Ist Ihnen die Idee gekommen, Ihre mutige Unternehmensanwendung von Grund auf neu zu schreiben? Wenn von Grund auf neu, dann ist es wow. Mindestens zweimal weniger Code, oder? Aber ein paar Jahre werden vergehen und es wird auch wachsen, Vermächtnis werden ... es gibt nicht viel Zeit und Geld für das perfekte Umschreiben.
Beruhige dich, die Behörden werden immer noch nicht erlauben, etwas umzuschreiben. Es bleibt zu refactor. Was ist der beste Weg, um Ihre kleinen Ressourcen auszugeben? Wie kann ich umgestalten, wo gereinigt werden soll?
Der Titel dieses Artikels enthält einen Verweis auf Onkel Bobs Buch
"Clean Architecture" und wurde auf der Grundlage eines wunderbaren Berichts von Victor Rentea (
Twitter ,
Website ) über JPoint erstellt (unter der Katze wird er in der ersten Person sprechen, aber vorerst die einleitende lesen). Dieser Artikel, der intelligente Bücher liest, ersetzt ihn nicht, ist aber für eine so kurze Beschreibung sehr gut dargelegt.
Die Idee ist, dass beliebte Dinge wie „Saubere Architektur“ wirklich nützlich sind. Überraschung Wenn Sie ein ganz bestimmtes Problem lösen müssen, erfordert ein einfacher, eleganter Code keinen zusätzlichen Aufwand und keine Überentwicklung. Die reine Architektur besagt, dass Sie Ihr Domänenmodell vor externen Effekten schützen müssen, und erklärt Ihnen genau, wie dies getan werden kann. Ein evolutionärer Ansatz zur Erhöhung des Volumens von Mikrodiensten. Tests, die das Refactoring weniger beängstigend machen. Weißt du das alles schon? Oder wissen Sie, aber Sie haben Angst, überhaupt darüber nachzudenken, denn es ist ein Horror, was Sie dann tun müssen?
Wer möchte eine magische Anti-Aufschub-Pille, die hilft, das Zittern zu stoppen und mit dem Refactor zu beginnen - willkommen im Videobericht oder unter Katze.
Mein Name ist Victor, ich komme aus Rumänien. Formal bin ich Berater, technischer Experte und leitender Architekt bei der rumänischen IBM. Aber wenn ich gebeten wurde, meine Tätigkeit selbst zu definieren, dann bin ich ein Evangelist des reinen Codes. Ich liebe es, schönen, sauberen und unterstützten Code zu erstellen - in der Regel spreche ich darüber in Berichten. Darüber hinaus inspiriert mich die Lehre: Schulung von Entwicklern in den Bereichen Java EE, Spring, Dojo, Test Driven Development, Java Performance sowie im Bereich der erwähnten Evangelisation - den Prinzipien sauberer Codemuster und ihrer Entwicklung.
Die Erfahrung, auf der meine Theorie basiert, ist hauptsächlich die Entwicklung von Unternehmensanwendungen für den größten IBM Kunden in Rumänien - den Bankensektor.
Der Plan für diesen Artikel lautet wie folgt:
- Datenmodellierung: Datenstrukturen sollten nicht zu unseren Feinden werden.
- Organisation der Logik: das Prinzip der "Zerlegung des Codes, die zu viel ist";
- "Onion" ist die reinste Architektur der Transaction Script-Philosophie.
- Testen als Möglichkeit, mit Entwicklerängsten umzugehen.
Aber zuerst erinnern wir uns an die Hauptprinzipien, an die wir uns als Entwickler immer erinnern müssen.
Grundsatz der alleinigen Verantwortung

Mit anderen Worten: Quantität gegen Qualität. Je mehr Funktionen Ihre Klasse enthält, desto schlechter wird sie in der Regel im qualitativen Sinne. Bei der Entwicklung großer Klassen wird der Programmierer verwirrt, macht Fehler beim Erstellen von Abhängigkeiten, und großer Code ist unter anderem schwieriger zu debuggen. Es ist besser, eine solche Klasse in mehrere kleinere zu unterteilen, von denen jede für eine Teilaufgabe verantwortlich ist. Besser ein paar eng gekoppelte Module als eines - groß und langsam. Die Modularität ermöglicht auch die Wiederverwendung von Logik.
Schwache Modulbindung

Der Bindungsgrad ist ein Maß dafür, wie eng Ihre Module miteinander interagieren. Es zeigt, wie weit sich die Auswirkungen der Änderungen, die Sie an einem bestimmten Punkt im System vornehmen, ausbreiten können. Je höher die Bindung, desto schwieriger ist es, Änderungen vorzunehmen: Sie ändern etwas in einem Modul, und der Effekt erstreckt sich weit und nicht immer in der erwarteten Weise. Daher sollte der Bindungsindikator so niedrig wie möglich sein - dies bietet mehr Kontrolle über das System, das geändert wird.
Nicht wiederholen

Ihre eigenen Implementierungen mögen heute gut sein, aber morgen nicht so gut. Erlauben Sie sich nicht, Ihre eigenen Best Practices zu kopieren und sie daher in einer Codebasis zu verteilen. Sie können aus StackOverflow oder aus Büchern kopieren - aus allen maßgeblichen Quellen, die (wie Sie sicher wissen) eine ideale (oder ähnliche) Implementierung bieten. Die Verbesserung Ihrer eigenen Implementierung, die mehrmals vorkommt, aber in der gesamten Codebasis multipliziert wird, kann sehr anstrengend sein.
Einfachheit und Prägnanz

Meiner Meinung nach ist dies das Hauptprinzip, das bei der Entwicklung und Softwareentwicklung beachtet werden muss. "Vorzeitige Einkapselung ist die Wurzel des Bösen", sagte Adam Bien. Mit anderen Worten, die Wurzel des Bösen liegt in der „Umgestaltung“. Der Autor des Zitats, Adam Bien, war einmal damit beschäftigt, Legacy-Anwendungen anzunehmen, und erhielt beim vollständigen Umschreiben des Codes eine 2-3-mal kleinere Codebasis als die ursprüngliche. Woher kommt so viel zusätzlicher Code? Immerhin entsteht es aus einem Grund. Seine Ängste lassen uns entstehen. Es scheint uns, dass wir durch das Anhäufen einer großen Anzahl von Mustern, das Erzeugen von Indirektheit und Abstraktionen unseren Code schützen - Schutz vor den Unbekannten von morgen und den Anforderungen von morgen. Tatsächlich brauchen wir heute nichts davon, wir erfinden dies alles nur um einiger „zukünftiger Bedürfnisse“ willen. Und es ist möglich, dass diese Datenstrukturen später stören. Um ehrlich zu sein, wenn einige meiner Entwickler auf mich zukommen und sagen, dass er etwas Interessantes gefunden hat, das dem Produktionscode hinzugefügt werden kann, antworte ich immer auf die gleiche Weise: "Junge, das wird für Sie nicht nützlich sein."
Es sollte nicht viel Code geben, und der, der einfach ist, sollte einfach sein - die einzige Möglichkeit, normal damit zu arbeiten. Dies ist ein Anliegen für Ihre Entwickler. Sie müssen sich daran erinnern, dass dies die Kennzahlen für Ihr System sind. Versuchen Sie, ihren Energieverbrauch zu senken, um die Risiken zu verringern, mit denen sie arbeiten müssen. Dies bedeutet nicht, dass Sie Ihr eigenes Framework erstellen müssen. Außerdem würde ich Ihnen nicht raten, dies zu tun: Es wird immer Fehler in Ihrem Framework geben, jeder muss es studieren usw. Es ist besser, vorhandene Vermögenswerte zu nutzen, von denen es heute eine Masse gibt. Dies sollten einfache Lösungen sein. Schreiben Sie globale Fehlerbehandlungsroutinen auf, wenden Sie Aspekttechnologie, Codegeneratoren, Spring- oder CDI-Erweiterungen an, konfigurieren Sie Anforderungs- / Thread-Bereiche, verwenden Sie die Bytecode-Manipulation und -Erstellung im laufenden Betrieb usw. All dies ist Ihr Beitrag zum wirklich Wichtigsten - dem Komfort Ihres Entwicklers.
Insbesondere möchte ich Ihnen die Anwendung der Request / Thread-Bereiche demonstrieren. Ich habe wiederholt beobachtet, wie dieses Ding Unternehmensanwendungen unglaublich vereinfacht. Unter dem Strich haben Sie als angemeldeter Benutzer die Möglichkeit, RequestContext-Daten zu speichern. Somit speichert RequestContext Benutzerdaten in kompakter Form.

Wie Sie sehen können, benötigt die Implementierung nur ein paar Codezeilen. Nachdem Sie die Anforderung in der erforderlichen Anmerkung geschrieben haben (es ist nicht schwierig, dies zu tun, wenn Sie Spring oder CDI verwenden), müssen Sie die Benutzeranmeldung nicht mehr an die Methoden und was auch immer übergeben: Die im Kontext gespeicherten Anforderungsmetadaten navigieren transparent durch die Anwendung. Mit dem Proxy mit Gültigkeitsbereich können Sie jederzeit auf die Metadaten der aktuellen Anforderung zugreifen.
Regressionstests

Entwickler haben Angst vor aktualisierten Anforderungen, weil sie Angst vor Refactoring-Verfahren (Code-Änderungen) haben. Der einfachste Weg, ihnen zu helfen, besteht darin, eine zuverlässige Testsuite für Regressionstests zu erstellen. Damit hat der Entwickler jederzeit die Möglichkeit, seine Betriebszeit zu testen - um sicherzustellen, dass das System nicht beschädigt wird.
Der Entwickler sollte keine Angst haben, etwas zu zerbrechen. Sie müssen alles tun, damit Refactoring als etwas Gutes wahrgenommen wird.
Refactoring ist ein kritischer Aspekt der Entwicklung. Denken Sie daran, dass die Anwendung genau in dem Moment, in dem Ihre Entwickler Angst vor Refactoring haben, als Legacy angesehen werden kann.
Wo soll die Geschäftslogik implementiert werden?
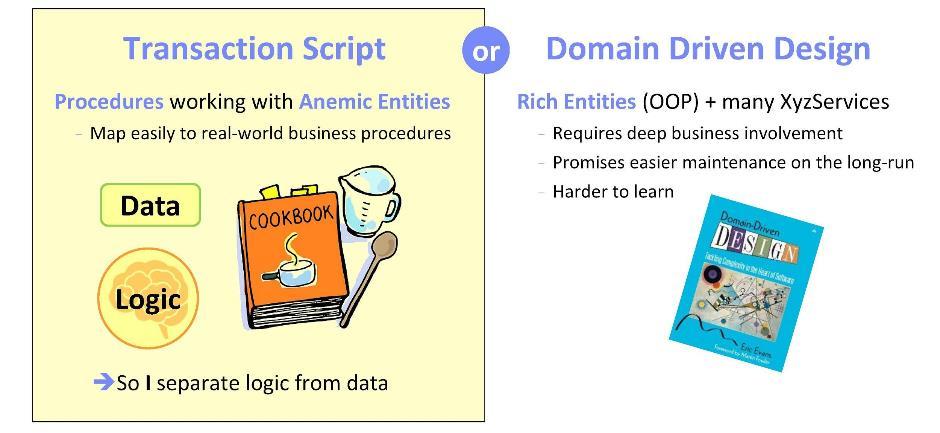
Wenn wir mit der Implementierung eines Systems (oder von Systemkomponenten) beginnen, stellen wir uns die Frage: Wo ist es besser, die Domänenlogik zu implementieren, dh die funktionalen Aspekte unserer Anwendung? Es gibt zwei gegensätzliche Ansätze.
Die erste basiert auf der
Transaktionsskript- Philosophie. Hier wird Logik in Prozeduren implementiert, die mit
anämischen Entitäten (
dh mit Datenstrukturen) arbeiten. Ein solcher Ansatz ist gut, da man sich bei seiner Umsetzung auf die formulierten Geschäftsaufgaben verlassen kann. Bei der Arbeit an Anwendungen für den Bankensektor habe ich wiederholt die Übertragung von Geschäftsabläufen auf Software beobachtet. Ich kann sagen, dass es wirklich sehr natürlich ist, Szenarien mit Software zu korrelieren.
Ein alternativer Ansatz besteht darin, die Prinzipien des
domänengesteuerten Designs zu verwenden . Hier müssen Sie Spezifikationen und Anforderungen mit einer objektorientierten Methodik korrelieren. Es ist wichtig, die Objekte sorgfältig zu prüfen und eine gute Geschäftsbeteiligung sicherzustellen. Das Plus der auf diese Weise entworfenen Systeme ist, dass sie in Zukunft leicht gewartet werden können. Nach meiner Erfahrung ist es jedoch ziemlich schwierig, diese Methode zu beherrschen: Sie werden sich frühestens nach sechs Monaten des Studiums mehr oder weniger mutig fühlen.
Für meine Entwicklungen habe ich immer den ersten Ansatz gewählt. Ich kann Ihnen versichern, dass es in meinem Fall perfekt funktioniert hat.
Datenmodellierung
Entitäten
Wie modellieren wir die Daten? Sobald die Anwendung mehr oder weniger anständige Größen annimmt, werden notwendigerweise
persistente Daten angezeigt. Dies ist die Art von Daten, die Sie länger als die anderen speichern müssen - es sind die
Domänenentitäten Ihres Systems. Wo sie gespeichert werden - ob in der Datenbank, in einer Datei oder direkt im Speicher - spielt keine Rolle. Wichtig ist,
wie Sie sie speichern - in welchen Datenstrukturen.

Diese Wahl haben Sie als Entwickler und es hängt nur von Ihnen ab, ob diese Datenstrukturen für Sie oder gegen Sie funktionieren, wenn Sie in Zukunft funktionale Anforderungen implementieren. Damit alles gut ist, müssen Sie Entitäten implementieren, indem Sie Körner
wiederverwendeter Domänenlogik in sie legen. Wie konkret? Ich werde anhand eines Beispiels verschiedene Methoden demonstrieren.

Mal sehen, was ich der Kundenentität zur Verfügung gestellt habe. Zuerst habe ich einen
synthetischen getFullName() Getter implementiert, der mir die Verkettung von Vorname und Nachname zurückgibt. Ich habe auch die Methode
activate() implementiert, um den Status meiner Entität zu überwachen und ihn so zu kapseln. Bei dieser Methode habe ich erstens eine
Validierungsoperation platziert und zweitens
den Feldern status und
enabledBy Werte zugewiesen , sodass keine Setter für sie erforderlich sind. Ich habe der Kundenentität auch die
isActive() und
canPlaceOrders() , die die Lambda-Validierung in mir implementieren. Dies wird als Prädikatenkapselung bezeichnet. Solche Prädikate sind nützlich, wenn Sie Java 8-Filter verwenden: Sie können sie als Argumente an Filter übergeben. Ich rate Ihnen, diese Helfer zu verwenden.
Vielleicht verwenden Sie eine Art ORM wie Hibernate. Angenommen, Sie haben zwei Entitäten mit bidirektionaler Kommunikation. Die Initialisierung muss auf beiden Seiten durchgeführt werden, da Sie sonst, wie Sie verstehen, in Zukunft Probleme beim Zugriff auf diese Daten haben werden. Entwickler vergessen jedoch häufig, ein Objekt von einer der Parteien zu initialisieren. Bei der Entwicklung dieser Entitäten können Sie spezielle Methoden bereitstellen, die eine bidirektionale Initialisierung gewährleisten. Schauen Sie sich
addAddress() .

Wie Sie sehen können, ist dies eine sehr gewöhnliche Einheit. Aber darin liegt die Domänenlogik. Solche Entitäten sollten nicht dürftig und oberflächlich sein, sondern nicht mit Logik überfordert sein. Ein Überlauf mit Logik tritt häufiger auf: Wenn Sie sich entscheiden, die gesamte Logik in der Domäne zu implementieren, ist es für jeden Anwendungsfall verlockend, eine bestimmte Methode zu implementieren. In der Regel gibt es viele Anwendungsfälle. Sie erhalten keine Entität, sondern einen großen Stapel aller Arten von Logik. Versuchen Sie hier das Maß zu beachten: Nur
wiederverwendete Logik wird in die Domäne gestellt und nur
in geringer Menge.
Wertobjekte
Neben Entitäten benötigen Sie höchstwahrscheinlich auch Objektwerte. Dies ist nichts anderes als eine Möglichkeit, Domänendaten zu gruppieren, damit Sie sie später gemeinsam im System verschieben können.
Das Wertobjekt muss sein:
- Klein . Kein
float für monetäre Variablen! Seien Sie vorsichtig bei der Auswahl der Datentypen. Je kompakter Ihr Objekt ist, desto einfacher ist es für einen neuen Entwickler, es herauszufinden. Dies ist die Basis für ein angenehmes Leben.
- Unveränderlich . Wenn das Objekt wirklich unveränderlich ist, kann der Entwickler ruhig sein, dass Ihr Objekt seinen Wert nicht ändert und nach der Erstellung nicht beschädigt wird. Dies legt den Grundstein für eine ruhige und selbstbewusste Arbeit.

Wenn Sie dem Konstruktor einen
validate() -Methodenaufruf hinzufügen, kann sich der Entwickler auf die Gültigkeit der erstellten Entität beruhigen (wenn beispielsweise eine nicht vorhandene Währung oder ein negativer Geldbetrag übergeben wird, funktioniert der Konstruktor nicht).
Der Unterschied zwischen einer Entität und einem Wertobjekt
Wertobjekte unterscheiden sich von Entitäten darin, dass sie keine feste ID haben. Entitäten haben immer Felder, die dem Fremdschlüssel einer Tabelle (oder eines anderen Speichers) zugeordnet sind. Wertobjekte haben solche Felder nicht. Es stellt sich die Frage: Sind die Verfahren zur Überprüfung der Gleichheit von zwei Wertobjekten und zwei Entitäten unterschiedlich? Da Wertobjekte kein ID-Feld haben, müssen Sie die Werte aller ihrer Felder paarweise vergleichen (dh den gesamten Inhalt untersuchen), um zu dem Schluss zu kommen, dass zwei solche Objekte gleich sind. Beim Vergleichen von Entitäten reicht es aus, einen einzigen Vergleich durchzuführen - nach Feld-ID. Im Vergleichsverfahren liegt der Hauptunterschied zwischen Entitäten und Wertobjekten.
Datenübertragungsobjekte (DTOs)

Wie ist die Interaktion mit der Benutzeroberfläche? Sie müssen die
Daten zur Anzeige an ihn weitergeben . Benötigen Sie wirklich eine andere Struktur? So ist es. Und das alles, weil die Benutzeroberfläche überhaupt nicht dein Freund ist. Er hat seine eigenen Anforderungen: Er muss die Daten so speichern, wie sie angezeigt werden sollen. Das ist so wunderbar - dass es manchmal die Benutzeroberflächen und ihre Entwickler sind, die uns benötigen. Dann müssen sie Daten für fünf Zeilen abrufen. Dann denken sie daran, ein
isDeletable Boolean-Feld für das Objekt zu erstellen (kann das Objekt im Prinzip ein solches Feld haben?), um zu wissen, ob die Schaltfläche Löschen aktiv ist oder nicht. Aber es gibt nichts zu empören. Benutzeroberflächen haben einfach unterschiedliche Anforderungen.
Die Frage ist, können unsere Entitäten ihnen zur Verwendung anvertraut werden? Höchstwahrscheinlich werden sie sie ändern, und zwar auf die für uns unerwünschteste Weise. Deshalb werden wir ihnen noch etwas anderes zur Verfügung stellen -
Data Transfer Objects (DTO). Sie werden speziell an externe Anforderungen und an eine andere Logik als unsere angepasst. Einige Beispiele für DTO-Strukturen sind: Formular / Anforderung (von der Benutzeroberfläche), Ansicht / Antwort (an die Benutzeroberfläche gesendet), SearchCriteria / SearchResult usw. Sie können dies gewissermaßen als API-Modell bezeichnen.
Erstes wichtiges Prinzip: DTO sollte ein Minimum an Logik enthalten.
Hier ist eine Beispielimplementierung von
CustomerDto .
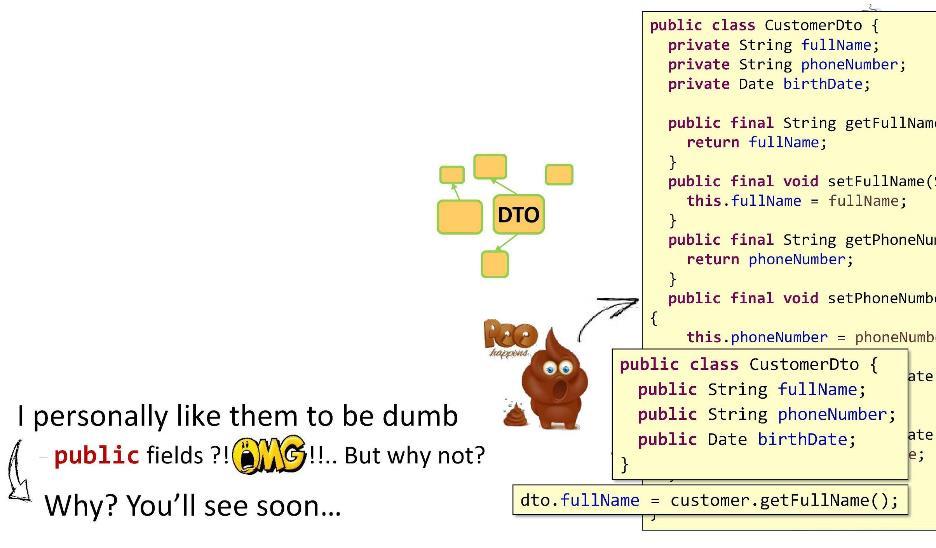
Inhalt:
private Felder,
öffentliche Getter und Setter für sie. Alles scheint super zu sein. OOP in seiner ganzen Pracht. Eines ist jedoch schlecht: In Form von Gettern und Setzern habe ich zu viele Methoden implementiert. In DTO sollte es so wenig Logik wie möglich geben. Und was ist dann mein Ausweg? Ich mache die Felder öffentlich! Sie werden sagen, dass dies mit Methodenreferenzen aus Java 8 schlecht funktioniert, dass es Einschränkungen gibt usw. Aber ob Sie es glauben oder nicht, ich habe alle meine Projekte (10-11 Teile) mit solchen DTOs durchgeführt. Bruder lebt. Da meine Felder nun öffentlich sind, kann ich den Wert einfach auf
dto.fullName indem
dto.fullName einfach ein Gleichheitszeichen
dto.fullName . Was könnte schöner und einfacher sein?
Logikorganisation
Zuordnung
Wir haben also eine Aufgabe: Wir müssen unsere Entitäten in DTO umwandeln. Wir implementieren die Transformation wie folgt:
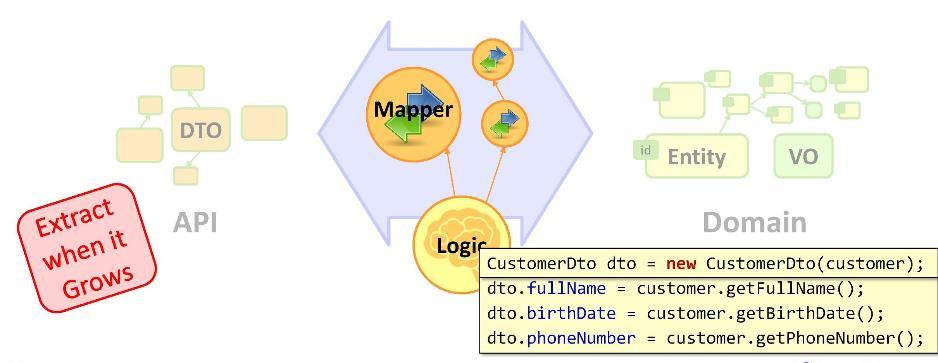
Wie Sie sehen können, fahren wir mit der Deklaration eines DTO mit Mapping-Operationen (Wertzuweisung) fort. Muss ich ein leitender Entwickler sein, um regelmäßige Aufgaben in solchen Zahlen zu schreiben? Für einige ist dies so ungewöhnlich, dass sie unterwegs beginnen, ihre Schuhe zu wechseln: Kopieren Sie beispielsweise Daten mithilfe eines Mapping-Frameworks mithilfe von Reflection. Aber sie vermissen die Hauptsache - dass die Benutzeroberfläche früher oder später mit dem DTO interagiert, wodurch die Entität und das DTO in ihren Bedeutungen voneinander abweichen.
Man könnte beispielsweise Mapping-Operationen in den Konstruktor einfügen. Dies ist jedoch für keine Zuordnung möglich. Insbesondere kann der Designer nicht auf die Datenbank zugreifen.
Daher sind wir gezwungen, Mapping-Operationen in der Geschäftslogik zu belassen. Und wenn sie ein kompaktes Erscheinungsbild haben, gibt es keinen Grund zur Sorge. Wenn das Mapping nicht ein paar Zeilen, sondern mehr umfasst, ist es besser, es im sogenannten
Mapper zu platzieren . Ein Mapper ist eine Klasse, die speziell zum Kopieren von Daten entwickelt wurde. Dies ist im Allgemeinen eine antidiluvianische Sache und eine Kesselplatte. Aber hinter ihnen können Sie unsere vielen Aufgaben verstecken - um den Code sauberer und schlanker zu machen.
Denken Sie daran: Ein
zu großer Code muss in eine separate Struktur verschoben werden . In unserem Fall waren die Mapping-Operationen wirklich ein bisschen viel, also haben wir sie in eine separate Klasse verschoben - den Mapper.
Ermöglichen Mapper den Datenbankzugriff? Sie können es standardmäßig aktivieren - dies geschieht häufig aus Gründen der Einfachheit und des Pragmatismus. Aber es setzt Sie bestimmten Risiken aus.
Ich werde mit einem Beispiel veranschaulichen. Basierend auf dem vorhandenen DTO erstellen wir die
Customer .
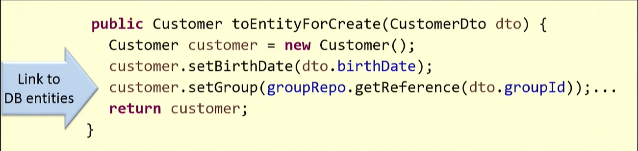
Für die Zuordnung benötigen wir einen Link zur Kundengruppe aus der Datenbank. Also
getReference() ich die Methode
getReference() und sie gibt mir eine Entität zurück. Die Anforderung wird höchstwahrscheinlich an die Datenbank gesendet (in einigen Fällen geschieht dies nicht und die Stub-Funktion funktioniert).
Aber das Problem erwartet uns nicht hier, sondern in der Methode, die die inverse Operation ausführt - die Umwandlung der Entität in DTO.

Mit einer Schleife gehen wir alle mit dem bestehenden Kunden verknüpften Adressen durch und übersetzen sie in DTO-Adressen. Wenn Sie ORM verwenden, wird wahrscheinlich beim Aufrufen der Methode
getAddresses() verzögertes Laden durchgeführt. Wenn Sie ORM nicht verwenden, ist dies eine offene Anfrage an alle Kinder dieses Elternteils. Und hier laufen Sie Gefahr, in das "N + 1-Problem" zu geraten. Warum?
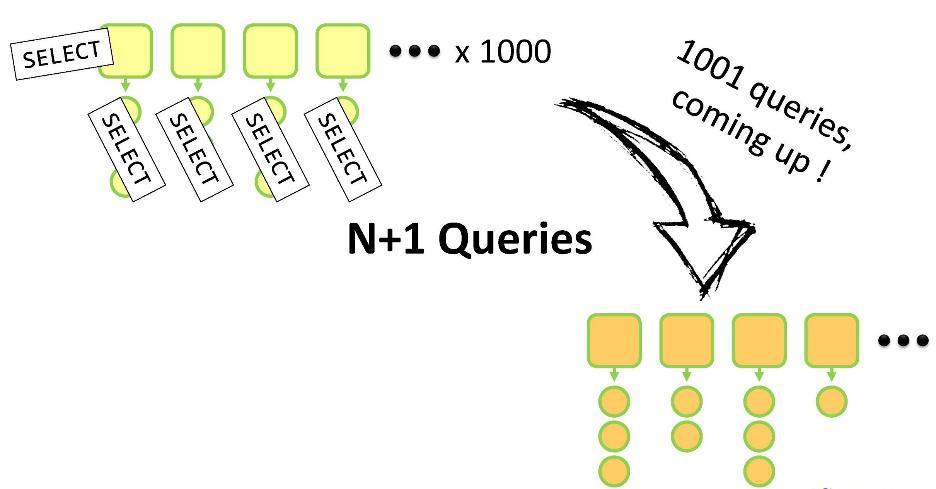
Sie haben eine Reihe von Eltern, von denen jeder Kinder hat. Für all dies müssen Sie Ihre eigenen Analoga innerhalb des DTO erstellen. Sie müssen eine
SELECT Abfrage ausführen, um N übergeordnete Entitäten zu durchlaufen, und dann N
SELECT Abfragen, um die
SELECT Entitäten der einzelnen Entitäten zu
SELECT . Insgesamt N + 1 Anfrage. Für 1000 übergeordnete
Customer dauert ein solcher Vorgang 5 bis 10 Sekunden, was natürlich lange dauert.
Angenommen, unsere
CustomerDto() -Methode wird dennoch innerhalb der Schleife aufgerufen und konvertiert die Liste der Kundenobjekte in die CustomerDto-Liste.
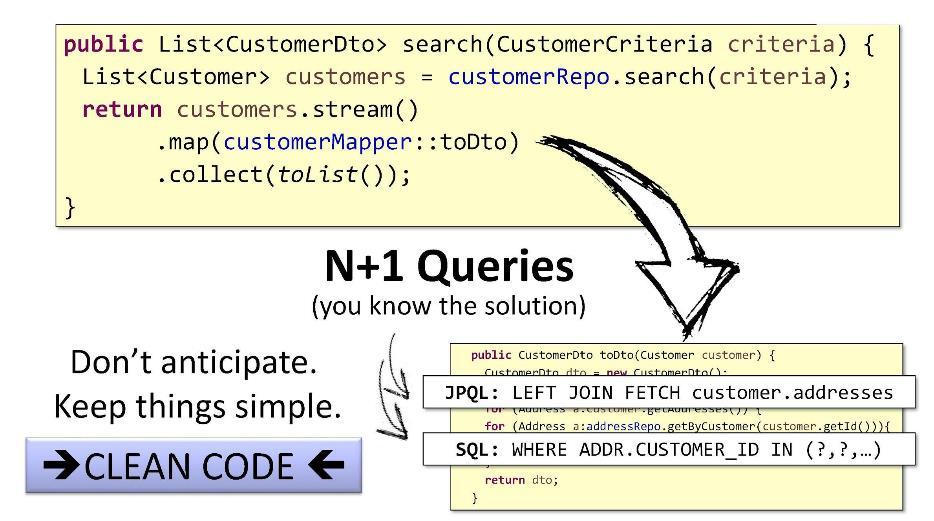
Das Problem mit N + 1-Abfragen hat einfache Standardlösungen: In
JPQL können Sie
FETCH by customer.addresses verwenden, um
FETCH abzurufen und sie dann mit
JOIN verbinden. In SQL können Sie die
IN Umgehung und die
WHERE .
Aber ich würde es anders machen. Sie können herausfinden, wie lang die Liste der Kinder maximal ist (dies kann beispielsweise anhand einer Suche mit Paginierung erfolgen). Wenn die Liste nur 15 Entitäten enthält, benötigen wir nur 16 Abfragen. Anstelle von 5 ms werden wir für alles ausgeben, zum Beispiel 15 ms - der Benutzer wird den Unterschied nicht bemerken.
Über Optimierung
Ich würde Ihnen nicht raten, in der Anfangsphase der Entwicklung auf die Systemleistung zurückzublicken. Wie Donald Knud sagte: "Vorzeitige Optimierung ist die Wurzel des Bösen." Sie können nicht von Anfang an optimieren. Genau das muss für später übrig bleiben. Und was besonders wichtig ist:
keine Annahmen - nur Messungen und Auswertung von Messungen!Sind Sie sicher, dass Sie kompetent sind, ein echter Experte zu sein? Sei demütig, wenn du dich selbst bewertest. Denken Sie nicht, dass Sie die JVM verstehen, bis Sie mindestens ein paar Bücher über die JIT-Kompilierung gelesen haben. Es kommt vor, dass die besten Programmierer aus unserem Team auf mich zukommen und sagen, dass
sie glauben , eine effizientere Implementierung gefunden zu haben. Es stellt sich heraus, dass sie wieder etwas erfunden haben, das den Code nur kompliziert. Also antworte ich immer wieder: YAGNI. Wir brauchen es nicht.
Für Unternehmensanwendungen ist häufig überhaupt keine Optimierung der Algorithmen erforderlich. Der Engpass für sie ist in der Regel nicht die Kompilierung und nicht für den Prozessor, sondern alle Arten von Eingabe-Ausgabe-Operationen. Beispiel: Lesen einer Million Zeilen aus einer Datenbank, umfangreiches Schreiben in eine Datei und Interaktion mit Sockets.
Mit der Zeit beginnen Sie zu verstehen, welche Engpässe das System enthält, und wenn Sie alles durch Messungen verstärken, werden Sie allmählich mit der Optimierung beginnen. Halten Sie den Code vorerst so sauber wie möglich. Sie werden feststellen, dass ein solcher Code viel einfacher weiter zu optimieren ist.
Ziehen Sie die Komposition der Vererbung vor
Zurück zu unserem DTO. Angenommen, wir definieren ein DTO wie folgt:

Möglicherweise benötigen wir es in vielen Workflows. Diese Abläufe sind jedoch unterschiedlich, und höchstwahrscheinlich wird jeder Anwendungsfall einen anderen Grad der Feldfüllung annehmen. Zum Beispiel müssen wir natürlich ein DTO früher erstellen, als wenn wir vollständige Benutzerinformationen haben. Sie können die Felder vorübergehend leer lassen. Je mehr Felder Sie ignorieren, desto mehr möchten Sie ein neues, strengeres DTO für diesen Anwendungsfall erstellen.
Alternativ können Sie Kopien eines übermäßig großen DTO (in der Anzahl der verfügbaren Anwendungsfälle) erstellen und dann für jede Kopie zusätzliche Felder daraus entfernen. Aber für viele Programmierer tut es aufgrund ihrer Intelligenz und Alphabetisierung wirklich weh, Strg + V zu drücken. Das Axiom besagt, dass Copy-Paste schlecht ist.
Sie können auf das in der OOP-Theorie bekannte
Vererbungsprinzip zurückgreifen: Definieren Sie einfach ein grundlegendes DTO und erstellen Sie für jeden Anwendungsfall einen Erben.
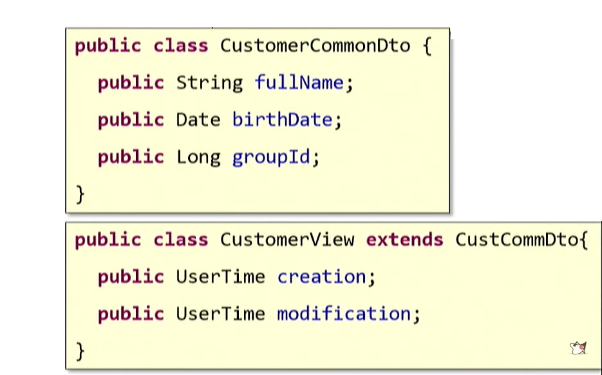
Ein bekanntes Prinzip lautet: „Bevorzugen Sie die Komposition gegenüber der Vererbung.“ Lesen Sie, was darin steht:
"erweitert" . Es scheint, dass wir die Quellklasse „erweitert“ haben sollten. Aber wenn Sie darüber nachdenken, dann haben wir überhaupt keine „Erweiterung“ getan. Dies ist die eigentliche „Wiederholung“ - dieselbe Seitenansicht zum Kopieren und Einfügen. Daher werden wir keine Vererbung verwenden.
Aber was sollen wir dann sein? Wie gehe ich zur Komposition? Gehen wir folgendermaßen vor: Schreiben Sie in CustomerView ein Feld, das auf das Objekt des zugrunde liegenden DTO verweist.
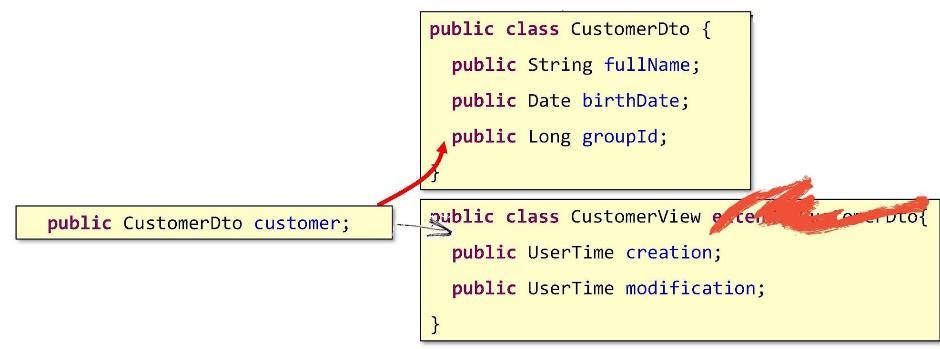
Somit wird unsere Basisstruktur im Inneren verschachtelt. So kommt die eigentliche Komposition heraus.
Ob wir die Vererbung verwenden oder das Problem durch Komposition lösen - all dies sind Einzelheiten, Feinheiten, die im Verlauf unserer Implementierung tiefgreifend entstanden sind. Sie sind sehr
zerbrechlich . Was bedeutet zerbrechlich? Schauen Sie sich diesen Code genau an:

Die meisten Entwickler, denen ich dies gezeigt habe, platzten sofort heraus, dass die Zahl "2" wiederholt wird, daher muss sie als Konstante herausgenommen werden. Sie bemerkten nicht, dass die Zwei in allen drei Fällen eine völlig andere Bedeutung (oder einen „Geschäftswert“) hat und dass ihre Wiederholung nichts anderes als ein Zufall ist. Eine Zwei in eine Konstante zu ziehen ist eine legitime Entscheidung, aber sehr fragil. Versuchen Sie, keine fragile Logik in die Domäne zuzulassen. Arbeiten Sie niemals mit externen Datenstrukturen, insbesondere mit DTO.
Warum ist die Arbeit, die Vererbung zu beseitigen und die Komposition einzuführen, nutzlos? Gerade weil wir DTO nicht für uns selbst, sondern für einen externen Kunden erstellen. Und wie die Client-Anwendung das von Ihnen erhaltene DTO analysiert, können Sie nur erraten. Dies hat jedoch offensichtlich wenig mit Ihrer Implementierung zu tun. Entwickler hingegen unterscheiden möglicherweise nicht zwischen den grundlegenden und nicht grundlegenden DTOs, die Sie sorgfältig durchdacht haben. Sie verwenden wahrscheinlich Vererbung und vielleicht dumm das Kopieren und Einfügen, das ist alles.
Fassaden

Kehren wir zum Gesamtbild der Anwendung zurück. Ich würde Ihnen raten, die Domänenlogik über das
Fassadenmuster zu implementieren und die
Fassaden nach Bedarf mit
Domänendiensten zu erweitern. Ein Domänendienst wird erstellt, wenn sich zu viel Logik in der Fassade ansammelt, und es ist bequemer, ihn einer separaten Klasse zuzuordnen.
Ihre Domain-Services müssen unbedingt die Sprache Ihres Domain-Modells (seine Entitäten und Wertobjekte) sprechen. In keinem Fall sollten sie mit DTO zusammenarbeiten, da DTO, wie Sie sich erinnern, Strukturen sind, die sich auf der Clientseite ständig ändern und für eine Domain zu zerbrechlich sind.
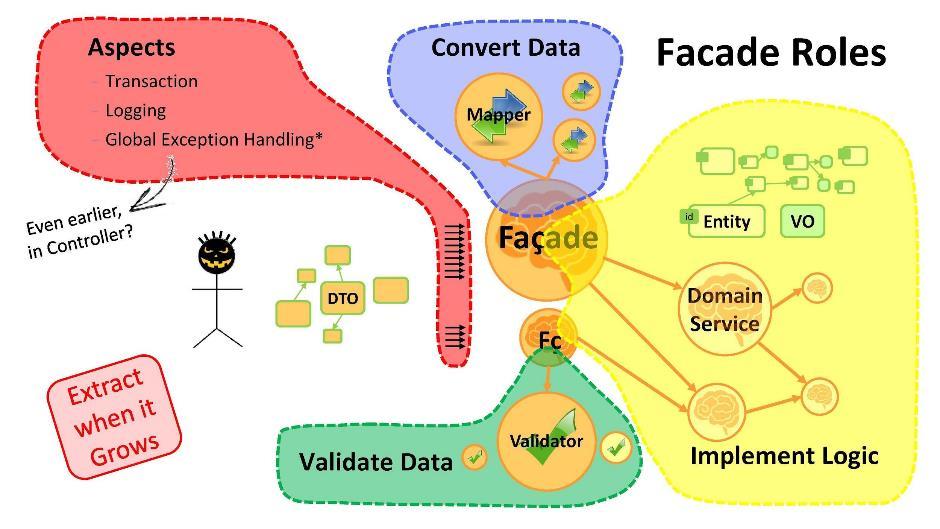
Was ist der Zweck der Fassade?
- Datenkonvertierung. Wenn wir Entitäten von einem Ende und DTO vom anderen haben, ist es notwendig, Transformationen von einem zum anderen durchzuführen. Und das ist das erste, wofür Fassaden sind. Wenn das Konvertierungsverfahren an Volumen zugenommen hat, verwenden Sie die Mapper-Klassen.
- Die Implementierung von Logik. In der Fassade beginnen Sie, die Hauptlogik der Anwendung zu schreiben. Sobald es viel wird - nehmen Sie Teile zum Domain-Service.
- Datenvalidierung. Denken Sie daran, dass alle vom Benutzer empfangenen Daten per Definition falsch sind (Fehler enthalten). Die Fassade kann Daten validieren. Diese Verfahren werden normalerweise zu den Validatoren gebracht , wenn das Volumen überschritten wird.
- Aspekte Sie können weiter gehen und jeden Anwendungsfall durch seine Fassade führen. Dann werden sich Dinge wie Transaktionen, Protokollierung und globale Ausnahmehandler zu Fassadenmethoden hinzufügen. Ich stelle fest, dass es sehr wichtig ist, globale Ausnahmehandler in jeder Anwendung zu haben, die alle Fehler abfangen, die nicht von anderen Handlern abgefangen wurden. Sie werden Ihren Programmierern sehr helfen - sie geben ihnen Ruhe und Handlungsfreiheit.
Zerlegung von viel Code
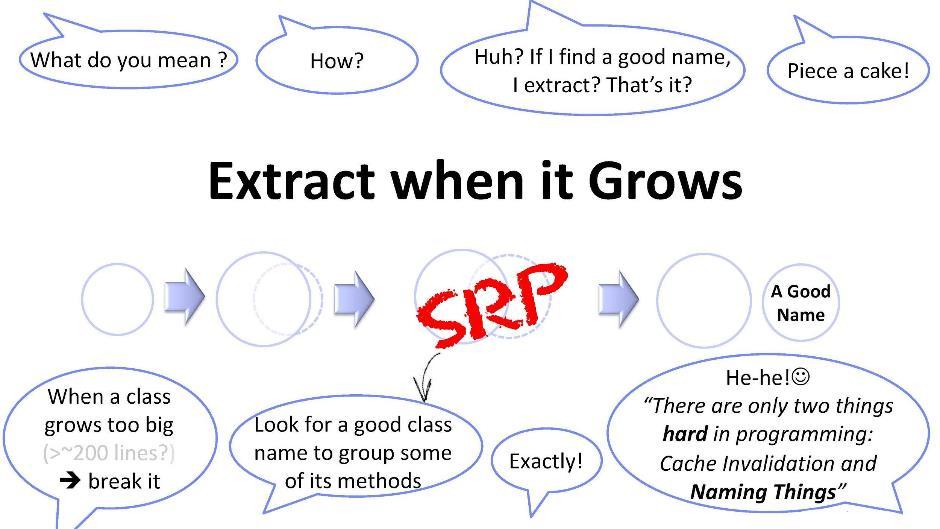
Noch ein paar Worte zu diesem Prinzip. Wenn die Klasse eine für mich unangenehme Größe erreicht hat (z. B. 200 Zeilen), sollte ich versuchen, sie in Stücke zu zerbrechen. Es ist jedoch nicht immer einfach, eine neue Klasse von einer vorhandenen zu isolieren. Wir müssen einige universelle Wege finden. Eine dieser Methoden ist die Suche nach Namen: Sie versuchen, einen Namen für eine Teilmenge der Methoden Ihrer Klasse zu finden. Sobald Sie einen Namen gefunden haben, können Sie eine neue Klasse erstellen. Das ist aber nicht so einfach. Wie Sie wissen, gibt es beim Programmieren nur zwei komplexe Dinge: Dies macht den Cache ungültig und erfindet Namen. In diesem Fall beinhaltet das Erfinden eines Namens das Identifizieren einer Unteraufgabe, die sich versteckt und daher zuvor von niemandem identifiziert wurde.
Ein Beispiel:
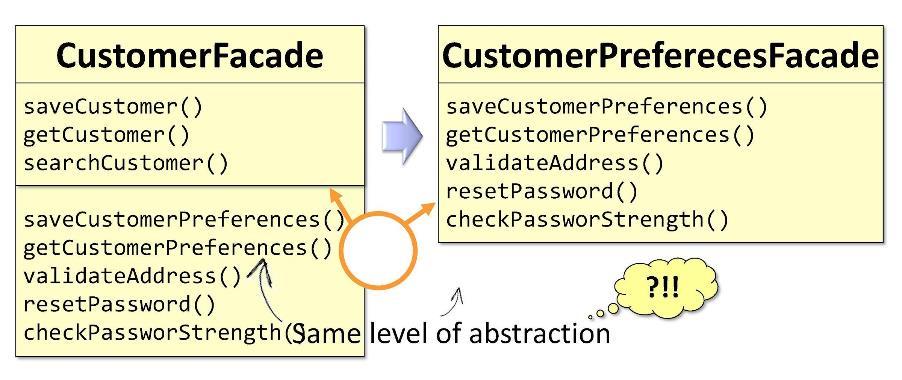
In der ursprünglichen Fassade von
CustomerFacade beziehen sich einige der Methoden direkt auf den Kunden, andere auf die Kundenpräferenzen. Auf dieser Grundlage kann ich die Klasse in zwei Teile aufteilen, wenn sie kritische Größen erreicht. Ich bekomme zwei Fassaden:
CustomerFacade und
CustomerPreferencesFacade . Das einzig schlechte ist, dass beide Fassaden zur gleichen Abstraktionsebene gehören. Die Trennung nach Abstraktionsebenen impliziert etwas anderes.
Ein weiteres Beispiel:

Angenommen, es gibt eine
OrderService Klasse in unserem System, in der wir einen E-Mail-Benachrichtigungsmechanismus implementiert haben. Jetzt erstellen wir einen
DeliveryService und möchten hier denselben Benachrichtigungsmechanismus verwenden. Kopieren-Einfügen ist ausgeschlossen. Gehen wir folgendermaßen vor: Extrahieren Sie die Benachrichtigungsfunktionalität in die neue
AlertService Klasse und schreiben Sie sie als Abhängigkeit für die
OrderService DeliveryService und
OrderService . Hier erfolgte die Trennung im Gegensatz zum vorherigen Beispiel genau auf den Abstraktionsebenen.
DeliveryServiceabstrakter als AlertService, weil es es als Teil seines Workflows verwendet.Bei der Trennung nach Abstraktionsebenen wird immer davon ausgegangen, dass die extrahierte Klasse zu einer Abhängigkeit wird , und die Extraktion wird zur Wiederverwendung durchgeführt .Die Extraktionsaufgabe ist nicht immer einfach. Dies kann auch einige Schwierigkeiten mit sich bringen und eine Umgestaltung der Komponententests erfordern. Nach meinen Beobachtungen ist es für Entwickler jedoch noch schwieriger, nach Funktionen in der riesigen monolithischen Codebasis der Anwendung zu suchen.Paarprogrammierung
 Viele Berater werden über die Paarprogrammierung sprechen, über die Tatsache, dass dies eine universelle Lösung für alle Probleme der heutigen IT-Entwicklung ist. Währenddessen entwickeln Programmierer ihre technischen Fähigkeiten und funktionalen Kenntnisse. Darüber hinaus ist der Prozess selbst interessant, er bringt das Team zusammen.Nicht als Berater, sondern menschlich gesehen ist das Wichtigste: Paarprogrammierung verbessert den „Busfaktor“. Das Wesentliche des „Busfaktors“ ist, dass möglichst viele Personen über die Systemstruktur informiert sein sollten . Diese Leute zu verlieren bedeutet, die letzten Hinweise auf dieses Wissen zu verlieren.Das Refactoring von Paarprogrammen ist eine Kunst, die Erfahrung und Schulung erfordert. Dies ist beispielsweise nützlich, um aggressives Refactoring durchzuführen, Hackathons, Schnitte durchzuführen, Dojos zu codieren usw. DiePaarprogrammierung funktioniert gut, wenn Sie Probleme mit hoher Komplexität lösen müssen. Der Prozess der Zusammenarbeit ist nicht immer einfach. Es garantiert Ihnen jedoch, dass Sie ein "Reengineering" vermeiden - im Gegenteil, Sie erhalten eine Implementierung, die die festgelegten Anforderungen mit minimaler Komplexität erfüllt.
Viele Berater werden über die Paarprogrammierung sprechen, über die Tatsache, dass dies eine universelle Lösung für alle Probleme der heutigen IT-Entwicklung ist. Währenddessen entwickeln Programmierer ihre technischen Fähigkeiten und funktionalen Kenntnisse. Darüber hinaus ist der Prozess selbst interessant, er bringt das Team zusammen.Nicht als Berater, sondern menschlich gesehen ist das Wichtigste: Paarprogrammierung verbessert den „Busfaktor“. Das Wesentliche des „Busfaktors“ ist, dass möglichst viele Personen über die Systemstruktur informiert sein sollten . Diese Leute zu verlieren bedeutet, die letzten Hinweise auf dieses Wissen zu verlieren.Das Refactoring von Paarprogrammen ist eine Kunst, die Erfahrung und Schulung erfordert. Dies ist beispielsweise nützlich, um aggressives Refactoring durchzuführen, Hackathons, Schnitte durchzuführen, Dojos zu codieren usw. DiePaarprogrammierung funktioniert gut, wenn Sie Probleme mit hoher Komplexität lösen müssen. Der Prozess der Zusammenarbeit ist nicht immer einfach. Es garantiert Ihnen jedoch, dass Sie ein "Reengineering" vermeiden - im Gegenteil, Sie erhalten eine Implementierung, die die festgelegten Anforderungen mit minimaler Komplexität erfüllt. Die Organisation eines praktischen Arbeitsformats ist eine Ihrer Hauptaufgaben gegenüber dem Team. Sie müssen sich ständig um die Arbeitsbedingungen des Entwicklers kümmern - ihm vollen Komfort und kreative Freiheit bieten, insbesondere wenn sie die Designarchitektur und ihre Komplexität erhöhen müssen.
Die Organisation eines praktischen Arbeitsformats ist eine Ihrer Hauptaufgaben gegenüber dem Team. Sie müssen sich ständig um die Arbeitsbedingungen des Entwicklers kümmern - ihm vollen Komfort und kreative Freiheit bieten, insbesondere wenn sie die Designarchitektur und ihre Komplexität erhöhen müssen.„Ich bin Architekt. Per Definition habe ich immer Recht. “
Diese Dummheit wird regelmäßig öffentlich oder hinter den Kulissen zum Ausdruck gebracht. In der heutigen Praxis finden sich Architekten als solche immer weniger. Mit dem Aufkommen von Agile ging diese Rolle allmählich auf leitende Entwickler über, da normalerweise die gesamte Arbeit auf die eine oder andere Weise um sie herum aufgebaut wird. Die Größe der Implementierung nimmt allmählich zu, und daher besteht Bedarf an Refactoring, und es werden neue Funktionen entwickelt.Zwiebelarchitektur
Zwiebel ist die reinste Transaktionsskript-Philosophie. Beim Aufbau orientieren wir uns am Ziel, den Code zu schützen, den wir für kritisch halten, und verschieben ihn dazu in das Domänenmodul. In unserer Anwendung sind Domänendienste am wichtigsten: Sie implementieren die kritischsten Abläufe. Verschieben Sie sie in das Domänenmodul. Natürlich lohnt es sich auch, alle Ihre Domänenobjekte hierher zu verschieben - Entitäten und Wertobjekte. Alles andere, was wir heute zusammengestellt haben - DTO, Mapper, Validatoren usw. - wird sozusagen zur ersten Verteidigungslinie des Benutzers. Weil der Benutzer leider nicht unser Freund ist und es notwendig ist, das System vor ihm zu schützen.Aufmerksamkeit für diese Abhängigkeit:
In unserer Anwendung sind Domänendienste am wichtigsten: Sie implementieren die kritischsten Abläufe. Verschieben Sie sie in das Domänenmodul. Natürlich lohnt es sich auch, alle Ihre Domänenobjekte hierher zu verschieben - Entitäten und Wertobjekte. Alles andere, was wir heute zusammengestellt haben - DTO, Mapper, Validatoren usw. - wird sozusagen zur ersten Verteidigungslinie des Benutzers. Weil der Benutzer leider nicht unser Freund ist und es notwendig ist, das System vor ihm zu schützen.Aufmerksamkeit für diese Abhängigkeit: Das Anwendungsmodul hängt vom Domänenmodul ab - also nicht umgekehrt. Durch die Registrierung einer solchen Verbindung garantieren wir, dass das DTO niemals in das heilige Gebiet des Domänenmoduls eindringt: Sie sind vom Domänenmodul aus einfach nicht sichtbar und nicht zugänglich. Es stellt sich heraus, dass wir in gewisser Weise das Domain-Territorium eingezäunt haben - wir haben den Zugang von Fremden darauf beschränkt.Möglicherweise muss die Domäne jedoch mit einem externen Dienst interagieren. Mit externen Mitteln unfreundlich, weil er mit seinem DTO ausgestattet ist. Welche Möglichkeiten haben wir?Erstens: Überspringen Sie den Feind im Modul.
Das Anwendungsmodul hängt vom Domänenmodul ab - also nicht umgekehrt. Durch die Registrierung einer solchen Verbindung garantieren wir, dass das DTO niemals in das heilige Gebiet des Domänenmoduls eindringt: Sie sind vom Domänenmodul aus einfach nicht sichtbar und nicht zugänglich. Es stellt sich heraus, dass wir in gewisser Weise das Domain-Territorium eingezäunt haben - wir haben den Zugang von Fremden darauf beschränkt.Möglicherweise muss die Domäne jedoch mit einem externen Dienst interagieren. Mit externen Mitteln unfreundlich, weil er mit seinem DTO ausgestattet ist. Welche Möglichkeiten haben wir?Erstens: Überspringen Sie den Feind im Modul.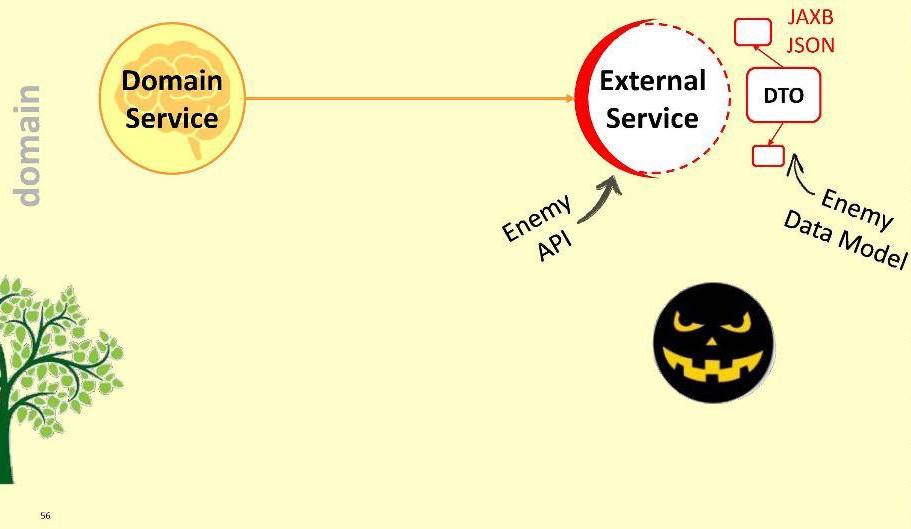 Dies ist natürlich eine schlechte Option: Es ist möglich, dass der externe Dienst morgen nicht auf Version 2.0 aktualisiert wird und wir unsere Domain neu zeichnen müssen. Lass den Feind nicht in die Domäne!Ich schlage einen anderen Ansatz vor: Wir werden einen speziellen Adapter für die Interaktion erstellen .
Dies ist natürlich eine schlechte Option: Es ist möglich, dass der externe Dienst morgen nicht auf Version 2.0 aktualisiert wird und wir unsere Domain neu zeichnen müssen. Lass den Feind nicht in die Domäne!Ich schlage einen anderen Ansatz vor: Wir werden einen speziellen Adapter für die Interaktion erstellen .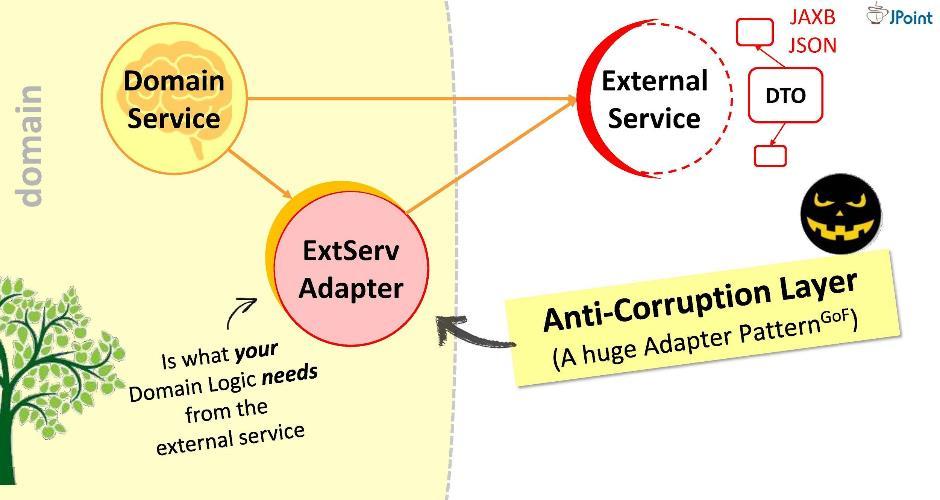 Der Adapter empfängt Daten von einem externen Dienst, extrahiert die Daten, die unsere Domäne benötigt, und konvertiert sie in die erforderlichen Arten von Strukturen. In diesem Fall müssen wir während der Entwicklung lediglich die Aufrufe des externen Systems mit den Anforderungen der Domäne korrelieren. Betrachten Sie es als einen riesigen Adapter wie diesen . Ich nenne diese Schicht "Korruptionsbekämpfung".Beispielsweise müssen wir möglicherweise LDAP-Abfragen von einer Domäne ausführen. Dazu implementieren wir das „Anti-Korruptions-Modul“
Der Adapter empfängt Daten von einem externen Dienst, extrahiert die Daten, die unsere Domäne benötigt, und konvertiert sie in die erforderlichen Arten von Strukturen. In diesem Fall müssen wir während der Entwicklung lediglich die Aufrufe des externen Systems mit den Anforderungen der Domäne korrelieren. Betrachten Sie es als einen riesigen Adapter wie diesen . Ich nenne diese Schicht "Korruptionsbekämpfung".Beispielsweise müssen wir möglicherweise LDAP-Abfragen von einer Domäne ausführen. Dazu implementieren wir das „Anti-Korruptions-Modul“ LDAPUserServiceAdapter. Im Adapter können wir:
Im Adapter können wir:- Hässliche API-Aufrufe ausblenden (in unserem Fall die Methode ausblenden, die das Object-Array verwendet);
- Pack Ausnahmen in unsere eigenen Implementierungen;
- Konvertieren Sie die Datenstrukturen anderer Personen in ihre eigenen (in unsere Domänenobjekte).
- Überprüfen Sie die Gültigkeit eingehender Daten.
Dies ist der Zweck des Adapters. Gut, an der Schnittstelle zu jedem externen System, mit dem Sie interagieren müssen, muss Ihr Adapter installiert sein. Daher leitet die Domäne den Anruf nicht an einen externen Dienst, sondern an den Adapter. Dazu muss die entsprechende Abhängigkeit in der Domäne registriert sein (vom Adapter oder vom Infrastrukturmodul, in dem sie sich befindet). Aber ist diese Sucht sicher? Wenn Sie es so installieren, kann ein externer Service-DTO in unsere Domain gelangen. Wir sollten das nicht zulassen. Daher schlage ich Ihnen eine andere Möglichkeit vor, Abhängigkeiten zu modellieren.
Daher leitet die Domäne den Anruf nicht an einen externen Dienst, sondern an den Adapter. Dazu muss die entsprechende Abhängigkeit in der Domäne registriert sein (vom Adapter oder vom Infrastrukturmodul, in dem sie sich befindet). Aber ist diese Sucht sicher? Wenn Sie es so installieren, kann ein externer Service-DTO in unsere Domain gelangen. Wir sollten das nicht zulassen. Daher schlage ich Ihnen eine andere Möglichkeit vor, Abhängigkeiten zu modellieren.Prinzip der Abhängigkeitsinversion
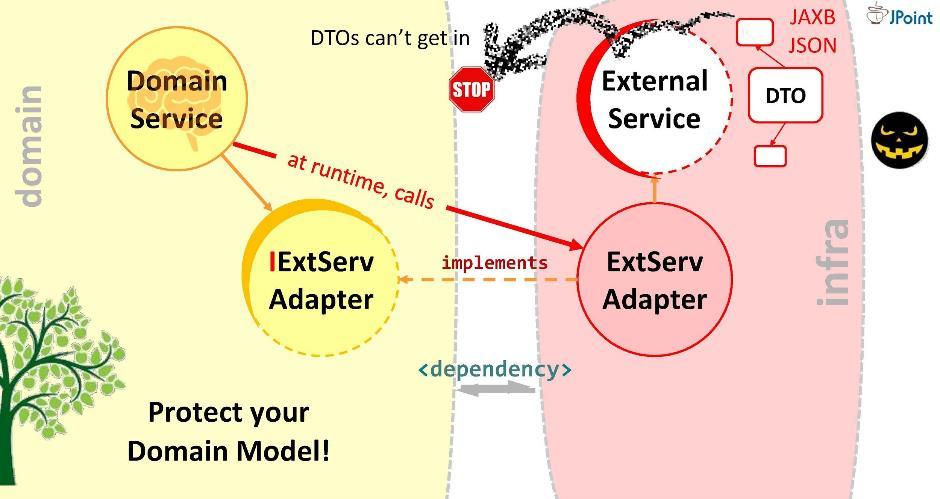 Erstellen wir eine Schnittstelle, schreiben Sie die Signatur der erforderlichen Methoden hinein und platzieren Sie sie in unserer Domäne. Die Aufgabe des Adapters besteht darin, diese Schnittstelle zu implementieren. Es stellt sich heraus, dass sich die Schnittstelle innerhalb der Domäne und der Adapter außerhalb des Infrastrukturmoduls befindet, das die Schnittstelle importiert. Wir haben also die Richtung der Abhängigkeit in die entgegengesetzte Richtung gedreht. Zur Laufzeit ruft das Domänensystem jede Klasse über Schnittstellen auf.Wie Sie sehen, konnten wir durch die Einführung von Schnittstellen in die Architektur Abhängigkeiten bereitstellen und so unsere Domäne vor fremden Strukturen und APIs schützen, die in sie fallen. Dieser Ansatz wird als Abhängigkeitsinversion bezeichnet .
Erstellen wir eine Schnittstelle, schreiben Sie die Signatur der erforderlichen Methoden hinein und platzieren Sie sie in unserer Domäne. Die Aufgabe des Adapters besteht darin, diese Schnittstelle zu implementieren. Es stellt sich heraus, dass sich die Schnittstelle innerhalb der Domäne und der Adapter außerhalb des Infrastrukturmoduls befindet, das die Schnittstelle importiert. Wir haben also die Richtung der Abhängigkeit in die entgegengesetzte Richtung gedreht. Zur Laufzeit ruft das Domänensystem jede Klasse über Schnittstellen auf.Wie Sie sehen, konnten wir durch die Einführung von Schnittstellen in die Architektur Abhängigkeiten bereitstellen und so unsere Domäne vor fremden Strukturen und APIs schützen, die in sie fallen. Dieser Ansatz wird als Abhängigkeitsinversion bezeichnet .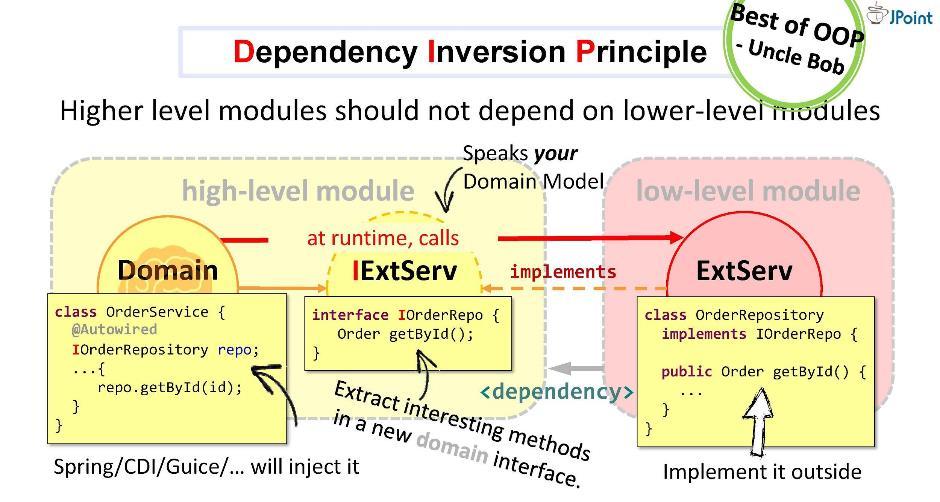 Im Allgemeinen setzt die Abhängigkeitsinversion voraus, dass Sie die für Sie interessanten Methoden in der Schnittstelle innerhalb Ihres High-Level-Moduls (in der Domäne) platzieren und diese Schnittstelle von außen implementieren - in dem einen oder anderen hässlichen Low-Level-Modul (Infrastruktur).Die im Domänenmodul implementierte Schnittstelle muss die Domänensprache sprechen, dh sie verarbeitet ihre Entitäten, ihre Parameter und Rückgabetypen. Zur Laufzeit ruft die Domäne eine beliebige Klasse über einen polymorphen Aufruf der Schnittstelle auf. Abhängigkeitsinjektions-Frameworks (wie Spring und CDI) bieten uns eine konkrete Instanz der Klasse direkt zur Laufzeit.Die Hauptsache ist jedoch, dass das Domänenmodul während der Kompilierung den Inhalt des externen Moduls nicht sieht. Das brauchen wir. Keine externe Entität sollte in die Domäne fallen.Laut Onkel Bob ist das Prinzip der Kontrollinversion (oder, wie er es nennt, „Plug-in-Architektur“) vielleicht das beste, das das OOP-Paradigma im Allgemeinen bietet.
Im Allgemeinen setzt die Abhängigkeitsinversion voraus, dass Sie die für Sie interessanten Methoden in der Schnittstelle innerhalb Ihres High-Level-Moduls (in der Domäne) platzieren und diese Schnittstelle von außen implementieren - in dem einen oder anderen hässlichen Low-Level-Modul (Infrastruktur).Die im Domänenmodul implementierte Schnittstelle muss die Domänensprache sprechen, dh sie verarbeitet ihre Entitäten, ihre Parameter und Rückgabetypen. Zur Laufzeit ruft die Domäne eine beliebige Klasse über einen polymorphen Aufruf der Schnittstelle auf. Abhängigkeitsinjektions-Frameworks (wie Spring und CDI) bieten uns eine konkrete Instanz der Klasse direkt zur Laufzeit.Die Hauptsache ist jedoch, dass das Domänenmodul während der Kompilierung den Inhalt des externen Moduls nicht sieht. Das brauchen wir. Keine externe Entität sollte in die Domäne fallen.Laut Onkel Bob ist das Prinzip der Kontrollinversion (oder, wie er es nennt, „Plug-in-Architektur“) vielleicht das beste, das das OOP-Paradigma im Allgemeinen bietet.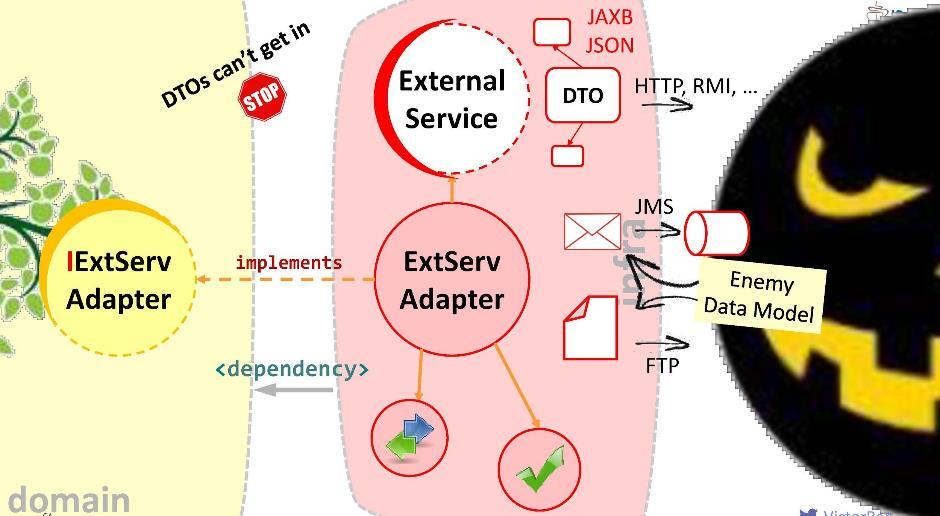 Diese Strategie kann zur Integration in beliebige Systeme, für synchrone und asynchrone Anrufe und Nachrichten, zum Senden von Dateien usw. verwendet werden.
Diese Strategie kann zur Integration in beliebige Systeme, für synchrone und asynchrone Anrufe und Nachrichten, zum Senden von Dateien usw. verwendet werden.Glühbirnenübersicht
 Deshalb haben wir beschlossen, das Domänenmodul zu schützen. Darin befinden sich ein Domänendienst, Entitäten, Wertobjekte und jetzt Schnittstellen für externe Dienste sowie Schnittstellen für das Repository (für die Interaktion mit der Datenbank).Die Struktur sieht folgendermaßen aus:
Deshalb haben wir beschlossen, das Domänenmodul zu schützen. Darin befinden sich ein Domänendienst, Entitäten, Wertobjekte und jetzt Schnittstellen für externe Dienste sowie Schnittstellen für das Repository (für die Interaktion mit der Datenbank).Die Struktur sieht folgendermaßen aus: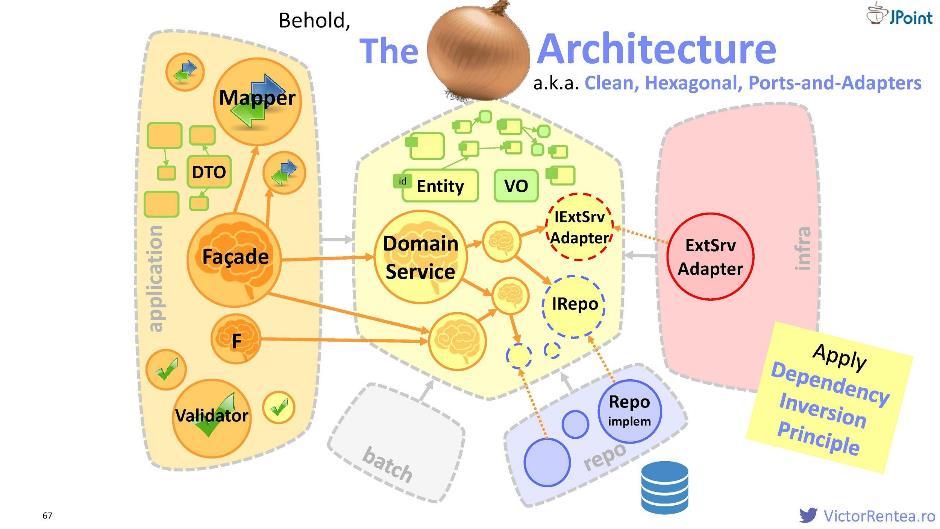 Das Anwendungsmodul, das Infrastrukturmodul (durch Abhängigkeitsinversion), das Repository-Modul (wir betrachten die Datenbank auch als externes System), das Batch-Modul und möglicherweise einige andere Module werden als Abhängigkeiten für die Domäne deklariert. Diese Architektur wird "Zwiebel" genannt ; Es wird auch als "sauber", "sechseckig" und "Anschlüsse und Adapter" bezeichnet.
Das Anwendungsmodul, das Infrastrukturmodul (durch Abhängigkeitsinversion), das Repository-Modul (wir betrachten die Datenbank auch als externes System), das Batch-Modul und möglicherweise einige andere Module werden als Abhängigkeiten für die Domäne deklariert. Diese Architektur wird "Zwiebel" genannt ; Es wird auch als "sauber", "sechseckig" und "Anschlüsse und Adapter" bezeichnet.Repository-Modul
Ich werde kurz auf das Repository-Modul eingehen. Ob es aus der Domain entfernt werden soll, ist eine Frage. Die Aufgabe des Repositorys ist es, die Logik sauberer zu machen und uns den Schrecken zu verbergen, mit persistenten Daten zu arbeiten. Die Option für Old-School-Leute besteht darin, JDBC für die Interaktion mit der Datenbank zu verwenden: Sie können auch Spring und dessen JdbcTemplate verwenden:
Sie können auch Spring und dessen JdbcTemplate verwenden: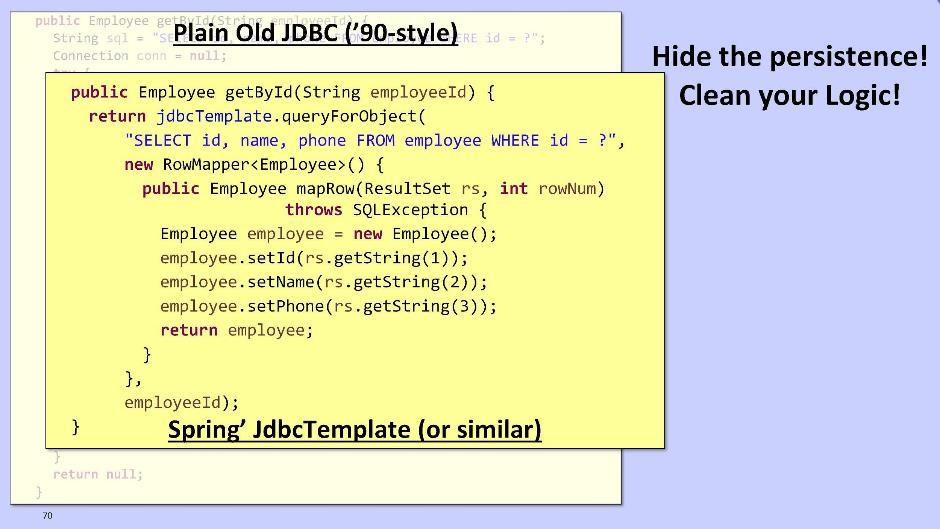 Oder MyBatis DataMapper:
Oder MyBatis DataMapper: Aber es ist so kompliziert und hässlich, dass es jeden Wunsch entmutigt, etwas weiter zu tun. Daher empfehle ich die Verwendung von JPA / Hibernate oder Spring Data JPA. Sie geben uns die Möglichkeit, Abfragen zu senden, die nicht auf dem Datenbankschema basieren, sondern direkt auf dem Modell unserer Entitäten.Implementierung für JPA / Hibernate:
Aber es ist so kompliziert und hässlich, dass es jeden Wunsch entmutigt, etwas weiter zu tun. Daher empfehle ich die Verwendung von JPA / Hibernate oder Spring Data JPA. Sie geben uns die Möglichkeit, Abfragen zu senden, die nicht auf dem Datenbankschema basieren, sondern direkt auf dem Modell unserer Entitäten.Implementierung für JPA / Hibernate: Im Fall von Spring Data JPA:
Im Fall von Spring Data JPA: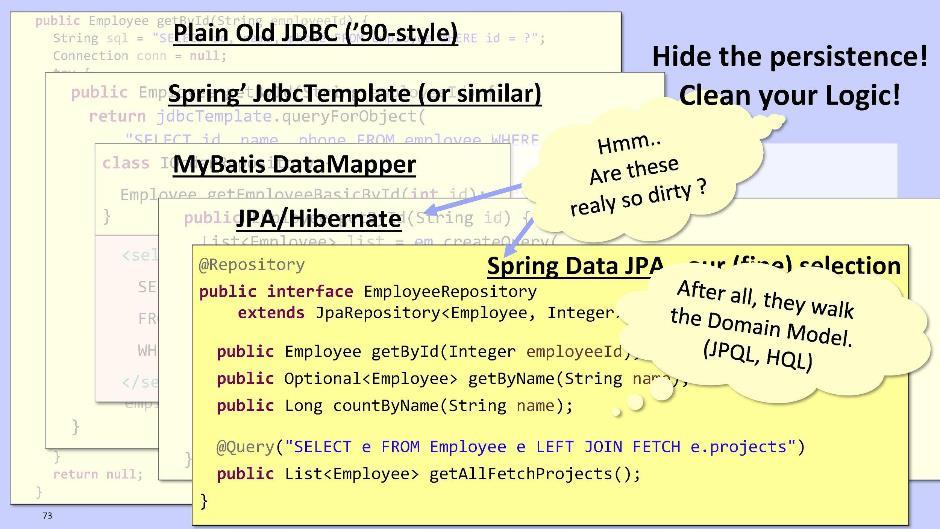 Spring Data JPA kann zur Laufzeit automatisch Methoden generieren, z. B. getById (), getByName (). Außerdem können Sie bei Bedarf JPQL-Abfragen ausführen - und zwar nicht in der Datenbank, sondern in Ihrem eigenen Entitätsmodell.Der JPA-Code für den Ruhezustand und Spring Data sieht wirklich ziemlich gut aus. Müssen wir es überhaupt aus der Domain extrahieren? Meiner Meinung nach ist dies nicht so und notwendig. Höchstwahrscheinlich wird der Code noch sauberer, wenn Sie dieses Fragment in der Domäne belassen. Handle also auf die Situation.
Spring Data JPA kann zur Laufzeit automatisch Methoden generieren, z. B. getById (), getByName (). Außerdem können Sie bei Bedarf JPQL-Abfragen ausführen - und zwar nicht in der Datenbank, sondern in Ihrem eigenen Entitätsmodell.Der JPA-Code für den Ruhezustand und Spring Data sieht wirklich ziemlich gut aus. Müssen wir es überhaupt aus der Domain extrahieren? Meiner Meinung nach ist dies nicht so und notwendig. Höchstwahrscheinlich wird der Code noch sauberer, wenn Sie dieses Fragment in der Domäne belassen. Handle also auf die Situation. Wenn Sie dennoch ein Repository-Modul erstellen, ist es für die Organisation von Abhängigkeiten besser, das Prinzip der Steuerungsinversion auf dieselbe Weise zu verwenden. Platzieren Sie dazu die Schnittstelle in der Domäne und implementieren Sie sie im Repository-Modul. Die Repository-Logik ist besser auf die Domäne zu übertragen. Dies erleichtert das Testen, da Sie Mock-Objekte in der Domäne verwenden können. Mit ihnen können Sie die Logik schnell und wiederholt testen.Traditionell wird nur eine Entität für ein Repository in einer Domäne erstellt. Sie zerbrechen es nur, wenn es zu voluminös wird. Denken Sie daran, dass Klassen kompakt sein müssen.
Wenn Sie dennoch ein Repository-Modul erstellen, ist es für die Organisation von Abhängigkeiten besser, das Prinzip der Steuerungsinversion auf dieselbe Weise zu verwenden. Platzieren Sie dazu die Schnittstelle in der Domäne und implementieren Sie sie im Repository-Modul. Die Repository-Logik ist besser auf die Domäne zu übertragen. Dies erleichtert das Testen, da Sie Mock-Objekte in der Domäne verwenden können. Mit ihnen können Sie die Logik schnell und wiederholt testen.Traditionell wird nur eine Entität für ein Repository in einer Domäne erstellt. Sie zerbrechen es nur, wenn es zu voluminös wird. Denken Sie daran, dass Klassen kompakt sein müssen.API
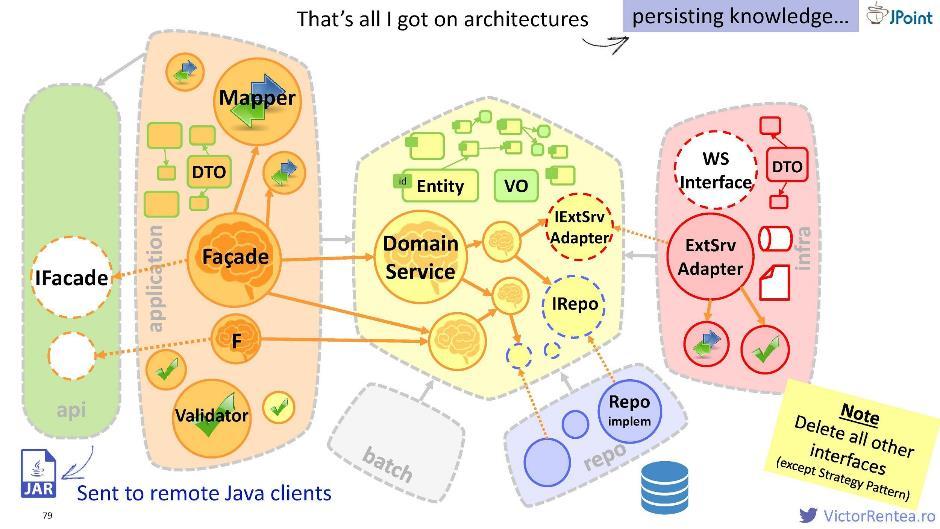 Sie können ein separates Modul erstellen, die aus der Fassade extrahierte Schnittstelle und die darauf basierenden DTOs platzieren, sie dann in eine JAR packen und in dieser Form an Ihre Java-Clients übertragen. Mit dieser Datei können sie Anfragen an die Fassaden senden.
Sie können ein separates Modul erstellen, die aus der Fassade extrahierte Schnittstelle und die darauf basierenden DTOs platzieren, sie dann in eine JAR packen und in dieser Form an Ihre Java-Clients übertragen. Mit dieser Datei können sie Anfragen an die Fassaden senden.Pragmatische Glühbirne
Zusätzlich zu denen unserer „Feinde“, denen wir Funktionen liefern, dh Kunden, haben wir auch Feinde und andererseits jene Module, von denen wir selbst abhängen. Wir müssen uns auch vor diesen Modulen schützen. Und dafür biete ich Ihnen eine leicht modifizierte „Zwiebel“ an - darin ist die gesamte Infrastruktur in einem Modul zusammengefasst.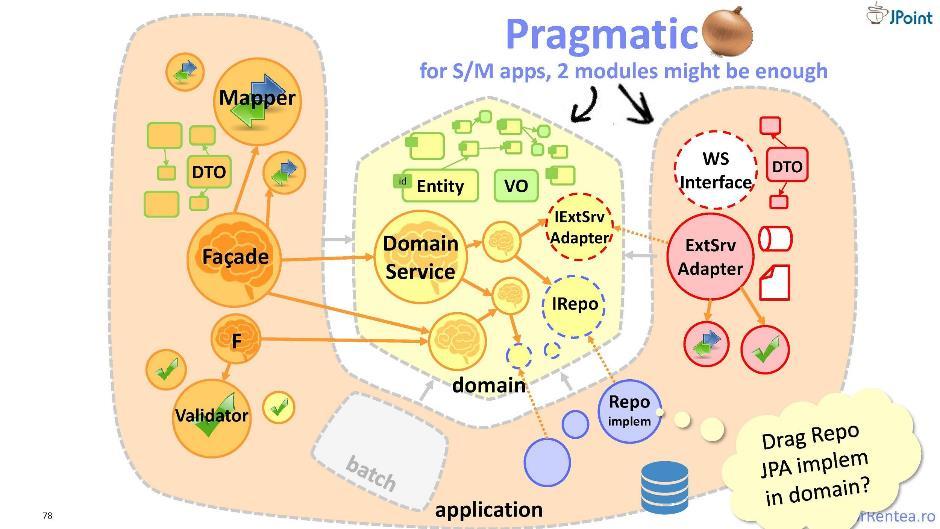 Ich nenne diese Architektur eine "pragmatische Glühbirne". Hier erfolgt die Trennung der Komponenten nach dem Prinzip „mein“ und „integrierbar“: getrennt, das bezieht sich auf meine Domäne, und getrennt, das bezieht sich auf die Integration mit externen Mitarbeitern. Somit werden nur zwei Module erhalten: die Domäne und die Anwendung. Eine solche Architektur ist sehr gut, aber nur, wenn das Anwendungsmodul klein ist. Ansonsten kehren Sie besser zur traditionellen Zwiebel zurück.
Ich nenne diese Architektur eine "pragmatische Glühbirne". Hier erfolgt die Trennung der Komponenten nach dem Prinzip „mein“ und „integrierbar“: getrennt, das bezieht sich auf meine Domäne, und getrennt, das bezieht sich auf die Integration mit externen Mitarbeitern. Somit werden nur zwei Module erhalten: die Domäne und die Anwendung. Eine solche Architektur ist sehr gut, aber nur, wenn das Anwendungsmodul klein ist. Ansonsten kehren Sie besser zur traditionellen Zwiebel zurück.Tests
Wie ich bereits sagte, wenn jeder Angst vor Ihrer Bewerbung hat, denken Sie daran, dass sie die Reihen von Legacy wieder aufgefüllt hat.  Aber die Tests sind gut. Sie geben uns ein Gefühl des Vertrauens, das es uns ermöglicht, das Refactoring fortzusetzen. Leider kann sich dieses Vertrauen leicht als ungerechtfertigt herausstellen. Ich werde erklären warum. TDD (Entwicklung durch Testen) setzt voraus, dass Sie sowohl der Autor des Codes als auch der Autor der Testfälle sind: Sie lesen die Spezifikationen, implementieren die Funktionalität und schreiben sofort eine Testsuite dafür. Tests werden beispielsweise erfolgreich sein. Aber was ist, wenn Sie die Anforderungen der Spezifikationen falsch verstanden haben? Dann prüfen die Tests nicht, was benötigt wird. Ihr Vertrauen ist also wertlos. Und das alles, weil Sie Code und Tests alleine geschrieben haben.Aber versuchen Sie, unsere Augen dafür zu schließen. Tests sind noch notwendig und geben uns auf jeden Fall Vertrauen. Vor allem lieben wir natürlich Funktionstests: Sie implizieren keine Nebenwirkungen, keine Abhängigkeiten - nur Eingabe- und Ausgabedaten. Um eine Domäne zu testen, müssen Sie Scheinobjekte verwenden: Mit ihnen können Sie Klassen isoliert testen.Das Testen von Datenbankabfragen ist unangenehm. Diese Tests sind fragil. Sie erfordern, dass Sie zuerst Testdaten zur Datenbank hinzufügen - und erst danach können Sie mit dem Testen der Funktionalität fortfahren. Wie Sie verstehen, sind diese Tests jedoch auch erforderlich, selbst wenn Sie JPA verwenden.
Aber die Tests sind gut. Sie geben uns ein Gefühl des Vertrauens, das es uns ermöglicht, das Refactoring fortzusetzen. Leider kann sich dieses Vertrauen leicht als ungerechtfertigt herausstellen. Ich werde erklären warum. TDD (Entwicklung durch Testen) setzt voraus, dass Sie sowohl der Autor des Codes als auch der Autor der Testfälle sind: Sie lesen die Spezifikationen, implementieren die Funktionalität und schreiben sofort eine Testsuite dafür. Tests werden beispielsweise erfolgreich sein. Aber was ist, wenn Sie die Anforderungen der Spezifikationen falsch verstanden haben? Dann prüfen die Tests nicht, was benötigt wird. Ihr Vertrauen ist also wertlos. Und das alles, weil Sie Code und Tests alleine geschrieben haben.Aber versuchen Sie, unsere Augen dafür zu schließen. Tests sind noch notwendig und geben uns auf jeden Fall Vertrauen. Vor allem lieben wir natürlich Funktionstests: Sie implizieren keine Nebenwirkungen, keine Abhängigkeiten - nur Eingabe- und Ausgabedaten. Um eine Domäne zu testen, müssen Sie Scheinobjekte verwenden: Mit ihnen können Sie Klassen isoliert testen.Das Testen von Datenbankabfragen ist unangenehm. Diese Tests sind fragil. Sie erfordern, dass Sie zuerst Testdaten zur Datenbank hinzufügen - und erst danach können Sie mit dem Testen der Funktionalität fortfahren. Wie Sie verstehen, sind diese Tests jedoch auch erforderlich, selbst wenn Sie JPA verwenden.Unit-Tests
 Ich würde sagen, dass die Kraft von Unit-Tests nicht in der Möglichkeit liegt, sie auszuführen, sondern darin, was der Prozess des Schreibens umfasst. Während Sie einen Test schreiben, überdenken Sie den Code und arbeiten ihn durch - reduzieren Sie die Konnektivität, teilen Sie ihn in Klassen auf - führen Sie mit einem Wort das nächste Refactoring durch. Der zu testende Code ist reiner Code. es ist einfacher, die Verbundenheit ist darin reduziert; Im Allgemeinen wird es auch dokumentiert (ein gut geschriebener Komponententest beschreibt perfekt, wie die Klasse funktioniert). Es ist nicht überraschend, dass das Schreiben von Unit-Tests schwierig ist, insbesondere bei den ersten Stücken.
Ich würde sagen, dass die Kraft von Unit-Tests nicht in der Möglichkeit liegt, sie auszuführen, sondern darin, was der Prozess des Schreibens umfasst. Während Sie einen Test schreiben, überdenken Sie den Code und arbeiten ihn durch - reduzieren Sie die Konnektivität, teilen Sie ihn in Klassen auf - führen Sie mit einem Wort das nächste Refactoring durch. Der zu testende Code ist reiner Code. es ist einfacher, die Verbundenheit ist darin reduziert; Im Allgemeinen wird es auch dokumentiert (ein gut geschriebener Komponententest beschreibt perfekt, wie die Klasse funktioniert). Es ist nicht überraschend, dass das Schreiben von Unit-Tests schwierig ist, insbesondere bei den ersten Stücken.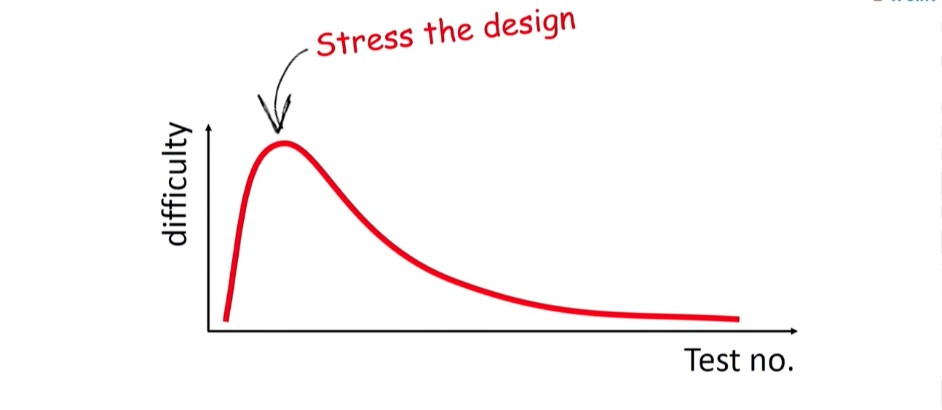 In der Phase der ersten Unit-Tests haben viele Menschen große Angst vor den Aussichten, dass sie wirklich etwas testen müssen. Warum werden sie so hart gegeben?Weil diese Tests die erste Belastung für Ihre Klasse sind. Dies ist der erste Schlag gegen das System, der vielleicht zeigt, dass es zerbrechlich und schwach ist. Sie müssen jedoch verstehen, dass diese wenigen Tests für Ihre Entwicklung am wichtigsten sind. Sie sind im Wesentlichen Ihre besten Freunde, weil sie alles sagen, was die Qualität Ihres Codes betrifft. Wenn Sie Angst vor dieser Phase haben, werden Sie nicht weit kommen. Sie müssen Tests für Ihr System ausführen. Danach nimmt die Komplexität ab, Tests werden schneller geschrieben. Wenn Sie sie einzeln hinzufügen, erstellen Sie eine zuverlässige Regressionstestbasis für Ihr System. Und das ist unglaublich wichtig für die zukünftige Arbeit Ihrer Entwickler. Es wird für sie einfacher sein, umzugestalten; Sie werden verstehen, dass das System jederzeit auf Regression getestet werden kann, weshalb die Arbeit mit der Codebasis sicher ist. Und ich versichere Ihnen, sie werden sich viel bereitwilliger mit der Umgestaltung befassen.
In der Phase der ersten Unit-Tests haben viele Menschen große Angst vor den Aussichten, dass sie wirklich etwas testen müssen. Warum werden sie so hart gegeben?Weil diese Tests die erste Belastung für Ihre Klasse sind. Dies ist der erste Schlag gegen das System, der vielleicht zeigt, dass es zerbrechlich und schwach ist. Sie müssen jedoch verstehen, dass diese wenigen Tests für Ihre Entwicklung am wichtigsten sind. Sie sind im Wesentlichen Ihre besten Freunde, weil sie alles sagen, was die Qualität Ihres Codes betrifft. Wenn Sie Angst vor dieser Phase haben, werden Sie nicht weit kommen. Sie müssen Tests für Ihr System ausführen. Danach nimmt die Komplexität ab, Tests werden schneller geschrieben. Wenn Sie sie einzeln hinzufügen, erstellen Sie eine zuverlässige Regressionstestbasis für Ihr System. Und das ist unglaublich wichtig für die zukünftige Arbeit Ihrer Entwickler. Es wird für sie einfacher sein, umzugestalten; Sie werden verstehen, dass das System jederzeit auf Regression getestet werden kann, weshalb die Arbeit mit der Codebasis sicher ist. Und ich versichere Ihnen, sie werden sich viel bereitwilliger mit der Umgestaltung befassen. Mein Rat an Sie: Wenn Sie heute das Gefühl haben, viel Kraft und Energie zu haben, widmen Sie sich dem Schreiben von Unit-Tests. Und stellen Sie sicher, dass jeder sauber und schnell ist, sein eigenes Gewicht hat und die anderen nicht wiederholt.
Mein Rat an Sie: Wenn Sie heute das Gefühl haben, viel Kraft und Energie zu haben, widmen Sie sich dem Schreiben von Unit-Tests. Und stellen Sie sicher, dass jeder sauber und schnell ist, sein eigenes Gewicht hat und die anderen nicht wiederholt.Tipps
Zusammenfassend möchte ich Sie mit den folgenden Tipps ermahnen:- Halten Sie es so lange wie möglich einfach (und egal was es kostet) : Vermeiden Sie „Reengineering“ und verspätete Optimierung, überlasten Sie die Anwendung nicht.
- , , ;
- «» — ;
- , — : ;
- «», , — ;
- Haben Sie keine Angst vor Tests : Geben Sie ihnen die Möglichkeit, Ihr System herunterzufahren, alle Vorteile zu spüren - am Ende sind sie Ihre Freunde, weil sie ehrlich auf Probleme hinweisen können.
Auf diese Weise helfen Sie sowohl Ihrem Team als auch sich selbst. Und dann, wenn der Tag der Lieferung des Produkts kommt, sind Sie bereit dafür.Was zu lesen

. JPoint — , 19-20 - Joker 2018 — Java-. . .