Das heutige Thema - die Zuverlässigkeit von World of Tanks Server - ist eher rutschig. Die Zuverlässigkeit des Spiels ist ein Kompromiss, daher muss bei der Spieleentwicklung alles schnell und schnell erledigt werden. Die Last auf den Servern ist groß, und Benutzer neigen dazu, etwas aus Interesse zu brechen. Levon Avakyan von RIT ++ sagte, was Wargaming tut, um Zuverlässigkeit zu gewährleisten.
Wenn es um Zuverlässigkeit geht, werden normalerweise ständig Überwachung, Stresstests usw. erwähnt. Darin liegt nichts Übernatürliches, und der Bericht war Panzerspezifischen Momenten gewidmet.

Über den Sprecher: Levon Avakyan arbeitet für Wargaming als Leiter von WoT Game Services und Reliability und befasst sich mit den Problemen der Zuverlässigkeit von Panzerservern.
Heute werde ich darüber sprechen, wie wir dies tun, einschließlich dessen, worum es beim World Of Tanks-Server geht, woraus er besteht, worauf er aufgebaut ist, damit Sie das Thema der Konversation verstehen. Weiter werden wir überlegen, was im Server selbst und um ihn herum schief gehen kann, da das Spiel bereits mehr als der Server ist. Und wir werden auch ein wenig über die Prozesse sprechen, da viele vergessen, dass ein gut etablierter Prozess in der Produktion nicht nur zum Erfolg von Ressourcen beiträgt (viele Praktiken stammen aus der realen Produktion), sondern auch die Qualität und Zuverlässigkeit der Lösung beeinträchtigt.

Wenn es um Zuverlässigkeit geht, werden normalerweise ständig Überwachung, Stresstests usw. erwähnt. Ich habe es hier nicht aufgenommen, weil ich es langweilig finde. Wir haben darin nichts Übernatürliches entdeckt. Ja, wir haben auch ein Überwachungssystem. Wir führen Stresstests mit Stresstests durch, um die Zuverlässigkeit des Systems zu erhöhen und zu wissen, wo es abfallen kann. Aber heute werde ich darüber sprechen, was spezifischer für Panzer ist.
BigWorld-Technologie
Dies ist eine Backend-Engine sowie ein Toolkit zum Erstellen von MMOs.
Diese ziemlich alte BigWorld Server-Engine (entstanden in den späten 90ern - frühen 2000ern) besteht aus einer Reihe verschiedener Prozesse, die das Spiel unterstützen. Prozesse werden in einem Cluster gestartet, der in einem Netzwerk von Maschinen miteinander verbunden ist. Die Prozesse, die miteinander interagieren, zeigen dem Benutzer eine Art Spielmechanik.
Die Engine heißt BigWorld, weil es sehr gut ist, Spiele darauf zu machen, in denen es ein großes Feld (Raum) gibt, auf dem militärische Operationen (Schlachten) stattfinden. Für Panzer passt das perfekt.
In Bezug auf die Zuverlässigkeit wurden die folgenden Hauptmerkmale in BigWorld investiert:
- Lastausgleich. Die Engine weist Ressourcen zu und versucht, zwei Ziele zu erreichen:
- benutze so wenig Maschinen wie möglich;
- Laden Sie gleichzeitig Ihre Anwendungen nicht so, dass ihre Auslastung einen bestimmten Grenzwert überschreitet.
- Skalierbarkeit. Wir haben das Auto zum Cluster hinzugefügt und Prozesse darauf gestartet - was bedeutet, dass Sie mehr Schlachten zählen und Spieler akzeptieren können.
- Hohe Verfügbarkeit. Wenn zum Beispiel ein Auto gefallen ist oder bei einem der Spielprozesse, die dem Spiel selbst dienen, ein Fehler aufgetreten ist, besteht kein Grund zur Sorge - das Spiel wird es nicht bemerken, wird an einem anderen Ort wiederhergestellt und funktioniert.
- Bewahren Sie die Datenintegrität und -konsistenz. Dies ist die zweite Stufe der Fehlertoleranz. Wenn es mehrere Cluster gibt, wie in Tanks, und eine Katastrophe im Rechenzentrum oder auf dem Hauptkanal aufgetreten ist, bedeutet dies nicht, dass wir die Spieldaten, die die Person gespielt hat, vollständig verlieren. Wir werden uns erholen, die Konsistenz wird sein.
Die Prozesse in unserem System und ihre Funktionen- CellApp ist der Prozess, der für die Verarbeitung des Spielraums oder eines Teils davon verantwortlich ist.
Wie gesagt, BigWorld arbeitet mit bestimmten Räumen, die wir in Zellen teilen. Jede bestimmte Zelle unseres Spielraums wird von einer bestimmten Anwendung berechnet.
- CellAppMgr - der Prozess, der die Arbeit von CellApp koordiniert, Lastenausgleich.
CellApp kann viele sein, dementsprechend muss es einen Prozess geben, der sie steuert.
- BaseApp verwaltet Entitäten und isoliert Clients von der Arbeit mit CellApp.
Eines der grundlegenden Dinge in BigWorld ist das Konzept der Entität - zum Beispiel das Konto eines Spielers. Alles, was wir auf dem Schlachtfeld tun, tun wir mit dieser Entität. CellApps berechnen Physik und Spielmechanik, z. B. Schießen. BaseApp arbeitet mit Entitäten. Es dient dem Konto, Tank usw.
- ServiceApp ist eine spezialisierte BaseApp, die eine Art Service implementiert.
Dies ist eine vereinfachte Version von BaseApp, einem Prozess, der verschiedene Servicearbeiten ausführt. Zum Beispiel sollte jemand in der Lage sein, aus RabbitMQ zu lesen. Hier geht es nicht um Spielentitäten, sondern auch um benötigt.
- BaseAppMgr verwaltet BaseApp und ServiceApp, da es auch viele davon gibt.
- LoginApp erstellt neue Verbindungen von Clients und Proxys für Benutzer auf BaseApp.
- DBApp implementiert eine Speicherzugriffsschnittstelle (Datenbanken). Wir arbeiten mit Percona, aber es kann sich um eine andere Datenbank handeln.
- DBAppMgr koordiniert die Arbeit von DBApp.
- InterClusterMgr verwaltet die Intercluster-Kommunikation.
- Reviewer ist ein Prozessinspektor, der Prozesse neu starten kann.
- Bwmachined - Ein Daemon, der auf jedem Computer im Cluster ausgeführt wird, um seine Arbeit zu koordinieren. Es ermöglicht allen BaseApp-Managern, miteinander zu kommunizieren.
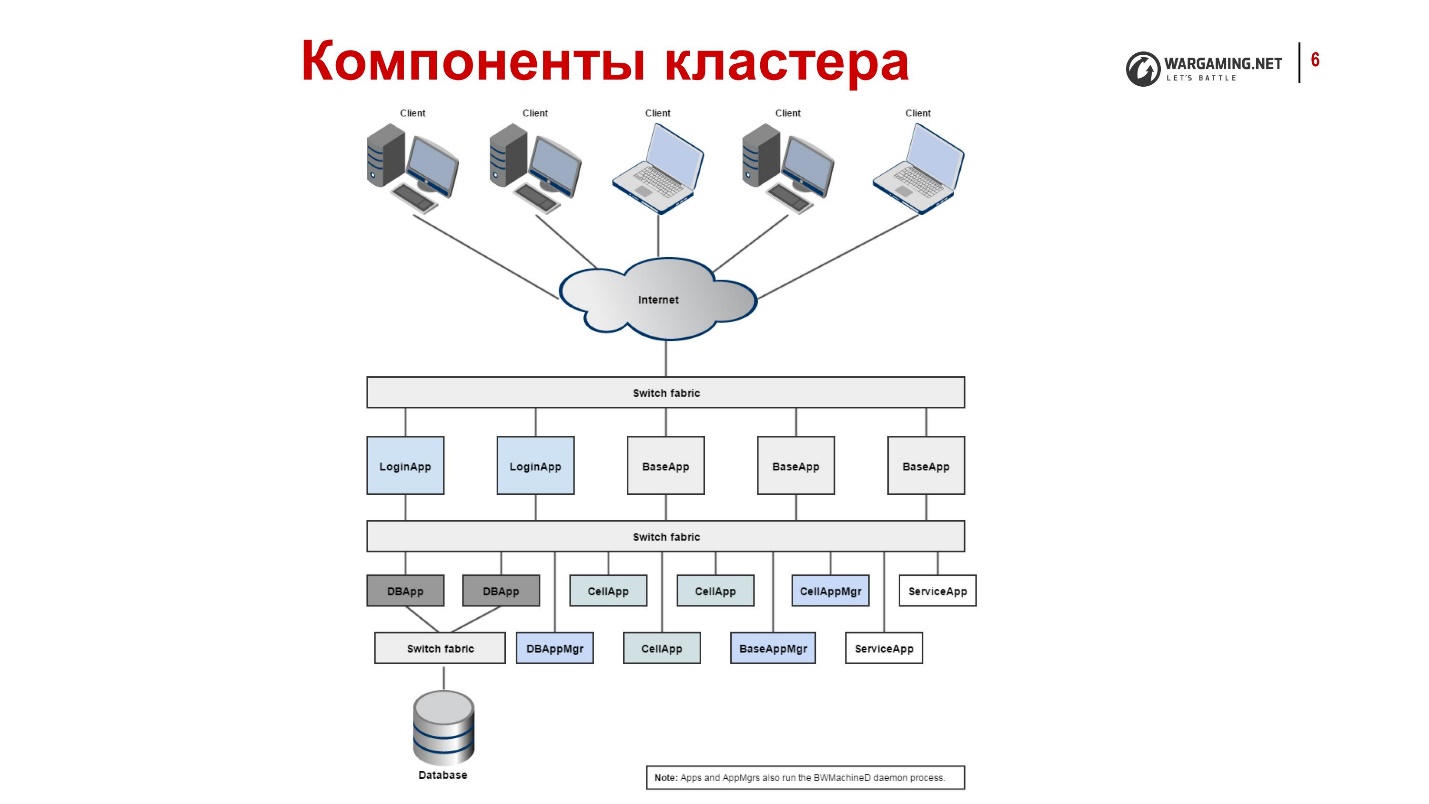
So sehen Panzer von innen aus, wenn auch nur ganz kurz:
- Kunden verbinden sich über das Internet und melden sich bei LoginApp an.
- LoginApp autorisiert sie mit DBApp und gibt eine Adresse von BaseApp aus.
- Weitere Kunden spielen auf ihnen.
All dies ist auf viele Maschinen verteilt, von denen jede über eine BWMachineD verfügt, die all dies verwalten, orchestrieren usw. kann.
Ökosystem der Panzerwelt
Was ist da? Es scheint, dass es einen Spieleserver gibt und die Spieler - einen Panzer gewählt, zum Spielen gegangen sind. Aber leider (oder freudig) entwickelt sich das Spiel weiter und die Spielmechanik des „einfachen Schießens“ reicht nicht mehr aus. Dementsprechend wurde der Spieleserver mit verschiedenen Diensten überwachsen, von denen einige im Allgemeinen im Server nicht möglich waren, während wir andere speziell herausnahmen, um die Geschwindigkeit der Bereitstellung von Inhalten für den Spieler zu erhöhen. Das heißt, es ist schneller, einen kleinen Dienst in Python zu schreiben, der eine Art Spielmechanik ausführt, als dies innerhalb des Servers auf allen BaseAPPs, Support-Clustern usw. der Fall ist.
Einige Dinge, zum Beispiel Zahlungssysteme, wurden ursprünglich ausgegeben. Wir ertragen andere, weil Wargaming schließlich mehr als ein Spiel entwickelt. Dies ist eine Trilogie: Panzer, Flugzeuge, Schiffe, und es gibt Blitz und Pläne für neue Spiele. Wenn sie sich in BigWorld befinden, können sie nicht bequem in anderen Produkten verwendet werden.
Alles ging ziemlich schnell und chaotisch, was zu einigen Zootechnologien führte, die in unserem Tank-Ökosystem verwendet werden.
Schlüsseltechnologien und Protokolle:
1. Python 2.7, 3.5;
2. Erlang;
3. Scala;
4. JavaScript;
Frameworks
5. Django;
6. Falke;
7. asyncio;
Lagerung:
8. Postgres;
9. Percona.
10. Memcached und Redis zum Zwischenspeichern.
Alles in allem ist dies für den Spieler der Panzerserver:
- Einzelautorisierungspunkt;
- Chat
- Clans;
- Zahlungssystem;
- Turniersystem;
- Metaspiele (globale Karte, befestigte Gebiete);
- Panzerportal, Clanportal;
- Content Management etc.
Aber wenn Sie schauen, sind dies etwas andere Dinge, die auf verschiedenen Technologien geschrieben sind. Dies verursacht einige Zuverlässigkeitsprobleme.
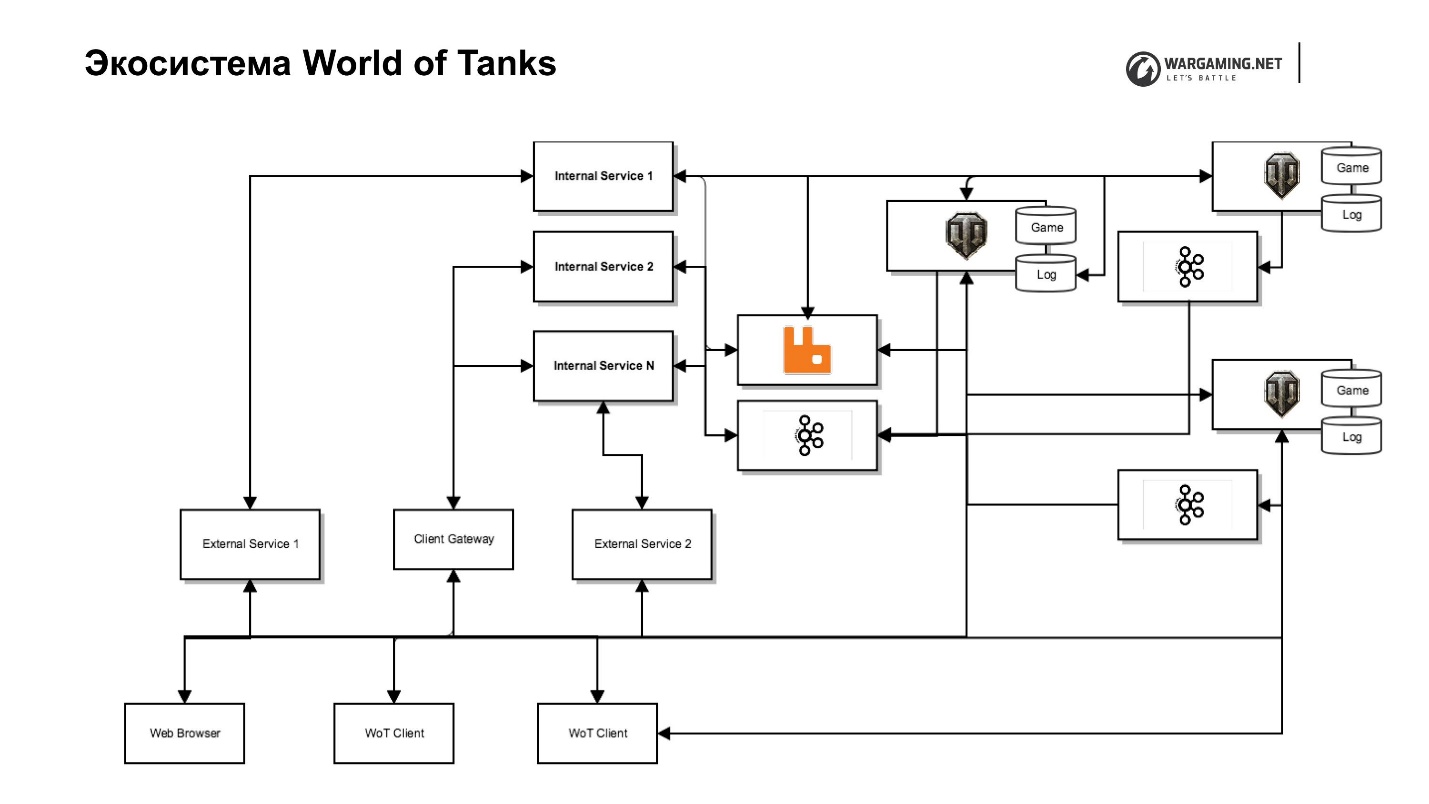
Das Diagramm zeigt unseren Panzerserver zusammen mit seinem Ökosystem. Es gibt einen Spieleserver, Webdienste (intern und extern), einschließlich ganz spezieller Dienste, die sich im Backend-Netzwerk befinden und Dienstfunktionen ausführen, sowie Dienste für diese, die die Schnittstellen tatsächlich implementieren. Zum Beispiel gibt es einen Clan-Dienst mit einem eigenen Clan-Portal, mit dem Sie diesen Clan verwalten können, es gibt ein Portal des Spiels selbst usw.
Durch diese Trennung müssen wir uns weniger um die Sicherheit kümmern, da niemand Zugriff auf das interne Netzwerk hat - weniger Probleme. Dies führt jedoch zu zusätzlichen Anstrengungen, da wir Proxys benötigen, die Zugriff gewähren, wenn wir sie nach draußen schieben müssen.
Ich habe bereits gesagt, dass wir die Entscheidung getroffen haben, einige der Spielelogiken und andere Dinge vom Server zu entfernen. Es gab eine Aufgabe, irgendwie alles in den Client aufzunehmen. Wir haben ein wunderbares Client-Gateway, mit dem ein Tank-Client über einige der APIs dieser internen Dienste direkt auf einen Server zugreifen kann - dieselben Clans oder APIs unserer Metaspiele.
Außerdem haben wir das Chromium Embedded Framework (CEF) in den Tank-Client integriert. Wir haben jetzt den gleichen Browser. Der Spieler unterscheidet ihn nicht vom Spielfenster. Auf diese Weise können Sie mit der gesamten Infrastruktur arbeiten und die Arbeit mit dem Spieleserver umgehen.
Wir haben viele Cluster - so ist es passiert - ich sage Ihnen warum. So sieht die GUS-Region aus.
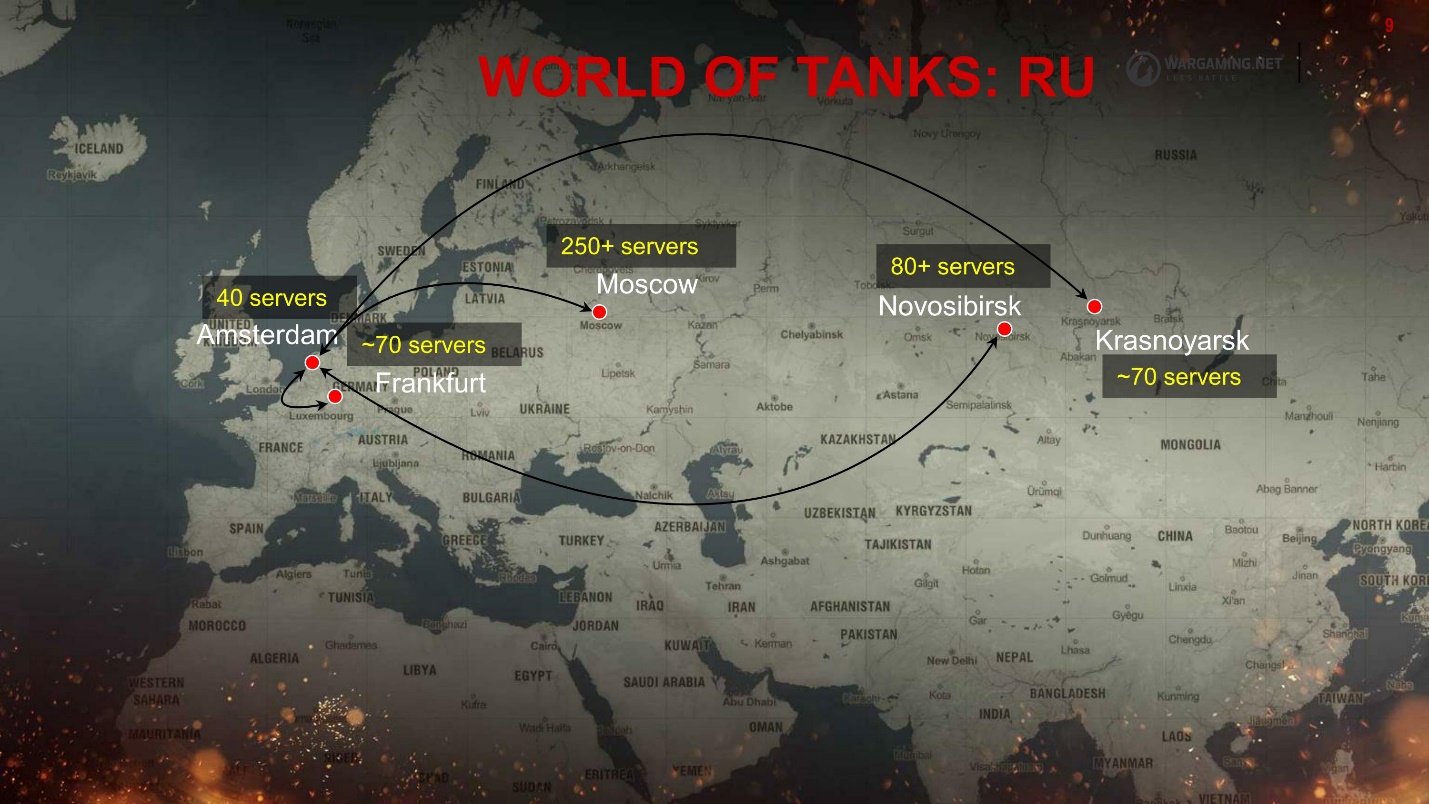
Alles ist in den Rechenzentren verteilt. Je nachdem, wo der Ping besser ist, stellen die Spieler eine Verbindung zum Standort her. Das gesamte Ökosystem lässt sich jedoch nicht so skalieren, sondern hauptsächlich in Europa und Moskau. Dies führt auch zu Problemen mit der Zuverlässigkeit - zusätzliche Latenz und Weiterleitung.
So sieht das World of Tanks-Ökosystem aus.
Was kann mit all dieser Wirtschaft schief gehen? Alles was du willst! Und geht J. Aber nehmen wir es auseinander.
Wichtige Fehlerquellen innerhalb eines Clusters
Ausfall einer einzelnen Maschine oder eines einzelnen Prozesses
Die einfachste Option, die wir vorhersagen können, ist der Ausfall einer Maschine oder eines Prozesses innerhalb eines Clusters. Wir haben Cluster von 10 bis 100 Autos - etwas kann herausfliegen. Wie gesagt, BigWorld selbst bietet sofort einsatzbereite Mechanismen, mit denen wir zuverlässiger arbeiten können.
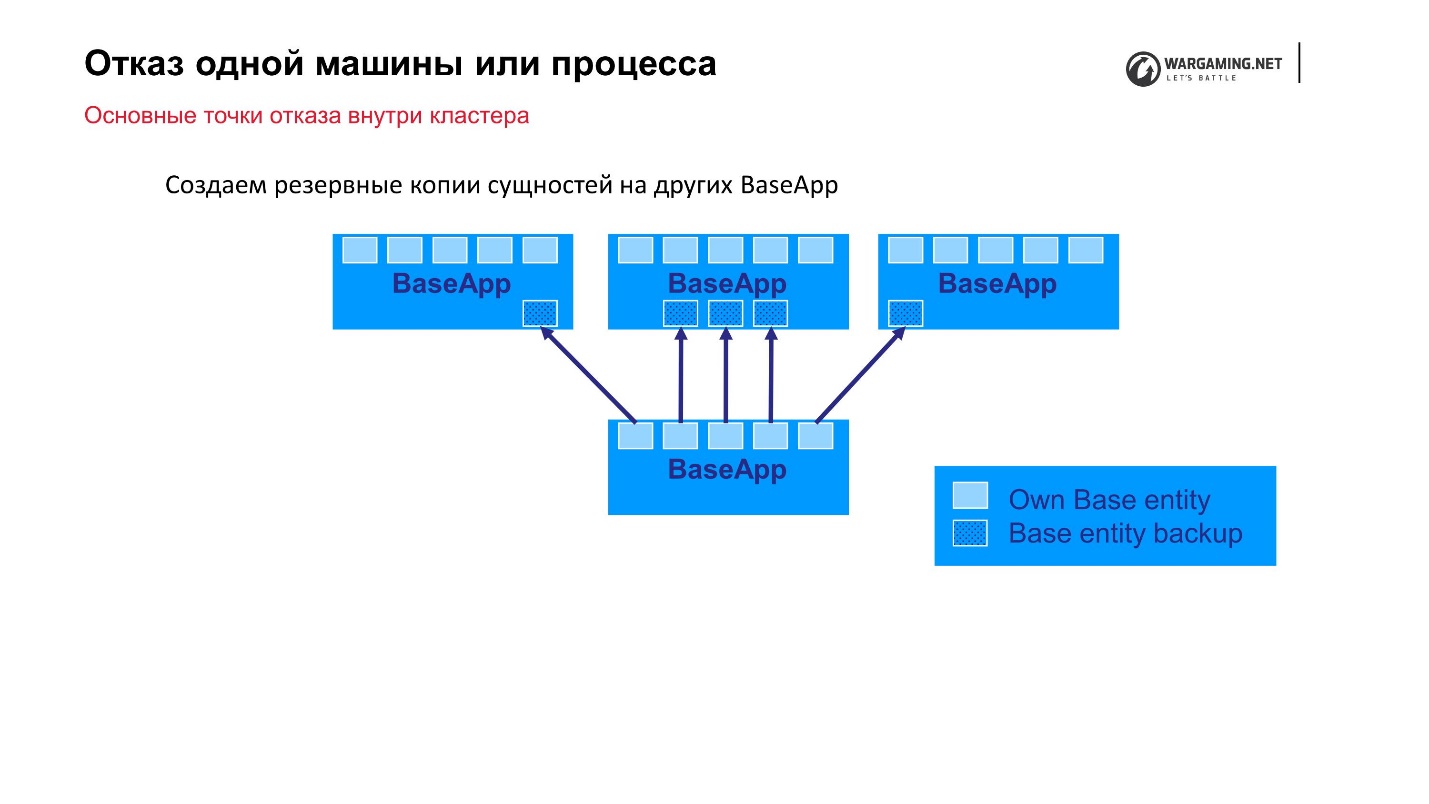
Standardschema: Es gibt BaseApps, die auf verschiedene Computer verteilt sind. Auf dieser BaseApp gibt es Entitäten, die Statusentitäten enthalten. Jede BaseApp sichert sich mit Round Robin auf anderen.
Angenommen, wir hatten eine Datei und einige BaseApp sind gestorben, oder die gesamte Maschine ist gestorben - es ist okay! Die verbleibenden BaseApps haben diese Entitäten verlassen, sie werden wiederhergestellt und das Gameplay für den Spieler wird nicht leiden.
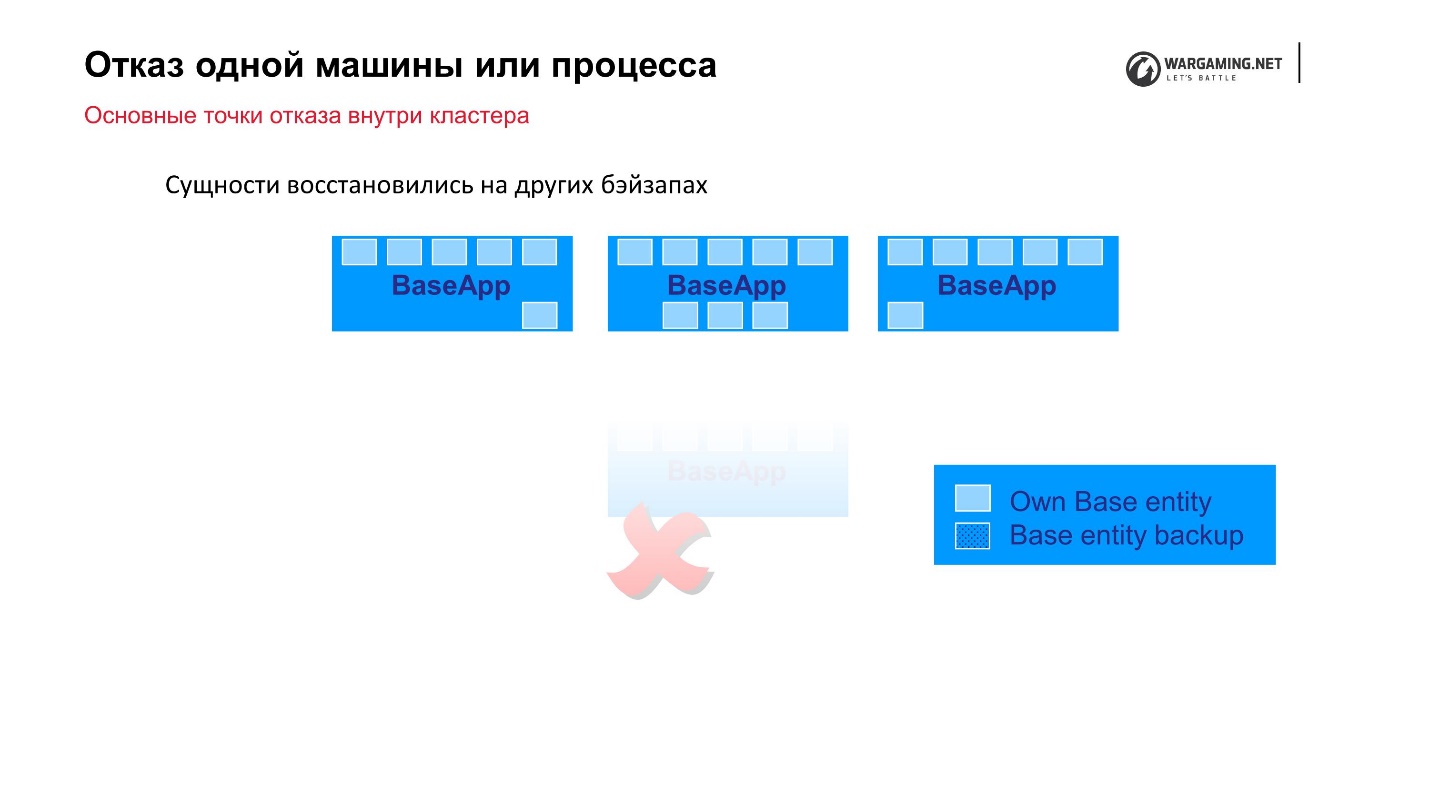
CellAPPs machen genau das Gleiche. Das einzige ist, dass sie ihre Zustände auch auf BaseApps und nicht auf anderen CellAPPs speichern.
Es scheint ein zuverlässiger Mechanismus zu sein, aber ...
Sie müssen für alles bezahlen
Im Laufe der Zeit begannen wir Folgendes zu beobachten.
• Das Erstellen von Sicherungskopien von Entitäten beansprucht immer mehr Systemressourcen und Netzwerkverkehr.
Tatsächlich beginnt der Sicherungsprozess selbst, die Stabilität des Systems zu beeinträchtigen, wenn innerhalb des Clusters der größte Teil des Netzwerks damit beschäftigt ist, Kopien an Round Robins zu übertragen.
• Die Größe von Entitäten nimmt mit der Zeit zu, wenn neue Attribute und Spielmechaniken hinzugefügt werden.
Das Unangenehmste ist jedoch, dass die Größe dieser Einheiten wie eine Lawine wächst. Zum Beispiel führt ein Spieler eine Aktion aus (kauft Spieleigenschaft), und dieser Vorgang wurde langsamer. Wir haben es noch nicht abgeschlossen, aber Änderungen an diesen Attributen gespeichert. Das heißt, das System ist so schlecht, und wir beginnen immer noch, die Größe der Sicherung zu erhöhen, die durchgeführt werden muss. Es gibt einen Schneeballeffekt.
• Die Systemstabilität nimmt insgesamt ab
Aufgrund der Tatsache, dass wir versuchen, dem Sturz einer Maschine oder eines Prozesses zu entkommen, verringern wir die Stabilität des gesamten Systems.
Was haben wir getan, um damit umzugehen ? Wir haben für jedes Unternehmen entschieden, hervorzuheben, was wirklich gesichert werden muss. Wir haben die Attribute in veränderbare und unveränderliche Attribute unterteilt und kopieren nicht die gesamte Entität, sondern sichern nur die veränderlichen Attribute. Auf diese Weise haben wir einfach die Menge an Informationen reduziert, die wirklich benötigt werden, um Eisen zu halten. Wenn Sie nun ein neues Attribut hinzufügen, sollte derjenige, der dies tut, klarer sehen, wo er es zuordnen soll. Aber im Allgemeinen hat uns dies die Situation gerettet.
Um ganz ehrlich zu sein, wurde dieser Mechanismus in BigWorld festgelegt, aber in Tanks wurde er irgendwann bis zum Ende nicht mehr unterstützt, und nicht jede Entität kann sich von ihrer Sicherung erholen. In Ships zum Beispiel unterstützen Jungs dies. Dort können Sie die Maschinen sicher ausschalten - die Informationen werden einfach auf anderen Maschinen wiederhergestellt, und der Client bemerkt nichts. Leider ist dies in Tanks nicht immer der Fall, aber wir werden die Rückgabe all dieser Funktionen erreichen, damit es so funktioniert, wie es sollte.
Ausfall des Rechenzentrums. Multi-Cluster
Wenn plötzlich nicht 1-2 Autos fielen und wir anfingen, das gesamte Rechenzentrum, dh den Cluster, vollständig zu verlieren, welche Eigenschaften sollte das System haben, damit das Spiel in einer solchen Situation nicht fällt?
- Jeder Cluster muss unabhängig sein, dh:
- muss eine eigene Datenbank haben;
- Der Cluster verarbeitet nur seine Räume (Kampfarenen).
Wenn also einige Arenen getroffen werden, funktionieren andere immer noch. - Cluster müssen miteinander kommunizieren, damit man zum zweiten sagen kann: „Ich bin gefallen!“ Wenn es steigt, werden die Daten aus den gespeicherten Kopien wiederhergestellt.
- Es ist auch wünschenswert, dass Sie den Benutzer von Cluster zu Cluster übertragen können.
Im Moment sieht das Schema unseres Multi-Clusters so aus.
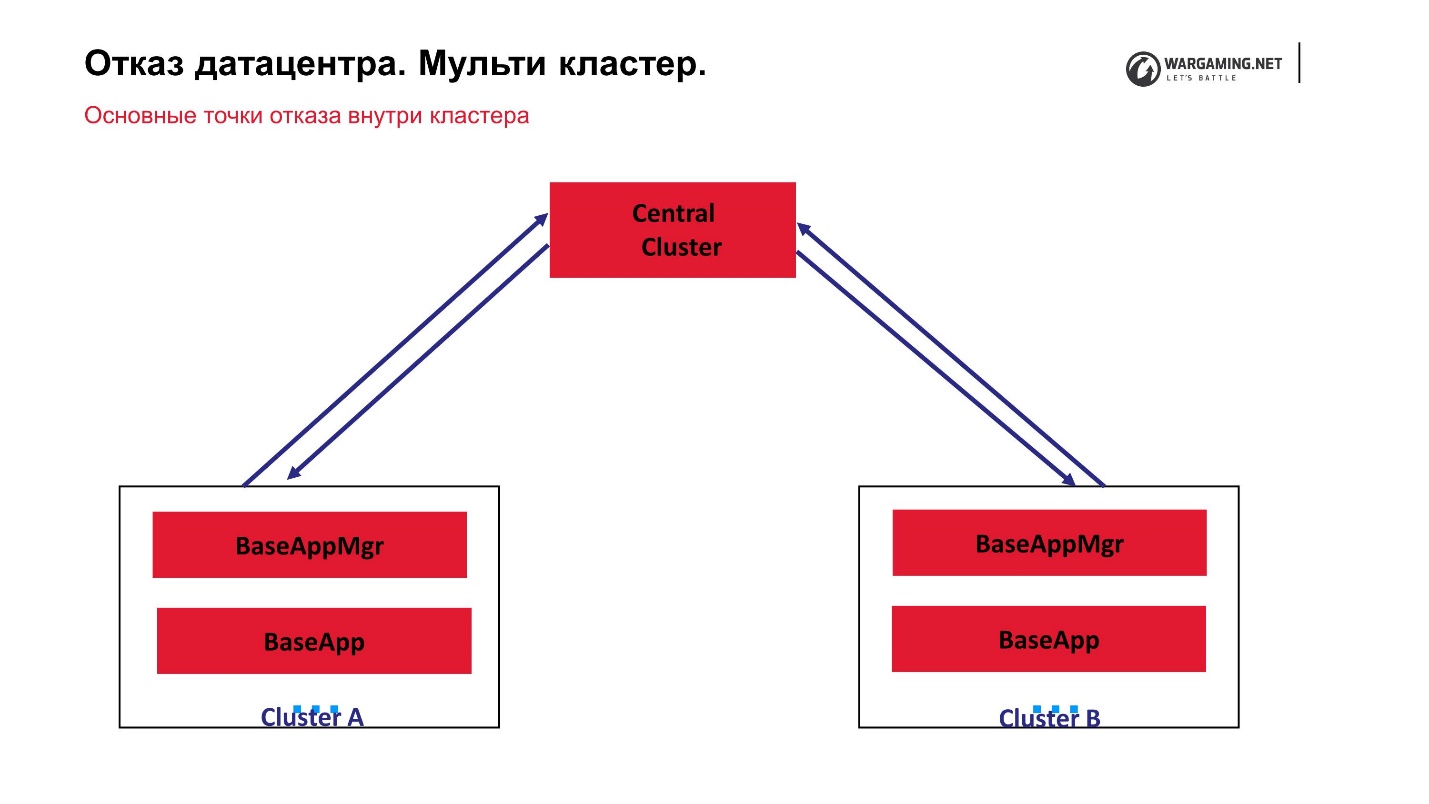
Wir haben einen zentralen Cluster und sogenannte Peripheriegeräte, auf denen die eigentlichen Schlachten ausgetragen werden. CellApp wird nicht auf dem zentralen Cluster ausgeführt, ansonsten ist es genau das gleiche wie alle anderen. Es ist der zentrale Punkt der Kontoverarbeitung: Sie steigen dort auf, werden an die Peripherie gesendet, und an der Peripherie spielt bereits eine Person. Das heißt, der Ausfall eines der Cluster führt nicht zu einem Verlust der Funktionsfähigkeit des gesamten Spiels. Selbst der Ausfall des zentralen Clusters ermöglicht es neuen Spielern nicht, sich anzumelden, aber diejenigen, die bereits an der Peripherie spielen, können das Spiel fortsetzen.
Die Tatsache, dass alles über den zentralen Cluster für uns funktioniert, hat sich herausgestellt, da die BigWorld-Technologie im Allgemeinen selbst davon ausgeht, dass es einen speziellen Interclaster-Manager für den Verwaltungsprozess gibt. In der Tat können solche Inter-Claster-Manager etwas angehoben werden.
In der Vergangenheit brauchten Panzer einen Multi-Cluster, da die Online-Lawine zunahm. Als wir den Höhepunkt von 200.000 Spielern erreichten, wurde der eingehende Datenverkehr von ihnen einfach nicht mehr über das Netzwerk im Rechenzentrum platziert. Wir mussten buchstäblich eine Lösung finden, damit die Spieler in mehrere Rechenzentren eingeführt werden konnten.
Tatsächlich haben wir nur gewonnen, weil wir jetzt einen Multi-Cluster haben. Es ist auch für Spieler nützlich geworden, da Ping, dh die Erreichbarkeit über das Netzwerk, das Gameplay stark beeinflusst. Wenn die Verzögerung mehr als 50-70 ms beträgt, wirkt sich dies bereits auf die Qualität des Spiels selbst aus, da in Tanks absolut alles auf dem Server berechnet wird. Es gibt keine Berechnungen auf dem Client. Denken Sie daher daran, dass praktisch nichts zu tun ist. Natürlich werden dort einige Mods gemacht, aber sie beeinflussen den Prozess selbst nicht. Sie können versuchen zu erraten, was passieren wird, aber die Spielmechanik selbst beeinflussen - nein.
Aufgrund dieses Ansatzes ist unser
zentraler Cluster zu einem Fehlerpunkt geworden . Alles war für ihn geschlossen. Wir haben uns entschieden - da diese Maschinen und eine große Wildlagerbasis dort stehen, lassen Sie unsere Peripheriegeräte sich ausschließlich mit Kämpfen befassen. Dann müssen wirklich keine großen Mengen an Informationen gespeichert werden - es werden Schlachten gespielt und gespielt - lassen Sie uns dort alles sperren.
Um absolut alles neu zu schreiben, um dem Konzept eines zentralen Clusters zu entkommen, gibt es jetzt keine Zeit, keinen besonderen Wunsch. Aber wir haben uns zunächst entschieden, periphere Cluster zu lehren, miteinander zu kommunizieren. Dann haben wir ein Loch in sie gesägt, damit sie über Dienste von Drittanbietern beeinflusst werden können.
Um beispielsweise eine Schlacht früher zu erstellen, musste dem zentralen Cluster mitgeteilt werden, dass eine Schlacht an einem Teil der Peripherie erstellt werden muss. Durch interne Mechanismen bewegten sich die Entitäten, die Essenz der Arena wurde geschaffen usw.
Jetzt ist es möglich, die Peripherie direkt zu umgehen und den zentralen Cluster zu umgehen. Also entfernen wir die zusätzliche Arbeit von ihm. Bisher besteht jedoch kein Wunsch, vollständig auf ein Schema umzusteigen, bei dem alle Cluster fast Peer-to-Peer sind und dies alles von einigen Prozessen gesteuert wird, nicht jedoch vom Cluster.
Ich erinnere Sie daran, dass wir zusätzlich zum Spielcluster mit seinen BaseApps, CellApps und anderen ein Ökosystem haben.
Wir versuchen sicherzustellen, dass die Leistung des Ökosystems das Gameplay nicht beeinflusst. Im schlimmsten Fall funktioniert das Turniersystem beispielsweise nicht, aber Sie können zufällig spielen - die meisten Leute spielen ohnehin zufällig. Ja, wir haben die Qualität verringert, aber im Allgemeinen können Sie mehrere Stunden ohne Turniere überleben.
Das passiert nicht immer. Erstens gibt es bereits solche Webdienste, die tief in das Spiel eingebettet sind. Ein einzelner Autorisierungspunkt ist beispielsweise ein Dienst, mit dem Sie sich im Web oder an einem Ort anmelden und tatsächlich im gesamten Wargaming-Universum angemeldet sein können.
Das zweite Beispiel ist ein Dienst, der Spielekäufe und -transaktionen bedient. Es musste auch nur ins Spiel gebracht werden, weil wir eine Spur der Einkäufe des Spielers brauchten. Tatsache ist, dass wir in einigen Regionen verpflichtet sind, dem Kunden Informationen darüber anzuzeigen, welche Spieleigenschaft für echtes Geld gekauft wurde und welche für Spielgeld. Das System hat dies anfangs nicht angenommen, niemand hat es vor 5 Jahren ausgelegt, aber das
Gesetz ist hart: Sie müssen es tun - tun Sie es .
Fehlerstellen des World of Tanks-Ökosystems
Problem Nummer 1. Erhöhte Last
Wir haben einen Multi-Cluster, in dem 10 Cluster mit einer großen Anzahl von Maschinen. Die Spieler spielen sie und das Web ist klein. In jedem Rechenzentrum kauft niemand mehr fünf Maschinen. Gleichzeitig bieten wir die gleiche Funktionalität und alles, was benötigt wird, direkt im Client. Dies ist das Hauptproblem.
Interaktivität und Reaktivität der Schnittstelle sind die Hauptursache für eine erhöhte Belastung des Ökosystems.
Ich werde zwei Beispiele aus dem Clandienst nennen:
- Sie möchten einen anderen Spieler in den Clan einladen. Natürlich möchte ich, dass der Eingeladene sofort eine Benachrichtigung erhält und er sich Ihnen anschließen kann. Um dies zu implementieren, muss der Clan-Dienst den Client irgendwie benachrichtigen oder den Client von Zeit zu Zeit den Webdienst fragen lassen: „Hat sich etwas geändert? Habe ich neue Einladungen? " Dies ist die erste Option, von der die zusätzliche Last kommen kann.
- Panzer haben ein befestigtes Regime. Angenommen, es wird nicht von einer Person gespielt, sondern von mehreren. Alle Spieler haben ein offenes Fenster mit befestigten Bereichen. Der Kommandant baute das Gebäude. Es ist ratsam, dass für alle, die dieses Fenster geöffnet haben, das Gebäude sofort angezeigt wird.
Die Entscheidung in der Stirn mit der Umfrage ist nicht sehr gut. Tatsächlich funktioniert es, es ist nur so, dass Sie so viele Kapazitäten dafür zuweisen müssen, dass diese Funktion keinen Gewinn für das Unternehmen bringt. Und wenn die Funktion keinen Gewinn bringt, müssen Sie dies nicht tun.
Mein persönlicher Rat, wie man damit umgeht: Der beste Weg, um das System unter Last zuverlässiger zu machen, besteht darin, die Last im Allgemeinen irgendwie logisch zu reduzieren.
Sie sollten sich nicht mit Eisen niederlassen, sich neue Systeme einfallen lassen, etwas optimieren - je größer die Last, desto mehr Artefakte erscheinen, von denen Sie nicht loskommen können. Darüber hinaus treten Artefakte auch auf immer niedrigeren Abstraktionsebenen auf - zuerst mit Anwendungen, dann mit verschiedenen Webdiensten, dann gelangen Sie zum Netzwerk (Cisco usw.). Auf einer bestimmten Ebene können Sie die Probleme einfach nicht lösen.
Wenn Sie sorgfältig überlegen, können sie einfach vermieden werden.
Als erstes haben wir
gelernt, wie man Clients über einen Spieleserver mithilfe seiner Infrastruktur
benachrichtigt . Wenn beispielsweise eine Einladung zum Clan eingeht, teilen wir dem Server mit: "Wir haben solche und solche Personen eingeladen", und dann findet der Cluster-Cluster selbst die Person, an die die Benachrichtigung gesendet werden soll, insbesondere da sie eine Verbindung haben. Das heißt, wir drängen vom Service und nicht jemand schüttet uns ständig aus. , , . , , .
—
Web-sockets (nginx-pushstream) . , Web-sockets. , Chromium Embedded Framework — , , Web-sockets Nginx. pushstream, Web-sockets .
№ 2.
, , ,
— . , , — .
, , .
? : - , - , , . - , , . .
.

,
120 Game Play . . , , . , . .
3 , :
- HTTP API;
- RabbitMQ — ;
- Apache Kafka .
, , , , , . , - — , . , .
1. HTTP— HTTP. , , -, . :
, , . , , , Django, 100 200 , API, . , , - 30-40 , , . , — .
, , HTTP, — . . — — . ,
, , , .
. . - , - API — API, .
— , . , , . , 10 , - 100 500. , HTTP . nginx' , — .
, HTTP , .
2. RabbitMQRabbitMQ BigWord .
— - , , , .
: . , API: « N — ». , , , , — . , .
«», «», — .
RabbitMQ , , , , , , , .
— RabbitMQ .
3. Kafka, , — Kafka. , RabbitMQ - .
, , , . , , . . Kafka. , — , .
, . , , - — .
Kafka , , , - , . .
— .

:
- . , - , ..
- — , , , .
- — , . , , .
. , , , entity. . , , .
DLC
, DLC (Development Lifecycle) — , , .
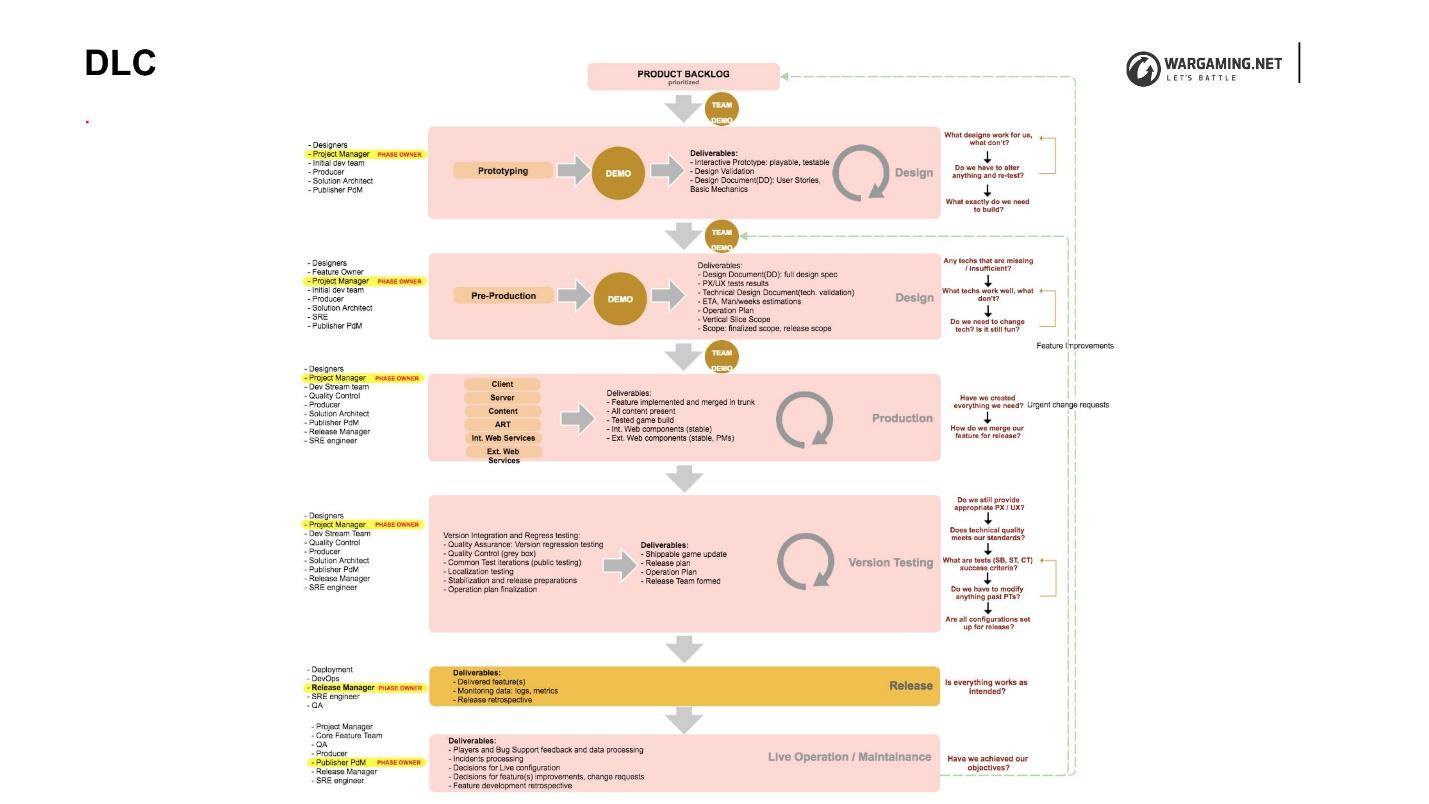
, , . DLC , , . , . , , , .
DLC, . , , , .
DLC, , :
•
( )., , «- , », . , , , , .
• : SRE.
, solution-, technical-owner, reability- — , - , game- . , , , . - , , , , . , .
•
SRE .— - . , . , SRE -. SRE , : « , , , — !» , .
QA , , - , , — .
BigWorld Technology «» . , . . « », .
« » , , . — «» (, ) — . , . , - .
: ++. , 40 , . , .RootConf — DevOpsConf Russia . DevOps 1 2 , . , . , — !