Hallo Habr. Mein Name ist Vitaliy Kotov, ich arbeite in der Testabteilung von Badoo. Ich schreibe viele automatische UI-Tests, aber ich arbeite noch mehr mit denen zusammen, die dies vor nicht allzu langer Zeit getan haben und es noch nicht geschafft haben, auf alle Rechen zu treten.
Nachdem ich meine eigenen Erfahrungen und Beobachtungen anderer Leute hinzugefügt hatte, beschloss ich, für Sie eine Sammlung von „Wie man Tests schreibt, lohnt sich nicht“ vorzubereiten. Ich habe jedes Beispiel mit einer detaillierten Beschreibung, Codebeispielen und Screenshots unterstützt.
Der Artikel wird für Anfänger von UI-Tests interessant sein, aber Oldtimer in diesem Thema werden wahrscheinlich etwas Neues lernen oder einfach nur lächeln und sich "in ihrer Jugend" an sich selbst erinnern. :) :)
Lass uns gehen!

Inhalt
Locators ohne Attribute
Beginnen wir mit einem einfachen Beispiel. Da es sich um UI-Tests handelt, spielen Locators eine wichtige Rolle. Ein Locator ist eine Zeile, die nach einer bestimmten Regel zusammengesetzt ist und ein oder mehrere XML-Elemente (insbesondere HTML-Elemente) beschreibt.
Es gibt verschiedene Arten von Locatoren. Beispielsweise werden
CSS-Locators zum Kaskadieren von Stylesheets verwendet.
XPath-Locators werden zum Arbeiten mit XML-Dokumenten verwendet. Usw.
Eine vollständige Liste der von
Selen verwendeten Locator-Typen finden Sie unter
seleniumhq.imtqy.com .
In UI-Tests werden Locators verwendet, um die Elemente zu beschreiben, mit denen der Treiber interagieren soll.
In fast jedem Browser-Inspektor ist es möglich, das für uns interessante Element auszuwählen und seinen XPath zu kopieren. Es sieht ungefähr so aus:
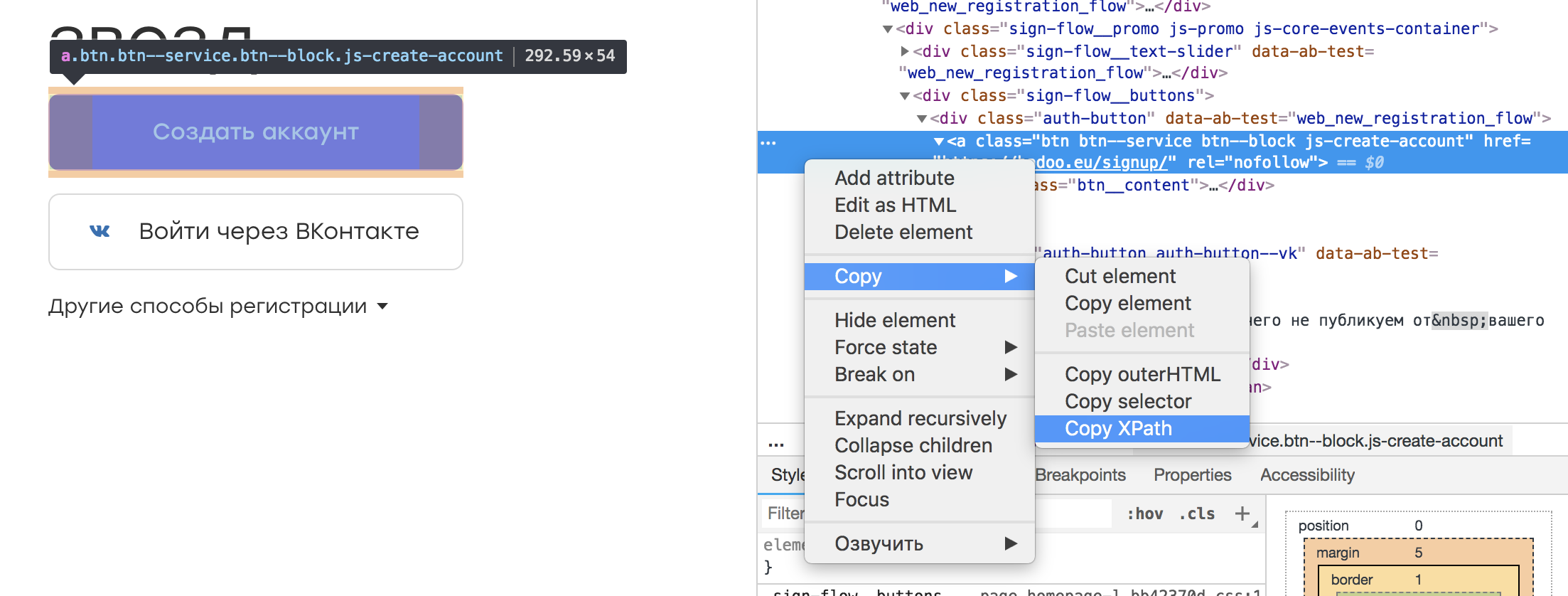
Es stellt sich heraus, ein solcher Locator:
/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a
Es scheint, dass an einem solchen Ortungsgerät nichts falsch ist. Schließlich können wir es in einer Konstanten oder einem Feld der Klasse speichern, die durch ihren Namen die Essenz des Elements vermitteln:
@FindBy(xpath = "/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a") public WebElement createAccountButton;
Und wickeln Sie den entsprechenden Fehlertext ein, falls das Element nicht gefunden wird:
public void waitForCreateAccountButton() { By by = By.xpath(this.createAccountButton); WebDriverWait wait = new WebDriverWait(driver, timeoutInSeconds); wait .withMessage(“Cannot find Create Account button.”) .until( ExpectedConditions.presenceOfElementLocated(by) ); }
Dieser Ansatz hat ein Plus: Es ist nicht erforderlich, XPath zu lernen.
Es gibt jedoch eine Reihe von Nachteilen. Erstens gibt es beim Ändern des Layouts keine Garantie dafür, dass das Element auf einem solchen Locator gleich bleibt. Es ist möglich, dass ein anderer seinen Platz einnimmt, was zu unvorhergesehenen Umständen führt. Zweitens besteht die Aufgabe von Autotests darin, nach Fehlern zu suchen und Layoutänderungen nicht zu überwachen. Daher sollte das Hinzufügen eines Wrappers oder anderer Elemente höher im Baum unsere Tests nicht beeinflussen. Andernfalls benötigen wir viel Zeit, um die Locators zu aktualisieren.
Fazit: Sie sollten Locators erstellen, die das Element korrekt beschreiben und gegen sich ändernde Layouts außerhalb des getesteten Teils unserer Anwendung resistent sind. Sie können beispielsweise an ein oder mehrere Attribute eines Elements binden:
//a[@rel=”createAccount”]
Ein solcher Locator ist im Code leichter zu erkennen und bricht nur ab, wenn "rel" verschwindet.
Ein weiteres Plus eines solchen Locators ist die Möglichkeit, im Vorlagen-Repository mit dem angegebenen Attribut zu suchen. Aber worauf ist zu achten, wenn der Locator im Originalbeispiel aussieht? :) :)
Wenn die Elemente anfangs in der Anwendung keine Attribute haben oder automatisch festgelegt werden (z. B. aufgrund der
Verschleierung von Klassen), sollten Sie dies mit den Entwicklern besprechen. Sie sollten nicht weniger an der Automatisierung von Produkttests interessiert sein und werden Sie sicherlich treffen und eine Lösung anbieten.
Überprüfen Sie, ob ein Artikel fehlt
Jeder Badoo-Benutzer hat sein eigenes Profil. Es enthält Informationen über den Benutzer: (Name, Alter, Fotos) und Informationen darüber, mit wem der Benutzer chatten möchte. Darüber hinaus ist es möglich, Ihre Interessen anzugeben.
Angenommen, wir hatten einmal einen Fehler (obwohl dies natürlich nicht so ist :)). Der Benutzer in seinem Profil hat Interessen ausgewählt. Da er kein geeignetes Interesse aus der Liste fand, entschied er sich, auf "Mehr" zu klicken, um die Liste zu aktualisieren.
Erwartetes Verhalten: Alte Interessen sollten verschwinden, neue sollten auftauchen. Stattdessen tauchte ein „unerwarteter Fehler“ auf:
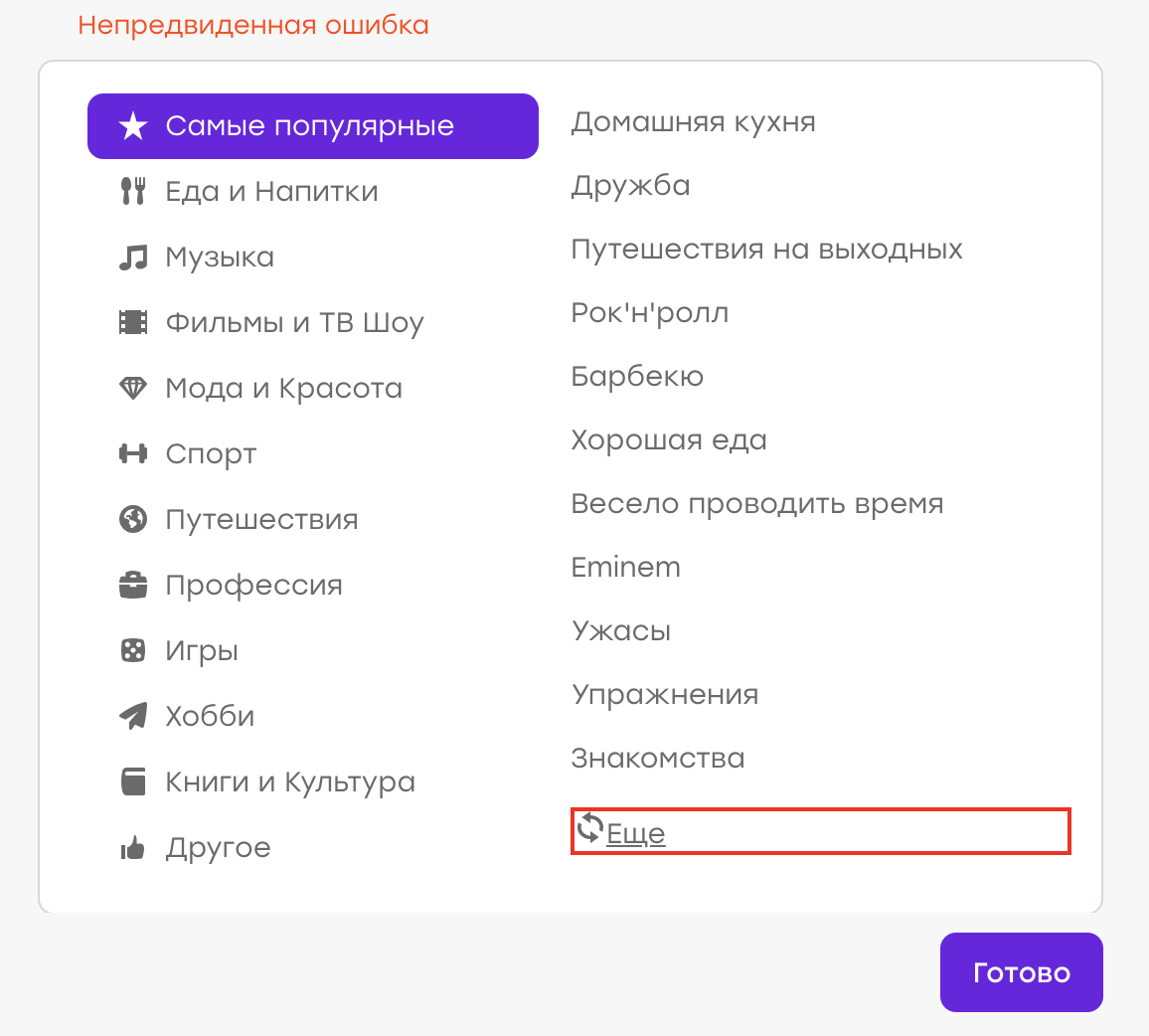
Es stellte sich heraus, dass auf der Serverseite ein Problem auftrat, die Antwort nicht dieselbe war und der Client diese Angelegenheit durch Anzeigen einer Benachrichtigung verarbeitete.
Unsere Aufgabe ist es, einen Autotest zu schreiben, der diesen Fall überprüft.
Wir schreiben ungefähr das folgende Skript:
- Profil öffnen
- Offene Interessenliste
- Klicken Sie auf die Schaltfläche "Mehr"
- Stellen Sie sicher, dass der Fehler nicht aufgetreten ist (z. B. gibt es kein div.error-Element).
Wir führen einen solchen Test durch. Folgendes passiert jedoch: Nach einigen Tagen / Monaten / Jahren tritt der Fehler erneut auf, obwohl der Test nichts abfängt. Warum?
Es ist ganz einfach: Während des erfolgreichen Bestehens des Tests hat sich der Locator des Elements geändert, mit dem wir nach dem Fehlertext gesucht haben. Es gab ein Refactoring der Vorlagen und anstelle der Klasse "error" haben wir die Klasse "error_new" erhalten.
Während des Refactorings funktionierte der Test wie erwartet weiter. Das div.error-Element wurde nicht angezeigt, es gab keinen Grund für den Fall. Aber jetzt existiert das Element "div.error" überhaupt nicht - daher wird der Test niemals fehlschlagen, egal was in der Anwendung passiert.
Fazit: Es ist besser, die Funktionsfähigkeit der Schnittstelle mit Positivprüfungen zu testen. In unserem Beispiel sollten wir erwarten, dass sich die Liste der Interessen geändert hat.
Es gibt Situationen, in denen ein negativer Test nicht durch einen positiven ersetzt werden kann. Wenn Sie beispielsweise mit einem Element interagieren, geschieht in einer „guten“ Situation nichts, und in einer „schlechten“ Situation tritt ein Fehler auf. In diesem Fall sollten Sie eine Möglichkeit finden, ein „schlechtes“ Szenario zu simulieren und auch einen Autotest darauf zu schreiben. Auf diese Weise überprüfen wir, ob das Fehlerelement im negativen Fall angezeigt wird, und überwachen damit die Relevanz des Locators.
Suchen Sie nach einem Artikel
Wie kann sichergestellt werden, dass die Testinteraktion mit der Schnittstelle erfolgreich war und alles funktioniert? Dies zeigt sich am häufigsten an den Änderungen, die an dieser Schnittstelle vorgenommen wurden.
Betrachten Sie ein Beispiel. Sie müssen sicherstellen, dass eine Nachricht beim Senden im Chat angezeigt wird:
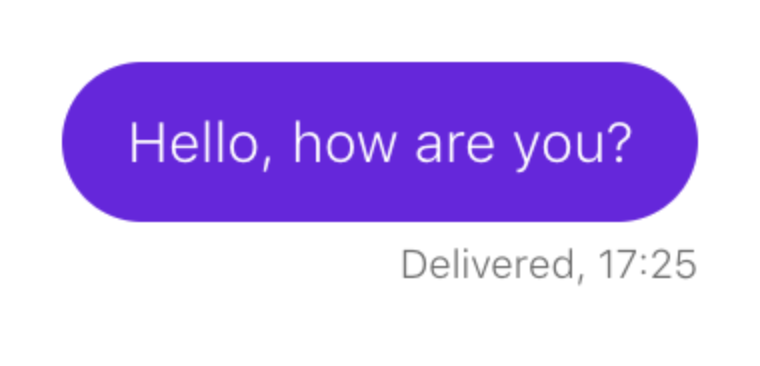
Das Skript sieht ungefähr so aus:
- Benutzerprofil öffnen
- Öffnen Sie den Chat mit ihm
- eine Nachricht schreiben
- Senden
- Warten Sie, bis die Nachricht angezeigt wird.
Wir beschreiben ein solches Szenario in unserem Test. Angenommen, eine Chat-Nachricht entspricht einem Locator:
p.message_text
So überprüfen wir, ob das Element angezeigt wird:
this.waitForPresence(By.css('p.message_text'), "Cannot find sent message.");
Wenn unser Warten funktioniert, ist alles in Ordnung: Chat-Nachrichten werden gezeichnet.
Wie Sie vielleicht vermutet haben, wird das Senden von Chat-Nachrichten nach einer Weile unterbrochen, aber unser Test funktioniert weiterhin ohne Unterbrechungen. Lass es uns richtig machen.
Es stellt sich heraus, dass am Tag zuvor ein neues Element im Chat angezeigt wurde: ein Text, der den Benutzer auffordert, die Nachricht hervorzuheben, wenn sie plötzlich unbemerkt blieb:
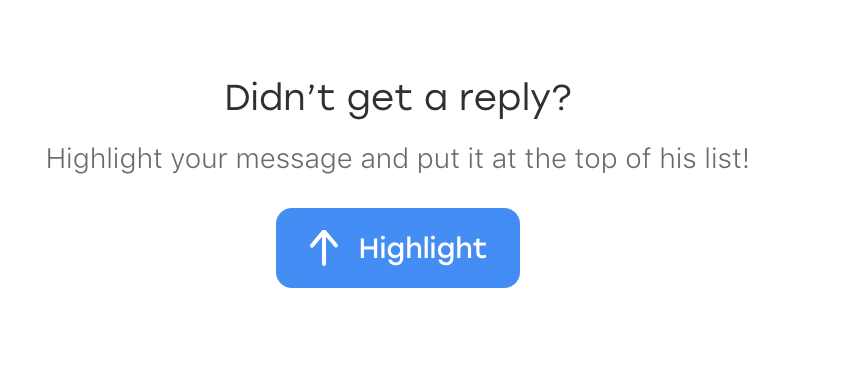
Und am lustigsten ist, dass es auch unter unseren Locator fällt. Nur hat es eine zusätzliche Klasse, die es von gesendeten Nachrichten unterscheidet:
p.message_text.highlight
Unser Test wurde nicht unterbrochen, als dieser Block angezeigt wurde, aber die Überprüfung "Warten auf das Erscheinen der Nachricht" war nicht mehr relevant. Das Element, das ein Indikator für eine erfolgreiche Veranstaltung war, ist jetzt immer da.
Schlussfolgerung: Wenn die Logik des Tests auf der Überprüfung des Erscheinungsbilds eines Elements basiert, muss vor unserer Interaktion mit der Benutzeroberfläche überprüft werden, ob es kein solches Element gibt.
- Benutzerprofil öffnen
- Öffnen Sie den Chat mit ihm
- Stellen Sie sicher, dass keine Nachrichten gesendet wurden
- eine Nachricht schreiben
- Senden
- Warten Sie, bis die Nachricht angezeigt wird.
Zufällige Daten
Sehr oft arbeiten UI-Tests mit Formularen, in die sie Daten eingeben. Zum Beispiel haben wir ein Anmeldeformular:
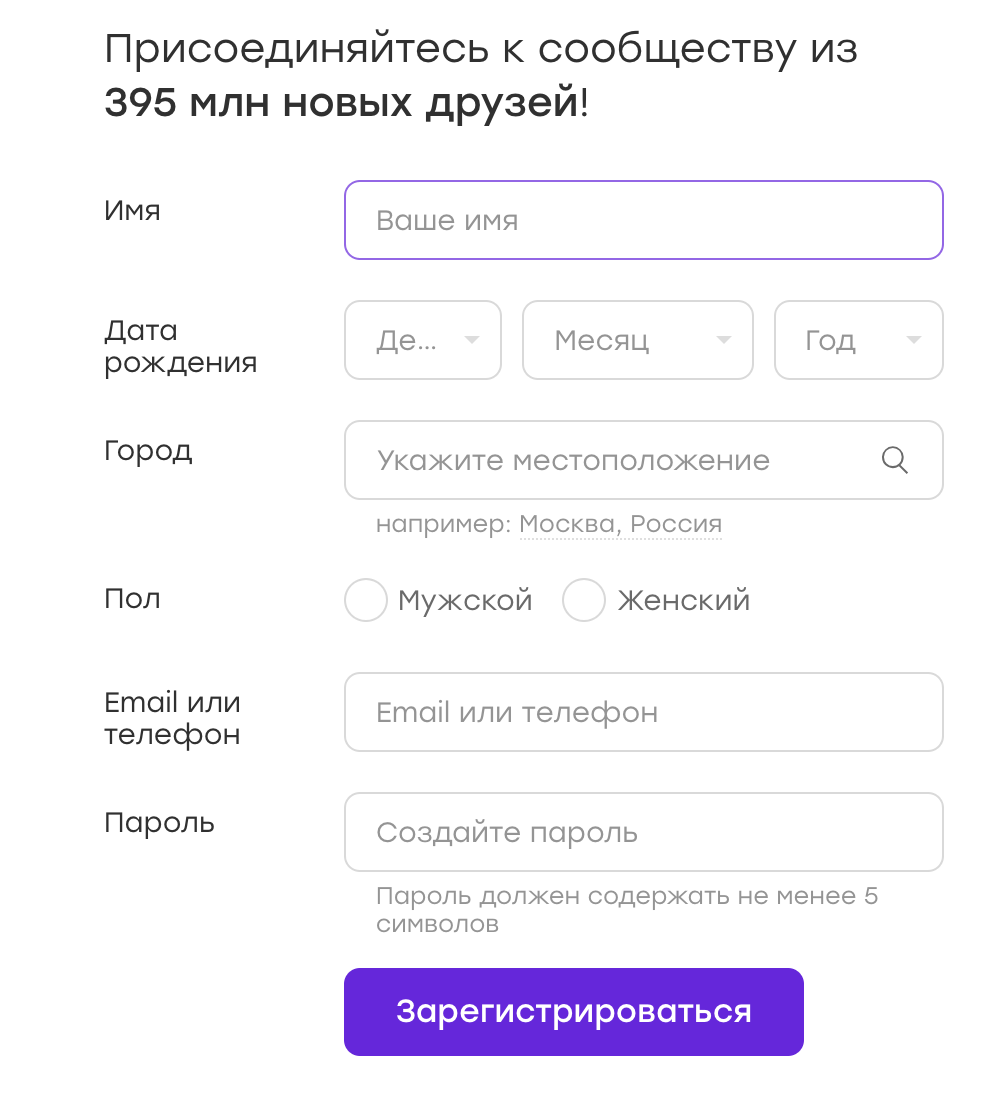
Daten für solche Tests können in Konfigurationen gespeichert oder in einem Test fest codiert werden. Aber manchmal kommt mir der Gedanke: Warum nicht die Daten randomisieren? Das ist gut, wir werden mehr Fälle abdecken!
Mein Rat: nicht. Und jetzt sage ich dir warum.
Angenommen, unser Test ist bei Badoo registriert. Wir entscheiden, dass wir das Geschlecht des Benutzers zufällig auswählen. Zum Zeitpunkt des Testschreibens ist der Registrierungsablauf für das Mädchen und den Jungen nicht anders, sodass unser Test erfolgreich bestanden wurde.
Stellen Sie sich nun vor, dass der Registrierungsfluss nach einer Weile anders wird. Zum Beispiel geben wir dem Mädchen sofort nach der Registrierung kostenlose Boni, über die wir sie mit einem speziellen Overlay informieren.
Im Test gibt es keine Logik zum Schließen der Überlagerung, diese stört jedoch alle weiteren im Test vorgeschriebenen Aktionen. Wir bekommen einen Test, der in 50% der Fälle fällt. Jedes Automatisierungstool bestätigt, dass UI-Tests von Natur aus nicht von Natur aus stabil sind. Und das ist normal, man muss damit leben und ständig zwischen redundanter Logik "für alle Gelegenheiten" (die die Lesbarkeit des Codes merklich beeinträchtigt und dessen Unterstützung erschwert) und dieser Instabilität selbst wechseln.
Wenn der Test das nächste Mal fällt, haben wir möglicherweise keine Zeit, uns damit zu befassen. Wir starten es einfach neu und sehen, dass es vorbei ist. Wir entscheiden, dass in unserer Anwendung alles so funktioniert, wie es sollte, und das Ding ist ein instabiler Test. Und beruhige dich.
Nun gehen wir weiter. Was ist, wenn diese Überlagerung bricht? Der Test wird in 50% der Fälle weiterhin bestanden, was die Suche nach dem Problem erheblich verzögert.
Und es ist gut, wenn wir aufgrund der Randomisierung von Daten eine "50 mal 50" -Situation erstellen. Aber es passiert anders. Vor der Registrierung wurde beispielsweise ein Kennwort mit mindestens drei Zeichen als akzeptabel angesehen. Wir schreiben Code, der ein zufälliges Passwort enthält, das nicht kürzer als drei Zeichen ist (manchmal drei Zeichen und manchmal mehr). Und dann ändert sich die Regel - und das Passwort sollte bereits mindestens vier Zeichen enthalten. Wie hoch ist in diesem Fall die Wahrscheinlichkeit eines Sturzes? Und wenn unser Test einen echten Fehler entdeckt, wie schnell werden wir ihn herausfinden?
Es ist besonders schwierig, mit Tests zu arbeiten, bei denen viele zufällige Daten eingegeben werden: Name, Geschlecht, Passwort usw. In diesem Fall gibt es auch viele verschiedene Kombinationen, und wenn in einer von ihnen ein Fehler auftritt, ist dies normalerweise schwer zu bemerken.
Fazit Wie ich oben geschrieben habe, ist das Randomisieren von Daten schlecht. Es ist natürlich besser, mehr Fälle auf Kosten der Datenanbieter abzudecken, ohne die
Äquivalenzklassen zu vergessen. Das Bestehen von Tests dauert länger, aber Sie können dagegen ankämpfen. Wir werden jedoch sicher sein, dass ein Problem erkannt wird.
Atomizität von Tests (Teil 1)
Schauen wir uns das folgende Beispiel an. Wir schreiben einen Test, der den Zähler der Benutzer in der Fußzeile überprüft.

Das Szenario ist einfach:
- Anwendung öffnen
- Fußzeilenzähler finden
- Stellen Sie sicher, dass es sichtbar ist
Wir nennen einen solchen Test testFooterCounter und führen ihn aus. Dann muss überprüft werden, ob der Zähler keine Null anzeigt. Wir fügen diesen Test einem vorhandenen Test hinzu. Warum nicht?
Dann muss jedoch überprüft werden, ob in der Fußzeile ein Link zur Beschreibung des Projekts vorhanden ist (der Link "Über uns"). Einen neuen Test schreiben oder zu einem bestehenden hinzufügen? Im Falle eines neuen Tests müssen wir die Anwendung erneut starten, den Benutzer vorbereiten (wenn wir die Fußzeile auf der autorisierten Seite überprüfen), uns anmelden - im Allgemeinen wertvolle Zeit verbringen. In einer solchen Situation scheint es eine gute Idee zu sein, den Test in testFooterCounterAndLinks umzubenennen.
Einerseits hat dieser Ansatz Vorteile: Zeit sparen, alle Überprüfungen eines Teils unserer Anwendung (in diesem Fall Fußzeile) an einem Ort speichern.
Aber es gibt ein merkliches Minus. Wenn der Test beim ersten Test fehlschlägt, wird der Rest der Komponente nicht überprüft. Angenommen, ein Test stürzt in einem Zweig ab, nicht aufgrund von Instabilität, sondern aufgrund eines Fehlers. Was zu tun ist? Eine Aufgabe zurückgeben, die nur dieses Problem beschreibt? Dann laufen wir Gefahr, eine Aufgabe zu bekommen, bei der nur dieser Fehler behoben wird, führen einen Test durch und stellen fest, dass die Komponente an einer anderen Stelle auch weiter defekt ist. Und es kann viele solcher Iterationen geben. Das Hin- und Herwerfen eines Tickets nimmt in diesem Fall viel Zeit in Anspruch und ist unwirksam.
Fazit: Wenn möglich, zerstäuben Sie die Schecks. In diesem Fall überprüfen wir alle anderen, auch wenn in einem Fall ein Problem vorliegt. Und wenn Sie das Ticket zurückgeben müssen, können wir sofort alle Problembereiche beschreiben.
Atomizität von Tests (Teil 2)
Betrachten Sie ein anderes Beispiel. Wir schreiben einen Chat-Test, der die folgende Logik überprüft. Wenn Benutzer gegenseitiges Mitgefühl haben, wird im Chat der folgende Promoblock angezeigt:

Das Szenario ist wie folgt:
- Stimmen Sie von Benutzer A für Benutzer B ab
- Stimmen Sie von Benutzer B für Benutzer A ab
- Benutzer A offener Chat mit Benutzer B.
- Vergewissern Sie sich, dass das Gerät installiert ist
Für einige Zeit funktioniert der Test erfolgreich, aber dann passiert Folgendes ... Nein, diesmal übersieht der Test keinen Fehler. :) :)
Nach einiger Zeit stellen wir fest, dass es einen weiteren Fehler gibt, der nicht mit unserem Test zusammenhängt: Wenn Sie einen Chat öffnen, ihn sofort schließen und wieder öffnen, verschwindet der Block. Nicht der offensichtlichste Fall, und im Test haben wir das natürlich nicht vorausgesehen. Aber wir entscheiden, dass wir es auch abdecken müssen.
Die gleiche Frage stellt sich: Schreiben Sie einen anderen Test oder fügen Sie einen Test in einen vorhandenen ein? Ein neues zu schreiben scheint unangemessen, da er in 99% der Fälle dasselbe tut wie das bestehende. Und wir beschließen, den Test zu dem bereits vorhandenen Test hinzuzufügen:
- Stimmen Sie von Benutzer A für Benutzer B ab
- Stimmen Sie von Benutzer B für Benutzer A ab
- Benutzer A offener Chat mit Benutzer B.
- Vergewissern Sie sich, dass das Gerät installiert ist
- Chat schließen
- Chat öffnen
- Vergewissern Sie sich, dass das Gerät installiert ist
Ein Problem kann auftreten, wenn wir beispielsweise einen Test nach langer Zeit umgestalten. Beispielsweise wird ein Projekt neu gestaltet - und Sie müssen viele Tests neu schreiben.
Wir werden den Test öffnen und versuchen, uns daran zu erinnern, was er überprüft. Ein Test heißt beispielsweise testPromoAfterMutualAttraction. Verstehen wir, warum das Öffnen und Schließen des Chats am Ende geschrieben wird? Höchstwahrscheinlich nicht. Vor allem, wenn dieser Test nicht von uns geschrieben wurde. Werden wir dieses Stück verlassen? Vielleicht ja, aber wenn es Probleme mit ihm gibt, werden wir ihn wahrscheinlich einfach löschen. Und die Überprüfung geht einfach verloren, weil ihre Bedeutung nicht offensichtlich ist.
Ich sehe hier zwei Lösungen. Erstens: Führen Sie immer noch den zweiten Test durch und nennen Sie ihn testCheckBlockPresentAfterOpenAndCloseChat. Mit einem solchen Namen wird klar, dass wir nicht nur eine bestimmte Reihe von Aktionen ausführen, sondern eine sehr bewusste Überprüfung durchführen, da es eine negative Erfahrung gab. Die zweite Lösung besteht darin, einen detaillierten Kommentar in den Code zu schreiben, warum wir diesen Test in diesem speziellen Test durchführen. Es ist auch ratsam, die Fehlernummer im Kommentar anzugeben.
Fehler beim Klicken auf ein vorhandenes Element
Das folgende Beispiel warf mir
Bbidox zu , wofür er ein großes Plus im Karma ist!
Es gibt eine sehr interessante Situation, wenn der Testcode bereits ... ein Framework wird. Angenommen, wir haben eine Methode wie diese:
public void clickSomeButton() { WebElement button_element = this.waitForButtonToAppear(); button_element.click(); }
Irgendwann passiert etwas Seltsames mit dieser Methode: Der Test stürzt ab, wenn Sie versuchen, auf eine Schaltfläche zu klicken. Wir öffnen den Screenshot, der zum Zeitpunkt des Testabsturzes aufgenommen wurde, und sehen, dass der Screenshot eine Schaltfläche enthält und die waitForButtonToAppear-Methode erfolgreich funktioniert hat. Frage: Was ist los mit dem Klick?
Das Schwierigste in dieser Situation ist, dass der Test manchmal erfolgreich sein kann. :) :)
Lass es uns richtig machen. Angenommen, die im Beispiel betrachtete Schaltfläche befindet sich auf einer solchen Überlagerung:
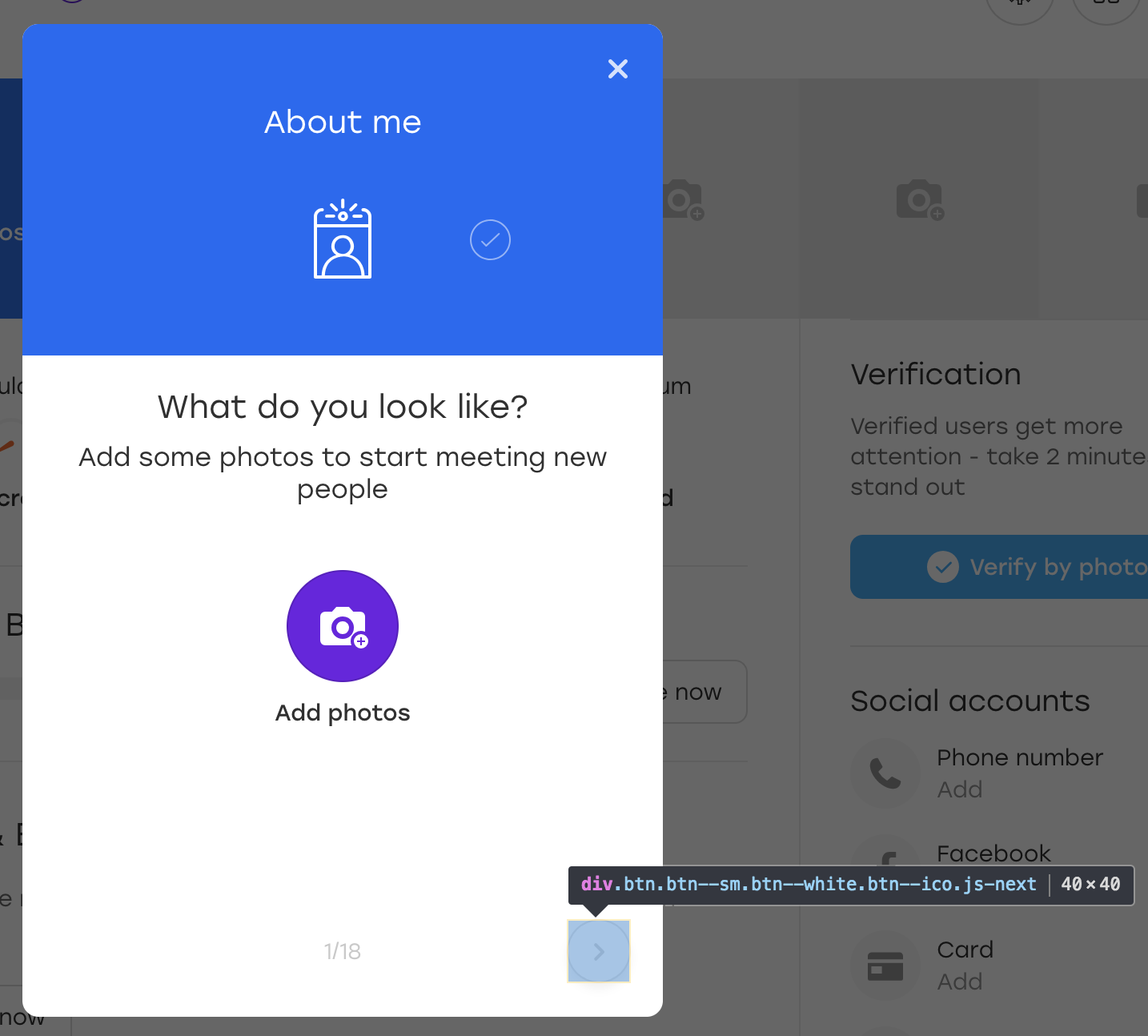
Dies ist eine spezielle Überlagerung, über die ein Benutzer unserer Website Informationen über sich selbst ausfüllen kann. Wenn Sie auf die hervorgehobene Überlagerungsschaltfläche klicken, wird der nächste Block gefüllt.
Fügen wir zum Spaß eine zusätzliche OLOLO-Klasse für diese Schaltfläche hinzu:
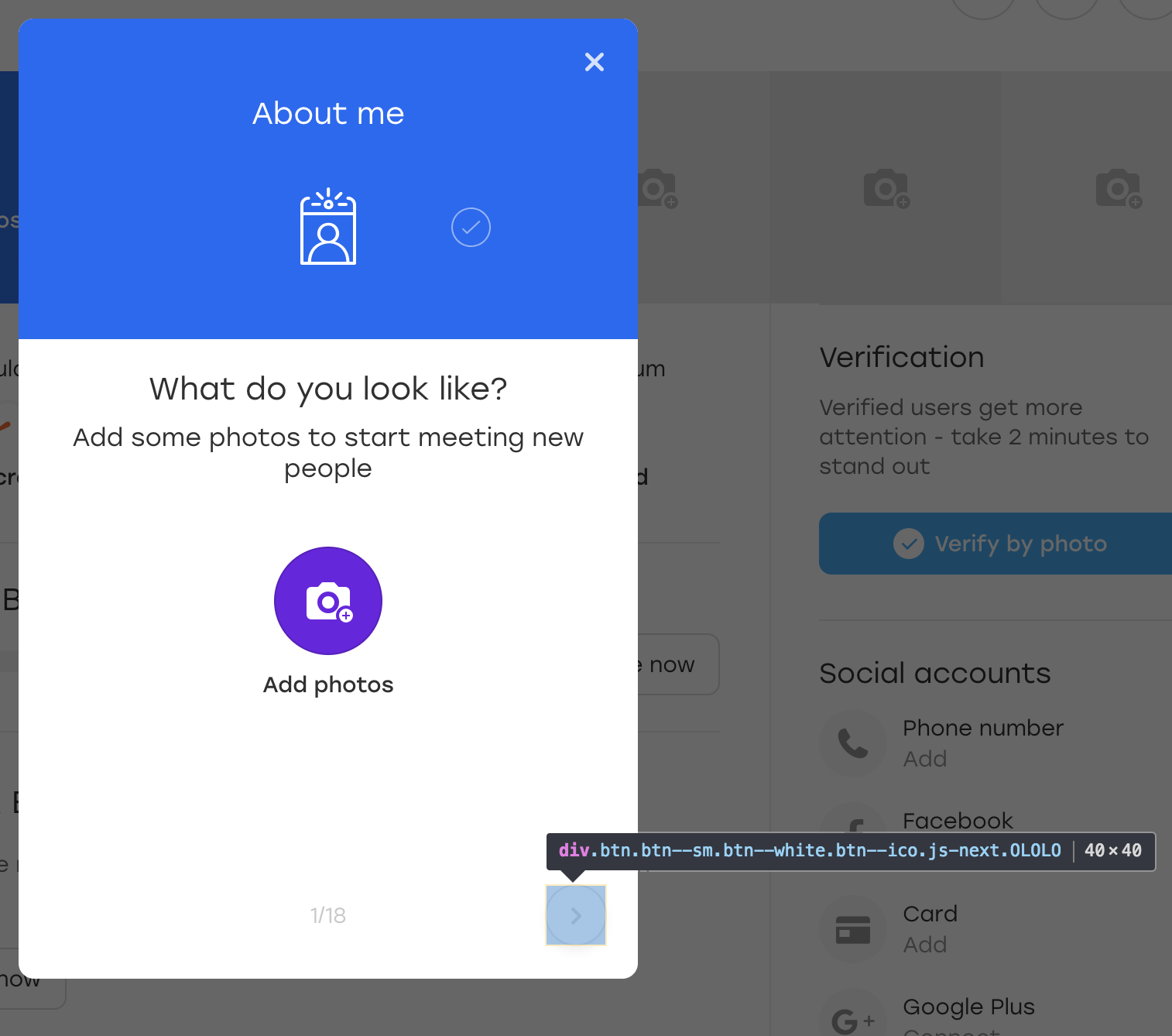
Danach klicken wir auf diese Schaltfläche. Optisch hat sich nichts geändert, aber der Knopf selbst ist an Ort und Stelle geblieben:
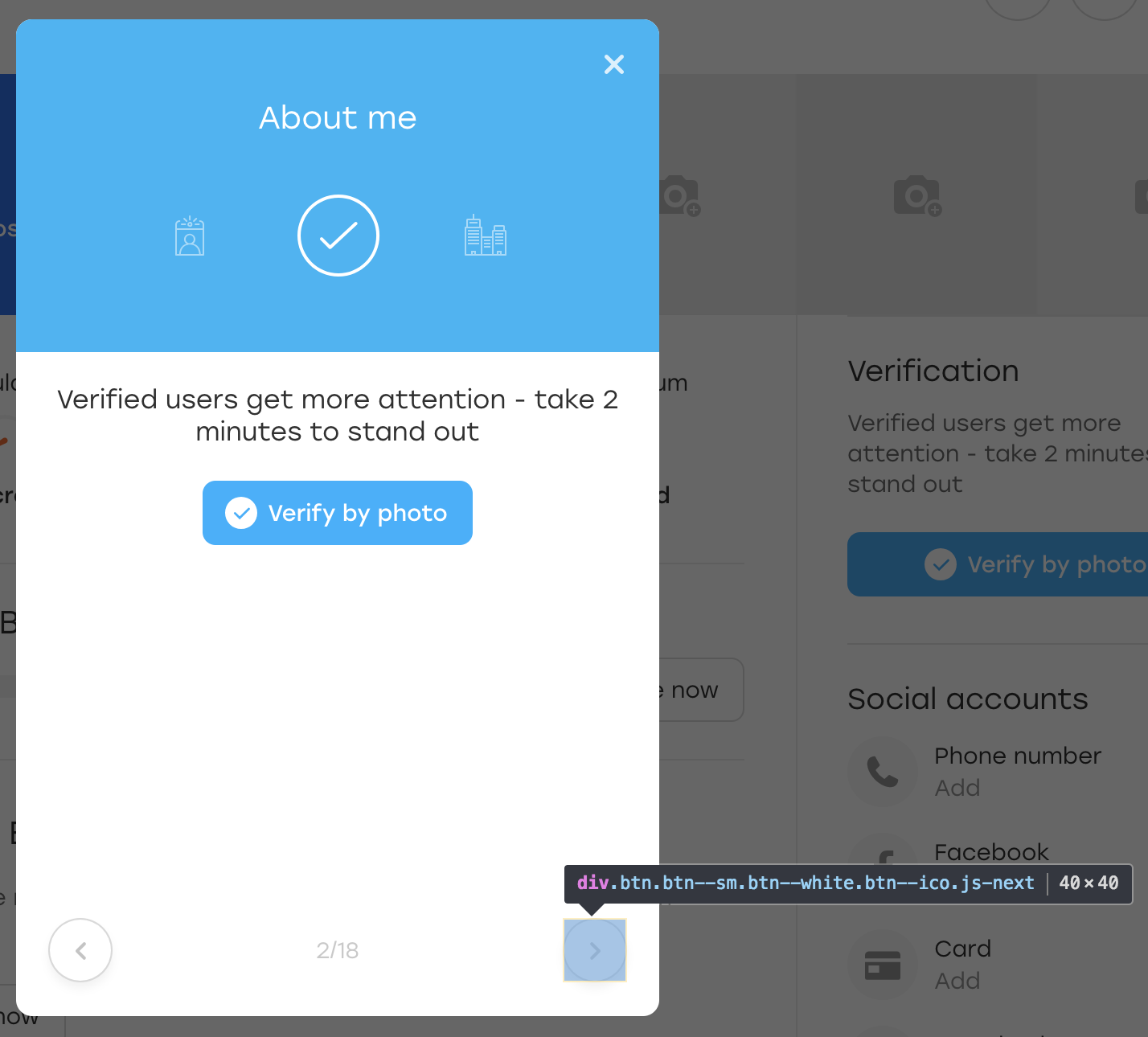
Was ist passiert? In der Tat, als JS den Block zu uns neu zeichnete, zeichnete er auch den Knopf neu. Es ist immer noch auf demselben Locator verfügbar, dies ist jedoch eine andere Schaltfläche. Dies wird durch das Fehlen der von uns hinzugefügten OLOLO-Klasse belegt.
Im obigen Code speichern wir das Element in der Variablen $ element. Wenn ein Element während dieser Zeit neu generiert wird, ist es möglicherweise nicht visuell sichtbar, aber Sie können nicht mehr darauf klicken - die click () -Methode schlägt fehl.
Es gibt verschiedene Lösungen:
- Wrap Click in Try Block und in Catch Rebuild Element
- Fügen Sie einem Attribut eine Schaltfläche hinzu, um zu signalisieren, dass es sich geändert hat
Fehlertext
Schließlich ein einfacher, aber nicht weniger wichtiger Punkt.
Dieses Beispiel gilt nicht nur für UI-Tests, sondern tritt auch sehr häufig in diesen auf. Wenn Sie einen Test schreiben, befinden Sie sich normalerweise im Kontext des Geschehens: Sie beschreiben die Überprüfung nach der Überprüfung und verstehen deren Bedeutung. Und Sie schreiben Fehlertexte im selben Kontext:
WebElement element = this.waitForPresence(By.css("a.link"), "Cannot find button");
Was könnte in diesem Code unverständlich sein? Der Test erwartet das Erscheinen einer Taste und fällt natürlich ab, wenn sie nicht vorhanden ist.
Stellen Sie sich nun vor, der Autor des Tests ist krankgeschrieben und sein Kollege kümmert sich um die Tests. Anschließend löscht er den TestQuestionsOnProfile-Test und schreibt die folgende Meldung: "Schaltfläche kann nicht gefunden werden". Ein Kollege muss so schnell wie möglich verstehen, was passiert, da die Veröffentlichung bald kommt.
Was wird er tun müssen?
Es ist sinnlos, die Seite zu öffnen, auf die der Test gefallen ist, und den Locator "a.link" zu überprüfen - es gibt kein Element. Daher müssen Sie den Test sorgfältig studieren und herausfinden, was er überprüft.
Mit einem detaillierteren Fehlertext wäre es viel einfacher: "Die Schaltfläche" Senden "in der Fragenüberlagerung kann nicht gefunden werden." Mit einem solchen Fehler können Sie das Overlay sofort öffnen und sehen, wohin die Schaltfläche gegangen ist.
Ausgabe zwei. Erstens lohnt es sich, den Fehlertext an eine beliebige Methode Ihres Testframeworks zu übergeben, und es ist ein erforderlicher Parameter, damit keine Versuchung besteht, ihn zu vergessen. Zweitens sollte der Fehlertext detailliert gemacht werden. Dies bedeutet nicht immer, dass es lang sein sollte, es reicht aus, um klar zu machen, was im Test schief gelaufen ist.
Wie kann man verstehen, dass der Fehlertext gut geschrieben ist? Sehr einfach. Stellen Sie sich vor, Ihre Anwendung ist fehlerhaft und Sie müssen zu den Entwicklern gehen und erklären, was und wo fehlerhaft ist. Wenn Sie ihnen nur sagen, was im Fehlertext geschrieben steht, werden sie dann verstehen?
Zusammenfassung
Das Schreiben eines Testskripts ist oft eine interessante Aktivität. Gleichzeitig verfolgen wir viele Ziele. Unsere Tests sollten:
- decken Sie so viele Fälle wie möglich ab
- arbeite so schnell wie möglich
- verstanden werden
- einfach erweitern
- leicht zu pflegen
- Pizza bestellen
- usw…
Es ist besonders interessant, mit Tests in einem sich ständig weiterentwickelnden und ändernden Projekt zu arbeiten, in dem sie ständig aktualisiert werden müssen: etwas hinzufügen und etwas schneiden. Deshalb lohnt es sich, einige Punkte im Voraus zu überdenken und nicht immer Entscheidungen zu treffen. :) :)
Ich hoffe, meine Tipps helfen Ihnen dabei, einige Probleme zu vermeiden und Sie in Fallstudien nachdenklicher zu machen. Wenn das Publikum den Artikel mag, werde ich versuchen, einige langweiligere Beispiele zu sammeln. In der Zwischenzeit - tschüss!