Einführung
Jeder, der das Zabbix-Überwachungssystem verwendet und dessen Entwicklung überwacht, weiß, dass wir mit der Veröffentlichung von Zabbix 3.4 eine großartige Funktion haben - abhängige Elemente (abhängige Datenelemente), über die es bereits einen
entsprechenden Blog-
Beitrag auf Zabbix gab. In der Form, in der es in 3.4 eingeführt wurde, war die Verwendung „in vollem Umfang“ problematisch, da LLD-Makros für die Verwendung in Vorverarbeitungsregeln (
ZBXNEXT-4109 ) sowie als „übergeordnetes
Element“ nicht unterstützt wurden. Aus dem Datenelement konnte nur eine ausgewählt werden, die von der LLD-Regel selbst erstellt wurde (
ZBXNEXT-4200 ). Kurz gesagt, ich musste alles genau so machen, wie im obigen Link beschrieben - um mit Ihren Händen zu arbeiten, was mit einer großen Anzahl von Metriken viele Unannehmlichkeiten verursachte. Mit der Veröffentlichung von Zabbix 4.0alpha9 hat sich jedoch alles geändert.
Ein bisschen Geschichte
Für mich war die beschriebene Funktionalität wichtig, da unser Unternehmen mehrere Speichersysteme von HP verwendet, nämlich HP MSA 2040/2050, deren Metriken durch Anforderungen an ihre XML-API mithilfe eines
Python-Skripts entfernt werden .
Ganz am Anfang, als die Aufgabe darin bestand, die vorgesehenen Geräte zu überwachen und eine Option unter Verwendung der API gefunden wurde, stellte sich heraus, dass im einfachsten Fall, um beispielsweise den Gesundheitszustand einer Komponente des Speichersystems herauszufinden, zwei Abfragen erforderlich waren:
- Authentifizierungstoken anfordern (Sitzungsschlüssel);
- Die Anforderung selbst, die Informationen zur Komponente zurückgibt.
Stellen Sie sich nun vor, der Speicher besteht aus 24 Festplatten (oder mehr), zwei Netzteilen, zwei Controllern, Lüftern, mehreren Festplattenpools usw. - wir multiplizieren dies alles mit 2 und erhalten mehr als 50 Datenelemente, was der gleichen Anzahl von Anforderungen entspricht API bei jeder Minute überprüft. Wenn Sie versuchen, diesen Weg zu gehen, legt sich die API schnell fest, und schließlich geht es nur darum, den „Zustand“ der Komponenten anzufordern, ohne die anderen möglichen und interessanten Messgrößen zu berücksichtigen - Temperatur, Betriebsstunden für Festplatten, Lüftergeschwindigkeit usw.
Die erste Entscheidung, die ich bereits vor der Veröffentlichung von Zabbix Version 3.4 zum Entladen der API getroffen habe, bestand darin, einen Cache für das empfangene Token zu erstellen, dessen Wert in die Datei geschrieben und N Minuten lang gespeichert wurde. Dadurch konnte die Anzahl der Aufrufe der API um genau das Zweifache reduziert werden. Die Situation änderte sich jedoch nicht wesentlich - es war schwierig, etwas anderes als den Gesundheitszustand zu ermitteln. Ungefähr zu dieser Zeit besuchte ich das von Badoo veranstaltete Zabbix Moscow Meetup 2017, wo ich etwas über die Funktionalität der oben genannten abhängigen Datenelemente erfuhr.
Das Skript wurde dahingehend geändert, dass detaillierte JSON-Objekte mit Informationen, die für uns von Interesse sind, zu verschiedenen Komponenten des Repositorys bereitgestellt werden können. Die Ausgabe sah ungefähr so aus wie einzelne Zeichenfolgen oder numerische Werte:
{"1.1":{"health":"OK","health-num":"0","error":"0","temperature":"24","power-on-hours":"27267"},"1.2":{"health":"OK","health-num":"0","error":"0","temperature":"23","power-on-hours":"27266"},"1.3":{"health":"OK","health-num":"0","error":"0","temperature":"24","power-on-hours":"27336"}, ... }
Dies ist ein Beispiel mit den angegebenen Daten auf allen Speicherplatten. Bei anderen Komponenten ist das Bild ähnlich - der Schlüssel ist die Komponenten-ID, und der Wert ist ein JSON-Objekt, das die erforderlichen Metriken enthält.
Alles war in Ordnung, aber die am Anfang des Artikels beschriebenen Nuancen tauchten schnell auf - alle abhängigen Metriken mussten manuell erstellt und aktualisiert werden, was ziemlich schmerzhaft war (etwa 300 Metriken pro Speichersystem plus Trigger und Grafiken). LLD konnte uns retten, aber hier konnten wir beim Erstellen des Prototyps nicht denjenigen angeben, der nicht von der Regel selbst als übergeordnetes Element erstellt wurde, und den Dirty Hack mit dem Erstellen eines fiktiven Elements über LLD und dem Ersetzen seiner Element-ID in der Datenbank durch das gewünschte Element löschen Zabbix Server. Die genannten Feature-Anfragen tauchten schnell im Zabbix Bug Tracker auf, was darauf hinwies, dass diese Funktionalität nicht nur für mich wichtig war.
Weil Alle vorbereitenden Arbeiten meinerseits waren abgeschlossen. Ich entschied mich, temporäre Lösungen wie die dynamische Vorlagengenerierung zu tolerieren und nicht zu produzieren, und wartete nur auf den Abschluss der ZBXNEXTs, die am Anfang des Artikels angegeben waren, und erst kürzlich wurde dies durchgeführt.
Wie es jetzt aussieht
Um die neuen Funktionen von Zabbix zu demonstrieren, nehmen wir:
- HPE MSA 2040-Speicher über HTTP / HTTPS verfügbar;
- Zabbix 4.0alpha9-Server aus dem offiziellen Repository unter CentOS 7.5.1804 installiert;
- Ein in Python der dritten Version geschriebenes Skript, mit dem Speicherkomponenten (LLD) erkannt und Daten im JSON-Format zum Parsen auf der Zabbix-Serverseite mithilfe des JSON-Pfads zurückgegeben werden können.
Das übergeordnete Datenelement ist eine „externe Prüfung“, die das Skript mit den erforderlichen Argumenten aufruft und die empfangenen Daten als Text speichert.
Vorbereitung
Das Python-Skript wird gemäß der
Dokumentation installiert und verfügt über eine Anforderungsbibliothek in Python-Abhängigkeiten. Wenn Sie eine RHEL-basierte Distribution haben, können Sie diese mit dem yum-Paketmanager installieren:
[root@zabbix]
Oder mit pip:
[root@zabbix]
Sie können das Skript über die Shell testen, indem Sie beispielsweise LLD-Daten zu Datenträgern anfordern:
[root@zabbix]
Host-Setup
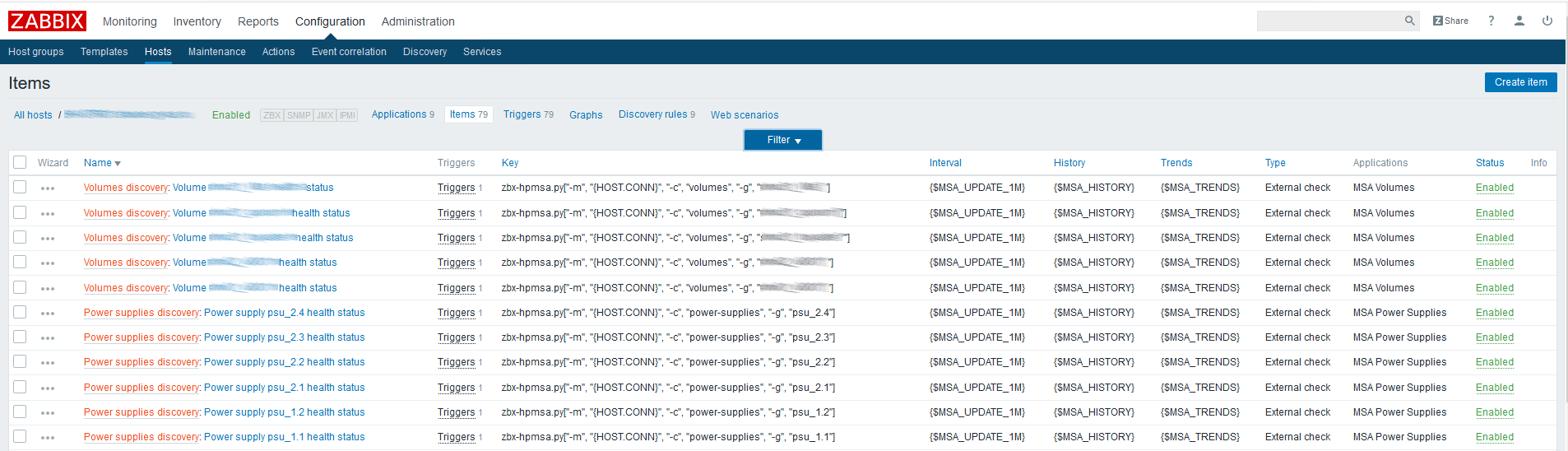
Zuerst müssen Sie übergeordnete Datenelemente erstellen, die alle benötigten Metriken enthalten. Erstellen Sie beispielsweise ein solches Element für physische Festplatten:
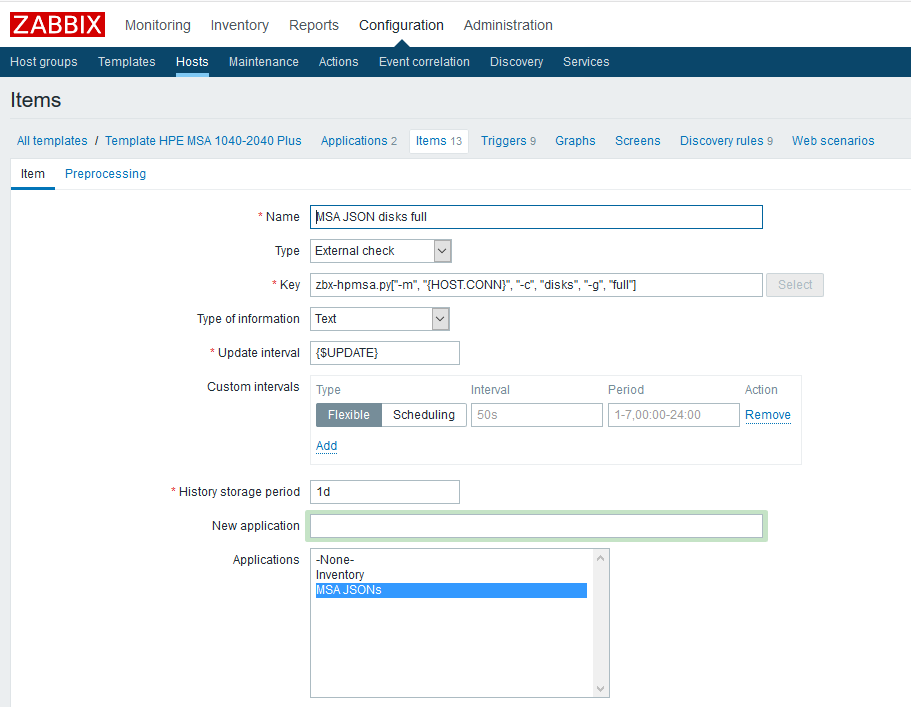 Name
Name - willkürlich angeben;
Typ - externe Überprüfung;
Der Schlüssel besteht darin, das Skript mit den erforderlichen Parametern aufzurufen (siehe die
Skriptdokumentation auf GitHub).
Art der Information - Text;
Aktualisierungsintervall - In diesem Beispiel wird ein benutzerdefiniertes Makro {$ UPDATE} verwendet, das auf den Wert "1m" erweitert wird.
Die Speicherdauer für den Verlauf beträgt einen Tag. Ich denke, dass das Speichern des übergeordneten Datenelements keinen Sinn mehr macht.
Überprüfen Sie die neuesten Daten für das erstellte Element:
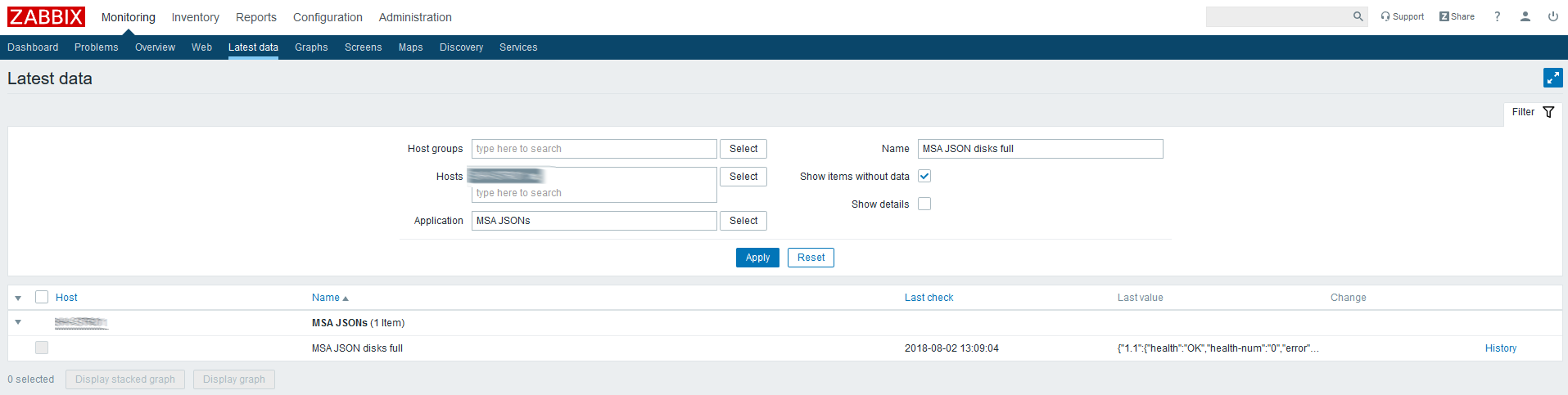
JSON kommt, dann ist alles richtig gemacht.
Als Nächstes werden Erkennungsregeln eingerichtet, mit denen alle für die Überwachung verfügbaren Komponenten gefunden und abhängige Elemente und Trigger erstellt werden. Wenn Sie das Beispiel mit physischen Datenträgern fortsetzen, sieht es folgendermaßen aus:
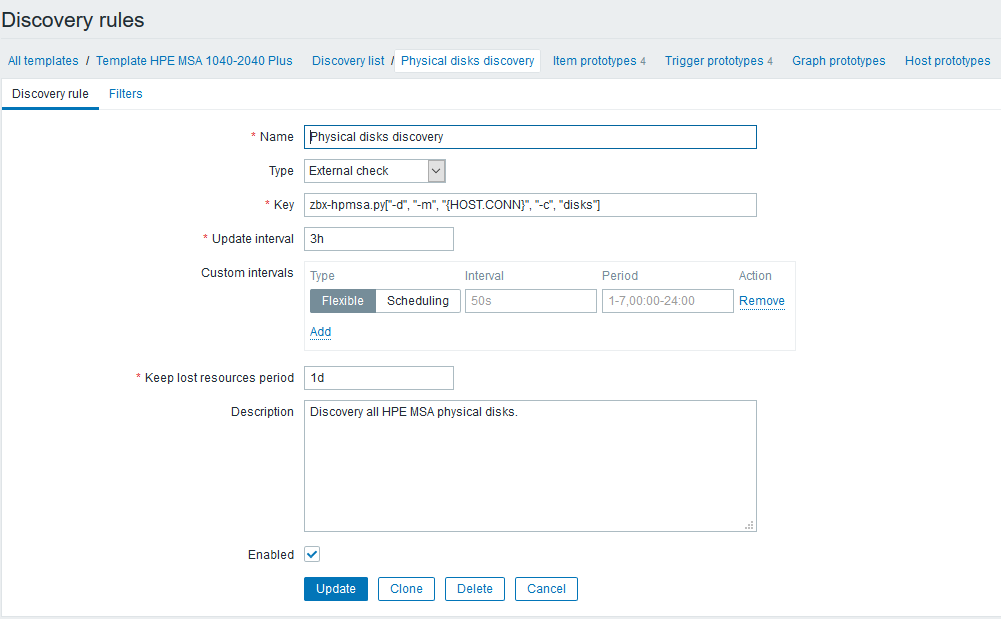
Nach dem Erstellen der LLD-Regel müssen Sie Datenelemente prototypisieren. Lassen Sie uns einen solchen Prototyp am Beispiel von Temperaturdaten erstellen:
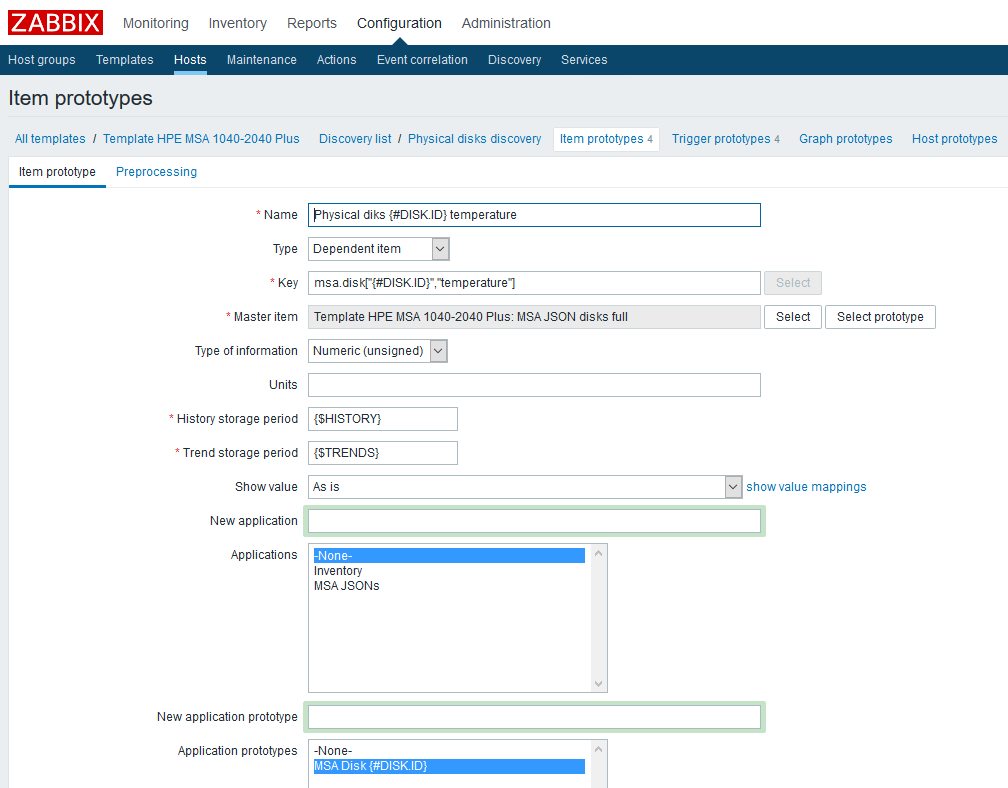 Name
Name - willkürlich angeben;
Typ ist abhängig. Wählen Sie als übergeordnetes Datenelement das entsprechende zuvor erstellte Element aus.
Schlüssel - Wir werden Phantasie zeigen, aber wir müssen berücksichtigen, dass jeder Schlüssel eindeutig sein muss. Deshalb werden wir das LLD-Makro darin aufnehmen.
Art der Informationen - in diesem Fall numerisch;
Zeitraum der Verlaufsspeicherung - In diesem Beispiel handelt es sich um ein benutzerdefiniertes Makro, das nach Ihrem Ermessen angegeben wird.
Der Trendspeicherzeitraum ist wiederum ein benutzerdefiniertes Makro.
Ich habe auch einen Prototyp der „Anwendung“ hinzugefügt - Sie können bequem Metriken für eine Komponente daran binden.
Erstellen Sie auf der Registerkarte "Vorverarbeitung" einen Schritt vom Typ "JSON-Pfad" mit einer Regel, die Temperaturwerte abruft:
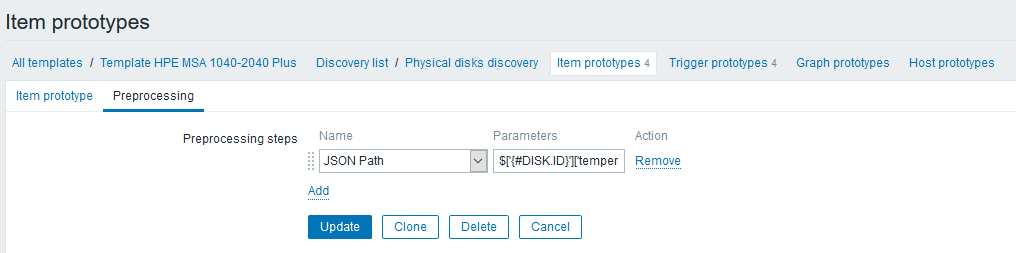
Der
$['{#DISK.ID}']['temperature'] sieht folgendermaßen aus:
$['{#DISK.ID}']['temperature']Bitte beachten Sie, dass Sie jetzt LLD-Makros im Ausdruck verwenden können, was nicht nur unsere Arbeit erheblich vereinfacht, sondern es auch recht einfach macht, solche Dinge zu tun (Sie würden vorher an die Zabbix-API gesendet).
Erstellen Sie anschließend in Analogie zur Temperatur die verbleibenden Prototypen von Datenelementen:

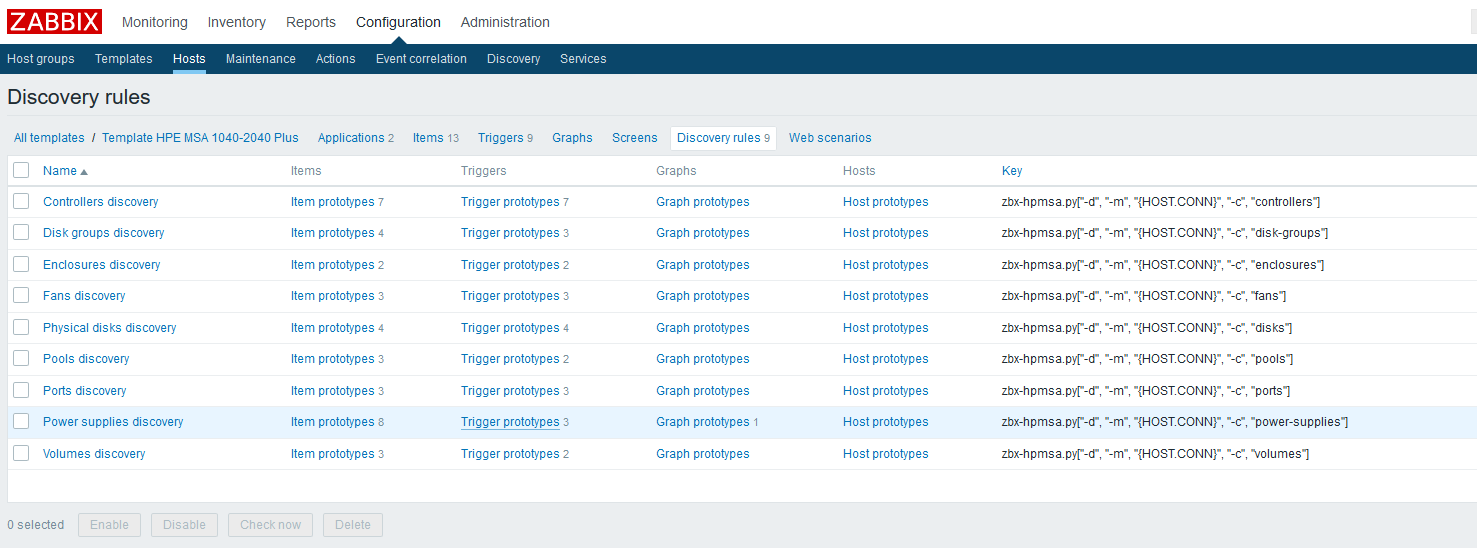
In diesem Stadium können Sie das Ergebnis überprüfen, indem Sie auf dem Host zu "Letzte Daten" gehen. Wenn Ihnen dort alles passt, arbeiten wir weiter. Am Ende hatte ich folgendes Bild:
Wir warten darauf, dass der Konfigurationscache aktualisiert wird, oder drücken ihn manuell, um ihn zu aktualisieren:
[root@zabbix]
Danach können Sie einen weiteren coolen „Trick“ der Version 4.0 verwenden - die Schaltfläche „Jetzt prüfen“, um die erstellten LLD-Regeln auszuführen:
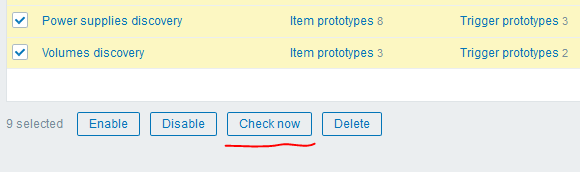
Ich habe folgendes Ergebnis erhalten:
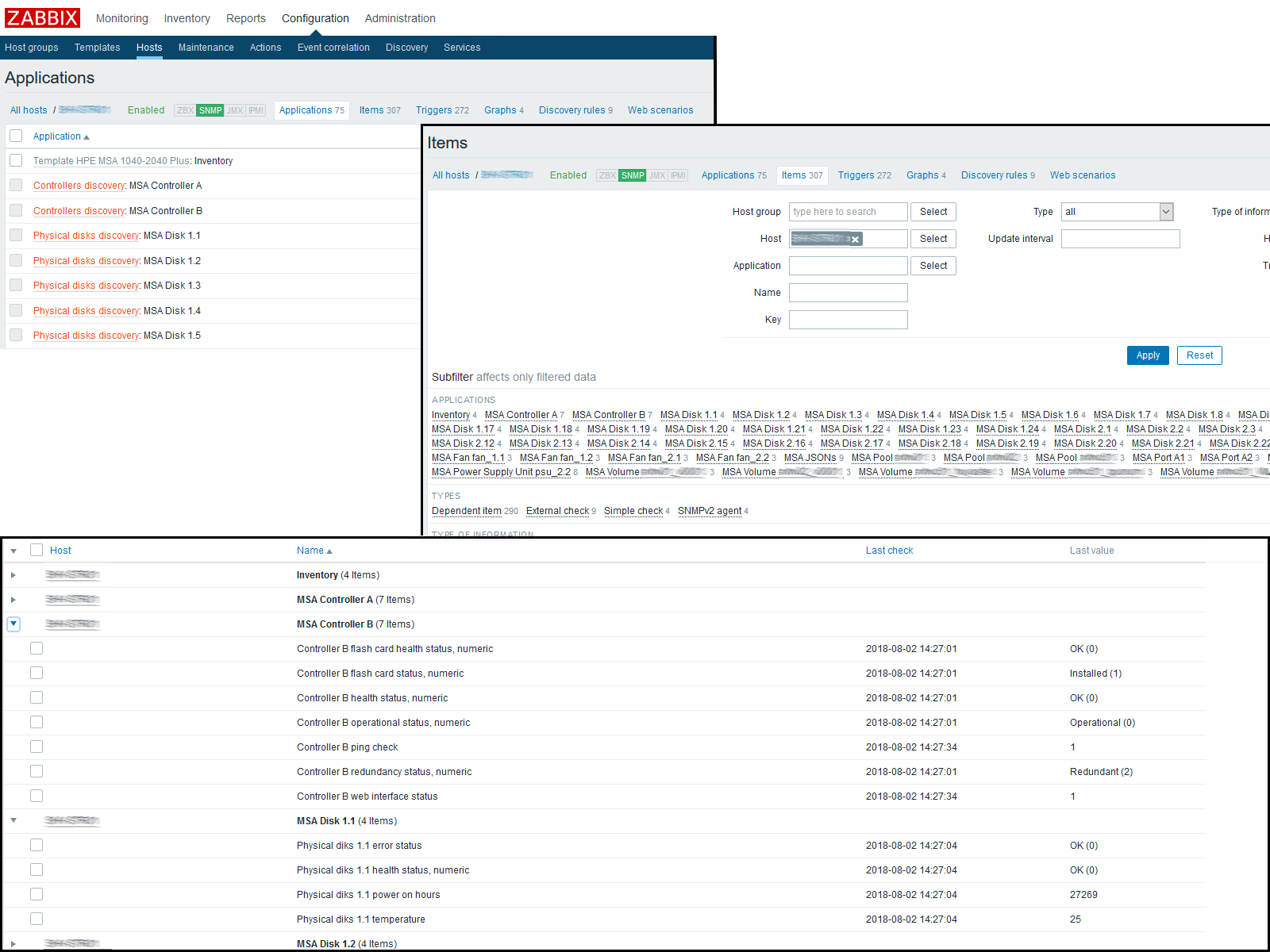
Fazit
Mit nur neun Anfragen an die XML-API konnten wir mehr als dreihundert Metriken von einem Netzwerkknoten abrufen, so wenig Zeit wie möglich damit verbringen und maximale Flexibilität erhalten. LLD gibt uns die Möglichkeit, neue Komponenten automatisch zu erkennen oder alte zu aktualisieren.
Vielen Dank für das Lesen, Links zu den verwendeten Materialien und auch zur aktuellen Vorlage für den HPE MSA P2000G3 / 2040/2050 finden Sie unten.
PS Übrigens wird in Version 4.0 auch eine neue Art von Überprüfungen eingeführt - ein HTTP-Agent, der uns in Verbindung mit Vorverarbeitung und XML-Pfad möglicherweise die Verwendung externer Skripte ersparen kann - Sie müssen nur das Problem lösen, ein Authentifizierungstoken zu erhalten, das noch regelmäßig aktualisiert werden muss. Eine der Optionen, die ich sehe, ist die Verwendung eines globalen Makros mit diesem Token, das über die Zabbix-API per Krone aktualisiert werden kann. Interessierte können diese Idee entwickeln. =)
SkriptZabbix Share VorlageAbhängige DatenelementeJson PfadZabbix 4.0alpha9