„Das @ Cloudflare-Team hat gerade Änderungen vorgenommen, die unsere Netzwerkleistung erheblich verbessert haben, insbesondere bei den langsamsten Anforderungen. Wie viel schneller? Wir schätzen, dass wir dem Internet etwa 54 Jahre Zeit pro Tag sparen, die sonst damit verbracht worden wären, auf das Laden der Websites zu warten .
“ - Matthew Prince
Tweet , 28. Juni 2018
10 Millionen Websites, Anwendungen und APIs verwenden Cloudflare, um das Herunterladen von Inhalten für Benutzer zu beschleunigen. In der Spitze verarbeiten wir mehr als 10 Millionen Anfragen pro Sekunde in 151 Rechenzentren. Im Laufe der Jahre haben wir viele Änderungen an unserer Version von Nginx vorgenommen, um mit dem Wachstum fertig zu werden. In diesem Artikel geht es um eine dieser Änderungen.
Wie Nginx funktioniert
Nginx ist eines der Programme, das Ereignisverarbeitungsschleifen verwendet, um
das C10K-Problem zu lösen. Jedes Mal, wenn ein Netzwerkereignis eintrifft (eine neue Verbindung, Anforderung oder Benachrichtigung zum Senden einer größeren Datenmenge usw.), wird Nginx aktiviert, verarbeitet das Ereignis und kehrt dann zu einem anderen Job zurück (dies kann andere Ereignisse verarbeiten). Wenn ein Ereignis eintrifft, sind die Daten dafür bereit, sodass Sie viele gleichzeitige Anforderungen ohne Ausfallzeiten effizient verarbeiten können.
num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ // handle event[1]: send out response to GET http://cloudflare.com/
So könnte beispielsweise ein Code aussehen, um Daten aus einem Dateideskriptor zu lesen:
// we got a read event on fd while (buf_len > 0) { ssize_t n = read(fd, buf, buf_len); if (n < 0) { if (errno == EWOULDBLOCK || errno == EAGAIN) { // try later when we get a read event again } if (errno == EINTR) { continue; } return total; } buf_len -= n; buf += n; total += n; }
Wenn fd ein Netzwerk-Socket ist, werden bereits empfangene Bytes zurückgegeben. Der letzte Aufruf gibt
EWOULDBLOCK . Dies bedeutet, dass der lokale Lesepuffer beendet wurde und Sie nicht mehr von diesem Socket lesen sollten, bis Daten angezeigt werden.
Die Festplatten-E / A unterscheidet sich vom Netzwerk
Wenn fd unter Linux eine reguläre Datei ist, werden
EWOULDBLOCK und
EAGAIN nie
EWOULDBLOCK und der
EAGAIN wartet immer darauf, den gesamten Puffer zu lesen, selbst wenn die Datei mit
O_NONBLOCK geöffnet
O_NONBLOCK . Wie im
offenen (2) Handbuch geschrieben:
Bitte beachten Sie, dass dieses Flag nicht für reguläre Dateien und Blockgeräte gültig ist.
Mit anderen Worten, der obige Code ist im Wesentlichen auf Folgendes reduziert:
if (read(fd, buf, buf_len) > 0) { return buf_len; }
Wenn der Handler von der Festplatte lesen muss, blockiert er die Ereignisschleife, bis der Lesevorgang abgeschlossen ist, und nachfolgende Ereignishandler warten.
Dies ist für die meisten Aufgaben normal, da das Lesen von einer Festplatte normalerweise recht schnell und viel vorhersehbarer ist als das Warten auf ein Paket aus dem Netzwerk. Besonders jetzt, wo jeder eine SSD hat und alle unsere Caches auf SSDs sind. Bei modernen SSDs eine sehr kleine Verzögerung, normalerweise in zehn Mikrosekunden. Darüber hinaus können Sie Nginx mit mehreren Workflows ausführen, sodass ein langsamer Ereignishandler Anforderungen in anderen Prozessen nicht blockiert. Meistens können Sie sich auf Nginx verlassen, um Anfragen schnell und effizient zu bearbeiten.
SSD-Leistung: nicht immer wie versprochen
Wie Sie vielleicht vermutet haben, sind diese rosigen Annahmen nicht immer wahr. Wenn jeder Messwert immer 50 μs dauert, dauert das Lesen von 0,19 MB in Blöcken von 4 KB (und wir lesen in noch größeren Blöcken) nur 2 ms. Tests haben jedoch gezeigt, dass die Zeit bis zum ersten Byte manchmal viel schlechter ist, insbesondere im 99. und 999. Perzentil. Mit anderen Worten, das langsamste Auslesen von 100 (oder 1000) Messwerten dauert oft viel länger.
Solid-State-Laufwerke sind sehr schnell, aber für ihre Komplexität bekannt. Sie haben Computer in dieser Warteschlange und ordnen E / A neu an. Außerdem führen sie verschiedene Hintergrundaufgaben aus, z. B. Speicherbereinigung und Defragmentierung. Von Zeit zu Zeit verlangsamen sich Anfragen merklich. Mein Kollege
Ivan Bobrov hat mehrere E / A-Benchmarks gestartet und Leseverzögerungen von bis zu 1 Sekunde registriert. Darüber hinaus weisen einige unserer SSDs mehr solche Leistungsspitzen auf als andere. In Zukunft werden wir diesen Indikator beim Kauf einer SSD berücksichtigen, aber jetzt müssen wir eine Lösung für vorhandene Geräte entwickeln.
Gleichmäßige Lastverteilung mit SO_REUSEPORT
Es ist schwierig, eine langsame Antwort pro 1000 Anfragen zu vermeiden, aber wir wollen wirklich nicht, dass die verbleibenden 1000 Anfragen für eine ganze Sekunde blockiert werden. Konzeptionell kann Nginx viele Anforderungen parallel verarbeiten, startet jedoch jeweils nur einen Ereignishandler. Also habe ich eine spezielle Metrik hinzugefügt:
gettimeofday(&start, NULL); num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ gettimeofday(&event_start_handle, NULL); // handle event[1]: send out response to GET http://cloudflare.com/ timersub(&event_start_handle, &start, &event_loop_blocked);
Das 99. Perzentil (p99)
event_loop_blocked 50% unseres TTFB überschritten. Mit anderen Worten, die Hälfte der Zeit bei der Bearbeitung einer Anforderung ist das Ergebnis der Blockierung des Ereignisverarbeitungszyklus durch andere Anforderungen.
event_loop_blocked misst nur die Hälfte der Sperre (da ausstehende Aufrufe von
epoll_wait() nicht gemessen werden), sodass das tatsächliche Verhältnis der blockierten Zeit viel höher ist.
Auf jedem unserer Computer wird Nginx mit 15 Workflows ausgeführt, d. H. Eine langsame E / A blockiert nicht mehr als 6% der Anforderungen. Die Ereignisse sind jedoch nicht gleichmäßig verteilt: Der Hauptmitarbeiter erhält 11% der Anfragen.
SO_REUSEPORT kann das Problem der ungleichmäßigen Verteilung lösen. Marek Maikovsky hat zuvor über den
Nachteil dieses Ansatzes im Zusammenhang mit anderen Nginx-Instanzen geschrieben, aber hier können Sie ihn größtenteils ignorieren: Upstream-Cache-Verbindungen sind dauerhaft, sodass Sie eine leichte Erhöhung der Verzögerung beim Öffnen der Verbindung vernachlässigen können. Diese Konfigurationsänderung allein mit der Aktivierung von
SO_REUSEPORT verbesserte den Peak p99 um 33%.
Read () in einen Thread-Pool verschieben: keine Silberkugel
Die Lösung besteht darin, read () nicht zu blockieren. Eigentlich ist diese Funktion
in normalem Nginx implementiert ! Bei Verwendung der folgenden Konfiguration werden read () und write () im Thread-Pool ausgeführt und blockieren die Ereignisschleife nicht:
aio threads; aio_write on;
Wir haben diese Konfiguration jedoch getestet und anstatt die Antwortzeit um das 33-fache zu verbessern, haben wir nur eine kleine Änderung von p99 festgestellt. Der Unterschied liegt innerhalb der Fehlergrenze. Das Ergebnis war sehr entmutigend, daher haben wir diese Option vorübergehend verschoben.
Es gibt mehrere Gründe, warum wir keine signifikanten Verbesserungen hatten, wie die Nginx-Entwickler. Im Test verwendeten sie 200 gleichzeitige Verbindungen, um Dateien mit 4 MB an die Festplatte anzufordern. Winchester haben eine viel höhere E / A-Latenz, sodass die Optimierung einen größeren Effekt hat.
Darüber hinaus sind wir hauptsächlich besorgt über die Leistung von p99 (und p999). Die Optimierung der durchschnittlichen Verzögerung löst nicht unbedingt das Problem der Spitzenemission.
Schließlich sind in unserer Umgebung typische Dateigrößen viel kleiner. 90% unserer Cache-Treffer sind weniger als 60 KB groß. Je kleiner die Dateien sind, desto weniger Fälle von Blockierung (normalerweise lesen wir die gesamte Datei in zwei Lesevorgängen).
Schauen wir uns die Festplatten-E / A an, wenn sie im Cache angezeigt werden:
// https://example.com 0xCAFEBEEF fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY); // 32 // , "aio threads" read(fd, buf, 32*1024);
32K werden nicht immer gelesen. Wenn die Header klein sind, müssen Sie nur 4 KB lesen (wir verwenden E / A nicht direkt, daher rundet der Kernel auf 4 KB).
open() scheint harmlos zu sein, benötigt aber tatsächlich Ressourcen. Der Kernel sollte mindestens prüfen, ob die Datei vorhanden ist und ob der aufrufende Prozess die Berechtigung zum Öffnen hat. Er muss den Inode für
/cache/prefix/dir/EF/BE/CAFEBEEF , und dafür muss er in
/cache/prefix/dir/EF/BE/ nach
CAFEBEEF suchen. Kurz gesagt, im schlimmsten Fall führt der Kernel diese Suche durch:
/cache /cache/prefix /cache/prefix/dir /cache/prefix/dir/EF /cache/prefix/dir/EF/BE /cache/prefix/dir/EF/BE/CAFEBEEF
Dies sind 6 separate Lesevorgänge, die
open() erzeugt, verglichen mit 1
read() ! Glücklicherweise fällt die Suche in den meisten Fällen in den
Dentry-Cache und erreicht die SSD nicht. Es ist jedoch klar, dass die Verarbeitung von
read() in einem Thread-Pool nur die Hälfte des Bildes ausmacht.
Schlussakkord: nicht blockierendes open () in Thread-Pools
Daher haben wir eine Änderung an Nginx vorgenommen, sodass
open() hauptsächlich im Thread-Pool ausgeführt wird und die Ereignisschleife nicht blockiert. Und hier ist das Ergebnis von nicht blockierendem open () und read () gleichzeitig:
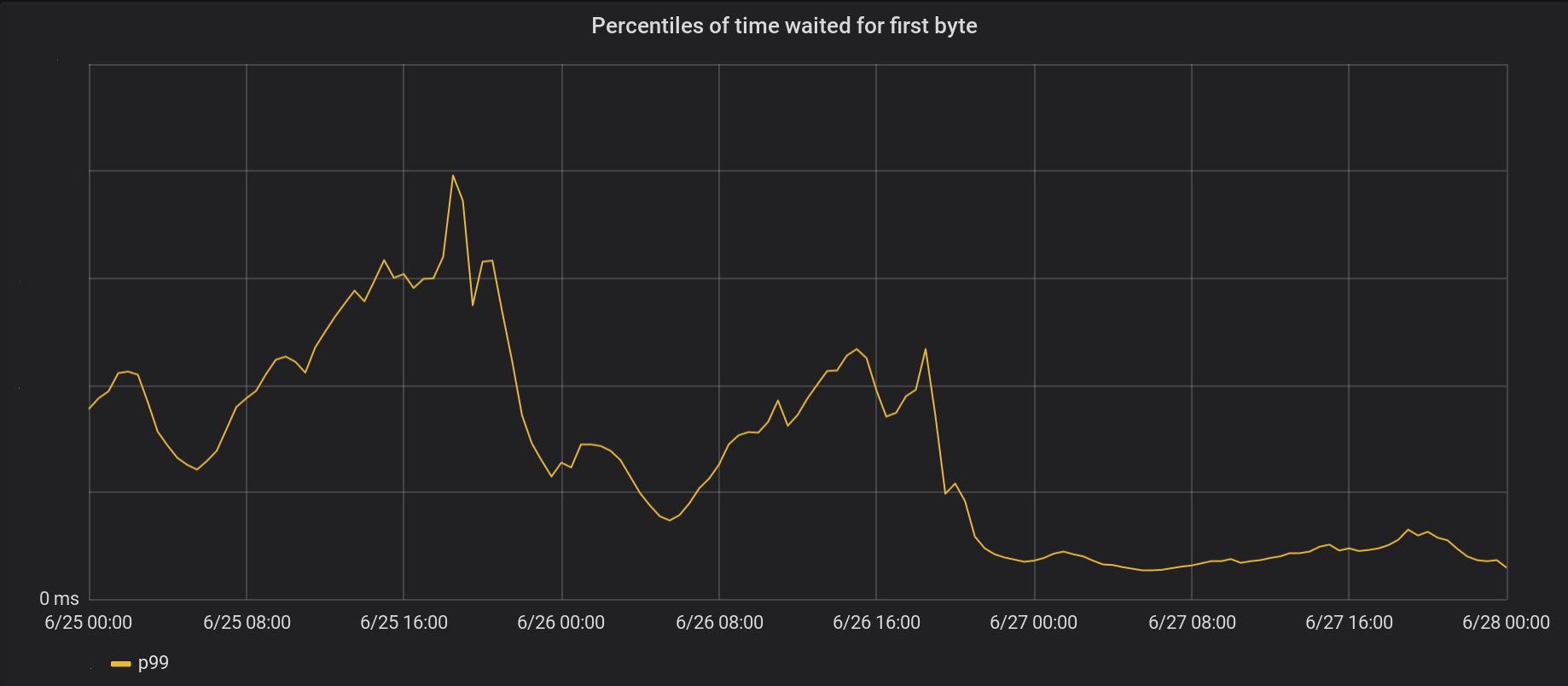
Am 26. Juni haben wir Änderungen an den 5 am stärksten frequentierten Rechenzentren und am nächsten Tag an allen anderen 146 Rechenzentren auf der ganzen Welt vorgenommen. Der Gesamtpeak p99 TTFB nahm um das 6-fache ab. Wenn wir die Zeit von 8 Millionen Anfragen pro Sekunde zusammenfassen, sparen wir dem Internet 54 Tage Wartezeit pro Tag.
Unsere Veranstaltungsreihe hat die Schlösser noch nicht vollständig beseitigt. Insbesondere tritt das Blockieren immer noch beim ersten
open(O_CREAT) der Datei (sowohl
open(O_CREAT) als auch beim
rename() ) oder beim Aktualisieren der
open(O_CREAT) . Solche Fälle sind jedoch im Vergleich zu Cache-Zugriffen selten. In Zukunft werden wir die Möglichkeit in Betracht ziehen, diese Elemente außerhalb der Ereignisverarbeitungsschleife zu verschieben, um den Verzögerungsfaktor p99 weiter zu verbessern.
Fazit
Nginx ist eine leistungsstarke Plattform, aber die Skalierung extrem hoher Linux-E / A-Lasten kann eine entmutigende Aufgabe sein. Standard Nginx entlädt das Lesen in separaten Threads, aber auf unserer Skala müssen wir oft noch einen Schritt weiter gehen.