Hallo% Benutzername%!
Sie wissen wahrscheinlich, was APIs sind und wie viel davon in Ihrem Projekt abhängt. Darüber hinaus glaube ich auch, dass Sie bereits mit dem
ersten Ansatz der
API vertraut sind und dass
Swagger und seine
offene API einige der beliebtesten Tools sind, mit denen er folgen kann.
In diesem Artikel möchte ich jedoch zunächst auf den Ansatz zur Implementierung der API eingehen, der sich konzeptionell von dem unterscheidet, was Swagger und Apiary bieten. An der Spitze der Idee steht das Konzept des
Einzelvertrags und die Möglichkeit seiner Implementierung auf Basis von RAML 1.0.
Unter dem Schnitt:
- Zuerst eine kurze Beschreibung der Prinzipien der API;
- Einzelvertrag - Einführung eines Konzepts, Voraussetzungen für das Erscheinen, Prüfung der Möglichkeit seiner Umsetzung auf der Grundlage von OAS (Swagger);
- RAML + Anmerkungen + Überlagerungen als Basis für Einzelverträge , Beispiele;
- RAML-Probleme, konzeptionelle Meinungsverschiedenheiten von Entwicklern;
- Die Idee eines SaaS-Dienstes basiert auf der obigen Idee (Prototypbild oben).
Von der API zuerst bei Swagger bis zum Einzelvertrag bei RAML
Beim Entwurf moderner Softwaresysteme entsteht häufig die Aufgabe, Schnittstellen für die Interaktion ihrer Komponenten miteinander zu koordinieren und zu entwickeln. In den letzten zehn Jahren haben SPA und dicke mobile Anwendungen, die über APIs mit dem Server interagieren, eine immense Popularität und Entwicklung erlangt. Früher wurde die Entwicklung einer interaktiven Website durch schrittweise Bearbeitung des serverseitigen Codes durchgeführt, um HTML-Markups mit anschließender Übertragung an den Browser des Clients zu generieren. Jetzt hat sich die Entwicklung dynamischer Webanwendungen auf die Erstellung einer einzigen Service-API und die parallele Entwicklung vieler Anwendungen (einschließlich SPA) verlagert mit dieser API als Hauptdatenquelle. Mit diesem Ansatz können Sie Aufgaben bequemer teilen, Teams organisieren, die sich nur auf bestimmte Technologien spezialisiert haben (spezialisiertere Spezialisten anziehen), die parallele Entwicklung in den ersten Phasen organisieren und einen einzigen Kommunikationspunkt erstellen - eine API-Schnittstelle.
Ein solcher einzelner Kommunikationspunkt erfordert eine formale und eindeutige Definition. Dieses Dokument ist eine API-Spezifikation. Um API-Spezifikationen heute zu entwickeln und zu dokumentieren, werden verschiedene Technologien und Sprachen verwendet, zum Beispiel: OAS (Swagger), Apiary und RAML.
Die folgenden drei Punkte bestimmen die Art des ersten API-Ansatzes:
- Die API sollte die allererste Client-Schnittstelle der entwickelten Anwendung sein.
- Zunächst wird eine API-Spezifikation entwickelt und dann der Software-Teil der Clients.
- Die Lebensphasen einer API sollten mit den Lebensphasen ihrer Dokumentation übereinstimmen.
Wenn wir den Prozess auf der Grundlage des Vorstehenden betrachten, steht die API-Spezifikation im Mittelpunkt des Entwicklungsprozesses, und alle Knoten, aus denen das System besteht und die diese API als Interaktions-Gateway verwenden, sind Clients der API-Spezifikation. Somit kann der Serverteil des Systems als dieselbe Client-Spezifikations-API betrachtet werden, wie jeder andere Knoten, der die API verwendet, um mit ihm zu kommunizieren. Anwendungsdomänenmodelle müssen nicht mit den in der API-Spezifikation beschriebenen Modellen übereinstimmen. Ihre möglichen absichtlichen Übereinstimmungen mit Klassenstrukturen im Clientanwendungscode oder mit Datenbankschemastrukturen werden eher eingeführt, um den Entwicklungsprozess zu vereinfachen, beispielsweise wenn ein Codegenerator gemäß der OAS-Spezifikation verwendet wird. Logischerweise kann das Obige unter der Definition eines
Einzelvertrags zusammengefasst werden .
Einzelvertrag - viele Kunden.
Einzelvertrag. Vertragstools und Bibliotheken
Der Begriff Einzelvertrag beansprucht keine Teilnahme an Kritik für seine Verwendung im Text des Artikels. Ihre Anwendung ist in diesem Zusammenhang persönlich meine Idee.
Wenn wir das API-Konzept
zunächst auf einen allgemeineren
Einzelvertrag erweitern, können wir die API-Spezifikation nicht nur als formale Beschreibung der Schnittstelle zwischen den Komponenten des Systems betrachten, sondern auch als
Einzelvertrag, der von einer beliebigen Anzahl externer Bibliotheken und Tools als Konfigurationsquelle verwendet wird. In diesem Fall können diese Tools und Bibliotheken zusammen mit SPA oder mobilen Anwendungen als Vertragskunden wahrgenommen werden. Beispiele für solche Kunden sind:
- Dokumentationsgenerator
- Mock-Server-API
- Stresstest-Service
- Anforderungs- / Antwortvalidierungsbibliothek
- Codegenerator
- UI-Generator
- usw.
Ein einzelner Vertrag für solche Clients ist eine einzelne Konfigurationsdatei und Datenquelle. Vertragsinstrumente funktionieren nur auf der Grundlage von Informationen, die aus einem bestimmten Vertrag stammen. Für die volle Funktionalität heterogener Clients wie des API-Mock-Servers reicht natürlich eine API-Beschreibung nicht aus. Zusätzliche Metainformationen werden benötigt, z. B. eine Beschreibung der Beziehung zwischen den GET-Anforderungsparametern (Ressourcen-ID) und den Daten, die der Server zurückgeben soll, Hinweise auf die Antwortfelder und Abfrageparameter zum Organisieren der Paginierung. Ferner wird dieses Beispiel genauer betrachtet. Gleichzeitig müssen spezifische Informationen für bestimmte Instrumente vorhanden sein und untrennbar mit dem Hauptdokument verbunden sein, da dies sonst gegen das Konzept eines einzelnen Vertrags verstößt.
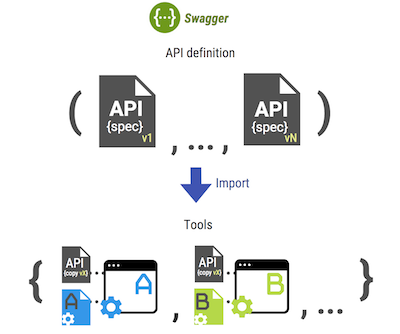
Swagger (OAS) als Einzelvertragsbeschreibungstool
Mit den auf dem Markt beliebtesten Swagger (OAS) und Apiary (Blueprint) können Sie HTTP-APIs in speziellen Sprachen beschreiben: Offene API basierend auf YAML oder JSON, Blueprint basierend auf Markdown, wodurch die Spezifikationen leicht lesbar sind. Es gibt auch viele Tools und Bibliotheken, die von der großen Open-Source-Community erstellt wurden. Swagger ist derzeit weit verbreitet und, könnte man sagen, zuerst zum De-facto-Standard der API geworden. Viele externe Systeme unterstützen den Import von Swagger-Spezifikationen wie
SoapUI ,
Readme.io ,
Apigee usw. Darüber hinaus können Benutzer mit dem vorhandenen SaaS
Swagger Hub und
Apiary Projekte erstellen, eigene Spezifikationen hochladen oder erstellen, die integrierten Dokumentationsgeneratoren und Mock-Server verwenden sowie Links veröffentlichen, um von außen auf sie zuzugreifen.
Swagger sieht zusammen mit OAS 3.0 ziemlich sicher aus und seine Funktionalität zur Beschreibung der API (besonders einfach) reicht in den meisten Fällen aus. Das Folgende ist eine Liste der Vor- und Nachteile von Swagger:
Vorteile:
- Klare und leicht lesbare Beschreibungssprache;
- Große Open-Source-Community;
- Viele offizielle und Open-Source-Editoren, Generatoren, Bibliotheken;
- Die Anwesenheit eines Kernentwicklungsteams, das ständig an der Entwicklung und Verbesserung des Formats arbeitet;
- Shareware Hub für Spezifikationen;
- Detaillierte offizielle Dokumentation;
- Niedrige Eintrittsschwelle.
Nachteile:
- Schwache Modularitätsunterstützung;
- Fehlen automatisch generierter Beispiele für Abfrageantworten basierend auf einer Beschreibung ihrer Strukturen;
- Es gibt häufig Probleme mit der schlechten Stabilität von SmartBear-Produkten (Prahlerautoren) und der späten Reaktion des Entwicklers darauf (die Meinung basiert ausschließlich auf persönlichen Nutzungserfahrungen und der Erfahrung unseres Teams).
Die Hauptbeschränkung, die die Verwendung von OAS als Mittel zur Beschreibung eines
Einzelvertrags nicht zulässt, ist jedoch das Fehlen der Möglichkeit, benutzerdefinierte Metainformationen anzuhängen, um zusätzliche Parameter von Zielwerkzeugen / -bibliotheken zu beschreiben.
Daher müssen alle Tools, die auf der Grundlage von Swagger-Spezifikationen arbeiten, mit den Informationen zufrieden sein, die das Grundformat unterstützen.
Beispielsweise erfordert die Implementierung eines Smart-Mock-API-Servers mehr Informationen, als ein Spezifikationsdokument bereitstellen kann, weshalb die integrierte Swagger Hub-Mock-API nur gefälschte Daten basierend auf Datentypen / -strukturen generieren kann, die aus einem Spezifikationsdokument erhalten wurden. Zweifellos reicht dies nicht aus, und eine solche Mock-Server-Funktionalität kann nur von einem einfachen API-Client erfüllt werden.
In unserem Unternehmen war während der Entwicklung eines der Projekte (React SPA + API-Server) die folgende Mock-Server-Funktionalität erforderlich:
- Nachahmung der Paginierung. Der Server sollte keine vollständig zufälligen Werte der Felder currentPage, nextPage, pagesTotal als Antwort auf Listenanforderungen zurückgeben, sondern in der Lage sein, das tatsächliche Verhalten des Paginierungsmechanismus mit der Generierung der Werte dieser Metapolen in Abhängigkeit vom vom Client empfangenen Seitenwert zu simulieren.
- Erzeugen von Antwortkörpern, die verschiedene Datensätze enthalten, abhängig von dem spezifischen Parameter der eingehenden Anforderung;
- Die Fähigkeit, echte Beziehungen zwischen gefälschten Objekten aufzubauen: Das Feld foo_id der Bar- Entität sollte sich auf die zuvor generierte Foo- Entität beziehen. Dies kann erreicht werden, indem dem Mock-Server Unterstützung für Idempotenz hinzugefügt wird.
- Nachahmung der Arbeit verschiedener Autorisierungsmethoden: OAuth2, JWT usw.
Ohne all dies ist es sehr schwierig, SPA parallel zur Entwicklung des Serverteils des Systems zu entwickeln. Gleichzeitig ist ein solcher Mock-Server aus dem oben beschriebenen Grund fast unmöglich zu implementieren, ohne zusätzliche spezifische Metainformationen, die direkt in der API-Spezifikation gespeichert werden könnten, und sie über das erforderliche Verhalten bei der Simulation des nächsten Endpunkts zu informieren. Dieses Problem kann gelöst werden, indem die erforderlichen Parameter in Form einer separaten Datei mit Konfigurationen parallel zur grundlegenden OAS-Spezifikation hinzugefügt werden. In diesem Fall müssen Sie diese beiden unterschiedlichen Quellen jedoch separat unterstützen.
Wenn es mehr als einen Mock-Server mit Tools gibt, die nach diesem Prinzip in der Entwicklungsprozessumgebung arbeiten, erhalten wir einen „Zoo“ von Tools, von denen jedes mit seiner eigenen einzigartigen Funktionalität gezwungen ist, eine eigene eindeutige Konfigurationsdatei zu haben, die logisch mit der Basis-API verknüpft ist -Spezifikationen, aber tatsächlich getrennt gelegen und "ihr eigenes Leben" leben.
Problem: Der Entwickler muss die Relevanz aller Konfigurationen beibehalten, nachdem er die Versionen der Basisspezifikation geändert hat, häufig an völlig anderen Orten und in völlig anderen Formaten.
Einige Beispiele für Dienste, die nach einem ähnlichen Prinzip arbeiten:
- SoapUI ist ein System zum Testen von REST- und SOAP-Schnittstellen. Unterstützt den Import eines Projekts aus der Swagger-Spezifikation. Beim Ändern der grundlegenden Swagger-Spezifikation bleibt die Konfiguration eines Projekts basierend auf einer Liste von API-Aufrufen parallel bestehen und erfordert eine manuelle Synchronisierung.
- Andere SmartBear- Produkte;
- Apigee ist ein API-Lifecycle-Management-Service. Es verwendet Swagger-Spezifikationen als Vorlagen, auf deren Grundlage es seine Konfigurationen interner Dienste initialisieren kann. Es gibt auch keine automatische Synchronisation.
- Readme.io ist ein Dienst, mit dem Sie eine schöne Dokumentation basierend auf der Swagger-Spezifikation erstellen können. Außerdem verfügt er über einen Mechanismus zum Verfolgen von Änderungen an der Basisspezifikation und zum Lösen von Konflikten durch Aktualisieren der Projektkonfiguration auf der Dienstseite. Dies erforderte sicherlich eine unnötige Komplexität bei der Entwicklung dieses Dienstes.
Sie können dieser Liste viele andere Dienste hinzufügen, die die Integrationsfunktion mit der Swagger-Spezifikation bereitstellen. Integration bedeutet für die meisten von ihnen das übliche Kopieren der Grundstruktur der Swagger-Spezifikation und die anschließende automatische Vervollständigung der lokalen Konfigurationsfelder, ohne die Synchronisation mit Änderungen an der Grundspezifikation zu unterstützen.
RAML, Anmerkungen, Überlagerungen
Der Wunsch, ein Tool zu finden, das die zuvor erwähnte OAS-Einschränkung ausschließt und es uns ermöglicht, die Spezifikation als einen einzigen Vertrag für alle Client-Tools zu betrachten, hat uns dazu gebracht, uns mit der RAML-Sprache vertraut zu machen. Es ist genug über RAML geschrieben, Sie können es zum Beispiel hier lesen:
https://www.infoq.com/articles/power-of-raml . RAML-Entwickler haben versucht, die Sprachunterstützung für Modularität auf der Ebene ihres Konzepts zu verankern. Jetzt kann jedes Unternehmen oder jeder einzelne Entwickler seine eigenen Wörterbücher erstellen oder vorgefertigte öffentliche Wörterbücher verwenden, um die API zu entwerfen, vorgefertigte Datenmodelle neu zu definieren und zu erben. Ab Version 1.0 unterstützt RAML 5 verschiedene Arten externer Module:
Include, Library, Extension, Trait, Overlay , sodass jedes Modul je nach Aufgabe so flexibel wie möglich verwendet werden kann.
Es ist an der Zeit, die Hauptmöglichkeit von RAML zu diskutieren, die aus Gründen, die nicht vollständig verstanden wurden, keine Analoga in OAS und Blueprint - Annotations enthält.
Anmerkungen in RAML sind die Möglichkeit, benutzerdefinierte Metadaten an die zugrunde liegenden Sprachstrukturen anzuhängen.
Es war diese RAML-Funktion, die zum Grund für das Schreiben dieses Artikels wurde.
Ein Beispiel:
#%RAML 1.0 title: Example API mediaType: application/json # Annotation types block may be placed into external file annotationTypes: validation-rules: description: | Describes strict validation rules for the model properties. Can be used by validation library allowedTargets: [ TypeDeclaration ] type: string[] info-tip: description: | Can be used by Documentation generator for showing tips allowedTargets: [ Method, DocumentationItem, TypeDeclaration ] type: string condition: description: | Named example can be returned if condition is evaluated to true. Can be used by Intelligent mock server allowedTargets: [ Example ] type: string types: Article: type: object properties: id: type: integer title: string paragraphs: Paragraph[] createdAt: type: string (validation-rules): ["regex:/\d{4}-[01]\d-[0-3]\dT[0-2]\d:[0-5]\d:[0-5]\d(?:\.\d+)?Z?/"] Paragraph: type: object properties: order: type: integer (validation-rules): ["min:0"] content: string (validation-rules): ["max-length:1024"] /articles/{articleId}: get: (info-tip): This endpoint is deprecated description: Returns Article object by ID responses: 200: body: application/json: type: Article
Benutzeranmerkungsstrukturen selbst müssen klare Beschreibungen in RAML enthalten. Hierzu wird ein spezieller Abschnitt
annotationTypes verwendet, dessen Definitionen auch in das externe Modul übernommen werden können. Auf diese Weise können spezielle Parameter eines externen Tools in Form von Anmerkungen definiert werden, die an die Basisdefinition der RAML-API angehängt sind. Um zu vermeiden, dass die Grundspezifikation mit einer großen Anzahl von Anmerkungen für verschiedene externe Tools überladen wird, wird die Möglichkeit unterstützt, sie in separate Dateien zu übertragen -
Überlagerungen (und auch
Erweiterungen ) mit Klassifizierung nach Umfang. In der RAML-Dokumentation (
https://github.com/raml-org/raml-spec/blob/master/versions/raml-10/raml-10.md#overlays ) wird Folgendes über Overlays gesagt:
Ein Overlay fügt Knoten einer RAML-API-Definition hinzu oder überschreibt sie, während die verhaltensbezogenen und funktionalen Aspekte beibehalten werden. Bestimmte Knoten einer RAML-API-Definition geben das Verhalten einer API an: ihre Ressourcen, Methoden, Parameter, Körper, Antworten usw. Diese Knoten können nicht durch Anwenden einer Überlagerung geändert werden. Im Gegensatz dazu befassen sich andere Knoten, wie z. B. Beschreibungen oder Anmerkungen, mit Problemen, die über die funktionale Schnittstelle hinausgehen, wie z. B. die menschenorientierte beschreibende Dokumentation in einer bestimmten Sprache oder Implementierungs- oder Verifizierungsinformationen zur Verwendung in automatisierten Tools. Diese Knoten können durch Anwenden einer Überlagerung geändert werden.
Überlagerungen sind besonders wichtig, um die Schnittstelle von der Implementierung zu trennen. Overlays ermöglichen separate Lebenszyklen für die Verhaltensaspekte der API, die streng kontrolliert werden müssen, z. B. ein Vertrag zwischen dem API-Anbieter und seinen Verbrauchern, im Vergleich zu solchen, die nur wenig Kontrolle benötigen, wie z. B. die menschen- oder implementierungsorientierten Aspekte, die sich entwickeln können verschiedene Schritte. Das Hinzufügen von Hooks zum Testen und Überwachen von Tools, das Anhängen von Metadaten, die für eine Registrierung von APIs relevant sind, oder das Bereitstellen aktualisierter oder übersetzter menschlicher Dokumentation kann beispielsweise erreicht werden, ohne dass Aspekte der Verhaltensaspekte der API geändert werden. Diese Dinge können durch einen strengen Versions- und Änderungsverwaltungsprozess gesteuert werden.
Mit anderen Worten, diese Funktionalität ermöglicht es Ihnen, "die Spreu von der Spreu zu trennen", beispielsweise die Hauptbeschreibung der API-Spezifikation, von zusätzlichen Metainformationen, die für ein bestimmtes Werkzeug spezifisch sind, das sie für die Arbeit verwendet. Metainformationen in jeder einzelnen Überlagerung werden in Form von Anmerkungen an verschiedene Blöcke der Spezifikation „gehängt“.
Ein Beispiel für eine Grundstruktur:
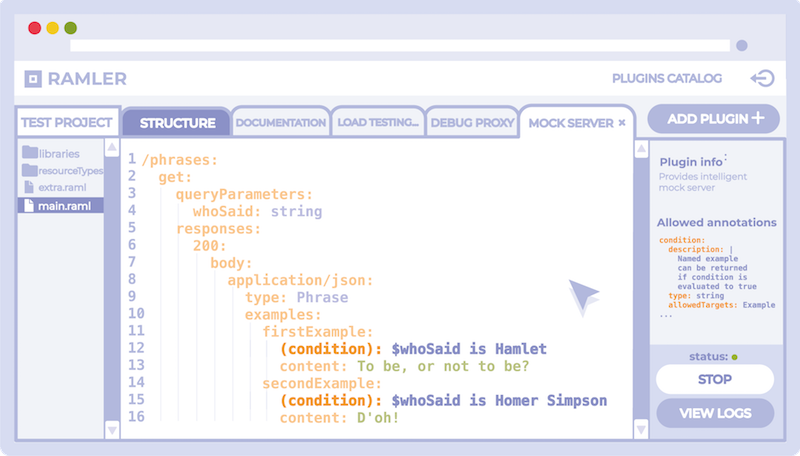
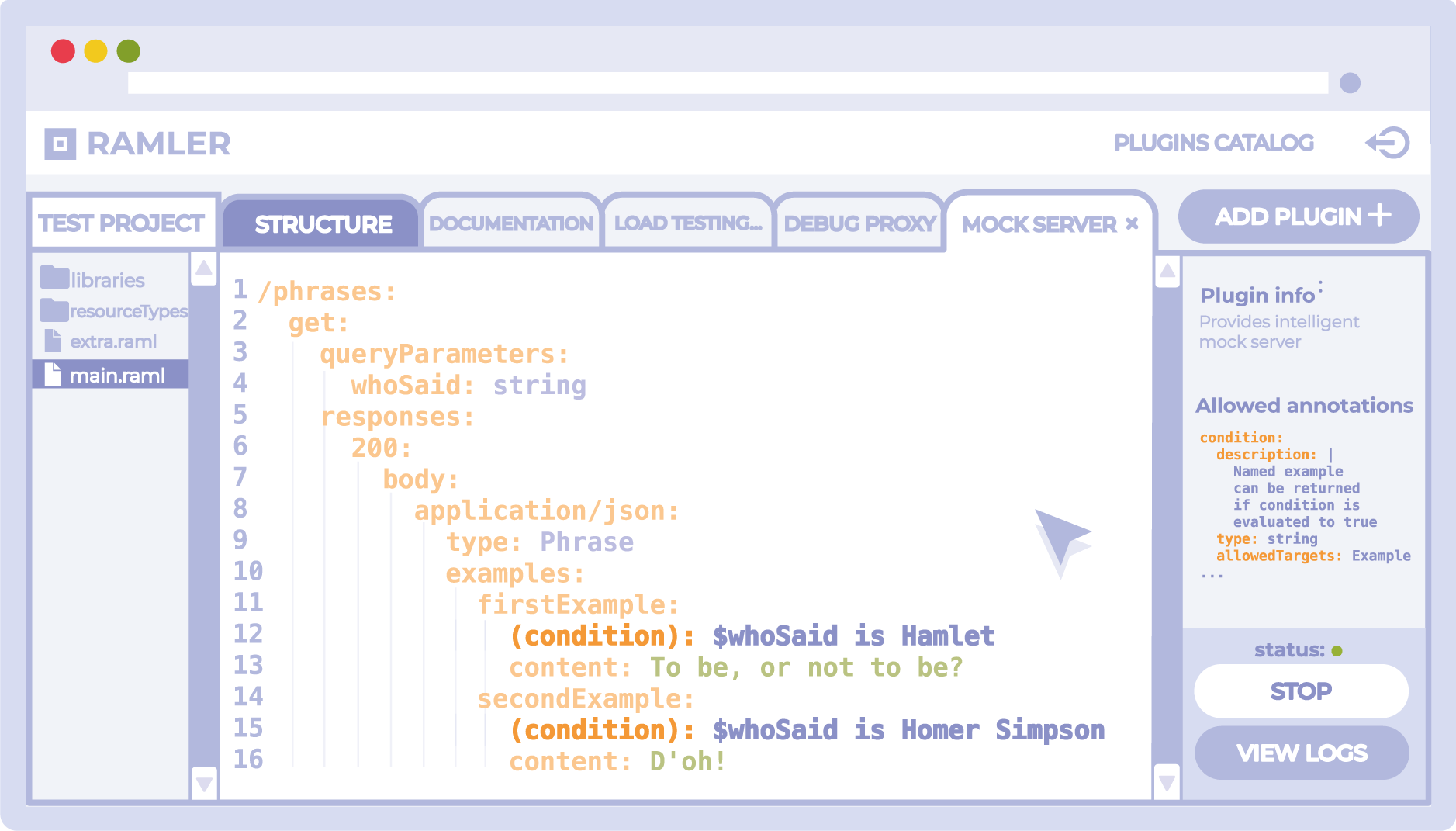
#%RAML 1.0 title: Phrases API mediaType: application/json types: Phrase: type: object properties: content: string /phrases: get: queryParameters: whoSaid: string responses: 200: body: application/json: type: Phrase
Überlagerung:
#%RAML 1.0 Overlay usage: Applies annotations for Intelligent mock server extends: example_for_article_2_1.raml annotationTypes: condition: description: | Named example can be returned if condition is evaluated to true type: string allowedTargets: Example /phrases: get: responses: 200: body: application/json: examples: firstExample: (condition): $whoSaid is Hamlet content: "To be, or not to be?" secondExample: (condition): $whoSaid is Homer Simpson content: "D'oh!"
Dadurch wird es möglich, einen einzigen Vertrag zu implementieren: Alle Funktions-, Verhaltens- und Metainformationen werden an einem einzigen Ort gespeichert und versioniert, und Vertragstools - Kunden des Vertrags - müssen Unterstützung für die in dieser Spezifikation verwendeten Anmerkungen haben. Auf der anderen Seite können die Tools selbst ihre eigenen Anforderungen an Anmerkungen darstellen, die an der Spezifikation „aufgehängt“ werden müssen - dies bietet ein breiteres Spektrum an Möglichkeiten bei der Entwicklung von Vertrags-Tools.
Das obige Konzept ist in der folgenden Abbildung dargestellt:
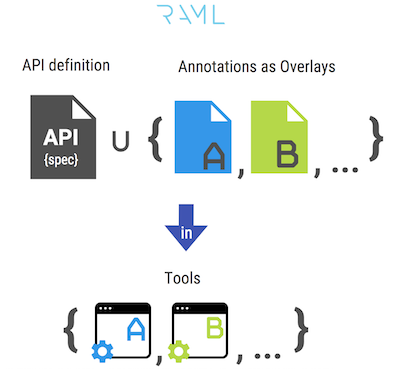
Unter den Minuspunkten dieses Ansatzes kann die hohe Komplexität der manuellen Synchronisation der Basisspezifikationsdatei und jeder der Überlagerungen herausgestellt werden: Wenn Sie die Struktur der Grundspezifikation aktualisieren, müssen Sie die erforderlichen Änderungen in den Strukturen der Überlagerungen anwenden. Dieses Problem wird schwerwiegender, wenn mehr als eine Überlagerung angezeigt wird.
Eine mögliche und naheliegendste Lösung wäre die Entwicklung eines speziellen Editors oder Add-Ons für den vorhandenen Online-RAML-Editor
https://github.com/mulesoft/api-designer . Der Bearbeitungsbereich bleibt unverändert, es können jedoch Registerkarten erstellt werden: Jede neue Registerkarte ist ein Fenster zum Bearbeiten der ihr zugewiesenen Überlagerung. Beim Bearbeiten der Grundstruktur der Spezifikation im Hauptfenster ändern sich auch die Strukturen in allen erstellten Registerkarten. Wenn eine Inkompatibilität der neuen Struktur mit vorhandenen Anmerkungen in Registerkartenüberlagerungen festgestellt wird, wird eine Warnung angezeigt. Eine detailliertere Betrachtung eines solchen Herausgebers ist ein separates Thema und verdient ernsthafte Beachtung.
Bestehende Entwicklungen
Bei der Suche nach vorhandenen Lösungen, die der Verwirklichung der Idee nahe kommen, Anmerkungen als Mittel zur Beschreibung von Metainformationen zu verwenden, wurden die folgenden Lösungen gefunden:
- https://github.com/raml-org/raml-annotations Repository mit offiziellen Anmerkungen, die von der RAML-Entwicklergemeinde genehmigt wurden. In der aktuellen Version sind nur OAuth2-Annotationen verfügbar. Sie können von externen Tools verwendet werden, um Metainformationen zu erhalten, die Aspekte der OAuth2-Implementierung für die entwickelte API-Spezifikation beschreiben.
- https://github.com/petrochenko-pavel-a/raml-annotations Benutzeranmerkungsbibliothek @ petrochenko-pavel-a mit einer logischen Gruppierung nach Anwendungsbereich. Das Projekt ist experimenteller, veranschaulicht jedoch perfekt die Idee der Verwendung von Anmerkungen. Die interessantesten Anmerkungsgruppen:
- AdditionalValidation.raml - Anmerkungen zur Beschreibung zusätzlicher Regeln für die Validierung von Spezifikationsmodellen. Sie können beispielsweise von der Serverbibliothek zum Validieren von Abfragen gemäß der RAML-Spezifikation verwendet werden.
- mock.raml - Anmerkungen zur Beschreibung der Details des Mock-Servers basierend auf der RAML-Spezifikation;
- semanticContexts.raml - Anmerkungen, die auf den semantischen Kontext der einzelnen deklarierten Strukturblöcke der RAML-Spezifikation verweisen;
- strukturelle.raml - Anmerkungen, die die Rolle einer separaten RAML-Entität in der Gesamtstruktur des beschriebenen Domänenmodells verdeutlichen;
- uiCore.raml - ein Beispiel für Anmerkungen, die von UI-Generierungswerkzeugen basierend auf der RAML-Spezifikation verwendet werden können;
Das Repository enthält auch Bibliotheken von Dienstprogrammtypen, die zur Verwendung als Grundelemente zur Beschreibung von Datenstrukturen der RAML-Spezifikation geeignet sind.
RAML-Probleme
Trotz der Funktionalität, des Fortschritts der Grundidee und der Aufmerksamkeit großer Softwarehersteller (Cisco, Spotify, VMware usw.) hat RAML heute ernsthafte Probleme, die im Hinblick auf sein erfolgreiches Schicksal fatal werden können:
- Kleine und fragmentierte Open-Source-Community;
- Eine unverständliche Strategie des Hauptentwicklers von RAML ist mulesoft . Das Unternehmen entwickelt Produkte, die nur eine Kopie bestehender OAS-basierter Lösungen (in Anypoint Platform enthalten ) sind, anstatt Services zu erstellen, die die Vorteile von RAML gegenüber Swagger hervorheben.
- Die Konsequenz des ersten Absatzes: eine kleine Anzahl von Open-Source-Bibliotheken / Tools;
- Höhere Eintrittsschwelle als OAS (das ist seltsam, aber viele Leute denken so);
- Aufgrund der großen Anzahl von Fehlern und Problemen mit UX / UI ist der Hauptdienst, der völlig ungeeignet ist und Benutzer abwehrt, der Einstiegspunkt in RAML - https://anypoint.mulesoft.com/ .
Konzeptionelle Meinungsverschiedenheit. Erste Schlussfolgerung
Innerhalb der Community gibt es Widersprüche bezüglich des Grundkonzepts. Jemand denkt, dass RAML eine
Modelldefinitionssprache ist , und jemand denkt, dass es eine
API-Definitionssprache wie OAS oder Blueprint ist (Leute, die sich RAML-Entwickler nennen, erwähnen dies oft in verschiedenen Kommentaren). Das Konzept der
Modelldefinitionssprache würde es innerhalb der RAML-Spezifikation ermöglichen, das Domänenmodell der Domäne zu beschreiben, ohne eng an den Kontext der API-Ressourcenbeschreibung gebunden zu sein, wodurch der Horizont der Optionen für die Verwendung der Spezifikation mit externen Tools erweitert wird (was tatsächlich die Grundlage für die Existenz dieses
Einzelvertrags schafft!). Hier ist eine Definition des Konzepts einer Ressource auf der Website readhat docs (
http://restful-api-design.readthedocs.io/en/latest/resources.html , ich empfehle übrigens jedem, diesen wunderbaren Leitfaden zum API-Design zu lesen):
Wir nennen Informationen, die verfügbare Ressourcentypen , ihr Verhalten und ihre Beziehungen beschreiben, das Ressourcenmodell einer API . Das Ressourcenmodell kann als RESTful-Zuordnung des Anwendungsdatenmodells angesehen werden .
Im RAML-
Anwendungsdatenmodell sind dies Typen, die im Typenblock deklariert sind, und das
Ressourcenmodell einer API wird im
Ressourcen- RAML-Block beschrieben. Daher müssen Sie in der Lage sein, diese
Zuordnung zu beschreiben. Die aktuelle Implementierung von RAML ermöglicht jedoch, dass eine solche
Zuordnung nur 1 zu 1 erfolgt, dh dass Typen "wie sie sind" in der Ressourcen-API-Deklaration verwendet werden.
Ich denke, dies ist das Hauptproblem der Sprache, deren Lösung es RAML ermöglicht, über die
API-Definitionssprache hinauszugehen und eine vollwertige
Modelldefinitionssprache zu werden : eine allgemeinere Sprache (anstelle von OAS oder Blueprint), die zur Beschreibung der einzelnen Verträge von Systemen verwendet wird, die im Wesentlichen den formalen Kern bilden viele ihrer Komponenten.
Das oben Gesagte macht RAML zu einem schwachen Spieler, der derzeit nicht in der Lage ist, den Wettbewerb gegen Swagger zu gewinnen. Vielleicht hat der Hauptentwickler von RAML deshalb drastische Maßnahmen ergriffen.
Https://blogs.mulesoft.com/dev/api-dev/open-api-raml-better-together/Die Idee von RAML SaaS mit einem Vertrag
Basierend auf dem Konzept des
Einzelvertrags , ausgehend von der Idee, eine OAS-basierte Swagger-Spezifikations-API für Spezifikationen zu hosten und sich auf die Möglichkeit von RAML zu stützen, Metainformationen zu deklarieren und die Basisspezifikation mithilfe von Overlays zu teilen, schlägt die Idee einer alternativen SaaS-Lösung zum Hosten und Verwalten von Spezifikationen basierend auf der RAML-Sprache vor Übertreffen Sie den Swagger Hub und das Bienenhaus in Bezug auf Umfang und Qualität der möglichen Funktionen.
Der neue Dienst wird in Analogie zum Swagger-Hub das Hosting von Benutzerverträgen mit der Bereitstellung eines Online-Editors und die Möglichkeit sein, Dokumentationsvorschauen mit Echtzeit-Updates anzuzeigen. Der Hauptunterschied sollte das Vorhandensein eines Katalogs von Vertrags-Plug-Ins sein, die in den Service integriert sind und von denen jeder Benutzer API-Spezifikationen in seinem aktuellen Projekt installieren kann. Für die Installation müssen die erforderlichen RAML-Anmerkungen implementiert werden, die in der Plugin-Dokumentation angegeben sind. Nachdem Sie dem Projekt ein neues Plug-In hinzugefügt haben, wird im Code-Editor-Fenster eine neue Registerkarte hinzugefügt, wenn Sie zu diesem wechseln. Die Bearbeitungsanmerkungen des installierten Plug-Ins werden verfügbar. Die Struktur der Basisspezifikation sollte automatisch in allen Registerkarten dupliziert werden, die den Plugins entsprechen. Wenn Konflikte zwischen der Grundstruktur und bereits vorhandenen Anmerkungen auftreten, sollte ein spezieller Mechanismus Optionen für seine Lösung anbieten oder diese automatisch lösen.
Technisch gesehen ist jede Registerkarte eine Abstraktion des RAML-Overlays, die Anmerkungen zu jedem bestimmten Plugin enthält. Dies stellt sicher, dass die Spezifikation mit jedem Tool kompatibel ist, das RAML 1.0 unterstützt.
Das Plugin-Verzeichnis muss für die Erweiterung durch die Open Source-Community geöffnet sein. Es ist auch möglich, kostenpflichtige Plug-Ins zu implementieren, die als Anreiz für die Entwicklung neuer Plug-Ins dienen können.
Mögliche Plugins: API-Dokumentation mit Unterstützung für eine große Anzahl von Anmerkungen zur flexiblen Parametrisierung des Renderings, „intelligenter“ Mock-Server (aus dem obigen Beispiel), herunterladbare Bibliotheken zur Validierung von Anforderungen oder zur Codegenerierung, Debugging-Tools für ausgehende API-Anforderungen für mobile Anwendungen (Caching-Proxy), Lasttests Mit der Einrichtung von Flusstests durch Anmerkungen werden verschiedene Plugins für die Integration mit externen Diensten erstellt.
Diese Idee des Dienstes enthält klare Vorteile gegenüber vorhandenen Diensten für die Verwaltung von API-Spezifikationen, und ihre Implementierung ebnet den Weg für eine mögliche Änderung des Ansatzes für die Implementierung externer Systeme, die in irgendeiner Weise mit der API zusammenhängen.
Zweite Schlussfolgerung
Der Zweck dieses Artikels besteht nicht darin, Swagger, Apiary oder andere De-facto-Standardtools für die Entwicklung von APIs zu kritisieren, sondern den konzeptionellen Unterschied zum Ansatz der von RAML geförderten Entwurfsspezifikationen zu untersuchen, zunächst das Konzept des
Vertrags einzuführen und die Möglichkeit seiner Implementierung auf der Grundlage von RAML zu prüfen. Ein weiteres Ziel war der Wunsch, die wohlverdiente Aufmerksamkeit der Entwickler auf RAML für die weitere mögliche Entwicklung seiner Community zu lenken.
Offizielle Seite RAMLSchlaffer KanalSpezifikationVielen Dank für Ihre Aufmerksamkeit.