Vor einigen Monaten wurde die erste Version von Kepler.gl veröffentlicht - ein neues Open Source-Tool zur Visualisierung und Analyse großer Mengen von Geodaten.
In diesem Artikel schlage ich vor, dass Sie sich mit den Hauptfunktionen der Anwendung vertraut machen und daraus zwei kartografische Visualisierungen erstellen, mit denen wir einige interessante Fakten über kostenpflichtiges Parken in Moskau herausfinden können.
Aber zuerst ein paar Worte darüber, wer und warum Kepler.gl erstellt hat
Ursprünglich wurde Kepler.Gl vom Uber Engineering-Team für Unternehmensanalysten entwickelt, die besser verstehen wollten, wie sich die Stadt bewegt. Dabei wurde eine große Menge von Geoinformations-Verkehrsdaten verwendet, die täglich von Tausenden von „Uber“ in verschiedenen Städten auf der ganzen Welt gesammelt wurden.
Im Mai dieses Jahres kündigte das Unternehmen jedoch den offenen Zugriff auf diese Anwendung an und veröffentlichte den gesamten Quellcode von Kepler.gl auf GitHub
Hauptmerkmale von Kepler.gl
Unabhängig von den ausgewählten Datenanalysetools, den verwendeten Kartendiensten oder Frameworks sowie den Bibliotheken zum Erstellen verschiedener Visualisierungen wird der Prozess der Bearbeitung auf vier Hauptschritte reduziert:
- Informationsbeschaffung
- Datenverarbeitung
- Recherche und Analyse vorbereiteter Daten (um Abhängigkeiten zu identifizieren, nach Anomalien zu suchen usw.)
- Visualisierungserstellung
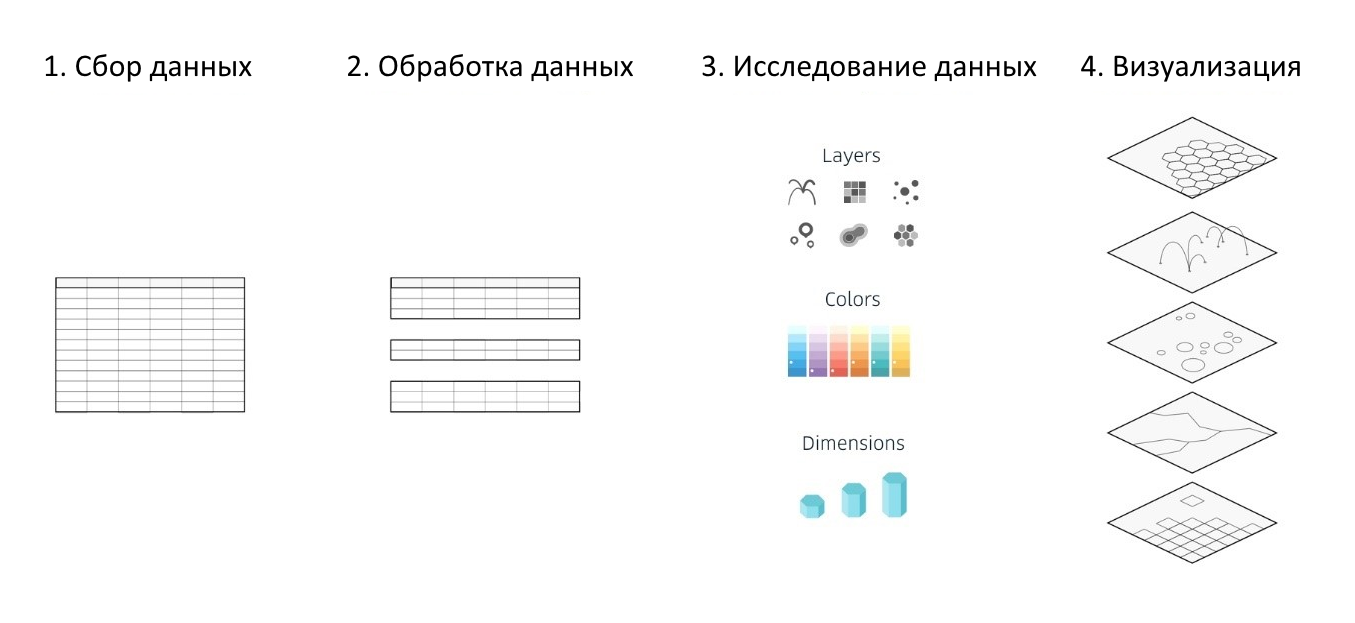 Abbildung 1. Die grundlegenden Schritte zum Erstellen einer Visualisierung
Abbildung 1. Die grundlegenden Schritte zum Erstellen einer VisualisierungKepler.gl automatisiert und vereinfacht teilweise 3 der 4 aufgeführten Schritte, was den gesamten Prozess der Analyse und Visualisierung großer Datenmengen erheblich vereinfacht und dazu beiträgt, in nur einer halben Stunde eine informative und vor allem farbenfrohe interaktive Karte auf der Grundlage Ihrer eigenen Geodatensätze zu erstellen.
Gleichzeitig sind Programmier- oder Entwurfserfahrung absolut nicht erforderlich, da Filterung und Datenaggregation, Auswahl einer Möglichkeit zur Anzeige von Daten in Abhängigkeit von verschiedenen Parametern der untersuchten Objekte, Überlagerung von Informationen aus verschiedenen Quellen, Umschalten zwischen 2D- und 3D-Modus und vieles mehr über das UI-Bedienfeld konfiguriert werden.
Verwendung von Kepler.gl für die Datenanalyse
Am einfachsten ist es, Kepler.gl über die Online-Version von
kepler.gl kennenzulernen . Wenn Sie Servern von Drittanbietern nicht vertrauen, können Sie eine lokale Version
gemäß den Anweisungen auf
GitHub selbst bereitstellen.
Im Folgenden werde ich die Daten zum „Bezahlten Parken in Moskau“ verwenden, die vom „Open Data Portal“ der Moskauer Regierung bereitgestellt werden. Dieses Set enthält Informationen zu mehr als 9.000 Objekten im Straßennetz, einschließlich Informationen zu Kosten und Anzahl der Parkplätze.
Stufe 1. Laden von Daten
Bisher unterstützt Kepler.gl drei Quelldatenformate: Geojson, Json und CSV. Nachdem wir die Daten in einem der angegebenen Formate gespeichert haben (in diesem Beispiel verwende ich .csv), laden wir sie einfach in die Anwendung. Übrigens können Sie hier im Download-Dialog, um sich mit der Anwendung vertraut zu machen, auch einen der Dutzenden vordefinierter Testdatensätze verwenden.
Hinweis Für Chrome sollte die maximale Größe der Upload-Datei 250 MB nicht überschreiten. Die Entwickler von Kepler.gl empfehlen die Verwendung von Safari, wenn Sie eine größere Datei herunterladen müssen. In jedem Fall müssen Sie jedoch berücksichtigen, dass die Leistung der Anwendung von dem Gerät abhängt, auf dem sie ausgeführt wird. Schließlich finden alle Manipulationen im Zusammenhang mit der Aggregation, Filterung und Anzeige von Daten auf dem Client statt.
Stufe 2. Anzeigen von Daten auf einer Karte
Die Anwendung unterstützt 9 Arten von Visualisierungsebenen (Ebene der Datenvisualisierung), die sich in einer Reihe anpassbarer Parameter voneinander unterscheiden:
- Punktschicht
- Bogenschicht (Bogen)
- Linienschicht (Linie)
- Gitter (Gitter)
- sechseckiges Gitter (Hexbin)
- Schichtpolygone (Poligon)
- Cluster-Schicht (Claster)
- Symbolebene (Symbol)
- Heatmap (Heatmap)
Darüber hinaus können sich sogar Ebenen desselben Typs, die denselben Datensatz anzeigen, je nach ausgewählter Konfiguration erheblich unterscheiden.

Abbildung 2. In kepler.gl mit verschiedenen Arten von Ebenen erstellte Karten
Kepler.gl begrenzt nicht die Anzahl der Ebenen, die beim Anzeigen des Testdatensatzes verwendet werden. Ebenen werden auf der Karte in derselben Reihenfolge gezeichnet, in der sie sich in der Ebenenliste im Seitenbereich befinden. Diese Reihenfolge kann einfach geändert werden, indem die entsprechenden Ebenen auf der Registerkarte Ebenen einfach relativ zueinander gezogen werden.
Beachten Sie bei Verwendung mehrerer Ebenen den Parameter „Ebenenüberblendung“, der für die Überlappung der Ebenen verantwortlich ist. Es ist über die gesamte Visualisierung hinweg einheitlich, was es unmöglich macht, verschiedene Arten der Mischung für verschiedene Schichten zu verwenden.
Derzeit sind drei Werte für diesen Parameter verfügbar:
- Normal
In diesem Fall beeinflussen die unteren Schichten die Farbe der Punkte (oder anderer Elemente) der oberen Schichten nicht.
- Additiv
Bei dieser Art der Überlagerung addieren sich die Farbwerte der übereinstimmenden Elemente. Es ist praktisch, um Bereiche mit hoher Dichte zu identifizieren, die in diesem Fall heller sind. - Subtraktiv
Im Gegensatz zum Additiv wird die Bedeutung von Farben in sich überschneidenden Bereichen nicht addiert, sondern subtrahiert. Dies ist praktisch, wenn Sie keine dunkle, sondern eine helle Karte verwenden.
Um unsere Daten auf der Karte zu sehen, muss mindestens eine Ebene daraus erstellt werden. Es ist erwähnenswert, dass Kepler.gl nach dem Herunterladen der Datei versucht, die Felder mit den Geolokalisierungsinformationen zu identifizieren und sofort anzuzeigen, wobei automatisch Ebenen der entsprechenden Typen (normalerweise Punkt oder Polygon) erstellt werden.
In unserem Fall müssen Sie jedoch aufgrund der unterschiedlichen erwarteten und verwendeten Datenformate die Koordinatenquelle selbst angeben. Löschen Sie dazu zuerst die von Kepler.gl erstellten Polygonebenen und fügen Sie dann manuell eine neue Ebene vom Typ Punkt hinzu. Als Koordinatenquelle verwenden wir die Felder Latitude_WGS84 und Longitude_WGS84 anstelle des von der Anwendung automatisch ausgewählten Felds Koordinaten zum Rendern von Daten auf der Karte.
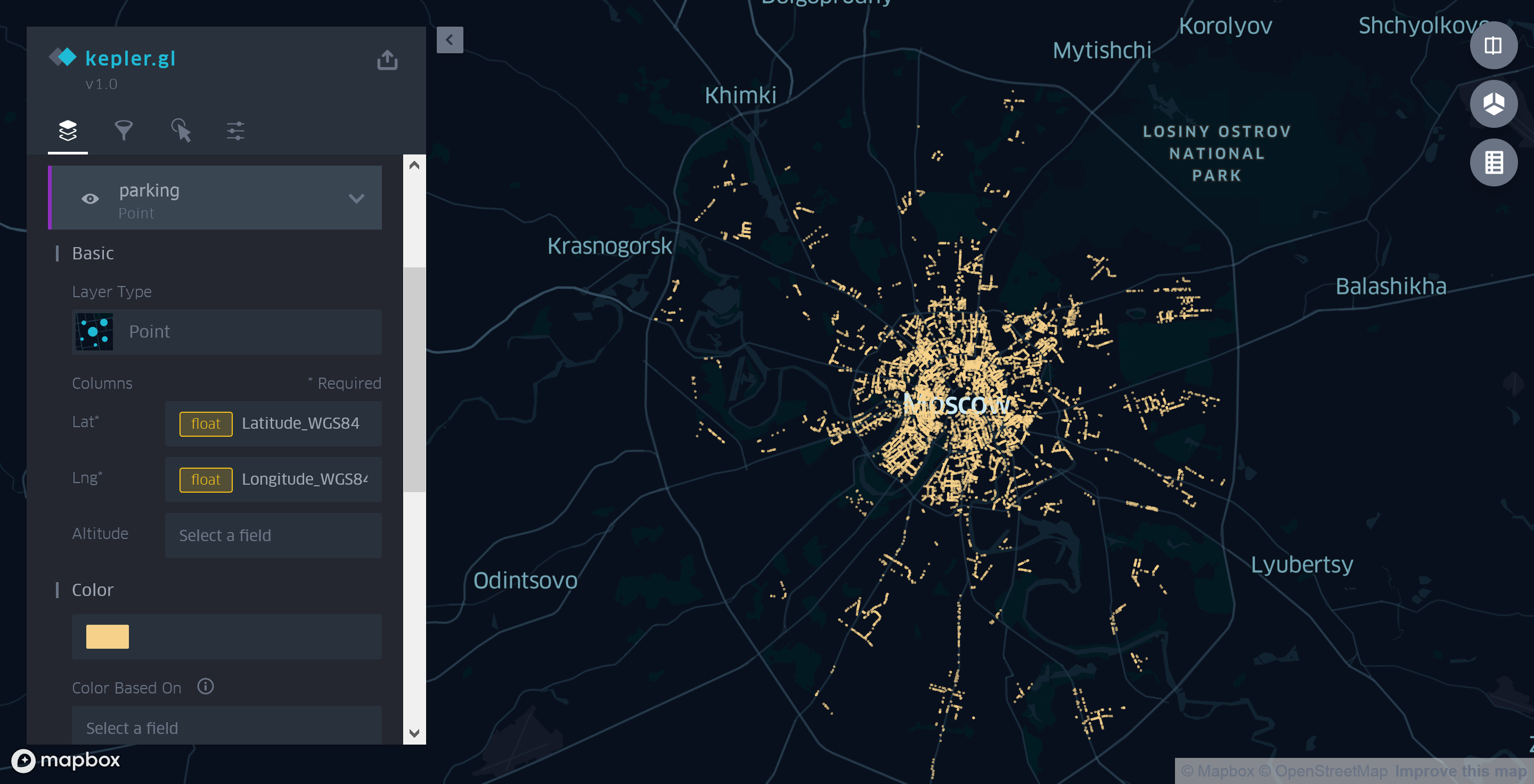
Abbildung 3. Verwenden der Spot-Ebene Kepler.gl zum Anzeigen von Moskauer Parkplätzen
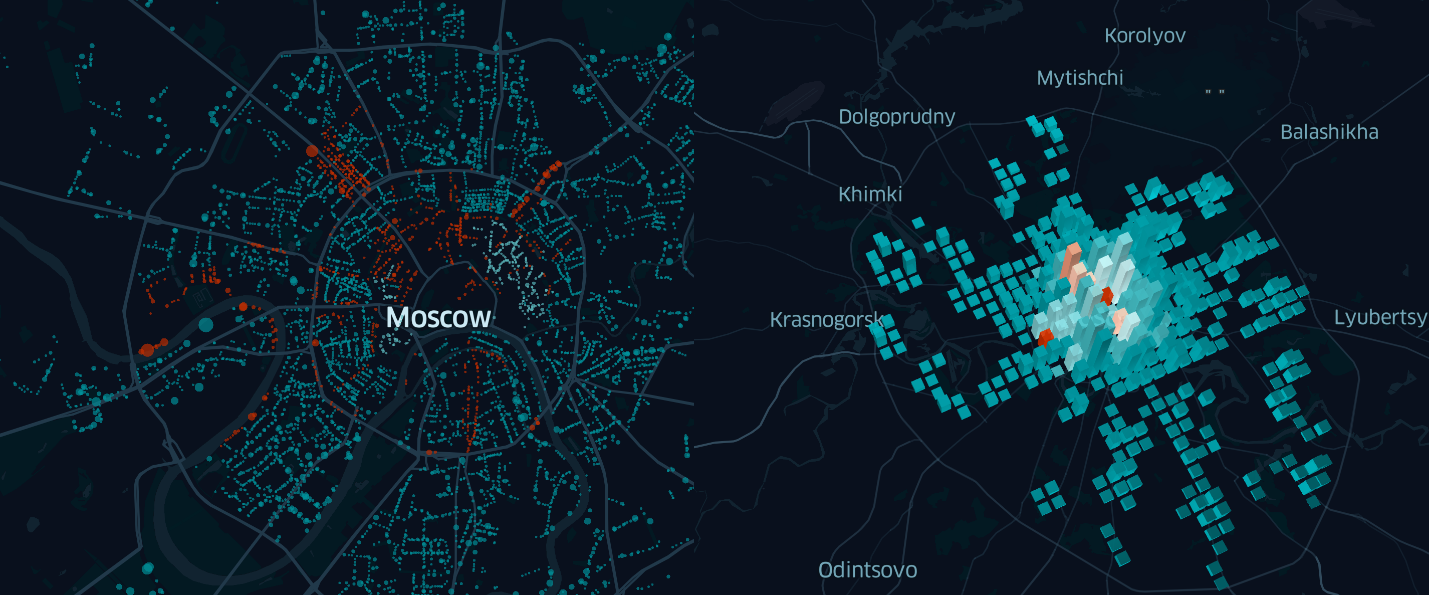
In dieser Ausführungsform ist die Karte nicht sehr informativ. Das einzige, was man sagen kann, wenn man sie ansieht, ist, dass es in der Mitte mehr Parkplätze gibt als am Stadtrand.
Es ist also an der Zeit, andere Informationen zu den untersuchten Objekten für eine detailliertere Analyse zu verwenden und nach interessanten Fakten und / oder Mustern zu suchen.
Stufe 3. Änderung des Erscheinungsbilds der Karte auf der Grundlage zugehöriger Daten zu den angezeigten Objekten
Das vom Open Data Portal heruntergeladene Set enthält viele Informationen zu den einzelnen Parkplätzen. Zwei Parameter schienen mir jedoch am interessantesten zu sein - die Kosten für eine Stunde Parken und die Anzahl der verfügbaren Parkplätze.
Wo sind die teuersten Parkplätze in Moskau? Gibt es einen Zusammenhang zwischen der Größe des Parkplatzes und seiner Entfernung vom Cent? Wie hoch ist der Unterschied in den Kosten für eine Stunde Parken innerhalb und außerhalb des Gartenrings? Um diese Fragen zu beantworten, müssen wir die Anzeigeeinstellungen der zuvor erstellten Punktebene leicht ändern und erneut auf die Karte schauen.
Ändern Sie zunächst die Farbe der Punkte in Abhängigkeit von den Kosten für eine Stunde Parken an diesem Ort. Zu diesem Zweck geben wir in der Dropdown-Liste „Farbe basierend auf“ als Grundlage für die Auswahl einer Farbe den Parameter „Preis“ des Originaldatensatzes an.

Abbildung 4. Verwenden der Farbe zum Anzeigen der Kosteninformationen für die Parkzeit
Bereits zu diesem Zeitpunkt können einige interessante Beobachtungen gemacht werden. Zum Beispiel, dass nicht das gesamte Zentrum für Autofahrer gleich teuer ist, aber auf Twerskaja ist es besser, Fußgänger zu sein
Schauen wir uns nun die Kapazität der Parkplätze an. Dazu verwenden wir das Feld „CarCapacity“ als Basisparameter zur Bestimmung des Radius eines Punktes (das Attribut „Radius Based On“ einer Punktebene). Stellen Sie den Radiusbereich von 0 bis 30 Pixel ein.

Abbildung 5. Anpassung der Größe der Punkte in Abhängigkeit von der Anzahl der Parkplätze
So ist unsere Parkkarte in wenigen Minuten spürbar informativer geworden. Selbst ein flüchtiger Blick darauf ermöglicht es nicht nur, die Preispolitik verschiedener Stadtteile zu vergleichen, sondern auch Ihre Chancen, einen freien Platz zu finden, grob zu bewerten, wenn man nicht nur die Anzahl der Parkplätze in der Nähe berücksichtigt, sondern auch deren Geräumigkeit.
Stufe 4. Aggregieren von Daten mit Kepler.gl
Durch die Verwendung einer Punktebene zur Anzeige von mehr als 9000 Parkplätzen konnten wir bereits einige interessante Beobachtungen machen. Auf der Karte können wir jedoch Fragen wie „Wo sind die meisten Parkplätze pro Flächeneinheit?“ Nicht einfach beantworten. Um dies zu beantworten, müssen wir eine der Aggregationsebenen verwenden.
Derzeit unterstützt Kepler.Gl vier Arten solcher Ebenen: Gitter (Gitter), hexagonales Gitter (Hexbin), Heatmap (Heatmap) und Cluster (Cluster). Die letzten beiden Typen (Cluster und Heatmap) sind praktisch, wenn Sie Daten nur mit einem Parameter aggregieren müssen. Das Gitter und das hexagonale Gitter ermöglichen die gleichzeitige Analyse aggregierter Werte anhand mehrerer Parameter.
Um die zuvor gestellte Frage zu beantworten, ändern wir den Typ der zuvor erstellten Punktebene in „Raster“ (Raster). Dadurch wird nicht nur die Gesamtzahl der Parkplätze pro Flächeneinheit ausgewertet, sondern auch Informationen über die durchschnittlichen Kosten einer Stunde Parken an diesem Ort gespeichert.
Stellen Sie die Rastergröße auf 1 km2 ein (das Minimum, das in Kepler.gl verfügbar ist). Der Wert des Coverage-Parameters wird von 1 auf 0,7 reduziert, sodass zwischen den Zellen ein kleiner Abstand erscheint, der die Lesbarkeit der endgültigen Karte verbessert.
Hinweis Die Liste der zur Anpassung verfügbaren Optionen hängt vom ausgewählten Ebenentyp ab. Weitere Details zu den von jedem von ihnen unterstützten Attributen finden Sie in der offiziellen Dokumentation von Kepler.gl.
Die Farbe jeder Zelle in der neuen Visualisierung hängt nach wie vor von den Kosten für eine Stunde Parken ab. Zusätzlich zum Namen des Felds im verwendeten Datensatz müssen wir jetzt jedoch auch angeben, wie Kepler.gl diese Informationen aggregiert. Aggregationsmethoden hängen von der Art des ausgewählten Feldes ab. In unserem Fall ist "Preis" ein numerischer Typ (int) und die Anwendung bietet eine von 5 Optionen:
- höchster Wert (Minimum)
- kleinster Wert (Maximum)
- Betrag (Summe)
- Durchschnittswert (Durchschnitt)
- Median
Die Höhe jeder Spalte des Rasters spiegelt die Gesamtzahl der Parkplätze in diesem Bereich wider. Wechseln Sie dazu in den 3D-Modus zum Anzeigen der Karte. Wählen Sie dann auf der Registerkarte "Ebenen" des Seitenbereichs "Höhe aktivieren" für unsere Aggregationsebene aus und wählen Sie das Feld "CarCapacity" als Basisparameter aus.
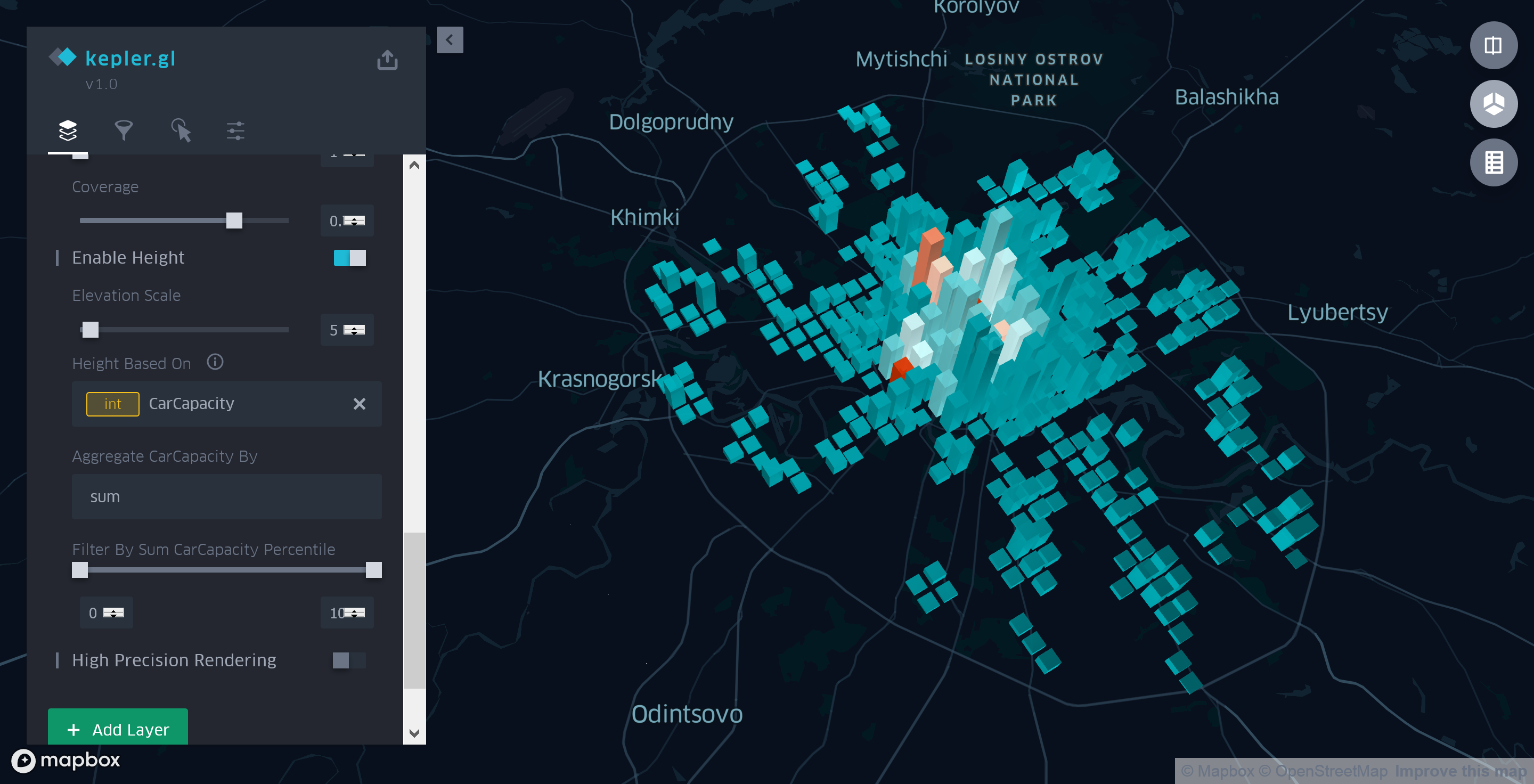
Abbildung 6. Allgemeine Informationen zu Kosten und Kapazität des Parkens
Nachdem wir einige Minuten mit dem Einrichten der Aggregationsschicht verbracht haben, können wir mit Sicherheit sagen, dass innerhalb des Gartenrings nicht nur die Anzahl der Parkplätze, sondern auch die tatsächliche Anzahl der Parkplätze viel größer ist als außerhalb.
Fazit
In diesem Artikel wurde anhand eines bestimmten Beispiels nur ein Teil der Funktionen von Kepler.gl als modernes Tool zur Visualisierung und grundlegenden Analyse verschiedener Geodaten betrachtet. Wenn Sie an dieser Anwendung interessiert sind, empfehlen wir Ihnen, sich auch mit den folgenden Artikeln und Tutorials vertraut zu machen, selbst mit der Datenfilterung zu experimentieren, QuickInfos und Kartenstile zu konfigurieren und andere Funktionen dieser Anwendung zu nutzen.
Im nächsten Artikel werde ich Ihnen erläutern, wie Sie die von Ihnen erstellten Visualisierungen und Karten freigeben und Kepler.gl als React-Komponente für Ihre Webanwendung verwenden können.
Nützliche Links