Dies ist eine Geschichte über das Portieren von JavaScript auf die heimische Elbrus-Plattform, die von Leuten von UniPro erstellt wurde. Der Artikel bietet eine kurze vergleichende Analyse von Plattformen, Prozessdetails und Fallstricken.

Der Artikel basiert auf einem Bericht von Dmitry (
dbezheckov ) Bezhetskov und Vladimir (
volodyabo ) Anufrienko mit HolyJS 2018 Piter. Unter dem Schnitt finden Sie Video- und Textabschriften des Berichts.
Teil 1. Elbrus, ursprünglich aus Russland
Zuerst werden wir verstehen, was Elbrus ist. Hier sind einige wichtige Funktionen dieser Plattform im Vergleich zu x86.
VLIW-Architektur
Eine völlig andere architektonische Lösung als die superskalare Architektur, die derzeit auf dem Markt üblich ist. Mit VLIW können Sie Absichten im Code feiner ausdrücken, da alle unabhängigen Arithmetik-Logik-Geräte (ALUs) explizit gesteuert werden, über die Elbrus übrigens verfügt. 4. Dies schließt die Möglichkeit von Ausfallzeiten einiger ALUs nicht aus, erhöht jedoch die theoretische Leistung um einen Taktzyklus der Prozessor.
Teambündelung
Bereit Prozessorbefehle werden in Bundles (Bundles) zusammengefasst. Ein Bundle ist eine große Anweisung, die pro bedingter Uhr ausgeführt wird. Es enthält viele atomare Anweisungen, die unabhängig und unmittelbar in der Elbrus-Architektur ausgeführt werden.

Im Bild rechts geben die grauen Rechtecke die Bündel an, die durch Verarbeiten des JS-Codes links erhalten wurden. Wenn mit den Anweisungen ldd, fmuld, faddd, fsqrts alles ungefähr klar ist, ist die return-Anweisung ganz am Anfang des ersten Bundles für Leute überraschend, die mit dem Elbrus-Assembler nicht vertraut sind. Diese Anweisung lädt die Rücksprungadresse von der aktuellen floatMath-Funktion vorab in das ctpr3-Register, damit der Prozessor die erforderlichen Anweisungen herunterladen kann. Dann machen wir im letzten Bundle bereits den Übergang zur vorinstallierten Adresse in ctpr3.
Es ist auch erwähnenswert, dass Elbrus viel mehr Register 192 + 32 + 32 hat als 16 + 16 + 8 für x86.
Explizite spekulative versus implizite
Elbrus unterstützt explizite Spekulativität auf Befehlsebene. Daher können wir a.bar aufrufen und aus dem Speicher laden, noch bevor wir überprüfen, ob es nicht null ist, wie im Code auf der rechten Seite zu sehen ist. Wenn sich das logische Lesen am Ende als ungültig herausstellt, wird der Wert in b einfach als Hardware als falsch markiert und es ist nicht möglich, darauf zuzugreifen.

Unterstützung für bedingte Ausführung
Elbrus unterstützt auch die bedingte Ausführung. Betrachten Sie dies im folgenden Beispiel.

Wie wir sehen können, wird der Code aus dem vorherigen Beispiel über Spekulativität auch aufgrund der Verwendung der Faltung des bedingten Ausdrucks in Abhängigkeit reduziert, nicht durch Kontrolle, sondern durch Daten. Die Elbrus-Hardware unterstützt Prädikatregister, in denen Sie nur zwei wahre oder falsche Werte speichern können. Ihr Hauptmerkmal ist, dass Sie Anweisungen mit einem solchen Prädikat markieren können. Abhängig von ihrem Wert zum Zeitpunkt der Ausführung wird die Anweisung ausgeführt oder nicht. In diesem Beispiel führt der Befehl cmpeq den Vergleich durch und fügt sein logisches Ergebnis in das Prädikat P1 ein, das dann als Marker verwendet wird, um den Wert von b in das Ergebnis zu laden. Wenn das Prädikat gleich true war, blieb dementsprechend der Wert 0 im Ergebnis.
Mit diesem Ansatz können Sie ein ziemlich komplexes Programmsteuerungsdiagramm in eine Prädikatausführung umwandeln und dementsprechend die Fülle des Bundles erhöhen. Jetzt können wir unabhängigere Teams unter verschiedenen Prädikaten generieren und sie mit Bündeln füllen. Elbrus unterstützt 32 Prädikatregister, mit denen Sie 65 Kontrollflüsse codieren können (plus eines für das Fehlen eines Prädikats im Befehl).
Drei Hardware-Stacks im Vergleich zu einem in Intel
Zwei davon sind vor Änderungen durch den Programmierer geschützt. Einer - der Kettenstapel - ist für das Speichern von Adressen für Rückgaben von Funktionen verantwortlich, der andere - der Registerstapel - enthält die Parameter, durch die sie übergeben werden. Der dritte - Benutzerstapel - speichert Benutzervariablen und Daten. In Intel wird alles auf einem Stapel gespeichert, was zu Sicherheitslücken führt, da sich alle Adressen von Übergängen und Parametern an einem Ort befinden, der nicht durch Änderungen durch den Benutzer geschützt ist.
Kein dynamischer Verzweigungsprädiktor
Stattdessen wird ein Schema mit if-Konvertierungs- und Übergangsvorbereitungen verwendet, damit die Ausführungspipeline nicht gestoppt wird.
Warum brauchen wir JS auf Elbrus?
- Substitution importieren.
- Elbrus 'Einführung in den Heimcomputermarkt, wo Javascript bereits für denselben Browser benötigt wird.
- Elbrus wird in der Branche bereits benötigt, zum Beispiel mit Node.js. Daher müssen Sie Node auf diese Architektur portieren.
- Die Entwicklung der Architektur von Elbrus sowie Spezialisten auf diesem Gebiet.
Wenn es keinen Interpreter gibt, kommen zwei Compiler
Die vorherige Implementierung von v8 von Google wurde als Grundlage genommen. Das funktioniert so: Aus dem Quellcode wird ein abstrakter Syntaxbaum erstellt. Je nachdem, ob der Code ausgeführt wurde oder nicht, wird mit einem der beiden Compiler (Crankshaft oder FullCodegen) optimierter oder nicht optimierter Binärcode erstellt. Es gibt keinen Dolmetscher.

Wie funktioniert FullCodegen?
Die Knoten des Syntaxbaums werden in Binärcode übersetzt, wonach alles „zusammengeklebt“ wird. Ein Knoten besteht aus ungefähr 300 Codezeilen in einem Makroassembler. Dies bietet zum einen einen weiten Horizont an Optimierungen, zum anderen gibt es keine Bytecode-Übergänge wie beim Interpreter. Es ist einfach, aber gleichzeitig gibt es ein Problem - während der Portierung müssen Sie viel Code im Makro-Assembler neu schreiben.
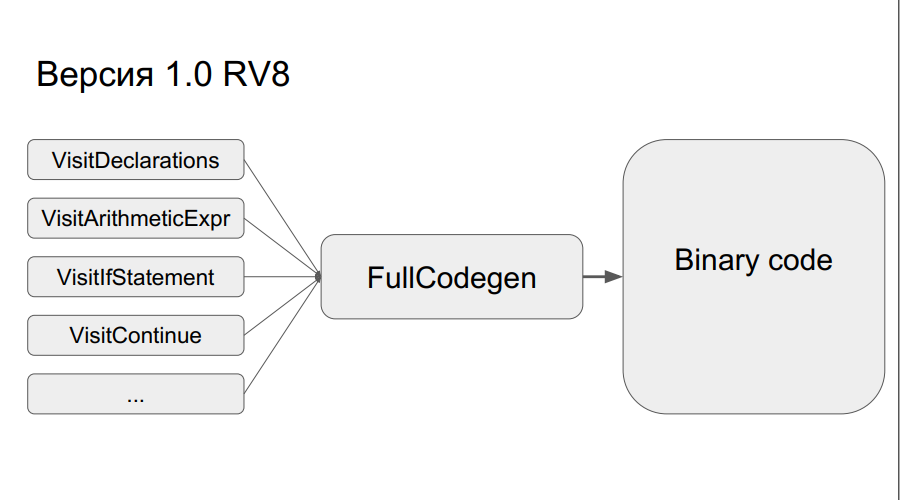
Trotzdem wurde dies alles getan und das Ergebnis war eine FullCodegen 1.0-Compilerversion für Elbrus. Alles wurde über C ++ Runtime v8 erledigt, sie haben nichts optimiert, der Assembler-Code wurde einfach von x86 in die Elbrus-Architektur umgeschrieben.
Codegen 1.1
Infolgedessen war das Ergebnis nicht ganz das gleiche wie erwartet, und es wurde beschlossen, FullCodegen 1.1 zu veröffentlichen:
- Weniger Laufzeit gemacht, auf einem Makro-Assembler geschrieben;
- Manuelle if-Konvertierungen hinzugefügt (in der Abbildung wird als Beispiel die Variable js auf wahr oder falsch geprüft);

Beachten Sie, dass die Überprüfung auf NaN, undefiniert, null, gleichzeitig erfolgt, ohne if zu verwenden, was in der Intel-Architektur erforderlich wäre.
- Der Code wurde nicht nur mit Intel neu geschrieben, sondern auch in Spekulationen spekulativ implementiert und auch über MAsm (Macro Assembler) als Fast-Path implementiert.
Tests wurden in Google Octane durchgeführt. Prüfmaschinen:
- Elbrus: E2S 750 MHz, 24 GB
- Intel: Core i7 3,4 GHz, 16 GB
Weitere Ergebnisse:

Auf dem Histogramm ist das Verhältnis der Ergebnisse, d.h. Wie oft ist Elbrus schlimmer als Intel? Bei zwei Tests, Crypto und zlib, sind die Ergebnisse deutlich schlechter, da Elbrus noch keine Hardwareanweisungen für die Arbeit mit Verschlüsselung hat. Im Allgemeinen fiel es angesichts der unterschiedlichen Frequenzen ziemlich gut aus.
Das Folgende ist ein Test im Vergleich zum js-Interpreter von Firefox, der Teil der Standardverteilung von Elbrus ist. Mehr ist besser.
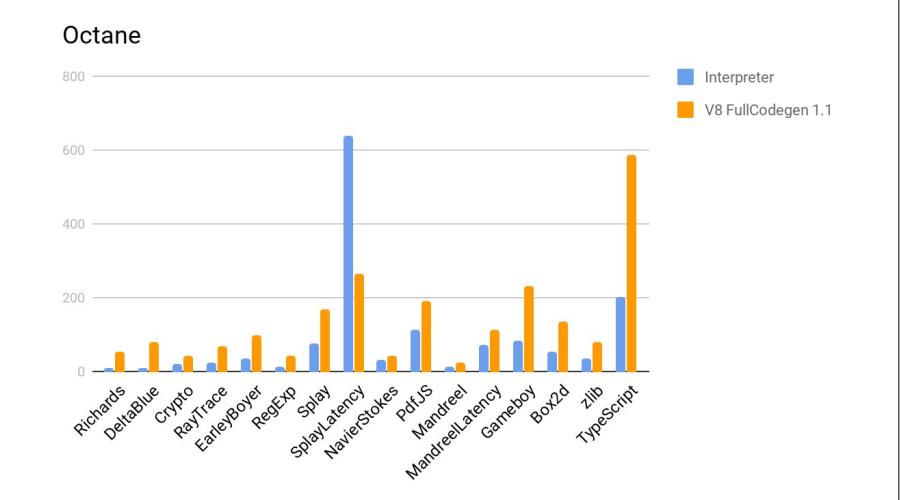
Fazit - der Compiler hat wieder gute Arbeit geleistet.
Entwicklungsergebnisse
- Die neue JS-Engine hat test262-Tests bestanden. Dies gibt ihm das Recht, als vollwertige Laufzeitumgebung ECMAScript 262 bezeichnet zu werden.
- Die Produktivität stieg im Vergleich zum vorherigen Motor - dem Dolmetscher - im Durchschnitt um das Fünffache.
- Node.js 6.10 wurde auch als Beispiel für die Verwendung von V8 portiert, da dies nicht schwierig war.
- Es ist jedoch immer noch siebenmal schlechter als Core i7 auf FullCodegen.
Nichts schien darauf hinzudeuten
Alles wäre in Ordnung, aber hier hat Google angekündigt, dass es FullCodegen und Crankshaft nicht mehr unterstützt und sie werden gelöscht. Danach erhielt das Team einen Entwicklungsauftrag für den Firefox-Browser und dazu später mehr.

Teil 2. Firefox und sein Klammeraffe
Es geht um die Firefox-Browser-Engine - SpiderMonkey. In der Abbildung sind die Unterschiede zwischen diesem Motor und dem neueren V8.
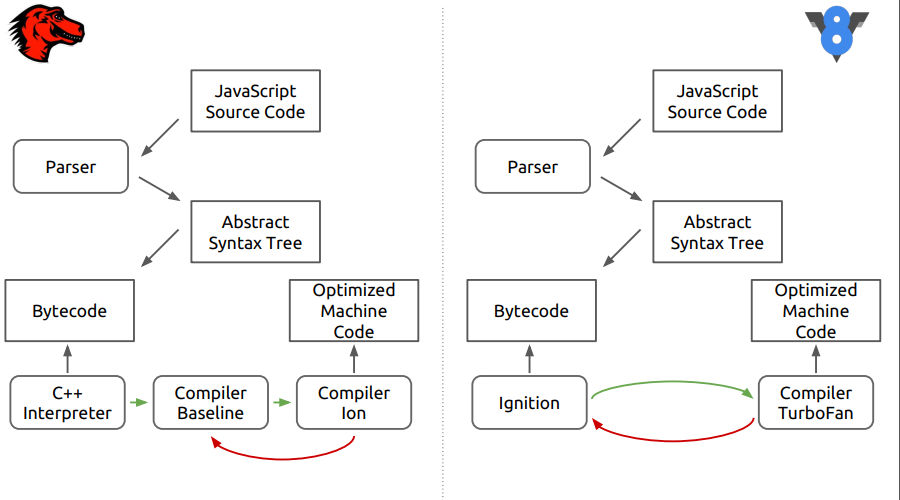
Es ist ersichtlich, dass in der ersten Phase alles so aussieht, als würde der Quellcode in einen abstrakten Syntaxbaum, dann in Bytecode analysiert, und dann beginnen die Unterschiede.
In SpiderMonkey wird der Bytecode vom C ++ - Interpreter interpretiert, der im Wesentlichen einem großen Schalter ähnelt, innerhalb dessen Bytecodesprünge ausgeführt werden. Ferner gelangt der interpretierte Code in die neotimisierende Compiler-Baseline. In der letzten Phase wird dann der optimierende Compiler Ion in den Fall aufgenommen. In der V8-Engine wird der Bytecode vom Ingnition-Interpreter und dann vom TurboFan-Compiler verarbeitet.
Baseline, ich wähle dich!
Die Portierung wurde mit dem Baseline-Compiler gestartet. Es ist im Wesentlichen eine gestapelte Maschine. Das heißt, es gibt einen bestimmten Stapel, aus dem er Variablen entnimmt, sich diese merkt und einige Aktionen mit ihnen ausführt. Danach gibt er sowohl die Variablen als auch die Ergebnisse der Aktionen an die Zellen des Stapels zurück. Nachfolgend in einigen Bildern wird dieser Mechanismus in Bezug auf die einfache Funktion foo Schritt für Schritt gezeigt:
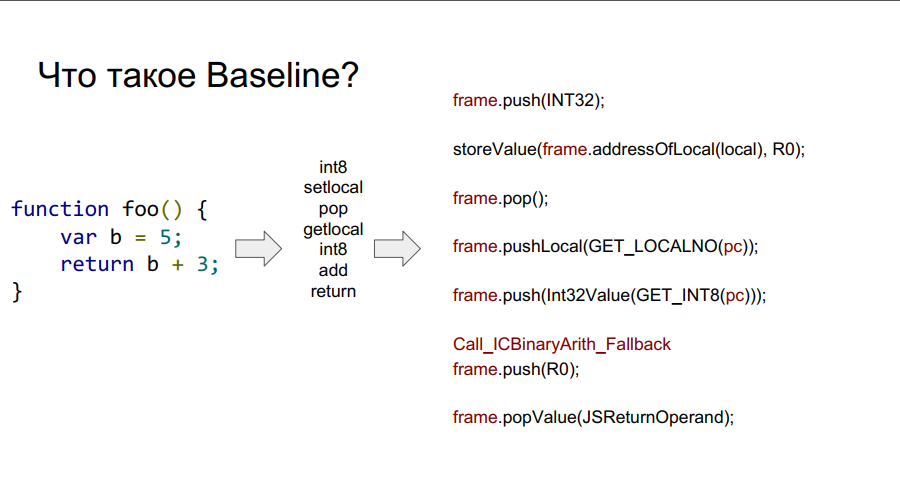


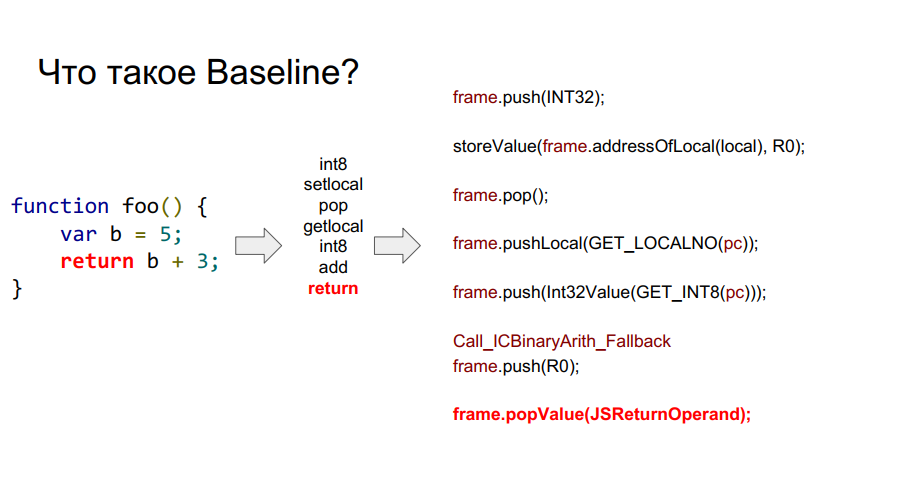
Was ist ein Rahmen?
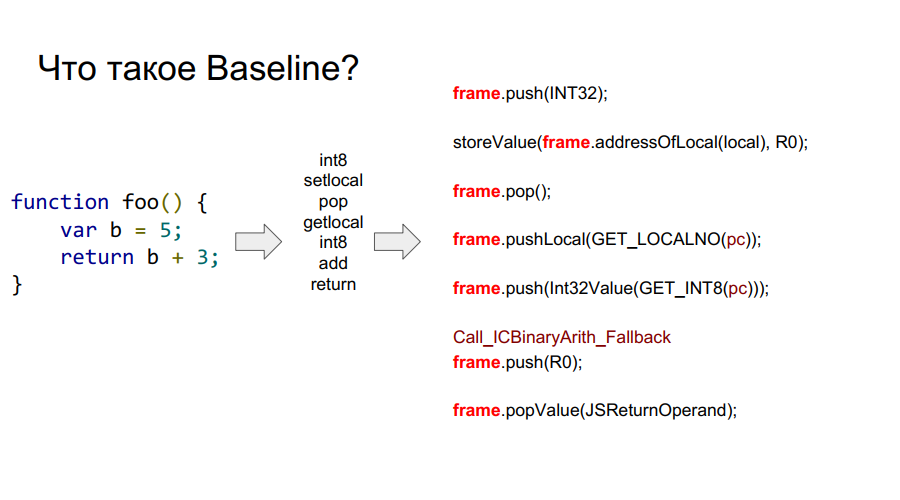
In den Bildern oben sehen Sie den Wortrahmen. Grob gesagt ist dies ein Javascript-Kontext auf Hardware, dh ein Datensatz auf dem Stapel, der eine Ihrer Funktionen beschreibt. In der Abbildung unten ist die Funktion foo und rechts davon sieht sie auf dem Stapel aus: Argumente, Beschreibung der Funktion, Rücksprungadresse, Angabe des vorherigen Frames, da die Funktion von irgendwoher aufgerufen wurde und um korrekt zum Ort des Aufrufs zurückzukehren, sollten diese Informationen gespeichert werden Stapel und dann lokale Variablen selbst Funktionen und Operanden für Berechnungen.

Somit sind die
Vorteile von Baseline :
- Sieht aus wie FullCodegen, daher hat sich seine Portierungserfahrung als nützlich erwiesen.
- Portieren Sie den Assembler und holen Sie sich einen funktionierenden Compiler.
- Es ist bequem zu debuggen;
- Jeder Stub kann umgeschrieben werden.
Es gibt aber auch
Nachteile :
- Linearer Code, bis Sie einen Bytecode ausführen, können Sie Folgendes nicht ausführen, was für Architekturen mit parallelem Rechnen nicht sehr gut ist.
- Da es mit Bytecode funktioniert, optimieren Sie nicht wirklich.
Es blieb nur noch, den Makro-Assembler zu implementieren und einen vorgefertigten Compiler zu erhalten. Das Debuggen war kein gutes Zeichen, es reichte aus, den Stapel auf der x86-Architektur und dann den Stapel zu betrachten, der beim Portieren erhalten wurde, um das Problem zu finden.
Bei Tests mit dem neuen Compiler hat sich die Produktivität verdreifacht:

Octane unterstützt jedoch keine Ausnahmen. Und ihre Umsetzung ist sehr wichtig.
Außergewöhnliche Arbeit
Lassen Sie uns zunächst sehen, wie Ausnahmen unter x86 funktionieren. Während das Programm ausgeführt wird, werden die Rücksprungadressen der Funktionen in den Stapel geschrieben. Irgendwann tritt eine Ausnahme auf. Wir übergeben an den Laufzeitausnahmehandler, der die oben genannten Frames verwendet. Wir finden heraus, wo genau die Ausnahme aufgetreten ist. Danach müssen wir den Stapel in den gewünschten Zustand zurückspulen, und dann ändert sich die Rücksprungadresse in die Adresse, in der die Ausnahme verarbeitet wird.
Das Problem ist, dass dies aufgrund eines anderen Stapelgeräts in der Elbrus-Architektur nicht funktioniert. Durch Systemaufrufe muss berechnet werden, wie viel Sie im Kettenstapel zurückspulen müssen. Als nächstes führen wir einen Systemaufruf durch, um den Aufrufstapel abzurufen. Als nächstes ersetzen wir in der Adresse im Kettenstapel die Adresse, die die Rückgabe vornimmt.
Unten sehen Sie eine Darstellung der Abfolge dieser Schritte.

Nicht der schnellste Weg, jedoch wird die Ausnahme behandelt. Trotzdem sieht es bei Intel etwas einfacher aus:

Mit Elbrus wird es mehr Sprünge zum Handler geben:

Deshalb sollten Sie die Programmlogik nicht auf Ausnahmen stützen, insbesondere nicht auf Elbrus.
Optimiere es!
Die Ausnahmebehandlung ist also implementiert. Jetzt erzählen wir Ihnen, wie wir alles etwas schneller gemacht haben:
- Inline-Caches neu geschrieben;
- Manuelle (und dann automatische) Anordnung der Verzögerungen;
- Sie haben Vorbereitungen für Übergänge getroffen (höher im Code): Je früher der Übergang vorbereitet wird, desto besser;
- Unterstützter inkrementeller Garbage Collector
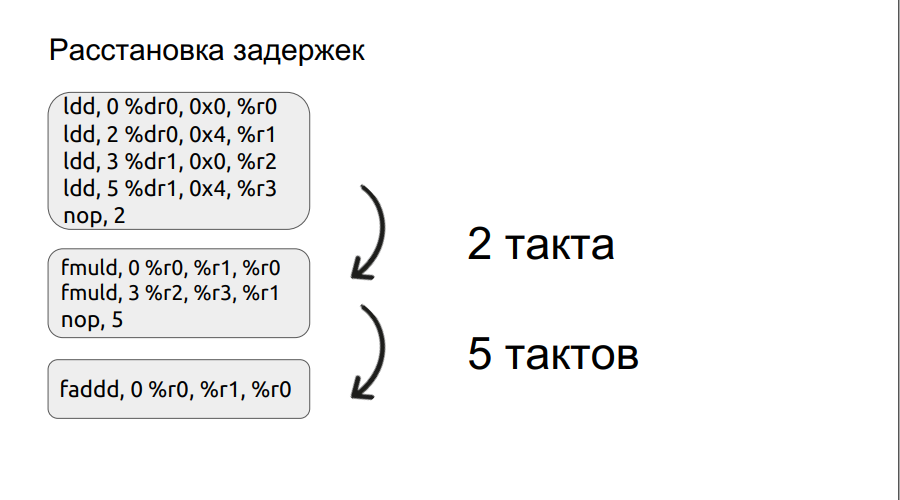
Der zweite Absatz wird etwas detaillierter behandelt. Wir haben bereits ein kleines Beispiel für die Arbeit mit Bundles untersucht und werden darauf eingehen.

Eine Operation, zum Beispiel das Laden, wird nicht in einem Zyklus ausgeführt, in diesem Fall in drei Zyklen. Wenn wir also zwei Zahlen multiplizieren möchten, haben wir die Multiplikationsoperation eingegeben, aber die Operanden selbst sind noch nicht geladen. Der Prozessor kann nur warten, bis sie geladen sind. Und er wird auf eine bestimmte Anzahl von Maßnahmen warten, ein Vielfaches von vier. Wenn Sie die Verzögerung jedoch manuell einstellen, kann die Wartezeit verkürzt werden, wodurch die Leistung verbessert wird. Ferner wurde der Prozess der Anordnung der Verzögerungen automatisiert.
Ergebnisse der Optimierung BaseLine v1.0 vs Baseline v1.1. Klar, der Motor ist schneller geworden.

Wie können Programmierer keine Ionenpistole herstellen?
Auf der Erfolgswelle der Implementierung von Baseline v1.1 wurde beschlossen, den optimierenden Compiler Ion zu portieren.

Wie funktioniert der optimierende Compiler? Der Quellcode wird interpretiert, die Kompilierung gestartet. Während der Ausführung des Bytecodes sammelt Ion Daten zu den im Programm verwendeten Typen und zur Analyse von „Hot-Funktionen“, die häufiger als andere ausgeführt werden. Danach wird die Entscheidung getroffen, sie besser zu kompilieren, zu optimieren. Als nächstes wird eine allgemeine Darstellung des Compilers, ein Operationsgraph, erstellt. Der Graph wird optimiert (opt 1, opt 2, opt ...), es wird eine Darstellung auf niedriger Ebene erstellt, die aus Maschinenbefehlen besteht, Register werden reserviert, ein direkt optimierter Binärcode wird generiert.
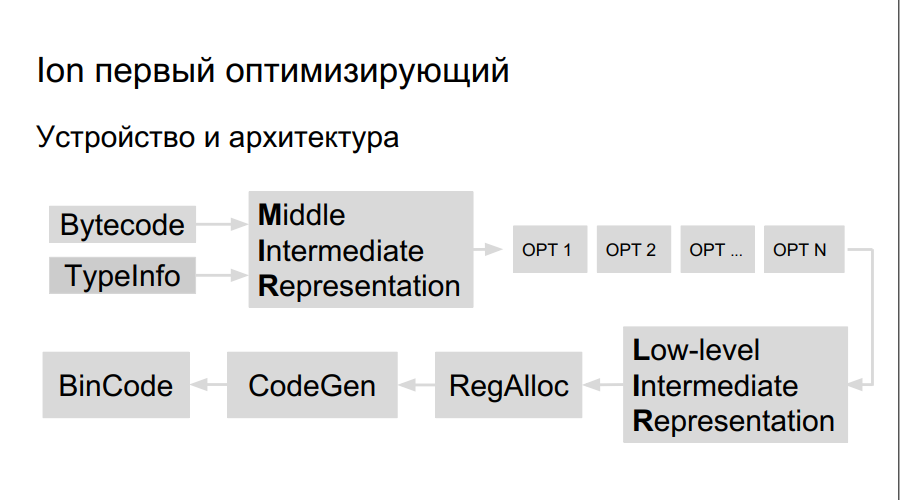
Es gibt mehr Register auf Elbrus und die Teams selbst sind groß, deshalb brauchen wir:
- Teamplaner
- Eigener Registerverteiler;
- Eigenes LIR (Low-Level Intermediate Representation);
- Eigener Code-Generator.
Das Team hatte bereits Erfahrung mit der Portierung von Java nach Elbrus. Es entschied sich, dieselbe Bibliothek für die Codegenerierung für die Portierung von Ion zu verwenden. Sie heißt TANGO. Es hat:
- Teamplaner
- Eigener Registerverteiler;
- Optimierungen auf niedriger Ebene.
Es bleibt eine hochrangige Darstellung in TANGO einzuführen, um eine Auswahl zu treffen. Das Problem ist, dass die Ansicht auf niedriger Ebene in TANGO wie ein Assembler ist, der schwer zu warten und zu debuggen ist. Wie soll der Compiler innen aussehen? Zum besseren Verständnis hat Mozilla einen eigenen HolyJit-Compiler erstellt. Es besteht auch die Möglichkeit, eine eigene Minisprache für die Übersetzung zwischen einer Darstellung auf hoher und niedriger Ebene zu schreiben.
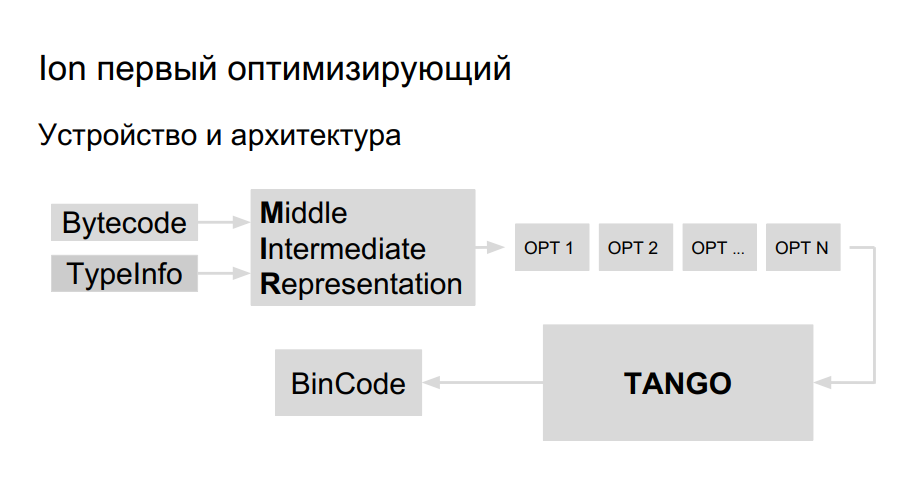
Die Entwicklung ist noch im Gange. Gut und weiter darüber, wie man es nicht mit Optimierung übertreibt.
Teil 3. Das Beste ist der Feind des Guten
Zusammenstellung wie sie ist
Der Optimierungsprozess in Ion ist gierig, wenn sich der Code erwärmt und dann kompiliert und optimiert. Dies ist im folgenden Beispiel zu sehen.
function foo(a, b) {
return a + b;
}
function doSomeStuff(obj) {
for (let i = 0; i < 1100; ++i) {
print(foo(obj,obj));
}
}
doSomeStuff("HollyJS");
doSomeStuff({n:10});
JS Shell ( ), Mozilla, :

. , , - bailout (). , . foo object, , , . , :
function doSomeStuff(obj) {
for (let i=0; i < 1100; ++i) {
if (!(obj instanceof String))
print(foo_only_str(obj, obj));
}
}
, .
. , , DCE.
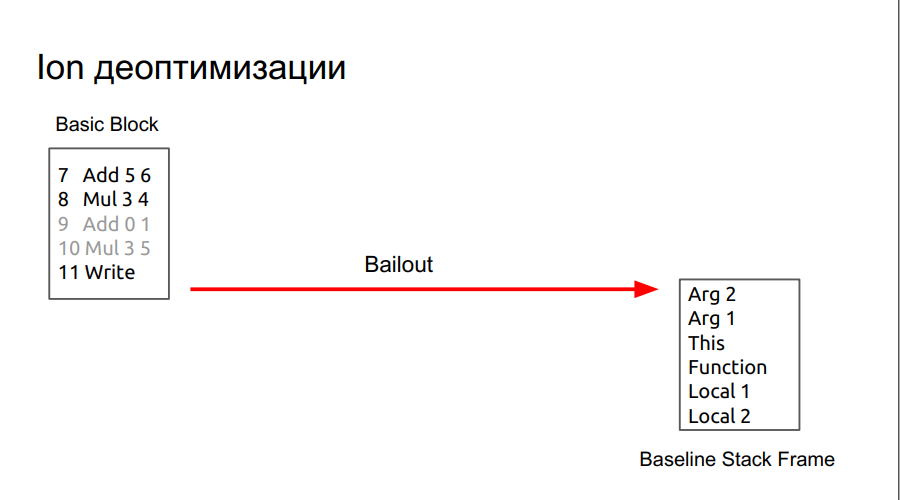
, , , .
, , , SpiderMonkey Resume Point. - , . , baseline . , runtime , . lowering, regAlloc, (snapshot), , . baseline .
:

runtime x86 : , . . , , , , , . , , Type . :
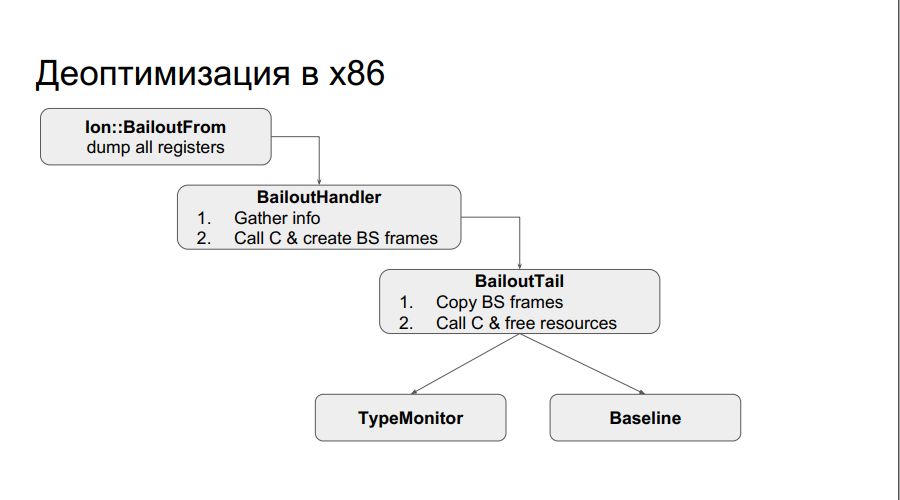
, , chain . , , .
: , chain-, N , , baseline, .
, .
:

Ion 4- baseline. :
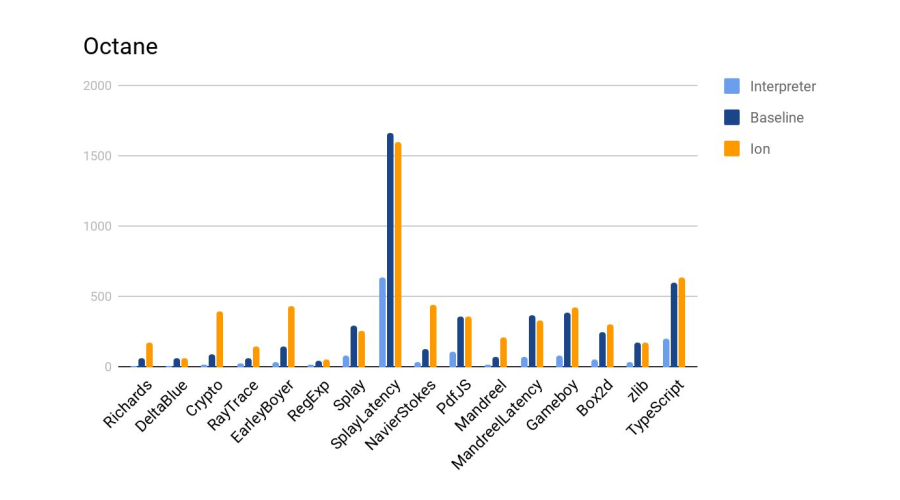
, , SpiderMonkey, V8 Node. — . .
. , , chain-.
, : 24-25 HolyJS, . — , .