Zeit, das Sparschwein guter russischsprachiger Berichte über maschinelles Lernen aufzufüllen! Das Sparschwein selbst wird nicht aufgefüllt!
Dieses Mal werden wir
Andrei Boyarovs faszinierende Geschichte über die
Szenenerkennung kennenlernen. Andrey ist ein Computer Vision-Forscher, der sich bei der Mail.Ru Group mit Machine Vision beschäftigt.
Die Szenenerkennung ist einer der weit verbreiteten Bereiche der Bildverarbeitung. Diese Aufgabe ist komplizierter als das untersuchte Erkennen von Objekten: Die Szene ist ein komplexeres und weniger formalisiertes Konzept, es ist schwieriger, Merkmale zu unterscheiden. Die Aufgabe, Sehenswürdigkeiten zu erkennen, ergibt sich aus der Szenenerkennung: Sie müssen bekannte Stellen auf dem Foto hervorheben, um eine geringe Anzahl von Fehlalarmen sicherzustellen.
Dies sind
30 Minuten Video von der Smart Data 2017-Konferenz. Das Video kann bequem zu Hause und unterwegs angesehen werden. Für diejenigen, die nicht bereit sind, so viel auf dem Bildschirm zu sitzen, oder die Informationen lieber in Textform wahrnehmen möchten, wenden wir eine Volltextentschlüsselung an, die in Form von Habrosta gestaltet ist.
Ich mache Bildverarbeitung bei Mail.ru. Heute werde ich darüber sprechen, wie wir durch tiefes Lernen Bilder von Szenen und Attraktionen erkennen.
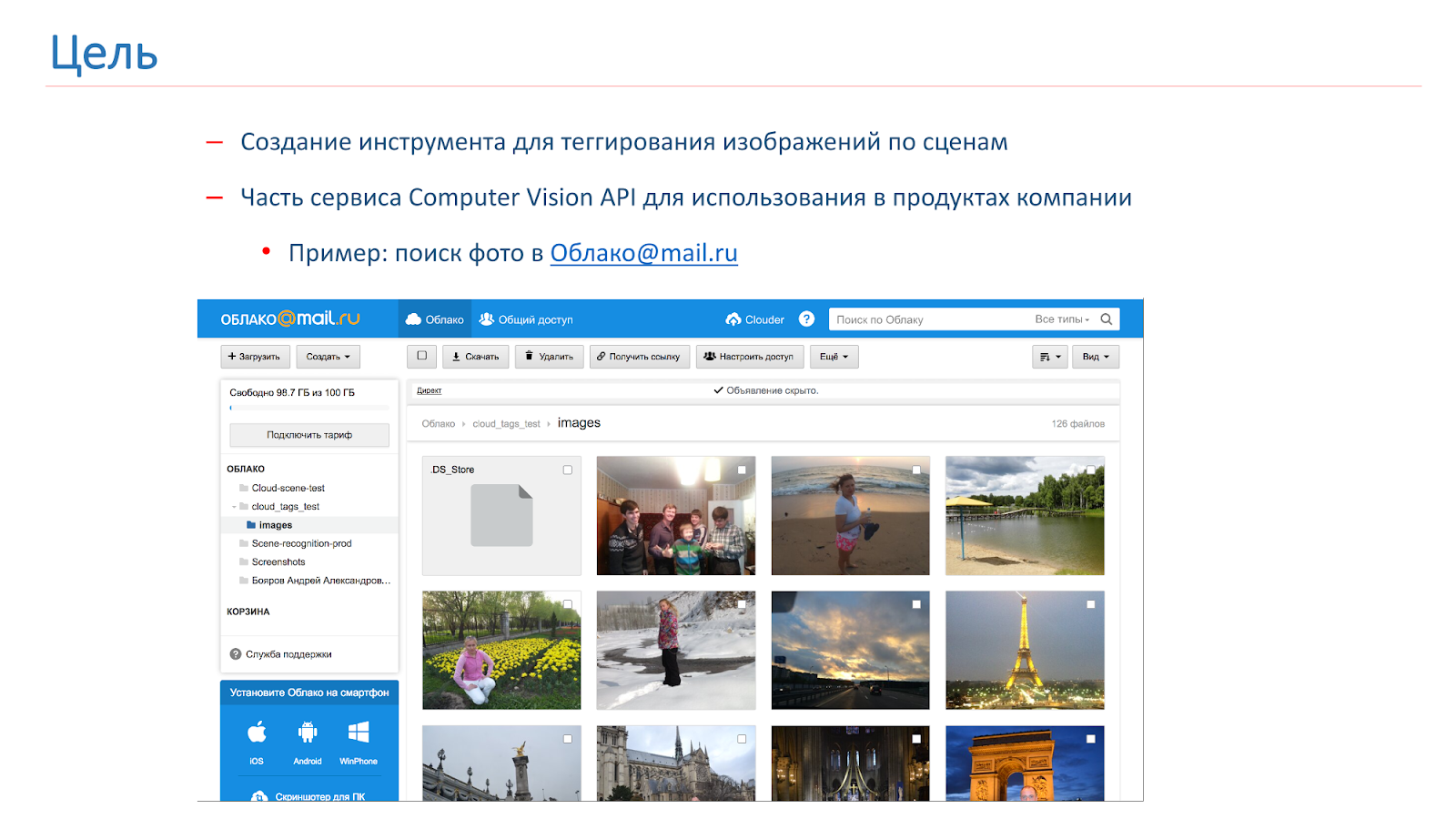
Das Unternehmen stellte die Notwendigkeit fest, Benutzerbilder zu markieren und zu suchen. Aus diesem Grund haben wir beschlossen, eine eigene Computer Vision-API zu erstellen, zu der auch ein Tool zum Markieren von Szenen gehören wird. Als Ergebnis dieses Tools möchten wir etwas wie das im Bild unten gezeigte erhalten: Der Benutzer stellt eine Anfrage, zum Beispiel "Kathedrale", und erhält alle seine Fotos mit Kathedralen.
In der Computer Vision-Community wurde das Thema Objekterkennung in Bildern recht gut untersucht. Es gibt einen bekannten
ImageNet-Wettbewerb , der seit mehreren Jahren stattfindet und dessen Hauptteil die Objekterkennung ist.
Grundsätzlich müssen wir ein Objekt lokalisieren und klassifizieren. Bei Szenen ist die Aufgabe etwas komplizierter, da die Szene ein komplexeres Objekt ist, aus einer großen Anzahl anderer Objekte besteht und der Kontext sie vereint, sodass die Aufgaben unterschiedlich sind.

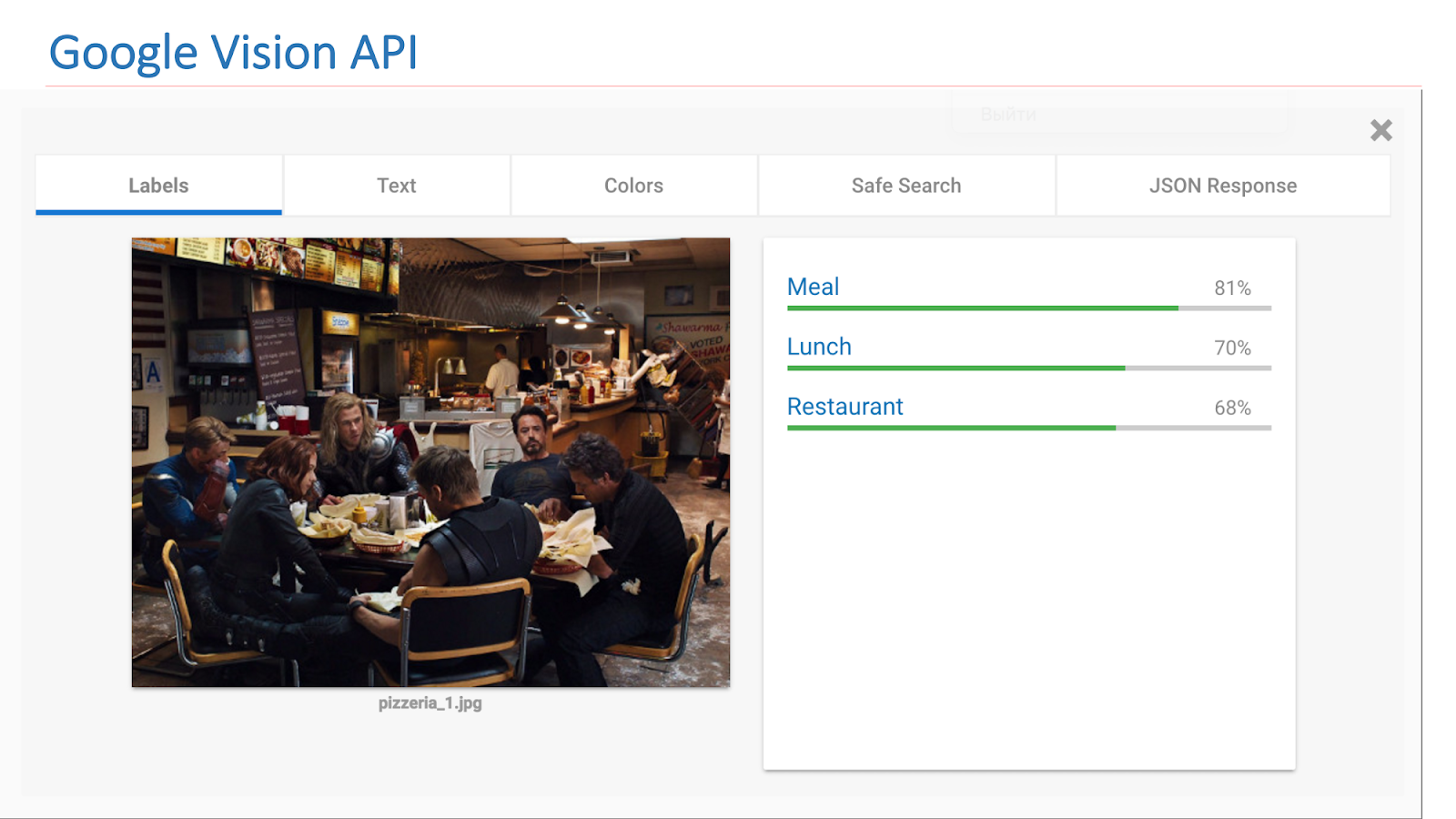
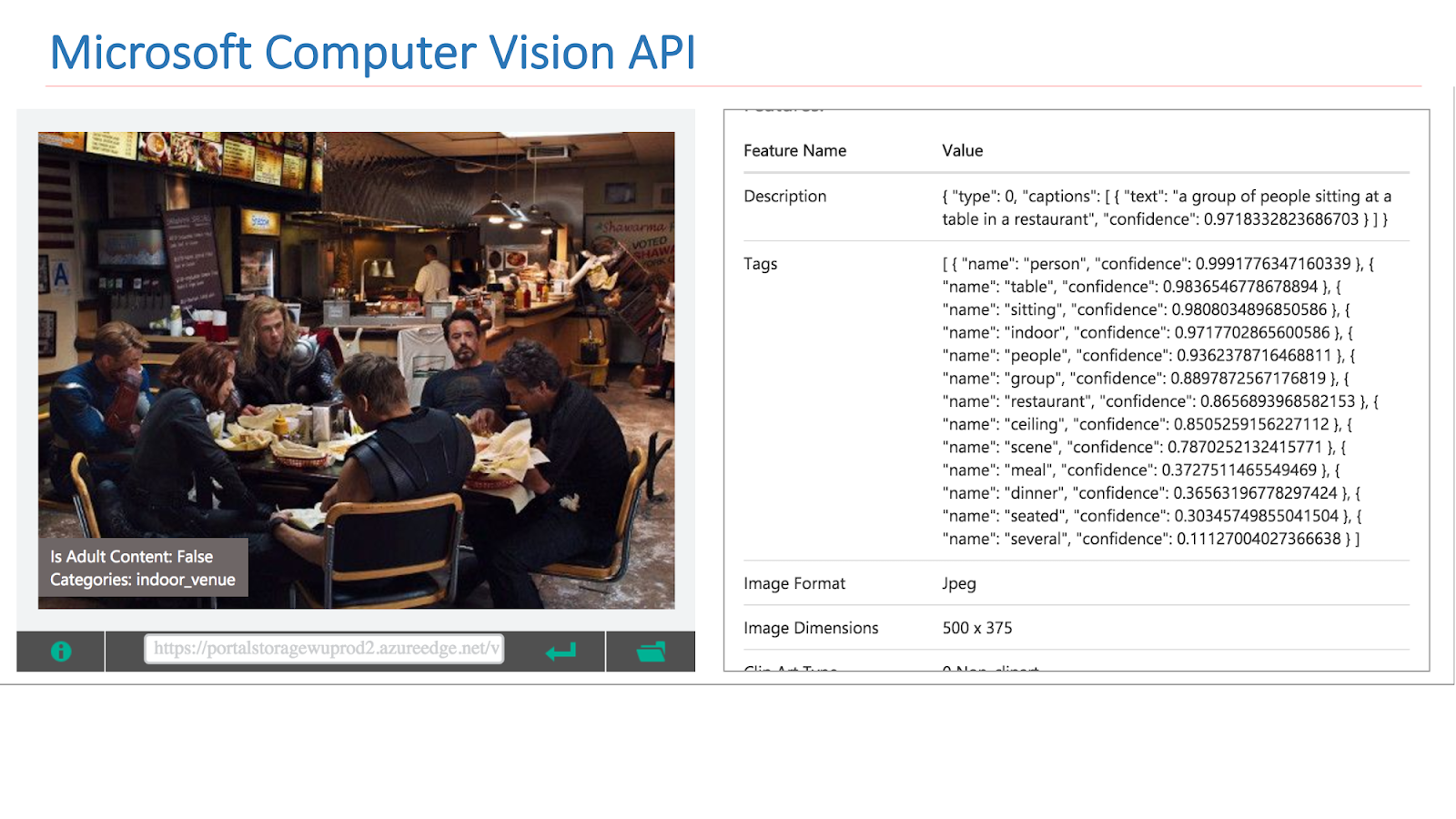
Im Internet stehen Dienste anderer Unternehmen zur Verfügung, die solche Funktionen implementieren. Dies ist insbesondere die Google Vision-API oder die Microsoft Computer Vision-API, mit der Szenen in Bildern gefunden werden können.
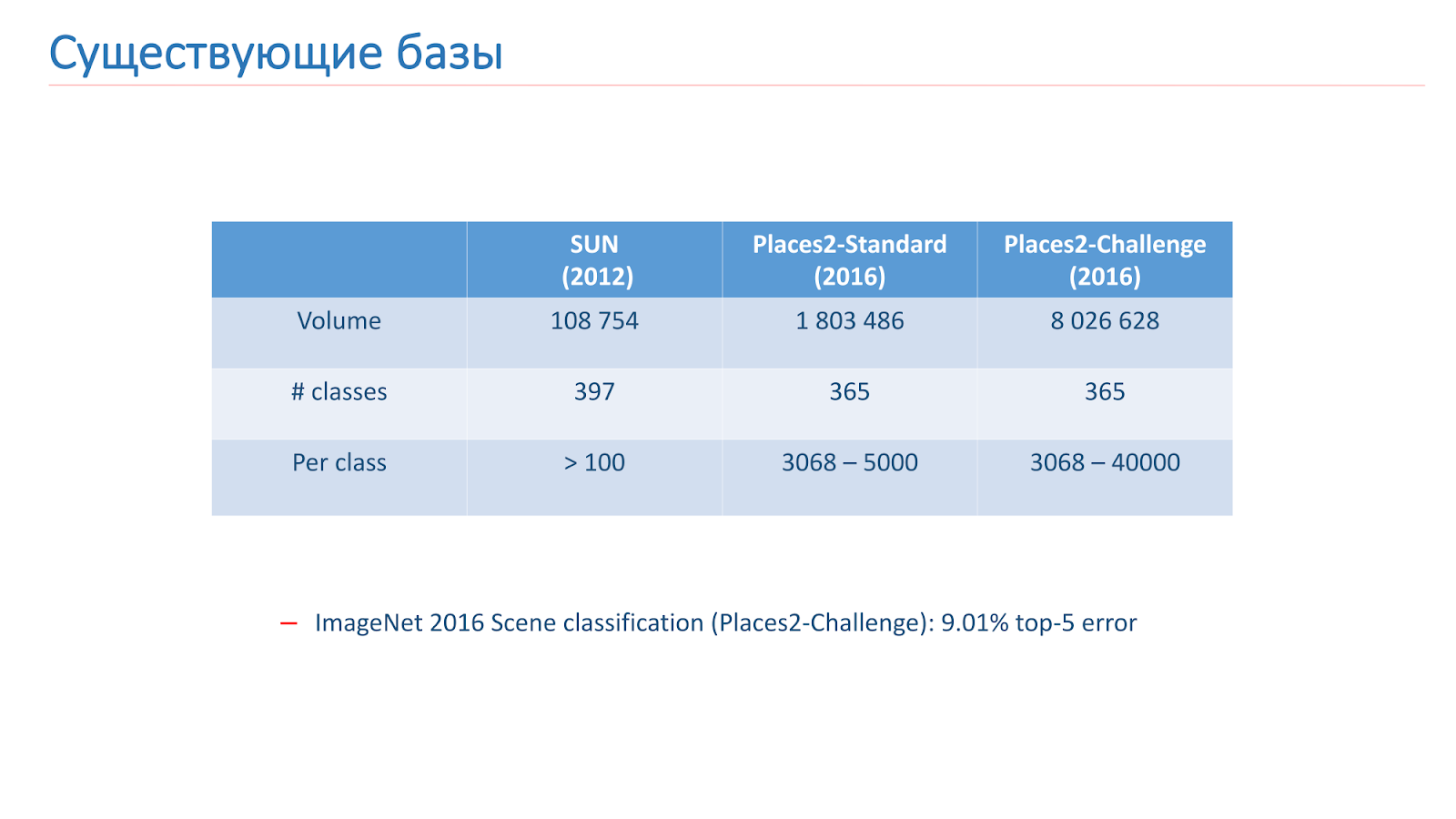
Wir haben dieses Problem mit Hilfe des maschinellen Lernens gelöst, daher benötigen wir Daten. Es gibt jetzt zwei Hauptgrundlagen für die Szenenerkennung im Open Access. Der erste von ihnen erschien 2013 - dies ist
die SUN-Basis der Princeton University. Diese Basis besteht aus Hunderttausenden von Bildern und 397 Klassen.
Die zweite Basis, auf der wir trainiert haben, ist
die Places2-Basis vom MIT. Sie erschien 2013 in zwei Versionen. Das erste ist Places2-Standart, eine ausgewogenere Basis mit 1,8 Millionen Bildern und 365 Klassen. Die zweite Option - Places2-Challenge - enthält acht Millionen Bilder und 365 Klassen, aber die Anzahl der Bilder zwischen den Klassen ist nicht ausgeglichen. Beim ImageNet-Wettbewerb 2016 enthielt der Bereich Szenenerkennung die Places2-Challenge, und der Gewinner zeigte das beste
Top-5-Klassifizierungsfehlerergebnis von etwa 9%.
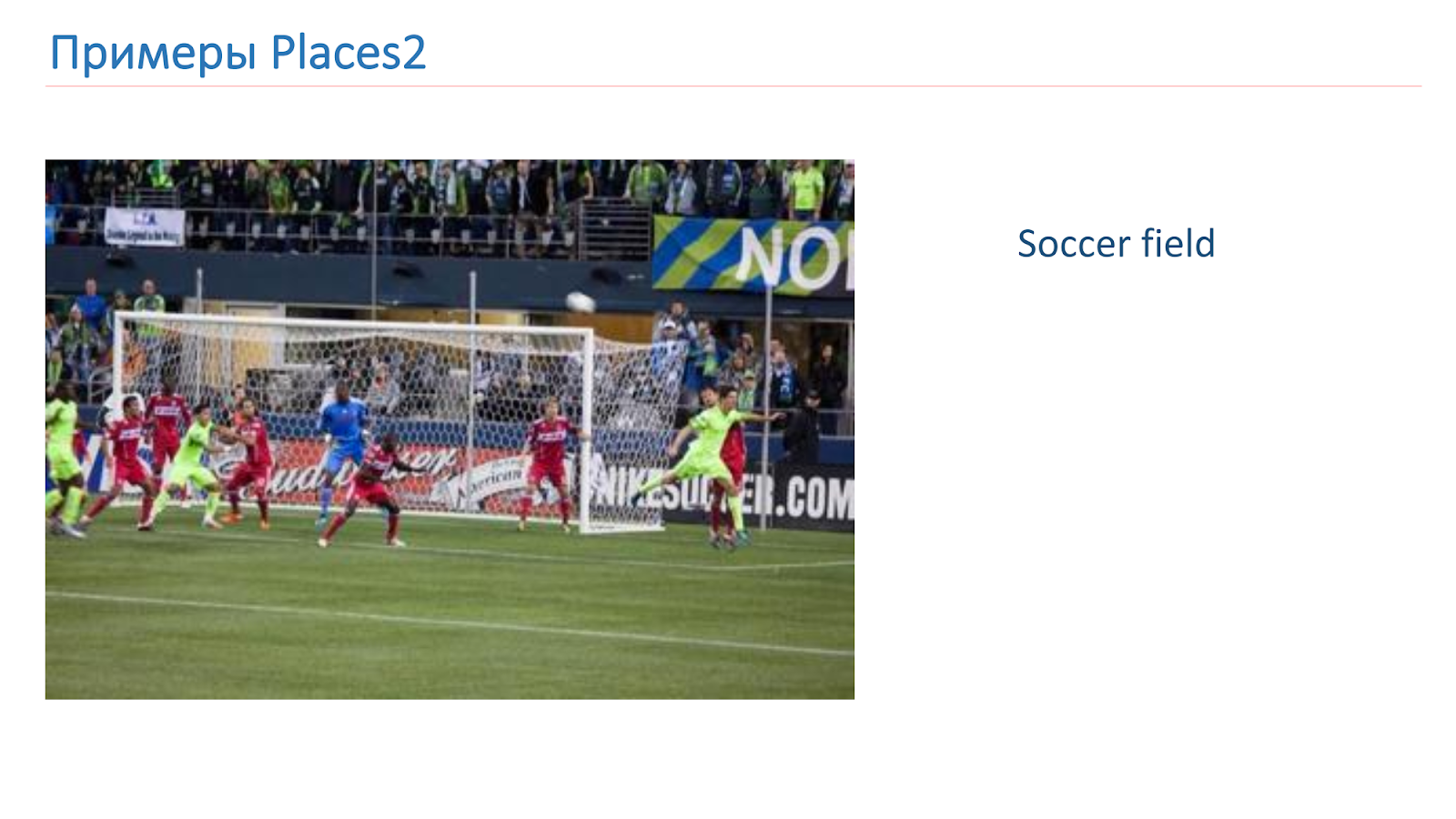
Wir haben auf Basis von Places2 trainiert. Hier ist ein Beispielbild von dort: Es ist eine Schlucht, eine Landebahn, eine Küche, ein Fußballplatz. Dies sind völlig unterschiedliche komplexe Objekte, an denen wir lernen müssen, sie zu erkennen.

Vor dem Studium haben wir die Grundlagen an unsere Bedürfnisse angepasst. Es gibt einen Trick für die Objekterkennung, wenn Sie mit Modellen auf kleinen CIFAR-10- und CIFAR-100-Basen anstelle von ImageNet experimentieren, und nur dann trainieren die besten auf ImageNet.
Wir beschlossen, den gleichen Weg zu gehen, nahmen die SUN-Datenbank, reduzierten sie, erhielten 89 Klassen, 50.000 Bilder im Zug und 10.000 Bilder bei der Validierung. Aus diesem Grund haben wir vor dem Training auf Places2 Experimente durchgeführt und unsere Modelle basierend auf SUN getestet. Das Training dauert nur 6-10 Stunden, im Gegensatz zu mehreren Tagen auf Places2, wodurch viel mehr Experimente durchgeführt und die Effektivität gesteigert werden konnten.
Wir haben uns auch die Places2-Datenbank selbst angesehen und festgestellt, dass wir einige Klassen nicht benötigen. Entweder aus Produktionsgründen oder weil zu wenig Daten darüber vorliegen, schneiden wir Klassen aus, wie zum Beispiel ein Aquädukt, ein Baumhaus oder ein Scheunentor.

Als Ergebnis haben wir nach all den Manipulationen die Places2-Datenbank erhalten, die 314 Klassen und eine halbe Million Bilder (in der Standardversion) enthält, in der Challenge-Version etwa 7,5 Millionen Bilder. Auf diesen Grundlagen haben wir Schulungen aufgebaut.
Außerdem haben wir beim Betrachten der verbleibenden Klassen festgestellt, dass es zu viele für die Produktion gibt, sie sind zu detailliert. Aus diesem Grund haben wir den Szenenzuordnungsmechanismus angewendet, wenn einige Klassen zu einer gemeinsamen Klasse zusammengefasst wurden. Zum Beispiel haben wir alles, was mit Wäldern zu tun hat, zu einem Wald verbunden, alles, was mit Krankenhäusern zu tun hat - zu einem Krankenhaus, zu Hotels - zu einem Hotel.
Wir verwenden die Szenenzuordnung nur zum Testen und für den Endbenutzer, da dies bequemer ist. Im Training verwenden wir alle Standardklassen 314. Wir haben die resultierende Basis Places Sift genannt.
Ansätze, Lösungen
Betrachten Sie nun die Ansätze, mit denen wir dieses Problem gelöst haben. Tatsächlich sind solche Aufgaben mit dem klassischen Ansatz verbunden - tiefen Faltungs-Neuronalen Netzen.
Das Bild unten zeigt eines der ersten klassischen Netzwerke, enthält jedoch bereits die Hauptbausteine, die in modernen Netzwerken verwendet werden.

Dies sind Faltungsschichten, dies sind Zugschichten, vollständig verbundene Schichten. Um die Architektur zu bestimmen, haben wir die Spitzen der ImageNet- und Places2-Wettbewerbe überprüft.

Wir können sagen, dass die wichtigsten führenden Architekturen in zwei Familien unterteilt werden können: Inception und die ResNet-Familie (Residual Network). Im Verlauf der Experimente haben wir herausgefunden, dass die ResNet-Familie besser für unsere Aufgabe geeignet ist, und wir haben das nächste Experiment mit dieser Familie durchgeführt.

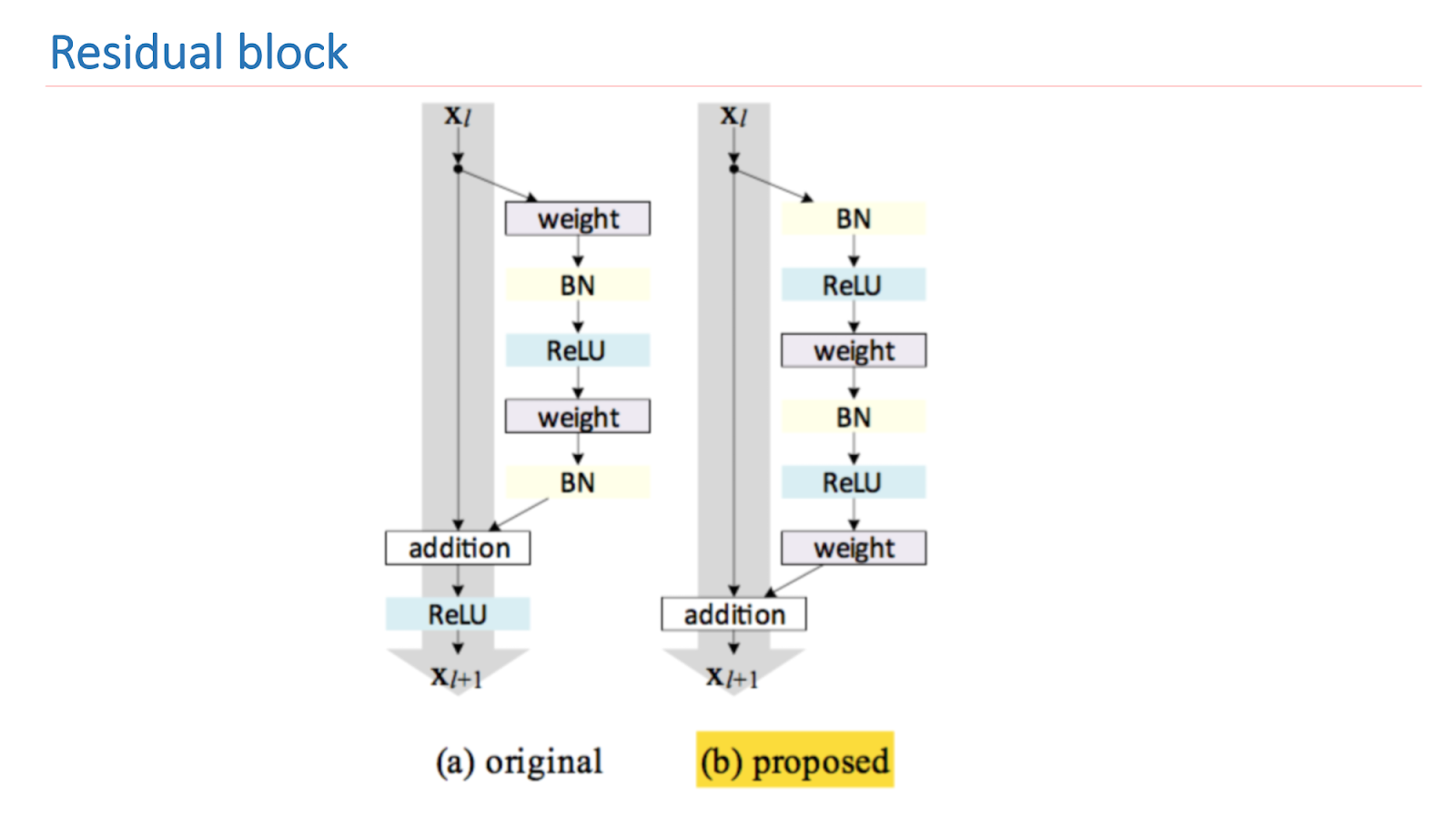
ResNet ist ein tiefes Netzwerk, das aus einer großen Anzahl von Restblöcken besteht. Dies ist der Hauptbaustein, der aus mehreren Schichten mit Gewichten und Verknüpfungsverbindung besteht. Infolge dieses Entwurfs lernt diese Einheit, wie stark sich das Eingangssignal x vom Ausgang f (x) unterscheidet. Infolgedessen können wir Netzwerke solcher Blöcke aufbauen, und während des Trainings kann das Netzwerk in den letzten Schichten Gewichte nahe Null erzeugen.
Wir können also sagen, dass das Netzwerk selbst entscheidet, wie tief es sein muss, um einige der Aufgaben zu lösen. Dank dieser Architektur können Netzwerke mit sehr großer Tiefe mit einer sehr großen Anzahl von Schichten aufgebaut werden. Der Gewinner von ImageNet 2014 enthielt nur 22 Ebenen, ResNet übertraf dieses Ergebnis und enthielt bereits 152 Ebenen.
Die Kernforschung von ResNet besteht darin, einen Restblock zu verbessern und ordnungsgemäß zu erstellen. Das Bild unten zeigt eine empirisch und mathematisch fundierte Version, die das beste Ergebnis liefert. Eine solche Konstruktion des Blocks ermöglicht es Ihnen, sich mit einem der grundlegenden Probleme des tiefen Lernens zu befassen - einem verblassenden Gradienten.
Um unsere Netzwerke zu trainieren, haben wir das in Lua geschriebene Torch-Framework aufgrund seiner Flexibilität und Geschwindigkeit verwendet und für ResNet die
Implementierung von ResNet von Facebook vorangetrieben . Um die Qualität des Netzwerks zu überprüfen, haben wir drei Tests verwendet.
Der erste Places-Val-Test ist die Validierung vieler Places-Sift-Sets. Der zweite Test ist Places Sift mit Scene Mapping und der dritte ist der Cloud-Test, der der Kampfsituation am nächsten kommt. Bilder von Mitarbeitern aus der Cloud, die manuell beschriftet wurden. Im Bild unten gibt es zwei Beispiele für solche Bilder.

Wir haben begonnen, Netzwerke zu messen, zu trainieren und miteinander zu vergleichen. Der erste ist der ResNet-152-Benchmark, der mit Places2 geliefert wird, der zweite ist ResNet-50, den wir auf ImageNet trainiert und auf unserer Basis trainiert haben. Das Ergebnis war bereits besser. Dann nahmen sie ResNet-200, das ebenfalls auf ImageNet trainiert wurde, und es zeigte am Ende das beste Ergebnis.

Nachfolgend finden Sie Beispiele für Arbeiten. Dies ist ein ResNet-152-Benchmark. Vorausgesagt werden die Originaletiketten, die das Netzwerk ausgibt. Zugeordnete Etiketten sind die Beschriftungen, die nach der Szenenzuordnung erstellt wurden. Es ist ersichtlich, dass das Ergebnis nicht sehr gut ist. Das heißt, sie scheint etwas zu dem Fall zu geben, aber nicht sehr gut.

Das nächste Beispiel ist der Betrieb von ResNet-200. Schon sehr ausreichend.

ResNet-Verbesserung
Wir haben uns entschlossen, unser Netzwerk zu verbessern, und zuerst haben wir nur versucht, die Tiefe des Netzwerks zu erhöhen, aber danach wurde es viel schwieriger zu trainieren. Dies ist ein bekanntes Problem. Letztes Jahr wurden mehrere Artikel zu diesem Thema veröffentlicht, die besagen, dass ResNet tatsächlich ein Ensemble einer großen Anzahl gewöhnlicher Netzwerke unterschiedlicher Tiefe ist.
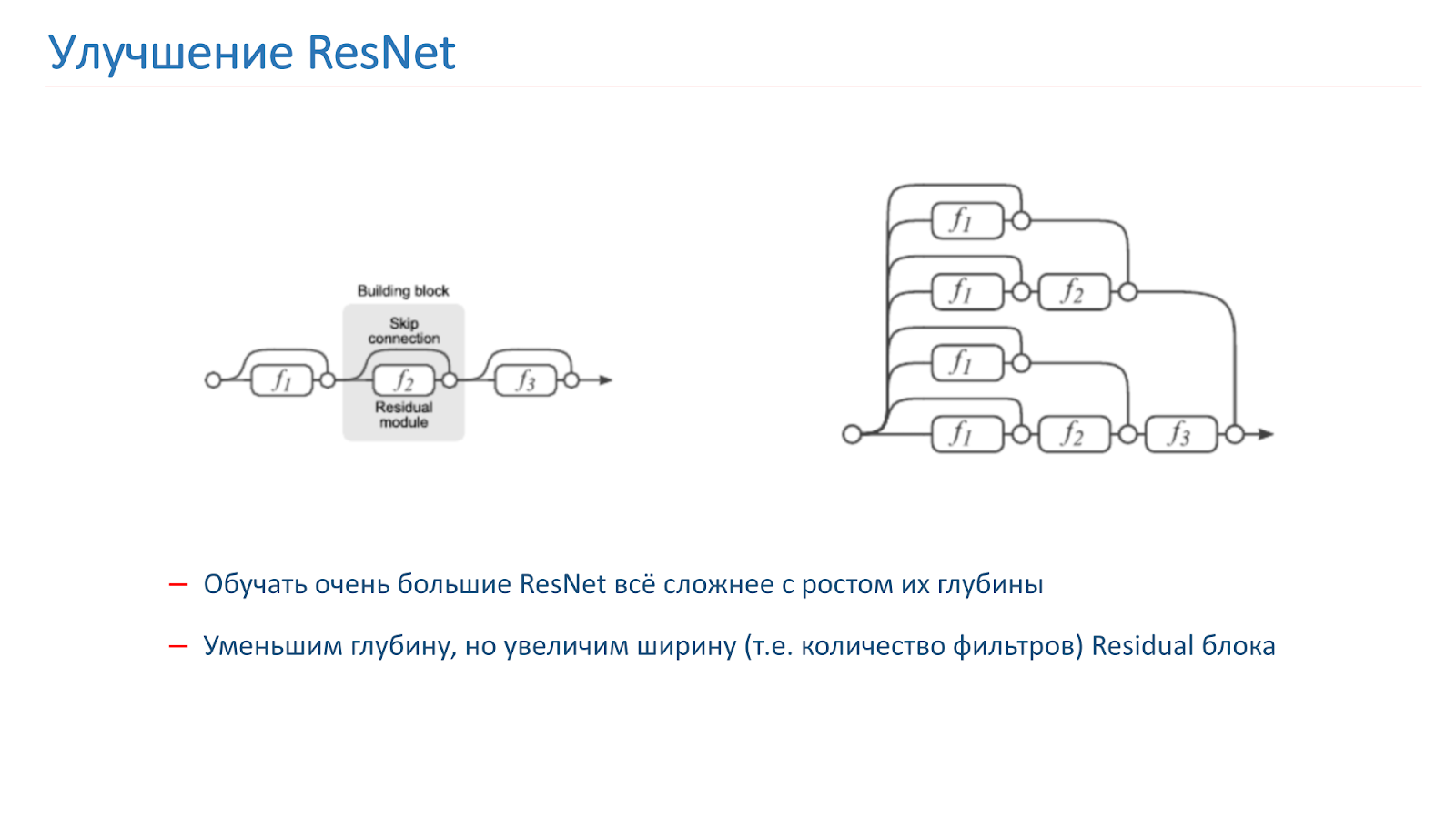
Res-Blöcke, die sich am Ende des Gitters befinden, tragen einen kleinen Beitrag zur Bildung des Endergebnisses bei. Es erscheint vielversprechender, nicht die Netzwerktiefe, sondern die Breite, dh die Anzahl der Filter im Res-Block, zu erhöhen.
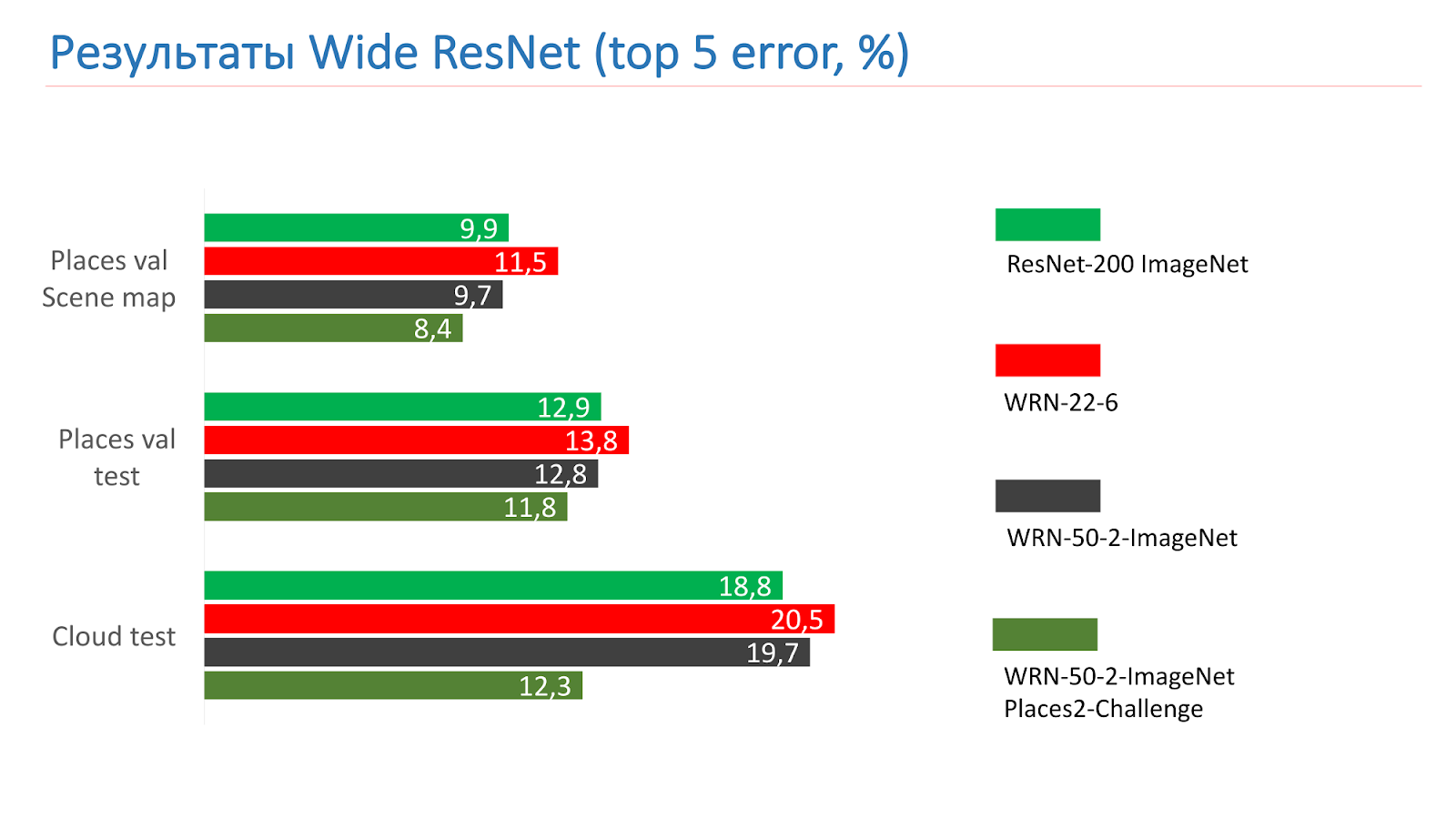
Diese Idee wird vom Wide Residual Network umgesetzt, das 2016 erschien. Am Ende haben wir WRN-50-2 verwendet, das übliche ResNet-50 mit der doppelten Anzahl von Filtern in der 3x3-Faltung des inneren Engpasses.

Das Netzwerk zeigt auf ImageNet ähnliche Ergebnisse mit dem ResNet-200, das wir bereits verwendet haben, aber vor allem ist es fast doppelt so schnell. Hier sind zwei Implementierungen des Restblocks auf der Taschenlampe: Der Parameter, der verdoppelt wird, wird hell hervorgehoben. Dies ist die Anzahl der Filter in der inneren Faltung.

Dies sind Messungen bei den ResNet-200 ImageNet-Tests. Zuerst nahmen wir WRN-22-6, es zeigte ein schlechteres Ergebnis. Dann nahmen sie WRN-50-2-ImageNet, trainierten ihn, nahmen WRN-50-2, trainierten auf ImageNet und trainierten ihn auf Places2-Challenge, und er zeigte das beste Ergebnis.
Hier ist ein Beispiel für den WRN-50-2 - ein völlig angemessenes Ergebnis in unseren Bildern, die Sie bereits gesehen haben.

Und dies ist ein Beispiel für die erfolgreiche Arbeit mit Kampffotografien.

Es gibt natürlich nicht sehr erfolgreiche Arbeiten. Die Brücke von Alexander III. In Paris wurde nicht als Brücke anerkannt.

Modellverbesserung
Wir haben darüber nachgedacht, wie wir dieses Modell verbessern können. Die ResNet-Familie verbessert sich weiter und es erscheinen neue Artikel. Insbesondere wurde 2016 ein interessanter Artikel PyramidNet veröffentlicht, der vielversprechende Ergebnisse zu CIFAR-10/100 und ImageNet zeigte.
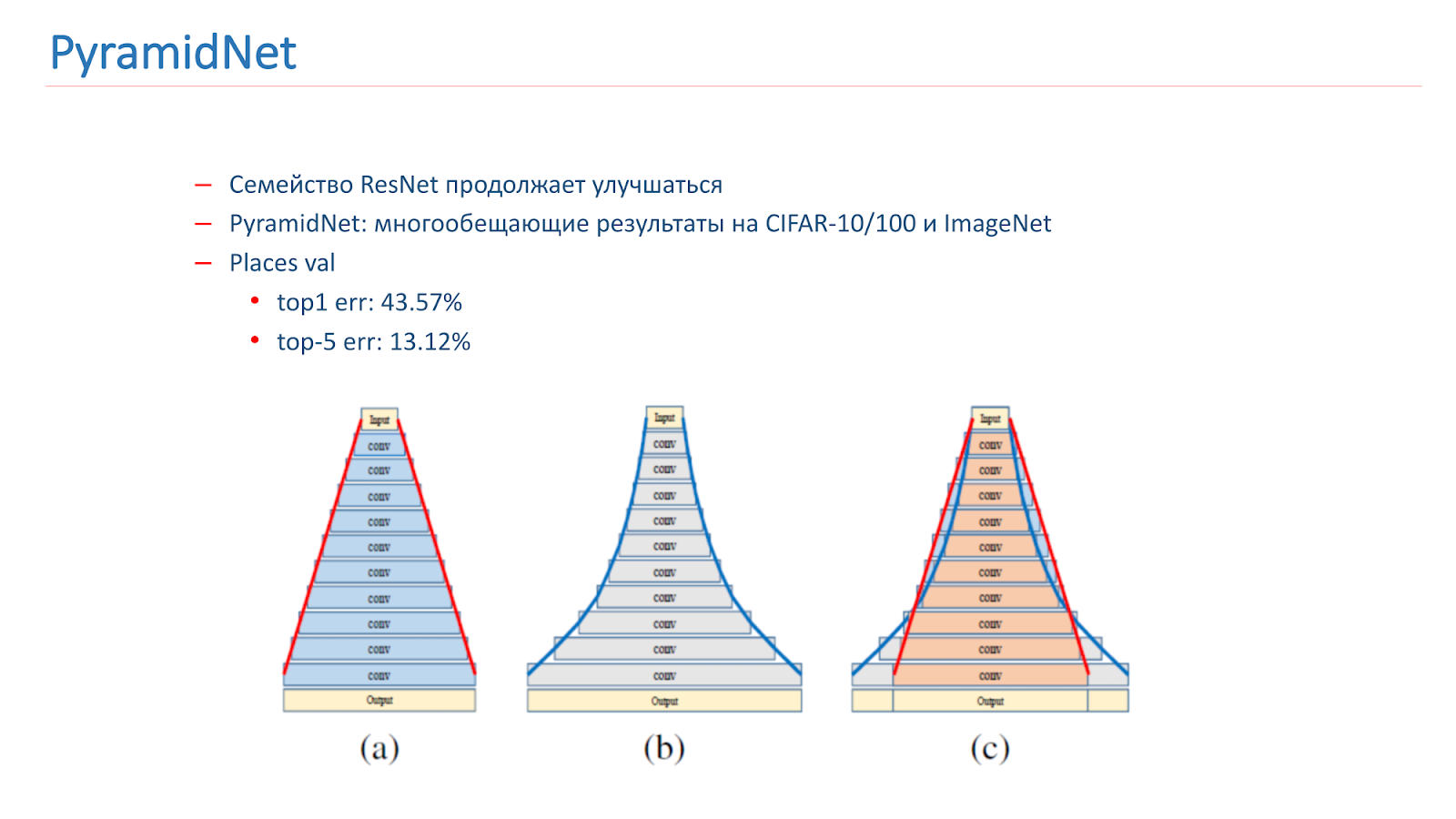
Die Idee ist nicht, die Breite des Restblocks stark zu vergrößern, sondern dies schrittweise zu tun. Wir haben verschiedene Optionen für dieses Netzwerk trainiert, aber leider zeigte es etwas schlechtere Ergebnisse als unser Kampfmodell.
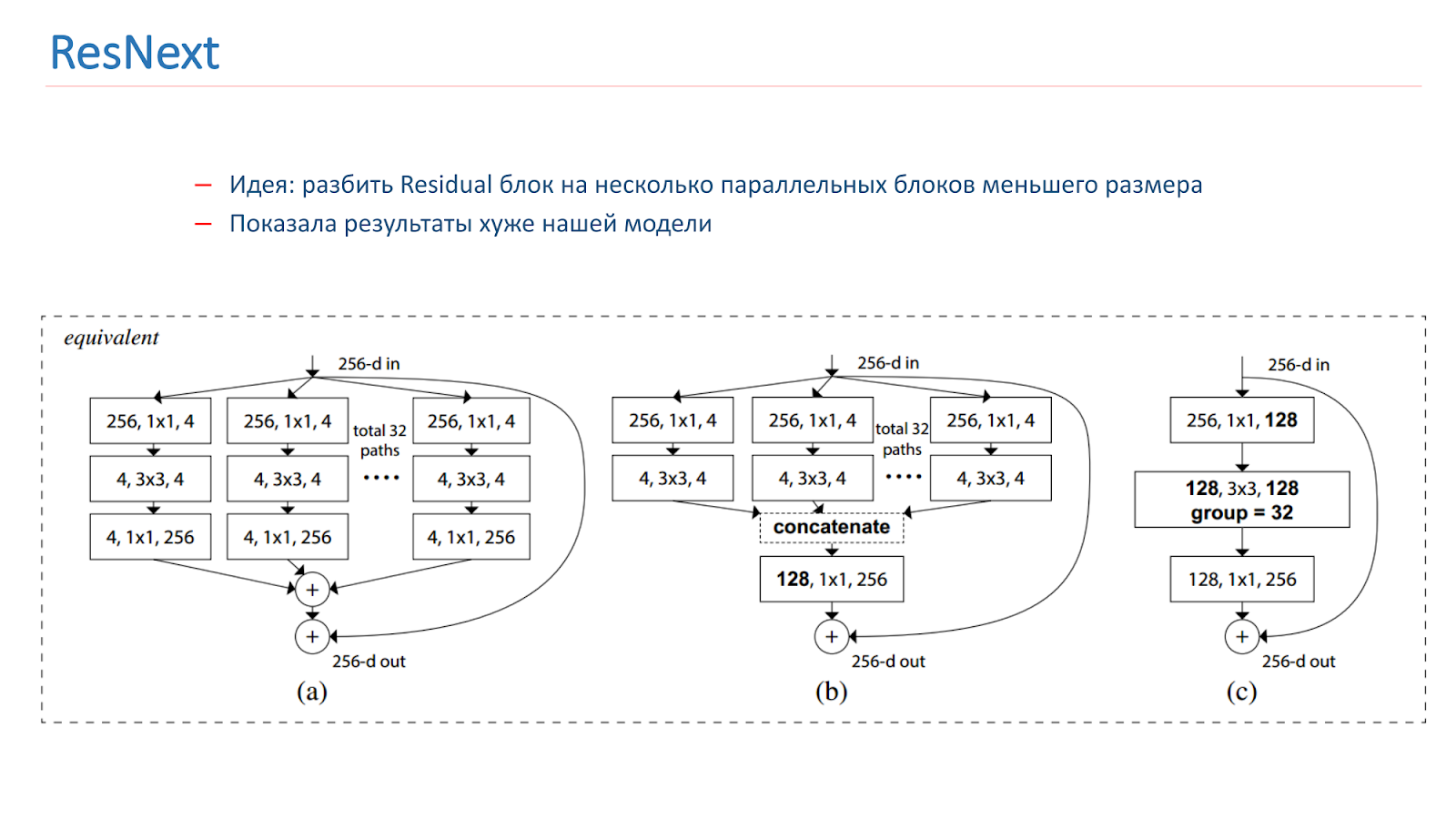
Im Frühjahr 2018 wurde das ResNext-Modell veröffentlicht, ebenfalls eine vielversprechende Idee: den Residual-Block in mehrere parallele Blöcke kleinerer Größe und kleinerer Breite zu unterteilen. Dies ähnelt der Idee von Inception, wir haben auch damit experimentiert. Leider zeigte sie schlechtere Ergebnisse als unser Modell.
Wir haben auch mit verschiedenen „kreativen“ Ansätzen experimentiert, um unsere Modelle zu verbessern. Insbesondere haben wir versucht, CAM (Class Activation Mapping) zu verwenden. Dies sind die Objekte, die das Netzwerk bei der Klassifizierung des Bildes betrachtet.

Unsere Idee war, dass Instanzen derselben Szene dieselben oder ähnliche Objekte wie eine CAM-Klasse haben sollten. Wir haben versucht, diesen Ansatz zu verwenden. Zuerst nahmen sie zwei Netzwerke. Einer ist ImageNet-geschult, der zweite ist unser Modell, das wir verbessern wollen.

Wir nehmen das Bild auf, führen es durch Netzwerk 2, fügen das CAM für die Schicht hinzu und führen es dann dem Eingang von Netzwerk 1 zu. Führen Sie es durch Netzwerk 1, fügen Sie die Ergebnisse zur Verlustfunktion von Netzwerk 2 hinzu und setzen Sie dies mit den neuen Verlustfunktionen fort.
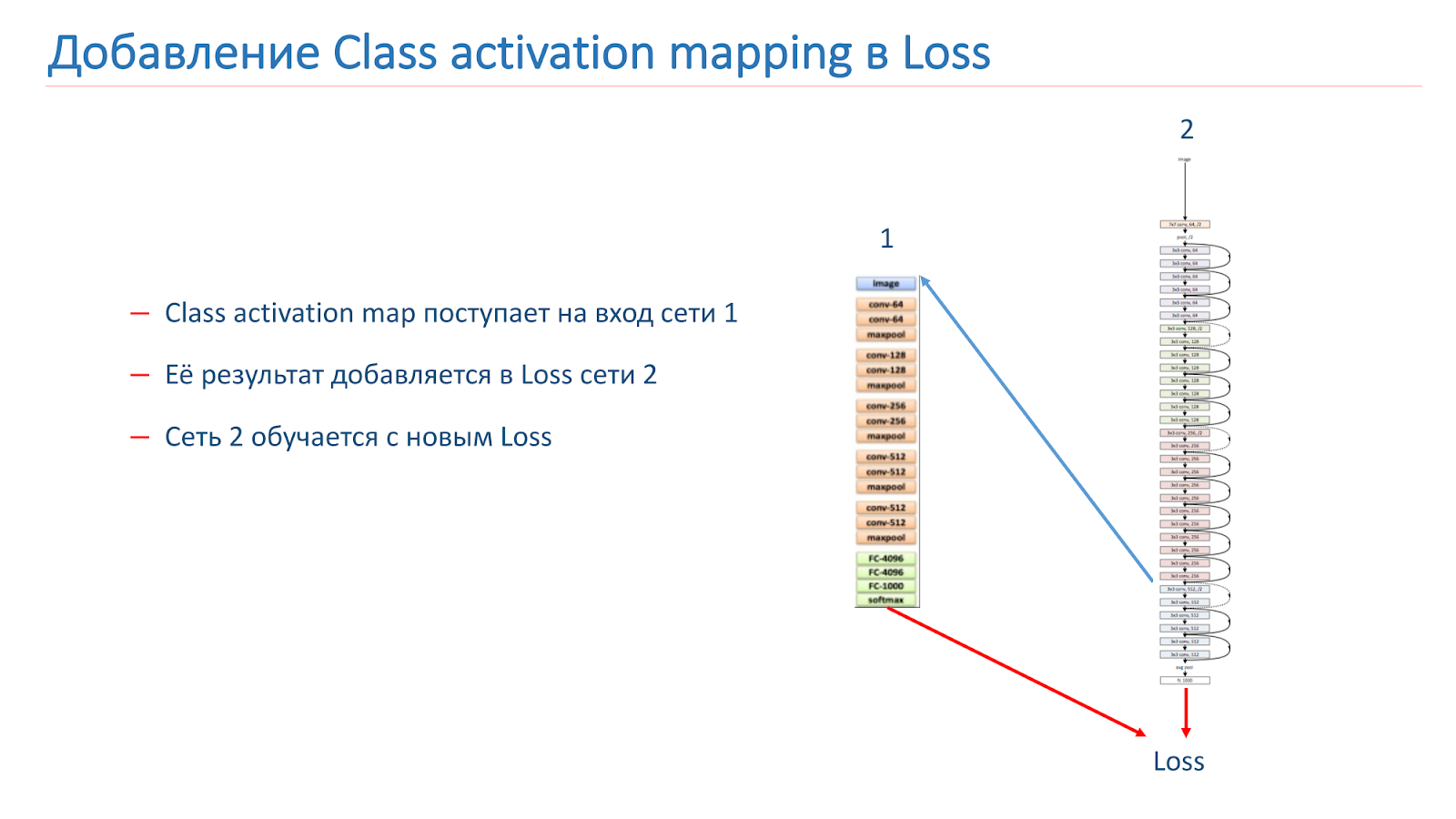
Die zweite Möglichkeit besteht darin, dass wir das Image über Netzwerk 2 ausführen, das CAM nehmen, es dem Eingang von Netzwerk 1 zuführen und dann anhand dieser Daten einfach Netzwerk 1 trainieren und das Ensemble aus den Ergebnissen von Netzwerk 1 und Netzwerk 2 verwenden.
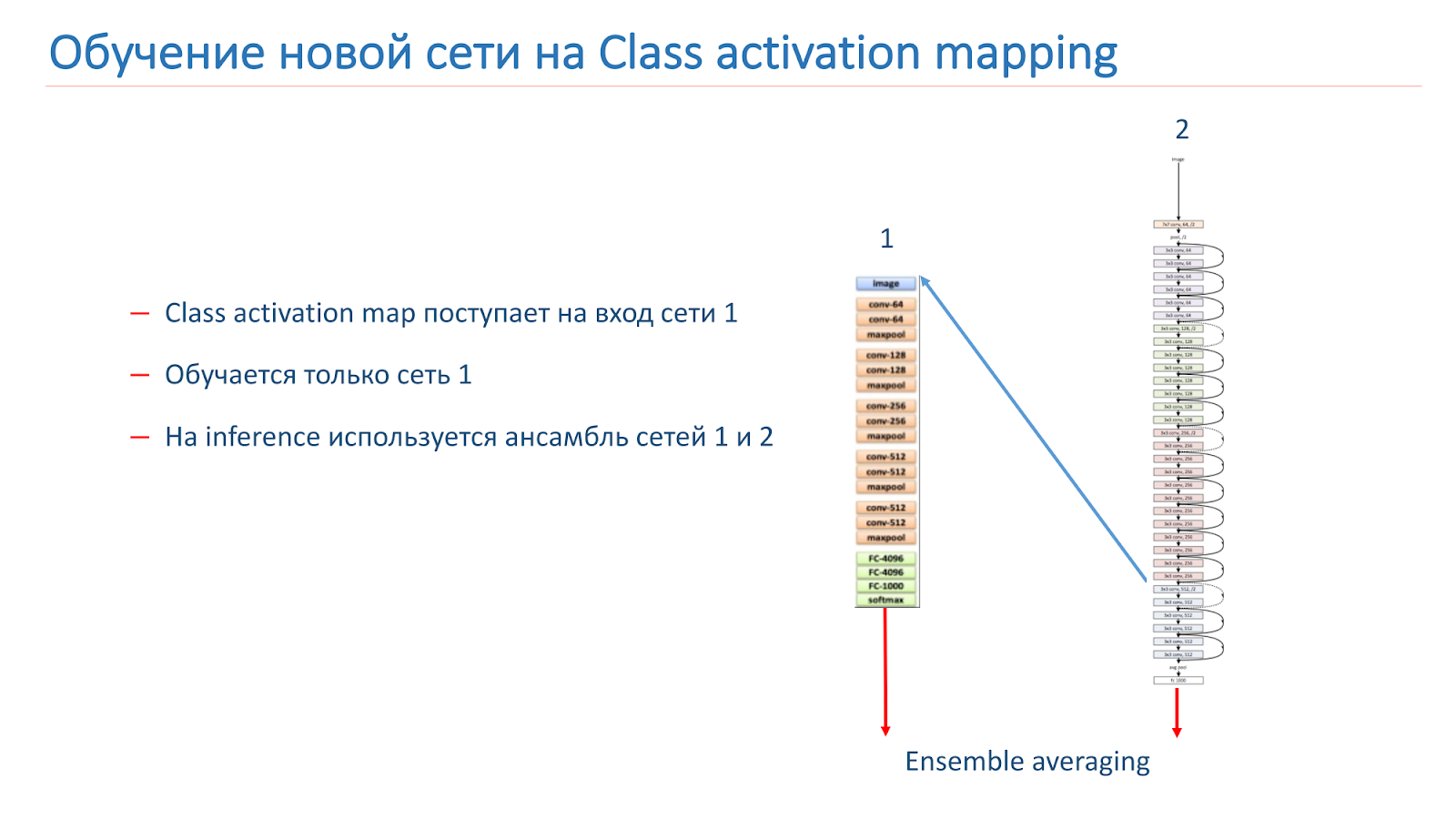
Wir haben unser Modell auf WRN-50-2 umgeschult, da wir als Netzwerk 1 ResNet-50 ImageNet verwendet haben, aber es war nicht möglich, die Qualität unseres Modells irgendwie signifikant zu verbessern.
Wir forschen jedoch weiter daran, wie wir unsere Ergebnisse verbessern können: Wir trainieren neue CNN-Architekturen, insbesondere die ResNet-Familie. Wir versuchen, mit CAM zu experimentieren und betrachten verschiedene Ansätze mit einer intelligenteren Verarbeitung von Bildfeldern - es scheint uns, dass dieser Ansatz ziemlich vielversprechend ist.
Landmark Recognition

Wir haben ein gutes Modell zum Erkennen von Szenen, aber jetzt wollen wir einige ikonische Orte herausfinden, dh Sehenswürdigkeiten. Darüber hinaus machen Benutzer häufig Fotos von ihnen oder machen Bilder vor ihrem Hintergrund.
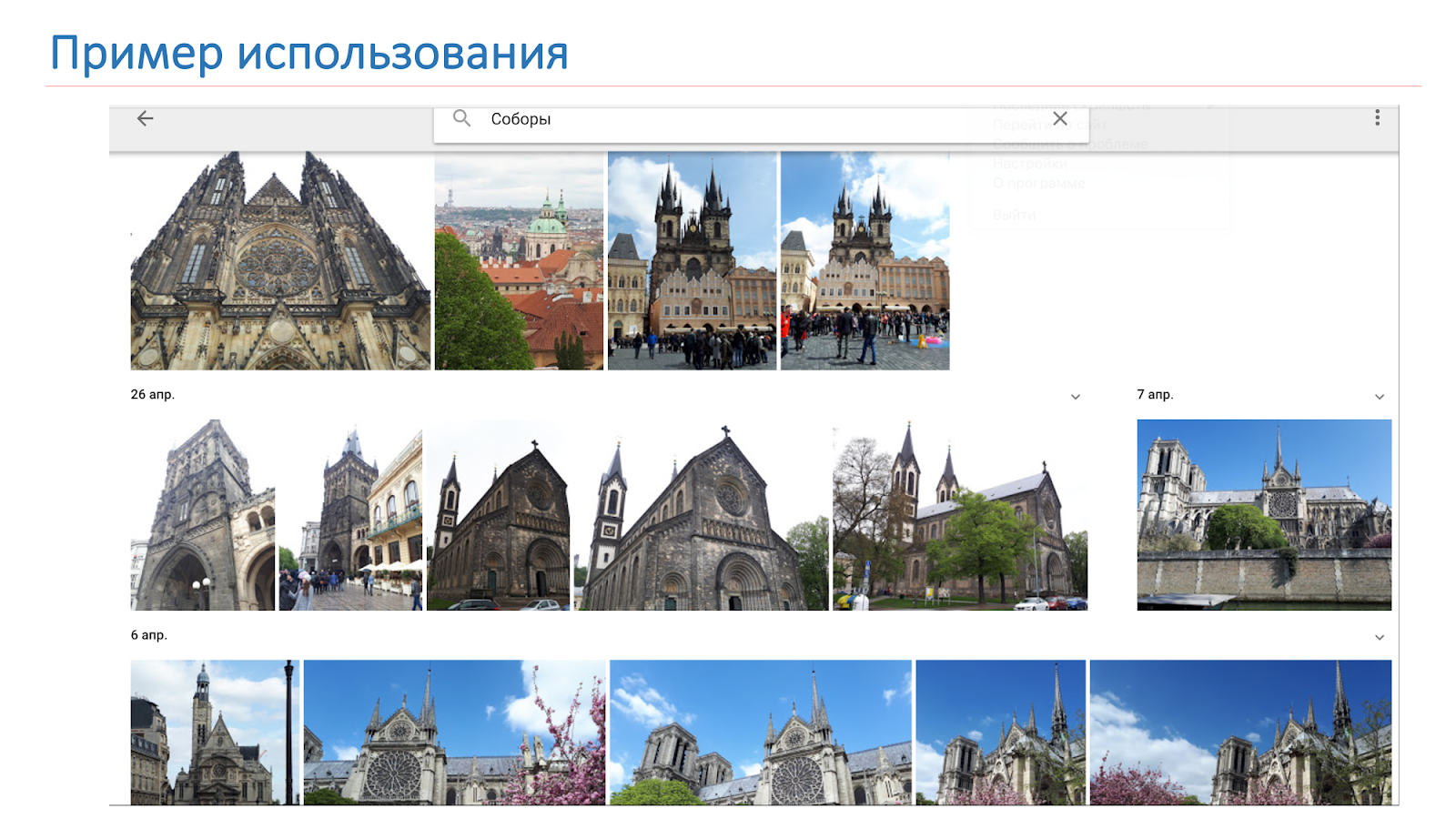
Wir möchten, dass das Ergebnis nicht nur die Kathedralen sind, wie auf dem Bild auf der Folie, sondern das System, das sagt: "Es gibt Notre Dame de Paris und die Kathedralen in Prag."
Als wir dieses Problem lösten, stießen wir auf einige Schwierigkeiten.
- Es gibt praktisch keine Studien zu diesem Thema und es gibt keine vorgefertigten Daten im öffentlichen Bereich.
- Eine kleine Anzahl von "sauberen" Bildern im öffentlichen Bereich für jede Attraktion.
- Es ist nicht ganz klar, was ein Wahrzeichen von Gebäuden ist. Zum Beispiel ein Haus mit Türmen auf Sq. Leo Tolstoi in Petersburg, TripAdvisor berücksichtigt keine Attraktionen, aber Google berücksichtigt.
Wir haben zunächst eine Datenbank gesammelt, eine Liste mit 100 Städten zusammengestellt und dann mithilfe der Google Places-API JSON-Daten für Sonderziele aus diesen Städten heruntergeladen.
Die Daten wurden gefiltert und analysiert, und gemäß der Liste haben wir für jede Attraktion 20 Bilder von der Google-Suche heruntergeladen. Die Zahl 20 stammt aus empirischen Überlegungen. Als Ergebnis haben wir eine Basis von 2827 Attraktionen und ungefähr 56.000 Bildern. Auf dieser Basis haben wir unser Modell trainiert. Zur Validierung unseres Modells haben wir zwei Tests verwendet.
Cloud-Test - Dies sind Bilder unserer Mitarbeiter, die manuell beschriftet wurden. Es enthält 200 Bilder in 15 Städten und 10 Tausend Bilder ohne Attraktionen. Der zweite ist der Suchtest. Es wurde mit der Mail.ru-Suche erstellt, die 3 bis 10 Bilder für jede Attraktion enthält, aber leider ist dieser Test schmutzig.
Wir haben die ersten Modelle trainiert, aber sie zeigten schlechte Ergebnisse beim Cloud-Test auf Kampffotos.
Hier ist ein Beispiel für das Bild, auf dem wir trainiert wurden, und ein Beispiel für Kampffotografie. Das Problem bei Menschen ist, dass sie oft vor dem Hintergrund der Sehenswürdigkeiten fotografiert werden. In diesen Bildern, die wir von der Suche erhalten haben, waren keine Menschen.
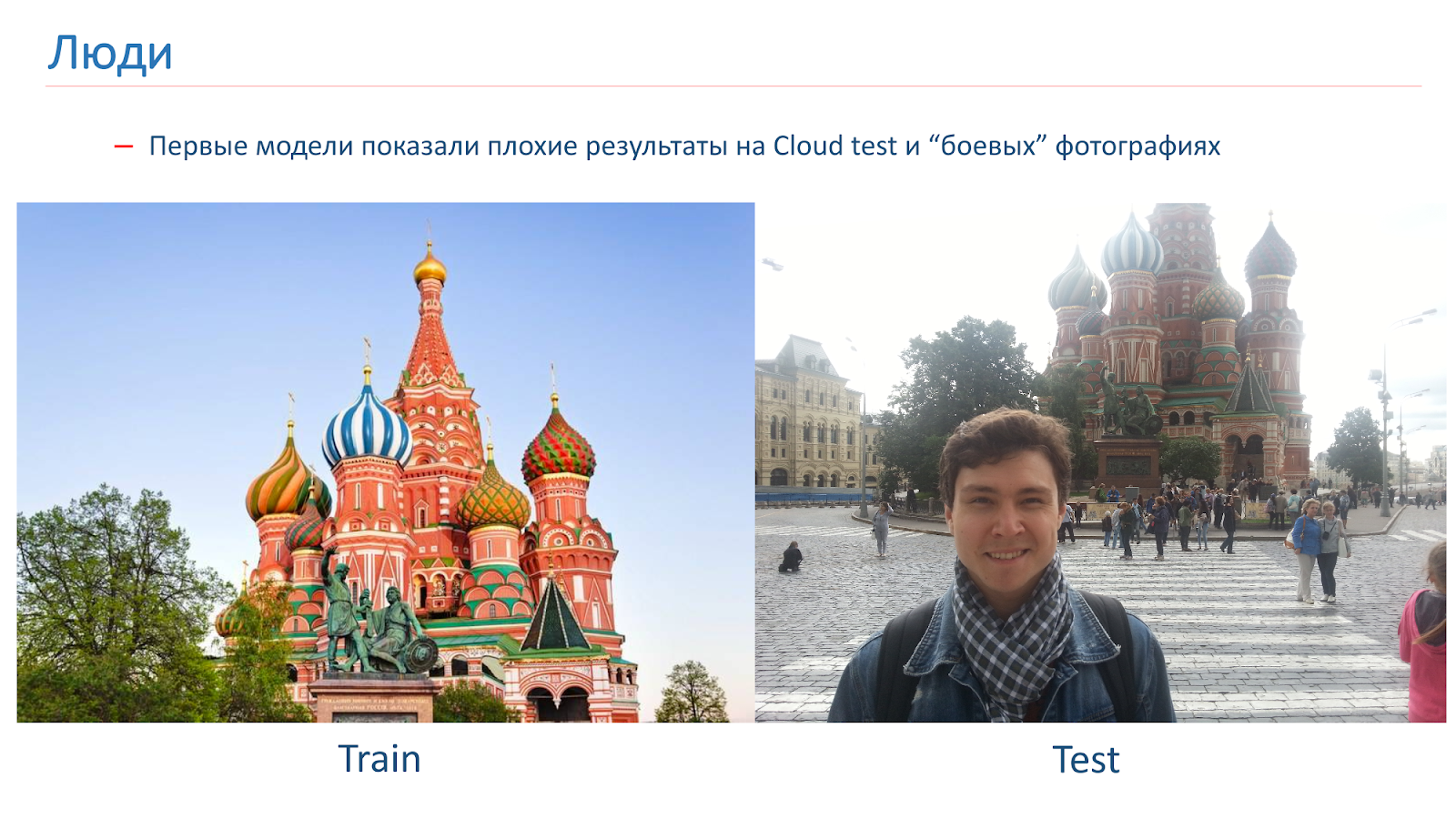
Um dem entgegenzuwirken, haben wir während des Trainings eine „menschliche“ Erweiterung hinzugefügt. Das heißt, wir haben Standardansätze verwendet: zufällige Rotationen, zufälliges Ausschneiden eines Teils des Bildes und so weiter. Aber auch im Lernprozess haben wir zufällig Bilder zu einigen Bildern hinzugefügt.

Dieser Ansatz hat uns geholfen, das Problem mit Menschen zu lösen und ein akzeptables Qualitätsmodell zu erhalten.
Feinabstimmung von Szenenmodellen
Wie wir das Modell trainiert haben: Es gibt eine Trainingsbasis, aber sie ist ziemlich klein. Wir wissen jedoch, dass eine Touristenattraktion ein Sonderfall der Szene ist. Und wir haben ein ziemlich gutes Szenenmodell. Wir beschlossen, sie für die Sehenswürdigkeiten zu trainieren. Zu diesem Zweck haben wir mehrere vollständig verbundene und BN-Schichten über dem Netzwerk hinzugefügt, sie und die drei obersten Restblöcke trainiert. Der Rest des Netzwerks wurde eingefroren.

Darüber hinaus verwenden wir für das Training die nicht standardmäßige Center-Loss-Funktion. Während des Trainings versucht Center Loss, Vertreter verschiedener Klassen in verschiedene Cluster zu „zerlegen“, wie in der Abbildung gezeigt.

Im Training haben wir eine weitere Klasse hinzugefügt, „keine Touristenattraktion“. Und der Mittelverlust wurde auf diese Klasse nicht angewendet. Für eine solche gemischte Verlustfunktion wurde ein Training durchgeführt.
Nachdem wir das Netzwerk trainiert haben, schneiden wir die letzte Klassifizierungsschicht davon ab. Wenn das Bild das Netzwerk durchläuft, wird es zu einem numerischen Vektor, der als Einbettung bezeichnet wird.
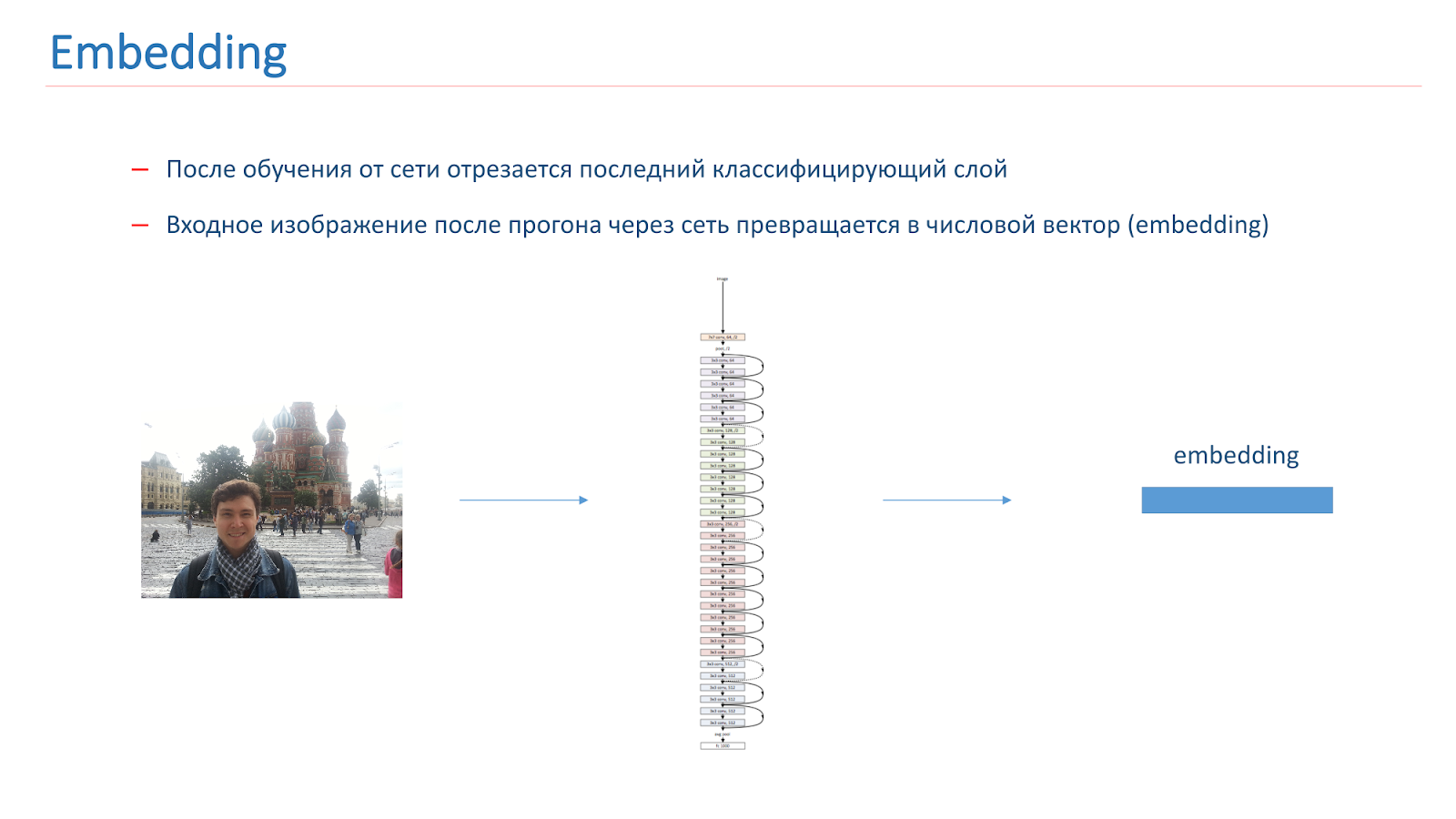
Um ein Landmark-Erkennungssystem weiter aufzubauen, haben wir Referenzvektoren für jede Klasse erstellt. Wir haben jede Klasse von Attraktionen aus der Menge genommen und die Bilder durch das Netzwerk geleitet. Sie bekamen Einbettungen und nahmen ihren mittleren Vektor, der als Klassenreferenzvektor bezeichnet wurde.

Um die Sehenswürdigkeiten auf dem Foto zu bestimmen, führen wir das Eingabebild durch das Netzwerk und seine Einbettung wird mit dem Referenzvektor jeder Klasse verglichen. Wenn das Ergebnis des Vergleichs unter dem Schwellenwert liegt, glauben wir, dass das Bild keine Attraktionen aufweist. Ansonsten nehmen wir die Klasse mit dem höchsten Vergleichswert.
Testergebnisse
- Beim Wolkentest betrug die Genauigkeit der Visiere 0,616, nicht die der Visiere - 0,981
- Die durchschnittliche Genauigkeit von 0,669 wurde beim Suchtest erhalten, und die durchschnittliche Vollständigkeit betrug 0,576.
Bei der Suche haben sie keine sehr guten Ergebnisse erzielt, aber dies erklärt sich aus der Tatsache, dass der erste ziemlich "schmutzig" ist und der zweite Merkmale aufweist - unter den Attraktionen gibt es verschiedene botanische Gärten, die in allen Städten ähnlich sind.
Es gab eine Idee für die Szenenerkennung, um zuerst das Netzwerk zu trainieren, das die Szenenmaske bestimmt, dh Objekte aus dem Vordergrund entfernt und sie dann in das Modell selbst einspeist, das Bildszenen ohne diese Bereiche erkennt, in denen der Hintergrund blockiert ist. Es ist jedoch nicht ganz klar, was genau von der vorderen Schicht entfernt werden muss, welche Maske benötigt wird.
Es wird eine ziemlich komplizierte und kluge Sache sein, weil nicht jeder versteht, welche Objekte zur Szene gehören und welche überflüssig sind. Beispielsweise können Personen in einem Restaurant benötigt werden. Dies ist eine nicht triviale Entscheidung, wir haben versucht, etwas Ähnliches zu tun, aber es hat keine guten Ergebnisse gebracht.
Hier ist ein Beispiel für die Arbeit mit Kampffotografien.
Beispiele für erfolgreiche Arbeit:


Aber der erfolglose Job: Es wurden keine Sehenswürdigkeiten gefunden. Das Hauptproblem unseres Modells besteht derzeit nicht darin, dass das Netzwerk die Sehenswürdigkeiten verwirrt, sondern dass es sie auf dem Foto nicht findet.

In Zukunft planen wir, eine Basis für eine noch größere Anzahl von Städten zu sammeln, neue Methoden zu finden, um das Netzwerk für diese Aufgabe zu trainieren und die Möglichkeiten zu ermitteln, die Anzahl der Klassen zu erhöhen, ohne das Netzwerk neu auszubilden.
Schlussfolgerungen
Heute haben wir:
- Wir haben uns angesehen, welche Datensätze für die Szenenerkennung verfügbar sind.
- Wir haben gesehen, dass das Wide Residual Network das beste Modell ist.
- Diskussion weiterer Möglichkeiten zur Qualitätssteigerung dieses Modells;
- Wir haben uns die Aufgabe angesehen, Sehenswürdigkeiten zu erkennen, welche Schwierigkeiten auftreten;
- Wir haben den Algorithmus zum Sammeln der Basis- und Lehrmethoden des Modells zum Erkennen von Attraktionen beschrieben.
Ich kann sagen, dass die Aufgaben interessant sind, aber in der Gemeinde wenig studiert werden. Es ist interessant, mit ihnen umzugehen, da Sie nicht standardmäßige Ansätze anwenden können, die bei der üblichen Erkennung von Objekten nicht angewendet werden.Minute der Werbung. Wenn Ihnen dieser Bericht von der SmartData-Konferenz gefallen hat, beachten Sie bitte, dass SmartData 2018 am 15. Oktober in St. Petersburg stattfindet, einer Konferenz für diejenigen, die in die Welt des maschinellen Lernens, der Analyse und der Datenverarbeitung eintauchen. Das Programm wird viele interessante Dinge enthalten, die Seite hat bereits ihre ersten Redner und Berichte.