 Für mich begann es vor sechseinhalb Jahren, als ich durch den Willen des Schicksals in ein geschlossenes Projekt hineingezogen wurde. Wessen Projekt - nicht fragen, werde ich nicht sagen. Ich kann nur sagen, dass seine Idee als Rechen einfach war: Einbetten des klirrenden Frontends in die IDE. Nun, wie kürzlich in QtCreator, in CLion (in gewissem Sinne) usw. getan. Clang war damals ein aufgehender Stern, viele trotteten über die Möglichkeit nach, den vollwertigen C ++ - Parser fast kostenlos zu nutzen. Und die Idee, sozusagen, schwebte buchstäblich in der Luft (und die automatische Vervollständigung des Codes, der in die Clang-API eingebaut war, wie es angedeutet wurde), musste man einfach nehmen und tun. Aber wie Boromir sagte: "Du kannst es nicht einfach nehmen und ...". So geschah es in diesem Fall. Für Details - Willkommen unter Katze.
Für mich begann es vor sechseinhalb Jahren, als ich durch den Willen des Schicksals in ein geschlossenes Projekt hineingezogen wurde. Wessen Projekt - nicht fragen, werde ich nicht sagen. Ich kann nur sagen, dass seine Idee als Rechen einfach war: Einbetten des klirrenden Frontends in die IDE. Nun, wie kürzlich in QtCreator, in CLion (in gewissem Sinne) usw. getan. Clang war damals ein aufgehender Stern, viele trotteten über die Möglichkeit nach, den vollwertigen C ++ - Parser fast kostenlos zu nutzen. Und die Idee, sozusagen, schwebte buchstäblich in der Luft (und die automatische Vervollständigung des Codes, der in die Clang-API eingebaut war, wie es angedeutet wurde), musste man einfach nehmen und tun. Aber wie Boromir sagte: "Du kannst es nicht einfach nehmen und ...". So geschah es in diesem Fall. Für Details - Willkommen unter Katze.
Zuerst über gut
Die Verwendung von clang als integrierter Parser in IDE C ++ bietet natürlich folgende Vorteile. Letztendlich beschränken sich die IDE-Funktionen nicht nur auf das Bearbeiten von Dateien. Dies ist eine Datenbank mit Zeichen, Navigationsaufgaben, Abhängigkeiten und vielem mehr. Und hier steuert ein vollwertiger Compiler seine volle Höhe, denn die gesamte Leistung des Präprozessors und der Vorlagen in einem relativ einfachen selbstgeschriebenen Parser zu überwältigen, ist keine triviale Aufgabe. Weil Sie normalerweise viele Kompromisse eingehen müssen, was sich offensichtlich auf die Qualität der Code-Analyse auswirkt. Wen kümmert es - sehen Sie sich beispielsweise den integrierten Parser des QtCeator an: Qt Creator C ++ - Parser
An derselben Stelle im Quellcode von QtCreator können Sie sehen, dass das Obige nicht alles ist, was die IDE vom Parser benötigt. Darüber hinaus benötigen Sie mindestens:
- Syntaxhervorhebung (lexikalisch und semantisch)
- alle möglichen Hinweise "on the fly" mit der Anzeige von Informationen auf dem Symbol
- Hinweise, was mit dem Code nicht stimmt und wie man ihn repariert / ergänzt
- Code-Vervollständigung in einer Vielzahl von Kontexten
- das vielfältigste Refactoring
Daher enden bei den zuvor aufgeführten Vorteilen (wirklich ernst!) Die Pluspunkte und der Schmerz beginnt. Um diesen Schmerz besser zu verstehen, können Sie zunächst den Bericht von Anastasia Kazakova ( anastasiak2512 ) über die tatsächlichen Anforderungen des in die IDE integrierten Code-Parsers betrachten:
Das Wesentliche des Problems
Aber es ist einfach, obwohl es auf den ersten Blick nicht offensichtlich ist. Kurz gesagt: clang ist ein Compiler . Und bezeichnet den Code als Compiler . Und geschärft durch die Tatsache, dass ihm der Code bereits ausgefüllt gegeben wird, und nicht durch den Stub der Datei, die jetzt im IDE-Editor geöffnet ist. Compiler mögen keine Dateibits wie unvollständige Konstruktionen, falsch geschriebene Bezeichner, erneutes Ausführen statt Zurückgeben und andere Freuden, die hier und jetzt im Editor auftreten können. Natürlich wird dies alles vor der Kompilierung aufgeräumt, repariert und in Einklang gebracht. Aber hier und jetzt, im Editor, ist es das, was es ist. In dieser Form gelangt der in die IDE integrierte Parser alle 5-10 Sekunden an die Tabelle. Und wenn die selbstgeschriebene Version davon perfekt "versteht", dass es sich um ein halbfertiges Produkt handelt, dann klingelt - nein. Und sehr überrascht. Was als Ergebnis einer solchen Überraschung passiert, hängt, wie man sagt, "von" ab.
Glücklicherweise ist Clang ziemlich tolerant gegenüber Codefehlern. Trotzdem kann es Überraschungen geben - plötzlich verschwindende Hintergrundbeleuchtung, automatisch vervollständigte Kurve, seltsame Diagnose. Sie müssen auf all das vorbereitet sein. Darüber hinaus ist Clang nicht alles fressend. Er hat das Recht, nichts in den Headern des Compilers zu akzeptieren, der hier und jetzt zum Erstellen des Projekts verwendet wird. Tricky Intrinsics, nicht standardmäßige Erweiterungen und andere, ähm ... Funktionen - all dies kann an den unerwartetsten Stellen zu Analysefehlern führen. Und natürlich Leistung. Das Bearbeiten einer Grammatikdatei auf Boost.Spirit oder das Arbeiten an einem llvm-basierten Projekt wird ein Vergnügen sein. Aber über alles im Detail.
Vorgefertigter Code
Angenommen, Sie haben ein neues Projekt gestartet. Ihre Umgebung hat ein Standard-Leerzeichen für main.cpp generiert, und Sie haben Folgendes geschrieben:
#include <iostream> int main() { foo(10) }
Der Code ist aus Sicht von C ++ offen gesagt ungültig. Es gibt keine Definition der Funktion foo (...) in der Datei, die Zeile ist nicht vollständig usw. Aber ... Sie haben gerade erst begonnen. Dieser Code hat das Recht auf diesen Typ. Wie nimmt dieser Code eine IDE mit einem selbstgeschriebenen Parser (in diesem Fall CLion) wahr?
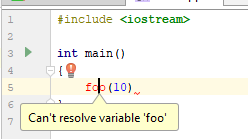
Und wenn Sie auf die Glühbirne klicken, können Sie Folgendes sehen:
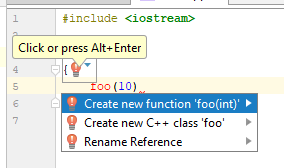
Eine solche IDE, die etwas weiß, ähm, mehr über das Geschehen, bietet die sehr erwartete Option: eine Funktion aus dem Nutzungskontext zu erstellen. Tolles Angebot, denke ich. Wie verhält sich die klirrbasierte IDE (in diesem Fall Qt Creator 4.7)?
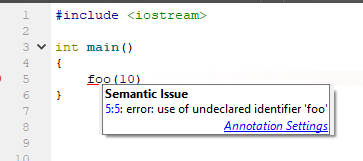
Und was wird vorgeschlagen, um die Situation zu korrigieren? Aber nichts! Nur Standard umbenennen!
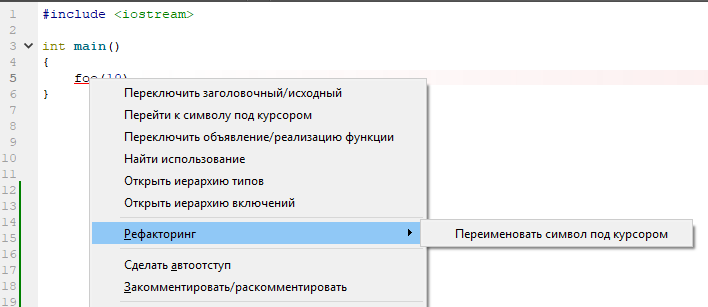
Der Grund für dieses Verhalten ist sehr einfach: Für Clang ist dieser Text vollständig (und es kann nichts anderes sein). Und er baut den AST auf dieser Annahme auf. Und dann ist alles einfach: clang sieht eine zuvor undefinierte Kennung. Dies ist Text in C ++ (nicht in C). Es werden keine Annahmen über die Art des Bezeichners getroffen - er ist nicht definiert, daher ist ein Code ungültig. Und in AST für diese Zeile erscheint nichts. Sie ist einfach nicht da. Und was nicht in AST ist, ist unmöglich zu analysieren. Es ist eine Schande, nervig, okay.
Der in die IDE integrierte Parser basiert auf einigen anderen Annahmen. Er weiß, dass der Code nicht fertig ist. Dass der Programmierer gerade Gedanken macht und die Finger hinter ihr keine Zeit haben. Daher können nicht alle Bezeichner definiert werden. Ein solcher Code ist natürlich unter dem Gesichtspunkt hoher Standards für die Compilerqualität falsch, aber der Parser weiß, was mit einem solchen Code getan werden kann, und bietet Optionen an. Ganz vernünftige Möglichkeiten.
Zumindest bis Version 3.7 (einschließlich) traten in diesem Code ähnliche Probleme auf:
#include <iostream> class Temp { public: int i; }; template<typename T> class Foo { public: int Bar(Temp tmp) { Tpl(tmp); } private: template<typename U> void Tpl(U val) { Foo<U> tmp(val); tmp. } int member; }; int main() { return 0; }
Innerhalb der Template-Klassenmethoden funktionierte das Clang-basierte Autocomplet nicht. Soweit ich es herausfinden konnte, lag der Grund in der Analyse von Vorlagen in zwei Durchgängen. Die automatische Vervollständigung in Clang wird beim ersten Durchgang ausgelöst, wenn Informationen zu den tatsächlich verwendeten Typen möglicherweise nicht ausreichen. In Clang 5.0 (nach Release Notes zu urteilen) wurde dies behoben.
Auf die eine oder andere Weise können Situationen auftreten, in denen der Compiler nicht in der Lage ist, den richtigen AST im bearbeiteten Code zu erstellen (oder die richtigen Schlussfolgerungen aus dem Kontext zu ziehen). In diesem Fall "sieht" die IDE die entsprechenden Textabschnitte einfach nicht und kann dem Programmierer in keiner Weise helfen. Was natürlich nicht so toll ist. Die Fähigkeit, effektiv mit falschem Code zu arbeiten, ist das, was der Parser in der IDE benötigt und was der reguläre Compiler überhaupt nicht benötigt. Daher kann der Parser in der IDE viele Heuristiken verwenden, die für den Compiler nicht nur nutzlos, sondern auch schädlich sein können. Und um zwei Betriebsmodi zu implementieren, müssen Sie die Entwickler noch überzeugen.
"Diese Rolle ist missbräuchlich!"
Die IDE des Programmierers ist normalerweise eine (also zwei), aber es gibt viele Projekte und Toolchains. Und natürlich möchte ich keine zusätzlichen Gesten ausführen, um von Toolchain zu Toolchain, von Projekt zu Projekt, zu wechseln. Ein oder zwei Klicks, und die Build-Konfiguration ändert sich von Debug zu Release und der Compiler von MSVC zu MinGW. Der Code-Parser in der IDE bleibt jedoch unverändert. Und er muss zusammen mit dem Build-System von einer Konfiguration zur anderen wechseln, von einer Toolchain zur anderen. Eine Toolchain kann eine Art Exotik oder Kreuz sein. Und die Aufgabe des Parsers hier ist es, den Code weiterhin korrekt zu analysieren. Wenn möglich mit einem Minimum an Fehlern.
Clang ist Allesfresser genug. Es kann gezwungen werden, Compiler-Erweiterungen von Microsoft, dem gcc-Compiler, zu akzeptieren. Es können Optionen im Format dieser Compiler übergeben werden, und Clang wird sie sogar verstehen. All dies garantiert jedoch nicht, dass Clang eine Überschrift von den Innereien akzeptiert, die aus dem GCC-Tank gesammelt wurden. Jeder __builtin_intrinsic_xxx kann für ihn zum Stolperstein werden. Oder Sprachkonstrukte, die die aktuelle Version von clang in der IDE einfach nicht unterstützt. Dies hat höchstwahrscheinlich keinen Einfluss auf die Qualität der AST-Konstruktion für die aktuell bearbeitete Datei. Das Erstellen einer globalen Zeichenbasis oder das Speichern vorkompilierter Header kann jedoch zu Problemen führen. Und das kann ein ernstes Problem sein. Ein ähnliches Problem könnte sich als ähnlicher Code herausstellen, nicht in den Kopfzeilen von Toolchains oder von Drittanbietern, sondern in den Kopfzeilen oder Quellcodes des Projekts. Übrigens ist all dies ein wichtiger Grund, dem Build-System (und der IDE) explizit mitzuteilen, welche Header-Dateien für Ihr Projekt "fremd" sind. Es kann das Leben leichter machen.
Auch hier wurde die IDE ursprünglich für die Verwendung mit verschiedenen Compilern, Einstellungen, Toolchains und mehr entwickelt. Entwickelt, um mit Code umgehen zu müssen, von dem einige Elemente nicht unterstützt werden. Der Release-Zyklus der IDE (nicht alle :) ist kürzer als der von Compilern. Daher besteht das Potenzial, neue Funktionen schneller aufzurufen und auf festgestellte Probleme zu reagieren. In der Welt der Compiler ist alles etwas anders: Der Release-Zyklus beträgt mindestens ein Jahr, die Probleme der Cross-Compiler-Kompatibilität werden durch bedingte Kompilierung gelöst und auf die Schultern des Entwicklers übertragen. Der Compiler muss nicht universell und Allesfresser sein - seine Komplexität ist bereits hoch. Klirren ist keine Ausnahme.
Der Kampf um Geschwindigkeit
In dem Teil der Zeit, die der Programmierer in der IDE verbringt, wenn er nicht im Debugger sitzt, bearbeitet er den Text. Und sein natürlicher Wunsch ist es, es bequem zu machen (sonst warum eine IDE? Kann ich mit einem Notizblock auskommen!). Komfort beinhaltet insbesondere die hohe Reaktionsgeschwindigkeit des Editors auf Textänderungen und das Drücken von Hotkeys. Wie Anastasia in ihrem Bericht richtig feststellte, ist dies schrecklich, wenn die Umgebung fünf Sekunden nach dem Drücken von Strg + Leertaste nicht mit dem Erscheinen eines Menüs oder einer Liste der automatischen Vervollständigung reagiert hat (im Ernst, versuchen Sie es selbst). In Zahlen bedeutet dies, dass der in die IDE integrierte Parser etwa eine Sekunde Zeit hat, um die Änderungen in der Datei auszuwerten und den AST neu zu erstellen, und eineinhalb oder zwei, um dem Entwickler eine kontextsensitive Auswahl zu bieten. Zweitens. Na ja, vielleicht zwei. Außerdem wird erwartet, dass die vorgenommenen Änderungen "sichtbar" sind, wenn der Entwickler den .h-Spitznamen ändert und dann auf .cpp-shnik wechselt. Die Dateien, hier sind sie, werden in den benachbarten Fenstern geöffnet. Und jetzt eine einfache Berechnung. Wenn Clang, das über die Befehlszeile gestartet wird, den Quellcode in etwa zehn bis zwanzig Sekunden verarbeiten kann, wo ist dann der Grund zu der Annahme, dass es beim Starten über die IDE den Quellcode viel schneller verarbeitet und in diese ein oder zwei Sekunden passt? Das heißt, es wird eine Größenordnung schneller arbeiten? Im Allgemeinen könnte dies beendet werden, aber ich werde nicht.
Etwa zehn bis zwanzig Sekunden bis zur Quelle übertreibe ich natürlich. Wenn dort eine schwere API enthalten ist oder beispielsweise boost.spirit mit Hana bereitsteht und all dies aktiv im Text verwendet wird, sind 10 bis 20 Sekunden immer noch gute Werte. Aber selbst wenn der AST Sekunden nach drei oder vier nach dem Start des integrierten Parsers bereit ist, ist es schon lange her. Vorausgesetzt, dass solche Starts so regelmäßig (um das Codemodell und den Index in einem konsistenten Zustand zu halten, hervorzuheben, aufzufordern usw.) sowie bei Bedarf erfolgen - Code-Vervollständigung ist auch der Start des Compilers. Ist es möglich, diese Zeit irgendwie zu verkürzen? Leider gibt es bei der Verwendung von clang als Parser nicht viele Möglichkeiten. Grund: Dies ist ein Tool eines Drittanbieters, bei dem (im Idealfall ) keine Änderungen vorgenommen werden können. Das heißt, mit perftool in den Clang-Code eintauchen, einige Zweige optimieren, vereinfachen - diese Funktionen sind nicht verfügbar und Sie haben mit dem zu tun, was die externe API bietet (im Fall der Verwendung von libclang ist sie auch ziemlich eng).
Die erste, offensichtliche und tatsächlich einzige Lösung besteht darin, dynamisch generierte vorkompilierte Header zu verwenden. Bei angemessener Implementierung ist die Lösung ein Killer. Erhöht die Kompilierungsgeschwindigkeit zumindest zeitweise. Das Wesentliche ist einfach: Die Umgebung sammelt alle Header von Drittanbietern (oder Header außerhalb des Projektstamms) in einer einzigen .h-Datei, erstellt pch aus dieser Datei und schließt diese pch dann implizit in jede Quelle ein. Natürlich tritt ein offensichtlicher Nebeneffekt auf: Im Quellcode ( in der Bearbeitungsphase ) sind Symbole zu sehen, die nicht darin enthalten sind. Dies ist jedoch eine Gebühr für die Geschwindigkeit. Ich muss wählen. Und alles wäre in Ordnung, wenn nicht ein kleines Problem wäre: clang ist immer noch ein Compiler. Und als Compiler mag er keine Fehler im Code. Und wenn plötzlich (plötzlich! - siehe vorherigen Abschnitt) Fehler in den Headern auftreten, wird die .pch-Datei nicht erstellt. Zumindest war es bis zur Version 3.7. Hat sich seitdem etwas geändert? Ich weiß nicht, es besteht der Verdacht, dass nein. Leider gibt es keine Möglichkeit mehr zu überprüfen.
Leider sind alternative Optionen aus demselben Grund nicht verfügbar: clang ist ein Compiler und eine Sache für sich. Aktiv in den AST-Generierungsprozess eingreifen, AST aus verschiedenen Teilen zusammenführen, externe Symbolbasen beibehalten und leider alle diese Funktionen sind nicht verfügbar. Nur externe API, nur Hardcore und Einstellungen über Kompilierungsoptionen verfügbar. Und dann Analyse des resultierenden AST. Wenn Sie auf der C ++ - Version der API sitzen, stehen Ihnen etwas mehr Möglichkeiten zur Verfügung. Sie können beispielsweise mit benutzerdefinierten FrontendActions herumspielen, feinere Einstellungen für Kompilierungsoptionen vornehmen usw. In diesem Fall ändert sich der Hauptpunkt jedoch nicht - der bearbeitete (oder indizierte) Text wird unabhängig von den anderen und vollständig kompiliert. Das ist alles. Der Punkt.
Vielleicht (vielleicht!) Wird es eines Tages eine Gabel des Upstream-Clangs geben, die speziell für die Verwendung als Teil der IDE zugeschnitten ist. Möglicherweise. Aber im Moment ist alles so wie es ist. Angenommen, die Integration des Teams von Qt Creator (bis zur "letzten" Phase) in libclang hat sieben Jahre gedauert. Ich habe QtC 4.7 mit einer libclang-basierten Engine ausprobiert - ich gebe zu, ich persönlich mag die alte Version (auf der selbstgeschriebenen) einfacher, weil sie in meinen Fällen besser funktioniert: Sie fordert und hebt hervor und alles andere. Ich werde mich nicht verpflichten zu schätzen, wie viele menschliche Stunden sie für diese Integration aufgewendet haben, aber ich wage vorzuschlagen, dass es in dieser Zeit möglich sein würde, meinen eigenen Parser fertigzustellen. Soweit ich das beurteilen kann (anhand indirekter Angaben), blickt das an CLion arbeitende Team vorsichtig auf die Integration mit libclang / clang ++ hin. Dies sind jedoch rein persönliche Annahmen. Die Integration auf der Ebene des Language Server-Protokolls ist eine interessante Option, aber speziell für den C ++ - Fall halte ich dies aus den oben genannten Gründen eher als Palliativ. Es überträgt einfach Probleme von einer Abstraktionsebene auf eine andere. Aber vielleicht verwechsle ich mich mit dem LSP - der Zukunft. Mal sehen. Trotzdem ist das Leben der Entwickler moderner IDEs für C ++ voller Abenteuer - mit Clang als Backend oder ohne.