große Datenmenge bereitzustellen und gleichzeitig ein gutes Maß an Fehlertoleranz sicherzustellen. Bei vielen Aufgaben hat die Geschwindigkeit des Datenzugriffs keine Priorität, das Volumen und die Speicherkosten sind viel wichtiger. Die Verwendung von Solid-State-Laufwerken als solcher Speicher ist mit unangemessen hohen Kosten verbunden.
Dieser Faktor war der Grund für die Erstellung des Pools, der eine Mischung aus Solid-State-Laufwerken (wie in anderen Pools Intel P4600) und von HGST entwickelten Festplatten auf Unternehmensebene ist. Ein hybrider Workflow beschleunigt den Zugriff auf häufig angeforderte Daten durch Zwischenspeichern von Lese- und Schreibvorgängen.
Auf der logischen Ebene werden Daten gespiegelt, um Verluste bei einem Hardwarefehler zu vermeiden. Jedes Objekt ist in identische Komponenten unterteilt und wird vom System an verschiedene Hosts verteilt.
Pool mit Notfallwiederherstellung

Die Hauptaufgabe des Pools besteht darin, ein Höchstmaß an Fehlertoleranz und Leistung zu erreichen. Durch die Verwendung der
Stretched vSAN- Technologie konnten wir den Speicher zwischen den Rechenzentren Tsvetochnaya-2 in St. Petersburg und Dubrovka-3 in der Region Leningrad
verteilen . Jeder Server in diesem Pool ist mit zwei leistungsstarken Intel P4600-Laufwerken für den Cache-Betrieb und 6 Intel P3520-Laufwerken für die Datenspeicherung ausgestattet. Auf der logischen Ebene sind dies 2 Plattengruppen pro Host.
Die AllFlash-Konfiguration hat keinen schwerwiegenden Nachteil - einen starken Rückgang der IOPS und eine Zunahme der Warteschlange für Festplattenanforderungen mit einem erhöhten Volumen an wahlfreiem Zugriff auf Daten. Genau wie in einem Pool mit schnellen Festplatten werden Schreibvorgänge durch den Cache geleitet und das Lesen erfolgt direkt.
Nun zum Hauptunterschied zum Rest der Pools. Die Daten jeder virtuellen Maschine werden in einem Rechenzentrum gespiegelt und gleichzeitig synchron in ein anderes Rechenzentrum repliziert, das uns gehört. Selbst ein schwerer Unfall, beispielsweise eine vollständige Unterbrechung der Konnektivität zwischen Rechenzentren, ist daher kein Problem. Selbst ein vollständiger Verlust des Rechenzentrums wirkt sich nicht auf die Daten aus.
Ein Unfall mit einem vollständigen Ausfall der Site - die Situation ist ziemlich selten, aber vSAN kann sie mit Ehre überleben, ohne Daten zu verlieren. Die Gäste unserer
SelectelTechDay 2018- Veranstaltung konnten sich selbst davon überzeugen, wie im Stretched vSAN-Cluster ein vollständiger Standortfehler aufgetreten ist. Virtuelle Maschinen wurden nur eine Minute nach dem Ausschalten aller Server an einem der Standorte verfügbar. Alle Mechanismen funktionierten genau wie geplant, aber die Daten blieben unberührt.
Die Aufgabe der bekannten Speicherarchitektur bringt viele Änderungen mit sich. Eine dieser Änderungen war die Entstehung neuer virtueller „Entitäten“, zu denen auch die Zeugen-Appliance gehört. Die Bedeutung dieser Lösung besteht darin, den Prozess der Aufzeichnung von Replikaten von Daten zu verfolgen und zu bestimmen, welche relevant sind. Gleichzeitig werden die Daten selbst nicht in Zeugenkomponenten gespeichert, sondern nur in Metadaten zum Aufzeichnungsprozess.
Dieser Mechanismus wird im Falle eines Unfalls wirksam, wenn während des Replikationsprozesses ein Fehler auftritt, der dazu führt, dass die Replikate nicht synchron sind.
Um festzustellen, welche relevante Informationen enthalten, wird ein Quorum-Bestimmungsmechanismus verwendet. Jede Komponente hat ein „Stimmrecht“ und erhält eine bestimmte Anzahl von Stimmen (1 oder mehr). Das gleiche „Stimmrecht“ hat Zeugenbestandteile, die im Falle einer kontroversen Situation die Rolle von Schiedsrichtern spielen.
Ein Quorum wird nur erreicht, wenn für ein Objekt eine vollständige Replik verfügbar ist und die Anzahl der aktuellen „Stimmen“ mehr als 50% beträgt.
Fazit
Die Wahl von VMware vSAN als Speichersystem ist für uns zu einer wichtigen Entscheidung geworden. Diese Option hat Stresstests und Fehlertoleranztests bestanden, bevor sie in unser VMware-basiertes Cloud-Projekt aufgenommen wurde.
Den Testergebnissen zufolge wurde deutlich, dass die deklarierte Funktionalität wie erwartet funktioniert und alle Anforderungen unserer Cloud-Infrastruktur erfüllt.
Haben Sie aufgrund Ihrer eigenen Erfahrung mit vSAN etwas zu erzählen? Willkommen zu den Kommentaren.