Hallo Habr, wir möchten über eines der Projekte der School of Programmers HeadHunter 2018 sprechen. Nachfolgend finden Sie einen Artikel unseres Absolventen, in dem er über die während des Trainings gesammelten Erfahrungen sprechen wird.

Hallo an alle. Dieses Jahr habe ich die hh School of Programmers abgeschlossen und in diesem Beitrag werde ich über das Trainingsprojekt sprechen, an dem ich teilgenommen habe. Während des Trainings in der Schule und insbesondere während des Projekts fehlte mir ein Beispiel für eine Kampfanwendung (und noch besser eine Anleitung), in der ich sehen konnte, wie man die Logik richtig trennt und eine skalierbare Architektur erstellt. Alle Artikel, die ich fand, waren für einen Anfänger schwer zu verstehen Entweder wurde IoC in ihnen aktiv verwendet, ohne umfassende Erklärungen zum Hinzufügen neuer oder Ändern alter Komponenten, oder sie waren archaisch und enthielten eine Menge XML-Konfigurationen und ein JSP-Frontend. Ich habe versucht, mich vor dem Training auf mein Niveau zu konzentrieren, d.h. Mit ein paar Einschränkungen fast Null, daher sollte dieser Artikel sowohl für zukünftige Schüler der Schule als auch für autodidaktische Enthusiasten nützlich sein, die beschlossen haben, in Java zu schreiben.
Gegeben (Erklärung des Problems)
Team - 5 Personen. Laufzeit - jeweils 3 Monate - eine Demo. Ziel ist es, eine Anwendung zu erstellen, mit der die Personalabteilung die Mitarbeiter während einer Testphase begleitet und alle sich daraus ergebenden Prozesse automatisiert. Am Eingang wurde uns mitgeteilt, wie die Probezeit (IS) jetzt angeordnet ist: Sobald bekannt wird, dass ein neuer Mitarbeiter herauskommt, tritt die Personalabteilung den zukünftigen Leiter, um Aufgaben für das geistige Eigentum festzulegen, und dies muss vor dem ersten Arbeitstag erfolgen. An dem Tag, an dem der Mitarbeiter zur Arbeit geht, hält die Personalabteilung ein Begrüßungsgespräch ab, spricht über die Infrastruktur des Unternehmens und übergibt Aufgaben für das geistige Eigentum. Nach 1,5 und 3 Monaten findet ein Zwischen- und Abschlusstreffen von HR, Leiter und Mitarbeiter statt, bei dem der Erfolg der Passage besprochen und ein Ergebnisformular erstellt wird. Bei Erfolg erhält der Mitarbeiter nach der Abschlussbesprechung einen gedruckten Fragebogen für einen Anfänger (Fragen im Stil "Genießen Sie das Vergnügen des geistigen Eigentums") und erhält eine HR-Aufgabe, die Jira dem VHI-Mitarbeiter ausstellen kann.
Design
Wir haben beschlossen, für jeden Mitarbeiter eine persönliche Seite zu erstellen, auf der allgemeine Informationen angezeigt werden (Name, Abteilung, Manager usw.), ein Feld für Kommentare und Änderungsverlauf, angehängte Dateien (Aufgaben im IP, Fragebogen) und den Workflow der Mitarbeiter Durchgangsniveau von IP. Der Workflow wurde in 8 Phasen unterteilt:
- Stufe 1 - Hinzufügen eines Mitarbeiters: Wird sofort nach der Registrierung eines neuen Mitarbeiters im HR-System abgeschlossen. Gleichzeitig werden drei Kalender an die Personalabteilung gesendet, um eine Zwischen- und Abschlussbesprechung durchzuführen.
- 2. Stufe - Koordination der Aufgaben im IP: An den Leiter wird ein Formular zum Festlegen von Aufgaben im IP gesendet, das die Personalabteilung nach dem Ausfüllen erhält. Als nächstes druckt HR sie aus, signiert sie und markiert den Abschluss der Phase in der Benutzeroberfläche.
- 3. Stufe - Begrüßungsbesprechung: Die Personalabteilung hält eine Besprechung ab und drückt den Knopf „Stufe abgeschlossen“.
- 4. Stufe - Zwischenbesprechung: ähnlich der dritten Stufe
- Die 5. Phase - die Ergebnisse eines Zwischenmeetings: HR gibt die Ergebnisse auf der Seite des Mitarbeiters ein und klickt auf "Weiter".
- 6. Stufe - Abschlussbesprechung: ähnlich der dritten Stufe
- 7. Stufe - Ergebnisse der Abschlussbesprechung: ähnlich der fünften Stufe
- 8. Stufe - Ausfüllen des IP: Bei erfolgreichem Ausfüllen des IP wird dem Mitarbeiter per E-Mail ein Link zum Formular des Fragebogens zugesandt, und in jira wird automatisch eine Aufgabe zur Registrierung der freiwilligen Krankenversicherung erstellt (wir haben die Aufgabe von Hand erhalten).
Alle Phasen haben Zeit. Danach gilt die Phase als abgelaufen und wird rot hervorgehoben. Eine Benachrichtigung wird per E-Mail gesendet. Die Endzeit muss beispielsweise bearbeitet werden können, wenn die Zwischenbesprechung auf einen Feiertag fällt oder die Besprechung aus irgendeinem Grund verschoben werden muss.
Leider sind die auf einem Stück Papier / Karton gezeichneten Prototypen nicht erhalten geblieben, aber am Ende werden Screenshots der fertigen Anwendung angezeigt.
Bedienung
Eines der Ziele der Schule ist es, die Schüler auf die Arbeit in großen Projekten vorzubereiten. Daher war der Prozess der Freigabe von Aufgaben für uns angemessen.
Am Ende der Arbeit an der Aufgabe geben wir sie einem anderen Schüler aus dem Team zur Überprüfung_1, um offensichtliche Fehler zu korrigieren / Erfahrungen auszutauschen. Dann kommt review_2 - die Aufgabe wird von zwei Mentoren überprüft, die sicherstellen, dass wir den Govnokod nicht zusammen mit dem Reviewer_1 freigeben. Weitere Tests wurden angenommen, aber diese Phase ist angesichts des Umfangs des Schulprojekts nicht sehr angemessen. Nachdem wir die Überprüfung durchlaufen hatten, dachten wir, dass die Aufgabe zur Veröffentlichung bereit war.
Nun ein paar Worte zur Bereitstellung. Die Anwendung sollte von allen Computern aus jederzeit im Netzwerk verfügbar sein. Zu diesem Zweck haben wir eine billige virtuelle Maschine gekauft (für 100 Rubel / Monat), aber wie ich später herausfand, konnte im AWS-Docker alles kostenlos und modisch arrangiert werden. Für die kontinuierliche Integration haben wir Travis gewählt. Wenn jemand es nicht weiß (ich persönlich habe vor der Schule noch nichts von kontinuierlicher Integration gehört), ist dies eine so coole Sache, dass Ihr Github sie überwacht. Wenn ein neues Commit angezeigt wird (wie es konfiguriert wird), sammeln Sie den Code in jar, senden Sie ihn an den Server und starten Sie die Anwendung automatisch neu. Wie man es baut, ist im Travis Jam im Stammverzeichnis des Projekts beschrieben. Es ist Bash ziemlich ähnlich, daher denke ich, dass keine Kommentare erforderlich sind. Wir haben auch die Domain www.adaptation.host gekauft , um keine hässliche IP-Adresse in der Adressleiste der Demo zu registrieren. Wir haben auch Postfix (zum Senden von E-Mails), Apache (nicht Nginx, da Apache sofort verfügbar war) und den Jira-Server (Testserver) konfiguriert. Das Frontend und das Backend wurden von zwei separaten Diensten erstellt, die über http (# 2k18, # microservices) kommunizieren. Dieser Teil des Artikels „an der HeadHunter School of Programmers“ endet reibungslos und wir gehen zum Java Rest Service über.
Backend
0. Einleitung
Wir haben die folgenden Technologien verwendet:
- JDK 1,8;
- Maven 3.5.2;
- Postgres 9,6;
- Ruhezustand 5.2.10;
- Anlegestelle 9.4.8;
- Jersey 2.27.
Als Framework haben wir NaB 3.5.0 von hh genommen. Erstens wird es in HeadHunter verwendet, und zweitens enthält es Steg, Trikot, Winterschlaf und eingebettete Postgres aus der Box, die auf dem Github geschrieben sind. Ich werde für Anfänger kurz erläutern: Jetty ist ein Webserver, der Clients identifiziert und Sitzungen für jeden von ihnen organisiert. Trikot - ein Framework, mit dem Sie bequem einen RESTful-Service erstellen können; Ruhezustand - ORM zur Vereinfachung der Arbeit mit der Datenbank; Maven ist ein Java-Projektsammler.
Ich werde ein einfaches Beispiel zeigen, wie man damit arbeitet. Ich habe ein kleines Test-Repository erstellt , in dem ich zwei Entitäten hinzugefügt habe: einen Benutzer und einen Lebenslauf sowie Ressourcen zum Erstellen und Empfangen dieser Entitäten mit dem OneToMany / ManyToOne-Link. Klonen Sie zunächst das Repository und führen Sie mvn clean install exec: java im Stammverzeichnis des Projekts aus. Bevor ich den Code kommentiere, werde ich Ihnen die Struktur unseres Service erläutern. Es sieht ungefähr so aus:
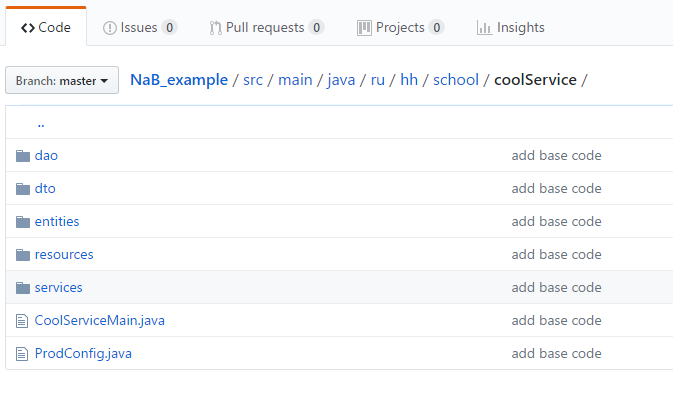
Hauptverzeichnisse:
- Dienste - Das Hauptverzeichnis in der Anwendung, in dem die gesamte Geschäftslogik gespeichert ist. An anderen Orten sollte das Arbeiten mit Daten ohne guten Grund nicht sein.
- Ressourcen - URL-Handler, eine Ebene zwischen Diensten und dem Frontend. Die Validierung eingehender Daten und die Konvertierung ausgehender Daten, jedoch nicht der Geschäftslogik, sind hier zulässig.
- Dao (Datenzugriffsobjekt) - eine Schicht zwischen Datenbank und Diensten. Das Tao sollte nur grundlegende grundlegende Operationen enthalten: Hinzufügen, Zählen, Aktualisieren, Löschen eines / aller.
- Entität - Objekte, die ORM mit der Datenbank austauscht. In der Regel entsprechen sie direkt den Tabellen und sollten alle Felder als Entität in der Datenbank mit den entsprechenden Typen enthalten.
- Dto (Datenübertragungsobjekt) - ein Analogon der Entität, nur für Ressourcen (vorne), hilft dabei, json aus den Daten zu bilden, die wir senden / empfangen möchten.
1. Basis
Auf eine gute Weise sollten Sie die in der Nähe installierten Postgres wie in der Hauptanwendung verwenden, aber ich wollte, dass der Testfall einfach ist und mit einem einzigen Befehl ausgeführt wird, also habe ich die integrierte HSQLDB verwendet. Das Verbinden der Datenbank mit unserer Infrastruktur erfolgt durch Hinzufügen einer DataSource zu ProdConfig (denken Sie auch daran, dem Ruhezustand mitzuteilen, welche Datenbank Sie verwenden):
@Bean(destroyMethod = "shutdown") DataSource dataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.HSQL) .addScript("db/sql/create-db.sql") .build(); }
Ich habe das Skript zur Tabellenerstellung in der Datei create-db.sql erstellt. Sie können andere Skripte hinzufügen, die die Datenbank initialisieren. In unserem einfachen in_memory-Beispiel könnten wir überhaupt auf Skripte verzichten. Wenn Sie in den Einstellungen für hibernate.properties hibernate.hbm2ddl.auto=create angeben, hibernate.hbm2ddl.auto=create der Ruhezustand selbst beim Starten der Anwendung Tabellen nach Entitäten. Wenn Sie jedoch etwas in der Datenbank benötigen, über das die Entität nicht verfügt, können Sie nicht auf eine Datei verzichten. Persönlich bin ich es gewohnt, die Datenbank und die Anwendung gemeinsam zu nutzen, daher vertraue ich normalerweise nicht auf den Ruhezustand, um solche Dinge zu tun.
db/sql/create-db.sql :
CREATE TABLE employee ( id INTEGER IDENTITY PRIMARY KEY, first_name VARCHAR(256) NOT NULL, last_name VARCHAR(256) NOT NULL, email VARCHAR(128) NOT NULL ); CREATE TABLE resume ( id INTEGER IDENTITY PRIMARY KEY, employee_id INTEGER NOT NULL, position VARCHAR(128) NOT NULL, about VARCHAR(256) NOT NULL, FOREIGN KEY (employee_id) REFERENCES employee(id) );
2. Entität
entities/employee :
@Entity @Table(name = "employee") public class Employee { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id", nullable = false) private Integer id; @Column(name = "first_name", nullable = false) private String firstName; @Column(name = "last_name", nullable = false) private String lastName; @Column(name = "email", nullable = false) private String email; @OneToMany(mappedBy = "employee") @OrderBy("id") private List<Resume> resumes;
entities/resume :
@Entity @Table(name = "resume") public class Resume { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "employee_id") private Employee employee; @Column(name = "position", nullable = false) private String position; @Column(name = "about") private String about;
Entitäten verweisen nicht mit dem Klassenfeld aufeinander, sondern mit dem gesamten übergeordneten / untergeordneten Objekt. Daher können wir eine Rekursion erhalten, wenn wir versuchen, aus der Mitarbeiterdatenbank zu entnehmen, für die Lebensläufe erstellt werden, für die ... Um dies zu verhindern, haben wir die Anmerkungen @OneToMany(mappedBy = "employee") und @ManyToOne(fetch = FetchType.LAZY) . Sie werden im Dienst bei der Ausführung einer Schreib- / Lesetransaktion aus der Datenbank berücksichtigt. Das Einrichten von FetchType.LAZY ist optional, aber die Verwendung einer verzögerten Kommunikation erleichtert die Transaktion. Wenn wir also bei einer Transaktion einen Lebenslauf aus der Datenbank erhalten und den Eigentümer nicht kontaktieren, wird die Mitarbeiterentität nicht geladen. Sie können dies selbst überprüfen: Entfernen Sie FetchType.LAZY und sehen Sie im Debug, dass es zusammen mit dem Lebenslauf vom Dienst zurückgegeben wird. Sie sollten jedoch vorsichtig sein. Wenn wir keinen Mitarbeiter in die Transaktion geladen haben, kann der Zugriff auf die Mitarbeiterfelder außerhalb der Transaktion eine LazyInitializationException .
3. Dao
In unserem Fall sind EmployeeDao und ResumeDao fast identisch, daher werde ich hier nur einen davon nennen
EmployeeDao :
public class EmployeeDao { private final SessionFactory sessionFactory; @Inject public EmployeeDao(SessionFactory sessionFactory) { this.sessionFactory = sessionFactory; } public void save(Employee employee) { sessionFactory.getCurrentSession().save(employee); } public Employee getById(Integer id) { return sessionFactory.getCurrentSession().get(Employee.class, id); } }
Die @Inject bedeutet, dass im Konstruktor unseres Dao Dependency Injection verwendet wird. In meinem früheren Leben, einem Physiker, der Dateien parzellierte, Diagramme auf der Grundlage der Ergebnisse von Zahlen erstellte und zumindest herausfand, dass solche Konstruktionen in Java-Handbüchern etwas verrückt wirkten. Und in der Schule ist dieses Thema vielleicht das offensichtlichste, IMHO. Glücklicherweise gibt es im Internet viel Material über DI. Wenn Sie zu faul zum Lesen sind, können Sie im ersten Monat die Regel befolgen: Registrieren Sie neue Ressourcen / Dienste / Tao in unserer Kontextkonfiguration und fügen Sie dem Mapping Entitäten hinzu. Wenn Sie einige Dienste / Tao in anderen verwenden müssen, müssen Sie sie wie oben gezeigt mit der Annotation Inject im Konstruktor hinzufügen, und die Feder initialisiert alles für Sie. Aber dann muss man sich noch um DI kümmern.
4. Dto
Dto ist wie dao für Mitarbeiter und Lebenslauf nahezu identisch. Wir betrachten hier nur employeeDto. Wir benötigen zwei Klassen: EmployeeCreateDto , erforderlich beim Erstellen eines Mitarbeiters; EmployeeDto wird beim Empfang verwendet (enthält zusätzliche Felder id und resumes ). Das id Feld wird hinzugefügt, damit wir in Zukunft auf Anfrage von außen mit Mitarbeitern zusammenarbeiten können, ohne eine vorläufige Suche der Entität per email . Das Feld resumes , um einen Mitarbeiter zusammen mit allen Lebensläufen in einer Anfrage zu empfangen. Es wäre möglich, mit einem dto für alle Vorgänge zu verwalten, aber dann müssten wir für die Liste aller Lebensläufe eines bestimmten Mitarbeiters eine zusätzliche Ressource wie getResumesByEmployeeEmail erstellen, den Code mit benutzerdefinierten Datenbankabfragen verschmutzen und alle von ORM bereitgestellten Annehmlichkeiten streichen.
EmployeeCreateDto :
public class EmployeeCreateDto { public String firstName; public String lastName; public String email; }
EmployeeDto :
public class EmployeeDto { public Integer id; public String firstName; public String lastName; public String email; public List<ResumeDto> resumes; public EmployeeDto(){ } public EmployeeDto(Employee employee){ id = employee.getId(); firstName = employee.getFirstName(); lastName = employee.getLastName(); email = employee.getEmail(); if (employee.getResumes() != null) { resumes = employee.getResumes().stream().map(ResumeDto::new).collect(Collectors.toList()); } } }
Ich mache noch einmal darauf aufmerksam, dass das Schreiben von Logik in dto so unanständig ist, dass alle Felder als public , um keine Getter und Setter zu verwenden.
5. Service
EmployeeService :
public class EmployeeService { private EmployeeDao employeeDao; private ResumeDao resumeDao; @Inject public EmployeeService(EmployeeDao employeeDao, ResumeDao resumeDao) { this.employeeDao = employeeDao; this.resumeDao = resumeDao; } @Transactional public EmployeeDto createEmployee(EmployeeCreateDto employeeCreateDto) { Employee employee = new Employee(); employee.setFirstName(employeeCreateDto.firstName); employee.setLastName(employeeCreateDto.lastName); employee.setEmail(employeeCreateDto.email); employeeDao.save(employee); return new EmployeeDto(employee); } @Transactional public ResumeDto createResume(ResumeCreateDto resumeCreateDto) { Resume resume = new Resume(); resume.setEmployee(employeeDao.getById(resumeCreateDto.employeeId)); resume.setPosition(resumeCreateDto.position); resume.setAbout(resumeCreateDto.about); resumeDao.save(resume); return new ResumeDto(resume); } @Transactional(readOnly = true) public EmployeeDto getEmployeeById(Integer id) { return new EmployeeDto(employeeDao.getById(id)); } @Transactional(readOnly = true) public ResumeDto getResumeById(Integer id) { return new ResumeDto(resumeDao.getById(id)); } }
Diese Transaktionen, die uns vor LazyInitializationException schützen (und nicht nur). Um Transaktionen im Ruhezustand zu verstehen, empfehle ich hervorragende Arbeit am Hub ( lesen Sie mehr ... ), was mir zu gegebener Zeit sehr geholfen hat.
6. Ressourcen
Fügen Sie abschließend die Ressourcen hinzu, um unsere Entitäten zu erstellen und abzurufen:
EmployeeResource :
@Path("/") @Singleton public class EmployeeResource { private final EmployeeService employeeService; public EmployeeResource(EmployeeService employeeService) { this.employeeService = employeeService; } @GET @Produces("application/json") @Path("/employee/{id}") @ResponseBody public Response getEmployee(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getEmployeeById(id)) .build(); } @POST @Produces("application/json") @Path("/employee/create") @ResponseBody public Response createEmployee(@RequestBody EmployeeCreateDto employeeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createEmployee(employeeCreateDto)) .build(); } @GET @Produces("application/json") @Path("/resume/{id}") @ResponseBody public Response getResume(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getResumeById(id)) .build(); } @POST @Produces("application/json") @Path("/resume/create") @ResponseBody public Response createResume(@RequestBody ResumeCreateDto resumeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createResume(resumeCreateDto)) .build(); } }
Produces(“application/json”) benötigt, damit json und dto korrekt ineinander konvertiert werden. Es erfordert eine pom.xml-Abhängigkeit:
<dependency> <groupId>org.glassfish.jersey.media</groupId> <artifactId>jersey-media-json-jackson</artifactId> <version>${jersey.version}</version> </dependency>
Andere JSON-Konverter machen aus irgendeinem Grund ungültigen MediaType verfügbar.
7. Ergebnis
Führen Sie aus und überprüfen Sie, was wir haben ( mvn clean install exec:java im Stammverzeichnis des Projekts). Der Port, auf dem die Anwendung ausgeführt wird, ist in service.properties angegeben . Erstellen Sie einen Benutzer und fahren Sie fort. Ich mache das mit Locken, aber Sie können Postboten verwenden, wenn Sie die Konsole verachten.
curl --header "Content-Type: application/json" \ --request POST \ --data '{"firstName": "Jason", "lastName": "Statham", "email": "jasonst@t.ham"}' \ http://localhost:9999/employee/create curl --header "Content-Type: application/json" \ --request POST \ --data '{"employeeId": 0, "position": "Voditel", "about": "Opyt raboty perevozchikom 15 let"}' \ http://localhost:9999/resume/create curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0 curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0
Alles funktioniert gut. Also haben wir ein Backend, das API bietet. Jetzt können Sie den Service mit dem Frontend starten und die entsprechenden Formulare zeichnen. Dies ist eine gute Grundlage für eine Anwendung, mit der Sie Ihre eigene Anwendung starten können, indem Sie verschiedene Komponenten während der Projektentwicklung konfigurieren.
Fazit
Der Hauptanwendungscode wird auf dem Github mit Anweisungen zum Starten auf der Registerkarte "Wiki" funktionsfähig gehalten. Versprochene Screenshots:
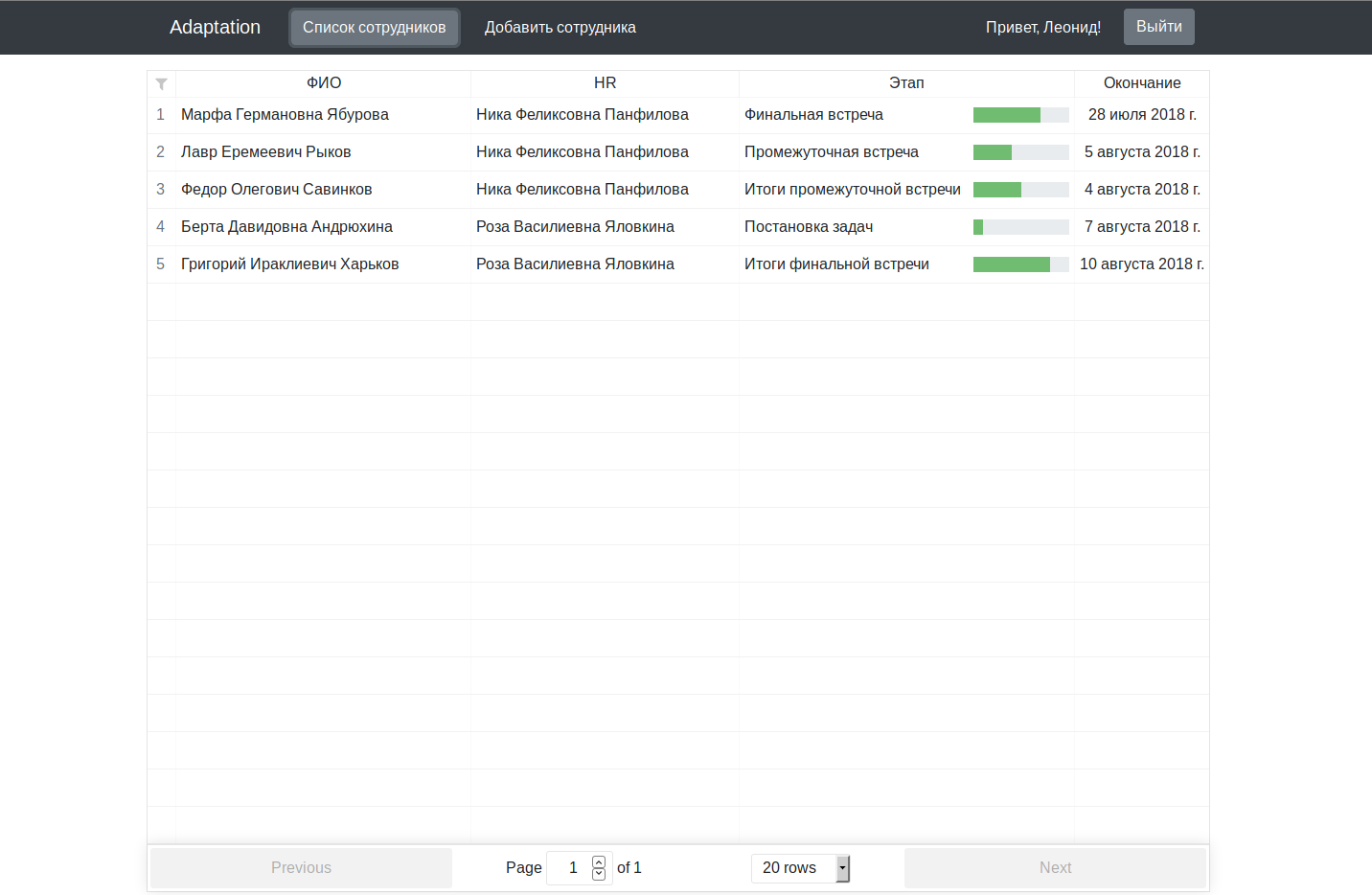
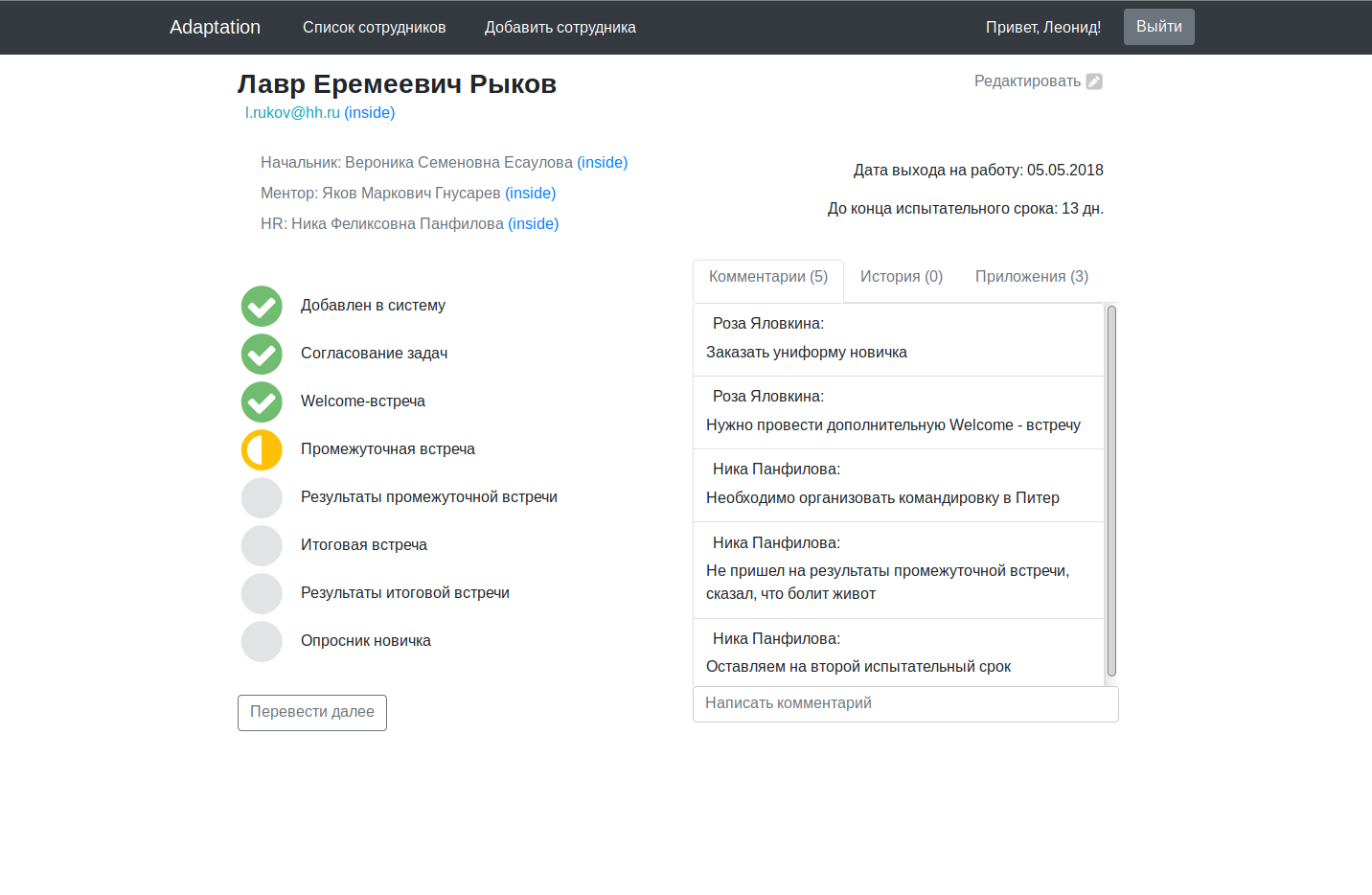
Für ein Multi-Millionen-Dollar-Projekt sieht es natürlich ein wenig feucht aus, aber als Ausrede erinnere ich Sie daran, dass wir am Abend nach der Arbeit / dem Studium daran gearbeitet haben.
Wenn die Anzahl der interessierten Personen die Anzahl der Hausschuhe überschreitet, kann ich dies in Zukunft in eine Reihe von Artikeln umwandeln, in denen ich über die Vorderseite, die Dockerisierung und die Nuancen spreche, die bei der Arbeit mit Mail- / Fett- / Dock-Dateien aufgetreten sind.
PS Nachdem einige Zeit den Schock der Schule überstanden hatte, versammelte sich der Rest des Teams und entschied sich nach Analyse der Flüge für die Anpassung 2.0 unter Berücksichtigung aller Fehler. Das Hauptziel des Projekts ist dasselbe: zu lernen, wie man ernsthafte Anwendungen erstellt, eine durchdachte Architektur aufbaut und von Spezialisten auf dem Markt nachgefragt wird. Sie können die Arbeit im selben Repository verfolgen. Poolanfragen sind willkommen. Vielen Dank für Ihre Aufmerksamkeit und wünschen uns viel Glück!
Brötchen
hoc ioc video vorlesung